- 11 Jan, 2023 1 commit
-
-
pbialecki authored
Summary: CC atalman Pull Request resolved: https://github.com/pytorch/audio/pull/2951 Reviewed By: mthrok Differential Revision: D42459205 Pulled By: atalman fbshipit-source-id: b2d7c5604ba1f3bb4d9a45a052ac41054acd52dd
-
- 10 Jan, 2023 2 commits
-
-
moto authored
Summary: filter graph does not fallback to `best_effort_timestamp`, thus applying filters (like changing fps) on videos without PTS values failed. This commit changes the behavior by overwriting the PTS values with best_effort_timestamp. Pull Request resolved: https://github.com/pytorch/audio/pull/2970 Reviewed By: YosuaMichael Differential Revision: D42425771 Pulled By: mthrok fbshipit-source-id: 7b7a033ea2ad89bb49d6e1663d35d377dab2aae9
-
moto authored
Summary: * Add missing docsrtings * Add default values Pull Request resolved: https://github.com/pytorch/audio/pull/2971 Reviewed By: xiaohui-zhang Differential Revision: D42425796 Pulled By: mthrok fbshipit-source-id: a6a946875142a54424c059bbfbab1908a1564bd3
-
- 06 Jan, 2023 6 commits
-
-
Zhaoheng Ni authored
Summary: `InverseMelScale` is missing from the nightly documentation webpage. `MelScale` is better in Feature Extractions section. This PR moves both documents into Feature Extractions section. Pull Request resolved: https://github.com/pytorch/audio/pull/2967 Reviewed By: mthrok Differential Revision: D42387886 Pulled By: nateanl fbshipit-source-id: cdac020887817ea2530bfb26e8ed414ae4761420
-
moto authored
Summary: This commit adds utility functions that fetch the available/supported formats/devices/codecs. These functions are mostly same with commands like `ffmpeg -decoders`. But the use of `ffmpeg` CLI can report different resutls if there are multiple installation of FFmpegs. Or, the CLI might not be available. Pull Request resolved: https://github.com/pytorch/audio/pull/2958 Reviewed By: hwangjeff Differential Revision: D42371640 Pulled By: mthrok fbshipit-source-id: 96a96183815a126cb1adc97ab7754aef216fff6f
-
moto authored
Summary: Introduced in hotfix https://github.com/pytorch/audio/issues/2964 Pull Request resolved: https://github.com/pytorch/audio/pull/2966 Reviewed By: carolineechen Differential Revision: D42385913 Pulled By: mthrok fbshipit-source-id: 6c42dbfbb914b0329c09a1bca591f11cf2e3c1a6
-
moto authored
Summary: Put the helper functions in unnamed namespace. Pull Request resolved: https://github.com/pytorch/audio/pull/2962 Reviewed By: carolineechen Differential Revision: D42378781 Pulled By: mthrok fbshipit-source-id: 74daf613f8b78f95141ae4e7c4682d8d0e97f72e
-
moto authored
Summary: Follow-up of f70b970a Pull Request resolved: https://github.com/pytorch/audio/pull/2964 Reviewed By: xiaohui-zhang Differential Revision: D42380451 Pulled By: mthrok fbshipit-source-id: 0569a32be576042ab419b363e694fe7d2db1feb0
-
Moto Hira authored
Summary: Pull Request resolved: https://github.com/pytorch/audio/pull/2963 Phaser batch consistency test takes longer than the rest. Change the sample rate from 44100 to 8000. Reviewed By: hwangjeff Differential Revision: D42379064 fbshipit-source-id: 2005b833c696bb3c2bb1d21c38c39e6163d81d53
-
- 05 Jan, 2023 4 commits
-
-
Zhaoheng Ni authored
