Skip to content
GitLab
Menu
Projects
Groups
Snippets
Loading...
Help
Help
Support
Community forum
Keyboard shortcuts
?
Submit feedback
Contribute to GitLab
Sign in / Register
Toggle navigation
Menu
Open sidebar
dongchy920
instruct_pix2pix
Commits
9cfc6603
Commit
9cfc6603
authored
Nov 26, 2024
by
dongchy920
Browse files
instruct first commit
parents
Pipeline
#1969
canceled with stages
Changes
200
Pipelines
1
Expand all
Hide whitespace changes
Inline
Side-by-side
Showing
20 changed files
with
943 additions
and
0 deletions
+943
-0
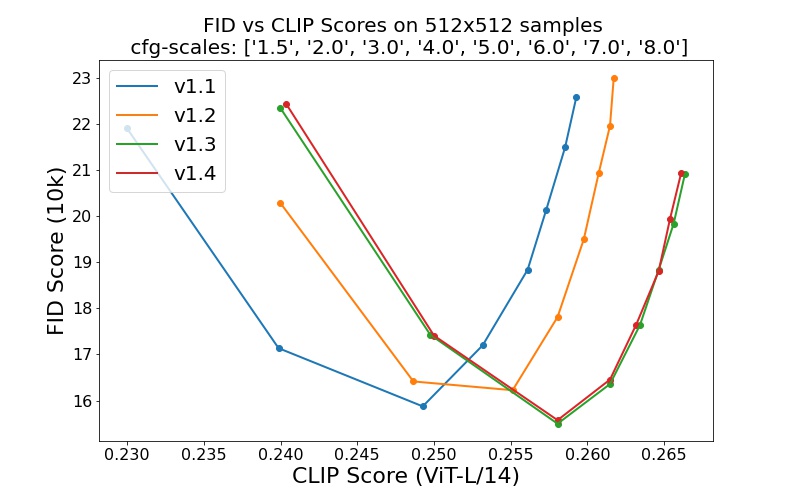
stable_diffusion/assets/v1-variants-scores.jpg
stable_diffusion/assets/v1-variants-scores.jpg
+0
-0
stable_diffusion/configs/autoencoder/autoencoder_kl_16x16x16.yaml
...iffusion/configs/autoencoder/autoencoder_kl_16x16x16.yaml
+54
-0
stable_diffusion/configs/autoencoder/autoencoder_kl_32x32x4.yaml
...diffusion/configs/autoencoder/autoencoder_kl_32x32x4.yaml
+53
-0
stable_diffusion/configs/autoencoder/autoencoder_kl_64x64x3.yaml
...diffusion/configs/autoencoder/autoencoder_kl_64x64x3.yaml
+54
-0
stable_diffusion/configs/autoencoder/autoencoder_kl_8x8x64.yaml
..._diffusion/configs/autoencoder/autoencoder_kl_8x8x64.yaml
+53
-0
stable_diffusion/configs/latent-diffusion/celebahq-ldm-vq-4.yaml
...diffusion/configs/latent-diffusion/celebahq-ldm-vq-4.yaml
+87
-0
stable_diffusion/configs/latent-diffusion/cin-ldm-vq-f8.yaml
stable_diffusion/configs/latent-diffusion/cin-ldm-vq-f8.yaml
+99
-0
stable_diffusion/configs/latent-diffusion/cin256-v2.yaml
stable_diffusion/configs/latent-diffusion/cin256-v2.yaml
+68
-0
stable_diffusion/configs/latent-diffusion/ffhq-ldm-vq-4.yaml
stable_diffusion/configs/latent-diffusion/ffhq-ldm-vq-4.yaml
+86
-0
stable_diffusion/configs/latent-diffusion/lsun_bedrooms-ldm-vq-4.yaml
...sion/configs/latent-diffusion/lsun_bedrooms-ldm-vq-4.yaml
+86
-0
stable_diffusion/configs/latent-diffusion/lsun_churches-ldm-kl-8.yaml
...sion/configs/latent-diffusion/lsun_churches-ldm-kl-8.yaml
+92
-0
stable_diffusion/configs/latent-diffusion/txt2img-1p4B-eval.yaml
...diffusion/configs/latent-diffusion/txt2img-1p4B-eval.yaml
+71
-0
stable_diffusion/configs/retrieval-augmented-diffusion/768x768.yaml
...fusion/configs/retrieval-augmented-diffusion/768x768.yaml
+69
-0
stable_diffusion/configs/stable-diffusion/v1-inference.yaml
stable_diffusion/configs/stable-diffusion/v1-inference.yaml
+70
-0
stable_diffusion/data/DejaVuSans.ttf
stable_diffusion/data/DejaVuSans.ttf
+0
-0
stable_diffusion/data/example_conditioning/superresolution/sample_0.jpg
...on/data/example_conditioning/superresolution/sample_0.jpg
+0
-0
stable_diffusion/data/example_conditioning/text_conditional/sample_0.txt
...n/data/example_conditioning/text_conditional/sample_0.txt
