- 15 Jan, 2023 1 commit
-
-
Zhaoheng Ni authored
Summary: The PR adds three `Wav2Vec2Bundle ` pipeline objects for XLS-R models: - WAV2VEC2_XLSR_300M - WAV2VEC2_XLSR_1B - WAV2VEC2_XLSR_2B All three models use layer normalization in the feature extraction layers, hence `_normalize_waveform` is set to `True`. Pull Request resolved: https://github.com/pytorch/audio/pull/2978 Reviewed By: hwangjeff Differential Revision: D42501491 Pulled By: nateanl fbshipit-source-id: 2429ec880cc14798034843381e458e1b4664dac3
-
- 14 Jan, 2023 1 commit
-
-
Zhaoheng Ni authored
Summary: XLS-R tests are supposed to be skipped on gpu machines, but they are forced to run in [_skipIf](https://github.com/pytorch/audio/blob/main/test/torchaudio_unittest/common_utils/case_utils.py#L143-L145) decorator. This PR skips the XLS-R tests if the machine is CI and CUDA is available. Pull Request resolved: https://github.com/pytorch/audio/pull/2982 Reviewed By: xiaohui-zhang Differential Revision: D42520292 Pulled By: nateanl fbshipit-source-id: c6ee4d4a801245226c26d9cd13e039e8d910add2
-
- 13 Jan, 2023 1 commit
-
-
Zhaoheng Ni authored
Summary: XLSR (cross-lingual speech representation) are a set of cross-lingual self-supervised learning models for generating cross-lingual speech representation. It was first proposed in https://arxiv.org/pdf/2006.13979.pdf which is trained on 53 languages (so-called XLSR-53). This PR supports more XLS-R models from https://arxiv.org/pdf/2111.09296.pdf that have more parameters (300M, 1B, 2B) and are trained on 128 languages. Pull Request resolved: https://github.com/pytorch/audio/pull/2959 Reviewed By: mthrok Differential Revision: D42397643 Pulled By: nateanl fbshipit-source-id: 23e8e51a7cde0a226db4f4028db7df8f02b986ce
-
- 12 Jan, 2023 2 commits
-
-
mthrok authored
Summary: * Refactor _extension module so that * the implementation of initialization logic and its execution are separated. * logic goes to `_extension.utils` * the execution is at `_extension.__init__` * global variables are defined and modified in `__init__`. * Replace `is_sox_available()` with `_extension._SOX_INITIALIZED` * Replace `is_kaldi_available()` with `_extension._IS_KALDI_AVAILABLE` * Move `requies_sox()` and `requires_kaldi()` to break the circular dependency among `_extension` and `_internal.module_utils`. * Merge the sox-related initialization logic in `_extension.utils` module. Pull Request resolved: https://github.com/pytorch/audio/pull/2968 Reviewed By: hwangjeff Differential Revision: D42387251 Pulled By: mthrok fbshipit-source-id: 0c3245dfab53f9bc1b8a83ec2622eb88ec96673f -
moto authored
Summary: This commit adds `buffer_chunk_size=-1`, which does not drop buffered frames. Pull Request resolved: https://github.com/pytorch/audio/pull/2969 Reviewed By: xiaohui-zhang Differential Revision: D42403467 Pulled By: mthrok fbshipit-source-id: a0847e6878874ce7e4b0ec3f56e5fbb8ebdb5992
-
- 10 Jan, 2023 1 commit
-
-
moto authored
Summary: filter graph does not fallback to `best_effort_timestamp`, thus applying filters (like changing fps) on videos without PTS values failed. This commit changes the behavior by overwriting the PTS values with best_effort_timestamp. Pull Request resolved: https://github.com/pytorch/audio/pull/2970 Reviewed By: YosuaMichael Differential Revision: D42425771 Pulled By: mthrok fbshipit-source-id: 7b7a033ea2ad89bb49d6e1663d35d377dab2aae9
-
- 06 Jan, 2023 2 commits
-
-
moto authored
