
bert-large training
Showing
File added
File added
bert.png
0 → 100644
{kind=link}

112 KB
bert_config.json
0 → 100644
bert_model.png
0 → 100644
{kind=link}
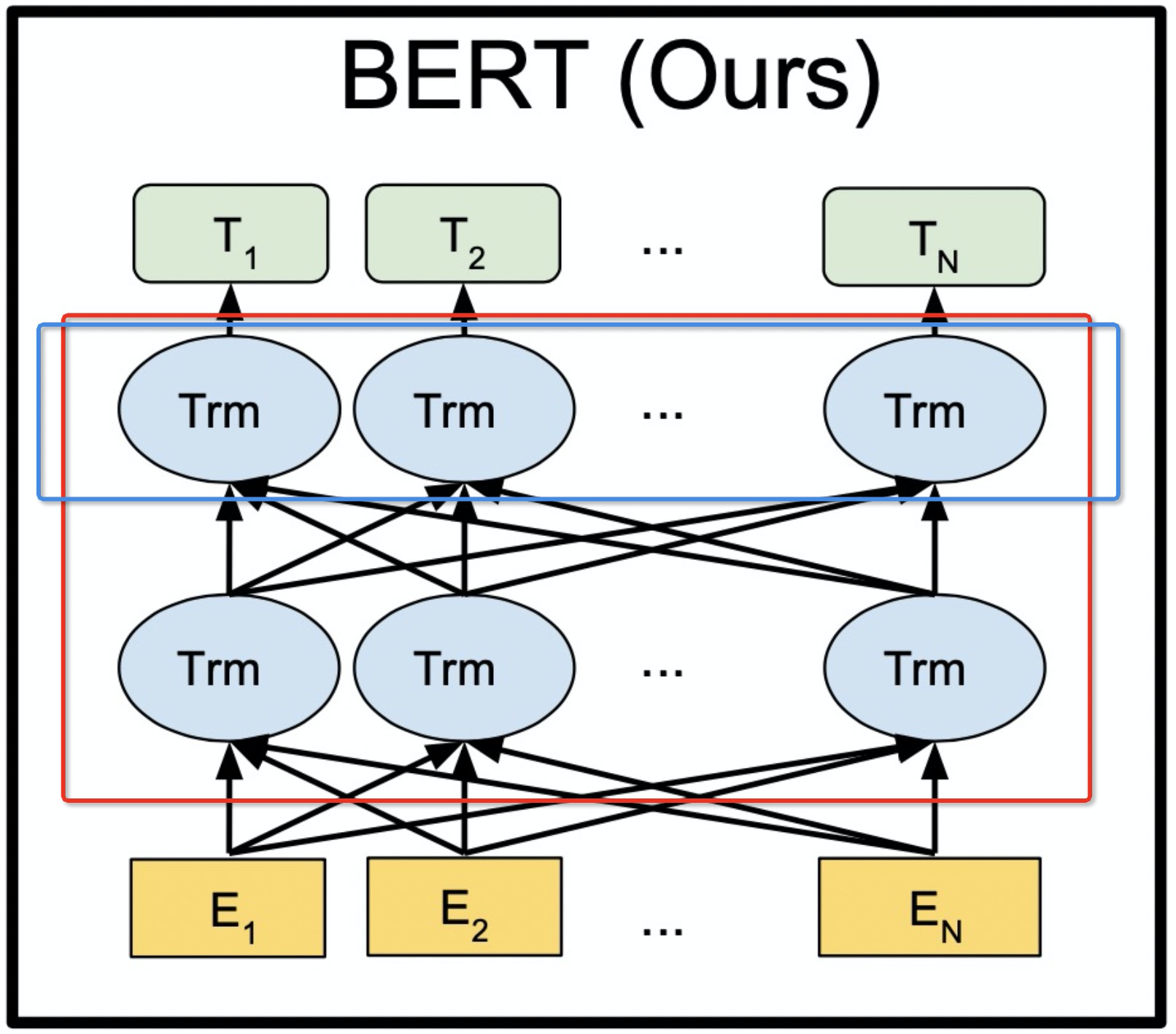
791 KB
bert_pre1.sh
0 → 100755
bert_pre1_4.log
0 → 100644
This diff is collapsed.
bert_pre1_4.sh
0 → 100755
bert_pre1_4_fp16.sh
0 → 100644
bert_pre1_fp16.sh
0 → 100644
bert_pre2.sh
0 → 100644
bert_pre2_4.sh
0 → 100644
bert_pre2_4_fp16.sh
0 → 100644
bert_pre2_fp16.sh
0 → 100644
bert_squad.sh
0 → 100644
bert_squad4.sh
0 → 100644
bert_squad4_fp16.sh
0 → 100644
bert_squad_fp16.sh
0 → 100644
bind.sh
0 → 100644
bind_pyt.py
0 → 100644