- 05 Jan, 2022 1 commit
-
-
moto authored
Summary: MSVS is strict on header and would not allow `std::runtime_error` without `<stdexcept>`. Also this commit removes the stray `"libavutil/frame.h"`, inserted by IDE, which I missed. Ref https://github.com/pytorch/audio/issues/2124 Pull Request resolved: https://github.com/pytorch/audio/pull/2135 Reviewed By: carolineechen Differential Revision: D33419120 Pulled By: mthrok fbshipit-source-id: 328e723b70a3608133d9ddef9fc4a95e5d90e61d
-
- 04 Jan, 2022 6 commits
-
-
moto authored
Summary: This commit enable ffmpeg-feature build on wheel-based binary distribution on macOS. For macOS, since the underlying Python env is Conda, it installs `ffmpeg` from conda. Depends on https://github.com/pytorch/audio/issues/1873 Pull Request resolved: https://github.com/pytorch/audio/pull/2122 Reviewed By: carolineechen, nateanl Differential Revision: D33409113 Pulled By: mthrok fbshipit-source-id: a73839087548010353422109b33e89e262c12a57
-
moto authored
Summary: * Before https://pytorch.org/audio/main/models.html <img width="852" alt="Screen Shot 2022-01-04 at 11 00 12 AM" src="https://user-images.githubusercontent.com/855818/148087255-3b94e63b-9870-4c7e-95c6-17acc1e65fef.png"> *After https://503135-90321822-gh.circle-artifacts.com/0/docs/models.html <img width="842" alt="Screen Shot 2022-01-04 at 10 59 40 AM" src="https://user-images.githubusercontent.com/855818/148087148-b951c7b0-d9cf-4014-8a50-b88c749f12ba.png"> Pull Request resolved: https://github.com/pytorch/audio/pull/2123 Reviewed By: carolineechen Differential Revision: D33409661 Pulled By: mthrok fbshipit-source-id: bb2dffea25ccc4356d257b2ab4a6e88f7f4e2bb3
-
Caroline Chen authored
Summary: update the logic for initializing and updating submodule in setup, now that we have more than one submodule Pull Request resolved: https://github.com/pytorch/audio/pull/2132 Reviewed By: mthrok Differential Revision: D33410039 Pulled By: carolineechen fbshipit-source-id: 6e18ec2904a01efb2f753f65345de063218c0b9b
-
moto authored
Summary: Preparation for updating the build process of ffmpeg-related feature to support Windows. Checking-in FindFFMPEG.cmake from Kitware/VTK repo without modification so that later it's easy to follow our modification on it with git tool. Pull Request resolved: https://github.com/pytorch/audio/pull/2125 Reviewed By: carolineechen Differential Revision: D33405408 Pulled By: mthrok fbshipit-source-id: 5faea8940d2dfcf0b2f647eda3754f713d21fcd1
-
Zhaoheng Ni authored
Summary: In [Fairseq](https://github.com/pytorch/fairseq/blob/main/examples/hubert/config/pretrain/hubert_base_librispeech.yaml#L48), the training applies additional penalty loss besides the cross-entropy losses. This PR adds the feature's mean square value to the model output to support such penalty loss. Pull Request resolved: https://github.com/pytorch/audio/pull/2128 Reviewed By: mthrok Differential Revision: D33403972 Pulled By: nateanl fbshipit-source-id: f08fefa2c975a847c6075171b310f57c1980309d
-
moto authored