+1
-0
stable_diffusion/data/imagenet_clsidx_to_label.txt
stable_diffusion/data/imagenet_clsidx_to_label.txt
+0
-0
stable_diffusion/data/imagenet_train_hr_indices.p.REMOVED.git-id
...diffusion/data/imagenet_train_hr_indices.p.REMOVED.git-id
+0
-0
stable_diffusion/data/imagenet_val_hr_indices.p
stable_diffusion/data/imagenet_val_hr_indices.p
+0
-0
No files found.
stable_diffusion/assets/v1-variants-scores.jpg
0 → 100644
View file @
9cfc6603
74.5 KB
stable_diffusion/configs/autoencoder/autoencoder_kl_16x16x16.yaml
0 → 100644
View file @
9cfc6603
model
:
base_learning_rate
:
4.5e-6
target
:
ldm.models.autoencoder.AutoencoderKL
params
:
monitor
:
"
val/rec_loss"
embed_dim
:
16
lossconfig
:
target
:
ldm.modules.losses.LPIPSWithDiscriminator
params
:
disc_start
:
50001
kl_weight
:
0.000001
disc_weight
:
0.5
ddconfig
:
double_z
:
True
z_channels
:
16
resolution
:
256
in_channels
:
3
out_ch
:
3
ch
:
128
ch_mult
:
[
1
,
1
,
2
,
2
,
4
]
# num_down = len(ch_mult)-1
num_res_blocks
:
2
attn_resolutions
:
[
16
]
dropout
:
0.0
data
:
target
:
main.DataModuleFromConfig
params
:
batch_size
:
12
wrap
:
True
train
:
target
:
ldm.data.imagenet.ImageNetSRTrain
params
:
size
:
256
degradation
:
pil_nearest
validation
:
target
:
ldm.data.imagenet.ImageNetSRValidation
params
:
size
:
256
degradation
:
pil_nearest
lightning
:
callbacks
:
image_logger
:
target
:
main.ImageLogger
params
:
batch_frequency
:
1000
max_images
:
8
increase_log_steps
:
True
trainer
:
benchmark
:
True
accumulate_grad_batches
:
2
stable_diffusion/configs/autoencoder/autoencoder_kl_32x32x4.yaml
0 → 100644
View file @
9cfc6603
model
:
base_learning_rate
:
4.5e-6
target
:
ldm.models.autoencoder.AutoencoderKL
params
:
monitor
:
"
val/rec_loss"
embed_dim
:
4
lossconfig
:
target
:
ldm.modules.losses.LPIPSWithDiscriminator
params
:
disc_start
:
50001
kl_weight
:
0.000001
disc_weight
:
0.5
ddconfig
:
double_z
:
True
z_channels
:
4
resolution
:
256
in_channels
:
3
out_ch
:
3
ch
:
128
ch_mult
:
[
1
,
2
,
4
,
4
]
# num_down = len(ch_mult)-1
num_res_blocks
:
2
attn_resolutions
:
[
]
dropout
:
0.0
data
:
target
:
main.DataModuleFromConfig
params
:
batch_size
:
12
wrap
:
True
train
:
target
:
ldm.data.imagenet.ImageNetSRTrain
params
:
size
:
256
degradation
:
pil_nearest
validation
:
target
:
ldm.data.imagenet.ImageNetSRValidation
params
:
size
:
256
degradation
:
pil_nearest
lightning
:
callbacks
:
image_logger
:
target
:
main.ImageLogger
params
:
batch_frequency
:
1000
max_images
:
8
increase_log_steps
:
True
trainer
:
benchmark
:
True
accumulate_grad_batches
:
2
stable_diffusion/configs/autoencoder/autoencoder_kl_64x64x3.yaml
0 → 100644
View file @
9cfc6603
model
:
base_learning_rate
:
4.5e-6
target
:
ldm.models.autoencoder.AutoencoderKL
