
add new model
parents
Showing
{kind=link}
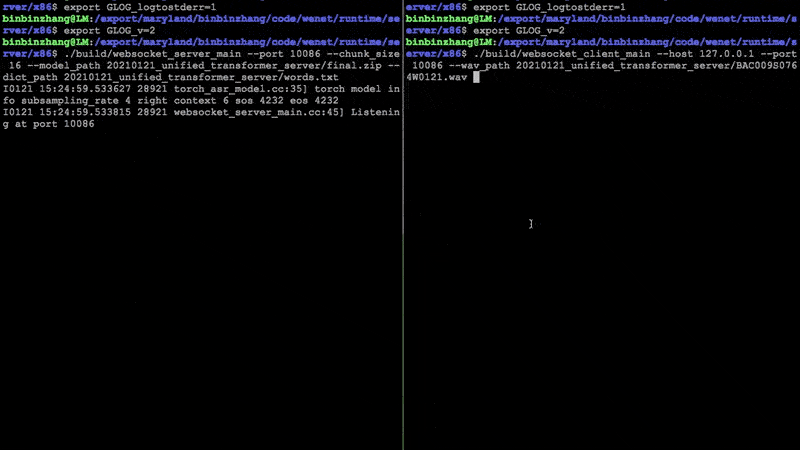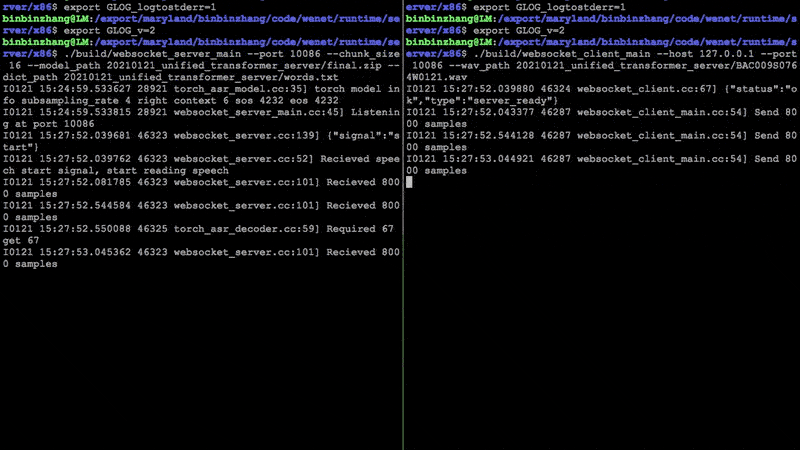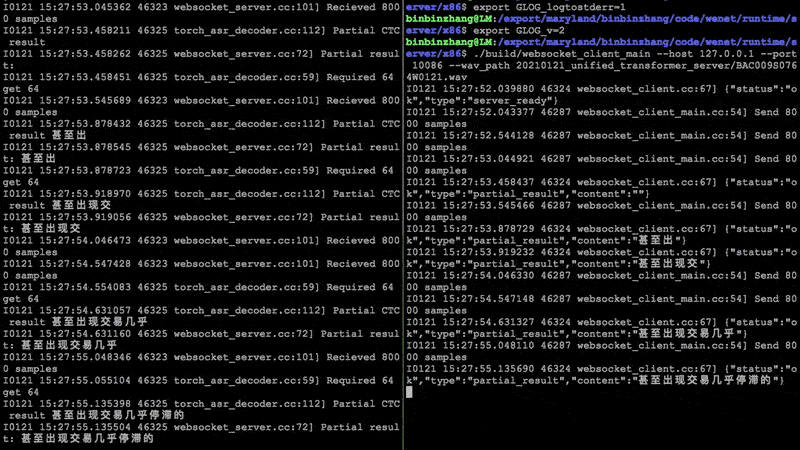