- 01 Apr, 2023 1 commit
-
-
moto authored
Summary: This commit adds a new feature AudioEffector, which can be used to apply various effects and codecs to waveforms in Tensor. Under the hood it uses StreamWriter and StreamReader to apply filters and encode/decode. This is going to replace the deprecated `apply_codec` and `apply_sox_effect_tensor` functions. It can also perform online, chunk-by-chunk filtering. Tutorial to follow. closes https://github.com/pytorch/audio/issues/3161 Pull Request resolved: https://github.com/pytorch/audio/pull/3163 Reviewed By: hwangjeff Differential Revision: D44576660 Pulled By: mthrok fbshipit-source-id: 2c5cc87082ab431315d29d56d6ac9efaf4cf7aeb
-
- 31 Mar, 2023 3 commits
-
-
Nouran Ali authored
Summary: Pull Request resolved: https://github.com/pytorch/audio/pull/3222 Reviewed By: nateanl Differential Revision: D44539424 Pulled By: mthrok fbshipit-source-id: 8fbcb5f9918c9930c939bcd448493fa5cf604545
-
Jeff Hwang authored
Summary: Pull Request resolved: https://github.com/pytorch/audio/pull/3223 Each `StreamProcessor` is responsible for processing a source stream. In the case where we support packet passthrough, `StreamProcessor`'s choice of decoder is irrelevant as no decoding is performed. Currently, however, `StreamProcessor` requires decoder params and fixes a decoder at construction time. To accommodate this future packet passthrough use case, this PR decouples the construction of `StreamProcessor` from the configuration of the decoder that it uses. Reviewed By: mthrok Differential Revision: D44554934 fbshipit-source-id: 1d1a89015e1181b71dfb95c928de4fc3ec6f63b6
-
moto authored
Summary: This commit adds the equivalent of `qscale` option in FFmpeg to StreamWriter.CodecConfig. `qscale` enables variable bit rate. The following figure illustrates the difference between currently available configs. From top to bottom; original, `compression_level=1`, `compression_level=9`, `bit_rate=192k`, `bit_rate=8k`, `qscale=9`, `qscale=1`. 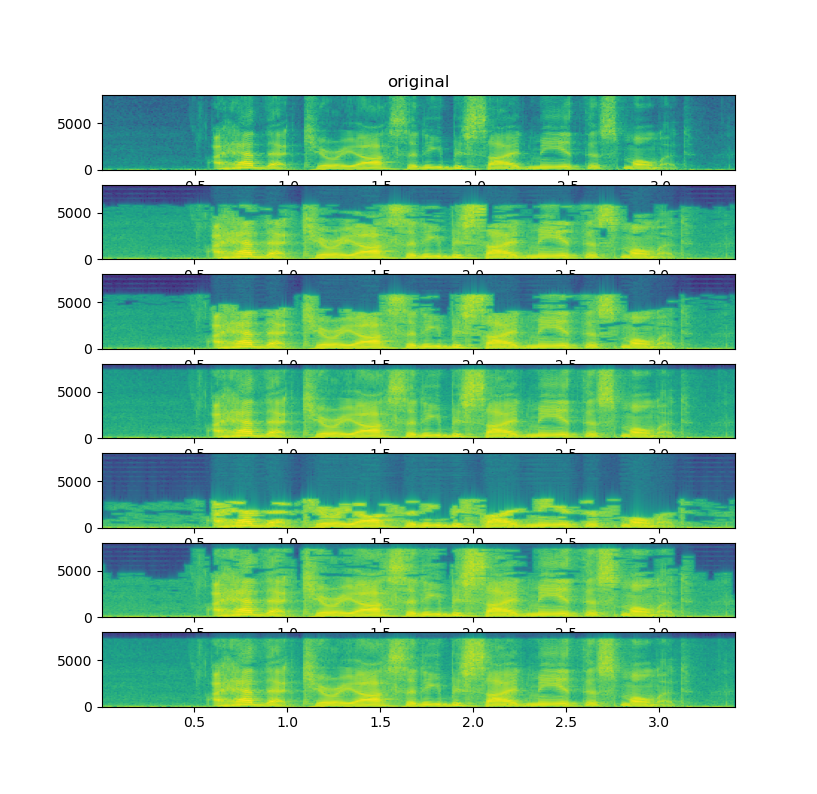 Pull Request resolved: https://github.com/pytorch/audio/pull/3224 Reviewed By: hwangjeff Differential Revision: D44563633 Pulled By: mthrok fbshipit-source-id: ff74cd803b5abf1222f087e3e46ba7d81a35f672
-
- 30 Mar, 2023 2 commits
-
-
moto authored
Summary: This commit adds support for changing the spec of media (such as sample rate, #channels, image size and frame rate) on-the-fly at encoding time. The motivation behind this addition is that certain media formats support only limited number of spec, and it is cumbersome to require client code to change the spec every time. For example, OPUS supports only 48kHz sampling rate, and vorbis only supports stereo. To make it easy to work with media of different formats, this commit makes it so that anything that's not compatible with the format is automatically converted, and allows users to specify the override. Notable implementation detail is that, for sample format and pixel format, the default value of encoder has higher precedent to source value, while for other attributes like sample rate and #channels, the source value has higher precedent as long as they are supported. Pull Request resolved: https://github.com/pytorch/audio/pull/3207 Reviewed By: nateanl Differential Revision: D44439622 Pulled By: mthrok fbshipit-source-id: 09524f201d485d201150481884a3e9e4d2aab081
-
moto authored
Summary: This commit adds `num_channels` argument, which allows one to change the number of channels on-the-fly. Pull Request resolved: https://github.com/pytorch/audio/pull/3216 Reviewed By: hwangjeff Differential Revision: D44516925 Pulled By: mthrok fbshipit-source-id: 3e5a11b3fdbb19071f712a8148e27aff60341df3
-
- 29 Mar, 2023 3 commits
-
-
Moto Hira authored
Summary: Pull Request resolved: https://github.com/pytorch/audio/pull/3217 This commit removes some tests for file-like object from StreamWriter test. The rational is that testing things after the output file is opened are same for file-like object and regular files. Things like filter-graph and encoder format change does not affect how the encoded bynary are written. Reviewed By: hwangjeff Differential Revision: D44518626 fbshipit-source-id: 821ec20deca92e5e5c85bf4d47997eed51735374
-
moto authored
Summary: In https://github.com/pytorch/audio/issues/3178, a mechanism to cache HW device context was introduced. This commit applies the reuse in StreamWriter, so that when using GPU video decoding and encoding, they are shared. This gives back about 250 - 300 MB of GPU memory. --- Q: What is HW device context? From https://ffmpeg.org/doxygen/4.1/structAVHWDeviceContext.html#details > This struct aggregates all the (hardware/vendor-specific) "high-level" state, i.e. > > state that is not tied to a concrete processing configuration. E.g., in an API that supports hardware-accelerated encoding and decoding, this struct will (if possible) wrap the state that is common to both encoding and decoding and from which specific instances of encoders or decoders can be derived. Pull Request resolved: https://github.com/pytorch/audio/pull/3215 Reviewed By: nateanl Differential Revision: D44504051 Pulled By: mthrok fbshipit-source-id: 77579cdc8bd9e9b8a218e3f29031d091cda83860
-
moto authored
Summary: There is a part of StreamWriter tutorial that warns about corrupted AAC audio output, but this is no longer relevant thus this commit deletes it. Pull Request resolved: https://github.com/pytorch/audio/pull/3214 Reviewed By: nateanl Differential Revision: D44504030 Pulled By: mthrok fbshipit-source-id: 4d26d582e9fb87d4e6fa674c05fe3192bc223eef
-
- 28 Mar, 2023 4 commits
-
-
nateanl authored
Summary: Fix https://github.com/pytorch/audio/issues/3211 Pull Request resolved: https://github.com/pytorch/audio/pull/3212 Reviewed By: mthrok Differential Revision: D44472523 Pulled By: nateanl fbshipit-source-id: eb519b0045e7518ad13863a53271745a80d89a21
-
moto authored
Summary: Pull Request resolved: https://github.com/pytorch/audio/pull/3194 Reviewed By: hwangjeff Differential Revision: D44283910 Pulled By: mthrok fbshipit-source-id: 49125724896bf7190ec27f056b6bfef260019f8e
-
Moto Hira authored
Summary: Pull Request resolved: https://github.com/pytorch/audio/pull/3208 StreamReader/Writer is evolving and the number of arguments in add_stream methods are growing. This commit adds default values to these arguments. Reviewed By: hwangjeff Differential Revision: D44447263 fbshipit-source-id: e1c09956d78c2b4738bbeafb88195ec8e8ca5513
-
Moto Hira authored
Summary: Pull Request resolved: https://github.com/pytorch/audio/pull/3209 The previous code prints out the uninitialized variable when invalid HW acceleration is provided. This commit fixes it. Reviewed By: hwangjeff Differential Revision: D44449715 fbshipit-source-id: 8b76cfc27816d5ea9fbc2bc37a3148f09a8ed6ed
-
- 27 Mar, 2023 2 commits
-
-
hwangjeff authored
Summary: For `StreamWriter`, * Renames arg `config` to codec_config`. * Renames struct `EncodingConfig` and dataclass `EncodeConfig` to `CodecConfig`. * Adds docstrings for arg codec_config`. * Updates `chunk` to `frames` in `write_*_chunk` methods. Pull Request resolved: https://github.com/pytorch/audio/pull/3203 Reviewed By: mthrok Differential Revision: D44350153 Pulled By: hwangjeff fbshipit-source-id: 1b940b1366a43ec0565c362bfcbf62744088b343
