
add new model
parents
Showing
CODE_OF_CONDUCT.md
0 → 100644
CONTRIBUTING.md
0 → 100644
CPPLINT.cfg
0 → 100644
LICENSE
0 → 100644
README.md
0 → 100644
README_CN.md
0 → 100644
ROADMAP.md
0 → 100644
docs/.gitignore
0 → 100644
docs/Makefile
0 → 100644
docs/UIO.md
0 → 100644
docs/conf.py
0 → 100644
docs/context.md
0 → 100644
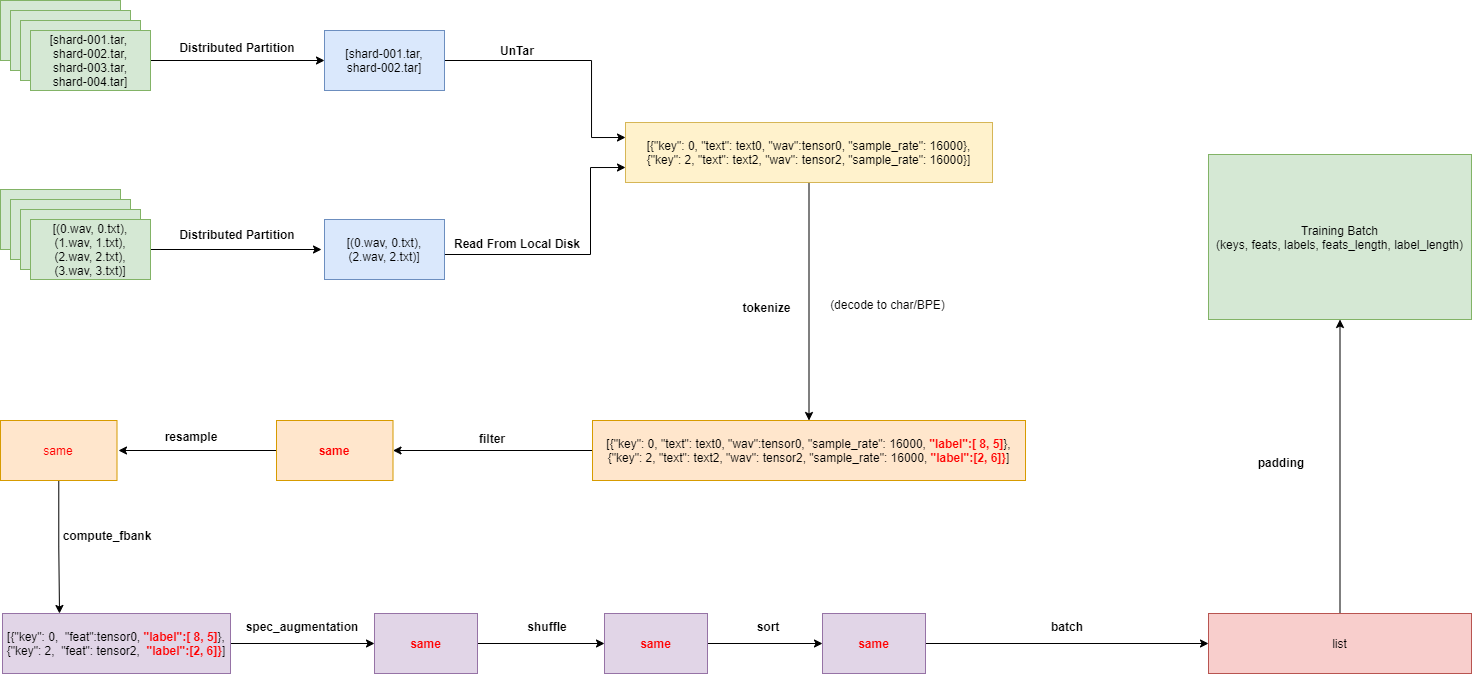
docs/images/UIO_dataflow.png
0 → 100644
{kind=link}
72.8 KB
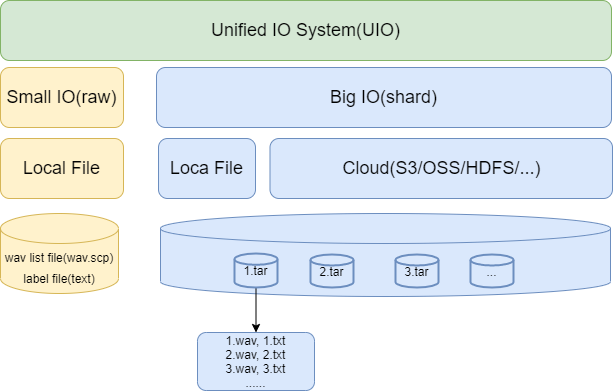
docs/images/UIO_system.png
0 → 100644
{kind=link}
40.2 KB
{kind=link}
55.5 KB
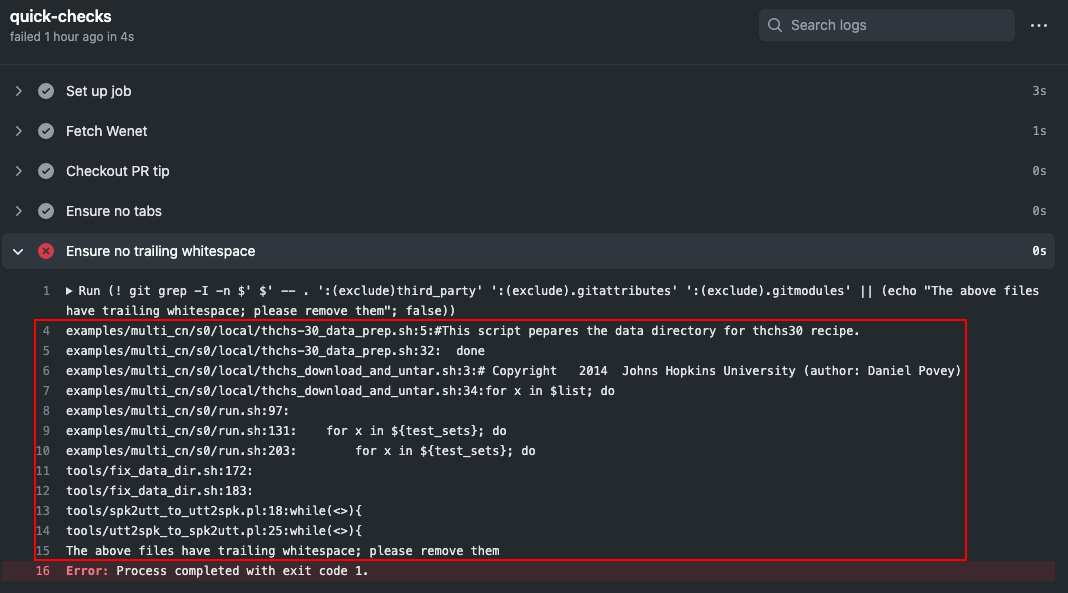
docs/images/check_detail.png
0 → 100644
{kind=link}
