
add icon
parents
Showing
{kind=link}

25.3 KB
{kind=link}

31.2 KB
assets/replicate-1.png
0 → 100644
{kind=link}
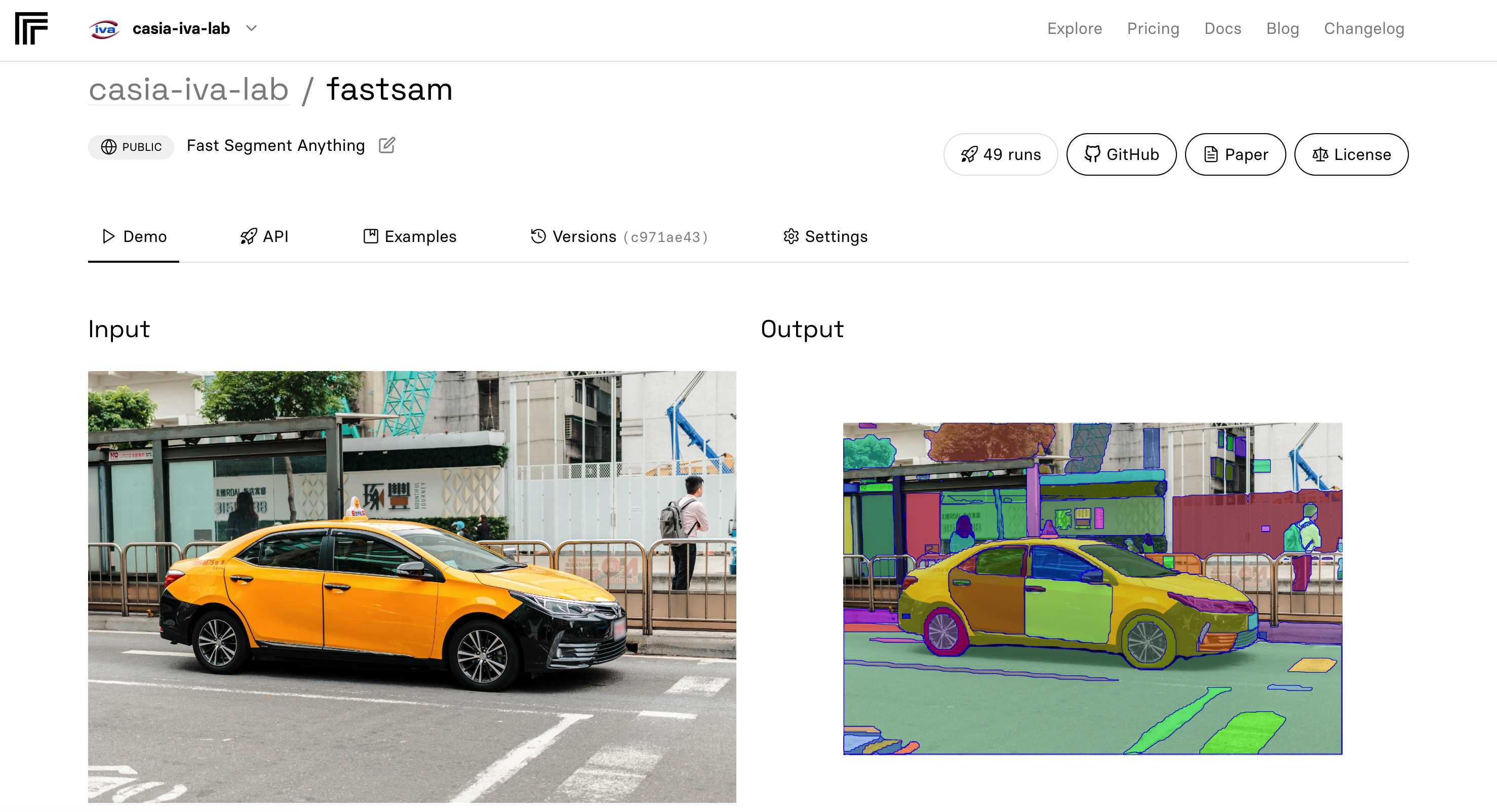
3.29 MB
assets/replicate-2.png
0 → 100644
{kind=link}
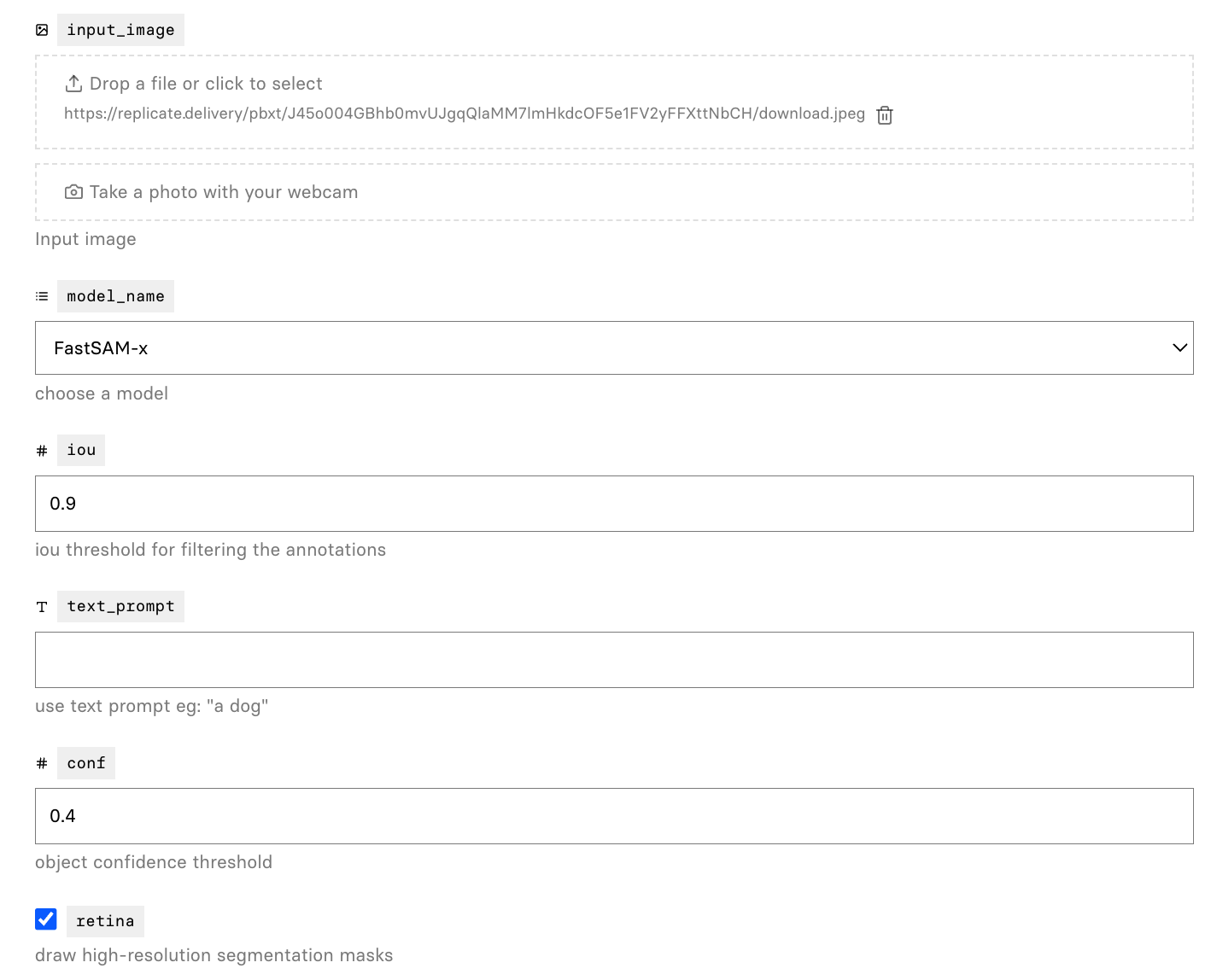
97.5 KB
assets/replicate-3.png
0 → 100644
{kind=link}
597 KB
assets/salient.png
0 → 100644
{kind=link}

1.48 MB
cog.yaml
0 → 100644
docker/Dockerfile
0 → 100644
docker/requirements.txt
0 → 100644
examples/dogs.jpg
0 → 100644
{kind=link}

438 KB
examples/sa_10039.jpg
0 → 100644
{kind=link}

381 KB
examples/sa_11025.jpg
0 → 100644
{kind=link}

965 KB
examples/sa_1309.jpg
0 → 100644
{kind=link}

1.06 MB
examples/sa_192.jpg
0 → 100644
{kind=link}

1.16 MB
examples/sa_414.jpg
0 → 100644
{kind=link}

2.13 MB
examples/sa_561.jpg
0 → 100644
{kind=link}

803 KB
examples/sa_862.jpg
0 → 100644
{kind=link}

1.48 MB
examples/sa_8776.jpg
0 → 100644
{kind=link}

460 KB
fastsam/__init__.py
0 → 100644
fastsam/decoder.py
0 → 100644