Summary: The generator part of HiFiGAN model is a vocoder which converts mel spectrogram to waveform. It makes more sense to name it as vocoder for better understanding. Pull Request resolved: https://github.com/pytorch/audio/pull/2955 Reviewed By: carolineechen Differential Revision: D42348864 Pulled By: nateanl fbshipit-source-id: c45a2f8d8d205ee381178ae5d37e9790a257e1aa
-
moto authored
Summary: lfilter, overdrive have faster implementation written in C++. If they are not available, torchaudio is supposed to fall back on Python-based implementation. The original fallback mechanism relied on error type and messages from PyTorch core, which has been changed. This commit updates it for more proper fallback mechanism. Pull Request resolved: https://github.com/pytorch/audio/pull/2953 Reviewed By: hwangjeff Differential Revision: D42344893 Pulled By: mthrok fbshipit-source-id: 18ce5c1aa1c69d0d2ab469b0b0c36c0221f5ccfd
-
Moto Hira authored
Summary: Pull Request resolved: https://github.com/pytorch/audio/pull/2956 Merge utility binding This commit updates the utility binding, so that we can use `is_module_available()` for checking the existence of extension modules. To ensure the existence of module, this commit migrates the binding of utility functions to PyBind11. Going forward, we should use TorchBind for ops that we want to support TorchScript, otherwise default to PyBind11. (PyBind has advantage of not copying strings.) Reviewed By: hwangjeff Differential Revision: D42355992 fbshipit-source-id: 4c71d65b24a0882a38a80dc097d45ba72b4c4a6b
-
Grigory Sizov authored
Summary: Closes [T138011314](https://www.internalfb.com/intern/tasks/?t=138011314) ## Description - Add bundle `HIFIGAN_GENERATOR_V3_LJSPEECH` to prototypes. The bundle contains pre-trained HiFiGAN generator weights from the [original HiFiGAN publication](https://github.com/jik876/hifi-gan#pretrained-model), converted slightly to fit our model - Add tests - unit tests checking that vocoder and mel-transform implementations in the bundle give the same results as the original ones. Part of the original HiFiGAN code is ported to this repo to enable these tests - integration test checking that waveform reconstructed from mel spectrogram by the bundle is close enough to the original - Add docs Pull Request resolved: https://github.com/pytorch/audio/pull/2921 Reviewed By: nateanl, mthrok Differential Revision: D42034761 Pulled By: sgrigory fbshipit-source-id: 8b0dadeed510b3c9371d6aa2c46ec7d8378f6048
-
- 04 Jan, 2023 5 commits
-
-
moto authored
Summary: Currently, when iterating media data with StreamReader, using the for-loop is the only way with public API. This does not support usecases like "Fetch one chunk after seek" well. ```python s = StreamReader s.add_audio_stream(...) s.seek(10) chunk = None for chunk, in s.stream(): break ``` This commit make the `fill_buffer` used in iterative method public API so that one acn do ```python s.seek(10) s.fill_buffer() chunk, = s.pop_chunks() ``` --- Also this commit moves the implementation to C++ so that it reduces the number of FFI boundary crossing. This improves the performance when the iteration is longer. AVI (generated with `ffmpeg -hide_banner -f lavfi -t ${duration} -i testsrc "${file}.avi"`) | Video Duration [sec] | Original [msec] | Fill Buffer C++ | One Go (reference) | |----------------------|----------|-----------------|--------| | 