params
:
monitor
:
"
val/rec_loss"
embed_dim
:
3
lossconfig
:
target
:
ldm.modules.losses.LPIPSWithDiscriminator
params
:
disc_start
:
50001
kl_weight
:
0.000001
disc_weight
:
0.5
ddconfig
:
double_z
:
True
z_channels
:
3
resolution
:
256
in_channels
:
3
out_ch
:
3
ch
:
128
ch_mult
:
[
1
,
2
,
4
]
# num_down = len(ch_mult)-1
num_res_blocks
:
2
attn_resolutions
:
[
]
dropout
:
0.0
data
:
target
:
main.DataModuleFromConfig
params
:
batch_size
:
12
wrap
:
True
train
:
target
:
ldm.data.imagenet.ImageNetSRTrain
params
:
size
:
256
degradation
:
pil_nearest
validation
:
target
:
ldm.data.imagenet.ImageNetSRValidation
params
:
size
:
256
degradation
:
pil_nearest
lightning
:
callbacks
:
image_logger
:
target
:
main.ImageLogger
params
:
batch_frequency
:
1000
max_images
:
8
increase_log_steps
:
True
trainer
:
benchmark
:
True
accumulate_grad_batches
:
2
stable_diffusion/configs/autoencoder/autoencoder_kl_8x8x64.yaml
0 → 100644
View file @
9cfc6603
model
:
base_learning_rate
:
4.5e-6
target
:
ldm.models.autoencoder.AutoencoderKL
params
:
monitor
:
"
val/rec_loss"
embed_dim
:
64
lossconfig
:
target
:
ldm.modules.losses.LPIPSWithDiscriminator
params
:
disc_start
:
50001
kl_weight
:
0.000001
disc_weight
:
0.5
ddconfig
:
double_z
:
True
z_channels
:
64
resolution
:
256
in_channels
:
3
out_ch
:
3
ch
:
128
ch_mult
:
[
1
,
1
,
2
,
2
,
4
,
4
]
# num_down = len(ch_mult)-1
num_res_blocks
:
2
attn_resolutions
:
[
16
,
8
]
dropout
:
0.0
data
:
target
:
main.DataModuleFromConfig
params
:
batch_size
:
12
wrap
:
True
train
:
target
:
ldm.data.imagenet.ImageNetSRTrain
params
:
size
:
256
degradation
:
pil_nearest
validation
:
target
:
ldm.data.imagenet.ImageNetSRValidation
params
:
size
:
256
degradation
:
pil_nearest
lightning
:
callbacks
:
image_logger
:
target
:
main.ImageLogger
params
:
batch_frequency
:
1000
max_images
:
8
increase_log_steps
:
True
trainer
:
benchmark
:
True
accumulate_grad_batches
:
2
stable_diffusion/configs/latent-diffusion/celebahq-ldm-vq-4.yaml
0 → 100644
View file @
9cfc6603
model
:
base_learning_rate
:
2.0e-06
target
:
ldm.models.diffusion.ddpm.LatentDiffusion
params
:
linear_start
:
0.0015
linear_end
:
0.0195
num_timesteps_cond
:
1
log_every_t
:
200
timesteps
:
1000
first_stage_key
:
image
image_size
:
64
channels
:
3
monitor
:
val/loss_simple_ema
unet_config
:
target
:
ldm.modules.diffusionmodules.openaimodel.UNetModel
params
:
image_size
:
64
in_channels
:
3
out_channels
:
3
model_channels
:
224
attention_resolutions
:
# note: this isn\t actually the resolution but
# the downsampling factor, i.e. this corresnponds to
# attention on spatial resolution 8,16,32, as the
# spatial reolution of the latents is 64 for f4
-
8
-
4
-
2
num_res_blocks
:
2
channel_mult
:
-
1
-
2
-
3
-
4
