- 17 Mar, 2023 1 commit
-
-
moto authored
Summary: Adds config object `EncodingConfig` and modifies `StreamWriter` to allow for passing in additional encoder configuration parameters, e.g. bit rate and compression level. Pull Request resolved: https://github.com/pytorch/audio/pull/3179 Pull Request resolved: https://github.com/pytorch/audio/pull/3164 Reviewed By: mthrok Differential Revision: D43861413 Pulled By: hwangjeff fbshipit-source-id: c1682cb2f6e682ab6f1a506511d2be7c7b254161
-
- 15 Mar, 2023 1 commit
-
-
Carl Parker authored
Summary: - Boldface the version-selection UX and increase size by three percent. - Add text to breadcrumbs to indicate version and stability. - New `breadcrumbs.html` in `_templates` overrides Sphinx version. I create a new variable in `conf.py`, **version_stable**, which has the version number for the most-recent stable release. I define this variable in the **html_context** dictionary so that it is visible to the templates. I use this approach because I was not able to find any other way of discerning the current stable release during the build. Note that the `versions.html` file--which identifies the current stable release--appears to be available only in the **gh-pages** branch and so it is not available at build time. However, this means that someone will need to update `conf.py` whenever the current stable release changes. Pull Request resolved: https://github.com/pytorch/audio/pull/3167 Reviewed By: mthrok Differential Revision: D44112224 Pulled By: carljparker fbshipit-source-id: e76f5cb6734a784d161342964459577aa9b64cac
-
- 14 Mar, 2023 2 commits
-
-
hwangjeff authored
Summary: Adds documentation that introduces forthcoming I/O backend revision and provides enablement directions for the current release. Doc pages: https://output.circle-artifacts.com/output/job/9c0e5a49-eaf4-404c-b910-ca1b18bb289b/artifacts/0/docs/torchaudio.html Pull Request resolved: https://github.com/pytorch/audio/pull/3147 Reviewed By: mthrok Differential Revision: D43824019 Pulled By: hwangjeff fbshipit-source-id: ad21d60c7e8f69f64859c56a8ca75735ddc22e40
-
Zhaoheng Ni authored
Summary: Add `2.0.0` release to the compatibility matrix Pull Request resolved: https://github.com/pytorch/audio/pull/3168 Reviewed By: mthrok Differential Revision: D44059197 Pulled By: nateanl fbshipit-source-id: a2830d059be90eddeab72b30e85cdfc393369bf8
-
- 08 Mar, 2023 1 commit
-
-
moto authored
Summary: This commit adds fields to OutputStream, which shows the result of fitlers, such as width and height after filtering. Before ``` OutputStream( source_index=0, filter_description='fps=3,scale=width=320:height=320,format=pix_fmts=gray') ``` After ``` OutputVideoStream( source_index=0, filter_description='fps=3,scale=width=320:height=320,format=pix_fmts=gray', media_type='video', format='gray', width=320, height=320, frame_rate=3.0) ``` Pull Request resolved: https://github.com/pytorch/audio/pull/3155 Reviewed By: nateanl Differential Revision: D43882399 Pulled By: mthrok fbshipit-source-id: 620676b1a06f293fdd56de8203a11120f228fa2d
-
- 02 Mar, 2023 1 commit
-
-
moto authored
