
lettucedetect
Showing
.gitignore
0 → 100644
Dockerfile
0 → 100644
LICENSE
0 → 100644
MANIFEST.in
0 → 100644
README.md
0 → 100644
assets/architecture.png
0 → 100644
{kind=link}
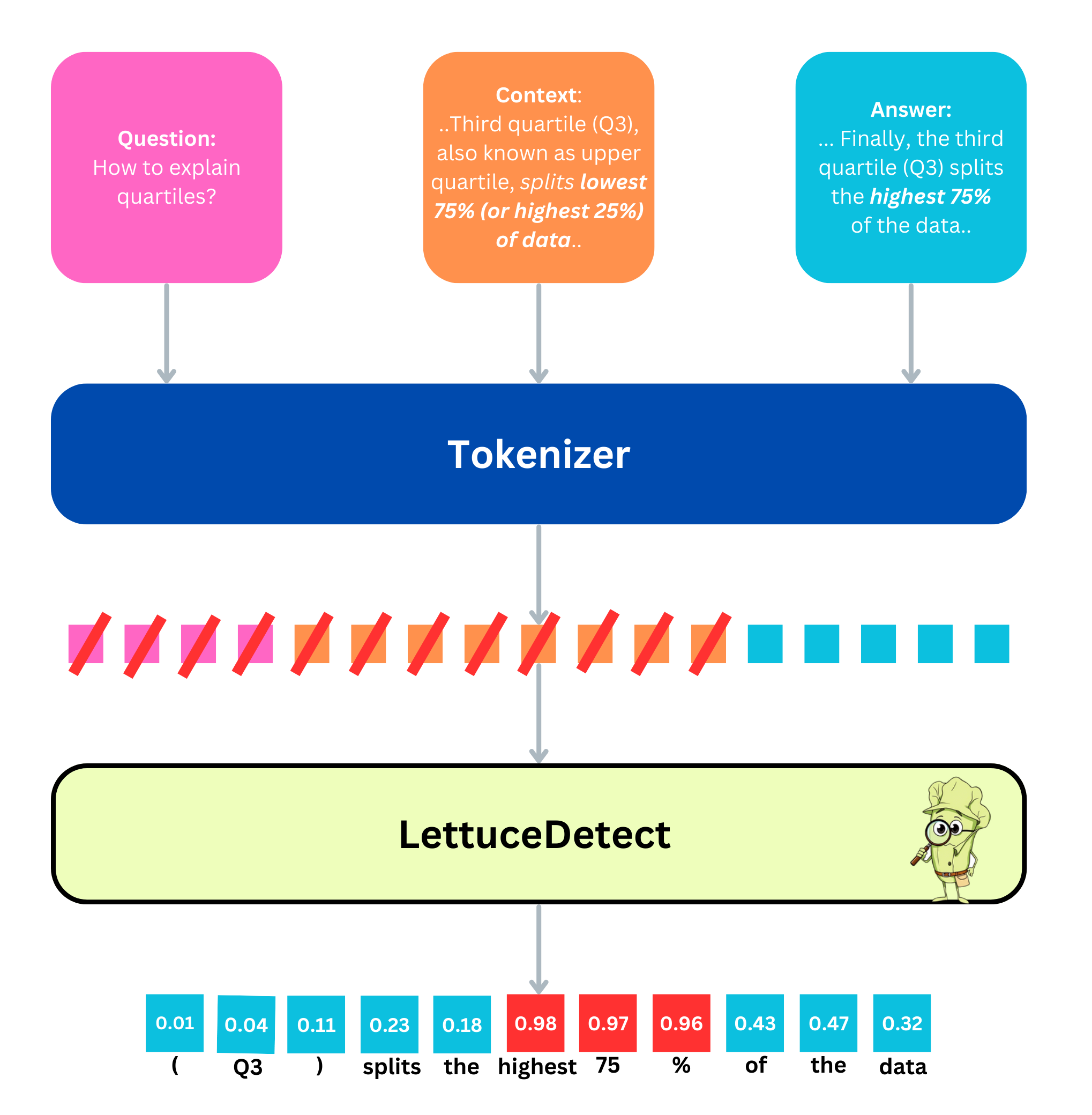
321 KB
assets/carbon.png
0 → 100644
{kind=link}
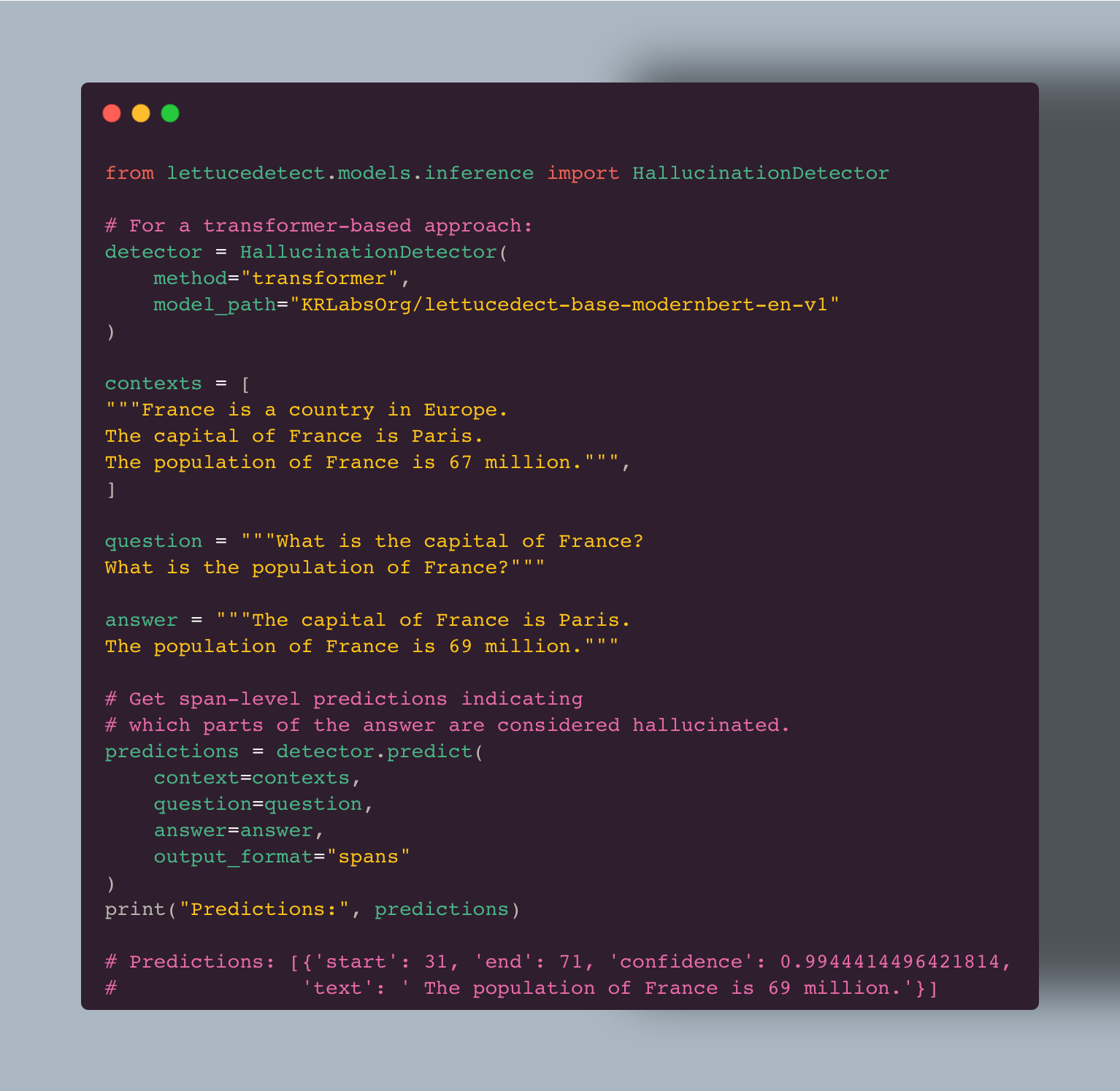
259 KB
