
init
parents
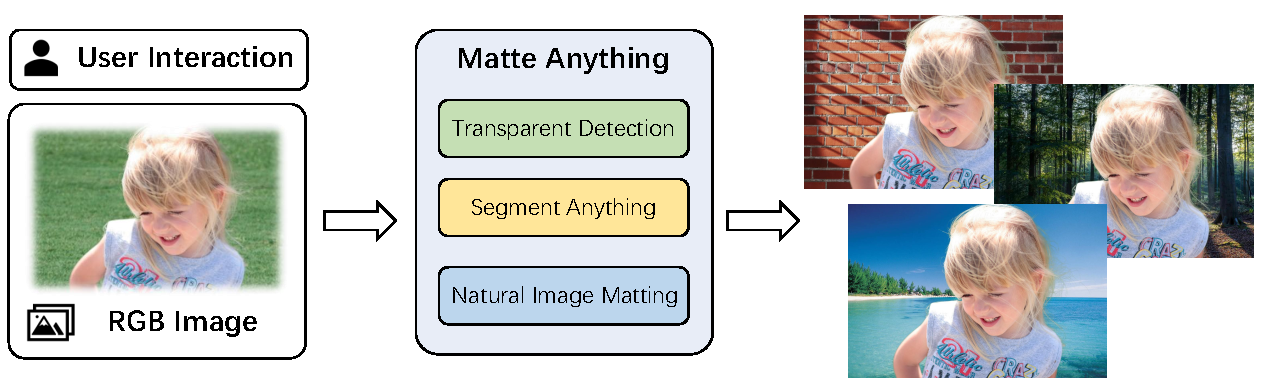
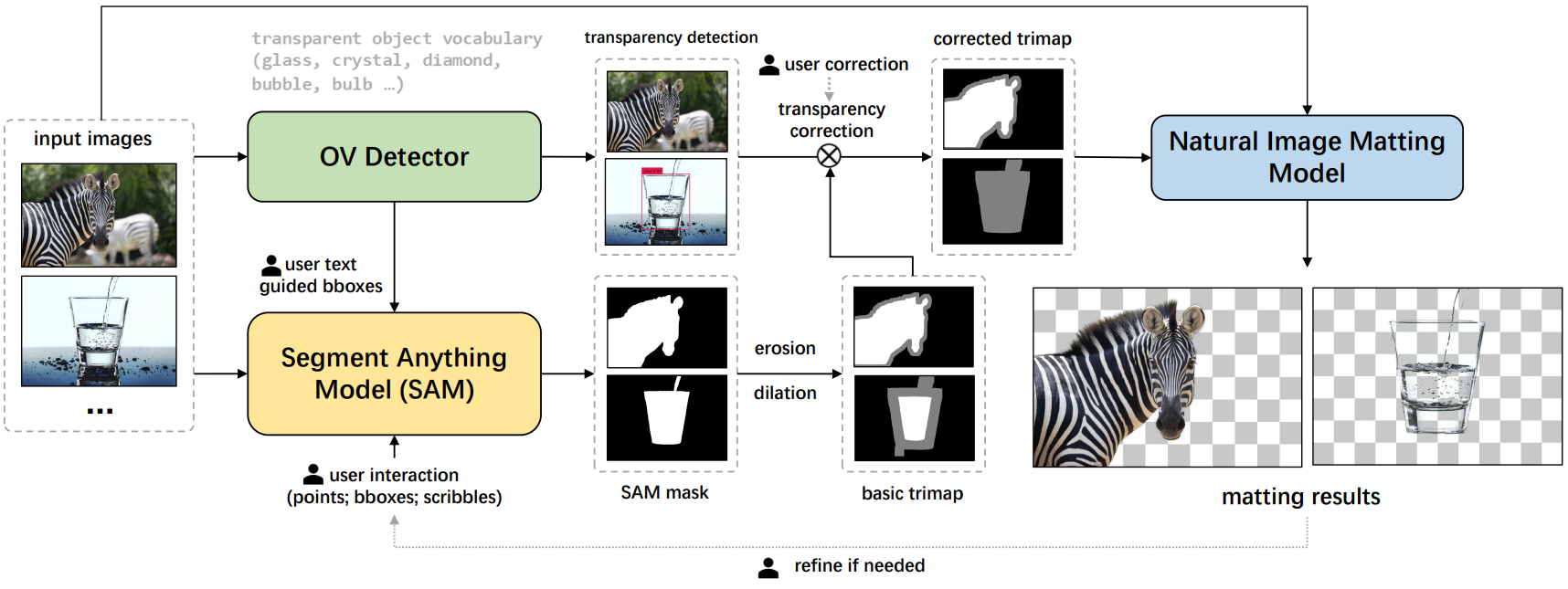
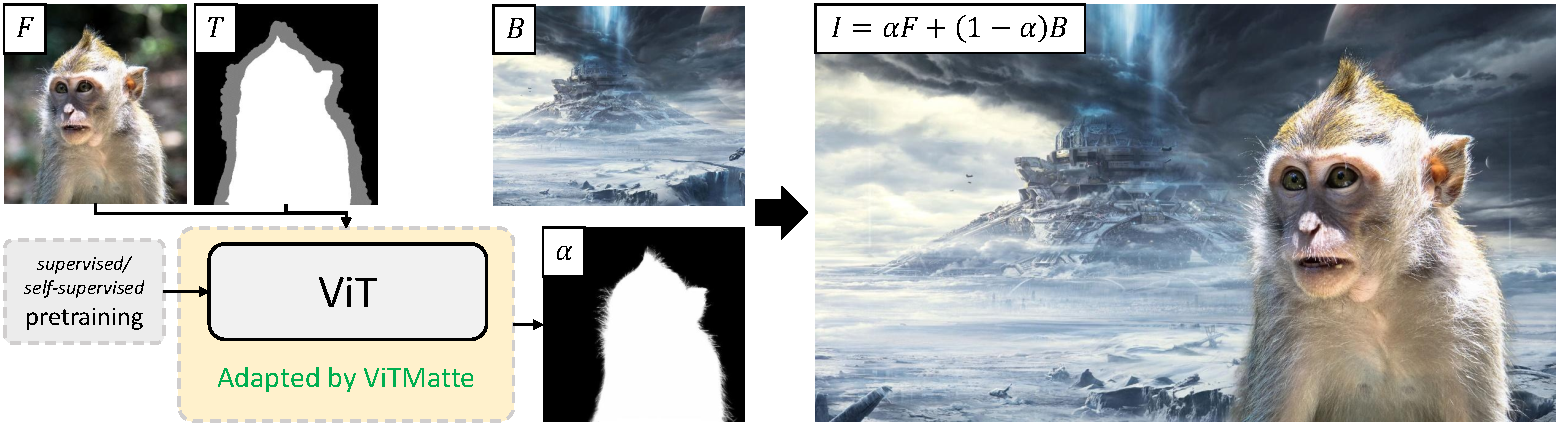
Showing
figs/demo2.png
0 → 100644
{kind=link}

1020 KB
figs/first.png
0 → 100644
{kind=link}
350 KB
figs/forest.jpg
0 → 100755
{kind=link}

203 KB
figs/materials.png
0 → 100644
{kind=link}

1.39 MB
figs/matte-anything.png
0 → 100644
{kind=link}
378 KB
figs/sea.jpg
0 → 100755
{kind=link}

198 KB
figs/sunny.jpg
0 → 100644
{kind=link}

303 KB
figs/vitmatte.png
0 → 100644
{kind=link}
679 KB
figs/web_ui.gif
0 → 100644
{kind=link}
1.07 MB
icon.png
0 → 100644
{kind=link}
68.4 KB
matte_anything.py
0 → 100644
model.properties
0 → 100644
modeling/__init__.py
0 → 100755
File added
File added
File added
File added
File added