Summary: Fix build_doc job https://app.circleci.com/pipelines/github/pytorch/audio/15217/workflows/ce50b317-a59e-4741-b8d2-59129420deb8 - build.ffmpeg.html might not exist when IPython notebook is processed. Changing to main doc URL. - Fix bash cell syntax in HW tutorial - Fix C++ doc - Fix duplicated target name in streamwriter tutorial Pull Request resolved: https://github.com/pytorch/audio/pull/3125 Reviewed By: xiaohui-zhang Differential Revision: D43724078 Pulled By: mthrok fbshipit-source-id: ea7d46ec5e377cf2fbd7c3798df57da73750ac5c
-
- 27 Feb, 2023 1 commit
-
-
Zhaoheng Ni authored
Summary: Add pre-trained pipeline support for `SquimObjective` model. The pre-trained model is trained on DNS 2020 challenge dataset. Pull Request resolved: https://github.com/pytorch/audio/pull/3103 Reviewed By: xiaohui-zhang, mthrok Differential Revision: D43611794 Pulled By: nateanl fbshipit-source-id: 0ac76a27e7027a43ffccb158385ddb2409b8526d
-
- 24 Feb, 2023 2 commits
-
-
moto authored
Summary: This commit is kind of clean up and preparation for future development. We plan to pass around more complicated objects among StreamReader and StreamWriter, and TorchBind is not expressive enough for defining intermediate object, so we use PyBind11 for binding StreamWriter. Pull Request resolved: https://github.com/pytorch/audio/pull/3091 Reviewed By: xiaohui-zhang Differential Revision: D43515714 Pulled By: mthrok fbshipit-source-id: 9097bb104bbf8c1536a5fab6f87447c08b10a7f2
-
Zhaoheng Ni authored
Summary: Pull Request resolved: https://github.com/pytorch/audio/pull/3084 Reviewed By: mthrok Differential Revision: D43550150 Pulled By: nateanl fbshipit-source-id: 5c5e3d9461e375be202493e3399ff38ce5cd7690
-
- 22 Feb, 2023 1 commit
-
-
Zhaoheng Ni authored
Summary: Pull Request resolved: https://github.com/pytorch/audio/pull/3042 Reviewed By: mthrok Differential Revision: D43405932 Pulled By: nateanl fbshipit-source-id: 88f6dabae35565b699230e9909b8f68f4a57f5c7
-
- 15 Feb, 2023 1 commit
-
-
moto authored
Summary: * Mention context manager in StreamWriter * Add FFmpeg as optional dependency Pull Request resolved: https://github.com/pytorch/audio/pull/3064 Reviewed By: hwangjeff Differential Revision: D43307818 Pulled By: mthrok fbshipit-source-id: 86339d973aba85e090f520e08af65b5d736e3d18
-
- 14 Feb, 2023 2 commits
-
-
moto authored
Summary: Pull Request resolved: https://github.com/pytorch/audio/pull/3053 Reviewed By: nateanl Differential Revision: D43238766 Pulled By: mthrok fbshipit-source-id: 4f82878b1c97b0e6a35af75855849b86200e6061
-
Zhaoheng Ni authored
Summary: replicate of https://github.com/pytorch/audio/issues/2644 Pull Request resolved: https://github.com/pytorch/audio/pull/2880 Reviewed By: mthrok Differential Revision: D41633911 Pulled By: nateanl fbshipit-source-id: 73cf145d75c389e996aafe96571ab86dc21f86e5
-
- 11 Feb, 2023 1 commit
-
-
moto authored
Summary: Par https://github.com/pytorch/audio/issues/3040 and https://github.com/pytorch/audio/issues/3041, it turned out Google Colab now has FFmpeg with GPU decoder/encoder preinstalled, and installing FFmpeg manually corrups the environment. This commit updates the tutorial by extracting and moving the how-to-install part to installation/build section. closes https://github.com/pytorch/audio/issues/3041 closes https://github.com/pytorch/audio/issues/3040 Pull Request resolved: https://github.com/pytorch/audio/pull/3050 Reviewed By: nateanl Differential Revision: D43166054 Pulled By: mthrok fbshipit-source-id: 32667f292a796344d5fcde86e8231e15ad904e58