-
Moto Hira authored
Summary: Pull Request resolved: https://github.com/pytorch/audio/pull/3205 This commit refactors the initialization of EncodeProcess. Interface-wise, the signature of the constructor of EncodeProcess has made simpler just to take rvalues of its components, and the initialization of the components have been moved to helper functions. Implementat-wise, the order that the components are initialized is revised, and the source of initialization parameters is also revised. For example, the original implementation first creates AVCodecContext, and passes it around to create the other components. This relied on an assumption that parameters AVCodecContext has (such as image size and sample rate) are same as the source data. This is not always right, and as we will introduce custom filter graph and allow on-the-fly transform of rates and dimensions, it will become even less correct. The new initialization constructs source AVFrame, TensorConverter and FilterGraph from source attributes. This makes it easy to introduce on-the-fly transform. Reviewed By: nateanl Differential Revision: D44360650 fbshipit-source-id: bf0e77dc1a5a40fc8e9870c50d07339d812762e8
-
- 25 Mar, 2023 1 commit
-
-
moto authored
Summary: Some audio encoders expect specific, exact number of samples described as in `AVCodecContext.frame_size`. The `AVFrame.nb_samples` is set for the frames passed to `AVFilterGraph`, but frames coming out of the graph do not necessarily have the same numbr of frames. This causes issues with encoding OPUS (among others). This commit fixes it by inserting `asetnsamples` to filter graph if a fixed number of samples is requested. Note: It turned out that FFmpeg 4.1 has issue with OPUS encoding. It does not properly discard some sample. We should probably move the minimum required FFmpeg to 4.2, but I am not sure if we can enforce it via ABI. Work around will be to issue an warning if encoding OPUS with 4.1. (follow-up) Pull Request resolved: https://github.com/pytorch/audio/pull/3204 Reviewed By: nateanl Differential Revision: D44374668 Pulled By: mthrok fbshipit-source-id: 10ef5333dc0677dfb83c8e40b78edd8ded1b21dc
-
- 23 Mar, 2023 6 commits
-
-
Scott Wolchok authored
Summary: Pull Request resolved: https://github.com/pytorch/audio/pull/3198 Fixes build after following diff to use F14 maps in pickler internally. Reviewed By: mthrok Differential Revision: D44098387 fbshipit-source-id: 9777517369d9a3f2599b273c04bf4a014f411f12
-
moto authored
Summary: With the support of CUDA filter in https://github.com/pytorch/audio/issues/3183, it is now possible to change the pixel format of CUDA frame. This commit adds conversion for YUV444P format. Pull Request resolved: https://github.com/pytorch/audio/pull/3199 Reviewed By: hwangjeff Differential Revision: D44323928 Pulled By: mthrok fbshipit-source-id: 6d9b205e7235df5f21e7d3e06166b3a169f1ae9f
-
Zhaoheng Ni authored
Summary: The PR adds the pre-trained pipeline for `SquimSubjective` model which predicts MOS score for speech enhancement task. Pull Request resolved: https://github.com/pytorch/audio/pull/3197 Reviewed By: mthrok Differential Revision: D44313244 Pulled By: nateanl fbshipit-source-id: 905095ff77006e9f441faa826fc25d9d8681e8aa
-
moto authored
Summary: StreamReader behaves differently when dealing with YUV formats. It implicitly converts the image format to YUV444P because otherwise image planes do not have the same shape and it is not possible to express it as a regular PyTorch Tensor with dedicated dimension for each color channel. This is commit adds warnings to such conversions. Pull Request resolved: https://github.com/pytorch/audio/pull/3201 Reviewed By: nateanl Differential Revision: D44311017 Pulled By: mthrok fbshipit-source-id: 73a02a19c013c0263f349e1f3a3603e3d3eddb6a
-
Zhaoheng Ni authored
Summary: In the nightly documentation, "Prototype Factory Functions of Beta Models" is listed as an individual section, which is not correct. <img width="310" alt="image" src="https://user-images.githubusercontent.com/8653221/227262349-604b99e8-1b20-4b19-9711-81e7b6cfa62e.png"> After the PR, the section outlook is fixed <img width="285" alt="image" src="https://user-images.githubusercontent.com/8653221/227262893-b938d81e-6c4b-432a-833c-95981bca5e65.png"> Pull Request resolved: https://github.com/pytorch/audio/pull/3202 Reviewed By: mthrok Differential Revision: D44338663 Pulled By: nateanl fbshipit-source-id: 09f591b9e4af66ebf34fb423bd5c30d4630f0b88
-
moto authored
Summary: OPUS encoder and VORBIS encoders require "strict=experimental" flags. This commit enables it automatically. The rational behind of it is typically we care if we can encode these formats at all and not how they are encoded. (This might be concern when these encoder becomes more mature on FFmpeg side and providing flags would result in weird behavior) Also when writing high-level functions that uses StreamWriter, if we do not set these flags, then these high-level functions have to add new options that should be passed down to StreamWriter, which turned out to be very painful in https://github.com/pytorch/audio/issues/3163 Pull Request resolved: https://github.com/pytorch/audio/pull/3192 Reviewed By: nateanl Differential Revision: D44275089 Pulled By: mthrok fbshipit-source-id: 74a757b4b7fc8467c8c88ffcb54fbaf89d6e4384
-
- 22 Mar, 2023 2 commits
-
-
moto authored
Summary: Follow up of https://github.com/pytorch/audio/pull/3083 Pull Request resolved: https://github.com/pytorch/audio/pull/3196 Reviewed By: nateanl Differential Revision: D44308940 Pulled By: mthrok fbshipit-source-id: e3ef27656e74c28ae78b767517d8e0ba3a9ac4a6
-
atalman authored
Summary: Adopt ffmpeg build to be executed from github actions for windows Tested by manually invoking this script: ``` c:\actions-runner\_work\test-infra\test-infra\pytorch\audio Chocolatey v1.2.1 Installing the following packages: msys2 By installing, you accept licenses for the packages. msys2 v20230318.0.0 already installed. Use --force to reinstall, specify a version to install, or try upgrade. Chocolatey installed 0/1 packages. See the log for details (C:\ProgramData\chocolatey\logs\chocolatey.log). Warnings: - msys2 - msys2 v20230318.0.0 already installed. Use --force to reinstall, specify a version to install, or try upgrade. Did you know the proceeds of Pro (and some proceeds from other licensed editions) go into bettering the community infrastructure? Your support ensures an active community, keeps Chocolatey tip-top, plus it nets you some awesome features! https://chocolatey.org/compare warning: base-devel-2022.12-2 is up to date -- skipping warning: mingw-w64-x86_64-binutils-2.40-2 is up to date -- skipping warning: mingw-w64-x86_64-crt-git-10.0.0.r234.g283e5b23a-1 is up to date -- skipping warning: mingw-w64-x86_64-gcc-12.2.0-10 is up to date -- skipping warning: mingw-w64-x86_64-gcc-ada-12.2.0-10 is up to date -- skipping warning: mingw-w64-x86_64-gcc-fortran-12.2.0-10 is up to date -- skipping warning: mingw-w64-x86_64-gcc-libgfortran-12.2.0-10 is up to date -- skipping warning: mingw-w64-x86_64-gcc-libs-12.2.0-10 is up to date -- skipping warning: mingw-w64-x86_64-gcc-objc-12.2.0-10 is up to date -- skipping warning: mingw-w64-x86_64-gdb-13.1-3 is up to date -- skipping warning: mingw-w64-x86_64-gdb-multiarch-13.1-3 is up to date -- skipping warning: mingw-w64-x86_64-headers-git-10.0.0.r234.g283e5b23a-1 is up to date -- skipping warning: mingw-w64-x86_64-libgccjit-12.2.0-10 is up to date -- skipping warning: mingw-w64-x86_64-libmangle-git-10.0.0.r234.g283e5b23a-1 is up to date -- skipping warning: mingw-w64-x86_64-libwinpthread-git-10.0.0.r234.g283e5b23a-1 is up to date -- skipping warning: mingw-w64-x86_64-make-4.4-2 is up to date -- skipping warning: mingw-w64-x86_64-pkgconf-1~1.8.0-2 is up to date -- skipping warning: mingw-w64-x86_64-tools-git-10.0.0.r234.g283e5b23a-1 is up to date -- skipping warning: mingw-w64-x86_64-winpthreads-git-10.0.0.r234.g283e5b23a-1 is up to date -- skipping warning: mingw-w64-x86_64-winstorecompat-git-10.0.0.r234.g283e5b23a-1 is up to date -- skipping warning: diffutils-3.9-1 is up to date -- skipping there is nothing to do runneruser@EC2AMAZ-S19AQ2Q C:\actions-runner\_work\test-infra\test-infra\pytorch\audio>set VC_VERSION_LOWER=16 runneruser@EC2AMAZ-S19AQ2Q C:\actions-runner\_work\test-infra\test-infra\pytorch\audio>set VC_VERSION_UPPER=17 runneruser@EC2AMAZ-S19AQ2Q C:\actions-runner\_work\test-infra\test-infra\pytorch\audio>for /F "usebackq tokens=*" %i in (`"C:\Program F iles (x86)\Microsoft Visual Studio\Installer\vswhere.exe" -legacy -products * -version [16,17) -property installationPath`) do (if exis t "%i" if exist "%i\VC\Auxiliary\Build\vcvarsall.bat" ( set "VS15INSTALLDIR=%i" set "VS15VCVARSALL=%i\VC\Auxiliary\Build\vcvarsall.bat" goto vswhere ) ) runneruser@EC2AMAZ-S19AQ2Q C:\actions-runner\_work\test-infra\test-infra\pytorch\audio>(if exist "C:\Program Files (x86)\Microsoft Visu al Studio\2019\BuildTools" if exist "C:\Program Files (x86)\Microsoft Visual Studio\2019\BuildTools\VC\Auxiliary\Build\vcvarsall.bat" ( set "VS15INSTALLDIR=C:\Program Files (x86)\Microsoft Visual Studio\2019\BuildTools" set "VS15VCVARSALL=C:\Program Files (x86)\Microsoft Visual Studio\2019\BuildTools\VC\Auxiliary\Build\vcvarsall.bat" goto vswhere ) ) runneruser@EC2AMAZ-S19AQ2Q C:\actions-runner\_work\test-infra\test-infra\pytorch\audio>if "" == "" (call "C:\Program Files (x86)\Micros oft Visual Studio\2019\BuildTools\VC\Auxiliary\Build\vcvarsall.bat" x64 || exit /b 1 ) else (call "C:\Program Files (x86)\Microsoft Visual Studio\2019\BuildTools\VC\Auxiliary\Build\vcvarsall.bat" x64 || exit /b 1 ) ********************************************************************** ** Visual Studio 2019 Developer Command Prompt v16.8.6 ** Copyright (c) 2020 Microsoft Corporation ********************************************************************** [vcvarsall.bat] Environment initialized for: 'x64' runneruser@EC2AMAZ-S19AQ2Q C:\actions-runner\_work\test-infra\test-infra\pytorch\audio>set DISTUTILS_USE_SDK=1 runneruser@EC2AMAZ-S19AQ2Q C:\actions-runner\_work\test-infra\test-infra\pytorch\audio>set args=bash runneruser@EC2AMAZ-S19AQ2Q C:\actions-runner\_work\test-infra\test-infra\pytorch\audio>shift runneruser@EC2AMAZ-S19AQ2Q C:\actions-runner\_work\test-infra\test-infra\pytorch\audio>if [./packaging/ffmpeg/build.sh] == [] goto done runneruser@EC2AMAZ-S19AQ2Q C:\actions-runner\_work\test-infra\test-infra\pytorch\audio>set args=bash ./packaging/ffmpeg/build.sh runneruser@EC2AMAZ-S19AQ2Q C:\actions-runner\_work\test-infra\test-infra\pytorch\audio>shift runneruser@EC2AMAZ-S19AQ2Q C:\actions-runner\_work\test-infra\test-infra\pytorch\audio>goto start runneruser@EC2AMAZ-S19AQ2Q C:\actions-runner\_work\test-infra\test-infra\pytorch\audio>if [] == [] goto done runneruser@EC2AMAZ-S19AQ2Q C:\actions-runner\_work\test-infra\test-infra\pytorch\audio>if "bash ./packaging/ffmpeg/build.sh" == "" ( echo Usage: vc_env_helper.bat [command] [args] echo e.g. vc_env_helper.bat cl /c test.cpp ) runneruser@EC2AMAZ-S19AQ2Q C:\actions-runner\_work\test-infra\test-infra\pytorch\audio>bash ./packaging/ffmpeg/build.sh || exit /b 1 + prefix=C:/actions-runner/_work/test-infra/test-infra/pytorch/audio/third_party/ffmpeg + args= + [[ msys == \m\s\y\s ]] + args=--toolchain=msvc ++ mktemp -d -t ffmpeg-build.XXXXXXXXXX + build_dir=/tmp/ffmpeg-build.bVdKugGnTP + trap 'cleanup $?' EXIT + cd /tmp/ffmpeg-build.bVdKugGnTP + curl -LsS -o ffmpeg.tar.gz https://github.com/FFmpeg/FFmpeg/archive/refs/tags/n4.1.8.tar.gz + tar -xf ffmpeg.tar.gz --strip-components 1 + ./configure --prefix=C:/actions-runner/_work/test-infra/test-infra/pytorch/audio/third_party/ffmpeg --disable-all --disable-everythin g --disable-programs --disable-doc --disable-debug --disable-autodetect --disable-x86asm --disable-iconv --disable-encoders --disable-d ecoders --disable-hwaccels --disable-muxers --disable-demuxers --disable-parsers --disable-bsfs --disable-protocols --disable-devices - -disable-filters --disable-asm --disable-static --enable-shared --enable-rpath --enable-pic --enable-avcodec --enable-avdevice --enable -avfilter --enable-avformat --enable-avutil --toolchain=msvc install prefix C:/actions-runner/_work/test-infra/test-infra/pytorch/audio/third_party/ffmpeg source path . C compiler cl C library msvcrt ARCH c (generic) big-endian no runtime cpu detection yes debug symbols no strip symbols no optimize for size no optimizations yes static no shared yes postprocessing support no network support yes threading support w32threads safe bitstream reader yes texi2html enabled no perl enabled yes pod2man enabled yes makeinfo enabled yes makeinfo supports HTML yes External libraries: External libraries providing hardware acceleration: Libraries: avcodec avdevice avfilter avformat avutil Programs: Enabled decoders: Enabled encoders: Enabled hwaccels: Enabled parsers: Enabled demuxers: Enabled muxers: Enabled protocols: Enabled filters: Enabled bsfs: null Enabled indevs: Enabled outdevs: License: LGPL version 2.1 or later + make -j install GEN libavdevice/libavdevice.version GEN libavfilter/libavfilter.version GEN libavformat/libavformat.version GEN libavcodec/libavcodec.version GEN libavutil/libavutil.version INSTALL doc/examples/avio_dir_cmd.c INSTALL doc/examples/avio_reading.c INSTALL doc/examples/decode_audio.c INSTALL doc/examples/decode_video.c INSTALL doc/examples/demuxing_decoding.c INSTALL doc/examples/encode_audio.c INSTALL doc/examples/encode_video.c INSTALL doc/examples/extract_mvs.c INSTALL doc/examples/filter_audio.c INSTALL doc/examples/filtering_audio.c INSTALL doc/examples/filtering_video.c INSTALL doc/examples/http_multiclient.c INSTALL doc/examples/hw_decode.c INSTALL doc/examples/metadata.c INSTALL doc/examples/muxing.c INSTALL doc/examples/qsvdec.c INSTALL doc/examples/remuxing.c INSTALL doc/examples/resampling_audio.c INSTALL doc/examples/scaling_video.c INSTALL doc/examples/transcode_aac.c INSTALL doc/examples/transcoding.c INSTALL doc/examples/vaapi_encode.c INSTALL doc/examples/vaapi_transcode.c INSTALL doc/examples/README INSTALL doc/examples/Makefile CC libavdevice/avdevice.o CC