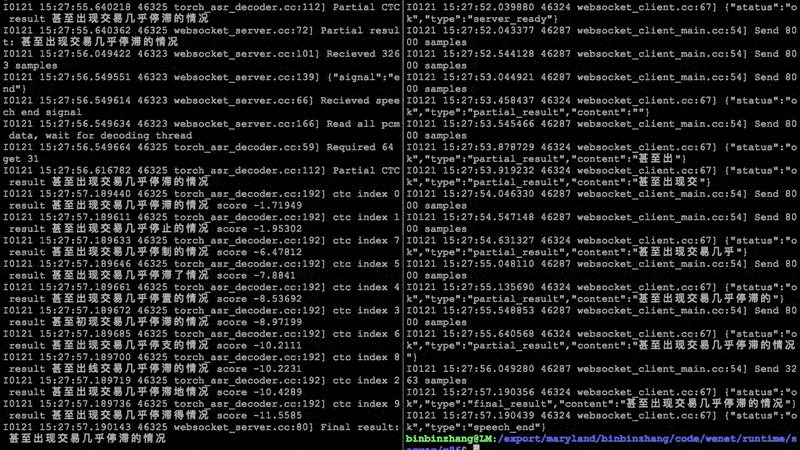
1.49 MB
docs/images/runtime_web.png
0 → 100644
{kind=link}
377 KB
{kind=link}
48 KB
docs/images/u2.gif
0 → 100644
{kind=link}