Summary: Currently, macOS CI jobs install `pkg-config` and `wget` with `brew`. This is problematic as brew takes a long time with auto-update, and disabling the auto-update is not an ideal solution. Conda also distributes these packages, so switching to conda. Example issues with brew installation. https://app.circleci.com/pipelines/github/pytorch/audio/7825/workflows/53965bcf-6ddf-4e42-ad52-83fd1bbab717 This commit removes the use of `brew` by 1. Replacing the use of `wget` with `curl` (pre-installed in most distro) 2. Install `pkg-condig` from conda. Note: All the macOS jobs, including binary build jobs, uses conda. Using `pkg-config` from Conda makes it easy to discover the packages installed from conda. (like `ffmpeg` in https://github.com/pytorch/audio/issues/2122) 3. Add `pkg-config` to conda build-time dependency 4. Make sure that the availability of `pkg-config` is explicitly checked when `sox` is being configured. (otherwise, it will fail at somewhere in the middle of build process with somewhat unintuitve error message) Pull Request resolved: https://github.com/pytorch/audio/pull/1873 Reviewed By: carolineechen, nateanl Differential Revision: D33404975 Pulled By: mthrok fbshipit-source-id: ae512d3a3a422ebfe3b46c492bed44deecc36e72
-
- 03 Jan, 2022 1 commit
-
-
moto authored
Summary: This commit enable ffmpeg-feature build on conda-based binary distribution on Linux and macOS. It adds `ffmpeg` as build-time dependencies and enable the build with `BUILD_FFMPEG=1`. Windows binaries, wheel-based binaries on Linux/macOS are not changed. Pull Request resolved: https://github.com/pytorch/audio/pull/2120 Reviewed By: nateanl Differential Revision: D33397473 Pulled By: mthrok fbshipit-source-id: 67a23a40c0614c56fee60cc06a45f3265037f6df
-
- 02 Jan, 2022 1 commit
-
-
moto authored
Summary: `libtorchaudio_decoder`, `torchaudio_decoder` and `libtorchaudio_ffmpeg` need not to be linked against `libtorchaudio`. 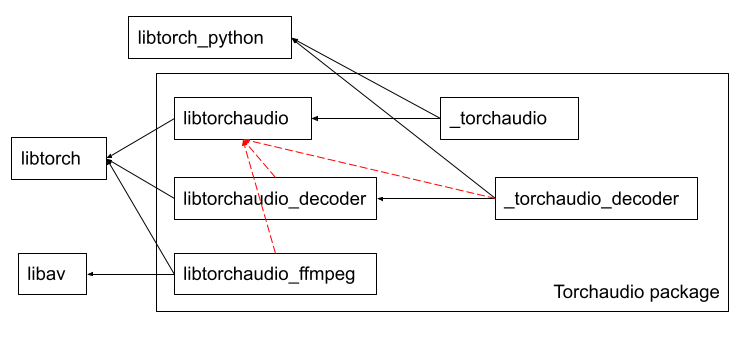 Pull Request resolved: https://github.com/pytorch/audio/pull/2121 Reviewed By: carolineechen Differential Revision: D33389197 Pulled By: mthrok fbshipit-source-id: ebb051e894e17519a87094b8056d26e7a1cd3281
-
- 31 Dec, 2021 2 commits
-
-
Werner Chao authored
Summary: As per item 2 on [issue 2051](https://github.com/pytorch/audio/issues/2051), dropping support for python 3.6. Removed 3.6 from test matrix and ran `.circleci/regenerate.py `. Pull Request resolved: https://github.com/pytorch/audio/pull/2119 Reviewed By: mthrok Differential Revision: D33379542 Pulled By: wernerchao fbshipit-source-id: 6d0fb51b18c2fa7c8cf4eeee4a7f19c4a5210fac
-
Caroline Chen authored
Summary: add documentaion for CTC decoder `Hypothesis` and include it in docs Pull Request resolved: https://github.com/pytorch/audio/pull/2117 Reviewed By: mthrok Differential Revision: D33370381 Pulled By: carolineechen fbshipit-source-id: cf6501a499e5303cda0410f733f0fab4e1c39aff
-
- 30 Dec, 2021 8 commits
-
-
moto authored
Summary: Preparation to land Python front-end of ffmpeg-related features. - Set BUILD_FFMPEG=1 in Linux/macOS unit test jobs - Install ffmpeg and pkg-config from conda-forge - Add note about Windows build process - Temporarily avoid `av_err2str` Pull Request resolved: https://github.com/pytorch/audio/pull/2114 Reviewed By: hwangjeff Differential Revision: D33371346 Pulled By: mthrok fbshipit-source-id: b0e16a35959a49a2166109068f3e0cbbb836e888
-
moto authored
Summary: Pull Request resolved: https://github.com/pytorch/audio/pull/2115 Reviewed By: carolineechen Differential Revision: D33370700 Pulled By: mthrok fbshipit-source-id: 591b67870247f69cc542f649cd62444ee3c45934
-
Joao Gomes authored
