
InstruceBLIP
Showing
Too many changes to show.
To preserve performance only 1000 of 1000+ files are displayed.
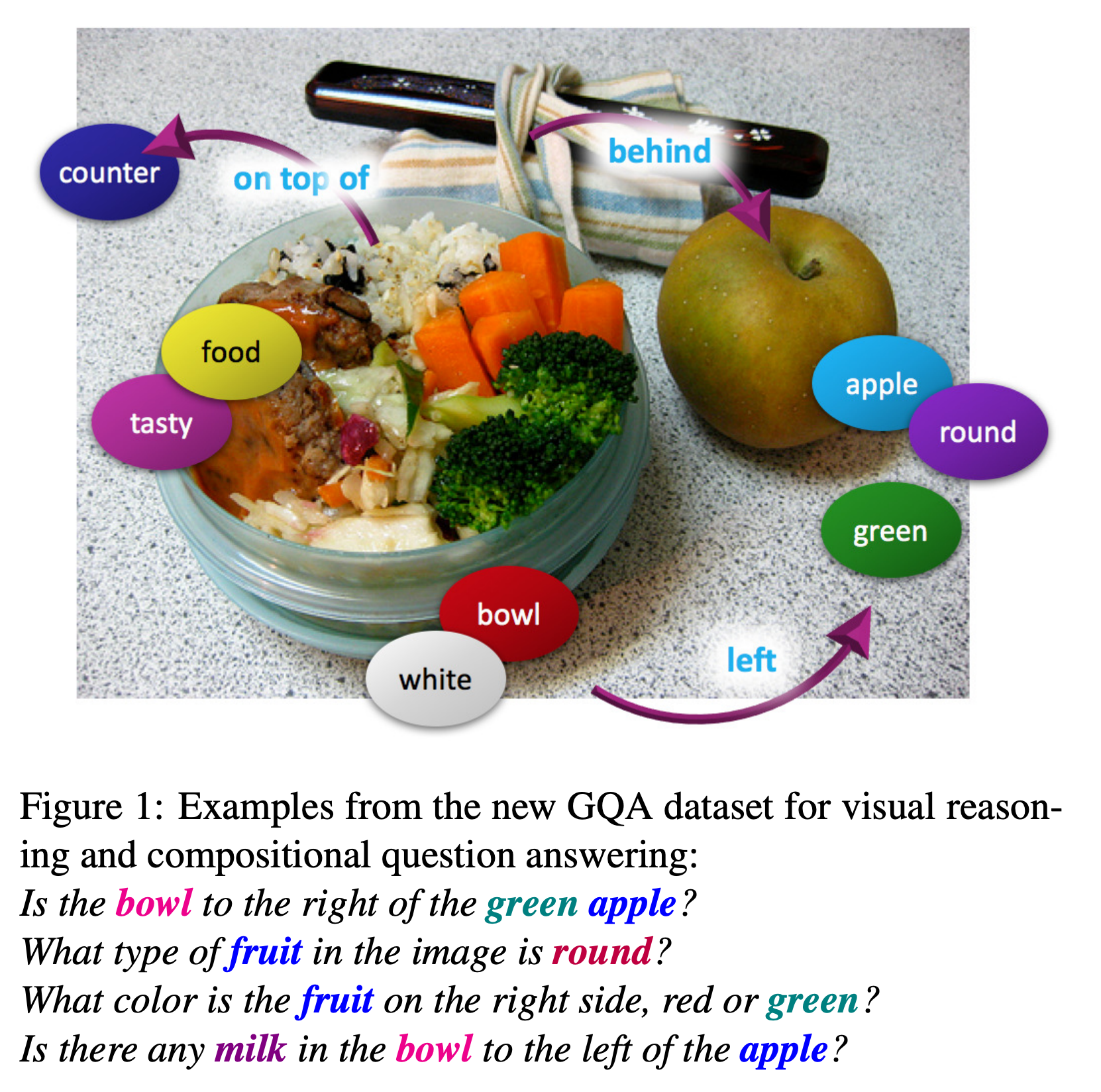
dataset_card/imgs/gqa.png
0 → 100644
{kind=link}
2.98 MB
dataset_card/imgs/msrvtt.png
0 → 100644
{kind=link}