1 | 18 | 18.4 | 16.6 | | 5 | 44 | 42.6 | 35.1 | | 10 | 75.3 | 74.4 | 60.9 | | 30 | 200 | 195 | 158 | | 60 | 423 | 382 | 343 | MP4 (generated with `ffmpeg -hide_banner -f lavfi -t ${duration} -i testsrc "${file}.mp4"`) | Video Duration [sec] | Original [msec] | Fill Buffer C++ | One Go | |----------------------|-----------------|-----------------|--------| | 1 | 18.7 | 18.1 | 10.3 | | 5 | 42.2 | 40.6 | 25.2 | | 10 | 73.9 | 71.8 | 43.6 | | 30 | 202 | 194 | 116 | | 60 | 396 | 386 | 227 | * Original (Python implementation) ```python r = StreamReader(src) r.add_video_stream(1, decoder_option={"threads": "1"}) for chunk, in r.stream(): pass ``` * This (C++) ```python r = StreamReader(src) r.add_video_stream(1, decoder_option={"threads": "1"}) for chunk, in r.stream(): pass ``` * Using `process_all_packets` (process all in one go) ```python r = StreamReader(src) r.add_video_stream(1, decoder_option={"threads": "1"}) r.process_all_packets() ``` Pull Request resolved: https://github.com/pytorch/audio/pull/2954 Reviewed By: carolineechen Differential Revision: D42349446 Pulled By: mthrok fbshipit-source-id: 9e4e37923e46299c3f43f4ad17a2a2b938b2b197 -
moto authored
Summary: One can pass "threads" and "thread_type" to `decoder_option` of StreamReaader to change the multithreading configuration. These affects the timing that decoder starts emitting the decoded frames. i.e. how many packets at minimum have to be processed before the first frame is decoded. Overall, multithreading in decoder does not improve the performance. (One possible reason is because the design of StreamReader, "decode few frames then fetch them", does not suited to saturate the decoder with incoming packets.) num_threads=1 seems to exhibit overall good performance/resource balance. 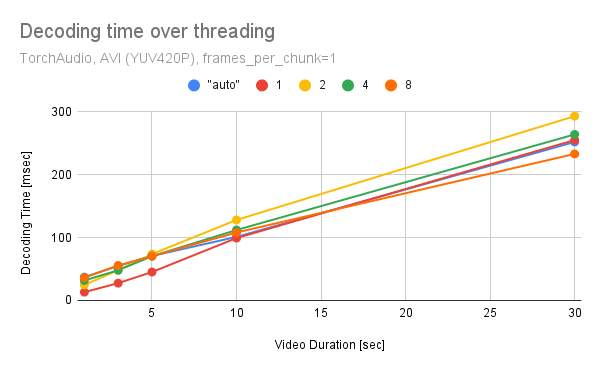 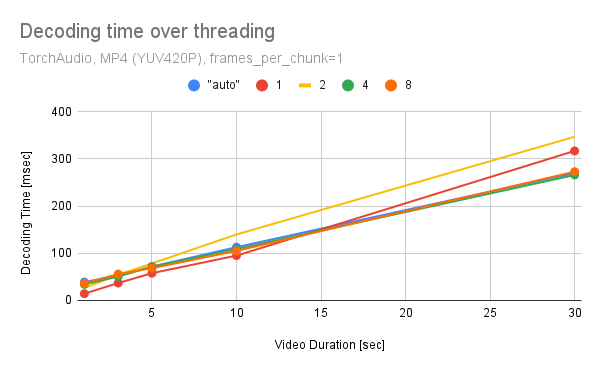 (Tested on 320x240 25 FPPS, YUV420P videos generated with `ffmpeg -f lavfi -t "${duration}" -i testsrc -pix_fmt "yuv420p"`) For this reason, we default to single thread execution in StreamReader. closes https://github.com/pytorch/audio/issues/2855 Follow-up: Apply similar change to encoder option in StreamWriter. Pull Request resolved: https://github.com/pytorch/audio/pull/2949 Reviewed By: carolineechen Differential Revision: D42343951 Pulled By: mthrok fbshipit-source-id: aea234717d37918f99fc24f575dbcfe7dcae1e80
-
moto authored
Summary: Pull Request resolved: https://github.com/pytorch/audio/pull/2866 Reviewed By: carolineechen Differential Revision: D42349474 Pulled By: mthrok fbshipit-source-id: 31455184031fff52719ef829e40bb1e09e11b0e7
-
hwangjeff authored
Summary: Currently, importing TorchAudio triggers a check of the CUDA version it was compiled with, which in turn calls `torch.ops.torchaudio.cuda_version()`. This function is available only if `libtorchaudio` is available; developers, however, may want to import TorchAudio regardless of its availability. To allow for such usage, this PR adds code that bypasses the check if `libtorchaudio` is not available. Pull Request resolved: https://github.com/pytorch/audio/pull/2952 Reviewed By: mthrok Differential Revision: D42336396 Pulled By: hwangjeff fbshipit-source-id: 465353cf46b218c0bcdf51ca5cf0b83c93185f39
-
Jeff Hwang authored
