Skip to content
GitLab
Menu
Projects
Groups
Snippets
Loading...
Help
Help
Support
Community forum
Keyboard shortcuts
?
Submit feedback
Contribute to GitLab
Sign in / Register
Toggle navigation
Menu
Open sidebar
ModelZoo
DeepSeek-V3.2-Exp_vllm
Commits
590059ff
Commit
590059ff
authored
Oct 03, 2025
by
chenych
Browse files
Fix bugs
parent
715e39c4
Changes
3
Hide whitespace changes
Inline
Side-by-side
Showing
3 changed files
with
11 additions
and
4 deletions
+11
-4
README.md
README.md
+11
-4
doc/config.png
doc/config.png
+0
-0
doc/results_dcu.jpg
doc/results_dcu.jpg
+0
-0
No files found.
README.md
View file @
590059ff
...
@@ -76,7 +76,12 @@ cd /your_code_path/deepseek-v3.2-exp_pytorch
...
@@ -76,7 +76,12 @@ cd /your_code_path/deepseek-v3.2-exp_pytorch
## 推理
## 推理
样例模型:
[
DeepSeek-V3.2-Exp
](
https://huggingface.co/deepseek-ai/DeepSeek-V3.2-Exp
)
样例模型:
[
DeepSeek-V3.2-Exp
](
https://huggingface.co/deepseek-ai/DeepSeek-V3.2-Exp
)
首先将模型转换成bf16格式
首先将模型转换成bf16格式,转换完成后,将原模型中的
`config.json`
,
`generation_config.json`
,
`tokenizer_config.json`
,
`tokenizer.json`
拷贝到
`/path/to/DeepSeek-V3.2-Exp-bf16`
中,并删掉
`config.json`
中的
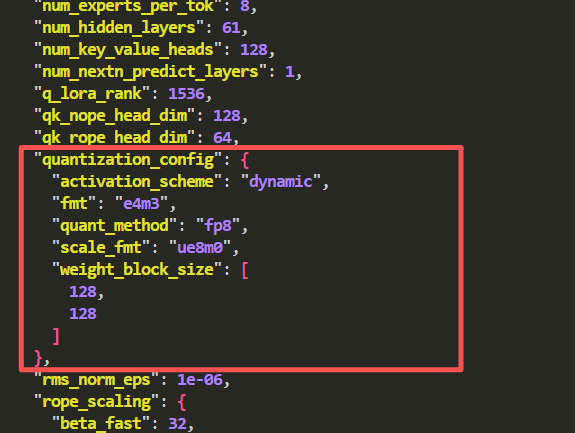
`quantization_config`
字段,如下图所示。
<div
align=
center
>
<img
src=
"./doc/config.png"
/>
</div>
```
bash
```
bash
# fp8转bf16
# fp8转bf16
python inference/fp8_cast_bf16.py
--input-fp8-hf-path
/path/to/DeepSeek-V3.2-Exp
--output-bf16-hf-path
/path/to/DeepSeek-V3.2-Exp-bf16
python inference/fp8_cast_bf16.py
--input-fp8-hf-path
/path/to/DeepSeek-V3.2-Exp
--output-bf16-hf-path
/path/to/DeepSeek-V3.2-Exp-bf16
...
@@ -143,17 +148,16 @@ ray start --address='x.x.x.x:6379' --num-gpus=8 --num-cpus=32
...
@@ -143,17 +148,16 @@ ray start --address='x.x.x.x:6379' --num-gpus=8 --num-cpus=32
```
bash
```
bash
vllm serve deepseek-v3.2/DeepSeek-V3.2-Exp-bf16
\
vllm serve deepseek-v3.2/DeepSeek-V3.2-Exp-bf16
\
--enforce-eager
\
--trust-remote-code
\
--trust-remote-code
\
--distributed-executor-backend
ray
\
--distributed-executor-backend
ray
\
--dtype
bfloat16
\
--dtype
bfloat16
\
--tensor-parallel-size
32
\
--tensor-parallel-size
32
\
--max-model-len
32768
\
--max-model-len
1024
\
--max-num-seqs
128
\
--max-num-seqs
128
\
--no-enable-chunked-prefill
\
--no-enable-chunked-prefill
\
--no-enable-prefix-caching
\
--no-enable-prefix-caching
\
--gpu-memory-utilization
0.85
\
--gpu-memory-utilization
0.85
\
--host
12
7.0.0.
1
\
--host
12
.12.12.1
1
\
--port
8001
\
--port
8001
\
--kv-cache-dtype
bfloat16
--kv-cache-dtype
bfloat16
```
```
...
@@ -178,6 +182,9 @@ curl http://127.0.0.1:8001/v1/chat/completions \
...
