
Add filter_waveform (#2928)
Summary: This commit adds "filter_waveform" prototype function. This function can apply non-stationary filters across the time. It also performs cropping at the end to compensate the delay introduced by filtering. The figure bellow illustrates this. See [subtractive_synthesis_tutorial](https://output.circle-artifacts.com/output/job/5233fda9-dadb-4710-9389-7e8ac20a062f/artifacts/0/docs/tutorials/subtractive_synthesis_tutorial.html) for example usages. 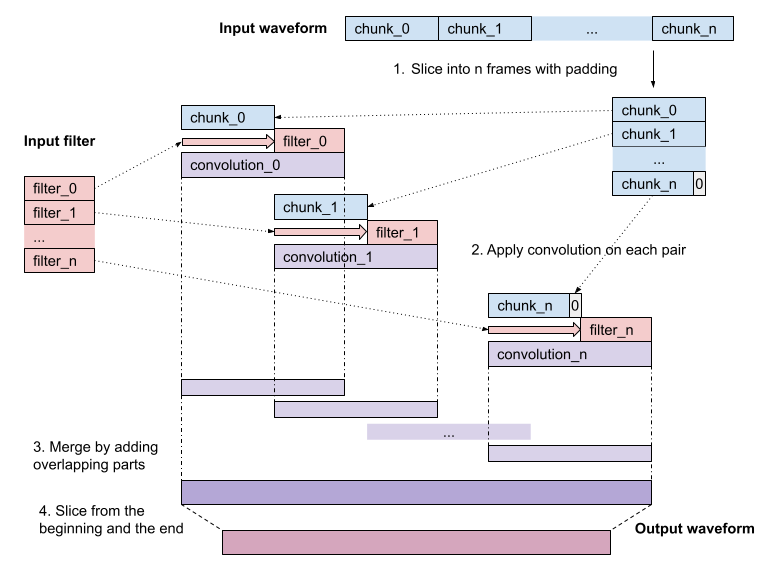 Pull Request resolved: https://github.com/pytorch/audio/pull/2928 Reviewed By: carolineechen Differential Revision: D42199955 Pulled By: mthrok fbshipit-source-id: e822510ab8df98393919bea33768f288f4d661b2
Showing
Please register or sign in to comment