Summary: Pull Request resolved: https://github.com/pytorch/audio/pull/2935 Reviewed By: mthrok Differential Revision: D42302275 Pulled By: hwangjeff fbshipit-source-id: d995d335bf17d63d3c1dda77d8ef596570853638
-
- 30 Dec, 2022 4 commits
-
-
moto authored
Summary: * Split `convert_[yuv420p|nv12|nv12_cuda]` functions into allocation and data write functions. * Merge the `get_[interlaced|planar]_image_buffer` functions into `get_buffer` and `get_image_buffer`. * Disassemble `convert_XXX_image` helper functions. Pull Request resolved: https://github.com/pytorch/audio/pull/2946 Reviewed By: nateanl Differential Revision: D42287501 Pulled By: mthrok fbshipit-source-id: b8dd0d52fd563a112a16887b643bf497f77dfb80
-
Zhaoheng Ni authored
Summary: The `root` path can be confusing to users without reading the document. The PR adds runtime error for a better understanding. Pull Request resolved: https://github.com/pytorch/audio/pull/2944 Reviewed By: mthrok Differential Revision: D42281034 Pulled By: nateanl fbshipit-source-id: 6e5f4bfb118583d678d6b7a2565ef263fe8e4a5a
-
moto authored
Summary: This commit refactors and optimizes functions that converts AVFrames of `yuv420p` and `nv12` into PyTorch's Tensor. The performance is improved about 30%. 1. Reduce the number of intermediate Tensors allocated. 2. Replace 2 calls to `repeat_interleave` with `F::interpolate`. * (`F::interpolate` is about 5x faster than `repeat_interleave`. ) <details><summary>code</summary> ```bash #!/usr/bin/env bash set -e python -c """ import torch import torch.nn.functional as F a = torch.arange(49, dtype=torch.uint8).reshape(7, 7).clone() val1 = a.repeat_interleave(2, -1).repeat_interleave(2, -2) val2 = F.interpolate(a.view((1, 1, 7, 7, 1)), size=[14, 14, 1], mode=\"nearest\") print(torch.sum(torch.abs(val1 - val2[0, 0, :, :, 0]))) """ python3 -m timeit \ --setup """ import torch a = torch.arange(49, dtype=torch.uint8).reshape(7, 7).clone() """ \ """ a.repeat_interleave(2, -1).repeat_interleave(2, -2) """ python3 -m timeit \ --setup """ import torch import torch.nn.functional as F a = torch.arange(49, dtype=torch.uint8).reshape(7, 7).clone() """ \ """ F.interpolate(a.view((1, 1, 7, 7, 1)), size=[14, 14, 1], mode=\"nearest\") """ ``` </details> ``` tensor(0) 10000 loops, best of 5: 38.3 usec per loop 50000 loops, best of 5: 7.1 usec per loop ``` ## Benchmark Result <details><summary>code</summary> ```bash #!/usr/bin/env bash set -e mkdir -p tmp for ext in avi mp4; do for duration in 1 5 10 30 60; do printf "Testing ${ext} ${duration} [sec]\n" test_data="tmp/test_${duration}.${ext}" if [ ! -f "${test_data}" ]; then printf "Generating test data\n" ffmpeg -hide_banner -f lavfi -t ${duration} -i testsrc "${test_data}" > /dev/null 2>&1 fi python -m timeit \ --setup="from torchaudio.io import StreamReader" \ """ r = StreamReader(\"${test_data}\") r.add_basic_video_stream(frames_per_chunk=-1, format=\"yuv420p\") r.process_all_packets() r.pop_chunks() """ done done ``` </details> 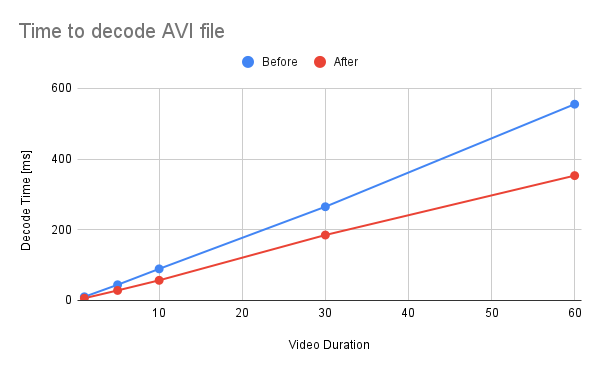 <details><summary>raw data</summary> Video Type - AVI Duration | Before | After -- | -- | -- 1 | 10.3 | 6.29 5 | 44.3 | 28.3 10 | 89.3 | 56.9 30 | 265 | 185 60 | 555 | 353 </details> 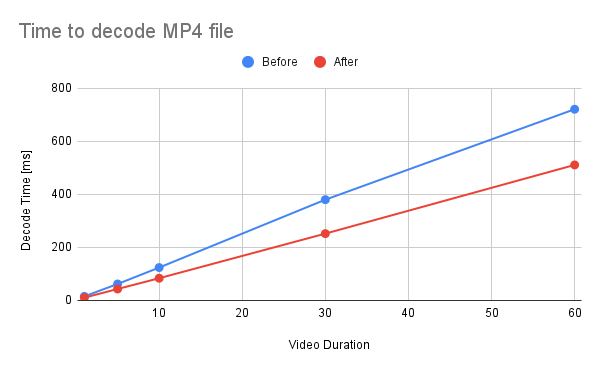 <details><summary>raw data</summary> Video Type - MP4 Duration | Before | After -- | -- | -- 1 | 15.3 | 10.5 5 | 62.1 | 43.2 10 | 124 | 83.8 30 | 380 | 252 60 | 721 | 511 </details> Pull Request resolved: https://github.com/pytorch/audio/pull/2945 Reviewed By: carolineechen Differential Revision: D42283269 Pulled By: mthrok fbshipit-source-id: 59840f943ff516b69ab8ad35fed7104c48a0bf0c -
