- 01 Apr, 2023 1 commit
-
-
moto authored
Summary: This commit adds a new feature AudioEffector, which can be used to apply various effects and codecs to waveforms in Tensor. Under the hood it uses StreamWriter and StreamReader to apply filters and encode/decode. This is going to replace the deprecated `apply_codec` and `apply_sox_effect_tensor` functions. It can also perform online, chunk-by-chunk filtering. Tutorial to follow. closes https://github.com/pytorch/audio/issues/3161 Pull Request resolved: https://github.com/pytorch/audio/pull/3163 Reviewed By: hwangjeff Differential Revision: D44576660 Pulled By: mthrok fbshipit-source-id: 2c5cc87082ab431315d29d56d6ac9efaf4cf7aeb
-
- 30 Mar, 2023 2 commits
-
-
moto authored
Summary: This commit adds support for changing the spec of media (such as sample rate, #channels, image size and frame rate) on-the-fly at encoding time. The motivation behind this addition is that certain media formats support only limited number of spec, and it is cumbersome to require client code to change the spec every time. For example, OPUS supports only 48kHz sampling rate, and vorbis only supports stereo. To make it easy to work with media of different formats, this commit makes it so that anything that's not compatible with the format is automatically converted, and allows users to specify the override. Notable implementation detail is that, for sample format and pixel format, the default value of encoder has higher precedent to source value, while for other attributes like sample rate and #channels, the source value has higher precedent as long as they are supported. Pull Request resolved: https://github.com/pytorch/audio/pull/3207 Reviewed By: nateanl Differential Revision: D44439622 Pulled By: mthrok fbshipit-source-id: 09524f201d485d201150481884a3e9e4d2aab081
-
moto authored
Summary: This commit adds `num_channels` argument, which allows one to change the number of channels on-the-fly. Pull Request resolved: https://github.com/pytorch/audio/pull/3216 Reviewed By: hwangjeff Differential Revision: D44516925 Pulled By: mthrok fbshipit-source-id: 3e5a11b3fdbb19071f712a8148e27aff60341df3
-
- 29 Mar, 2023 1 commit
-
-
Moto Hira authored
Summary: Pull Request resolved: https://github.com/pytorch/audio/pull/3217 This commit removes some tests for file-like object from StreamWriter test. The rational is that testing things after the output file is opened are same for file-like object and regular files. Things like filter-graph and encoder format change does not affect how the encoded bynary are written. Reviewed By: hwangjeff Differential Revision: D44518626 fbshipit-source-id: 821ec20deca92e5e5c85bf4d47997eed51735374
-
- 28 Mar, 2023 1 commit
-
-
moto authored
Summary: Pull Request resolved: https://github.com/pytorch/audio/pull/3194 Reviewed By: hwangjeff Differential Revision: D44283910 Pulled By: mthrok fbshipit-source-id: 49125724896bf7190ec27f056b6bfef260019f8e
-
- 27 Mar, 2023 1 commit
-
-
hwangjeff authored
Summary: For `StreamWriter`, * Renames arg `config` to codec_config`. * Renames struct `EncodingConfig` and dataclass `EncodeConfig` to `CodecConfig`. * Adds docstrings for arg codec_config`. * Updates `chunk` to `frames` in `write_*_chunk` methods. Pull Request resolved: https://github.com/pytorch/audio/pull/3203 Reviewed By: mthrok Differential Revision: D44350153 Pulled By: hwangjeff fbshipit-source-id: 1b940b1366a43ec0565c362bfcbf62744088b343
-
- 25 Mar, 2023 1 commit
-
-
moto authored