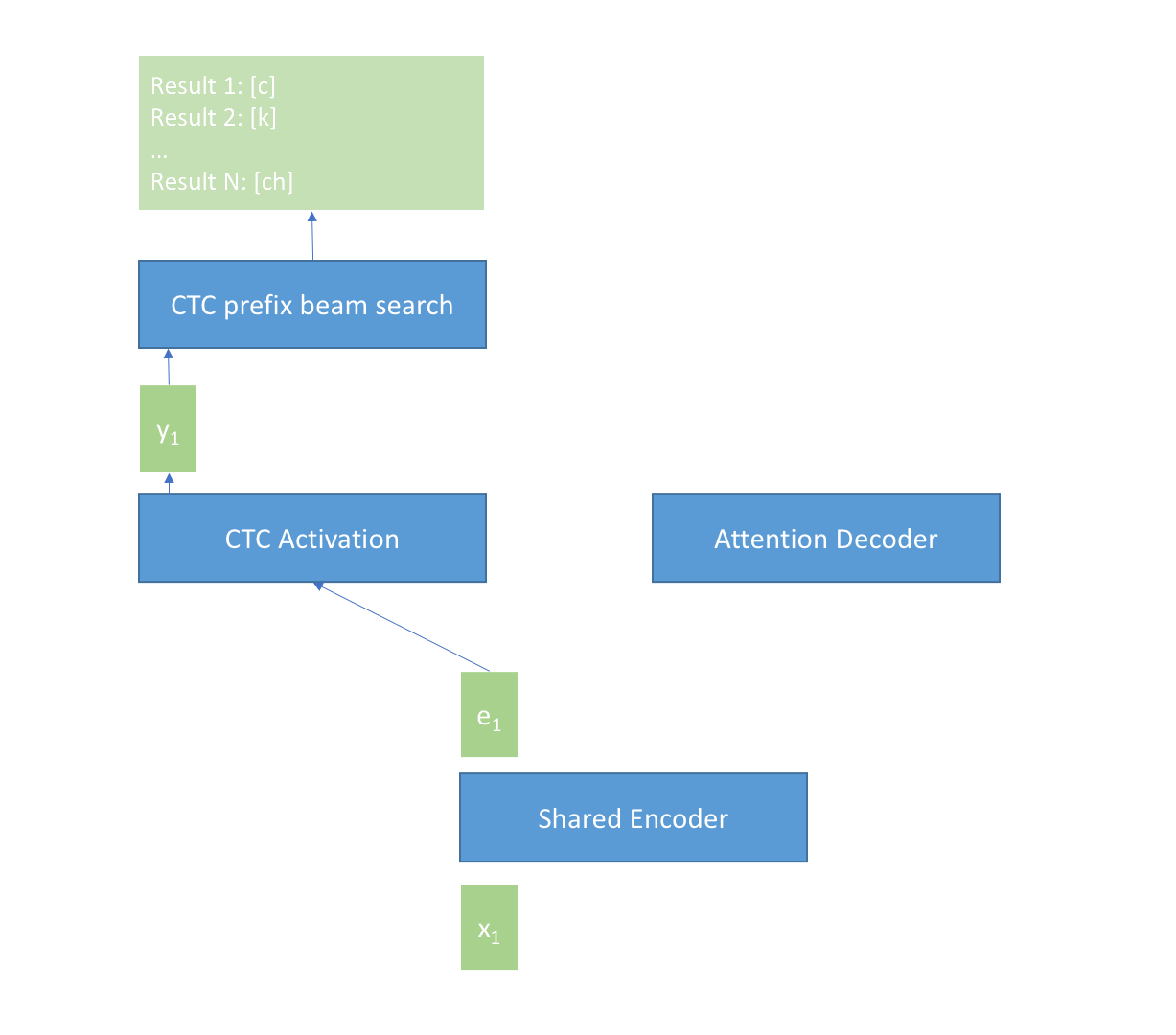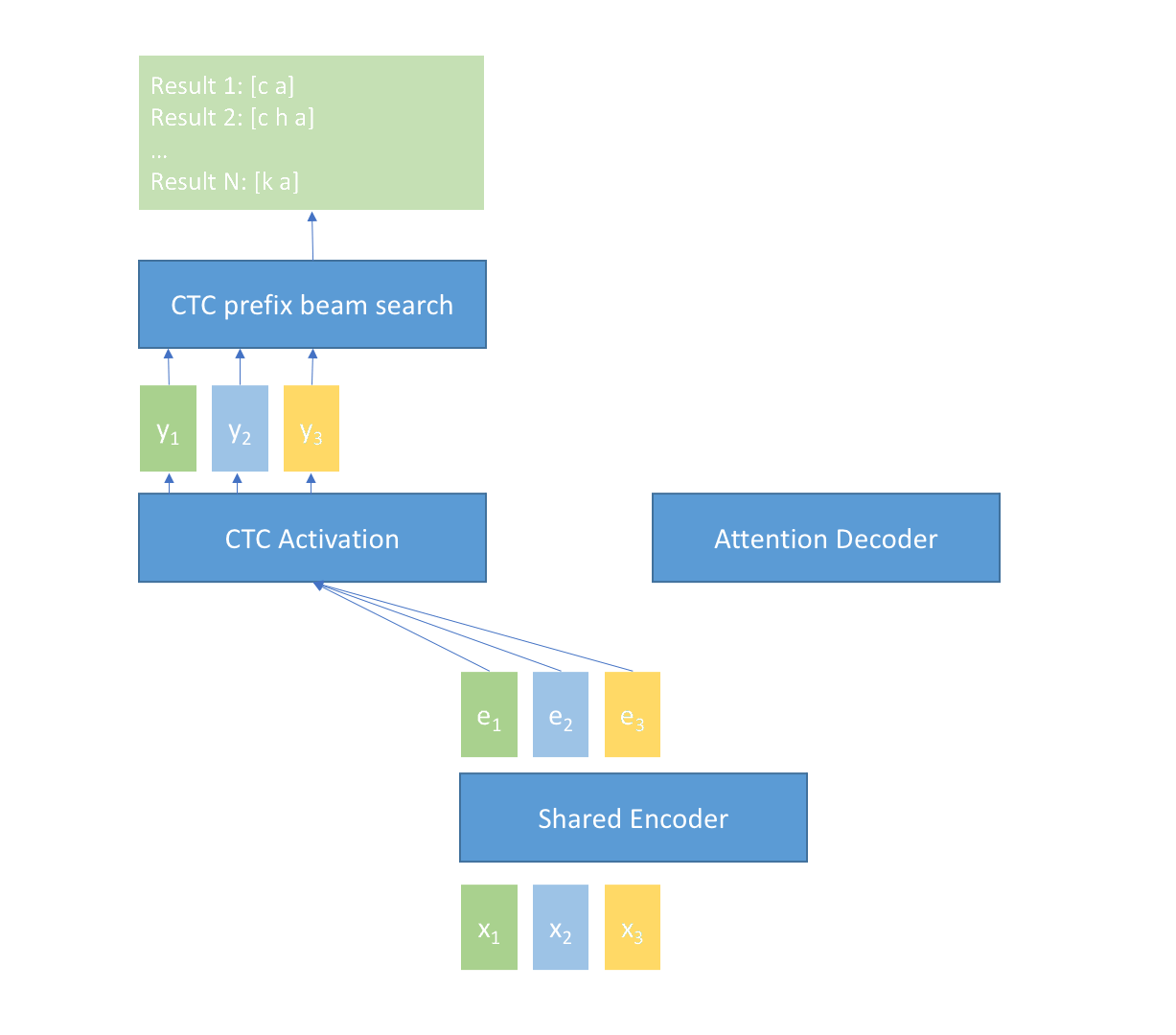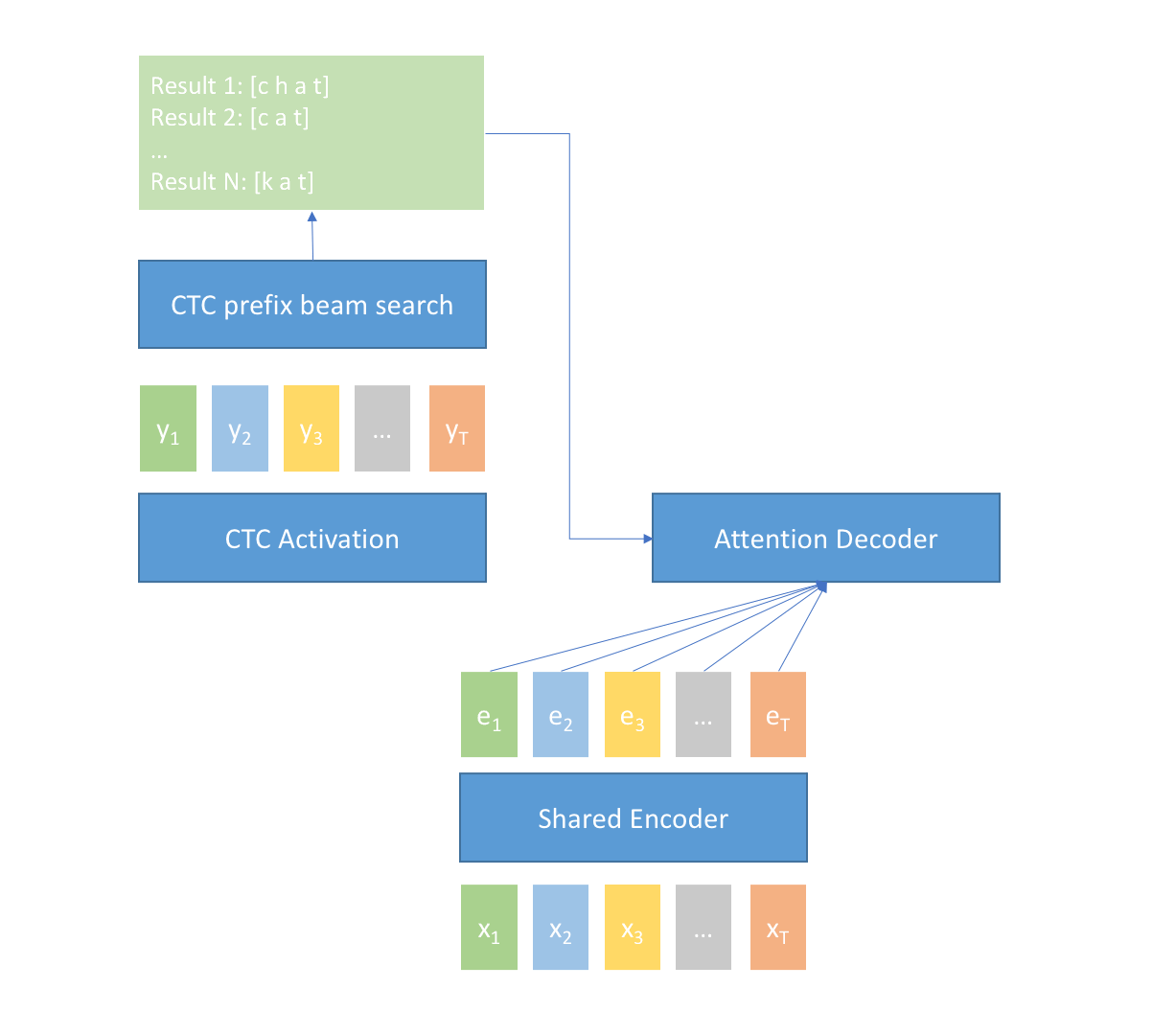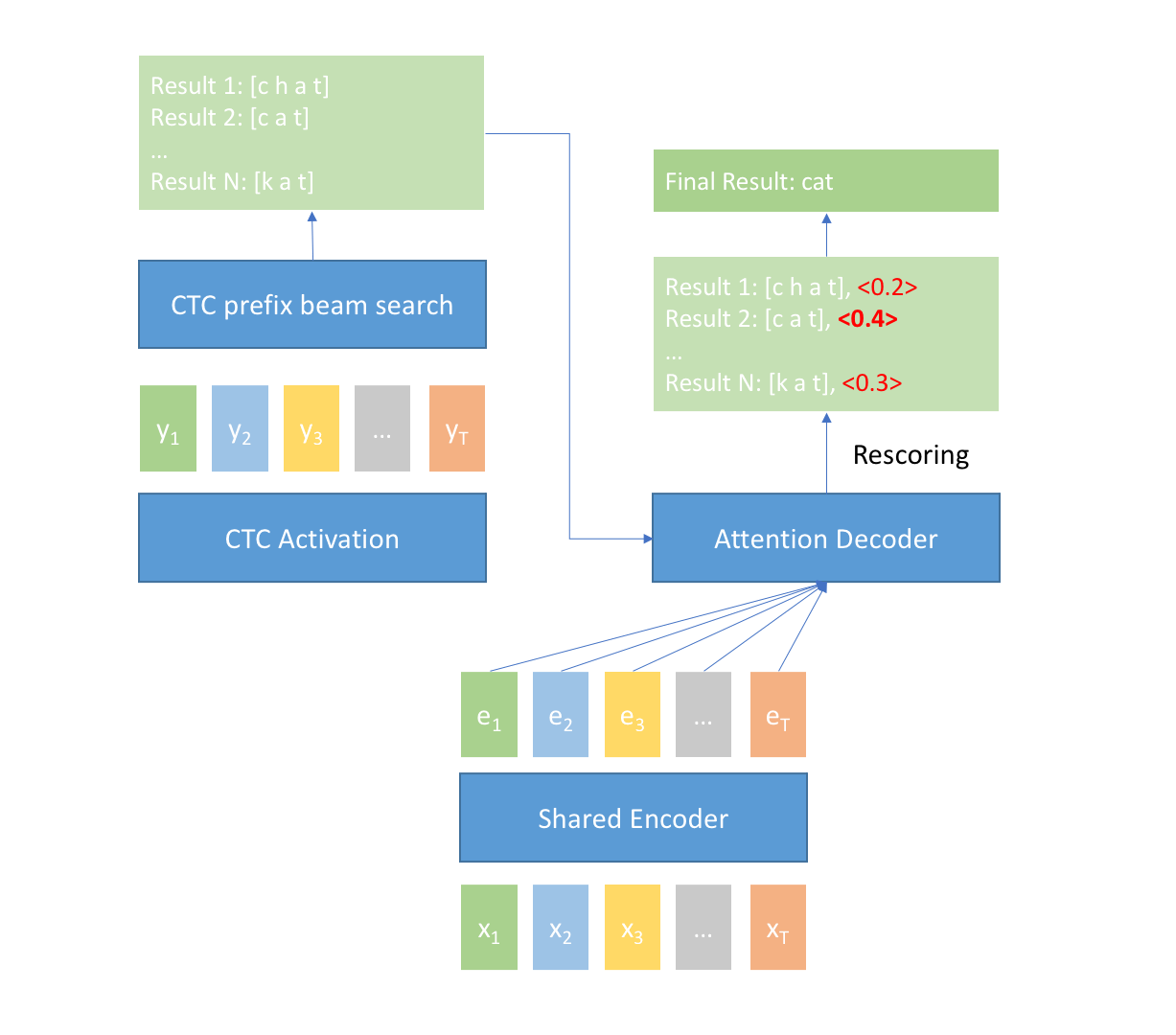
225 KB
docs/index.rst
0 → 100644
docs/jit_in_wenet.md
0 → 100644
docs/lm.md
0 → 100644
docs/make.bat
0 → 100644
docs/papers.md
0 → 100644
docs/pretrained_models.en.md
0 → 100644
docs/pretrained_models.md
0 → 100644
docs/python_binding.md
0 → 120000
docs/runtime.md
0 → 100644
docs/tutorial_aishell.md
0 → 100644
docs/tutorial_librispeech.md
0 → 100644
{kind=link}

64.1 KB