num_head_channels
:
32
first_stage_config
:
target
:
ldm.models.autoencoder.VQModelInterface
params
:
embed_dim
:
3
n_embed
:
8192
ckpt_path
:
models/first_stage_models/vq-f4/model.ckpt
ddconfig
:
double_z
:
false
z_channels
:
3
resolution
:
256
in_channels
:
3
out_ch
:
3
ch
:
128
ch_mult
:
-
1
-
2
-
4
num_res_blocks
:
2
attn_resolutions
:
[]
dropout
:
0.0
lossconfig
:
target
:
torch.nn.Identity
cond_stage_config
:
__is_unconditional__
data
:
target
:
main.DataModuleFromConfig
params
:
batch_size
:
48
num_workers
:
5
wrap
:
false
train
:
target
:
taming.data.faceshq.CelebAHQTrain
params
:
size
:
256
validation
:
target
:
taming.data.faceshq.CelebAHQValidation
params
:
size
:
256
lightning
:
callbacks
:
image_logger
:
target
:
main.ImageLogger
params
:
batch_frequency
:
5000
max_images
:
8
increase_log_steps
:
False
trainer
:
benchmark
:
True
\ No newline at end of file
stable_diffusion/configs/latent-diffusion/cin-ldm-vq-f8.yaml
0 → 100644
View file @
9cfc6603
model
:
base_learning_rate
:
1.0e-06
target
:
ldm.models.diffusion.ddpm.LatentDiffusion
params
:
linear_start
:
0.0015
linear_end
:
0.0195
num_timesteps_cond
:
1
log_every_t
:
200
timesteps
:
1000
first_stage_key
:
image
cond_stage_key
:
class_label
image_size
:
32
channels
:
4
cond_stage_trainable
:
true
conditioning_key
:
crossattn
monitor
:
val/loss_simple_ema
unet_config
:
target
:
ldm.modules.diffusionmodules.openaimodel.UNetModel
params
:
image_size
:
32
in_channels
:
4
out_channels
:
4
model_channels
:
256
attention_resolutions
:
#note: this isn\t actually the resolution but
# the downsampling factor, i.e. this corresnponds to
# attention on spatial resolution 8,16,32, as the
# spatial reolution of the latents is 32 for f8
-
4
-
2
-
1
num_res_blocks
:
2
channel_mult
:
-
1
-
2
-
4
num_head_channels
:
32
use_spatial_transformer
:
true
transformer_depth
:
1
context_dim
:
512
first_stage_config
:
target
:
ldm.models.autoencoder.VQModelInterface
params
:
embed_dim
:
4
n_embed
:
16384
ckpt_path
:
configs/first_stage_models/vq-f8/model.yaml
ddconfig
:
double_z
:
false
z_channels
:
4
resolution
:
256
in_channels
:
3
out_ch
:
3
ch
:
128
ch_mult
:
-
1
-
2
-
2
-
4
num_res_blocks
:
2
attn_resolutions
:
-
32
dropout
:
0.0
lossconfig
:
target
:
torch.nn.Identity
cond_stage_config
:
target
:
ldm.modules.encoders.modules.ClassEmbedder
params
:
embed_dim
:
512
key
:
class_label
data
:
target
:
main.DataModuleFromConfig
params
:
batch_size
:
64
num_workers
:
12
wrap
:
false
train
:
target
:
ldm.data.imagenet.ImageNetTrain
params
:
config
:
size
:
256
validation
:
target
:
ldm.data.imagenet.ImageNetValidation
params
:
config
:
size
:
256
lightning
:
callbacks
:
image_logger
:
target
:
main.ImageLogger
params
:
batch_frequency
:
5000
max_images
:
