
v1.0
parents
Showing
docs/README.ko.md
0 → 100644
docs/README.pt-BR.md
0 → 100644
docs/README.zh.md
0 → 100644
docs/assets/figs/VS_1.jpg
0 → 100644
{kind=link}

27.3 KB
{kind=link}
157 KB
{kind=link}
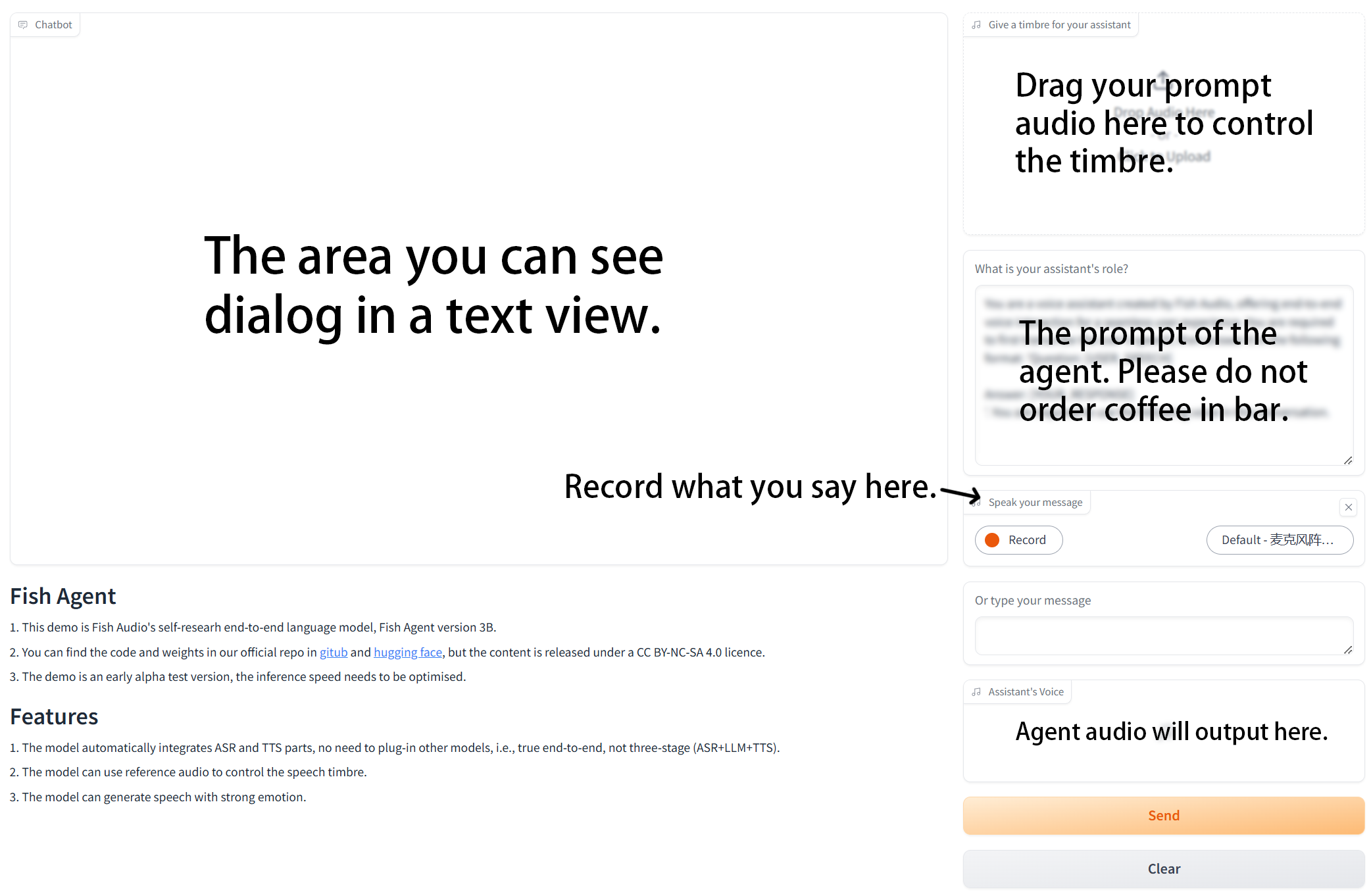
251 KB
docs/assets/figs/diagram.png
0 → 100644
{kind=link}
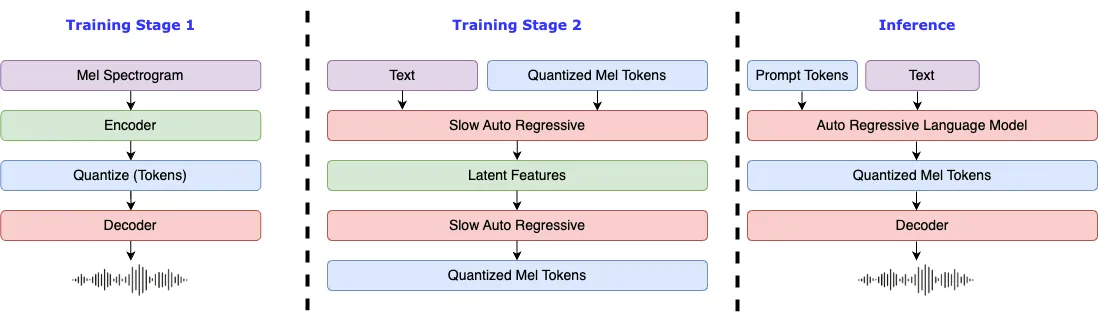
129 KB
{kind=link}
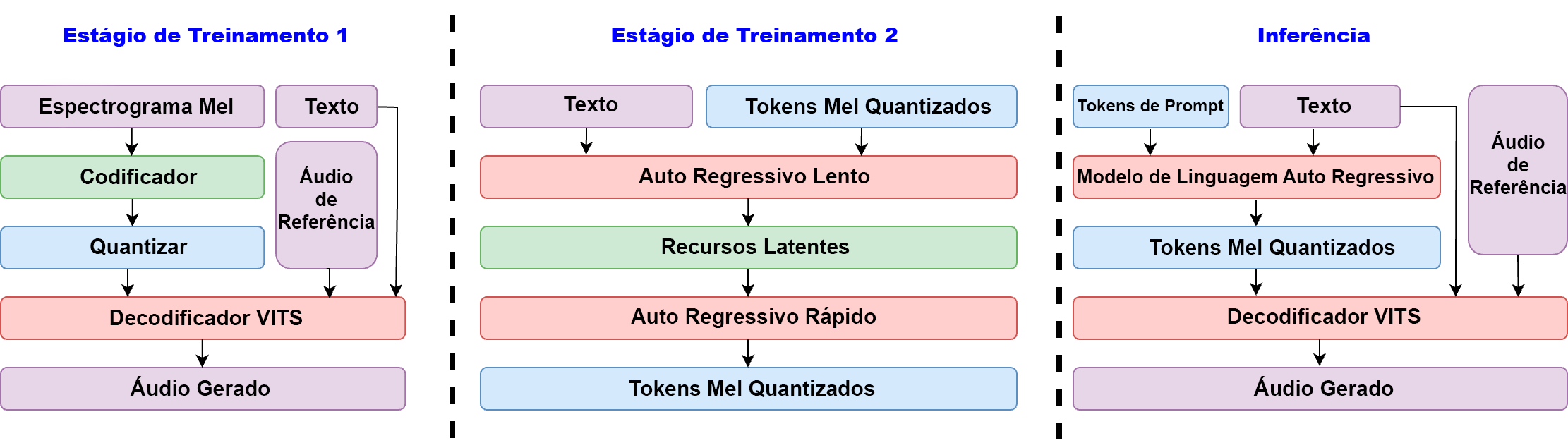
84.5 KB
{kind=link}
13.5 KB
docs/en/finetune.md
0 → 100644
docs/en/index.md
0 → 100644
docs/en/inference.md
0 → 100644
docs/en/samples.md
0 → 100644
docs/en/start_agent.md
0 → 100644
docs/ja/finetune.md
0 → 100644
docs/ja/index.md
0 → 100644
docs/ja/inference.md
0 → 100644
docs/ja/samples.md
0 → 100644
docs/ja/start_agent.md
0 → 100644
docs/ko/finetune.md
0 → 100644