
v1.0
parents
Showing
figures/MiniMaxLogo-Dark.png
0 → 100644
{kind=link}

55.7 KB
{kind=link}

55.5 KB
figures/TextBench.png
0 → 100644
{kind=link}
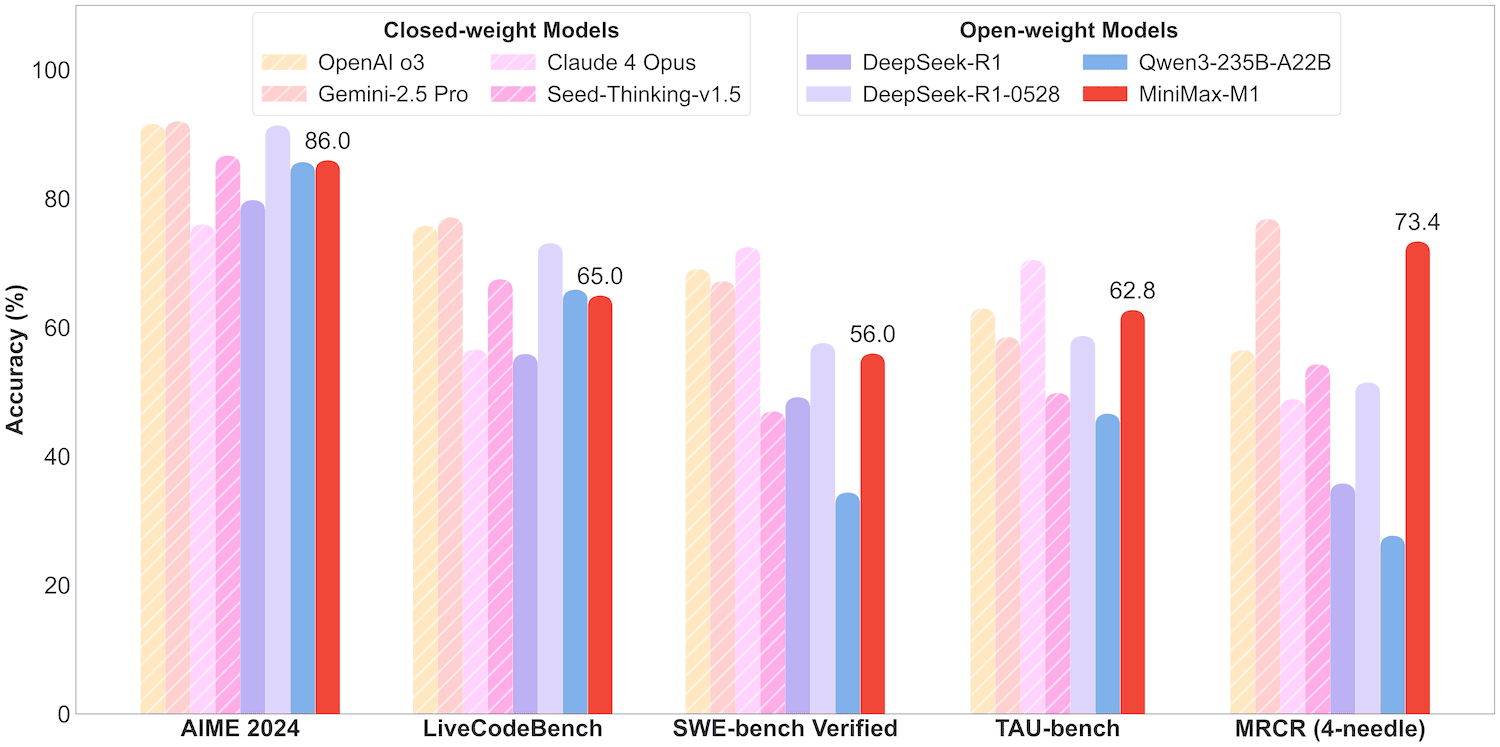
51.7 KB
figures/wechat-qrcode.jpeg
0 → 100644
{kind=link}

88.6 KB
icon.png
0 → 100644
{kind=link}
53.8 KB
infer_vllm.py
0 → 100644
main.py
0 → 100644
merges.txt
0 → 100644
This diff is collapsed.
model.properties
0 → 100644
model.safetensors.index.json
0 → 100644
This diff is collapsed.
modeling_minimax_m1.py
0 → 100644
This diff is collapsed.
tokenizer.json
0 → 100644
This diff is collapsed.
tokenizer_config.json
0 → 100644
vocab.json
0 → 100644
This diff is collapsed.