# RepPoints: Point Set Representation for Object Detection
By [Ze Yang](https://yangze.tech/), [Shaohui Liu](http://b1ueber2y.me/), and [Han Hu](https://ancientmooner.github.io/).
We provide code support and configuration files to reproduce the results in the paper for
["RepPoints: Point Set Representation for Object Detection"](https://arxiv.org/abs/1904.11490) on COCO object detection.
## Introduction
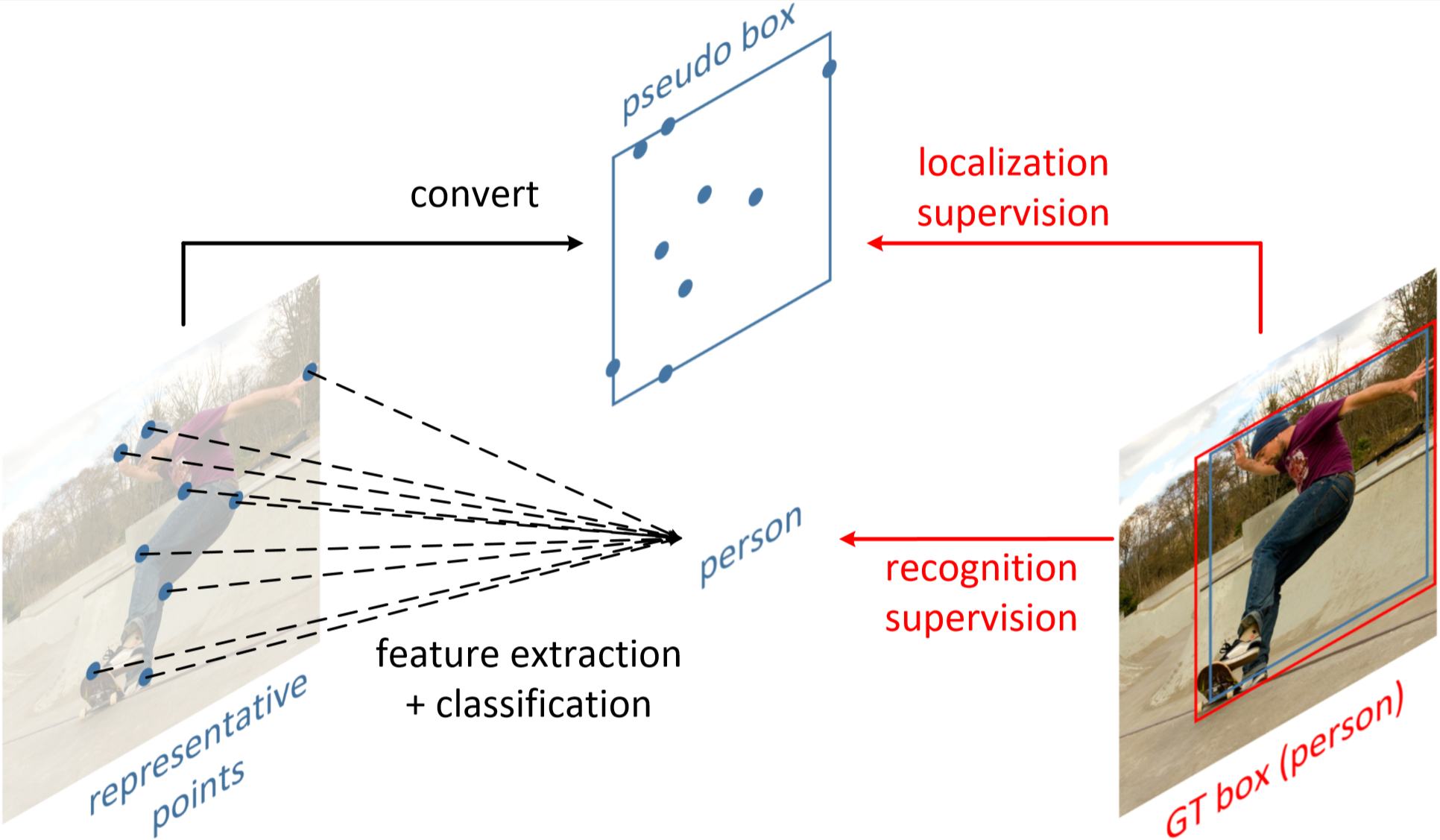
**RepPoints**, initially described in [arXiv](https://arxiv.org/abs/1904.11490), is a new representation method for visual objects, on which visual understanding tasks are typically centered. Visual object representation, aiming at both geometric description and appearance feature extraction, is conventionally achieved by `bounding box + RoIPool (RoIAlign)`. The bounding box representation is convenient to use; however, it provides only a rectangular localization of objects that lacks geometric precision and may consequently degrade feature quality. Our new representation, RepPoints, models objects by a `point set` instead of a `bounding box`, which learns to adaptively position themselves over an object in a manner that circumscribes the object’s `spatial extent` and enables `semantically aligned feature extraction`. This richer and more flexible representation maintains the convenience of bounding boxes while facilitating various visual understanding applications. This repo demonstrated the effectiveness of RepPoints for COCO object detection.
Another feature of this repo is the demonstration of an `anchor-free detector`, which can be as effective as state-of-the-art anchor-based detection methods. The anchor-free detector can utilize either `bounding box` or `RepPoints` as the basic object representation.
<divalign="center">
<imgsrc="reppoints.png"width="400px"/>
<p>Learning RepPoints in Object Detection.</p>
</div>
## Citing RepPoints
```
@inproceedings{yang2019reppoints,
title={RepPoints: Point Set Representation for Object Detection},
author={Yang, Ze and Liu, Shaohui and Hu, Han and Wang, Liwei and Lin, Stephen},
booktitle={The IEEE International Conference on Computer Vision (ICCV)},
month={Oct},
year={2019}
}
```
## Results and models
The results on COCO 2017val are shown in the table below.
| Method | Backbone | Anchor | convert func | Lr schd | box AP | Download |
-`R-xx`, `X-xx` denote the ResNet and ResNeXt architectures, respectively.
-`DCN` denotes replacing 3x3 conv with the 3x3 deformable convolution in `c3-c5` stages of backbone.
-`none` in the `anchor` column means 2-d `center point` (x,y) is used to represent the initial object hypothesis. `single` denotes one 4-d anchor box (x,y,w,h) with IoU based label assign criterion is adopted.
-`moment`, `partial MinMax`, `MinMax` in the `convert func` column are three functions to convert a point set to a pseudo box.
-`ms` denotes multi-scale training or multi-scale test.
- Note the results here are slightly different from those reported in the paper, due to framework change. While the original paper uses an [MXNet](https://mxnet.apache.org/) implementation, we re-implement the method in [PyTorch](https://pytorch.org/) based on mmdetection.

{kind=link}