Summary: Some audio encoders expect specific, exact number of samples described as in `AVCodecContext.frame_size`. The `AVFrame.nb_samples` is set for the frames passed to `AVFilterGraph`, but frames coming out of the graph do not necessarily have the same numbr of frames. This causes issues with encoding OPUS (among others). This commit fixes it by inserting `asetnsamples` to filter graph if a fixed number of samples is requested. Note: It turned out that FFmpeg 4.1 has issue with OPUS encoding. It does not properly discard some sample. We should probably move the minimum required FFmpeg to 4.2, but I am not sure if we can enforce it via ABI. Work around will be to issue an warning if encoding OPUS with 4.1. (follow-up) Pull Request resolved: https://github.com/pytorch/audio/pull/3204 Reviewed By: nateanl Differential Revision: D44374668 Pulled By: mthrok fbshipit-source-id: 10ef5333dc0677dfb83c8e40b78edd8ded1b21dc
-
- 23 Mar, 2023 2 commits
-
-
moto authored
Summary: With the support of CUDA filter in https://github.com/pytorch/audio/issues/3183, it is now possible to change the pixel format of CUDA frame. This commit adds conversion for YUV444P format. Pull Request resolved: https://github.com/pytorch/audio/pull/3199 Reviewed By: hwangjeff Differential Revision: D44323928 Pulled By: mthrok fbshipit-source-id: 6d9b205e7235df5f21e7d3e06166b3a169f1ae9f
-
moto authored
Summary: OPUS encoder and VORBIS encoders require "strict=experimental" flags. This commit enables it automatically. The rational behind of it is typically we care if we can encode these formats at all and not how they are encoded. (This might be concern when these encoder becomes more mature on FFmpeg side and providing flags would result in weird behavior) Also when writing high-level functions that uses StreamWriter, if we do not set these flags, then these high-level functions have to add new options that should be passed down to StreamWriter, which turned out to be very painful in https://github.com/pytorch/audio/issues/3163 Pull Request resolved: https://github.com/pytorch/audio/pull/3192 Reviewed By: nateanl Differential Revision: D44275089 Pulled By: mthrok fbshipit-source-id: 74a757b4b7fc8467c8c88ffcb54fbaf89d6e4384
-
- 20 Mar, 2023 1 commit
-
-
moto authored
Summary: This commit adds CUDA frame support to FilterGraph It initializes and attaches CUDA frames context to FilterGraph, so that CUDA frames can be processed in FilterGraph. As a result, it enables 1. CUDA filter support such as `scale_cuda` 2. Properly retrieve the pixel format coming out of FilterGraph when CUDA HW acceleration is enabled. (currently it is reported as "cuda") Resolves https://github.com/pytorch/audio/issues/3159 Pull Request resolved: https://github.com/pytorch/audio/pull/3183 Reviewed By: hwangjeff Differential Revision: D44183722 Pulled By: mthrok fbshipit-source-id: 522d21039c361ddfaa87fa89cf49c19d210ac62f
-
- 17 Mar, 2023 1 commit
-
-
moto authored
Summary: Adds config object `EncodingConfig` and modifies `StreamWriter` to allow for passing in additional encoder configuration parameters, e.g. bit rate and compression level. Pull Request resolved: https://github.com/pytorch/audio/pull/3179 Pull Request resolved: https://github.com/pytorch/audio/pull/3164 Reviewed By: mthrok Differential Revision: D43861413 Pulled By: hwangjeff fbshipit-source-id: c1682cb2f6e682ab6f1a506511d2be7c7b254161
-
- 16 Mar, 2023 1 commit
-
-
moto authored
