
提交codellama
parents
Showing
README.md
0 → 100644
docs/llama.png
0 → 100644
{kind=link}
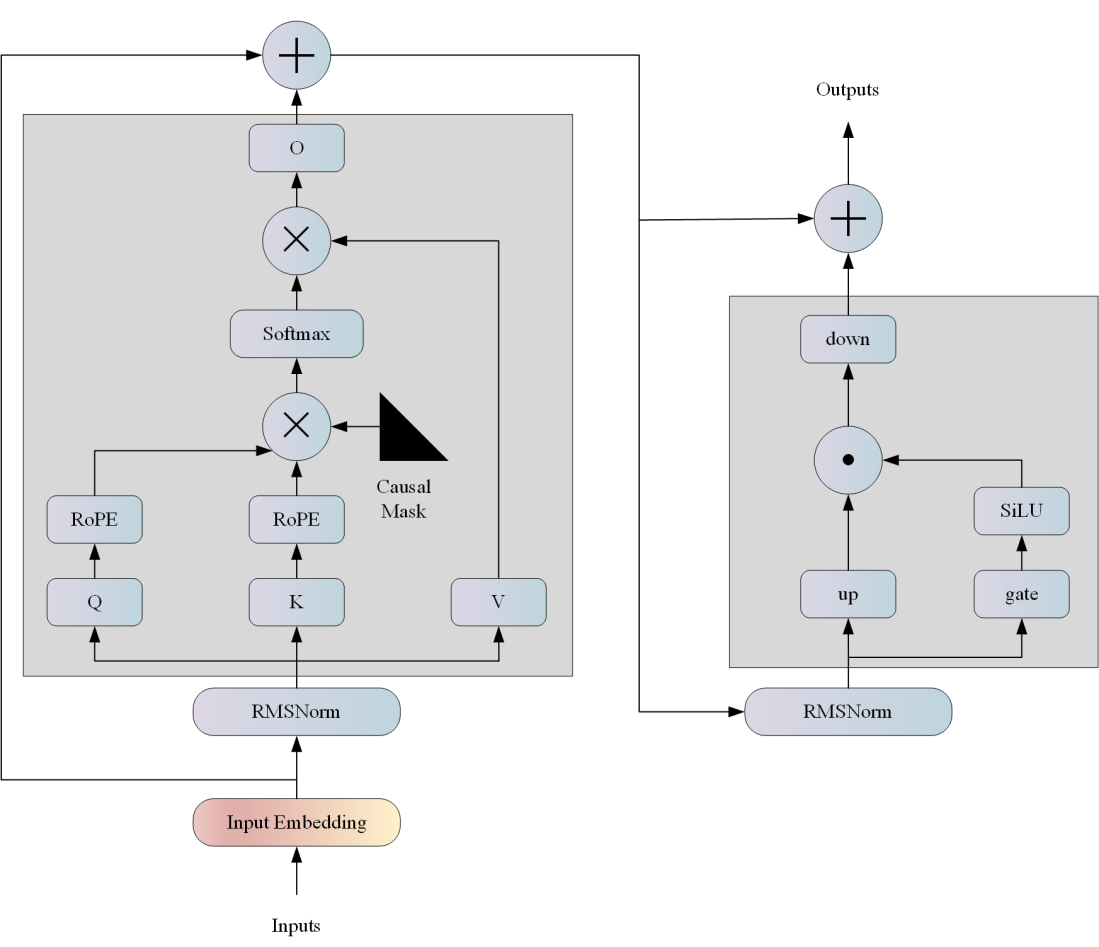
77.3 KB
docs/llama_1.png
0 → 100644
{kind=link}
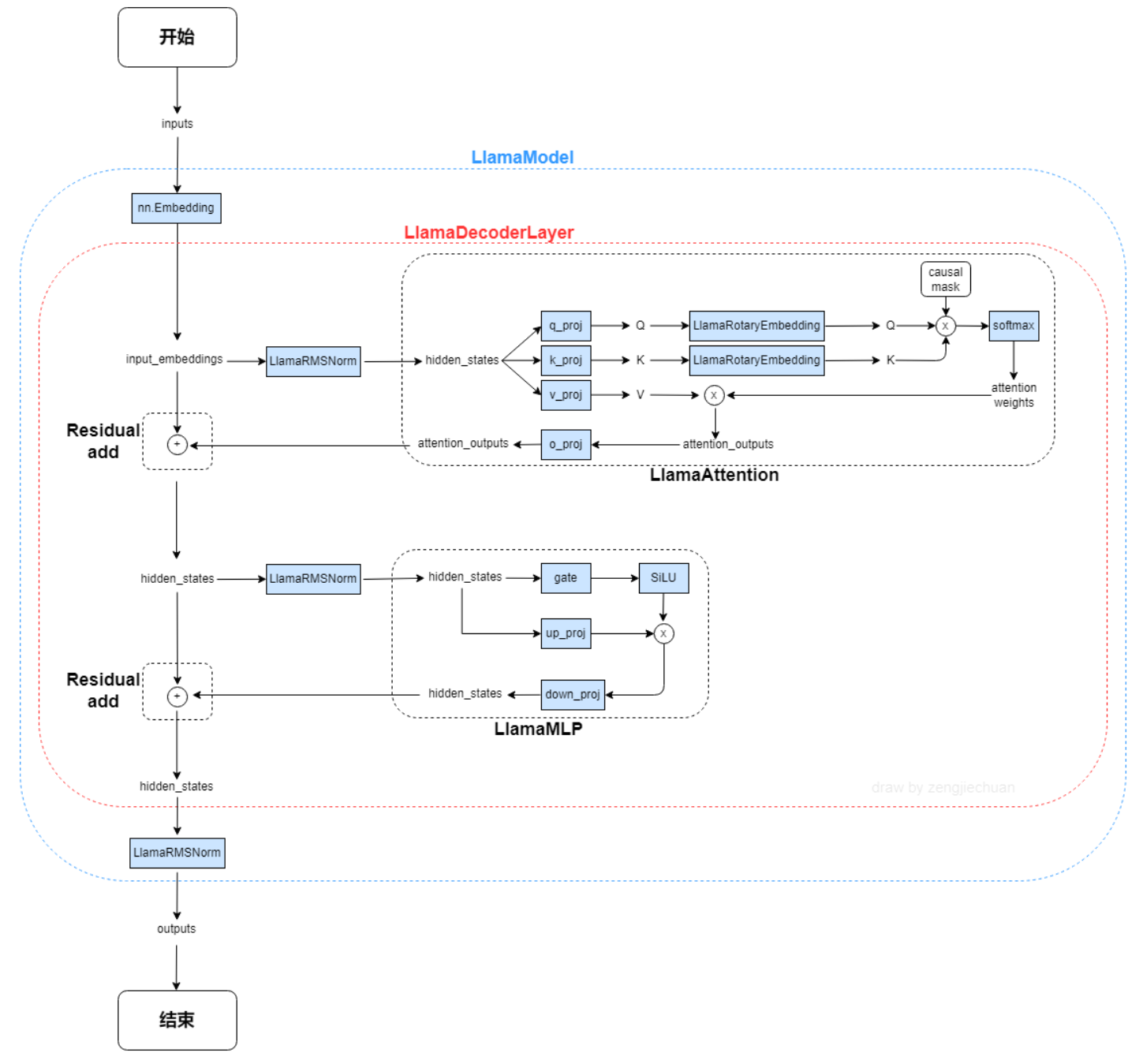
188 KB
model.properties
0 → 100644
77.3 KB
188 KB