116 KB
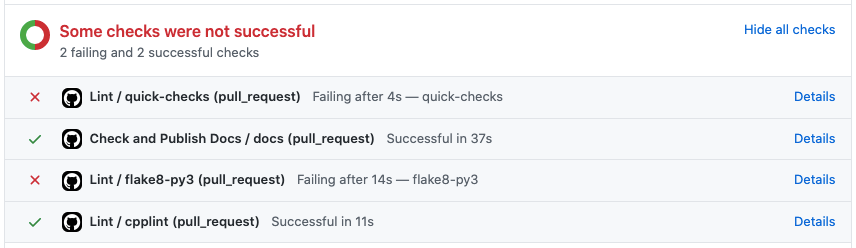
docs/images/checks.png
0 → 100644
{kind=link}
45.5 KB
{kind=link}
85.3 KB
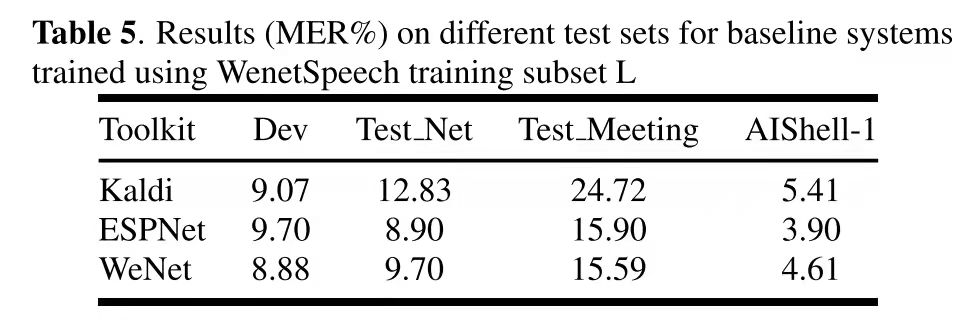
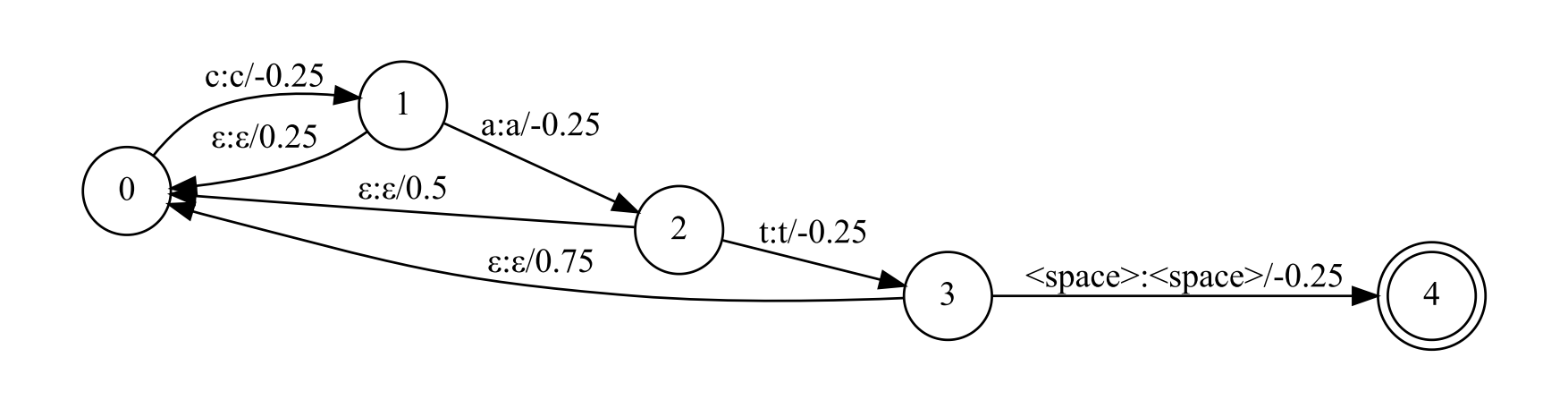
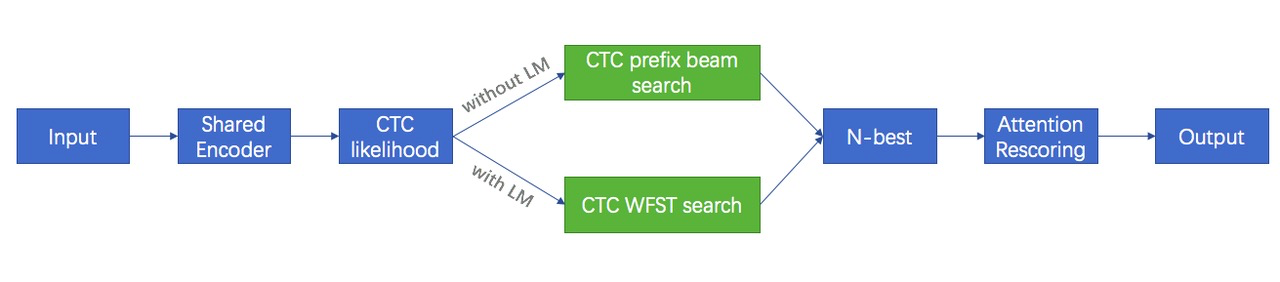
docs/images/lm_system.png
0 → 100644
{kind=link}
139 KB
{kind=link}
196 KB