-
- 09 Feb, 2023 1 commit
-
-
moto authored
Summary: - Add documentation - Tweak docsrting - Fix import Pull Request resolved: https://github.com/pytorch/audio/pull/3051 Reviewed By: weiwangmeta, atalman, nateanl Differential Revision: D43166081 Pulled By: mthrok fbshipit-source-id: 7d77aa34a6318a64824626cff8372f8b9aebf6f9
-
- 07 Feb, 2023 1 commit
-
-
moto authored
Summary: Add a section about installation/build https://output.circle-artifacts.com/output/job/f121cd38-68f3-47a3-ac29-c7b0cfe94c77/artifacts/0/docs/installation.html <img width="1102" alt="Screenshot 2023-02-06 at 6 13 50 PM" src="https://user-images.githubusercontent.com/855818/217108551-622b117b-209e-4776-b5d6-d6934c8126a4.png"> https://output.circle-artifacts.com/output/job/f121cd38-68f3-47a3-ac29-c7b0cfe94c77/artifacts/0/docs/build.html <img width="1072" alt="Screenshot 2023-02-06 at 6 13 57 PM" src="https://user-images.githubusercontent.com/855818/217108568-c125cdc2-9d6a-4c1d-a155-2cee40c9dac6.png"> Pull Request resolved: https://github.com/pytorch/audio/pull/3038 Reviewed By: hwangjeff, nateanl Differential Revision: D43083469 Pulled By: mthrok fbshipit-source-id: e0b5b76dbf706552dd60ae26ea40ebc98627e3b0
-
- 01 Feb, 2023 1 commit
-
-
moto authored
Summary: Adding C++ documentation. (C++ APIs are categorized as prototype, though it's used by Python beta APIs.) https://output.circle-artifacts.com/output/job/69654229-a99e-4b15-9ce0-7bc6bcf01101/artifacts/0/docs/libtorchaudio.html <img width="1202" alt="Screenshot 2023-01-31 at 11 48 47 AM" src="https://user-images.githubusercontent.com/855818/215828167-d23032f8-9e40-4413-b5b1-5cbd12d705e9.png"> Pull Request resolved: https://github.com/pytorch/audio/pull/2994 Reviewed By: hwangjeff Differential Revision: D42876621 Pulled By: mthrok fbshipit-source-id: d8b8d610b87ec766501baa88b7506368a9905a6a
-
- 27 Jan, 2023 1 commit
-
-
hwangjeff authored
Summary: Moves `AddNoise`, `Convolve`, `FFTConvolve`, `Speed`, `SpeedPerturbation`, `Deemphasis`, and `Preemphasis` out of `torchaudio.prototype.transforms` and into `torchaudio.transforms`. Pull Request resolved: https://github.com/pytorch/audio/pull/3009 Reviewed By: xiaohui-zhang, mthrok Differential Revision: D42730322 Pulled By: hwangjeff fbshipit-source-id: 43739ac31437150d3127e51eddc0f0bba5facb15
-
- 26 Jan, 2023 1 commit
-
-
moto authored
Summary: These functions are called part of sox initialization, thus it is no longer needed. Pull Request resolved: https://github.com/pytorch/audio/pull/3010 Reviewed By: hwangjeff Differential Revision: D42744478 Pulled By: mthrok fbshipit-source-id: 17d715b328392397ec47d81a533a307aac22862d
-
- 24 Jan, 2023 1 commit
-
-
hwangjeff authored
Summary: Moves `add_noise`, `fftconvolve`, `convolve`, `speed`, `preemphasis`, and `deemphasis` out of `torchaudio.prototype.functional` and into `torchaudio.functional`. Pull Request resolved: https://github.com/pytorch/audio/pull/3001 Reviewed By: mthrok Differential Revision: D42688971 Pulled By: hwangjeff fbshipit-source-id: 43280bd3ffeccddae57f1092ac45afb64dd426cc
-
- 23 Jan, 2023 1 commit
-
-
moto authored