Summary: Currently, when the Buffer converts AVFrame* to torch::Tensor, it checks the format at each time a frame is passed, and perform the conversion. This commit changes it so that the conversion operation is pre-instantiated at the time outside stream is configured. It introduces Converter implementations for various formats, and use template to embed them in Buffer class. This way, branching like if/switch are eliminated from decoding path. Pull Request resolved: https://github.com/pytorch/audio/pull/3170 Reviewed By: xiaohui-zhang Differential Revision: D44048293 Pulled By: mthrok fbshipit-source-id: 30d8b240a5695d7513f499ce17853f2f0ffcab9f
-
- 08 Mar, 2023 2 commits
-
-
moto authored
Summary: This commit adds fields to OutputStream, which shows the result of fitlers, such as width and height after filtering. Before ``` OutputStream( source_index=0, filter_description='fps=3,scale=width=320:height=320,format=pix_fmts=gray') ``` After ``` OutputVideoStream( source_index=0, filter_description='fps=3,scale=width=320:height=320,format=pix_fmts=gray', media_type='video', format='gray', width=320, height=320, frame_rate=3.0) ``` Pull Request resolved: https://github.com/pytorch/audio/pull/3155 Reviewed By: nateanl Differential Revision: D43882399 Pulled By: mthrok fbshipit-source-id: 620676b1a06f293fdd56de8203a11120f228fa2d -
moto authored
Summary: Pull Request resolved: https://github.com/pytorch/audio/pull/3135 Reviewed By: xiaohui-zhang Differential Revision: D43724273 Pulled By: mthrok fbshipit-source-id: 9b52823618948945a26e57d5b3deccbf5f9268c1
-
- 07 Mar, 2023 1 commit
-
-
Moto Hira authored
Summary: Pull Request resolved: https://github.com/pytorch/audio/pull/3152 In StreamWriter, if the destination is not opened when attempting to write data, it causes segmentation fault. This commit adds guard so that instead of segfault, it will error-out. Reviewed By: nateanl Differential Revision: D43852649 fbshipit-source-id: aef5db7c1508f8a7db5834c2ab6de3cad09f9d60
-
- 02 Mar, 2023 1 commit
-
-
Moto Hira authored
Summary: Pull Request resolved: https://github.com/pytorch/audio/pull/3131 In https://github.com/pytorch/audio/pull/3122, the intermediate `num_frames` variable is removed. PTS can be incremented the same way, but the timing was wrong in #3122. This commit fixes it. Reviewed By: xiaohui-zhang Differential Revision: D43712046 fbshipit-source-id: 2fe0082969296f4f3964e62e55b5325fcd45f4f9
-
- 23 Feb, 2023 1 commit
-
-
mthrok authored
Summary: Remove the Tensor input support from StreamReader Follow up of https://github.com/pytorch/audio/pull/3086 Pull Request resolved: https://github.com/pytorch/audio/pull/3093 Reviewed By: xiaohui-zhang Differential Revision: D43526066 Pulled By: mthrok fbshipit-source-id: 57ba4866c413649173e1c2c3b23ba7de3231b7bc
-
- 07 Feb, 2023 1 commit
-
-
juan.azcarreta.ortiz authored
Summary: Allows user to play audio through the device speaker. Pull Request resolved: https://github.com/pytorch/audio/pull/3026 Test Plan: Created a new test that mocks a call to the write audio chunk method from StreamWriter. To run the test: `pytest test/torchaudio_unittest/io/_playback_test.py` Reviewed By: mthrok Differential Revision: D43082062 Pulled By: jazcarretao fbshipit-source-id: 01a85b32ce925687a633d1208d15d54556e89dd8
-
- 04 Feb, 2023 1 commit
-
-
Tristan Rice authored
Summary: This adds 2 10 bit pix formats one for CPU and one for CUDA. This allows for training on HDR/10bit video datasets. Pull Request resolved: https://github.com/pytorch/audio/pull/3023 Test Plan: ```py r = StreamReader( reader, format='hevc', ) stream = r.add_video_stream( frames_per_chunk=-1, decoder="hevc_cuvid", hw_accel="cuda", ) frame = next(r.stream()) ``` ```py r = StreamReader( reader, format='hevc', ) stream = r.add_video_stream( frames_per_chunk=-1, filter_desc="format=rgb48le", ) frame = next(r.stream()) ```  Reviewed By: xiaohui-zhang Differential Revision: D43019191 Pulled By: mthrok fbshipit-source-id: fe4359e525b24c8b856dfdf3d2f8596871566350