Summary: cc mthrok Pull Request resolved: https://github.com/pytorch/audio/pull/2116 Reviewed By: mthrok Differential Revision: D33368453 Pulled By: jdsgomes fbshipit-source-id: 09cf3fe5ed6f771c2f16505633c0e59b0c27453c
-
hwangjeff authored
Summary: * Removes redundant declaration `right_context_blocks = []`, as flagged by kobenaxie. * Adds random seed to tests, as flagged by carolineechen in other PRs. Pull Request resolved: https://github.com/pytorch/audio/pull/2091 Reviewed By: mthrok Differential Revision: D33340964 Pulled By: hwangjeff fbshipit-source-id: a9de43e28d1bae7bd4806b280717b0d822bb42fc
-
moto authored
Summary: This PR adds `BUILD_FFMPEG` switch to torchaudio build process so that features related to ffmpeg are built. The flag is false by default, so no CI jobs or development flow are affected. This is because handling the dependencies around ffmpeg is a bit tricky. Currently, the CMake file uses `pkg-config` to find an ffmpeg installation in the system. This works fine for both conda-based installation and system-managed installation (like `apt`). In subsequent PRs, I will find a solution that works for local development and binary distributions. Pull Request resolved: https://github.com/pytorch/audio/pull/2048 Reviewed By: hwangjeff, nateanl Differential Revision: D33367260 Pulled By: mthrok fbshipit-source-id: 94517acecb62bd6d4e96d4b7cbc3ab3c2a25706c
-
moto authored
Summary: - Introduce AudioBuffer and VideoBuffer for different way of handling frames - Update the way option dictionary is passed - Remove unused AutoFrameUnref - Add SrcStreamInfo/OutputStreamInfo classes Pull Request resolved: https://github.com/pytorch/audio/pull/2113 Reviewed By: nateanl Differential Revision: D33356144 Pulled By: mthrok fbshipit-source-id: e837e84fae48baa7befd5c70599bcd2cbb61514d
-
 CodemodService Bot authored
CodemodService Bot authoredReviewed By: zertosh Differential Revision: D33361077 fbshipit-source-id: 007db010bd38c28f597ea66f68f97b13309e878c
-
moto authored
Summary: Part of https://github.com/pytorch/audio/issues/1986. Splitting the PR for easier review. Add `Streamer` TorchBind. For the overall architecture, see https://github.com/mthrok/audio/blob/ffmpeg/torchaudio/csrc/ffmpeg/README.md. Note: Without a change to build process, the code added here won't be compiled. The build process will be updated later. Needs to be imported after https://github.com/pytorch/audio/issues/2046. Pull Request resolved: https://github.com/pytorch/audio/pull/2047 Reviewed By: hwangjeff Differential Revision: D33355190 Pulled By: mthrok fbshipit-source-id: a3ad4c2822ed3a7ddc19b1aaca9dddabd59ce2f8
-
- 29 Dec, 2021 9 commits
-
-
hwangjeff authored
Summary: Adds parameter `p` to `TimeMasking` to allow for enforcing an upper bound on the proportion of time steps that it can mask. This behavior is consistent with the specifications provided in the SpecAugment paper (https://arxiv.org/abs/1904.08779). Pull Request resolved: https://github.com/pytorch/audio/pull/2090 Reviewed By: carolineechen Differential Revision: D33344772 Pulled By: hwangjeff fbshipit-source-id: 6ff65f5304e489fa1c23e15c3d96b9946229fdcf
-
Caroline Chen authored
Summary: Additionally accept list of tokens as CTC decoder input. This makes it possible to directly pass in something like `bundles.get_labels()` into the decoder factory function instead of requiring a separate tokens file. Pull Request resolved: https://github.com/pytorch/audio/pull/2112 Reviewed By: hwangjeff, nateanl, mthrok Differential Revision: D33352909 Pulled By: carolineechen fbshipit-source-id: 6d22072e34f6cd7c6f931ce4eaf294ae4cf0c5cc