Summary: This change fixes the issue where syntax highlighting is broken up par word. ## Plain Before <img width="243" alt="Screenshot 2023-01-20 at 1 28 48 PM" src="https://user-images.githubusercontent.com/855818/213778202-27ec8030-3f2f-4ef9-8210-bce7cfc3cb38.png"> After <img width="244" alt="Screenshot 2023-01-20 at 1 29 01 PM" src="https://user-images.githubusercontent.com/855818/213778231-61c52825-d63a-4913-b10d-a65f3b2cfbbb.png"> ## In articles Before <img width="786" alt="Screenshot 2023-01-20 at 1 34 12 PM" src="https://user-images.githubusercontent.com/855818/213779050-c21ba5e2-84b3-4935-bbab-6edcb7bc89ce.png"> After <img width="783" alt="Screenshot 2023-01-20 at 1 34 17 PM" src="https://user-images.githubusercontent.com/855818/213779069-f1406422-27a4-41cf-8ccd-5058f80860bd.png"> ## In tables Before <img width="813" alt="Screenshot 2023-01-20 at 1 27 35 PM" src="https://user-images.githubusercontent.com/855818/213778039-fede6f18-5a35-47f2-9e0b-a9be5716dc73.png"> After <img width="813" alt="Screenshot 2023-01-20 at 1 27 51 PM" src="https://user-images.githubusercontent.com/855818/213778073-e26275a9-d380-4601-aa92-84af7aeab00f.png"> Pull Request resolved: https://github.com/pytorch/audio/pull/3000 Reviewed By: xiaohui-zhang Differential Revision: D42642522 Pulled By: mthrok fbshipit-source-id: 6831bb90da005aff8d7f178ef768e967bc6d2640
-
- 22 Jan, 2023 1 commit
-
-
moto authored
Summary: This commit makes `StreamReader` report PTS (presentation time stamp) of the returned chunk as well. Example ```python from torchaudio.io import StreamReader s = StreamReader(...) s.add_video_stream(...) for (video_chunk, ) in s.stream(): # video_chunk is Torch tensor type but has extra attribute of PTS print(video_chunk.pts) # reports the PTS of the first frame of the video chunk. ``` For the backward compatibility, we introduce a `_ChunkTensor`, that is a composition of Tensor and metadata, but works like a normal tensor in PyTorch operations. The implementation of `_ChunkTensor` is based on [TrivialTensorViaComposition](https://github.com/albanD/subclass_zoo/blob/0eeb1d68fb59879029c610bc407f2997ae43ba0a/trivial_tensors.py#L83). It was also suggested to attach metadata directly to Tensor object, but the possibility to have the collision on torchaudio's metadata and new attributes introduced in PyTorch cannot be ignored, so we use Tensor subclass implementation. If any unexpected issue arise from metadata attribute name collision, client code can fetch the bare Tensor and continue. Pull Request resolved: https://github.com/pytorch/audio/pull/2975 Reviewed By: hwangjeff Differential Revision: D42526945 Pulled By: mthrok fbshipit-source-id: b4e9422e914ff328421b975120460f3001268f35
-
- 15 Jan, 2023 1 commit
-
-
Zhaoheng Ni authored
Summary: The PR adds three `Wav2Vec2Bundle ` pipeline objects for XLS-R models: - WAV2VEC2_XLSR_300M - WAV2VEC2_XLSR_1B - WAV2VEC2_XLSR_2B All three models use layer normalization in the feature extraction layers, hence `_normalize_waveform` is set to `True`. Pull Request resolved: https://github.com/pytorch/audio/pull/2978 Reviewed By: hwangjeff Differential Revision: D42501491 Pulled By: nateanl fbshipit-source-id: 2429ec880cc14798034843381e458e1b4664dac3
-