-
- 22 Jan, 2023 1 commit
-
-
moto authored
Summary: This commit makes `StreamReader` report PTS (presentation time stamp) of the returned chunk as well. Example ```python from torchaudio.io import StreamReader s = StreamReader(...) s.add_video_stream(...) for (video_chunk, ) in s.stream(): # video_chunk is Torch tensor type but has extra attribute of PTS print(video_chunk.pts) # reports the PTS of the first frame of the video chunk. ``` For the backward compatibility, we introduce a `_ChunkTensor`, that is a composition of Tensor and metadata, but works like a normal tensor in PyTorch operations. The implementation of `_ChunkTensor` is based on [TrivialTensorViaComposition](https://github.com/albanD/subclass_zoo/blob/0eeb1d68fb59879029c610bc407f2997ae43ba0a/trivial_tensors.py#L83). It was also suggested to attach metadata directly to Tensor object, but the possibility to have the collision on torchaudio's metadata and new attributes introduced in PyTorch cannot be ignored, so we use Tensor subclass implementation. If any unexpected issue arise from metadata attribute name collision, client code can fetch the bare Tensor and continue. Pull Request resolved: https://github.com/pytorch/audio/pull/2975 Reviewed By: hwangjeff Differential Revision: D42526945 Pulled By: mthrok fbshipit-source-id: b4e9422e914ff328421b975120460f3001268f35
-
- 16 Jan, 2023 1 commit
-
-
moto authored
Summary: So that the number of Tensor frames stored in buffers is always a multiple of frames_per_chunk. This makes it easy to store PTS values in aligned manner. Pull Request resolved: https://github.com/pytorch/audio/pull/2984 Reviewed By: nateanl Differential Revision: D42526670 Pulled By: mthrok fbshipit-source-id: d83ee914b7e50de3b51758069b0e0b6b3ebe2e54
-
- 12 Jan, 2023 1 commit
-
-
moto authored
Summary: This commit adds `buffer_chunk_size=-1`, which does not drop buffered frames. Pull Request resolved: https://github.com/pytorch/audio/pull/2969 Reviewed By: xiaohui-zhang Differential Revision: D42403467 Pulled By: mthrok fbshipit-source-id: a0847e6878874ce7e4b0ec3f56e5fbb8ebdb5992
-
- 10 Jan, 2023 1 commit
-
-
moto authored
Summary: filter graph does not fallback to `best_effort_timestamp`, thus applying filters (like changing fps) on videos without PTS values failed. This commit changes the behavior by overwriting the PTS values with best_effort_timestamp. Pull Request resolved: https://github.com/pytorch/audio/pull/2970 Reviewed By: YosuaMichael Differential Revision: D42425771 Pulled By: mthrok fbshipit-source-id: 7b7a033ea2ad89bb49d6e1663d35d377dab2aae9
-
- 30 Dec, 2022 1 commit
-
-
moto authored
Summary: This commit refactors and optimizes functions that converts AVFrames of `yuv420p` and `nv12` into PyTorch's Tensor. The performance is improved about 30%. 1. Reduce the number of intermediate Tensors allocated. 2. Replace 2 calls to `repeat_interleave` with `F::interpolate`. * (`F::interpolate` is about 5x faster than `repeat_interleave`. ) <details><summary>code</summary> ```bash #!/usr/bin/env bash set -e python -c """ import torch import torch.nn.functional as F a = torch.arange(49, dtype=torch.uint8).reshape(7, 7).clone() val1 = a.repeat_interleave(2, -1).repeat_interleave(2, -2) val2 = F.interpolate(a.view((1, 1, 7, 7, 1)), size=[14, 14, 1], mode=\"nearest\") print(torch.sum(torch.abs(val1 - val2[0, 0, :, :, 0]))) """ python3 -m timeit \ --setup """ import torch a = torch.arange(49, dtype=torch.uint8).reshape(7, 7).clone() """ \ """ a.repeat_interleave(2, -1).repeat_interleave(2, -2) """ python3 -m timeit \ --setup """ import torch import torch.nn.functional as F a = torch.arange(49, dtype=torch.uint8).reshape(7, 7).clone() """ \ """ F.interpolate(a.view((1, 1, 7, 7, 1)), size=[14, 14, 1], mode=\"nearest\") """ ``` </details> ``` tensor(0) 10000 loops, best of 5: 38.3 usec per loop 50000 loops, best of 5: 7.1 usec per loop ``` ## Benchmark Result <details><summary>code</summary> ```bash #!