
add new
Showing
.gitignore
0 → 100644
LICENSE
0 → 100644
This diff is collapsed.
README.md
0 → 100644
doc/unet.png
0 → 100644
{kind=link}
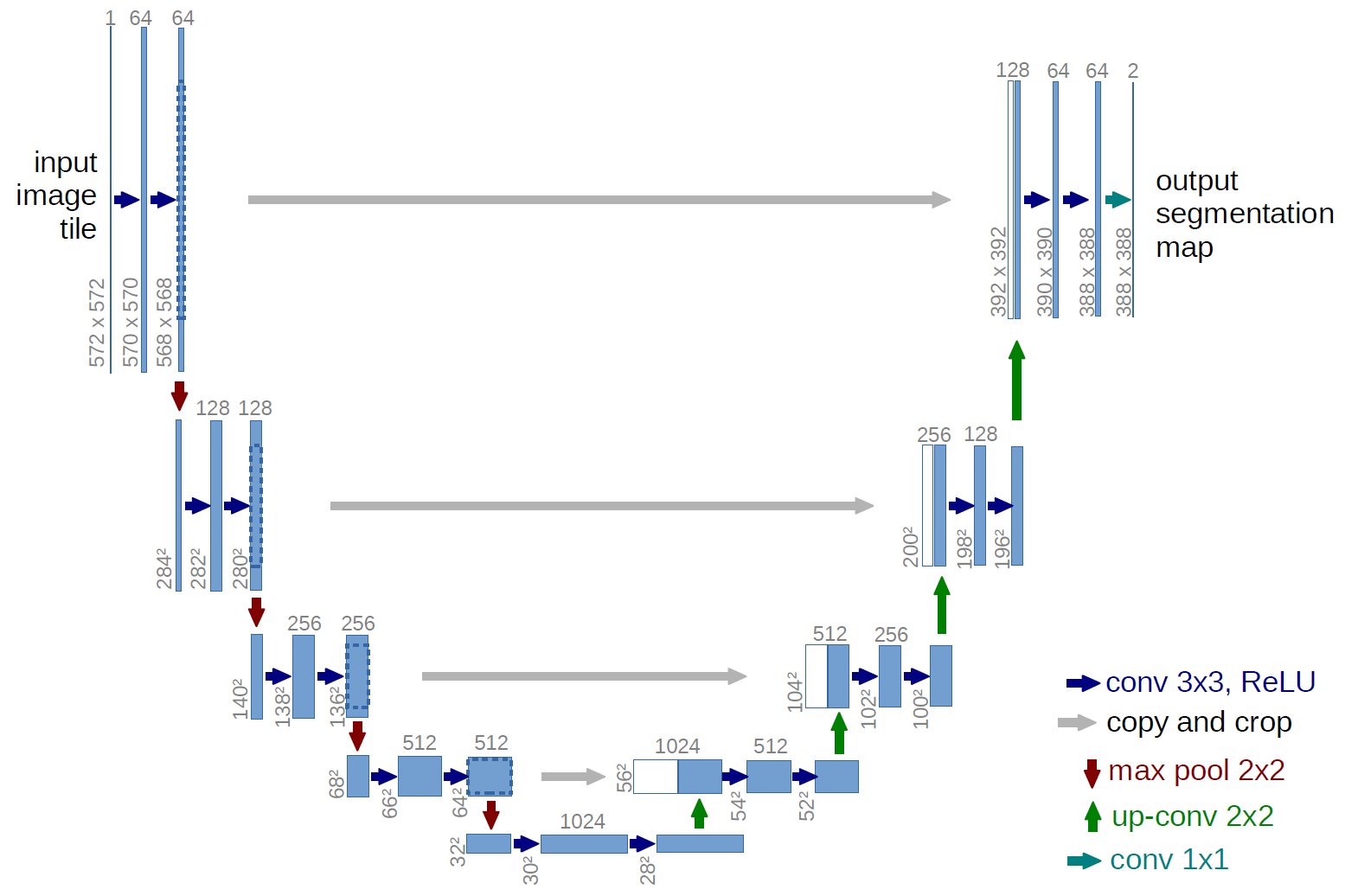
101 KB
doc/原理.png
0 → 100644
{kind=link}
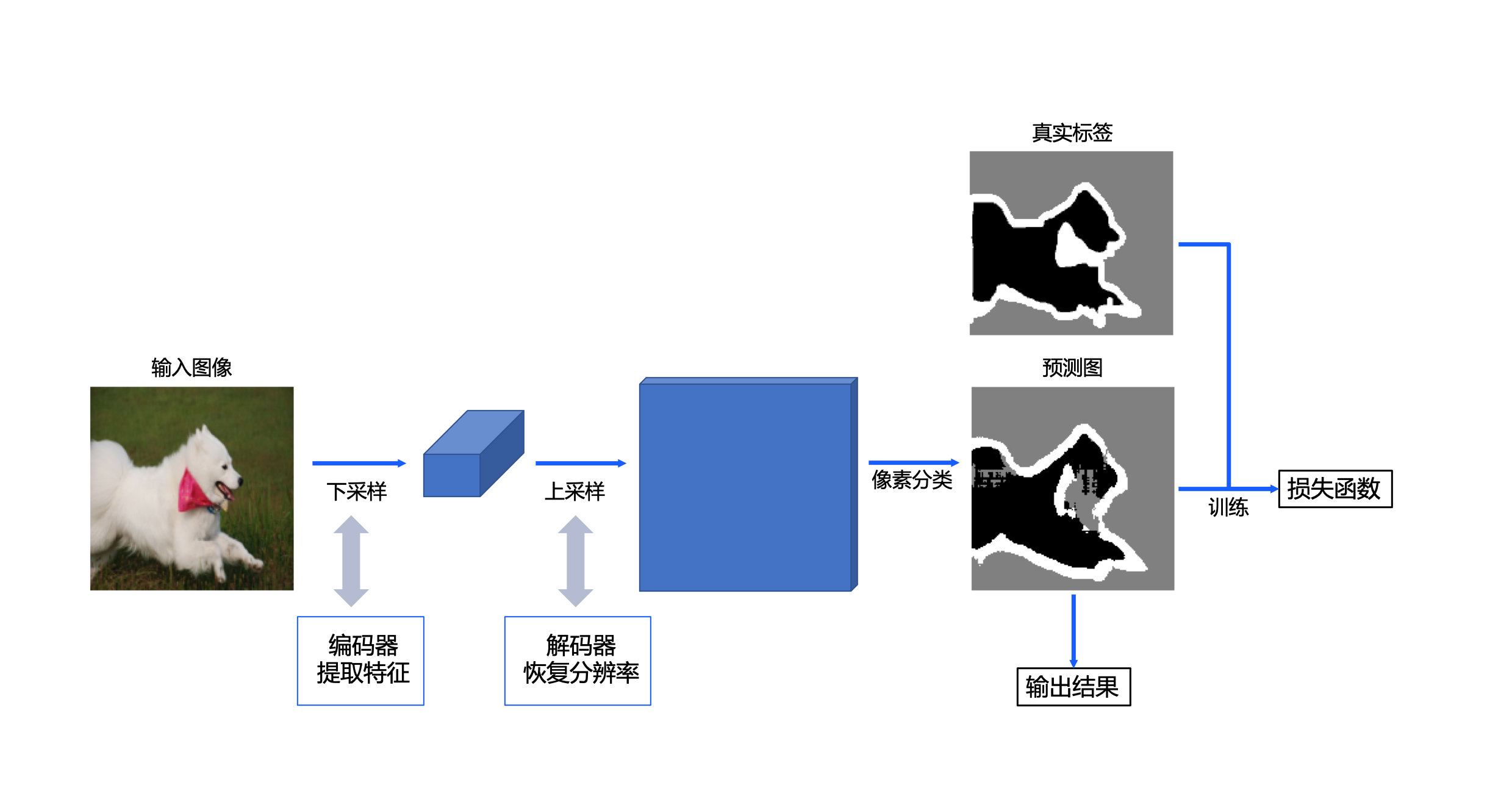
314 KB
doc/结果.png
0 → 100644
{kind=link}
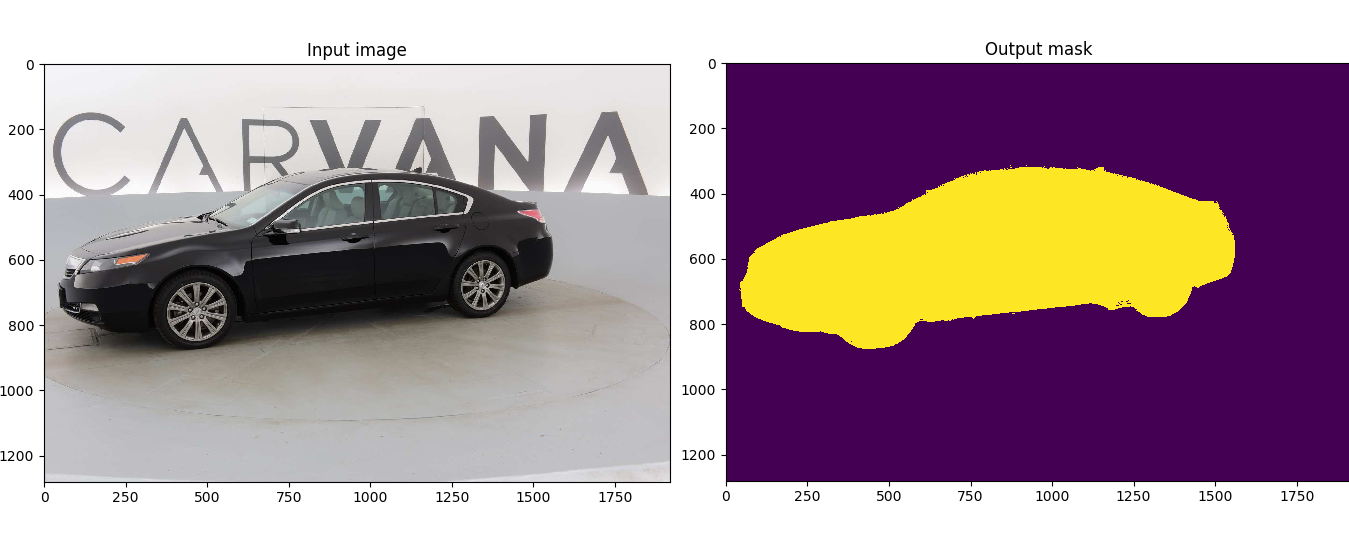
185 KB
evaluate.py
0 → 100644
hubconf.py
0 → 100644
predict.py
0 → 100644
requirements.txt
0 → 100644
| apex==0.1+f49ddd4.abi0.dtk2304.torch1.13 | |||
| matplotlib==3.5.3 | |||
| numpy==1.21.6 | |||
| Pillow==9.5.0 | |||
| Pillow==10.0.1 | |||
| torch==1.13.1+git55d300e.abi0.dtk2304 | |||
| torchvision==0.14.1+git9134838.abi0.dtk2304.torch1.13 | |||
| tqdm==4.65.0 |
scripts/download_data.sh
0 → 100644
train.py
0 → 100644
train_ddp.py
0 → 100644
train_ddp启动.txt
0 → 100644
unet/__init__.py
0 → 100644
unet/unet_model.py
0 → 100644
unet/unet_parts.py
0 → 100644
utils/__init__.py
0 → 100644
utils/data_loading.py
0 → 100644
utils/dice_score.py
0 → 100644