moto authored
Summary: Artifact: [subtractive_synthesis_tutorial](https://output.circle-artifacts.com/output/job/4c1ce33f-834d-48e0-ba89-2e91acdcb572/artifacts/0/docs/tutorials/subtractive_synthesis_tutorial.html) Pull Request resolved: https://github.com/pytorch/audio/pull/2934 Reviewed By: carolineechen Differential Revision: D42284945 Pulled By: mthrok fbshipit-source-id: d255b8e8e2a601a19bc879f9e1c38edbeebaf9b3
-
- 29 Dec, 2022 3 commits
-
-
TruscaPetre authored
Summary: I have spent 2 hours because I read the documentation wrongly and trying to figure out why the I couldn't read the data from the dataset. The initial phrase was very confusing. Pull Request resolved: https://github.com/pytorch/audio/pull/2937 Reviewed By: mthrok Differential Revision: D42280738 Pulled By: nateanl fbshipit-source-id: a48b9bc27d44ca8106bd56f805294a5a0e3ede1b
-
moto authored
Summary: Pull Request resolved: https://github.com/pytorch/audio/pull/2930 Reviewed By: carolineechen, nateanl Differential Revision: D42280966 Pulled By: mthrok fbshipit-source-id: f9d5f1dc7c1a62d932fb2020aafb63734f2bf405
-
moto authored
Summary: * move helper functions to `detail` namespace. * move helper functions out of `buffer.h` Pull Request resolved: https://github.com/pytorch/audio/pull/2943 Reviewed By: carolineechen Differential Revision: D42271652 Pulled By: mthrok fbshipit-source-id: abbfc8e8bac97d4eeb34221d4c20763477bd982e
-
- 28 Dec, 2022 1 commit
-
-
moto authored
Summary: Refactor the two helper functions that convert AVFrame to torch::Tensor into separate buffer allocation and data copy. Pull Request resolved: https://github.com/pytorch/audio/pull/2940 Reviewed By: carolineechen Differential Revision: D42247915 Pulled By: mthrok fbshipit-source-id: 2f504d48674088205e6039e8aadd8856b3fe5eee
-
- 27 Dec, 2022 1 commit
-
-
moto authored
Summary: The `Buffer` class is responsible for converting `AVFrame` into `torch::Tensor` and storing the frames in accordance to `frames_per_chunk` and `buffer_chunk_size`. There are four operating modes of Buffer; [audio|video] x [chunked|unchunked]. Audio and video have a separate class implementations, but the behavior of chunked/unchunked depends on `frames_per_chunk<0` or not. Chunked mode is where frames should be returned by chunk of a unit number frames, while unchunked mode is where frames are returned as-is. When frames are accumulated, in chunked mode, old frames are dropped, while in unchunked mode all the frames are retained. Currently, the underlying buffer implementations are the same `std::dequeu<torch::Tensor>`. As we plan to make chunked-mode behavior more efficient by changing the underlying buffer container, it will be easier if the unchuked-mode behavior is kept as-is as a separate class. This commit makes the following changes. * Change `Buffer` class into pure virtual class (interface). * Split `AudioBuffer` into` UnchunkedAudioBuffer` and `ChunkedAudioBuffer`. * Split `VideoBuffer` into` UnchunkedVideoBuffer` and `ChunkedVideoBuffer`. Pull Request resolved: https://github.com/pytorch/audio/pull/2939 Reviewed By: carolineechen Differential Revision: D42247509 Pulled By: mthrok fbshipit-source-id: 7363e442a5b2db5dcbaaf0ffbfa702e088726d1b
