
v1.0
Showing
.gitmodules
0 → 100644
LICENSE
0 → 100644
README.md
0 → 100644
README_origin.md
0 → 100644
File added
File added
File added
asset/logo.png
0 → 100644
{kind=link}
2.3 MB
asset/piano.mp3
0 → 100644
File added
asset/qa_speed.gif
0 → 100644
{kind=link}
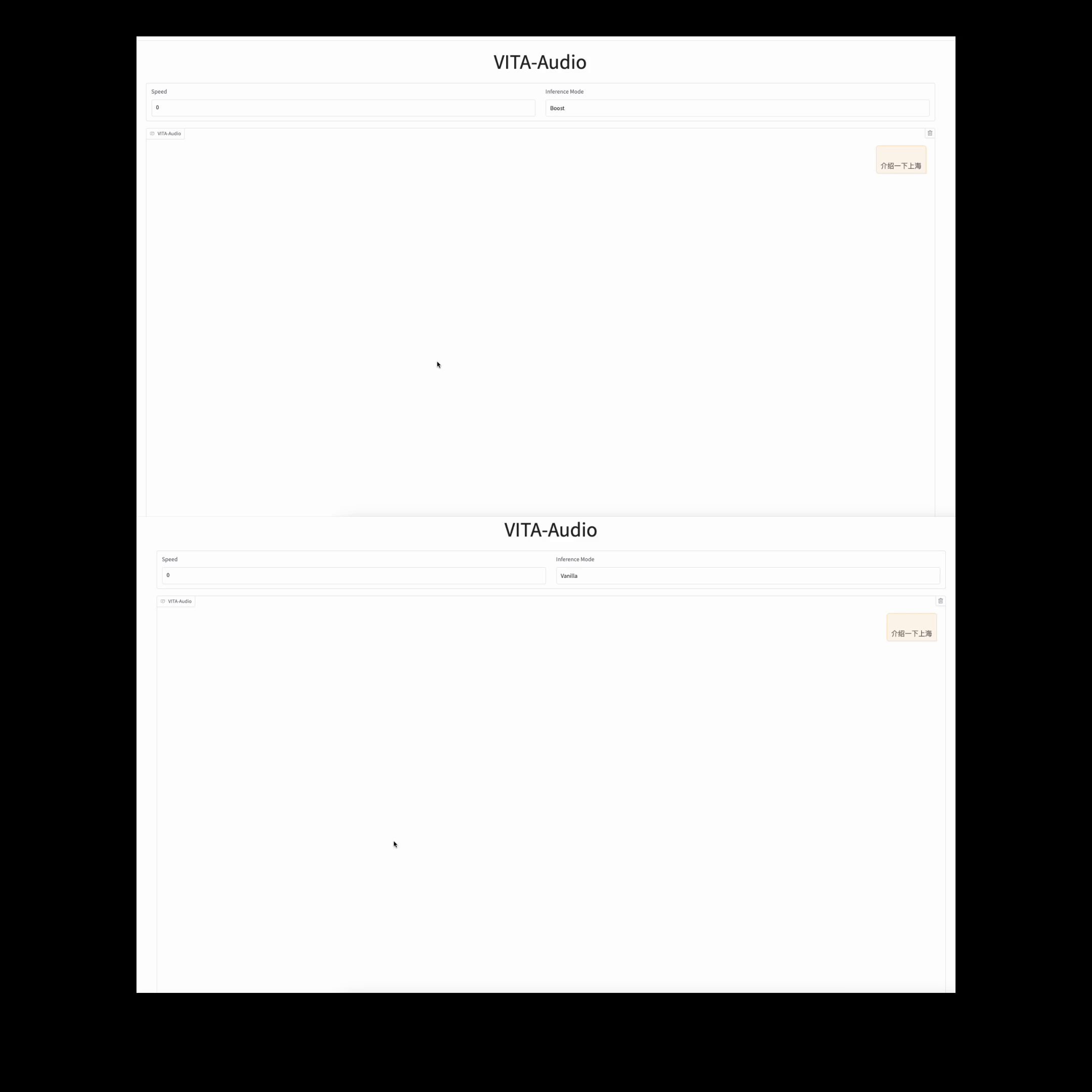