
v1.0
parents
Showing
.dockerignore
0 → 100644
.gitignore
0 → 100644
.pre-commit-config.yaml
0 → 100644
.project-root
0 → 100644
.readthedocs.yaml
0 → 100644
API_FLAGS.txt
0 → 100644
LICENSE
0 → 100644
README.md
0 → 100644
README_origin.md
0 → 100644
apt.sh
0 → 100644
doc/algorithm.png
0 → 100644
{kind=link}
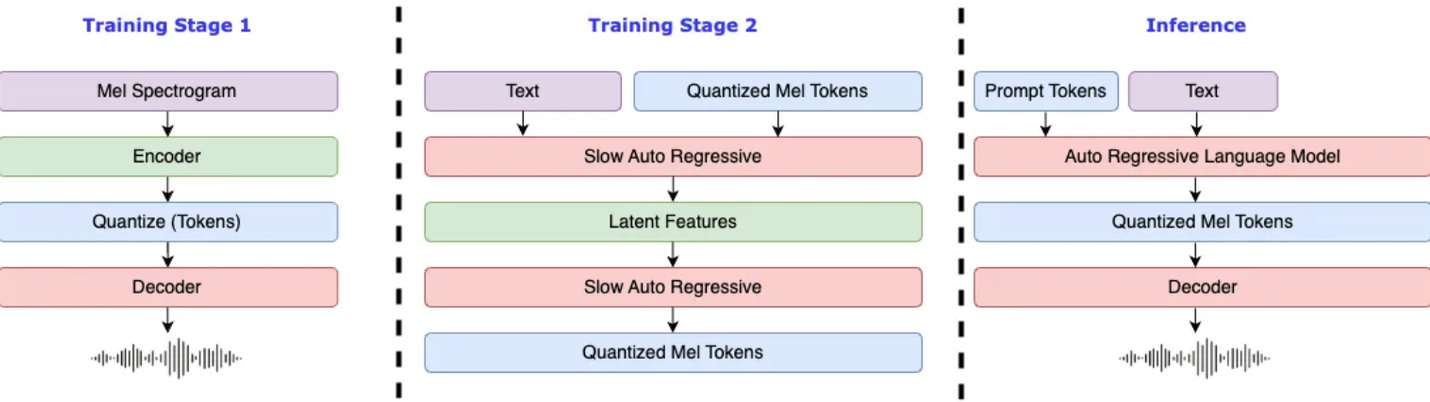
234 KB
doc/structure.png
0 → 100644
{kind=link}
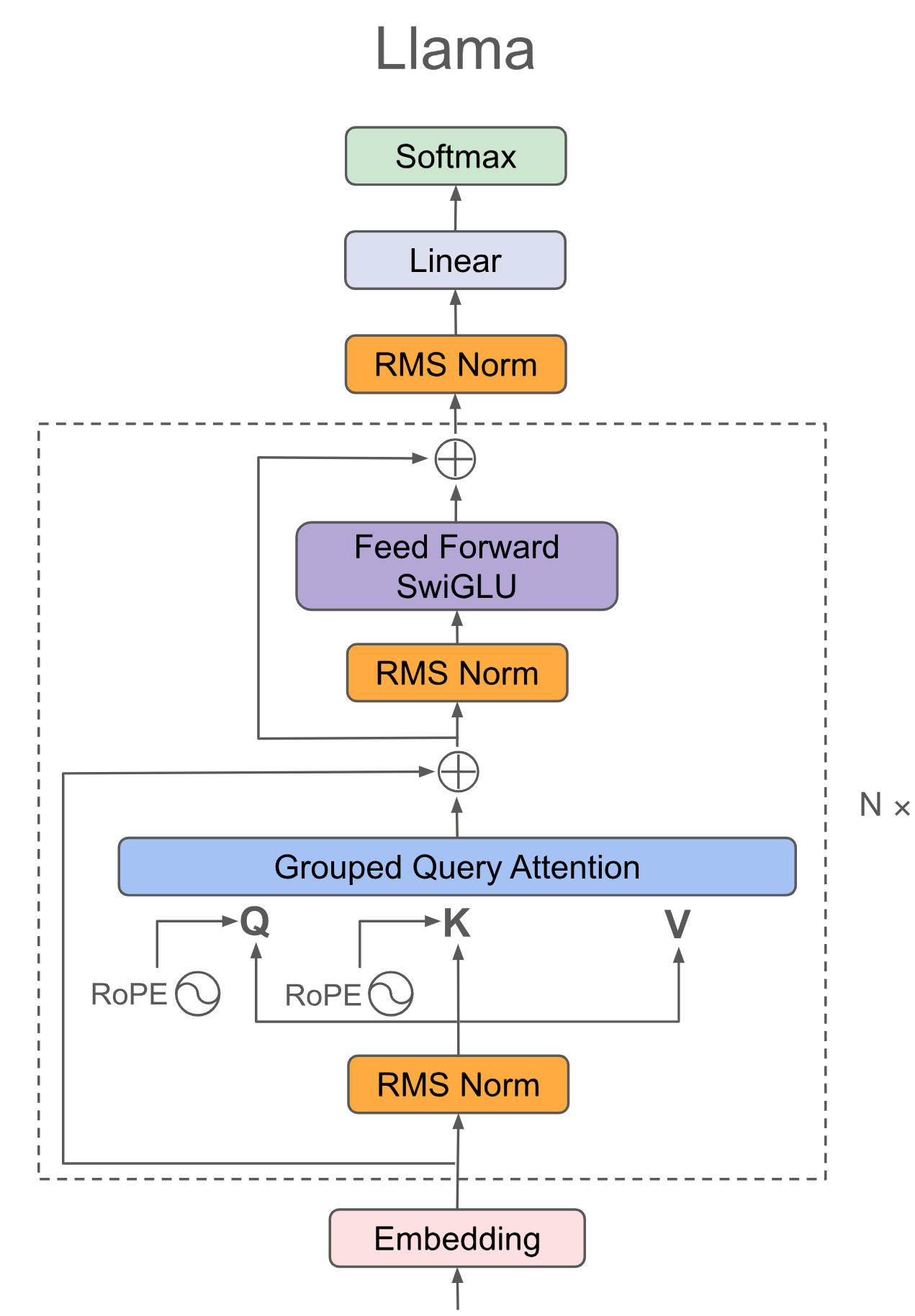
334 KB
docker-compose.dev.yml
0 → 100644
docker/Dockerfile
0 → 100644
docker/requirements.txt
0 → 100644
docker_start.sh
0 → 100644
dockerfile
0 → 100644
dockerfile.dev
0 → 100644
docs/CNAME
0 → 100644
docs/README.ja.md
0 → 100644