- 13 Jan, 2023 1 commit
-
-
Zhaoheng Ni authored
Summary: XLSR (cross-lingual speech representation) are a set of cross-lingual self-supervised learning models for generating cross-lingual speech representation. It was first proposed in https://arxiv.org/pdf/2006.13979.pdf which is trained on 53 languages (so-called XLSR-53). This PR supports more XLS-R models from https://arxiv.org/pdf/2111.09296.pdf that have more parameters (300M, 1B, 2B) and are trained on 128 languages. Pull Request resolved: https://github.com/pytorch/audio/pull/2959 Reviewed By: mthrok Differential Revision: D42397643 Pulled By: nateanl fbshipit-source-id: 23e8e51a7cde0a226db4f4028db7df8f02b986ce
-
- 06 Jan, 2023 1 commit
-
-
Zhaoheng Ni authored
Summary: `InverseMelScale` is missing from the nightly documentation webpage. `MelScale` is better in Feature Extractions section. This PR moves both documents into Feature Extractions section. Pull Request resolved: https://github.com/pytorch/audio/pull/2967 Reviewed By: mthrok Differential Revision: D42387886 Pulled By: nateanl fbshipit-source-id: cdac020887817ea2530bfb26e8ed414ae4761420
-
- 05 Jan, 2023 2 commits
-
-
Zhaoheng Ni authored
Summary: The generator part of HiFiGAN model is a vocoder which converts mel spectrogram to waveform. It makes more sense to name it as vocoder for better understanding. Pull Request resolved: https://github.com/pytorch/audio/pull/2955 Reviewed By: carolineechen Differential Revision: D42348864 Pulled By: nateanl fbshipit-source-id: c45a2f8d8d205ee381178ae5d37e9790a257e1aa
-
Grigory Sizov authored
Summary: Closes [T138011314](https://www.internalfb.com/intern/tasks/?t=138011314) ## Description - Add bundle `HIFIGAN_GENERATOR_V3_LJSPEECH` to prototypes. The bundle contains pre-trained HiFiGAN generator weights from the [original HiFiGAN publication](https://github.com/jik876/hifi-gan#pretrained-model), converted slightly to fit our model - Add tests - unit tests checking that vocoder and mel-transform implementations in the bundle give the same results as the original ones. Part of the original HiFiGAN code is ported to this repo to enable these tests - integration test checking that waveform reconstructed from mel spectrogram by the bundle is close enough to the original - Add docs Pull Request resolved: https://github.com/pytorch/audio/pull/2921 Reviewed By: nateanl, mthrok Differential Revision: D42034761 Pulled By: sgrigory fbshipit-source-id: 8b0dadeed510b3c9371d6aa2c46ec7d8378f6048
-
- 04 Jan, 2023 1 commit
-
-
Jeff Hwang authored
Summary: Pull Request resolved: https://github.com/pytorch/audio/pull/2935 Reviewed By: mthrok Differential Revision: D42302275 Pulled By: hwangjeff fbshipit-source-id: d995d335bf17d63d3c1dda77d8ef596570853638
-
- 30 Dec, 2022 1 commit
-
-
moto authored
Summary: Artifact: [subtractive_synthesis_tutorial](https://output.circle-artifacts.com/output/job/4c1ce33f-834d-48e0-ba89-2e91acdcb572/artifacts/0/docs/tutorials/subtractive_synthesis_tutorial.html) Pull Request resolved: https://github.com/pytorch/audio/pull/2934 Reviewed By: carolineechen Differential Revision: D42284945 Pulled By: mthrok fbshipit-source-id: d255b8e8e2a601a19bc879f9e1c38edbeebaf9b3
-
- 22 Dec, 2022 1 commit
-
-
moto authored