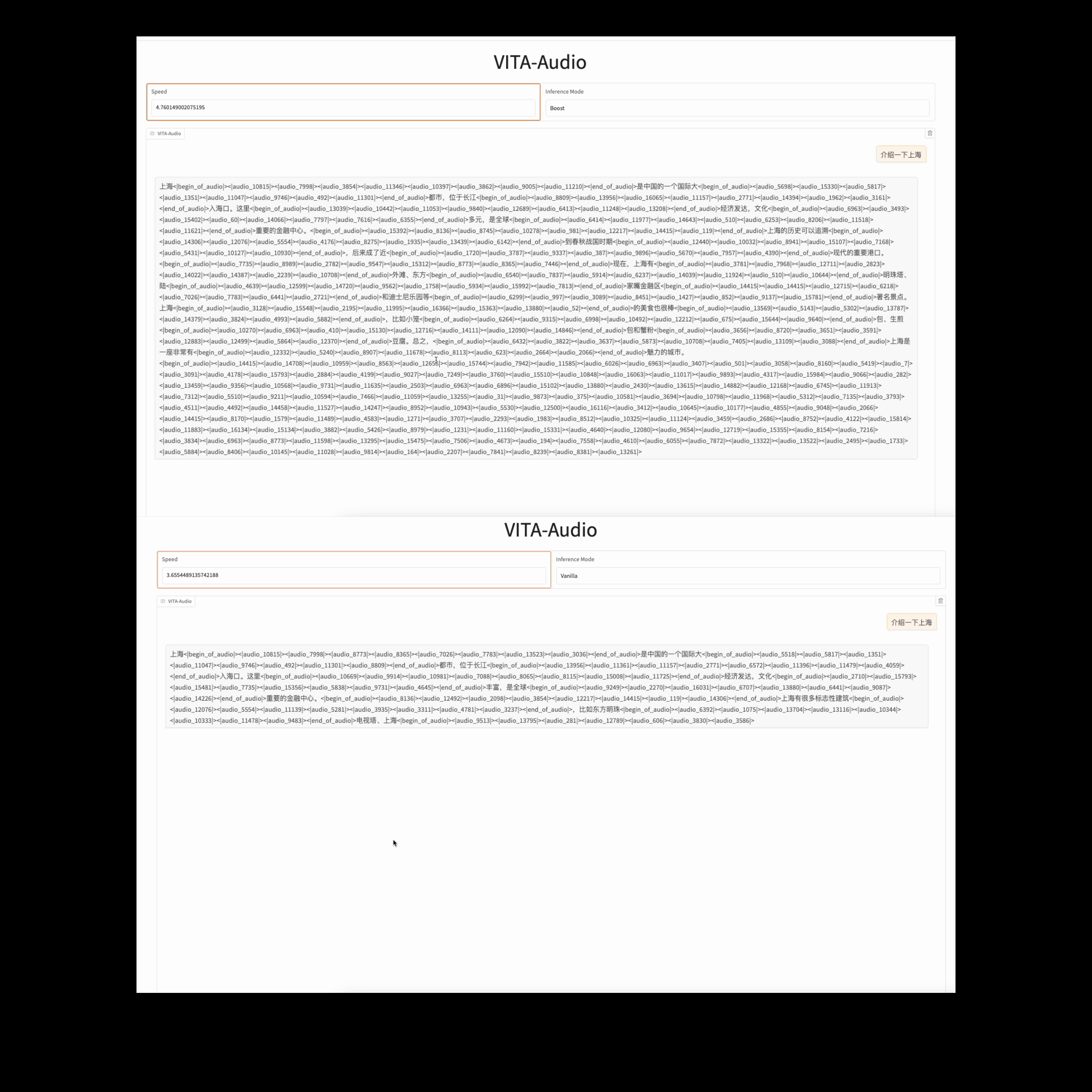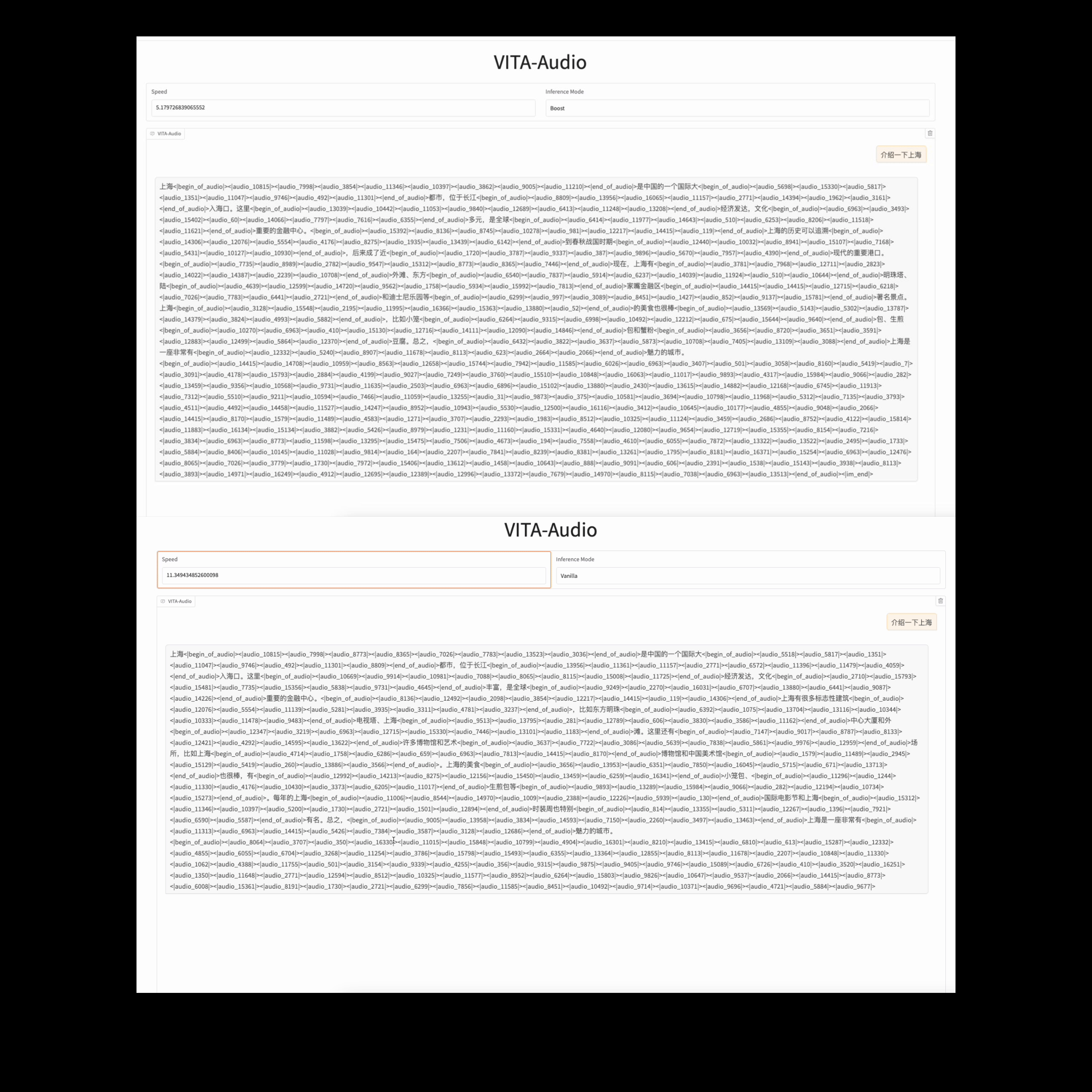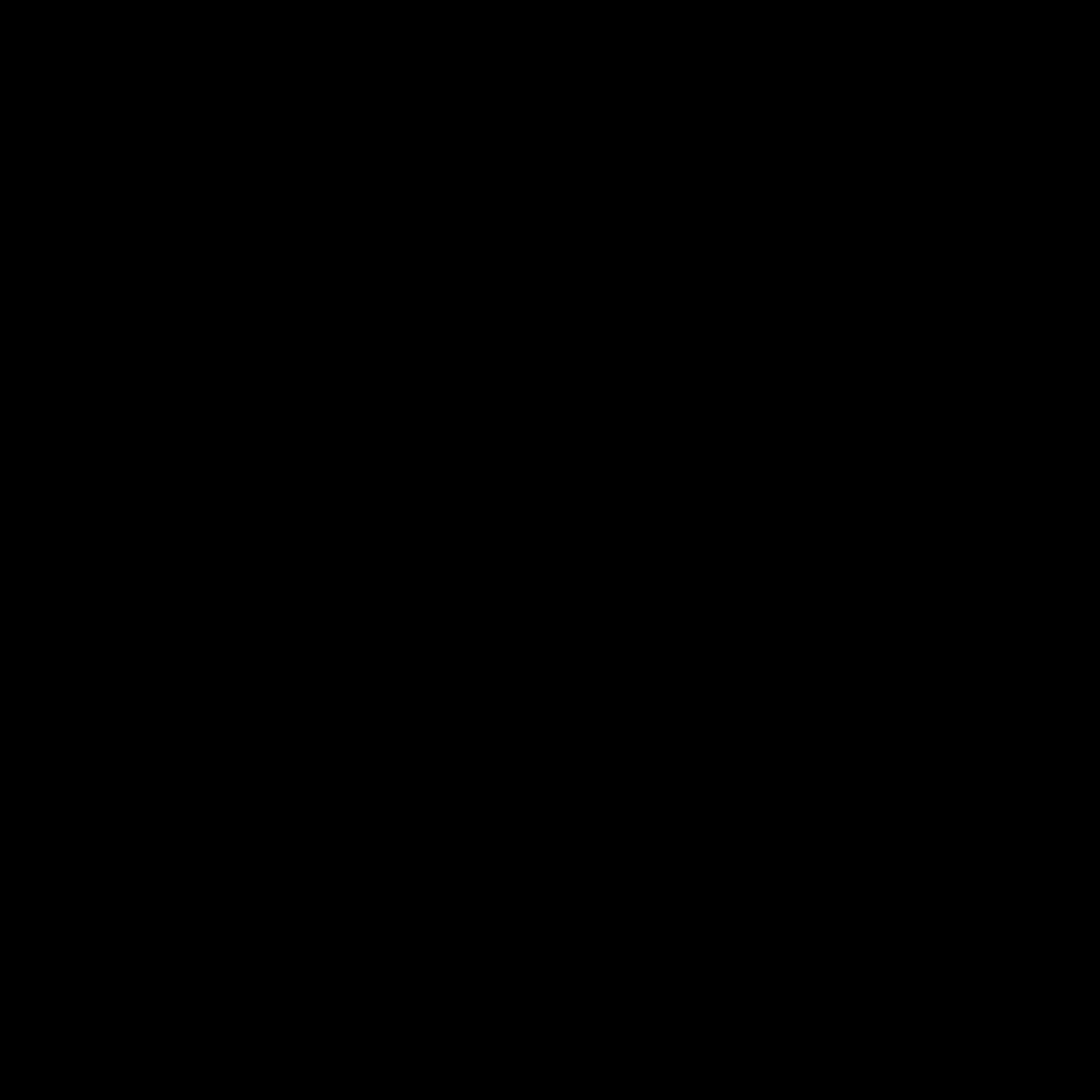
9.5 MB
asset/tts_speed.gif
0 → 100644
{kind=link}

8.53 MB
asset/vita-audio_logo.jpg
0 → 100644
{kind=link}
2.07 MB
asset/wechat-group.jpg
0 → 100644
{kind=link}

1.12 MB
asset/介绍一下上海.wav
0 → 100644
File added