libavdevice/reverse.o avdevice.c reverse.c libavdevice/avdevice.c(88): warning C4996: 'av_oformat_next': was declared deprecated libavdevice/avdevice.c(92): warning C4996: 'av_iformat_next': was declared deprecated CC libavdevice/utils.o INSTALL doc/examples/avio_dir_cmd.c INSTALL doc/examples/avio_reading.c INSTALL doc/examples/decode_audio.c INSTALL doc/examples/decode_video.c INSTALL doc/examples/demuxing_decoding.c CC libavdevice/alldevices.o INSTALL doc/examples/encode_audio.c INSTALL doc/examples/encode_video.c INSTALL doc/examples/extract_mvs.c INSTALL doc/examples/filter_audio.c INSTALL doc/examples/filtering_audio.c INSTALL doc/examples/filtering_video.c INSTALL doc/examples/http_multiclient.c INSTALL doc/examples/hw_decode.c INSTALL doc/examples/metadata.c INSTALL doc/examples/muxing.c INSTALL doc/examples/qsvdec.c INSTALL doc/examples/remuxing.c INSTALL doc/examples/resampling_audio.c INSTALL doc/examples/scaling_video.c INSTALL doc/examples/transcode_aac.c INSTALL doc/examples/transcoding.c INSTALL doc/examples/vaapi_encode.c INSTALL doc/examples/vaapi_transcode.c INSTALL doc/examples/README INSTALL doc/examples/Makefile utils.c CC libavformat/dump.o CC libavformat/allformats.o alldevices.c dump.c allformats.c CC libavformat/id3v1.o CC libavformat/golomb_tab.o CC libavformat/metadata.o CC libavformat/log2_tab.o id3v1.c golomb_tab.c log2_tab.c CC libavdevice/file_open.o metadata.c CC libavformat/protocols.o file_open.c CC libavformat/avio.o CC libavformat/format.o protocols.c format.c libavformat/protocols.c(99): warning C4090: '=': different 'const' qualifiers avio.c CC libavformat/file_open.o CC libavformat/cutils.o CC libavcodec/ac3_parser.o file_open.c CC libavformat/aviobuf.o libavformat/format.c(308): warning C4090: 'function': different 'const' qualifiers aviobuf.c cutils.c ac3_parser.c C:\tools\msys64\tmp\ffmpeg-build.bVdKugGnTP\libavcodec\get_bits.h(481): warning C4101: 're_cache': unreferenced local variable CC libavformat/qtpalette.o libavformat/avio.c(113): warning C4267: 'initializing': conversion from 'size_t' to 'int', possible loss of dataCC libavformat/id3 v2.o libavformat/avio.c(276): warning C4090: 'function': different 'const' qualifiers libavformat/avio.c(281): warning C4090: 'function': different 'const' qualifiers libavformat/avio.c(285): warning C4090: 'function': different 'const' qualifiers CC libavcodec/allcodecs.o CC libavformat/network.o CC libavcodec/avpacket.o id3v2.c qtpalette.c CC libavcodec/adts_parser.o CC libavcodec/avpicture.o avpacket.c allcodecs.c network.c adts_parser.c libavformat/aviobuf.c(389): warning C4267: '+=': conversion from 'size_t' to 'int', possible loss of data libavformat/aviobuf.c(1230): warning C4267: 'function': conversion from 'size_t' to 'int', possible loss of data libavformat/aviobuf.c(1265): warning C4267: 'function': conversion from 'size_t' to 'int', possible loss of data CC libavcodec/avdct.o libavcodec/avpacket.c(131): warning C4267: 'function': conversion from 'size_t' to 'int', possible loss of data libavcodec/avpacket.c(307): warning C4267: '=': conversion from 'size_t' to 'int', possible loss of data libavcodec/avpacket.c(321): warning C4267: '=': conversion from 'size_t' to 'int', possible loss of data libavcodec/avpacket.c(512): warning C4267: '=': conversion from 'size_t' to 'int', possible loss of data avpicture.c C:\tools\msys64\tmp\ffmpeg-build.bVdKugGnTP\libavcodec\get_bits.h(481): warning C4101: 're_cache': unreferenced local variable CC libavformat/mux.o CC libavformat/utils.o CC libavcodec/bitstream_filter.o avdct.c libavformat/id3v2.c(347): warning C4090: 'function': different 'const' qualifiers CC libavformat/os_support.o mux.c utils.c bitstream_filter.c CC libavformat/options.o libavformat/network.c(340): warning C4267: 'function': conversion from 'size_t' to 'socklen_t', possible loss of data libavformat/network.c(377): warning C4267: 'function': conversion from 'size_t' to 'int', possible loss of data libavformat/network.c(428): warning C4267: 'function': conversion from 'size_t' to 'socklen_t', possible loss of data libavformat/network.c(485): warning C4267: 'function': conversion from 'size_t' to 'socklen_t', possible loss of dataCC libavcodec/bits tream_filters.o libavformat/network.c(500): warning C4267: 'function': conversion from 'size_t' to 'socklen_t', possible loss of dataCC libavcodec/d3d1 1va.o libavformat/network.c(537): warning C4267: '=': conversion from 'size_t' to 'int', possible loss of data libavformat/network.c(538): warning C4267: '=': conversion from 'size_t' to 'int', possible loss of data CC libavformat/url.o os_support.c CC libavformat/sdp.o CC libavformat/riff.o CC libavcodec/bsf.o url.c d3d11va.c options.c bitstream_filters.c CC libavcodec/bitstream.o CC libavcodec/dirac.o libavformat/utils.c(225): warning C4996: 'av_codec_next': was declared deprecated riff.c sdp.c bsf.c libavformat/utils.c(4716): warning C4267: '=': conversion from 'size_t' to 'int', possible loss of data libavformat/utils.c(5520): warning C4267: '=': conversion from 'size_t' to 'int', possible loss of data libavformat/utils.c(5539): warning C4267: '=': conversion from 'size_t' to 'int', possible loss of data dirac.c C:\tools\msys64\tmp\ffmpeg-build.bVdKugGnTP\libavcodec\get_bits.h(481): warning C4101: 're_cache': unreferenced local variable bitstream.c libavcodec/bitstream.c(125): warning C4334: '<<': result of 32-bit shift implicitly converted to 64 bits (was 64-bit shift intended?) C:\tools\msys64\tmp\ffmpeg-build.bVdKugGnTP\libavcodec\get_bits.h(481): warning C4101: 're_cache': unreferenced local variable CC libavcodec/fdctdsp.o CC libavcodec/codec_desc.o libavformat/options.c(64): warning C4996: 'av_iformat_next': was declared deprecated libavformat/options.c(69): warning C4996: 'av_oformat_next': was declared deprecated fdctdsp.c libavformat/options.c(73): warning C4996: 'av_iformat_next': was declared deprecatedCC libavcodec/encode.o libavformat/options.c(77): warning C4996: 'av_oformat_next': was declared deprecated CC libavcodec/faanidct.o libavformat/url.c(77): warning C4267: 'return': conversion from 'size_t' to 'int', possible loss of data codec_desc.c encode.c CC libavcodec/faandct.o CC libavcodec/decode.o CC libavcodec/dv_profile.o faanidct.c libavcodec/encode.c(365): warning C4996: 'avcodec_encode_video2': was declared deprecated libavcodec/encode.c(368): warning C4996: 'avcodec_encode_audio2': was declared deprecated faandct.c dv_profile.c decode.c CC libavcodec/idctdsp.o libavcodec/decode.c(845): warning C4267: '=': conversion from 'size_t' to 'int', possible loss of data idctdsp.c CC libavcodec/imgconvert.o CC libavcodec/jfdctint.o CC libavcodec/jfdctfst.o jfdctint.c imgconvert.c jfdctfst.c CC libavcodec/jni.o CC libavcodec/jrevdct.o CC libavcodec/log2_tab.o CC libavcodec/mediacodec.o jrevdct.c jni.c log2_tab.c mediacodec.c CC libavcodec/file_open.o CC libavcodec/null_bsf.o CC libavcodec/options.o CC libavcodec/mathtables.o CC libavcodec/mjpegenc_huffman.o options.c file_open.c null_bsf.c mathtables.c mjpegenc_huffman.c libavcodec/options.c(61): warning C4996: 'av_codec_next': was declared deprecated libavcodec/options.c(66): warning