/usr/bin/env bash set -e mkdir -p tmp for ext in avi mp4; do for duration in 1 5 10 30 60; do printf "Testing ${ext} ${duration} [sec]\n" test_data="tmp/test_${duration}.${ext}" if [ ! -f "${test_data}" ]; then printf "Generating test data\n" ffmpeg -hide_banner -f lavfi -t ${duration} -i testsrc "${test_data}" > /dev/null 2>&1 fi python -m timeit \ --setup="from torchaudio.io import StreamReader" \ """ r = StreamReader(\"${test_data}\") r.add_basic_video_stream(frames_per_chunk=-1, format=\"yuv420p\") r.process_all_packets() r.pop_chunks() """ done done ``` </details> 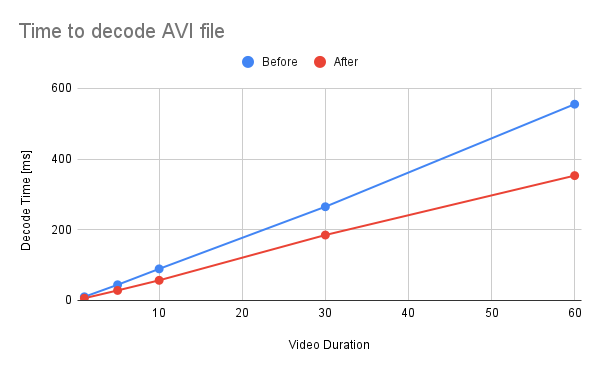 <details><summary>raw data</summary> Video Type - AVI Duration | Before | After -- | -- | -- 1 | 10.3 | 6.29 5 | 44.3 | 28.3 10 | 89.3 | 56.9 30 | 265 | 185 60 | 555 | 353 </details> 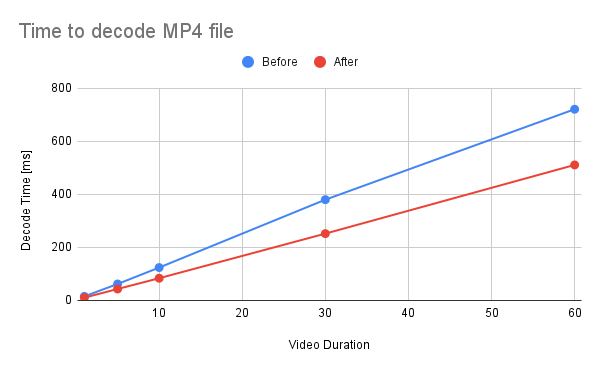 <details><summary>raw data</summary> Video Type - MP4 Duration | Before | After -- | -- | -- 1 | 15.3 | 10.5 5 | 62.1 | 43.2 10 | 124 | 83.8 30 | 380 | 252 60 | 721 | 511 </details> Pull Request resolved: https://github.com/pytorch/audio/pull/2945 Reviewed By: carolineechen Differential Revision: D42283269 Pulled By: mthrok fbshipit-source-id: 59840f943ff516b69ab8ad35fed7104c48a0bf0c
-
- 20 Dec, 2022 1 commit
-
-
moto authored
Summary: If the input video has invalid PTS, the current precise seek fails except when seeking into t=0. This commit updates the discard mechanism to fallback to `best_effort_timestamp` in such cases. `best_effort_timestamp` is just the number of frames went through decoder starting from the beginning of the file. This means if the input file is very long, but seeking towards the end of the file, the StreamReader still decodes all the frames. For videos with valid PTS, `best_effort_timestamp` should be same as `pts`. [[src](https://ffmpeg.org/doxygen/4.1/decode_8c.html#a8d86329cf58a4adbd24ac840d47730cf)] Pull Request resolved: https://github.com/pytorch/audio/pull/2916 Reviewed By: YosuaMichael Differential Revision: D42170204 Pulled By: mthrok fbshipit-source-id: 80c04dc376e0f427d41eb9feb44c251a1648a998
-
- 04 Nov, 2022 1 commit
-
-
moto authored
Summary: StreamWriter assumed that frame rate is always expressed as 1/something, which is a reasonable assumption. This commit fixes it by properly computing time_base from frame rate. Address https://github.com/pytorch/audio/issues/2830 Pull Request resolved: https://github.com/pytorch/audio/pull/2831 Reviewed By: carolineechen Differential Revision: D41036084 Pulled By: mthrok fbshipit-source-id: 805881d4cb221ab2c002563aefb986e30fb91609
-
- 31 Oct, 2022 1 commit
-
-
Joao Gomes authored
Summary: cc mthrok Implements precise seek and seek to any frame in torchaudio Pull Request resolved: https://github.com/pytorch/audio/pull/2737 Reviewed By: mthrok Differential Revision: D40546716 Pulled By: jdsgomes fbshipit-source-id: d37da7f55977337eb16a3c4df44ce8c3c102698e
-
- 25 Oct, 2022 1 commit
-
-
moto authored