Summary: This commit adds utility functions that fetch the available/supported formats/devices/codecs. These functions are mostly same with commands like `ffmpeg -decoders`. But the use of `ffmpeg` CLI can report different resutls if there are multiple installation of FFmpegs. Or, the CLI might not be available. Pull Request resolved: https://github.com/pytorch/audio/pull/2958 Reviewed By: hwangjeff Differential Revision: D42371640 Pulled By: mthrok fbshipit-source-id: 96a96183815a126cb1adc97ab7754aef216fff6f
-
Moto Hira authored
Summary: Pull Request resolved: https://github.com/pytorch/audio/pull/2963 Phaser batch consistency test takes longer than the rest. Change the sample rate from 44100 to 8000. Reviewed By: hwangjeff Differential Revision: D42379064 fbshipit-source-id: 2005b833c696bb3c2bb1d21c38c39e6163d81d53
-
- 05 Jan, 2023 2 commits
-
-
Zhaoheng Ni authored
Summary: The generator part of HiFiGAN model is a vocoder which converts mel spectrogram to waveform. It makes more sense to name it as vocoder for better understanding. Pull Request resolved: https://github.com/pytorch/audio/pull/2955 Reviewed By: carolineechen Differential Revision: D42348864 Pulled By: nateanl fbshipit-source-id: c45a2f8d8d205ee381178ae5d37e9790a257e1aa
-
Grigory Sizov authored
Summary: Closes [T138011314](https://www.internalfb.com/intern/tasks/?t=138011314) ## Description - Add bundle `HIFIGAN_GENERATOR_V3_LJSPEECH` to prototypes. The bundle contains pre-trained HiFiGAN generator weights from the [original HiFiGAN publication](https://github.com/jik876/hifi-gan#pretrained-model), converted slightly to fit our model - Add tests - unit tests checking that vocoder and mel-transform implementations in the bundle give the same results as the original ones. Part of the original HiFiGAN code is ported to this repo to enable these tests - integration test checking that waveform reconstructed from mel spectrogram by the bundle is close enough to the original - Add docs Pull Request resolved: https://github.com/pytorch/audio/pull/2921 Reviewed By: nateanl, mthrok Differential Revision: D42034761 Pulled By: sgrigory fbshipit-source-id: 8b0dadeed510b3c9371d6aa2c46ec7d8378f6048
-
- 04 Jan, 2023 1 commit
-
-
Jeff Hwang authored
Summary: Pull Request resolved: https://github.com/pytorch/audio/pull/2935 Reviewed By: mthrok Differential Revision: D42302275 Pulled By: hwangjeff fbshipit-source-id: d995d335bf17d63d3c1dda77d8ef596570853638
-
- 30 Dec, 2022 1 commit
-
-
moto authored
Summary: This commit refactors and optimizes functions that converts AVFrames of `yuv420p` and `nv12` into PyTorch's Tensor. The performance is improved about 30%. 1. Reduce the number of intermediate Tensors allocated. 2. Replace 2 calls to `repeat_interleave` with `F::interpolate`. * (`F::interpolate` is about 5x faster than `repeat_interleave`. ) <details><summary>code</summary> ```bash #!/usr/bin/env bash set -e python -c """ import torch import torch.nn.functional as F a = torch.arange(49, dtype=torch.uint8).reshape(7, 7).clone() val1 = a.repeat_interleave(2, -1).repeat_interleave(2, -2) val2 = F.interpolate(a.view((1, 1, 7, 7, 1)), size=[14, 14, 1], mode=\"nearest\") print(torch.sum(torch.abs(val1 - val2[0, 0, :, :, 0]))) """ python3 -m timeit \ --setup """ import torch a = torch.arange(49, dtype=torch.uint8).reshape(7, 7).clone() """ \ """ a.repeat_interleave(2, -1).repeat_interleave(2, -2) """ python3 -m timeit \ --setup """ import torch import torch.nn.functional as F a = torch.arange(49, dtype=torch.uint8).reshape(7, 7).clone() """ \ """ F.interpolate(a.view((1, 1, 7, 7, 1)), size=[14, 14, 1], mode=\"nearest\") """ ``` </details> ``` tensor(0) 10000 loops, best of 5: 38.3 usec per loop 50000 loops, best of 5: 7.1 usec per loop ``` ## Benchmark Result <details><summary>code</summary> ```bash #!