
提交RetinaFace推理示例
Showing
FaceDetector.onnx
0 → 100644
File added
RetinaFace_infer_migraphx.py
0 → 100644
convert_to_onnx.py
0 → 100644
curve/1.jpg
0 → 100644
{kind=link}

247 KB
curve/FDDB.png
0 → 100644
{kind=link}
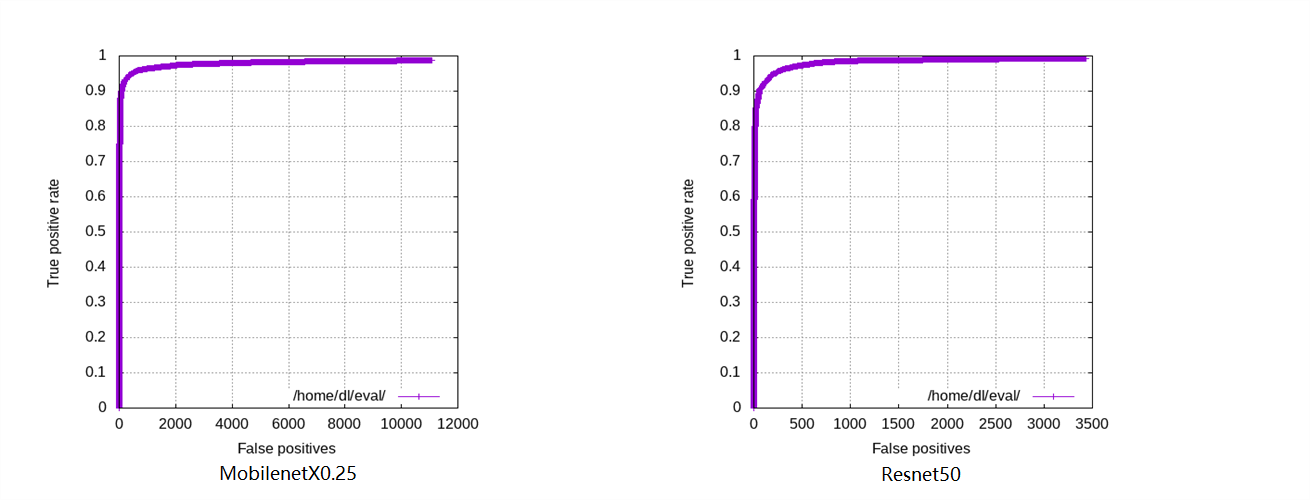
83.7 KB
curve/Result.jpg
0 → 100644
{kind=link}

194 KB
curve/Widerface.jpg
0 → 100644
{kind=link}

221 KB
curve/test.jpg
0 → 100644
{kind=link}

108 KB
data/FDDB/img_list.txt
0 → 100644
This diff is collapsed.
data/__init__.py
0 → 100644
data/config.py
0 → 100644
data/data_augment.py
0 → 100644
data/wider_face.py
0 → 100644
layers/__init__.py
0 → 100644
layers/modules/__init__.py
0 → 100644
models/__init__.py
0 → 100644
models/net.py
0 → 100644