{kind=link}
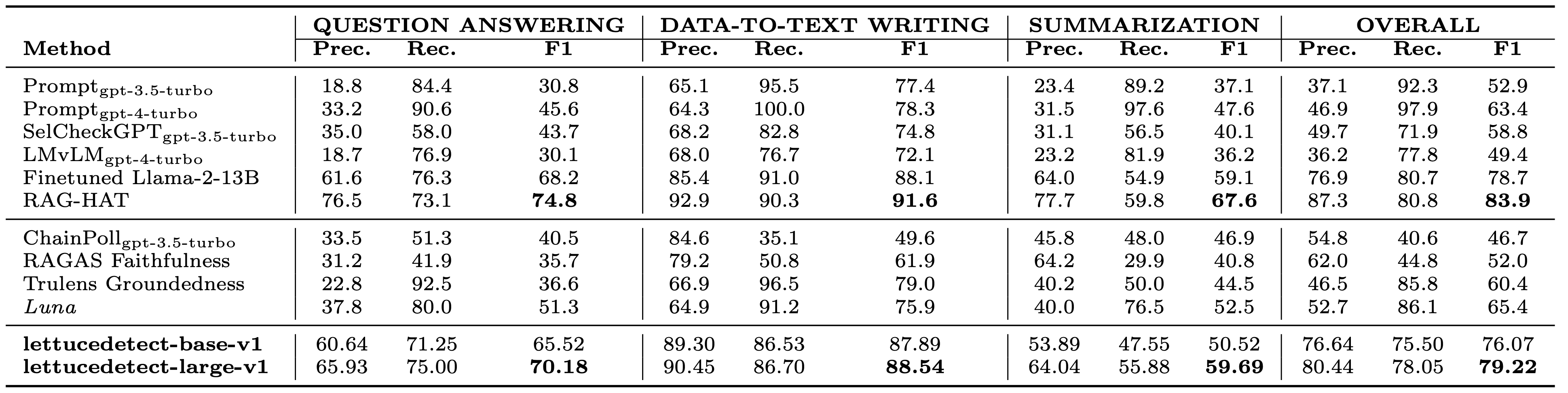
373 KB
assets/lettuce_detective.png
0 → 100644
{kind=link}

345 KB
{kind=link}

305 KB
demo/detection.ipynb
0 → 100644
demo/streamlit_demo.py
0 → 100644
docs/README.md
0 → 100644
icon.png
0 → 100644
{kind=link}
61.5 KB
lettucedetect/__init__.py
0 → 100644