1.06 MB
{kind=link}

327 KB
{kind=link}

379 KB
dataset_card/imgs/nocaps.png
0 → 100644
{kind=link}

1.44 MB
{kind=link}

1.45 MB
{kind=link}

2.22 MB
dataset_card/imgs/vqav2.png
0 → 100644
{kind=link}

2.18 MB
dataset_card/msrvtt_qa.md
0 → 100644
dataset_card/msvd_qa.md
0 → 100644
dataset_card/nlvr2.md
0 → 100644
dataset_card/nocaps.md
0 → 100644
dataset_card/sbu_caption.md
0 → 100644
dataset_card/vqav2.md
0 → 100644
docker/dockerfile
0 → 100644
docs/Makefile
0 → 100644
{kind=link}

45.2 KB
{kind=link}
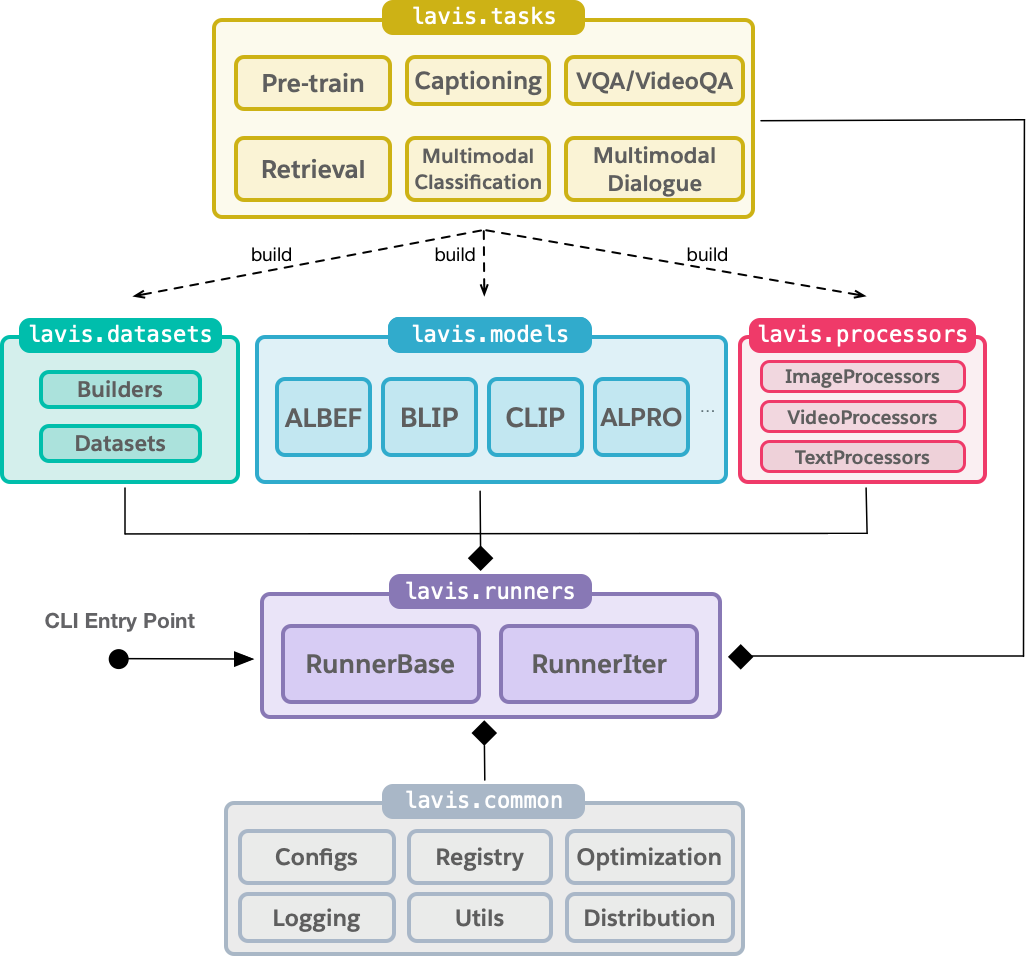
130 KB