/usr/bin/env bash set -e mkdir -p tmp for ext in avi mp4; do for duration in 1 5 10 30 60; do printf "Testing ${ext} ${duration} [sec]\n" test_data="tmp/test_${duration}.${ext}" if [ ! -f "${test_data}" ]; then printf "Generating test data\n" ffmpeg -hide_banner -f lavfi -t ${duration} -i testsrc "${test_data}" > /dev/null 2>&1 fi python -m timeit \ --setup="from torchaudio.io import StreamReader" \ """ r = StreamReader(\"${test_data}\") r.add_basic_video_stream(frames_per_chunk=-1, format=\"yuv420p\") r.process_all_packets() r.pop_chunks() """ done done ``` </details> 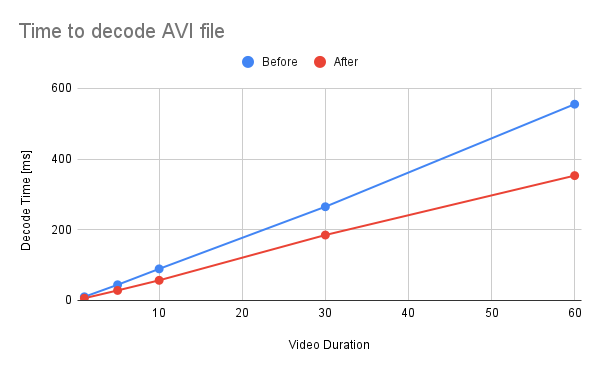 <details><summary>raw data</summary> Video Type - AVI Duration | Before | After -- | -- | -- 1 | 10.3 | 6.29 5 | 44.3 | 28.3 10 | 89.3 | 56.9 30 | 265 | 185 60 | 555 | 353 </details> 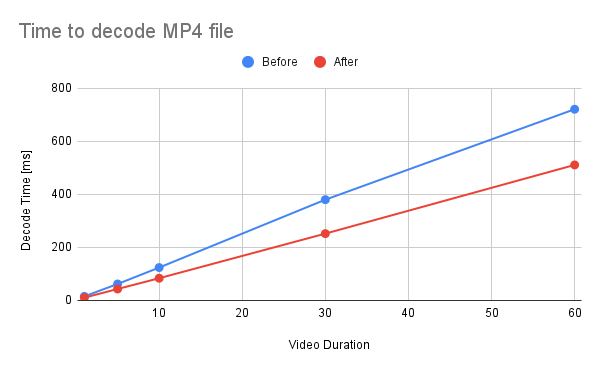 <details><summary>raw data</summary> Video Type - MP4 Duration | Before | After -- | -- | -- 1 | 15.3 | 10.5 5 | 62.1 | 43.2 10 | 124 | 83.8 30 | 380 | 252 60 | 721 | 511 </details> Pull Request resolved: https://github.com/pytorch/audio/pull/2945 Reviewed By: carolineechen Differential Revision: D42283269 Pulled By: mthrok fbshipit-source-id: 59840f943ff516b69ab8ad35fed7104c48a0bf0c
-
- 22 Dec, 2022 1 commit
-
-
moto authored
Summary: This commit adds "filter_waveform" prototype function. This function can apply non-stationary filters across the time. It also performs cropping at the end to compensate the delay introduced by filtering. The figure bellow illustrates this. See [subtractive_synthesis_tutorial](https://output.circle-artifacts.com/output/job/5233fda9-dadb-4710-9389-7e8ac20a062f/artifacts/0/docs/tutorials/subtractive_synthesis_tutorial.html) for example usages. 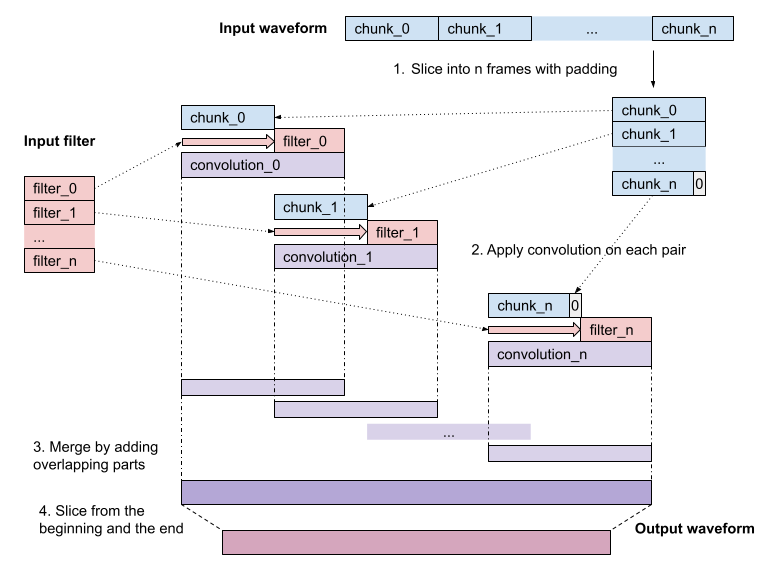 Pull Request resolved: https://github.com/pytorch/audio/pull/2928 Reviewed By: carolineechen Differential Revision: D42199955 Pulled By: mthrok fbshipit-source-id: e822510ab8df98393919bea33768f288f4d661b2
-
- 21 Dec, 2022 1 commit
-
-
moto authored
Summary: This commit makes the following changes to the C++ library organization - Move sox-related feature implementations from `libtorchaudio` to `libtorchaudio_sox`. - Remove C++ implementation of `is_sox_available` and `is_ffmpeg_available` as it is now sufficient to check the existence of `libtorchaudio_sox` and `libtorchaudio_ffmpeg` to check the availability. This makes `libtorchaudio_sox` and `libtorchaudio_ffmpeg` independent from `libtorchaudio`. - Move PyBind11-based bindings (`_torchaudio_sox`, `_torchaudio_ffmpeg`) into `torchaudio.lib` so that the built library structure is less cluttered. Background: Originally, when the `libsox` was the only C++ extension and `libtorchaudio` was supposed to contain all the C++ code. The things are different now. We have a bunch of C++ extensions and we need to make the code/build structure more modular. The new `libtorchaudio_sox` contains the implementations and `_torchaudio_sox` contains the PyBin11-based bindings. Pull Request resolved: https://github.com/pytorch/audio/pull/2929 Reviewed By: hwangjeff Differential Revision: D42159594 Pulled By: mthrok fbshipit-source-id: 1a0fbca9e4143137f6363fc001b2378ce6029aa7
-
- 20 Dec, 2022 1 commit
-
-
moto authored