-
moto authored
Summary: Part of https://github.com/pytorch/audio/issues/1986. Splitting the PR for easier review. Add `Streamer` class that bundles `StreamProcessor` and handle input. For the overall architecture, see https://github.com/mthrok/audio/blob/ffmpeg/torchaudio/csrc/ffmpeg/README.md. Note: Without a change to build process, the code added here won't be compiled. The build process will be updated later. Needs to be imported after https://github.com/pytorch/audio/issues/2045. Pull Request resolved: https://github.com/pytorch/audio/pull/2046 Reviewed By: carolineechen Differential Revision: D33299863 Pulled By: mthrok fbshipit-source-id: 6470cbe061057c8cb970ce7bb5692be04efb5fe9
-
hwangjeff authored
Summary: Regroup RNN-T components under `torchaudio.prototype.models` and `torchaudio.prototype.pipelines`. Updated docs: https://492321-90321822-gh.circle-artifacts.com/0/docs/prototype.html Pull Request resolved: https://github.com/pytorch/audio/pull/2110 Reviewed By: carolineechen, mthrok Differential Revision: D33354116 Pulled By: hwangjeff fbshipit-source-id: 9cf4afed548cb173d56211c16d31bcfa25a8e4cb
-
moto authored
Summary: Part of https://github.com/pytorch/audio/issues/1986. Splitting the PR for easier review. Add StreamProcessor class that bundles `Buffer`, `FilterGraph` and `Decoder`. Note: The API to retrieve the buffered Tensors is tentative. For the overall architecture, see https://github.com/mthrok/audio/blob/ffmpeg/torchaudio/csrc/ffmpeg/README.md. Note: Without a change to build process, the code added here won't be compiled. The build process will be updated later. Needs to be imported after https://github.com/pytorch/audio/issues/2044. Pull Request resolved: https://github.com/pytorch/audio/pull/2045 Reviewed By: carolineechen Differential Revision: D33299858 Pulled By: mthrok fbshipit-source-id: d85bececed475f45622743f137dd59cb1390ceed
-
moto authored
Summary: Add Sink class that bundles FilterGraph and Buffer. Part of https://github.com/pytorch/audio/issues/1986. Splitting the PR for easier review. For the overall architecture, see https://github.com/mthrok/audio/blob/ffmpeg/torchaudio/csrc/ffmpeg/README.md. Note: Without a change to build process, the code added here won't be compiled. The build process will be updated later. Pull Request resolved: https://github.com/pytorch/audio/pull/2111 Reviewed By: carolineechen Differential Revision: D33350388 Pulled By: mthrok fbshipit-source-id: 8f42c5fe4be39ef2432c51fc0d0ac72ba3f06a26
-
CodemodService Bot authored
Reviewed By: zertosh Differential Revision: D33347867 fbshipit-source-id: 7672f65392e363c0359de2d86e745782a09cf9dc
-
moto authored
Summary: ### Change list * Split the documentation of prototypes * Add a new API reference section dedicated for prototypes. * Hide the signature of KenLMLexiconDecoder constructor. (cc carolineechen ) * https://489516-90321822-gh.circle-artifacts.com/0/docs/prototype.ctc_decoder.html#torchaudio.prototype.ctc_decoder.KenLMLexiconDecoder * Hide the signature of RNNT constructor. (cc hwangjeff ) * https://489516-90321822-gh.circle-artifacts.com/0/docs/prototype.rnnt.html#torchaudio.prototype.RNNT * Tweak CTC tutorial * Replace hyperlinks to API reference with backlinks * Add `progress=False` to download ### Follow-up RNNT decoder and CTC decode returns their own `Hypothesis` classes. When I tried to add Hypothesis of CTC decode to the documentation, the build process complains that it's ambiguous. I think the Hypothesis classes can be put inside of each decoder. (if TorchScript supports it) or make the name different, but in that case the interface of each Hypothesis has to be generic enough. ### Before https://pytorch.org/audio/main/prototype.html <img width="1390" alt="Screen Shot 2021-12-28 at 1 05 53 PM" src="https://user-images.githubusercontent.com/855818/147594425-6c7f8126-ab76-4edc-a616-a00901e7e9ef.png"> ### After https://489516-90321822-gh.circle-artifacts.com/0/docs/prototype.html <img width="1202" alt="Screen Shot 2021-12-28 at 8 37 35 PM" src="https://user-images.githubusercontent.com/855818/147619281-8152b1ae-e127-40b2-a944-dc11b114b629.png"> https://489516-90321822-gh.circle-artifacts.com/0/docs/prototype.rnnt.html <img width="1415" alt="Screen Shot 2021-12-28 at 8 38 27 PM" src="https://user-images.githubusercontent.com/855818/147619331-077b55b5-c5e9-47ab-bfe6-873e41c738c8.png"> https://489516-90321822-gh.circle-artifacts.com/0/docs/prototype.ctc_decoder.html <img width="1417" alt="Screen Shot 2021-12-28 at 8 39 04 PM" src="https://user-images.githubusercontent.com/855818/147619364-63df3457-a4b2-4223-973f-f4301bd45280.png"> Pull Request resolved: https://github.com/pytorch/audio/pull/2108 Reviewed By: hwangjeff, carolineechen, nateanl Differential Revision: D33340816 Pulled By: mthrok fbshipit-source-id: 870edfadbe41d6f8abaf78fdb7017b3980dfe187
-
hwangjeff authored
Summary: Adds pretrained Emformer RNN-T inference pipeline that's capable of performing streaming and non-streaming ASR. Includes demo script that uses pipeline to alternately perform streaming and non-streaming ASR on LibriSpeech test samples (video below). https://user-images.githubusercontent.com/8345689/147590753-d5126557-d575-4551-8dfe-5977276cb4ad.mov Pull Request resolved: https://github.com/pytorch/audio/pull/2093 Reviewed By: mthrok Differential Revision: D33340776 Pulled By: hwangjeff fbshipit-source-id: fbb3b1d471b4e9f1b93fa9dea9c464154537a8ac
-
- 28 Dec, 2021 6 commits
-
-
Zhaoheng Ni authored
Summary: Remove it as it's already introduced in the [gallery](https://github.com/pytorch/audio/blob/main/examples/tutorials/mvdr_tutorial.py). Pull Request resolved: https://github.com/pytorch/audio/pull/2109 Reviewed By: carolineechen Differential Revision: D33341574 Pulled By: nateanl fbshipit-source-id: e5c1c8537063b9453947dc3ecafa70e9b6c74146
-
Caroline Chen authored
Summary: demonstrate usage of the CTC beam search decoder w/ lexicon constraint and KenLM support, on a LibriSpeech sample and using a pretrained wav2vec2 model rendered: https://485200-90321822-gh.circle-artifacts.com/0/docs/tutorials/asr_inference_with_ctc_decoder_tutorial.html follow-ups: - incorporate `nbest` - demonstrate customizability of different beam search parameters Pull Request resolved: https://github.com/pytorch/audio/pull/2106 Reviewed By: mthrok Differential Revision: D33340946 Pulled By: carolineechen fbshipit-source-id: 0ab838375d96a035d54ed5b5bd9ab4dc8d19adb7
-
Zhaoheng Ni authored