C4996: 'av_codec_next': was declared deprecated CC libavcodec/parser.o CC libavcodec/profiles.o CC libavcodec/mpeg12framerate.o CC libavcodec/pthread.o parser.c profiles.c mpeg12framerate.c pthread.c C:\tools\msys64\tmp\ffmpeg-build.bVdKugGnTP\libavcodec\get_bits.h(481): warning C4101: 're_cache': unreferenced local variable CC libavcodec/simple_idct.o CC libavcodec/raw.o CC libavcodec/pthread_slice.o CC libavcodec/qsv_api.o simple_idct.c CC libavcodec/reverse.o raw.c CC libavcodec/xiph.o pthread_slice.c CC libavcodec/vorbis_parser.o qsv_api.c reverse.c CC libavcodec/parsers.o xiph.c vorbis_parser.c CC libavcodec/pthread_frame.o C:\tools\msys64\tmp\ffmpeg-build.bVdKugGnTP\libavcodec\get_bits.h(481): warning C4101: 're_cache': unreferenced local variable parsers.c pthread_frame.c CC libavutil/aes.o aes.c CC libavutil/audio_fifo.o CC libavutil/base64.o CC libavutil/avstring.o CC libavutil/aes_ctr.o audio_fifo.c CC libavcodec/utils.o avstring.c base64.c CC libavutil/bprint.o CC libavutil/blowfish.o CC libavutil/adler32.o libavutil/avstring.c(246): warning C4267: 'function': conversion from 'size_t' to 'unsigned int', possible loss of data libavutil/avstring.c(248): warning C4267: 'function': conversion from 'size_t' to 'unsigned int', possible loss of dataaes_ctr.c libavutil/avstring.c(352): warning C4267: '=': conversion from 'size_t' to 'int', possible loss of data CC libavutil/camellia.o utils.c blowfish.c adler32.c bprint.c CC libavutil/buffer.o CC libavutil/color_utils.o CC libavutil/channel_layout.o .\libavutil/mem_internal.h(42): warning C4267: '=': conversion from 'size_t' to 'unsigned int', possible loss of data libavutil/bprint.c(190): warning C4267: '=': conversion from 'size_t' to 'unsigned int', possible loss of data libavutil/bprint.c(215): warning C4267: 'function': conversion from 'size_t' to 'unsigned int', possible loss of data camellia.c buffer.c color_utils.c CC libavutil/cast5.o channel_layout.c C:\tools\msys64\tmp\ffmpeg-build.bVdKugGnTP\libavcodec\get_bits.h(481): warning C4101: 're_cache': unreferenced local variable libavcodec/utils.c(1361): warning C4267: 'function': conversion from 'size_t' to 'int', possible loss of data libavcodec/utils.c(2034): warning C4267: '=': conversion from 'size_t' to 'int', possible loss of data cast5.c CC libavutil/cpu.o cpu.c CC libavutil/crc.o CC libavutil/dict.o CC libavutil/des.o des.c crc.c dict.c CC libavutil/downmix_info.o libavutil/cpu.c(185): warning C4090: 'function': different 'const' qualifiers libavutil/cpu.c(264): warning C4090: 'function': different 'const' qualifiers CC libavutil/display.o downmix_info.c CC libavutil/error.o CC libavutil/eval.o CC libavutil/encryption_info.o CC libavutil/fixed_dsp.o display.c CC libavutil/hmac.o error.c eval.c encryption_info.c fixed_dsp.c hmac.c CC libavutil/hash.o libavutil/fixed_dsp.c(161): warning C4028: formal parameter 1 different from declaration libavutil/fixed_dsp.c(161): warning C4028: formal parameter 2 different from declaration CC libavutil/fifo.o CC libavutil/hwcontext.o CC libavutil/float_dsp.o hash.c fifo.c CC libavutil/file.o CC libavutil/imgutils.o hwcontext.c float_dsp.c CC libavutil/integer.o CC libavutil/frame.o file.c imgutils.c CC libavutil/file_open.o CC libavutil/intmath.o CC libavutil/lfg.o libavutil/imgutils.c(527): warning C4267: 'function': conversion from 'size_t' to 'int', possible loss of data libavutil/imgutils.c(527): warning C4267: 'function': conversion from 'size_t' to 'int', possible loss of data frame.c integer.c file_open.c libavutil/frame.c(760): warning C4090: 'function': different 'const' qualifiers libavutil/frame.c(903): warning C4267: '-=': conversion from 'size_t' to 'int', possible loss of data libavutil/frame.c(904): warning C4267: '-=': conversion from 'size_t' to 'int', possible loss of data libavutil/frame.c(915): warning C4267: 'function': conversion from 'size_t' to 'int', possible loss of data libavutil/frame.c(919): warning C4267: 'function': conversion from 'size_t' to 'int', possible loss of data libavutil/frame.c(937): warning C4267: '-=': conversion from 'size_t' to 'int', possible loss of data libavutil/frame.c(938): warning C4267: '-=': conversion from 'size_t' to 'int', possible loss of data intmath.c lfg.c CC libavutil/lls.o lls.c CC libavutil/log2_tab.o CC libavutil/mastering_display_metadata.o CC libavutil/mathematics.o log2_tab.c CC libavutil/mem.o CC libavutil/md5.o mastering_display_metadata.c mathematics.c mem.c md5.c CC libavutil/murmur3.o CC libavutil/log.o C:\tools\msys64\tmp\ffmpeg-build.bVdKugGnTP\libavutil\mem_internal.h(42): warning C4267: '=': conversion from 'size_t' to 'unsigned int ', possible loss of data libavutil/mem.c(495): warning C4267: '=': conversion from 'size_t' to 'unsigned int', possible loss of data murmur3.c log.c libavutil/md5.c(103): warning C4101: 'i': unreferenced local variableCC libavutil/parseutils.o CC libavutil/opt.o CC libavutil/pixelutils.o parseutils.c CC libavutil/pixdesc.o CC libavutil/reverse.o CC libavutil/rational.o libavutil/parseutils.c(367): warning C4267: '=': conversion from 'size_t' to 'int', possible loss of data libavutil/parseutils.c(372): warning C4267: '=': conversion from 'size_t' to 'int', possible loss of data libavutil/parseutils.c(479): warning C4267: 'initializing': conversion from 'size_t' to 'int', possible loss of data opt.c pixelutils.c CC libavutil/rc4.o pixdesc.c rational.c reverse.c libavutil/opt.c(189): warning C4267: '=': conversion from 'size_t' to 'int', possible loss of data libavutil/opt.c(440): warning C4133: 'function': incompatible types - from 'AVPixelFormat (__cdecl *)(const char *)' to 'int (__cdecl * )(const char *)' libavutil/opt.c(446): warning C4133: 'function': incompatible types - from 'AVSampleFormat (__cdecl *)(const char *)' to 'int (__cdecl *)(const char *)' libavutil/opt.c(847): warning C4267: '=': conversion from 'size_t' to 'int', possible loss of data libavutil/opt.c(982): warning C4133: 'function': incompatible types - from 'AVPixelFormat *' to 'int *' libavutil/opt.c(987): warning C4133: 'function': incompatible types - from 'AVSampleFormat *' to 'int *' libavutil/opt.c(1632): warning C4090: 'function': different 'const' qualifiers libavutil/opt.c(1675): warning C4090: 'function': different 'const' qualifiers libavutil/opt.c(1877): warning C4090: 'function': different 'const' qualifiers libavutil/pixdesc.c(2551): warning C4267: '=': conversion from 'size_t' to 'int', possible loss of data rc4.c CC libavutil/ripemd.o CC libavutil/sha.o CC libavutil/samplefmt.o ripemd.c samplefmt.c CC libavutil/sha512.o sha.c libavutil/ripemd.c(136): warning C4101: 't': unreferenced local variable libavutil/ripemd.c(193): warning C4101: 't': unreferenced local variable libavutil/ripemd.c(318): warning C4101: 't': unreferenced local variable libavutil/ripemd.c(390): warning C4101: 't': unreferenced local variable sha512.c CC libavutil/stereo3d.o CC libavutil/xtea.o CC libavutil/slicethread.o CC libavutil/threadmessage.o stereo3d.c xtea.c CC libavutil/timecode.o slicethread.c CC libavutil/xga_font_data.o CC libavutil/utils.o threadmessage.c timecode.c CC libavutil/tree.o utils.c CC