Summary: This commit adds "filter_waveform" prototype function. This function can apply non-stationary filters across the time. It also performs cropping at the end to compensate the delay introduced by filtering. The figure bellow illustrates this. See [subtractive_synthesis_tutorial](https://output.circle-artifacts.com/output/job/5233fda9-dadb-4710-9389-7e8ac20a062f/artifacts/0/docs/tutorials/subtractive_synthesis_tutorial.html) for example usages. 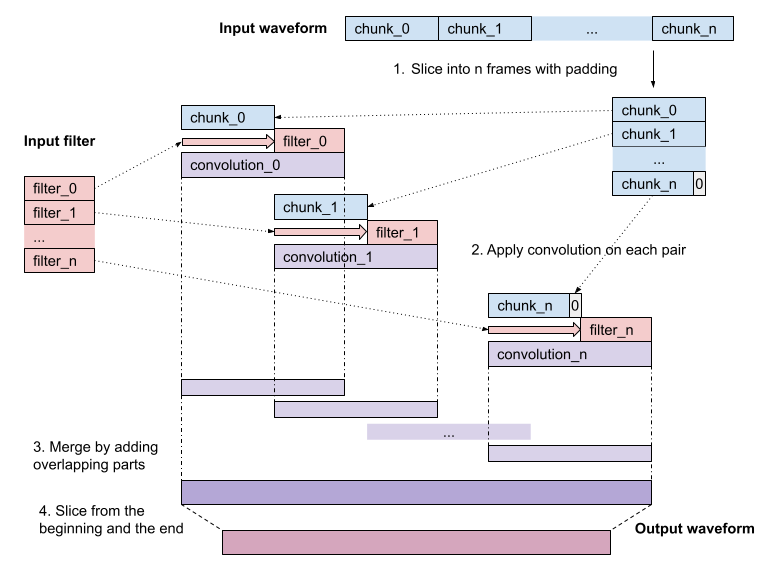 Pull Request resolved: https://github.com/pytorch/audio/pull/2928 Reviewed By: carolineechen Differential Revision: D42199955 Pulled By: mthrok fbshipit-source-id: e822510ab8df98393919bea33768f288f4d661b2
-
- 17 Dec, 2022 1 commit
-
-
moto authored
Summary: Adds filter design tutorial, which demonstrates `sinc_impulse_response` and `frequency_impulse_response`. Example: - [filter_design_tutorial](https://output.circle-artifacts.com/output/job/bd22c615-9215-4b17-a52c-b171a47f646c/artifacts/0/docs/tutorials/filter_design_tutorial.html) Pull Request resolved: https://github.com/pytorch/audio/pull/2894 Reviewed By: xiaohui-zhang Differential Revision: D42117658 Pulled By: mthrok fbshipit-source-id: f7dd04980e8557bb6f0e0ec26ac2c7f53314ea16
-
- 10 Dec, 2022 1 commit
-
-
moto authored
Summary: Currently, the documentation page for `torchaudio.models` have separate sections for model definitions and factory functions. The relationships between models and factory functions are not immediately clear. This commit moves the list of factory functions to the list of models. After: - https://output.circle-artifacts.com/output/job/242a9521-7460-4043-895b-9995bf5093b5/artifacts/0/docs/generated/torchaudio.models.Wav2Vec2Model.html <img width="1171" alt="Screen Shot 2022-12-08 at 8 41 03 PM" src="https://user-images.githubusercontent.com/855818/206603743-74a6e368-c3cf-4b87-b854-518a95893f06.png"> Pull Request resolved: https://github.com/pytorch/audio/pull/2902 Reviewed By: carolineechen Differential Revision: D41897800 Pulled By: mthrok fbshipit-source-id: a3c01d28d80e755596a9bc37c951960eb84870b9
-
- 08 Dec, 2022 2 commits
-
-
Grigory Sizov authored
Summary: Addressed mthrok's comments in https://github.com/pytorch/audio/pull/2833: - Moved model type from `_params` directly into the bundle definition. For now I defined model type as "WavLM" for WavLM bundles and "Wav2Vec2" for everything else. We can also distinguish between different Wav2Vec2 falvours - Hubert, VoxPopuli etc, but at the moment this won't imply any functional differences, so I didn't do it - Expanded the title underline to match the title length Pull Request resolved: https://github.com/pytorch/audio/pull/2895 Reviewed By: nateanl, mthrok Differential Revision: D41799875 Pulled By: sgrigory fbshipit-source-id: 0730d4f91ed60e900643bb74d6cccdd7aa5d7b39
-
Grigory Sizov authored