-
- 22 Dec, 2022 1 commit
-
-
moto authored
Summary: This commit adds "filter_waveform" prototype function. This function can apply non-stationary filters across the time. It also performs cropping at the end to compensate the delay introduced by filtering. The figure bellow illustrates this. See [subtractive_synthesis_tutorial](https://output.circle-artifacts.com/output/job/5233fda9-dadb-4710-9389-7e8ac20a062f/artifacts/0/docs/tutorials/subtractive_synthesis_tutorial.html) for example usages. 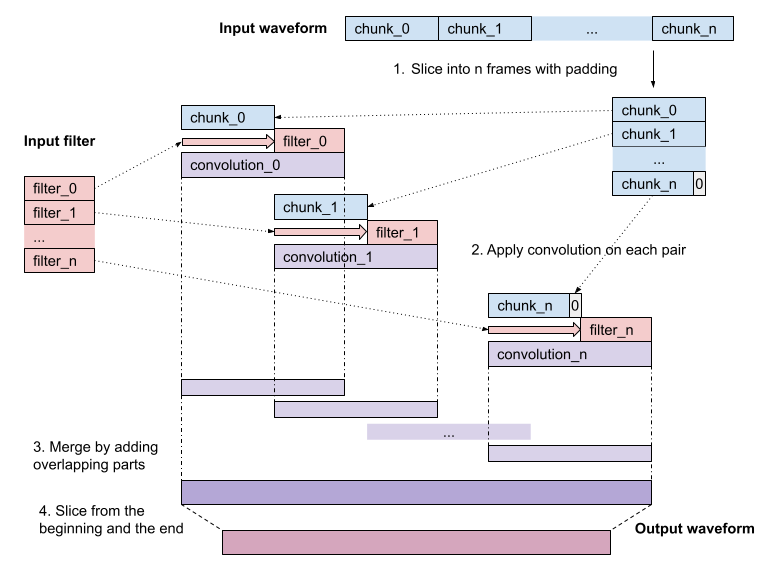 Pull Request resolved: https://github.com/pytorch/audio/pull/2928 Reviewed By: carolineechen Differential Revision: D42199955 Pulled By: mthrok fbshipit-source-id: e822510ab8df98393919bea33768f288f4d661b2
-
- 21 Dec, 2022 1 commit
-
-
moto authored
Summary: This commit makes the following changes to the C++ library organization - Move sox-related feature implementations from `libtorchaudio` to `libtorchaudio_sox`. - Remove C++ implementation of `is_sox_available` and `is_ffmpeg_available` as it is now sufficient to check the existence of `libtorchaudio_sox` and `libtorchaudio_ffmpeg` to check the availability. This makes `libtorchaudio_sox` and `libtorchaudio_ffmpeg` independent from `libtorchaudio`. - Move PyBind11-based bindings (`_torchaudio_sox`, `_torchaudio_ffmpeg`) into `torchaudio.lib` so that the built library structure is less cluttered. Background: Originally, when the `libsox` was the only C++ extension and `libtorchaudio` was supposed to contain all the C++ code. The things are different now. We have a bunch of C++ extensions and we need to make the code/build structure more modular. The new `libtorchaudio_sox` contains the implementations and `_torchaudio_sox` contains the PyBin11-based bindings. Pull Request resolved: https://github.com/pytorch/audio/pull/2929 Reviewed By: hwangjeff Differential Revision: D42159594 Pulled By: mthrok fbshipit-source-id: 1a0fbca9e4143137f6363fc001b2378ce6029aa7
-
- 20 Dec, 2022 1 commit
-
-
moto authored
Summary: If the input video has invalid PTS, the current precise seek fails except when seeking into t=0. This commit updates the discard mechanism to fallback to `best_effort_timestamp` in such cases. `best_effort_timestamp` is just the number of frames went through decoder starting from the beginning of the file. This means if the input file is very long, but seeking towards the end of the file, the StreamReader still decodes all the frames. For videos with valid PTS, `best_effort_timestamp` should be same as `pts`. [[src](https://ffmpeg.org/doxygen/4.1/decode_8c.html#a8d86329cf58a4adbd24ac840d47730cf)] Pull Request resolved: https://github.com/pytorch/audio/pull/2916 Reviewed By: YosuaMichael Differential Revision: D42170204 Pulled By: mthrok fbshipit-source-id: 80c04dc376e0f427d41eb9feb44c251a1648a998
-
- 19 Dec, 2022 2 commits
-
-
moto authored