libavutil/random_seed.o xga_font_data.c CC libavutil/twofish.o tree.c CC libavutil/time.o CC libavutil/tea.o CC libavutil/spherical.o random_seed.c time.c twofish.c tea.c spherical.c CC libavfilter/avfiltergraph.o CC libavfilter/audio.o avfiltergraph.c GEN libavdevice/libavdevice.pc audio.c CC libavfilter/buffersrc.o CC libavfilter/fifo.o buffersrc.c CC libavfilter/allfilters.o fifo.c CC libavfilter/log2_tab.o CC libavfilter/framequeue.o CC libavfilter/framepool.o CC libavfilter/graphdump.o CC libavfilter/drawutils.o allfilters.c CC libavfilter/formats.o INSTALL libavdevice/avdevice.h INSTALL libavdevice/version.h log2_tab.c framepool.c framequeue.c graphdump.c CC libavfilter/buffersink.o drawutils.c formats.c CC libavfilter/transform.o CC libavfilter/avfilter.o libavfilter/framequeue.c(143): warning C4267: '-=': conversion from 'size_t' to 'int', possible loss of data libavfilter/framequeue.c(144): warning C4267: '-=': conversion from 'size_t' to 'int', possible loss of data libavfilter/graphdump.c(79): warning C4267: '=': conversion from 'size_t' to 'unsigned int', possible loss of data libavfilter/graphdump.c(86): warning C4267: '=': conversion from 'size_t' to 'unsigned int', possible loss of data libavfilter/graphdump.c(108): warning C4267: '=': conversion from 'size_t' to 'unsigned int', possible loss of data libavfilter/graphdump.c(72): warning C4267: 'initializing': conversion from 'size_t' to 'unsigned int', possible loss of data libavfilter/graphdump.c(73): warning C4267: 'initializing': conversion from 'size_t' to 'unsigned int', possible loss of data libavfilter/graphdump.c(77): warning C4267: 'initializing': conversion from 'size_t' to 'unsigned int', possible loss of data libavfilter/graphdump.c(84): warning C4267: 'initializing': conversion from 'size_t' to 'unsigned int', possible loss of data libavfilter/graphdump.c(133): warning C4267: 'initializing': conversion from 'size_t' to 'unsigned int', possible loss of data buffersink.c GEN libavfilter/libavfilter.pc CC libavfilter/pthread.o CC libavfilter/graphparser.o libavfilter/buffersink.c(137): warning C4133: '=': incompatible types - from 'const int *' to 'const AVPixelFormat *' transform.c avfilter.c CC libavfilter/video.o pthread.c graphparser.c GEN libavformat/libavformat.pc INSTALL libavfilter/avfilter.h INSTALL libavfilter/buffersink.h INSTALL libavfilter/buffersrc.h INSTALL libavfilter/version.h video.c GEN libavcodec/libavcodec.pc libavfilter/avfilter.c(51): warning C4101: 'buf': unreferenced local variable INSTALL libavformat/avformat.h INSTALL libavformat/avio.h INSTALL libavformat/version.h INSTALL libavcodec/ac3_parser.h INSTALL libavcodec/adts_parser.h INSTALL libavcodec/avcodec.h INSTALL libavcodec/avdct.h INSTALL libavcodec/avfft.h INSTALL libavcodec/d3d11va.h INSTALL libavcodec/dirac.h INSTALL libavcodec/dv_profile.h INSTALL libavcodec/dxva2.h INSTALL libavcodec/jni.h INSTALL libavcodec/mediacodec.h INSTALL libavcodec/qsv.h INSTALL libavcodec/vaapi.h INSTALL libavcodec/vdpau.h INSTALL libavcodec/version.h INSTALL libavcodec/videotoolbox.h INSTALL libavcodec/vorbis_parser.h INSTALL libavcodec/xvmc.h GEN libavutil/libavutil.pc GEN libavdevice/libavdevice.ver INSTALL libavutil/adler32.h INSTALL libavutil/aes.h INSTALL libavutil/aes_ctr.h INSTALL libavutil/attributes.h INSTALL libavutil/audio_fifo.h INSTALL libavutil/avassert.h INSTALL libavutil/avstring.h INSTALL libavutil/avutil.h INSTALL libavutil/base64.h INSTALL libavutil/blowfish.h INSTALL libavutil/bprint.h INSTALL libavutil/bswap.h INSTALL libavutil/buffer.h INSTALL libavutil/cast5.h INSTALL libavutil/camellia.h INSTALL libavutil/channel_layout.h INSTALL libavutil/common.h INSTALL libavutil/cpu.h INSTALL libavutil/crc.h INSTALL libavutil/des.h INSTALL libavutil/dict.h INSTALL libavutil/display.h INSTALL libavutil/downmix_info.h INSTALL libavutil/encryption_info.h INSTALL libavutil/error.h INSTALL libavutil/eval.h INSTALL libavutil/fifo.h INSTALL libavutil/file.h INSTALL libavutil/frame.h INSTALL libavutil/hash.h INSTALL libavutil/hmac.h INSTALL libavutil/hwcontext.h INSTALL libavutil/hwcontext_cuda.h INSTALL libavutil/hwcontext_d3d11va.h INSTALL libavutil/hwcontext_drm.h INSTALL libavutil/hwcontext_dxva2.h INSTALL libavutil/hwcontext_qsv.h INSTALL libavutil/hwcontext_mediacodec.h INSTALL libavutil/hwcontext_vaapi.h INSTALL libavutil/hwcontext_videotoolbox.h INSTALL libavutil/hwcontext_vdpau.h INSTALL libavutil/imgutils.h INSTALL libavutil/intfloat.h INSTALL libavutil/intreadwrite.h INSTALL libavutil/lfg.h INSTALL libavutil/log.h INSTALL libavutil/macros.h INSTALL libavutil/mathematics.h INSTALL libavutil/mastering_display_metadata.h INSTALL libavutil/md5.h INSTALL libavutil/mem.h INSTALL libavutil/motion_vector.h INSTALL libavutil/murmur3.h INSTALL libavutil/opt.h INSTALL libavutil/parseutils.h INSTALL libavutil/pixdesc.h INSTALL libavutil/pixelutils.h INSTALL libavutil/pixfmt.h INSTALL libavutil/random_seed.h INSTALL libavutil/rc4.h INSTALL libavutil/rational.h INSTALL libavutil/replaygain.h INSTALL libavutil/ripemd.h INSTALL libavutil/samplefmt.h INSTALL libavutil/sha.h INSTALL libavutil/sha512.h INSTALL libavutil/spherical.h INSTALL libavutil/stereo3d.h INSTALL libavutil/threadmessage.h INSTALL libavutil/time.h INSTALL libavutil/timecode.h INSTALL libavutil/timestamp.h INSTALL libavutil/tree.h INSTALL libavutil/twofish.h INSTALL libavutil/version.h INSTALL libavutil/xtea.h INSTALL libavutil/tea.h INSTALL libavutil/avconfig.h INSTALL libavutil/ffversion.h GEN libavformat/libavformat.ver GEN libavcodec/libavcodec.ver GEN libavutil/libavutil.ver GEN libavfilter/libavfilter.ver EXTERN_PREFIX="" ./compat/windows/makedef libavutil/libavutil.ver libavutil/adler32.o libavutil/aes.o libavutil/aes_ctr.o libavutil/aud io_fifo.o libavutil/avstring.o libavutil/base64.o libavutil/blowfish.o libavutil/bprint.o libavutil/buffer.o libavutil/camellia.o libav util/cast5.o libavutil/channel_layout.o libavutil/color_utils.o libavutil/cpu.o libavutil/crc.o libavutil/des.o libavutil/dict.o libavu til/display.o libavutil/downmix_info.o libavutil/encryption_info.o libavutil/error.o libavutil/eval.o libavutil/fifo.o libavutil/file.o libavutil/file_open.o libavutil/fixed_dsp.o libavutil/float_dsp.o libavutil/frame.o libavutil/hash.o libavutil/hmac.o libavutil/hwcont ext.o libavutil/imgutils.o libavutil/integer.o libavutil/intmath.o libavutil/lfg.o libavutil/lls.o libavutil/log.o libavutil/log2_tab.o libavutil/mastering_display_metadata.o libavutil/mathematics.o libavutil/md5.o libavutil/mem.o libavutil/murmur3.o libavutil/opt.o lib avutil/parseutils.o libavutil/pixdesc.o libavutil/pixelutils.o libavutil/random_seed.o libavutil/rational.o libavutil/rc4.o libavutil/r everse.o libavutil/ripemd.o libavutil/samplefmt.o libavutil/sha.o libavutil/sha512.o libavutil/slicethread.o libavutil/spherical.o liba vutil/stereo3d.o libavutil/tea.o libavutil/threadmessage.o libavutil/time.o libavutil/timecode.o libavutil/tree.o libavutil/twofish.o l ibavutil/utils.o libavutil/xga_font_data.o libavutil/xtea.o > libavutil/avutil-56.def INSTALL libavdevice/libavdevice.pc INSTALL libavfilter/libavfilter.pc INSTALL libavformat/libavformat.pc INSTALL