
Merge branch 'PaddlePaddle:dygraph' into dygraph
Showing
File moved
File moved
File moved
{kind=link}

49.4 KB
{kind=link}
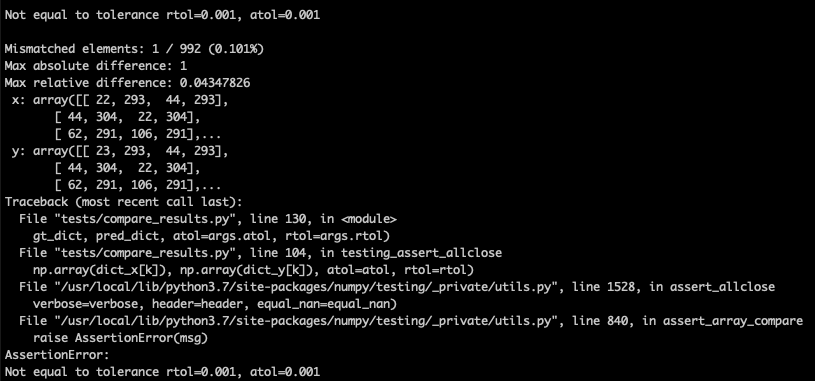
63.3 KB
{kind=link}
{kind=link}
{kind=link}
PTDN/docs/install.md
0 → 100644
PTDN/docs/test.png
0 → 100644
{kind=link}
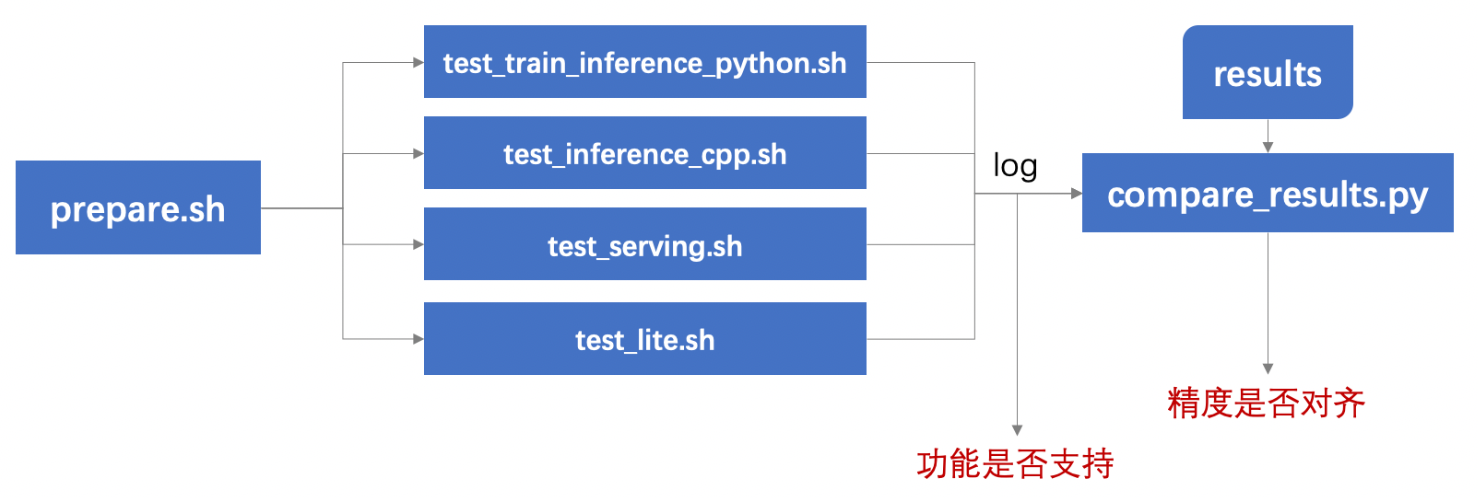
224 KB
PTDN/docs/test_serving.md
0 → 100644