Summary: `extra_archive` in `datasets.utils` does not distinguish the input type, and blindly treats it as tar, then zip in case of failure. This is an anti-pattern. All the dataset implementations know which archive type the downloaded files are. This commit splits extract_archive function into dedicated functions, and make each dataset use the correct one. Pull Request resolved: https://github.com/pytorch/audio/pull/2927 Reviewed By: carolineechen Differential Revision: D42154069 Pulled By: mthrok fbshipit-source-id: bc46cc2af26aa086ef49aa1f9a94b6dedb55f85e
-
moto authored
Summary: `stream_url`, `download_url` and `validate_file` are not used and not listed in documentation (`download_url` is marked as deprecated) so remove them. This will also fix the failing bandit workflow. Pull Request resolved: https://github.com/pytorch/audio/pull/2926 Reviewed By: carolineechen Differential Revision: D42153484 Pulled By: mthrok fbshipit-source-id: 0fccdc7b7e0e40db8046e12f46eb68de57d838ca
-
- 17 Dec, 2022 1 commit
-
-
moto authored
Summary: Adds filter design tutorial, which demonstrates `sinc_impulse_response` and `frequency_impulse_response`. Example: - [filter_design_tutorial](https://output.circle-artifacts.com/output/job/bd22c615-9215-4b17-a52c-b171a47f646c/artifacts/0/docs/tutorials/filter_design_tutorial.html) Pull Request resolved: https://github.com/pytorch/audio/pull/2894 Reviewed By: xiaohui-zhang Differential Revision: D42117658 Pulled By: mthrok fbshipit-source-id: f7dd04980e8557bb6f0e0ec26ac2c7f53314ea16
-
- 16 Dec, 2022 3 commits
-
-
Caroline Chen authored
Summary: resolves https://github.com/pytorch/audio/issues/2891 Rename `resampling_method` options to more accurately describe what is happening. Previously the methods were set to `sinc_interpolation` and `kaiser_window`, which can be confusing as both options actually use sinc interpolation methodology, but differ in the window function used. As a result, rename `sinc_interpolation` to `sinc_interp_hann` and `kaiser_window` to `sinc_interp_kaiser`. Using an old option will throw a warning, and those options will be deprecated in 2 released. The numerical behavior is unchanged. Pull Request resolved: https://github.com/pytorch/audio/pull/2922 Reviewed By: mthrok Differential Revision: D42083619 Pulled By: carolineechen fbshipit-source-id: 9a9a7ea2d2daeadc02d53dddfd26afe249459e70
-
moto authored
Summary: Updating the version to 2.0.0 to match PyTorch core Pull Request resolved: https://github.com/pytorch/audio/pull/2924 Reviewed By: carolineechen Differential Revision: D42098238 Pulled By: mthrok fbshipit-source-id: 19cb290e493293d1db4211f9bfcdcdffa3e96e45
-
moto authored
Summary: Pull Request resolved: https://github.com/pytorch/audio/pull/2923 Reviewed By: carolineechen Differential Revision: D42090164 Pulled By: mthrok fbshipit-source-id: 4816d9922cc54f42ad2137a3bba1a61f3be68f57
-
- 15 Dec, 2022 1 commit
-
-
DanilBaibak authored
Summary: Switch to Nova MacOS and M1 Wheels. This PR is a step in migrating from CircleCI to the Nova workflow. - [x] Disable the CircleCI builds for MacOS Wheel. - [x] Disable the CircleCI builds for M1 Wheel. - [x] Enable the Nova workflow for MacOS Wheel. - [x] Enable the Nova workflow for M1 Wheel. Pull Request resolved: https://github.com/pytorch/audio/pull/2907 Reviewed By: osalpekar, mthrok Differential Revision: D42040965 Pulled By: DanilBaibak fbshipit-source-id: b87f028cf5686bf97265109591fb0a8c1190324c
