
instruct first commit
Showing
LICENSE
0 → 100644
README.md
0 → 100644
configs/generate.yaml
0 → 100644
configs/train.yaml
0 → 100644
docker/dockerfile
0 → 100644
edit_app.py
0 → 100644
edit_cli.py
0 → 100644
edit_dataset.py
0 → 100644
environment.yaml
0 → 100644
imgs/dataset.jpg
0 → 100644
{kind=link}

98.1 KB
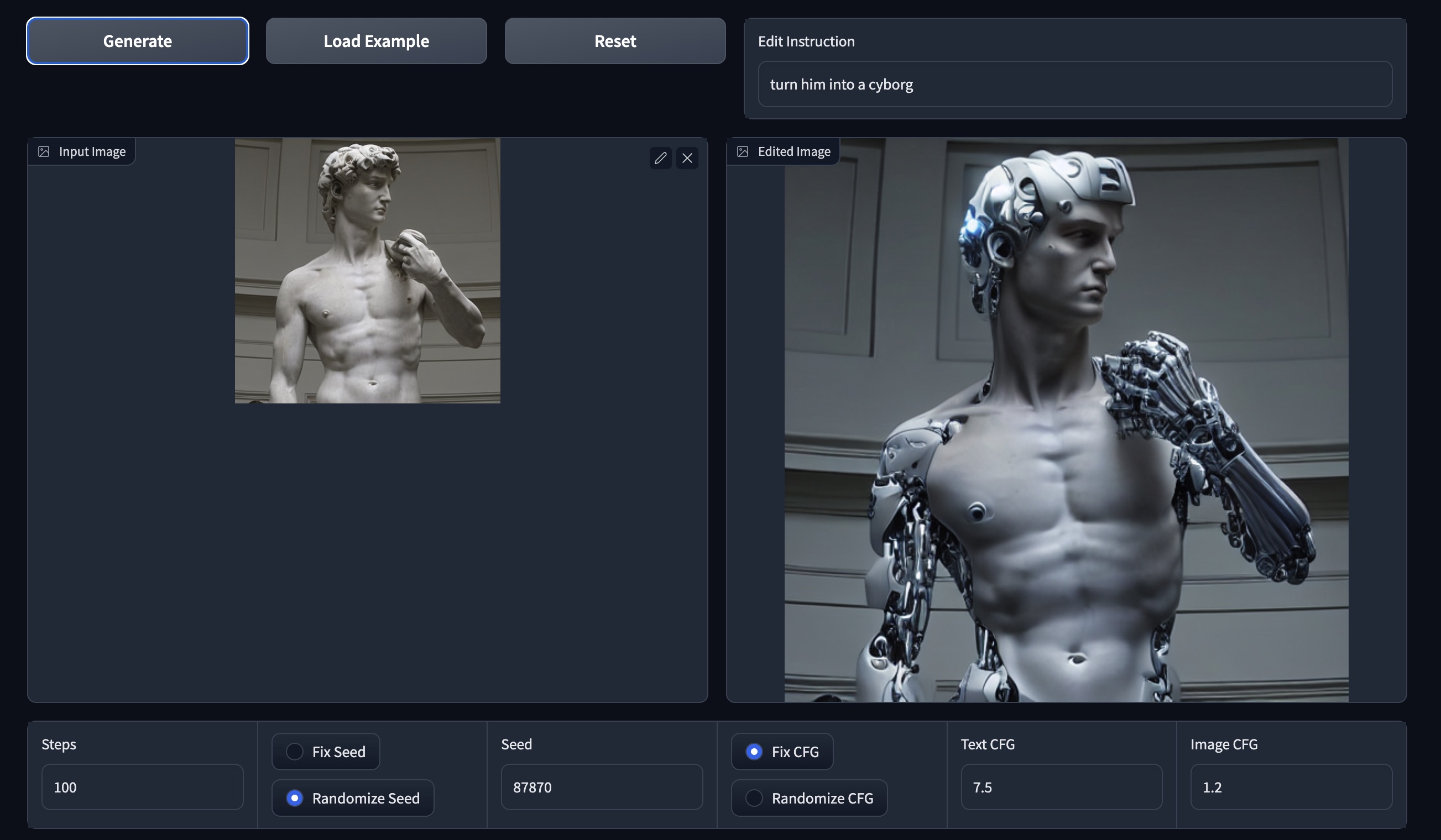
imgs/edit_app.jpg
0 → 100644
{kind=link}
392 KB
imgs/example.jpg
0 → 100644
{kind=link}