libavcodec/libavcodec.pc INSTALL libavutil/libavutil.pc LD libavutil/avutil-56.dll LINK : warning LNK4044: unrecognized option '/Wl,-rpath,C:/actions-runner/_work/test-infra/test-infra/pytorch/audio/third_party/ffmpeg/ lib'; ignored Creating library libavutil/avutil.lib and object libavutil/avutil.exp EXTERN_PREFIX="" ./compat/windows/makedef libavcodec/libavcodec.ver libavcodec/ac3_parser.o libavcodec/adts_parser.o libavcodec/allcode cs.o libavcodec/avdct.o libavcodec/avpacket.o libavcodec/avpicture.o libavcodec/bitstream.o libavcodec/bitstream_filter.o libavcodec/bi tstream_filters.o libavcodec/bsf.o libavcodec/codec_desc.o libavcodec/d3d11va.o libavcodec/decode.o libavcodec/dirac.o libavcodec/dv_pr ofile.o libavcodec/encode.o libavcodec/faandct.o libavcodec/faanidct.o libavcodec/fdctdsp.o libavcodec/file_open.o libavcodec/idctdsp.o libavcodec/imgconvert.o libavcodec/jfdctfst.o libavcodec/jfdctint.o libavcodec/jni.o libavcodec/jrevdct.o libavcodec/log2_tab.o libavc odec/mathtables.o libavcodec/mediacodec.o libavcodec/mjpegenc_huffman.o libavcodec/mpeg12framerate.o libavcodec/null_bsf.o libavcodec/o ptions.o libavcodec/parser.o libavcodec/parsers.o libavcodec/profiles.o libavcodec/pthread.o libavcodec/pthread_frame.o libavcodec/pthr ead_slice.o libavcodec/qsv_api.o libavcodec/raw.o libavcodec/reverse.o libavcodec/simple_idct.o libavcodec/utils.o libavcodec/vorbis_pa rser.o libavcodec/xiph.o > libavcodec/avcodec-58.def EXTERN_PREFIX="" ./compat/windows/makedef libavfilter/libavfilter.ver libavfilter/allfilters.o libavfilter/audio.o libavfilter/avfilter .o libavfilter/avfiltergraph.o libavfilter/buffersink.o libavfilter/buffersrc.o libavfilter/drawutils.o libavfilter/fifo.o libavfilter/ formats.o libavfilter/framepool.o libavfilter/framequeue.o libavfilter/graphdump.o libavfilter/graphparser.o libavfilter/log2_tab.o lib avfilter/pthread.o libavfilter/transform.o libavfilter/video.o > libavfilter/avfilter-7.def INSTALL libavutil/avutil.dll STRIP install-libavutil-shared skipping strip C:/actions-runner/_work/test-infra/test-infra/pytorch/audio/third_party/ffmpeg/bin/avutil-56.dll INSTALL libavutil/avutil.dll INSTALL libavutil/avutil.dll LD libavcodec/avcodec-58.dll LINK : warning LNK4044: unrecognized option '/Wl,-rpath,C:/actions-runner/_work/test-infra/test-infra/pytorch/audio/third_party/ffmpeg/ lib'; ignored Creating library libavcodec/avcodec.lib and object libavcodec/avcodec.exp LD libavfilter/avfilter-7.dll LINK : warning LNK4044: unrecognized option '/Wl,-rpath,C:/actions-runner/_work/test-infra/test-infra/pytorch/audio/third_party/ffmpeg/ EXTERN_PREFIX="" ./compat/windows/makedef libavdevice/libavdevice.ver libavdevice/alldevices.o libavdevice/avdevice.o libavdevice/file_opeEXTERN_PREFIX="" ./compat/windows/makedef libavdevice/libavdevice.ver libavdevice/alldevices.o libavdevice/avdevice.o libavdevice/file_openNSTALL libavformat/avformat.dll .o libavdevice/reverse.o libavdevice/utils.o > libavdevice/avdevice-58.def INSTALL libavformat/avformat.dll EXTERN_PREFIX="" ./compat/windows/makedef libavdevice/libavdevice.ver libavdevice/alldevices.o libavdevice/avdevice.o libavdevice/file_ope n.o libavdevice/reverse.o libavdevice/utils.o > libavdevice/avdevice-58.def INSTALL libavformat/avformat.dll STRIP install-libavformat-shared skipping strip C:/actions-runner/_work/test-infra/test-infra/pytorch/audio/third_party/ffmpeg/bin/avformat-58.dll INSTALL libavformat/avformat.dll INSTALL libavformat/avformat.dll LD libavdevice/avdevice-58.dll LINK : warning LNK4044: unrecognized option '/Wl,-rpath,C:/actions-runner/_work/test-infra/test-infra/pytorch/audio/third_party/ffmpeg/lib '; ignored Creating library libavdevice/avdevice.lib and object libavdevice/avdevice.exp INSTALL libavdevice/avdevice.dll STRIP install-libavdevice-shared skipping strip C:/actions-runner/_work/test-infra/test-infra/pytorch/audio/third_party/ffmpeg/bin/avdevice-58.dll INSTALL libavdevice/avdevice.dll INSTALL libavdevice/avdevice.dll + ls C:/actions-runner/_work/test-infra/test-infra/pytorch/audio/third_party/ffmpeg/bin C:/actions-runner/_work/test-infra/test-infra/pytorch/audio/third_party/ffmpeg/include C:/actions-runner/_work/test-infra/test-infra/pytorch/audio/third_party/ffmpeg/lib C:/actions-runner/ _work/test-infra/test-infra/pytorch/audio/third_party/ffmpeg/share 'C:/actions-runner/_work/test-infra/test-infra/pytorch/audio/third_party/ffmpeg/bin': avcodec.lib avdevice.lib avfilter.lib avformat.lib avutil.lib avcodec-58.dll avdevice-58.dll avfilter-7.dll avformat-58.dll avutil-56.dll 'C:/actions-runner/_work/test-infra/test-infra/pytorch/audio/third_party/ffmpeg/include': libavcodec libavdevice libavfilter libavformat libavutil 'C:/actions-runner/_work/test-infra/test-infra/pytorch/audio/third_party/ffmpeg/lib': avcodec-58.def avdevice-58.def avfilter-7.def avformat-58.def avutil-56.def pkgconfig 'C:/actions-runner/_work/test-infra/test-infra/pytorch/audio/third_party/ffmpeg/share': ffmpeg ++ uname + [[ MINGW64_NT-10.0-17763 == Darwin ]] + cleanup 0 + rm -rf /tmp/ffmpeg-build.bVdKugGnTP runneruser@EC2AMAZ-S19AQ2Q c:\actions-runner\_work\test-infra\test-infra\pytorch\audio> ``` Pull Request resolved: https://github.com/pytorch/audio/pull/3193 Reviewed By: DanilBaibak Differential Revision: D44294838 Pulled By: atalman fbshipit-source-id: 7522d329537daf99dff8a12db8afdeeffaa2138c
-
- 21 Mar, 2023 6 commits
-
-
Zhaoheng Ni authored
Summary: Add model architecture and factory functions for `SquimSubjective` which predicts subjective evaluation metric scores (e.g. MOS) for speech enhancement task. Pull Request resolved: https://github.com/pytorch/audio/pull/3189 Reviewed By: mthrok Differential Revision: D44267255 Pulled By: nateanl fbshipit-source-id: f8060398b14c625b38ea1bb2417f61aeaec3f1db
-
moto authored
Summary: To suppress local warning of flake8 <120 Pull Request resolved: https://github.com/pytorch/audio/pull/3191 Reviewed By: nateanl Differential Revision: D44263027 Pulled By: mthrok fbshipit-source-id: b3e48dba21fc5c9813f07e624a93f38a68956c6e
-
moto authored
Summary: oscillator_bank perform cumsum on large number of elements and typically, float32 is not good enough. This PR makes the cumsum operation default to float64, so that the result is better. Pull Request resolved: https://github.com/pytorch/audio/pull/3083 Reviewed By: nateanl Differential Revision: D44257182 Pulled By: mthrok fbshipit-source-id: a38a465d33559a415e8c744e61292f4fab64b0e1
-
moto authored
Summary: Fixes the issue https://app.circleci.com/pipelines/github/pytorch/audio/15501/workflows/ebaa2c87-efc3-44a8-b86d-5a3b99870588/jobs/1164478 Pull Request resolved: https://github.com/pytorch/audio/pull/3190 Reviewed By: nateanl Differential Revision: D44263564 Pulled By: mthrok fbshipit-source-id: e610be3a91888c859ebdc31081b2d1ba9d61737e
-
Zhaoheng Ni authored
Summary: In librosa 0.10 release, positional arguments are deprecated (see https://github.com/librosa/librosa/pull/1521 for details). The PR fixes the HiFiGAN unit test by using keyword arguments for `librosa.filters.mel` function. Pull Request resolved: https://github.com/pytorch/audio/pull/3185 Reviewed By: mthrok Differential Revision: D44218852 Pulled By: nateanl fbshipit-source-id: 6171f7bec6a2144917697c1d640e701d95ec60d7