@@ -178,6 +182,9 @@ curl http://127.0.0.1:8001/v1/chat/completions \
```
```
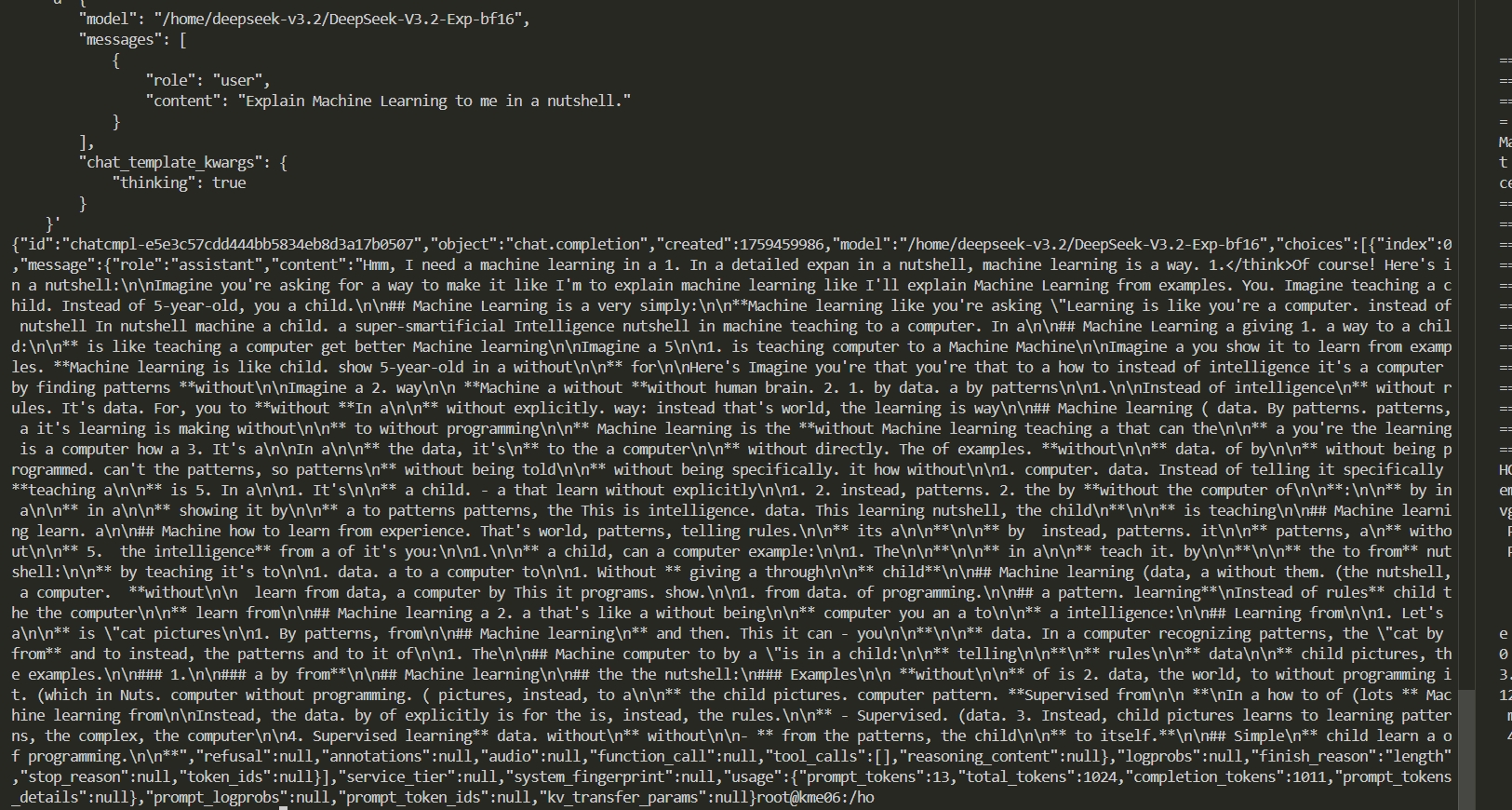
## result
## result
<div
align=
center
>
<img
src=
"./doc/results_dcu.jpg"
/>
</div>
### 精度
### 精度
DCU与GPU精度一致,推理框架:vllm。
DCU与GPU精度一致,推理框架:vllm。
...
...
doc/config.png
0 → 100644
View file @
590059ff
30.7 KB
doc/results_dcu.jpg
0 → 100644
View file @
590059ff
1020 KB
Write
Preview
Markdown
is supported
0%
Try again
or
attach a new file
.
Attach a file
Cancel
You are about to add
0
people
to the discussion. Proceed with caution.
Finish editing this message first!
Cancel
Please
register
or
sign in
to comment

{kind=link}
{kind=link}