8
increase_log_steps
:
False
trainer
:
benchmark
:
True
\ No newline at end of file
stable_diffusion/configs/latent-diffusion/cin256-v2.yaml
0 → 100644
View file @
9cfc6603
model
:
base_learning_rate
:
0.0001
target
:
ldm.models.diffusion.ddpm.LatentDiffusion
params
:
linear_start
:
0.0015
linear_end
:
0.0195
num_timesteps_cond
:
1
log_every_t
:
200
timesteps
:
1000
first_stage_key
:
image
cond_stage_key
:
class_label
image_size
:
64
channels
:
3
cond_stage_trainable
:
true
conditioning_key
:
crossattn
monitor
:
val/loss
use_ema
:
False
unet_config
:
target
:
ldm.modules.diffusionmodules.openaimodel.UNetModel
params
:
image_size
:
64
in_channels
:
3
out_channels
:
3
model_channels
:
192
attention_resolutions
:
-
8
-
4
-
2
num_res_blocks
:
2
channel_mult
:
-
1
-
2
-
3
-
5
num_heads
:
1
use_spatial_transformer
:
true
transformer_depth
:
1
context_dim
:
512
first_stage_config
:
target
:
ldm.models.autoencoder.VQModelInterface
params
:
embed_dim
:
3
n_embed
:
8192
ddconfig
:
double_z
:
false
z_channels
:
3
resolution
:
256
in_channels
:
3
out_ch
:
3
ch
:
128
ch_mult
:
-
1
-
2
-
4
num_res_blocks
:
2
attn_resolutions
:
[]
dropout
:
0.0
lossconfig
:
target
:
torch.nn.Identity
cond_stage_config
:
target
:
ldm.modules.encoders.modules.ClassEmbedder
params
:
n_classes
:
1001
embed_dim
:
512
key
:
class_label
stable_diffusion/configs/latent-diffusion/ffhq-ldm-vq-4.yaml
0 → 100644
View file @
9cfc6603
model
:
base_learning_rate
:
2.0e-06
target
:
ldm.models.diffusion.ddpm.LatentDiffusion
params
:
linear_start
:
0.0015
linear_end
:
0.0195
num_timesteps_cond
:
1
log_every_t
:
200
timesteps
:
1000
first_stage_key
:
image
image_size
:
64
channels
:
3
monitor
:
val/loss_simple_ema
unet_config
:
target
:
ldm.modules.diffusionmodules.openaimodel.UNetModel
params
:
image_size
:
64
in_channels
:
3
out_channels
:
3
model_channels
:
224
attention_resolutions
:
# note: this isn\t actually the resolution but
# the downsampling factor, i.e. this corresnponds to
# attention on spatial resolution 8,16,32, as the
# spatial reolution of the latents is 64 for f4
-
8
-
4
-
2
num_res_blocks
:
2
channel_mult
:
-
1
-
2
-
3
-
4
num_head_channels
:
32
first_stage_config
:
target
:
ldm.models.autoencoder.VQModelInterface
params
:
embed_dim
:
3
n_embed
:
8192
ckpt_path
:
configs/first_stage_models/vq-f4/model.yaml
ddconfig
:
double_z
:
false
z_channels
:
3
resolution
:
256
in_channels
:
3
out_ch
:
3
ch
:
128
ch_mult
:
-
1
-
2
-
4
num_res_blocks
:
2
attn_resolutions
:
[]
dropout
:
0.0
lossconfig
:
target
:
torch.nn.Identity
cond_stage_config
:
__is_unconditional__
data
:
target
:
main.DataModuleFromConfig
params
:
batch_size
:
42
num_workers
:
5
wrap
:
false
train
:
target
:
taming.data.faceshq.FFHQTrain
params
:
size
:
256