Summary: If the input video has invalid PTS, the current precise seek fails except when seeking into t=0. This commit updates the discard mechanism to fallback to `best_effort_timestamp` in such cases. `best_effort_timestamp` is just the number of frames went through decoder starting from the beginning of the file. This means if the input file is very long, but seeking towards the end of the file, the StreamReader still decodes all the frames. For videos with valid PTS, `best_effort_timestamp` should be same as `pts`. [[src](https://ffmpeg.org/doxygen/4.1/decode_8c.html#a8d86329cf58a4adbd24ac840d47730cf)] Pull Request resolved: https://github.com/pytorch/audio/pull/2916 Reviewed By: YosuaMichael Differential Revision: D42170204 Pulled By: mthrok fbshipit-source-id: 80c04dc376e0f427d41eb9feb44c251a1648a998
-
- 16 Dec, 2022 1 commit
-
-
Caroline Chen authored
Summary: resolves https://github.com/pytorch/audio/issues/2891 Rename `resampling_method` options to more accurately describe what is happening. Previously the methods were set to `sinc_interpolation` and `kaiser_window`, which can be confusing as both options actually use sinc interpolation methodology, but differ in the window function used. As a result, rename `sinc_interpolation` to `sinc_interp_hann` and `kaiser_window` to `sinc_interp_kaiser`. Using an old option will throw a warning, and those options will be deprecated in 2 released. The numerical behavior is unchanged. Pull Request resolved: https://github.com/pytorch/audio/pull/2922 Reviewed By: mthrok Differential Revision: D42083619 Pulled By: carolineechen fbshipit-source-id: 9a9a7ea2d2daeadc02d53dddfd26afe249459e70
-
- 09 Dec, 2022 2 commits
-
-
Zhaoheng Ni authored
Summary: After https://github.com/pytorch/audio/issues/2873, the pre-trained Wav2Vec2 models with larger datasets can get better performances. The PR fixes the integration test of bundle `WAV2VEC2_ASR_LARGE_LV60K_10M` which predicts the word `CURIOUSITY` to `CURIOUSSITY` before but now to `CURIOUSITY` correctly. Pull Request resolved: https://github.com/pytorch/audio/pull/2910 Reviewed By: mthrok Differential Revision: D41881919 Pulled By: nateanl fbshipit-source-id: 236fd00b983a5205c731f3efa31033a6b8257cab
-
atalman authored
Summary: Toggle on/off ffmpeg test if needed By default it ON, hence should not affect any current tests. To toggle ON no change required. To toggle OFF use: ``` smoke_test.py --no-ffmpeg ``` To be used when calling from builder currently. Since we do not install ffmpeg currently. Pull Request resolved: https://github.com/pytorch/audio/pull/2901 Reviewed By: carolineechen, mthrok Differential Revision: D41874976 Pulled By: atalman fbshipit-source-id: c57b19f37c63a1f476f93a5211550e980e67d9c7
-
- 08 Dec, 2022 1 commit
-
-
Grigory Sizov authored
Summary: Part 1 of [T138011314](https://www.internalfb.com/intern/tasks/?t=138011314) This PR ports the generator part of [HiFi GAN](https://arxiv.org/abs/2010.05646v2) from [the original implementation](https://github.com/jik876/hifi-gan/blob/4769534d45265d52a904b850da5a622601885777/models.py#L75) Adds tests: - Smoke tests for architectures V1, V2, V3 - Check that output shapes are correct - Check that the model is torchscriptable and scripting doesn't change the output - Check that our code's output matches the original implementation. Here I clone the original repo inside `/tmp` and import necessary objects from inside the test function. On test teardown I restore `PATH`, but don't remove the cloned code, so that it can be reused on subsequent runs - let me know if removing it would be a better practice There are no quantization tests, because the model consists mainly of `Conv1d` and `ConvTransposed1d`, and they are [not supported by dynamic quantization](https://pytorch.org/docs/stable/quantization.html) Pull Request resolved: https://github.com/pytorch/audio/pull/2860 Reviewed By: nateanl Differential Revision: D41433416 Pulled By: sgrigory fbshipit-source-id: f135c560df20f5138f01e3efdd182621edabb4f5