Summary: Addresses https://github.com/pytorch/audio/issues/2790. Previously AVPacket objects had duration==0. `av_interleaved_write_frame` function was inferring the duration of packets by comparing them against the next ones but It could not infer the duration of the last packet, as there is no subsequent frame, thus was omitting it from the final data. This commit fixes it by explicitly setting packet duration = 1 (one frame) only for video. (audio AVPacket contains multiple samples, so it's different. To ensure the correctness for audio, the tests were added.) Pull Request resolved: https://github.com/pytorch/audio/pull/2789 Reviewed By: xiaohui-zhang Differential Revision: D40627439 Pulled By: mthrok fbshipit-source-id: 4d0d827bff518c017b115445e03bdf0bf1e68320
-
- 21 Sep, 2022 1 commit
-
-
Moto Hira authored
Summary: Pull Request resolved: https://github.com/pytorch/audio/pull/2694 This commit adds Tensor type as input to `StreamReader`. The Tensor is interpreted as byte string buffer. Reviewed By: hwangjeff Differential Revision: D39467630 fbshipit-source-id: 6369eed5e16fbb657568bf6bb80d703483d72f8e
-
- 01 Sep, 2022 1 commit
-
-
moto authored
Summary: Pull Request resolved: https://github.com/pytorch/audio/pull/2648 Reviewed By: nateanl Differential Revision: D38976874 Pulled By: mthrok fbshipit-source-id: 0541dea2a633d97000b4b8609ff6b83f6b82c864
-
- 24 Aug, 2022 1 commit
-
-
moto authored
Summary: This commit adds FFmpeg-based encoder StreamWriter class. StreamWriter is pretty much the opposite of StreamReader class, and it supports; * Encoding audio / still image / video * Exporting to local file / streaming protocol / devices etc... * File-like object support (in later commit) * HW video encoding (in later commit) See also: https://fburl.com/gslide/z85kn5a9 (Meta internal) Pull Request resolved: https://github.com/pytorch/audio/pull/2628 Reviewed By: nateanl Differential Revision: D38816650 Pulled By: mthrok fbshipit-source-id: a9343b0d55755e186971dc96fb86eb52daa003c8
-
- 07 Jul, 2022 1 commit
-
-
moto authored
Summary: This commit add support for `"yuv444p"` type as output format of StreamReader. Pull Request resolved: https://github.com/pytorch/audio/pull/2516 Reviewed By: hwangjeff Differential Revision: D37659715 Pulled By: mthrok fbshipit-source-id: eae9b5590d8f138a6ebf3808c08adfe068f11a2b
-
- 28 Jun, 2022 1 commit
-
-
moto authored
Summary: Small clean up in ffmpeg binding code. 1. Make `get_option_dict` and `clean_up_dict` public utility 2. Merge the exception into `clean_up_dict` 3. Get rid of custom string join function and use `c10::Join`. Pull Request resolved: https://github.com/pytorch/audio/pull/2507 Reviewed By: hwangjeff Differential Revision: D37466022 Pulled By: mthrok fbshipit-source-id: 44b769ac6ff1ab20e6d6ae086cd1447deacb5969
-
- 27 Jun, 2022 2 commits
-
-
moto authored
Summary: Pull Request resolved: https://github.com/pytorch/audio/pull/2511 Reviewed By: nateanl Differential Revision: D37461021 Pulled By: mthrok fbshipit-source-id: 6f894c02bbefc5afda0f9584d26ad785f7c71ee4
-
moto authored
Summary: Follow-up of https://github.com/pytorch/audio/issues/2464. Add utility function to fetch the versions of FFmpeg. Pull Request resolved: https://github.com/pytorch/audio/pull/2467 Reviewed By: carolineechen Differential Revision: D37028006 Pulled By: mthrok fbshipit-source-id: 72adce1e6b43985760ce55b715b0e59af5244fdb
-
- 08 Jun, 2022 2 commits
-
-
moto authored
Summary: In https://github.com/pytorch/audio/issues/2461, `metadata` field was added to StreamInfo. However, the value attached to this new field was source-level metadata, while each stream can have different metadata. * source level metadata [AVFormatContext->metadata](https://ffmpeg.org/doxygen/4.1/structAVFormatContext.html#a3019a56080ed2e3297ff25bc2ff88adf) * stream level metadata [AVFormatContext->streams[]->metadata](https://ffmpeg.org/doxygen/4.1/structAVStream.html#a50d250a128a3da9ce3d135e84213fb82) This commit moves source level metadata to dedicated method, `get_metadata`, and fix the stream-level metadata to report stream metadata. Pull Request resolved: https://github.com/pytorch/audio/pull/2464 Reviewed By: hwangjeff, xiaohui-zhang Differential Revision: D36995452 Pulled By: mthrok fbshipit-source-id: 534be1f7feb07790a0ce8624c336cdb7b65a8697