55.5 KB
imgs/model.png
0 → 100644
{kind=link}

517 KB
imgs/output.jpg
0 → 100644
{kind=link}

31.6 KB
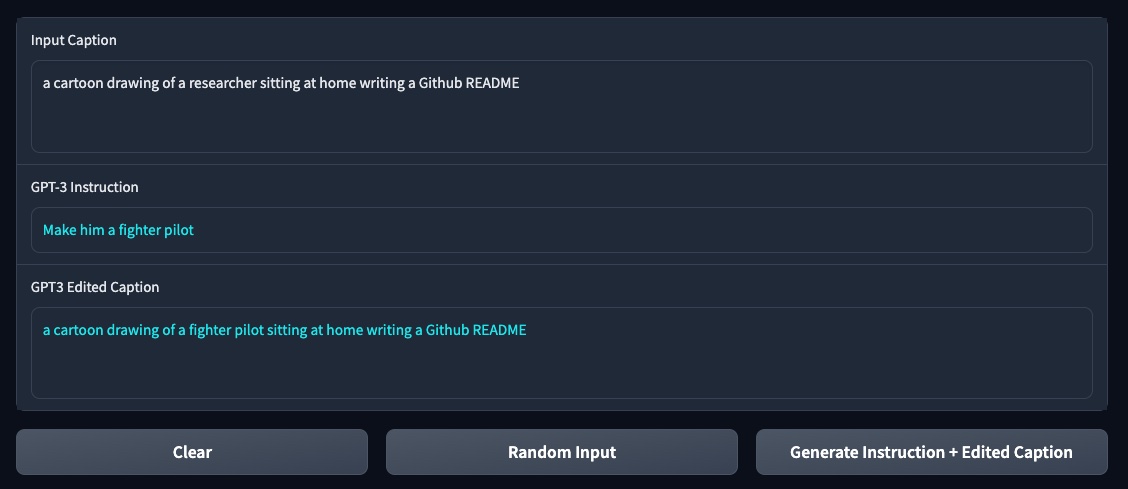
imgs/prompt_app.jpg
0 → 100644
{kind=link}
68.7 KB
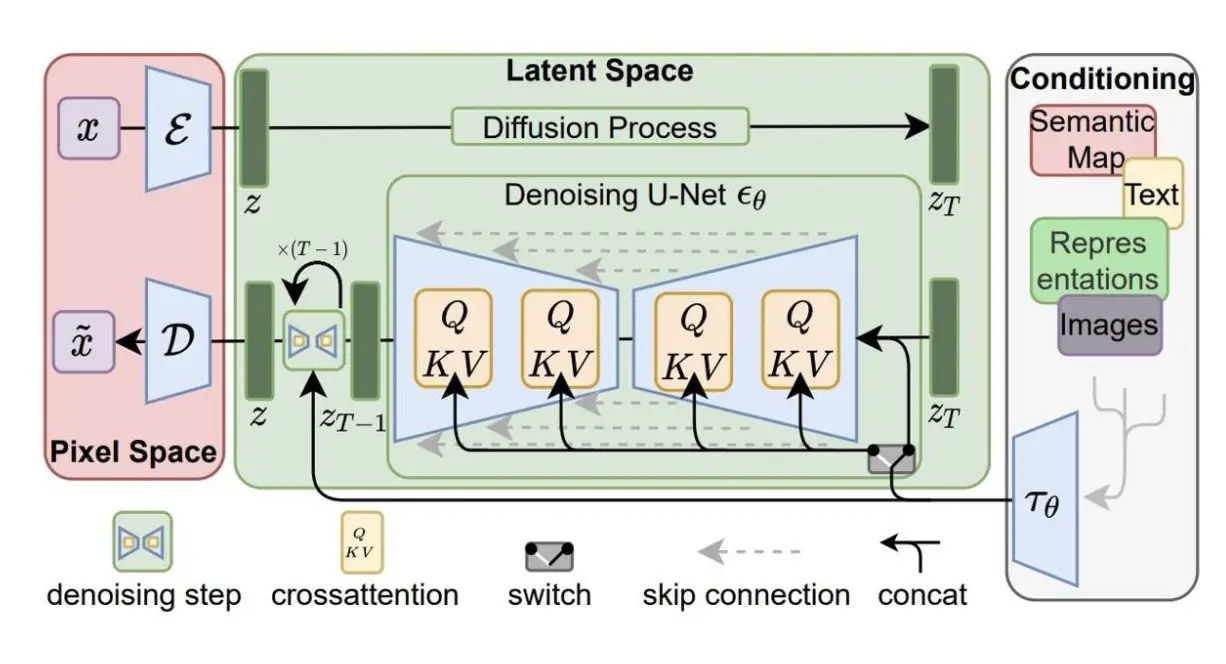
imgs/sd.png
0 → 100644
{kind=link}
704 KB