
init llama
Showing
README.md
0 → 100644
docs/llama_pri.png
0 → 100644
{kind=link}
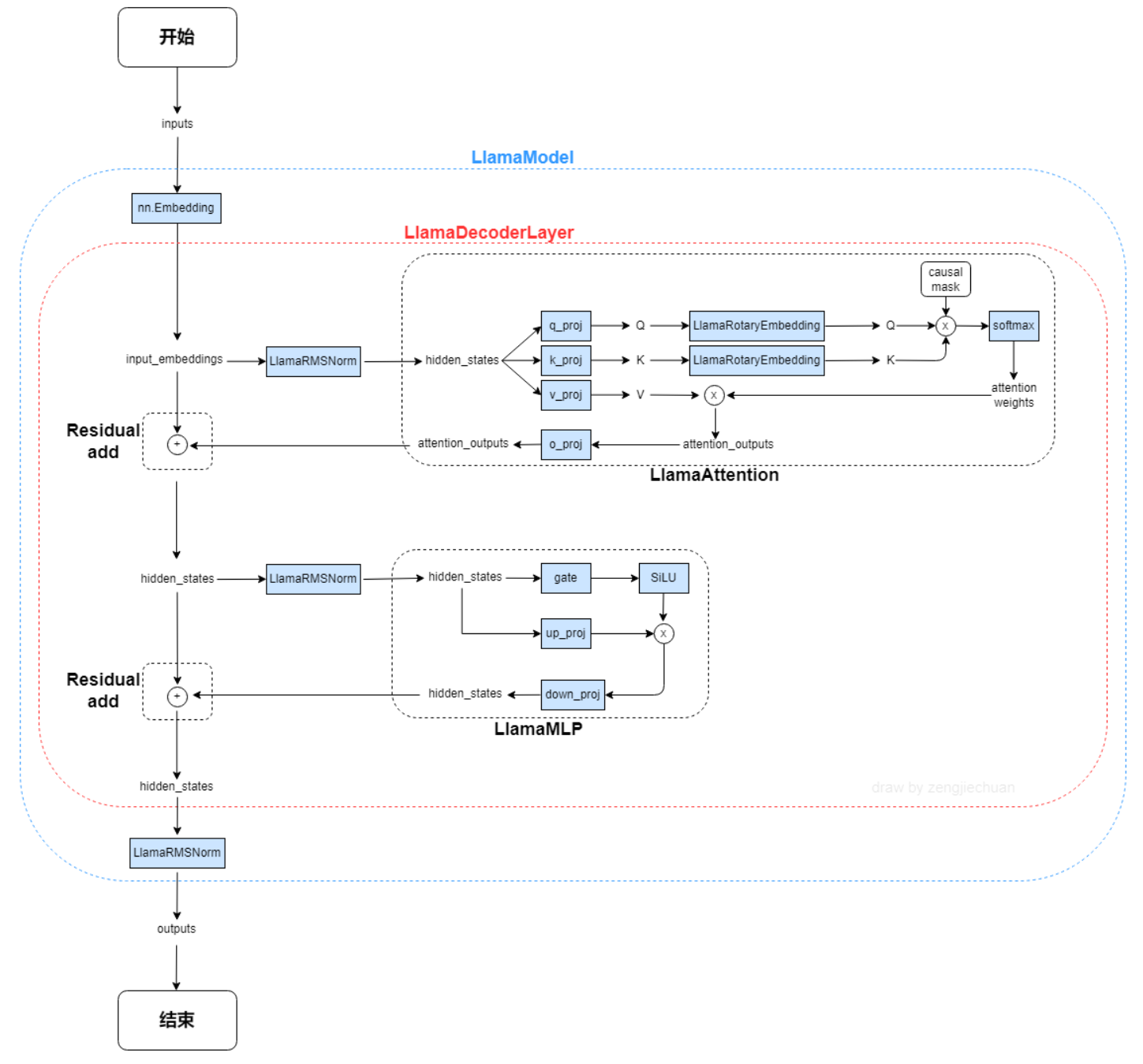
188 KB
docs/llama_str.png
0 → 100644
{kind=link}
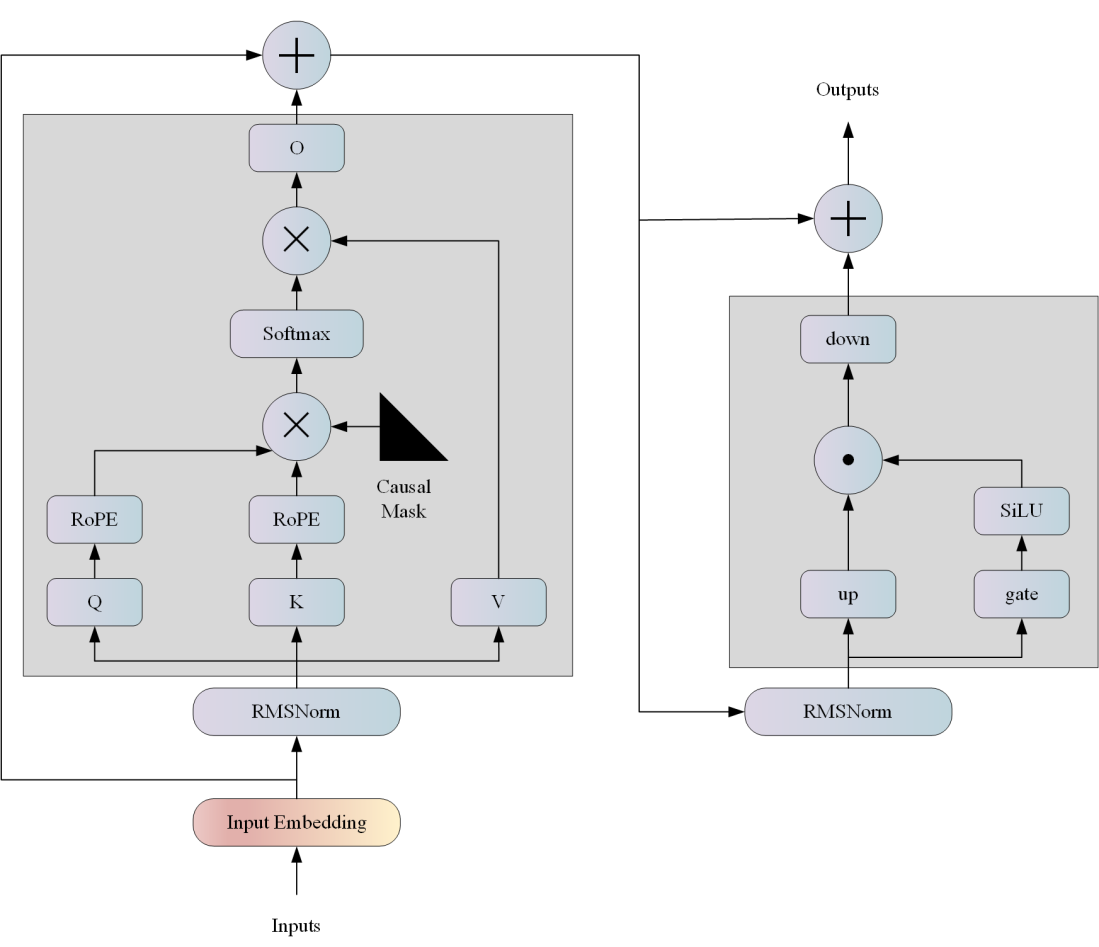
77.3 KB
model.properties
0 → 100644
offline_inference.py
0 → 100644