-
Moto Hira authored
Summary: Pull Request resolved: https://github.com/pytorch/audio/pull/3188 Refactor the process after decoding in StreamRader. The post-decode process consists of three parts, 1. preprocessing using FilterGraph 2. conversion to Tensor 3. store in Buffer The FilterGraph class is a thin wrapper around AVFilterGraph structure from FFmpeg and it is agnostic to media type. However Tensor conversion and buffering consists of bunch of different logics. Currently, conversion process is abstracted away with template, i.e. `template<typename Conversion> Buffer`, and the whole process is implemeted in Sink class which consists of `FilterGraph` and `Buffer` which internally contains Conversion logic, even though conversion logic and buffer have nothing in common and beter logically separated. The new implementation replaces `Sink` class with `IPostDecodeProcess` interface, which contains the three components. The different post process is implemented as a template argument of the actual implementation, i.e. ```c++ template<typename Converter, typename Buffer> ProcessImpl : IPostDecodeProcess ``` and stored as `unique_ptr<IPostDecodeProcess>` on `StreamProcessor`. ([functionoid pattern](https://isocpp.org/wiki/faq/pointers-to-members#functionoids), which allows to eliminate all the branching based on the media format.) Note: This implementation was not possible at the initial version of StreamReader, as there was no way of knowing the media attributes coming out of `AVFilterGraph`. https://github.com/pytorch/audio/pull/3155 and https://github.com/pytorch/audio/pull/3183 added features to parse it properly, so we can finally make the post processing strongly-typed. Reviewed By: hwangjeff Differential Revision: D44242647 fbshipit-source-id: 96b8c6c72a2b8af4fa86a9b02292c65078ee265b
-
- 20 Mar, 2023 3 commits
-
-
Moto Hira authored
Summary: Pull Request resolved: https://github.com/pytorch/audio/pull/3184 Tweak internals of StreamReader 1. Pass time_base to Buffer class so that * no need to pass frame_duration separately * Conversion of PTS to double type can be delayed until when it's popped 2. Merge `get_output_timebase` method into `get_output_stream_info`. 3. If filter description is not provided, fill in null filter at top-level StreamReader 4. Expose filer and filter description from Sink class to get rid of wrapper get methods. Reviewed By: nateanl Differential Revision: D44207976 fbshipit-source-id: f25ac9be69c9897e9dcec0c6e978f29b83b166e8
-
Moto Hira authored
Summary: Pull Request resolved: https://github.com/pytorch/audio/pull/3186 Fix the GPU memory leak introduced in https://github.com/pytorch/audio/pull/3183 The HW frames context is owned by AVCodecContext. The removed `av_buffer_ref` call increased the ferenrence counting unnecessarily, and prevented AVCodecContext from feeing the resource. (Note: this ignores all push blocking failures!) Reviewed By: nateanl Differential Revision: D44231876 fbshipit-source-id: 9be2c33049dd02a3fa82a85271de7fb62e5b09ea
-
moto authored
Summary: This commit adds CUDA frame support to FilterGraph It initializes and attaches CUDA frames context to FilterGraph, so that CUDA frames can be processed in FilterGraph. As a result, it enables 1. CUDA filter support such as `scale_cuda` 2. Properly retrieve the pixel format coming out of FilterGraph when CUDA HW acceleration is enabled. (currently it is reported as "cuda") Resolves https://github.com/pytorch/audio/issues/3159 Pull Request resolved: https://github.com/pytorch/audio/pull/3183 Reviewed By: hwangjeff Differential Revision: D44183722 Pulled By: mthrok fbshipit-source-id: 522d21039c361ddfaa87fa89cf49c19d210ac62f
-
- 17 Mar, 2023 4 commits
-
-
moto authored
Summary: TODO: add cache release Pull Request resolved: https://github.com/pytorch/audio/pull/3178 Reviewed By: hwangjeff Differential Revision: D44136275 Pulled By: mthrok fbshipit-source-id: 4eaf646fe17a469e8bbbdf43441d5532f9f8461d
-
moto authored
Summary: Pull Request resolved: https://github.com/pytorch/audio/pull/3181 Reviewed By: nateanl Differential Revision: D44167788 Pulled By: mthrok fbshipit-source-id: 375293df836456adc40020d323efbc0aebc60d83
-
moto authored
Summary: Pull Request resolved: https://github.com/pytorch/audio/pull/3182 Reviewed By: nateanl Differential Revision: D44167810 Pulled By: mthrok fbshipit-source-id: 6ecbae54224ef7ba32835e4006aa5f2dc16b9acb
-
moto authored
Summary: Adds config object `EncodingConfig` and modifies `StreamWriter` to allow for passing in additional encoder configuration parameters, e.g. bit rate and compression level. Pull Request resolved: https://github.com/pytorch/audio/pull/3179 Pull Request resolved: https://github.com/pytorch/audio/pull/3164 Reviewed By: mthrok Differential Revision: D43861413 Pulled By: hwangjeff fbshipit-source-id: c1682cb2f6e682ab6f1a506511d2be7c7b254161
-
- 16 Mar, 2023 2 commits
-
-
jiyuntu-eero authored
Summary: Fix https://github.com/pytorch/audio/issues/3166. In `get_trellis` method, the index of blank symbol is regarded as 0 by default. It should be changed to `blank_id`. Pull Request resolved: https://github.com/pytorch/audio/pull/3172 Reviewed By: mthrok Differential Revision: D44090889 Pulled By: nateanl fbshipit-source-id: d119f4ded895d31aeefd59f8d975224870100264
-
moto authored
Summary: Currently, when the Buffer converts AVFrame* to torch::Tensor, it checks the format at each time a frame is passed, and perform the conversion. This commit changes it so that the conversion operation is pre-instantiated at the time outside stream is configured. It introduces Converter implementations for various formats, and use template to embed them in Buffer class. This way, branching like if/switch are eliminated from decoding path. Pull Request resolved: https://github.com/pytorch/audio/pull/3170 Reviewed By: xiaohui-zhang Differential Revision: D44048293 Pulled By: mthrok fbshipit-source-id: 30d8b240a5695d7513f499ce17853f2f0ffcab9f
-
- 15 Mar, 2023 1 commit
-
-
Carl Parker authored
Summary: - Boldface the version-selection UX and increase size by three percent. - Add text to breadcrumbs to indicate version and stability. - New `breadcrumbs.html` in `_templates` overrides Sphinx version. I create a new variable in `conf.py`, **version_stable**, which has the version number for the most-recent stable release. I define this variable in the **html_context** dictionary so that it is visible to the templates. I use this approach because I was not able to find any other way of discerning the current stable release during the build. Note that the `versions.html` file--which identifies the current stable release--appears to be available only in the **gh-pages** branch and so it is not available at build time. However, this means that someone will need to update `conf.py` whenever the current stable release changes. Pull Request resolved: https://github.com/pytorch/audio/pull/3167 Reviewed By: mthrok Differential Revision: D44112224 Pulled By: carljparker fbshipit-source-id: e76f5cb6734a784d161342964459577aa9b64cac
-