validation
:
target
:
taming.data.faceshq.FFHQValidation
params
:
size
:
256
lightning
:
callbacks
:
image_logger
:
target
:
main.ImageLogger
params
:
batch_frequency
:
5000
max_images
:
8
increase_log_steps
:
False
trainer
:
benchmark
:
True
\ No newline at end of file
stable_diffusion/configs/latent-diffusion/lsun_bedrooms-ldm-vq-4.yaml
0 → 100644
View file @
9cfc6603
model
:
base_learning_rate
:
2.0e-06
target
:
ldm.models.diffusion.ddpm.LatentDiffusion
params
:
linear_start
:
0.0015
linear_end
:
0.0195
num_timesteps_cond
:
1
log_every_t
:
200
timesteps
:
1000
first_stage_key
:
image
image_size
:
64
channels
:
3
monitor
:
val/loss_simple_ema
unet_config
:
target
:
ldm.modules.diffusionmodules.openaimodel.UNetModel
params
:
image_size
:
64
in_channels
:
3
out_channels
:
3
model_channels
:
224
attention_resolutions
:
# note: this isn\t actually the resolution but
# the downsampling factor, i.e. this corresnponds to
# attention on spatial resolution 8,16,32, as the
# spatial reolution of the latents is 64 for f4
-
8
-
4
-
2
num_res_blocks
:
2
channel_mult
:
-
1
-
2
-
3
-
4
num_head_channels
:
32
first_stage_config
:
target
:
ldm.models.autoencoder.VQModelInterface
params
:
ckpt_path
:
configs/first_stage_models/vq-f4/model.yaml
embed_dim
:
3
n_embed
:
8192
ddconfig
:
double_z
:
false
z_channels
:
3
resolution
:
256
in_channels
:
3
out_ch
:
3
ch
:
128
ch_mult
:
-
1
-
2
-
4
num_res_blocks
:
2
attn_resolutions
:
[]
dropout
:
0.0
lossconfig
:
target
:
torch.nn.Identity
cond_stage_config
:
__is_unconditional__
data
:
target
:
main.DataModuleFromConfig
params
:
batch_size
:
48
num_workers
:
5
wrap
:
false
train
:
target
:
ldm.data.lsun.LSUNBedroomsTrain
params
:
size
:
256
validation
:
target
:
ldm.data.lsun.LSUNBedroomsValidation
params
:
size
:
256
lightning
:
callbacks
:
image_logger
:
target
:
main.ImageLogger
params
:
batch_frequency
:
5000
max_images
:
8
increase_log_steps
:
False
trainer
:
benchmark
:
True
\ No newline at end of file
stable_diffusion/configs/latent-diffusion/lsun_churches-ldm-kl-8.yaml
0 → 100644
View file @
9cfc6603
model
:
base_learning_rate
:
5.0e-5
# set to target_lr by starting main.py with '--scale_lr False'
target
:
ldm.models.diffusion.ddpm.LatentDiffusion
params
:
linear_start
:
0.0015
linear_end
:
0.0155
num_timesteps_cond
:
1
log_every_t
:
200
timesteps
:
1000
loss_type
:
l1
first_stage_key
:
"
image"
cond_stage_key
:
"
image"
image_size
:
32
channels
:
4
cond_stage_trainable
:
False
concat_mode
:
False
scale_by_std
:
True
monitor
:
'
val/loss_simple_ema'
scheduler_config
:
# 10000 warmup steps
target
:
ldm.lr_scheduler.LambdaLinearScheduler
params
:
warm_up_steps
:
[
10000
]
cycle_lengths
:
[
10000000000000
]
f_start
:
[
1.e-6
]
f_max
:
[
1.
]
f_min
:
[
1.