Summary: Part 1 of [T138011314](https://www.internalfb.com/intern/tasks/?t=138011314) This PR ports the generator part of [HiFi GAN](https://arxiv.org/abs/2010.05646v2) from [the original implementation](https://github.com/jik876/hifi-gan/blob/4769534d45265d52a904b850da5a622601885777/models.py#L75) Adds tests: - Smoke tests for architectures V1, V2, V3 - Check that output shapes are correct - Check that the model is torchscriptable and scripting doesn't change the output - Check that our code's output matches the original implementation. Here I clone the original repo inside `/tmp` and import necessary objects from inside the test function. On test teardown I restore `PATH`, but don't remove the cloned code, so that it can be reused on subsequent runs - let me know if removing it would be a better practice There are no quantization tests, because the model consists mainly of `Conv1d` and `ConvTransposed1d`, and they are [not supported by dynamic quantization](https://pytorch.org/docs/stable/quantization.html) Pull Request resolved: https://github.com/pytorch/audio/pull/2860 Reviewed By: nateanl Differential Revision: D41433416 Pulled By: sgrigory fbshipit-source-id: f135c560df20f5138f01e3efdd182621edabb4f5
-
- 07 Dec, 2022 2 commits
-
-
hwangjeff authored
Summary: Pull Request resolved: https://github.com/pytorch/audio/pull/2889 Reviewed By: xiaohui-zhang Differential Revision: D41760084 Pulled By: hwangjeff fbshipit-source-id: d2f5253e1fae7e7aafa9fa6043c6a7045c5b33a0
-
hwangjeff authored
Summary: Introduces the MUSAN dataset (https://www.openslr.org/17/), which contains music, speech, and noise recordings. Pull Request resolved: https://github.com/pytorch/audio/pull/2888 Reviewed By: xiaohui-zhang Differential Revision: D41762164 Pulled By: hwangjeff fbshipit-source-id: 14d5baaa4d40f065dd5d99bf7f2e0a73aa6c31a9
-
- 06 Dec, 2022 1 commit
-
-
moto authored
Summary: This commit adds `frequency_impulse_response` function, which generates filter from desired frequency response. [Example](https://output.circle-artifacts.com/output/job/5233fda9-dadb-4710-9389-7e8ac20a062f/artifacts/0/docs/tutorials/filter_design_tutorial.html#frequency-sampling) Pull Request resolved: https://github.com/pytorch/audio/pull/2879 Reviewed By: hwangjeff Differential Revision: D41767787 Pulled By: mthrok fbshipit-source-id: 6d5e44c6390e8cf3028994a1b1de590ff3aaf6c2
-
- 02 Dec, 2022 1 commit
-
-
hwangjeff authored
Summary: Adds pre-emphasis and de-emphasis functions. Pull Request resolved: https://github.com/pytorch/audio/pull/2871 Reviewed By: carolineechen Differential Revision: D41651097 Pulled By: hwangjeff fbshipit-source-id: 7a3cf6ce68b6ce1b9ae315ddd8bd8ed71acccdf1
-
- 30 Nov, 2022 1 commit
-
-
hwangjeff authored
Summary: Adds functions and transforms for speed and speed perturbation (https://www.isca-speech.org/archive/interspeech_2015/ko15_interspeech.html). Pull Request resolved: https://github.com/pytorch/audio/pull/2829 Reviewed By: xiaohui-zhang Differential Revision: D41285114 Pulled By: hwangjeff fbshipit-source-id: 114740507698e01f35d4beb2c568a2479e847506
-
- 29 Nov, 2022 1 commit
-
-
moto authored
Summary: This commit adds `sinc_impulse_response`, which generates windowed-sinc low-pass filters for given cutoff frequencies. Example usage: - [Filter Design Tutorial](https://output.circle-artifacts.com/output/job/c0085baa-5345-4aeb-bd44-448034caa9e1/artifacts/0/docs/tutorials/filter_design_tutorial.html) Pull Request resolved: https://github.com/pytorch/audio/pull/2875 Reviewed By: carolineechen Differential Revision: D41586631 Pulled By: mthrok fbshipit-source-id: a9991dbe5b137b0b4679228ec37072a1da7e50bb
-






