
init
parents
Showing
LICENSE
0 → 100644
README.md
0 → 100644
README_origin.md
0 → 100644
configs/common/dataloader.py
0 → 100755
configs/common/model.py
0 → 100755
configs/common/optimizer.py
0 → 100755
configs/common/scheduler.py
0 → 100755
configs/common/train.py
0 → 100755
configs/matte_anything.py
0 → 100755
doc/Refined.png
0 → 100644
{kind=link}

248 KB
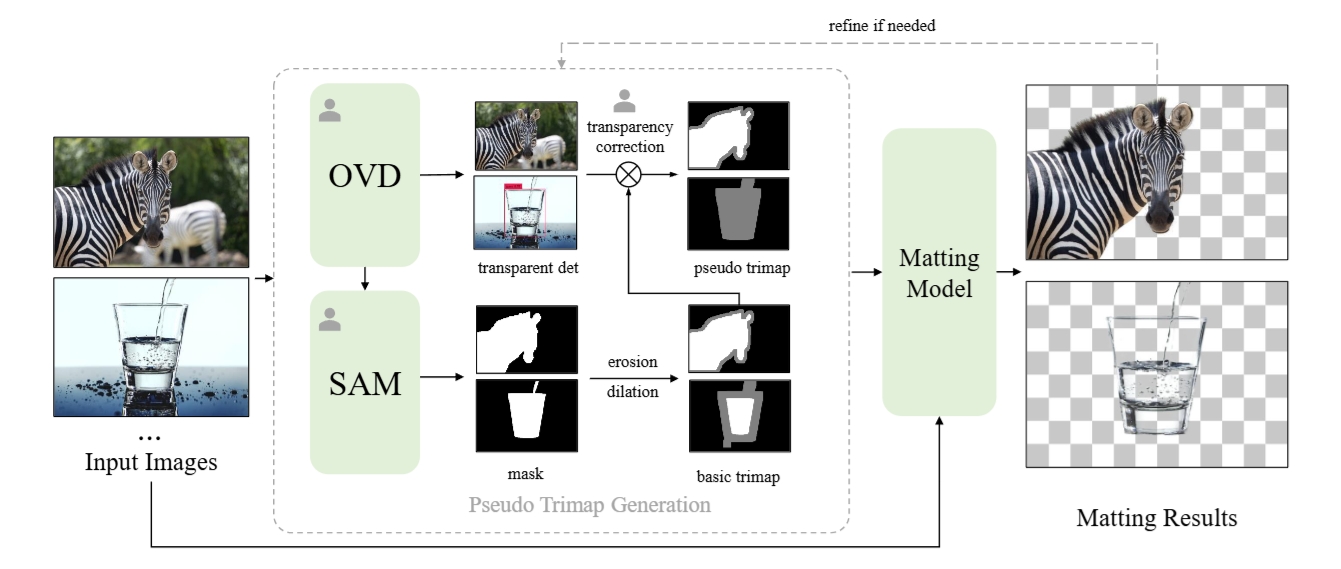
doc/architecture.png
0 → 100644
{kind=link}
196 KB
doc/demo.png
0 → 100644
{kind=link}

6.38 MB
doc/new_background.png
0 → 100644
{kind=link}

3.55 MB
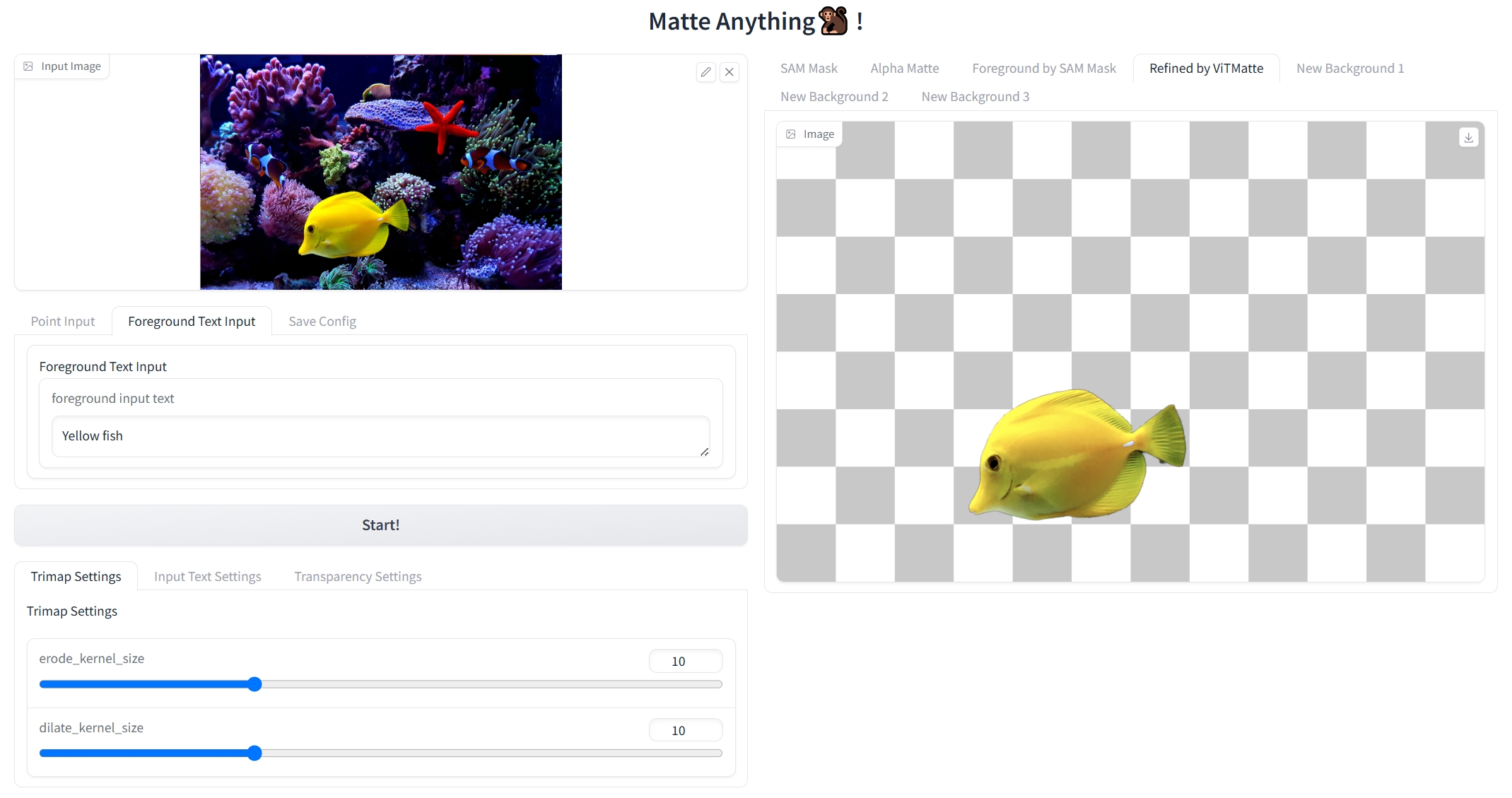
doc/webui.png
0 → 100644
{kind=link}
429 KB
docker/Dockerfile
0 → 100644
engine/__init__.py
0 → 100755
engine/mattingtrainer.py
0 → 100755
figs/demo.png
0 → 100644
{kind=link}

2.69 MB
figs/demo1.png
0 → 100644
{kind=link}

1.76 MB