
add icon
parents
Showing
fastsam/model.py
0 → 100644
fastsam/predict.py
0 → 100644
fastsam/prompt.py
0 → 100644
fastsam/utils.py
0 → 100644
icon.png
0 → 100644
{kind=link}
66.7 KB
images/cat.jpg
0 → 100644
{kind=link}

2.41 MB
images/dogs.jpg
0 → 100644
{kind=link}

438 KB
model.properties
0 → 100644
output/cat.jpg
0 → 100644
{kind=link}

30.1 KB
output/dogs.jpg
0 → 100644
{kind=link}

121 KB
predict.py
0 → 100644
requirements.txt
0 → 100644
| # Base----------------------------------- | ||
| matplotlib>=3.2.2 | ||
| opencv-python>=4.6.0 | ||
| Pillow>=7.1.2 | ||
| PyYAML>=5.3.1 | ||
| requests>=2.23.0 | ||
| scipy>=1.4.1 | ||
| torch>=1.7.0 | ||
| torchvision>=0.8.1 | ||
| tqdm>=4.64.0 | ||
| pandas>=1.1.4 | ||
| seaborn>=0.11.0 | ||
| gradio==3.35.2 | ||
| # Ultralytics----------------------------------- | ||
| ultralytics == 8.0.120 | ||
resources/11.png
0 → 100644
{kind=link}
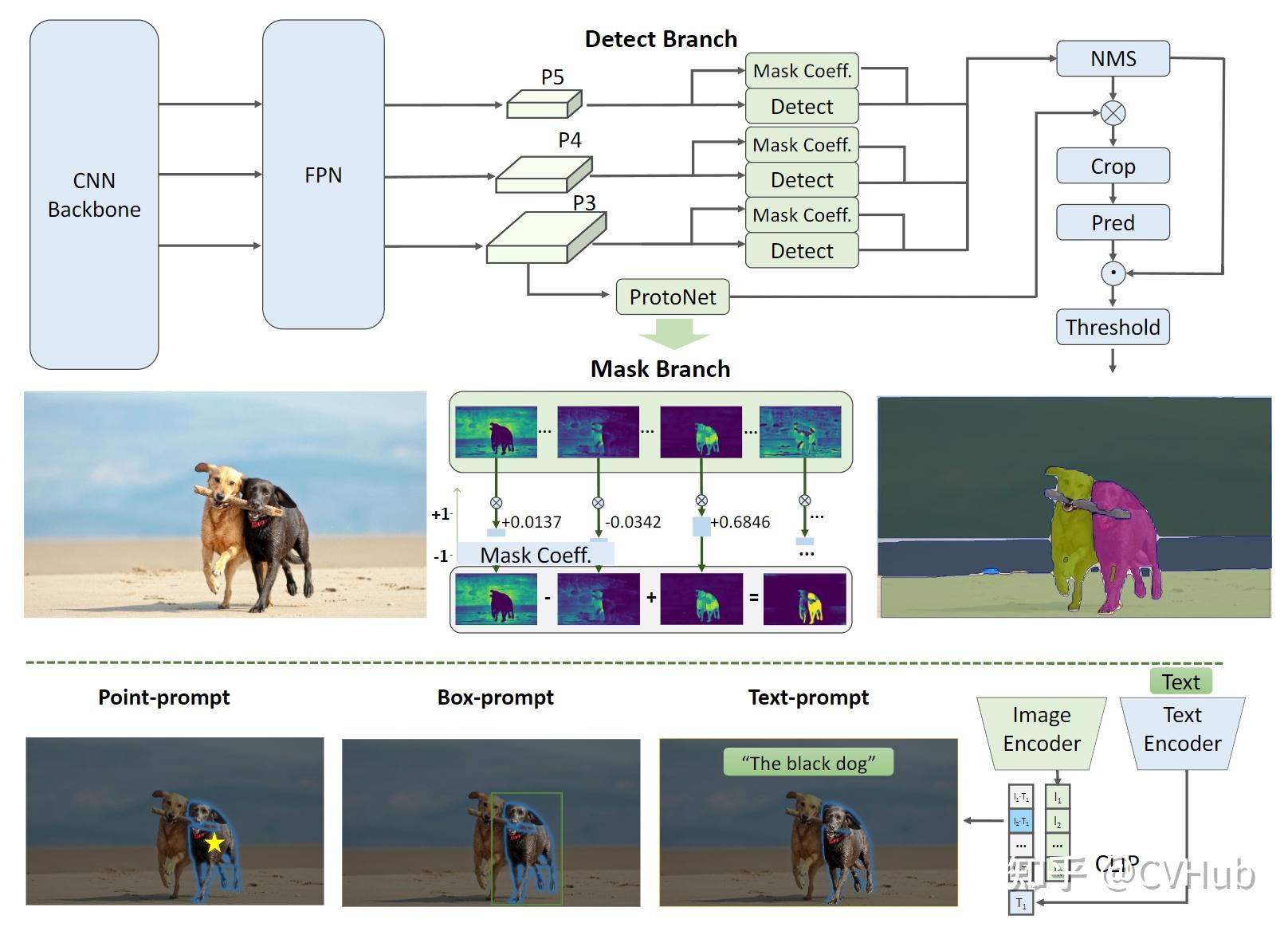
823 KB
resources/model.jpg
0 → 100644
{kind=link}
167 KB
resources/model_s.png
0 → 100644
{kind=link}
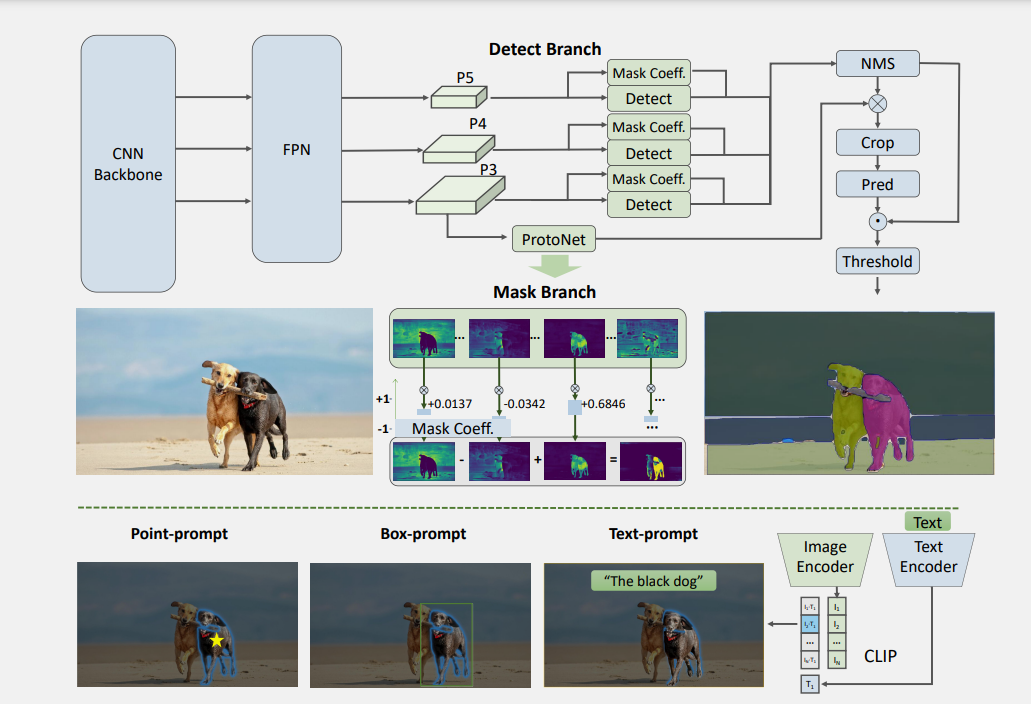
318 KB
segpredict.py
0 → 100644
setup.py
0 → 100644
utils/__init__.py
0 → 100644
utils/tools.py
0 → 100644
utils/tools_gradio.py
0 → 100644