
Initial commit
parents
Showing
.gitattributes
0 → 100644
.gitignore
0 → 100644
LICENSE.md
0 → 100644
This diff is collapsed.
MinerU_CLA.md
0 → 100644
README.md
0 → 100644
README_ori.md
0 → 100644
This diff is collapsed.
README_zh-CN.md
0 → 100644
This diff is collapsed.
SECURITY.md
0 → 100644
assets/framework.png
0 → 100644
{kind=link}
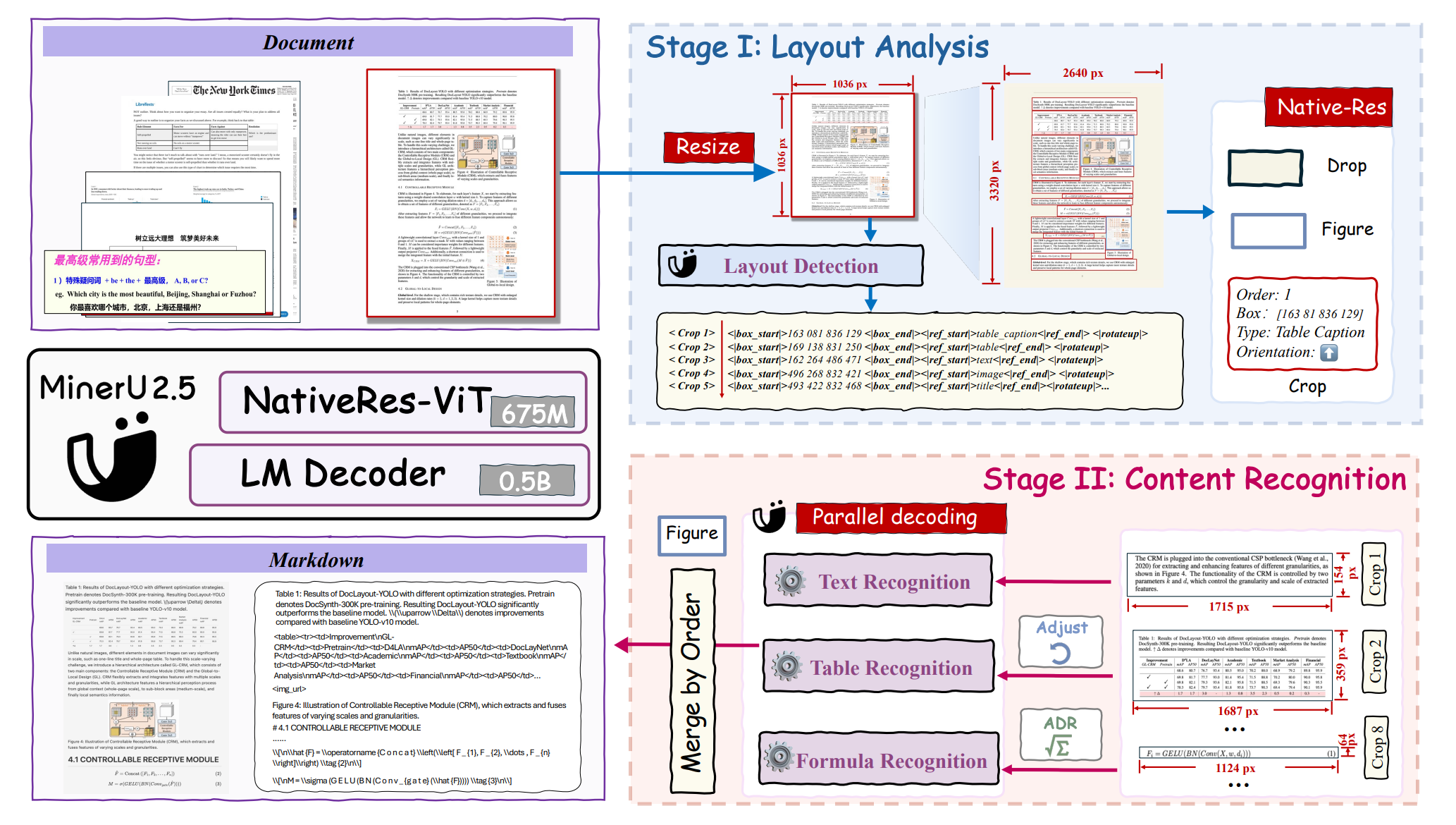
819 KB
assets/layout.png
0 → 100644
{kind=link}

543 KB
assets/result.png
0 → 100644
{kind=link}
413 KB
demo/demo.py
0 → 100644
demo/pdfs/demo1.pdf
0 → 100644
File added
demo/pdfs/demo2.pdf
0 → 100644
File added
demo/pdfs/demo3.pdf
0 → 100644
File added
demo/pdfs/small_ocr.pdf
0 → 100644
File added
docker/Dockerfile
0 → 100644
File added
File added
docs/en/demo/index.md
0 → 100644