-
- 07 Dec, 2022 2 commits
-
-
hwangjeff authored
Summary: Pull Request resolved: https://github.com/pytorch/audio/pull/2889 Reviewed By: xiaohui-zhang Differential Revision: D41760084 Pulled By: hwangjeff fbshipit-source-id: d2f5253e1fae7e7aafa9fa6043c6a7045c5b33a0
-
hwangjeff authored
Summary: Introduces the MUSAN dataset (https://www.openslr.org/17/), which contains music, speech, and noise recordings. Pull Request resolved: https://github.com/pytorch/audio/pull/2888 Reviewed By: xiaohui-zhang Differential Revision: D41762164 Pulled By: hwangjeff fbshipit-source-id: 14d5baaa4d40f065dd5d99bf7f2e0a73aa6c31a9
-
- 06 Dec, 2022 1 commit
-
-
moto authored
Summary: This commit adds `frequency_impulse_response` function, which generates filter from desired frequency response. [Example](https://output.circle-artifacts.com/output/job/5233fda9-dadb-4710-9389-7e8ac20a062f/artifacts/0/docs/tutorials/filter_design_tutorial.html#frequency-sampling) Pull Request resolved: https://github.com/pytorch/audio/pull/2879 Reviewed By: hwangjeff Differential Revision: D41767787 Pulled By: mthrok fbshipit-source-id: 6d5e44c6390e8cf3028994a1b1de590ff3aaf6c2
-
- 04 Dec, 2022 1 commit
-
-
Zhaoheng Ni authored
Summary: address https://github.com/pytorch/audio/issues/2885 In `_init_hubert_pretrain_model ` method which initialize the hubert pretrain models, `kaiming_normal_` should be applied on `ConvLayerBlock` instead of `LayerNorm` layer. This PR fixes it and adds more unit tests. Pull Request resolved: https://github.com/pytorch/audio/pull/2886 Reviewed By: hwangjeff Differential Revision: D41713801 Pulled By: nateanl fbshipit-source-id: ed199baf7504d06bbf2d31c522ae708a75426a2d
-
- 02 Dec, 2022 1 commit
-
-
hwangjeff authored
Summary: Adds pre-emphasis and de-emphasis functions. Pull Request resolved: https://github.com/pytorch/audio/pull/2871 Reviewed By: carolineechen Differential Revision: D41651097 Pulled By: hwangjeff fbshipit-source-id: 7a3cf6ce68b6ce1b9ae315ddd8bd8ed71acccdf1
-
- 30 Nov, 2022 1 commit
-
-
hwangjeff authored
Summary: Adds functions and transforms for speed and speed perturbation (https://www.isca-speech.org/archive/interspeech_2015/ko15_interspeech.html). Pull Request resolved: https://github.com/pytorch/audio/pull/2829 Reviewed By: xiaohui-zhang Differential Revision: D41285114 Pulled By: hwangjeff fbshipit-source-id: 114740507698e01f35d4beb2c568a2479e847506
-
- 29 Nov, 2022 3 commits
-
-
moto authored
Summary: This commit adds `sinc_impulse_response`, which generates windowed-sinc low-pass filters for given cutoff frequencies. Example usage: - [Filter Design Tutorial](https://output.circle-artifacts.com/output/job/c0085baa-5345-4aeb-bd44-448034caa9e1/artifacts/0/docs/tutorials/filter_design_tutorial.html) Pull Request resolved: https://github.com/pytorch/audio/pull/2875 Reviewed By: carolineechen Differential Revision: D41586631 Pulled By: mthrok fbshipit-source-id: a9991dbe5b137b0b4679228ec37072a1da7e50bb
-
moto authored