]
unet_config
:
target
:
ldm.modules.diffusionmodules.openaimodel.UNetModel
params
:
image_size
:
32
in_channels
:
4
out_channels
:
4
model_channels
:
192
attention_resolutions
:
[
1
,
2
,
4
,
8
]
# 32, 16, 8, 4
num_res_blocks
:
2
channel_mult
:
[
1
,
2
,
2
,
4
,
4
]
# 32, 16, 8, 4, 2
num_heads
:
8
use_scale_shift_norm
:
True
resblock_updown
:
True
first_stage_config
:
target
:
ldm.models.autoencoder.AutoencoderKL
params
:
embed_dim
:
4
monitor
:
"
val/rec_loss"
ckpt_path
:
"
models/first_stage_models/kl-f8/model.ckpt"
ddconfig
:
double_z
:
True
z_channels
:
4
resolution
:
256
in_channels
:
3
out_ch
:
3
ch
:
128
ch_mult
:
[
1
,
2
,
4
,
4
]
# num_down = len(ch_mult)-1
num_res_blocks
:
2
attn_resolutions
:
[
]
dropout
:
0.0
lossconfig
:
target
:
torch.nn.Identity
cond_stage_config
:
"
__is_unconditional__"
data
:
target
:
main.DataModuleFromConfig
params
:
batch_size
:
96
num_workers
:
5
wrap
:
False
train
:
target
:
ldm.data.lsun.LSUNChurchesTrain
params
:
size
:
256
validation
:
target
:
ldm.data.lsun.LSUNChurchesValidation
params
:
size
:
256
lightning
:
callbacks
:
image_logger
:
target
:
main.ImageLogger
params
:
batch_frequency
:
5000
max_images
:
8
increase_log_steps
:
False
trainer
:
benchmark
:
True
\ No newline at end of file
stable_diffusion/configs/latent-diffusion/txt2img-1p4B-eval.yaml
0 → 100644
View file @
9cfc6603
model
:
base_learning_rate
:
5.0e-05
target
:
ldm.models.diffusion.ddpm.LatentDiffusion
params
:
linear_start
:
0.00085
linear_end
:
0.012
num_timesteps_cond
:
1
log_every_t
:
200
timesteps
:
1000
first_stage_key
:
image
cond_stage_key
:
caption
image_size
:
32
channels
:
4
cond_stage_trainable
:
true
conditioning_key
:
crossattn
monitor
:
val/loss_simple_ema
scale_factor
:
0.18215
use_ema
:
False
unet_config
:
target
:
ldm.modules.diffusionmodules.openaimodel.UNetModel
params
:
image_size
:
32
in_channels
:
4
out_channels
:
4
model_channels
:
320
attention_resolutions
:
-
4
-
2
-
1
num_res_blocks
:
2
channel_mult
:
-
1
-
2
-
4
-
4
num_heads
:
8
use_spatial_transformer
:
true
transformer_depth
:
1
context_dim
:
1280
use_checkpoint
:
true
legacy
:
False
first_stage_config
:
target
:
ldm.models.autoencoder.AutoencoderKL
params
:
embed_dim
:
4
monitor
:
val/rec_loss
ddconfig
:
double_z
:
true
z_channels
:
4
resolution
:
256
in_channels
:
3
out_ch
:
3
ch
:
128
ch_mult
:
-
1
-
2
-
4
-
4
num_res_blocks
:
2
attn_resolutions
:
[]
dropout
:
0.0
lossconfig
:
target
:
torch.nn.Identity
cond_stage_config
:
target
:
ldm.modules.encoders.modules.BERTEmbedder
params
:
n_embed
:
1280
n_layer
:
32
stable_diffusion/configs/retrieval-augmented-diffusion/768x768.yaml
0 → 100644
View file @
9cfc6603
model
:
base_learning_rate
:
0.0001
target
:
ldm.models.diffusion.ddpm.LatentDiffusion
params
:
linear_start
:
0.0015
linear_end
:
0.015
num_timesteps_cond
:
1
log_every_t
:
200
timesteps
:
1000
first_stage_key
:
jpg
cond_stage_key
:
nix
image_size
:
48
channels
:
16
cond_stage_trainable
:
false
conditioning_key
:
crossattn
monitor
:
val/loss_simple_ema
scale_by_std
:
false
scale_factor
:
0.22765929
unet_config
:
target
:
ldm.modules.diffusionmodules.openaimodel.UNetModel
params
:
image_size
:
48
in_channels
:
16
out_channels
:
16
model_channels
:
448
attention_resolutions
:
-
4
-
2
-
1
num_res_blocks
:
2
channel_mult
:
-
1
-
2
-
3
-
4
use_scale_shift_norm
:
false
resblock_updown
:
false
num_head_channels
:
32
use_spatial_transformer
:
true
transformer_depth
:
1
context_dim
:
768
use_checkpoint
:
true
first_stage_config
:
target
:
ldm.models.autoencoder.AutoencoderKL
params
:
monitor
:
val/rec_loss
embed_dim
:
16
ddconfig
:
double_z
:
true
z_channels
:
16
resolution
:
256
in_channels
:
3
out_ch
:
3
ch
:
128
ch_mult
:
-
1
-
1
-
2
-
2
-
4
num_res_blocks
:
2
attn_resolutions
:
-
16
dropout
:
0.0
lossconfig
:
target
:
torch.nn.Identity
cond_stage_config
:
target
:
torch.nn.Identity
\ No newline at end of file
stable_diffusion/configs/stable-diffusion/v1-inference.yaml
0 → 100644
View file @
9cfc6603
model
:
base_learning_rate
:
1.0e-04
target
:
ldm.models.diffusion.ddpm.LatentDiffusion
params
:
linear_start
:
0.00085
linear_end
:
0.0120
num_timesteps_cond
:
1
log_every_t
:
200
timesteps
:
1000
first_stage_key
:
"
jpg"
cond_stage_key
:
"
txt"
image_size
:
64
channels
:
4
cond_stage_trainable
:
false
# Note: different from the one we trained before
conditioning_key
:
crossattn
monitor
:
val/loss_simple_ema
scale_factor
:
0.18215
use_ema
:
False
scheduler_config
:
# 10000 warmup steps
target
:
ldm.lr_scheduler.LambdaLinearScheduler
params
:
warm_up_steps
:
[
10000
]
cycle_lengths
:
[
10000000000000
]
# incredibly large number to prevent corner cases
f_start
:
[
1.e-6
]
f_max
:
[
1.
]
f_min
:
[
1.
]
unet_config
:
target
:
ldm.modules.diffusionmodules.openaimodel.UNetModel
params
:
image_size
:
32
# unused
in_channels
:
4
out_channels
:
4
model_channels
:
320
attention_resolutions
:
[
4
,
2
,
1
]
num_res_blocks
:
2
channel_mult
:
[
1
,
2
,
4
,
4
]
num_heads
:
8
use_spatial_transformer
:
True
transformer_depth
:
1
context_dim
:
768
use_checkpoint
:
True
legacy
:
False
first_stage_config
:
target
:
ldm.models.autoencoder.AutoencoderKL
params
:
embed_dim
:
4
monitor
:
val/rec_loss
ddconfig
:
double_z
:
true
z_channels
:
4
resolution
:
256
in_channels
:
3
out_ch
:
3
ch
:
128
ch_mult
:
-
1
-
2
-
4
-
4
num_res_blocks
:
2
attn_resolutions
:
[]
dropout
:
0.0
lossconfig
:
target
:
torch.nn.Identity
cond_stage_config
:
target
:
ldm.modules.encoders.modules.FrozenCLIPEmbedder
stable_diffusion/data/DejaVuSans.ttf
0 → 100644
View file @
9cfc6603
File added
stable_diffusion/data/example_conditioning/superresolution/sample_0.jpg
0 → 100644
View file @
9cfc6603
14.5 KB
stable_diffusion/data/example_conditioning/text_conditional/sample_0.txt
0 → 100644
View file @
9cfc6603
A basket of cerries
stable_diffusion/data/imagenet_clsidx_to_label.txt
0 → 100644
View file @
9cfc6603
This diff is collapsed.
Click to expand it.
stable_diffusion/data/imagenet_train_hr_indices.p.REMOVED.git-id
0 → 100644
View file @
9cfc6603
This diff is collapsed.
Click to expand it.
stable_diffusion/data/imagenet_val_hr_indices.p
0 → 100644
View file @
9cfc6603
This diff is collapsed.
Click to expand it.
Prev
1
2
3
4
5
6
7
8
…
10
Next
Write
Preview
Markdown
is supported
0%
Try again
or
attach a new file
.
Attach a file
Cancel
You are about to add
0
people
to the discussion. Proceed with caution.
Finish editing this message first!
Cancel
Please
register
or
sign in
to comment

{kind=link}
{kind=link}