-
- 13 Dec, 2022 2 commits
-
-
atalman authored
Summary: Return version from cuda version check so that we can display it in the test details Pull Request resolved: https://github.com/pytorch/audio/pull/2919 Reviewed By: mthrok Differential Revision: D42001252 Pulled By: atalman fbshipit-source-id: 0d8fc3812a13fe098cdf8e0f3df7b66161ba3f95
-
DanilBaibak authored
Summary: Switch to Nova Linux Wheel build. - [x] Disable the CircleCI builds for Linux Wheel. - [x] Enable the Nova workflow for Linux Wheel. ~The Linux Wheel Python3.8 build has been kept because it is a dependency for the `docstring_parameters_sync` job.~ As Omkar pointed out, Docstring Parameters Sync also runs on GHA (https://github.com/pytorch/audio/actions/runs/3638187635/jobs/6140090209). So, we completely switched to the Nova Linux Wheel build. Pull Request resolved: https://github.com/pytorch/audio/pull/2896 Reviewed By: mthrok Differential Revision: D41994993 Pulled By: DanilBaibak fbshipit-source-id: 2bafdbe1b62ef8fa194ce96f4d4667a3ed3dc44f
-
- 12 Dec, 2022 1 commit
-
-
moto authored
Summary: It was reported that when videos with invalid PTS values are fed to StreamReader, StreamReader returns only the last frame. https://github.com/pytorch/vision/blob/677fc939b21a8893f07db4c1f90482b648b6573f/test/assets/videos/RATRACE_wave_f_nm_np1_fr_goo_37.avi ``` import torchaudio src = "RATRACE_wave_f_nm_np1_fr_goo_37.avi" streamer = torchaudio.io.StreamReader(src=src) streamer.add_basic_video_stream(frames_per_chunk=-1) streamer.process_all_packets() video, = streamer.pop_chunks() print(video.size(0)) # prints 1, but there are more than 70 frames ``` The reason why all the frames are not returned is due to invalid PTS values. All the frames's PTS values are `-9223372036854775808` so the internal mechanism discards them. The reason why the last frame is output is because when entering drain mode, the discard value of -1 is used, which is interpreted as no discard. For the second issue, the discard behavior should be consistent across regular decoding and drain mode. For the first issue, although the normal behavior is not guaranteed for such invalid input, we can support the case where one reads video from start (or when one seeks into t=0) --- This commits make the following changes to address the above two. 1. Define the discard_before_pts attribtue on StreamProcessor, so that StreamProcessor is aware of the discard behavior without being told by StreamReader, and its behavior is consistent between regular decoding and drain. This gets rid of the discard_before_pts computation that is currently happening at the every time a frame is processed, so this should improve the peformance a bit. 2. Change the meaning of discard_before_pts, so that when it's 0, no discard happens. With this change, the negative value is not necessary so we put it a UB status. Note: Even with those changes seeking videos with invalid PTS is not plausible, client codes can implement a fallback which decodes frames first and discard undesired ones. Pull Request resolved: https://github.com/pytorch/audio/pull/2915 Reviewed By: nateanl Differential Revision: D41957784 Pulled By: mthrok fbshipit-source-id: 2dafdbada5aa33bfc81c986306f80642ba6277df
-