Summary: Currently, fftconvolve only accepts the tensors for the exact same leading dimensions. This commit loosens the restriction to allow shapes that are broadcast-able. This makes the fftconvolve operation more efficient for cases like signal filtering where one operand (waveform) is larger than the other (filter kernel) and the same filter kernels are applied across channels and batches. Pull Request resolved: https://github.com/pytorch/audio/pull/2874 Reviewed By: carolineechen Differential Revision: D41581588 Pulled By: mthrok fbshipit-source-id: c0117e11b979fb53236cc307a970a461b0e50134
-
Caroline Chen authored
Summary: modeled after [paper](https://arxiv.org/pdf/2110.07313.pdf) and internal flow f288347302 internal comparison tests: D40080919 Pull Request resolved: https://github.com/pytorch/audio/pull/2827 Reviewed By: nateanl Differential Revision: D41569046 Pulled By: carolineechen fbshipit-source-id: 43c5313074af05972d93da55b2029c746b75c380
-
- 28 Nov, 2022 2 commits
-
-
Zhaoheng Ni authored
Summary: - layer_norm in `EmformerEncoder` is set as default in emformer_hubert_model, change the type to be non-optional. - add `aux_num_out` to emformer_hubert_model to support fine-tuning model. - update unit tests. Pull Request resolved: https://github.com/pytorch/audio/pull/2868 Reviewed By: carolineechen Differential Revision: D41451311 Pulled By: nateanl fbshipit-source-id: 5fa0f19255e4f01e001d62f8689e36f134030083
-
moto authored
Summary: Add `extend_pitch` function that can be used for augmenting fundamental frequencies with its harmonic overtones or inharmonic partials. it can be use for amplitude as well. For example usages, see https://output.circle-artifacts.com/output/job/4ad0c29a-d75a-4244-baad-f5499f11d94b/artifacts/0/docs/tutorials/synthesis_tutorial.html Part of https://github.com/pytorch/audio/issues/2835 Extracted from https://github.com/pytorch/audio/issues/2808 Pull Request resolved: https://github.com/pytorch/audio/pull/2863 Reviewed By: carolineechen Differential Revision: D41543880 Pulled By: mthrok fbshipit-source-id: 4f20e55770b0b3bee825ec07c73f9ec7cb181109
-
- 19 Nov, 2022 1 commit
-
-
moto authored
Summary: Missing from https://github.com/pytorch/audio/issues/2848 Pull Request resolved: https://github.com/pytorch/audio/pull/2864 Reviewed By: carolineechen Differential Revision: D41413381 Pulled By: mthrok fbshipit-source-id: 4377ed4a59504c6ade9ee6f42938a2bc3f04fb73
-
- 18 Nov, 2022 1 commit
-
-
Zhaoheng Ni authored
Summary: Pull Request resolved: https://github.com/pytorch/audio/pull/2836 Reviewed By: carolineechen Differential Revision: D41208630 Pulled By: nateanl fbshipit-source-id: 625e1651f0b8a6e20876409739cf7084cb7c748b
-
- 17 Nov, 2022 2 commits
-
-
moto authored
Summary: Add adsr_envelope op, which generates ADSR envelope * Supports generation of the envelope on GPU * Supports optional Hold * Supports polynomial decay <image src='https://download.pytorch.org/torchaudio/doc-assets/adsr_examples.png'> Pull Request resolved: https://github.com/pytorch/audio/pull/2859 Reviewed By: nateanl Differential Revision: D41379601 Pulled By: mthrok fbshipit-source-id: 3717a6e0360d2a24913c2a836c57c5edec1d7b31
-
moto authored
