
inference
Showing
.github/workflows/test.yml
0 → 100644
.gitignore
0 → 100644
CLIP.png
0 → 100644
{kind=link}
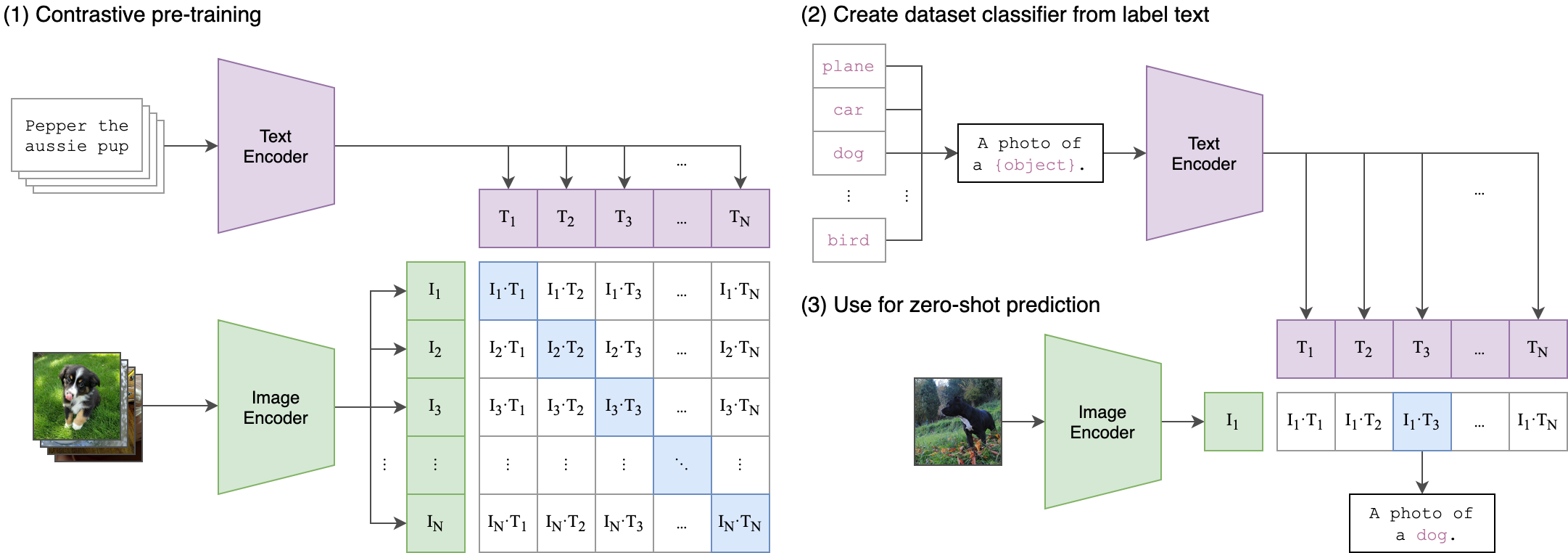
247 KB
LICENSE
0 → 100644
MANIFEST.in
0 → 100644
README.md
0 → 100644
README_official.md
0 → 100644
clip/__init__.py
0 → 100644
File added
clip/clip.py
0 → 100644
clip/model.py
0 → 100644
clip/simple_tokenizer.py
0 → 100644
data/country211.md
0 → 100644
data/prompts.md
0 → 100644
This diff is collapsed.
data/rendered-sst2.md
0 → 100644
data/yfcc100m.md
0 → 100644
hubconf.py
0 → 100644
model-card.md
0 → 100644
model.properties
0 → 100644
This diff is collapsed.