
v1.0
Showing
.all-contributorsrc
0 → 100644
.circleci/config.yml
0 → 100644
.gitignore
0 → 100644
.gitmodules
0 → 100644
.pre-commit-config.yaml
0 → 100644
CODE_OF_CONDUCT.md
0 → 100644
CONTRIBUTING.md
0 → 100644
LICENSE
0 → 100644
MANIFEST.in
0 → 100644
README.md
0 → 100644
README_origin.md
0 → 100644
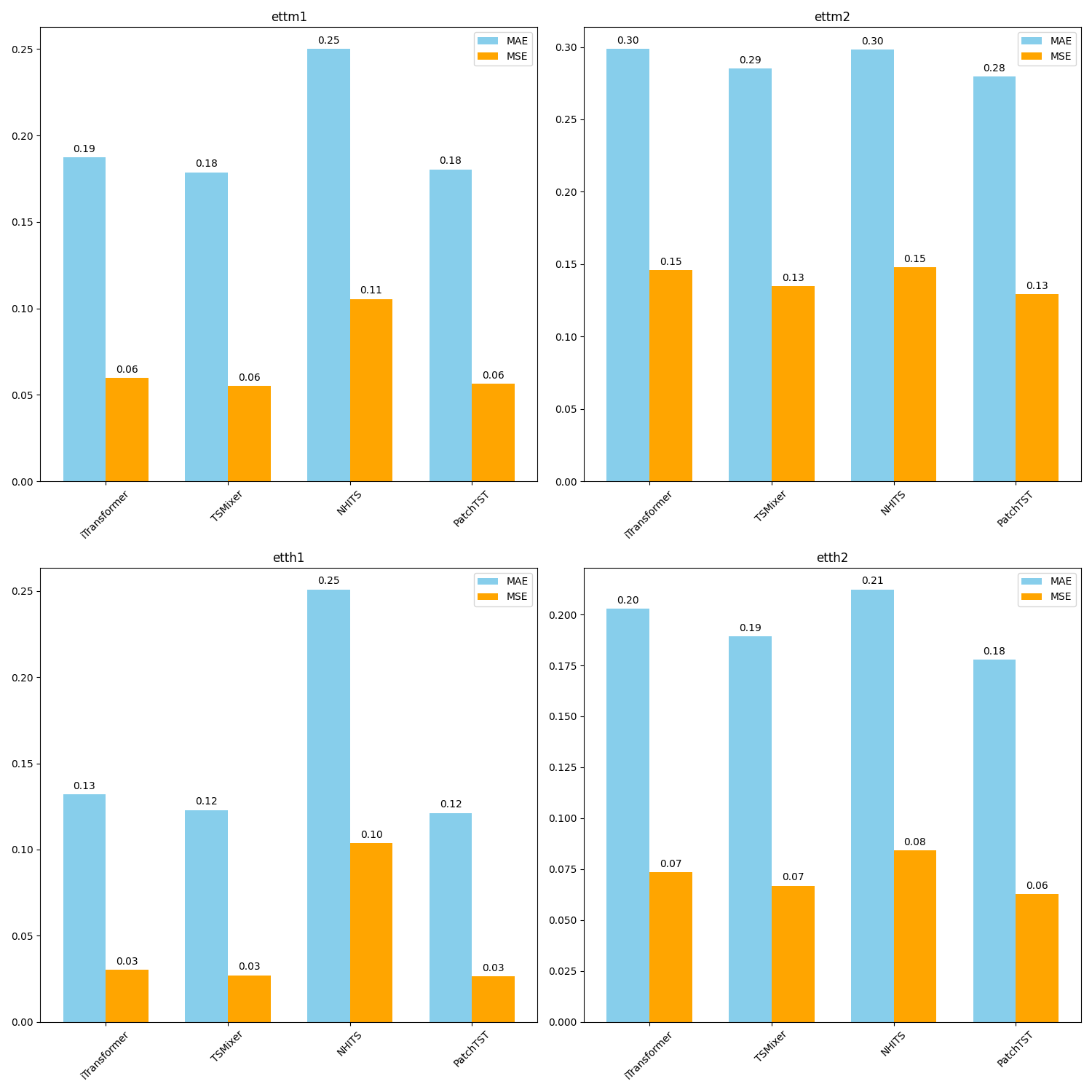
bars.png
0 → 100644
{kind=link}
76.3 KB
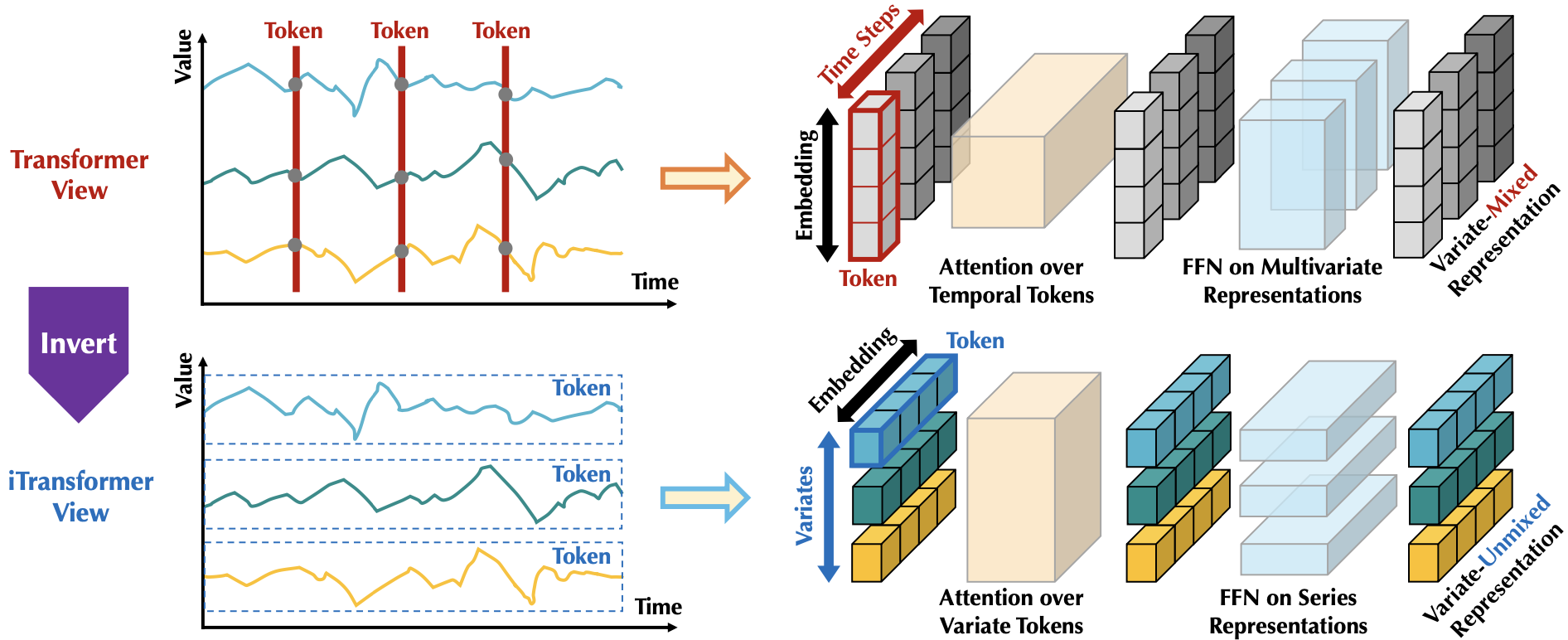
doc/iTransformer.png
0 → 100644
{kind=link}
232 KB