Summary: This commit adds `oscillator_bank` op, which is the core of (differential) digital signal processing ops. The implementation itself is pretty simple, sum instantaneous frequencies, take sin and multiply with amplitudes. Following the magenta implementation, amplitudes for frequency range outside of [-Nyquist, Nyquist] \ are suppressed. The differentiability is tested within frequency range of [- Nyquist, Nyquist], and amplitude range of [-5, 5], which should be enough. For example usages: - https://output.circle-artifacts.com/output/job/129f3e21-41ce-406b-bc6b-833efb3c3141/artifacts/0/docs/tutorials/oscillator_tutorial.html - https://output.circle-artifacts.com/output/job/129f3e21-41ce-406b-bc6b-833efb3c3141/artifacts/0/docs/tutorials/synthesis_tutorial.html Part of https://github.com/pytorch/audio/issues/2835 Extracted from https://github.com/pytorch/audio/issues/2808 Pull Request resolved: https://github.com/pytorch/audio/pull/2848 Reviewed By: carolineechen Differential Revision: D41353075 Pulled By: mthrok fbshipit-source-id: 80e60772fb555760f2396f7df40458803c280225
-
- 15 Nov, 2022 1 commit
-
-
Grigory Sizov authored
Summary: Closes T136364380, follow-up to https://github.com/pytorch/audio/issues/2822 - Added "base", "base+", and "large" bundles for WavLM - Expanded `wav2vec2_pipeline_test.py` to include the new bundles - Added the new bundles to docs in `pipelines.rst` Pull Request resolved: https://github.com/pytorch/audio/pull/2833 Reviewed By: nateanl Differential Revision: D41194796 Pulled By: sgrigory fbshipit-source-id: bf8e96c05b6a81ac5c5a014c46adeeac12685328
-
- 14 Nov, 2022 1 commit
-
-
Caroline Chen authored
Summary: follow up to https://github.com/pytorch/audio/issues/2823 - move bark spectrogram to prototype - decrease autograd test tolerance (passing on circle ci) - add diagram for bark fbanks cc jdariasl Pull Request resolved: https://github.com/pytorch/audio/pull/2843 Reviewed By: nateanl Differential Revision: D41199522 Pulled By: carolineechen fbshipit-source-id: 8e6c2e20fb7b14f39477683b3c6ed8356359a213
-
- 10 Nov, 2022 2 commits
-
-
Julián D. Arias-Londoño authored
Summary: I have added BarkScale transform, which can transform a regular Spectrogram into a BarkSpectrograms similar to MelScale. ahmed-fau opened this requirement in December 2021 with the number (https://github.com/pytorch/audio/issues/2103). The new functionality includes three different well-known approximations of the Bark scale. Pull Request resolved: https://github.com/pytorch/audio/pull/2823 Reviewed By: nateanl Differential Revision: D41162100 Pulled By: carolineechen fbshipit-source-id: b2670c4972e49c9ef424da5d5982576f7a4df831
-
Caroline Chen authored
Summary: internal comparison tests: D40080919 follow up PR for pretrained models https://github.com/pytorch/audio/issues/2827 Pull Request resolved: https://github.com/pytorch/audio/pull/2826 Reviewed By: nateanl Differential Revision: D41160061 Pulled By: carolineechen fbshipit-source-id: f3c478b28c235af53d1d8e21b573c53684a63ac4
-
- 09 Nov, 2022 1 commit
-
-
Grigory Sizov authored
Summary: Closes T136364380 Added [WavLM Model](https://github.com/microsoft/UniSpeech/tree/main/WavLM): - Added `WavLMSelfAttention` class (from [original implementation](https://github.com/microsoft/UniSpeech/blob/2e9dde8bf815a5f5fd958e3435e5641f59f96928/WavLM/modules.py)) and adjusted existing Encoder and Transformer classes to be compatible with it - Added factory functions `wavlm_model`, `wavlm_base`, `wavlm_large` to `models/wav2vec2/model.py` - Added bundles for base and large models to pipelines. **TODO**: pre-trained model weights are not yet uploaded to `download.pytorch.org`, permissions not granted yet. ## Tests - Expanded HuggingFace integration tests to cover WavLM. For there tests, added JSON configs for base and large models from HF ([base](https://huggingface.co/microsoft/wavlm-base/blob/main/config.json), [large](https://huggingface.co/microsoft/wavlm-large/blob/main/config.json)) into test assets - Expanded TorchScript and quantization tests to cover WavLM ## Comments There are a few workarounds I had to introduce: - Quantization tests for WavLM were breaking down at [`torch.cat`](https://github.com/pytorch/audio/pull/2822/files#diff-6f1486901c94320ec0610a460dc674638fab9d104a61564ff7b59353a8b8547cR466) ~~until I excluded the arguments of `torch.cat` from quantization [here](https://github.com/pytorch/audio/pull/2822/files#diff-6f1486901c94320ec0610a460dc674638fab9d104a61564ff7b59353a8b8547cR368-R369). I haven't found a better way to fix it, let me know if there is one~~ The reason for this seems to be that quantization replaces `.bias` and `.weight` attributes of a `Linear` module with methods. Since we are using weights and biases directly, the code was break. The final solution suggested by nateanl was to define attention weights and biases directly in `WavLMSelfAttention`, skipping the `Linear` layers - ~~WavLM uses position embedding in the first layer of encoder, but not in the subsequent ones. So [UniSpeech](https://github.com/microsoft/UniSpeech/blob/2e9dde8bf815a5f5fd958e3435e5641f59f96928/WavLM/modules.py#L342) and [HF](https://github.com/huggingface/transformers/blob/b047472650cba259621549ac27b18fd2066ce18e/src/transformers/models/wavlm/modeling_wavlm.py#L441-L442) implementations only create this embedding module in the layers where it's used. However, we can't do this here because it breaks TorchScript. So as a solution I add a dummy `Identity` module to `WavLMSelfAttention` when the actual embedding is not needed: [here](https://github.com/pytorch/audio/pull/2822/files#diff-6f1486901c94320ec0610a460dc674638fab9d104a61564ff7b59353a8b8547cR361-R368).~~ Thanks nateanl for resolving this! - I had to add dummy `position_bias` and `key_padding_mask` arguments to `SelfAttention.forward` to make TorchScript tests pass. Since both `SelfAttention` and `WavLMSelfAttention` are called from `EncoderLayer`, they need to have compatible signatures. Having a variable number of arguments with `**kwargs` or checking object class doesn't seem to work with TorchScript, so I instead made both types of attention accept `position_bias` and `key_padding_mask` arguments. Nit: do we still need to specify `__all__` if there are no wildcard imports in `__init__.py`, e.g. in `torchaudio/models/__init__.py`? Pull Request resolved: https://github.com/pytorch/audio/pull/2822 Reviewed By: nateanl Differential Revision: D41121855 Pulled By: sgrigory fbshipit-source-id: 9f4f787e5810010de4e74cb704063a26c66767d7
-
- 08 Nov, 2022 1 commit
-
-
Caroline Chen authored
Summary: Add `fused_log_softmax` argument (default/current behavior = True) to rnnt loss. If setting it to `False`, call `log_softmax` on the logits prior to passing it in to the rnnt loss function. The following should produce the same output: ``` rnnt_loss(logits, targets, logit_lengths, target_lengths, fused_log_softmax=True) ``` ``` log_probs = torch.nn.functional.log_softmax(logits, dim=-1) rnnt_loss(log_probs, targets, logit_lengths, target_lengths, fused_log_softmax=False) ``` testing -- unit tests + get same results on the conformer rnnt recipe Pull Request resolved: https://github.com/pytorch/audio/pull/2798 Reviewed By: xiaohui-zhang Differential Revision: D41083523 Pulled By: carolineechen fbshipit-source-id: e15442ceed1f461bbf06b724aa0561ff8827ad61
-