-
moto authored
Summary: Add metadata, such as ID3 (https://github.com/pytorch/audio/commit/7d98db0567cb60fabcc173949b8c08e3a3487ac2)tag to `StreamReaderSourceAudioStream`. Pull Request resolved: https://github.com/pytorch/audio/pull/2461 Reviewed By: hwangjeff Differential Revision: D36985656 Pulled By: mthrok fbshipit-source-id: e66f9e6e980eb57c378cc643a8979b6b7813dae7
-
- 01 Jun, 2022 1 commit
-
-
moto authored
Summary: * Update error messages * Update audio stream tests Pull Request resolved: https://github.com/pytorch/audio/pull/2429 Reviewed By: carolineechen, nateanl Differential Revision: D36812769 Pulled By: mthrok fbshipit-source-id: 7a51d0c4dbae558010d2e59412333e4a7f00d318
-
- 29 May, 2022 1 commit
-
-
moto authored
Summary: Add num_frames and bits_per_sample to match with the current `torchaudio.info` capability. Pull Request resolved: https://github.com/pytorch/audio/pull/2418 Reviewed By: carolineechen Differential Revision: D36749077 Pulled By: mthrok fbshipit-source-id: 7b368ee993cf5ed63ff2f53c9e3b1f50fcce7713
-
- 21 May, 2022 1 commit
-
-
moto authored
Summary: This commit adds file-like object support to Streaming API. ## Features - File-like objects are expected to implement `read(self, n)`. - Additionally `seek(self, offset, whence)` is used if available. - Without `seek` method, some formats cannot be decoded properly. - To work around this, one can use the existing `decoder` option to tell what decoder it should use. - The set of `decoder` and `decoder_option` arguments were added to `add_basic_[audio|video]_stream` method, similar to `add_[audio|video]_stream`. - So as to have the arguments common to both audio and video in front of the rest of the arguments, the order of the arguments are changed. - Also `dtype` and `format` arguments were changed to make them consistent across audio/video methods. ## Code structure The approach is very similar to how file-like object is supported in sox-based I/O. In Streaming API if the input src is string, it is passed to the implementation bound with TorchBind, if the src has `read` attribute, it is passed to the same implementation bound via PyBind 11.  ## Refactoring involved - Extracted to https://github.com/pytorch/audio/issues/2402 - Some implementation in the original TorchBind surface layer is converted to Wrapper class so that they can be re-used from PyBind11 bindings. The wrapper class serves to simplify the binding. - `add_basic_[audio|video]_stream` methods were removed from C++ layer as it was just constructing string and passing it to `add_[audio|video]_stream` method, which is simpler to do in Python. - The original core Streamer implementation kept the use of types in `c10` namespace minimum. All the `c10::optional` and `c10::Dict` were converted to the equivalents of `std` at binding layer. But since they work fine with PyBind11, Streamer core methods deal them directly. ## TODO: - [x] Check if it is possible to stream MP4 (yuv420p) from S3 and directly decode (with/without HW decoding). Pull Request resolved: https://github.com/pytorch/audio/pull/2400 Reviewed By: carolineechen Differential Revision: D36520073 Pulled By: mthrok fbshipit-source-id: a11d981bbe99b1ff0cc356e46264ac8e76614bc6
-