Summary: - Add three factory functions:`hubert_pretrain_base`, `hubert_pretrain_large`, and `hubert_pretrain_xlarge`, to enable the HuBERT model to train from scratch. - Add `num_classes` argument to `hubert_pretrain_base` factory function because the base model has two iterations of training, the first iteration the `num_cluster` is 100, in the second iteration `num_cluster` is 500. - The model takes `waveforms`, `labels`, and `lengths` as inputs - The model generates the last layer of transformer embedding, `logit_m`, `logit_u` as the outputs. Pull Request resolved: https://github.com/pytorch/audio/pull/2064 Reviewed By: hwangjeff, mthrok Differential Revision: D33338587 Pulled By: nateanl fbshipit-source-id: 534bc17c576c5f344043d8ba098204b8da6e630a
-
moto authored
Summary: *Before:* https://pytorch.org/audio/main/tutorials/audio_data_augmentation_tutorial.html#effects-applied <img width="831" alt="Screen Shot 2021-12-28 at 11 25 08 AM" src="https://user-images.githubusercontent.com/855818/147586457-55d566bf-f016-4327-a07e-5de68f80e984.png"> *After:* https://484994-90321822-gh.circle-artifacts.com/0/docs/tutorials/audio_data_augmentation_tutorial.html#effects-applied <img width="830" alt="Screen Shot 2021-12-28 at 11 25 57 AM" src="https://user-images.githubusercontent.com/855818/147586531-90333201-b9e3-450f-a2d7-6fb987b7e9d9.png"> Pull Request resolved: https://github.com/pytorch/audio/pull/2107 Reviewed By: carolineechen Differential Revision: D33337164 Pulled By: mthrok fbshipit-source-id: 20e3309f0d11d46619f516dc46d967b34f22ec95
-
moto authored
Summary: This commit updates the documentation configuration so that if an API (function or class) is used in tutorials, then it automatically add the links to the tutorials. It also adds `py:func:` so that it's easy to jump from tutorials to API reference. Note: the use of `py:func:` is not required to be recognized by Shpinx-gallery. * https://482162-90321822-gh.circle-artifacts.com/0/docs/transforms.html#feature-extractions <img width="776" alt="Screen Shot 2021-12-24 at 12 41 43 PM" src="https://user-images.githubusercontent.com/855818/147367407-cd86f114-7177-426a-b5ee-a25af17ae476.png"> * https://482162-90321822-gh.circle-artifacts.com/0/docs/transforms.html#mvdr <img width="769" alt="Screen Shot 2021-12-24 at 12 42 31 PM" src="https://user-images.githubusercontent.com/855818/147367422-01fd245f-2f25-4875-a206-910e17ae0161.png"> Pull Request resolved: https://github.com/pytorch/audio/pull/2101 Reviewed By: hwangjeff Differential Revision: D33311283 Pulled By: mthrok fbshipit-source-id: e0c124d2a761e0f8d81c3d14c4ffc836ffffe288
-
moto authored
Summary: *Before* <img width="1094" alt="Screen Shot 2021-12-24 at 12 34 14 PM" src="https://user-images.githubusercontent.com/855818/147367213-b1e539c1-6e06-4e9b-aaf4-0458c502379b.png"> *After* https://app.circleci.com/pipelines/github/pytorch/audio/8870/workflows/0445f1ac-ad48-412f-8045-2400d0cef4f4/jobs/482060 <img width="1096" alt="Screen Shot 2021-12-24 at 12 33 32 PM" src="https://user-images.githubusercontent.com/855818/147367210-a9b759bb-f992-4dc1-9359-0ec3912b3070.png"> Pull Request resolved: https://github.com/pytorch/audio/pull/2102 Reviewed By: carolineechen Differential Revision: D33311253 Pulled By: mthrok fbshipit-source-id: 6944921a8be58a2062b66a7dfd2c7ffe8c0866c3
-
- 24 Dec, 2021 2 commits
-
-
CodemodService Bot authored
Reviewed By: zertosh Differential Revision: D33307283 fbshipit-source-id: 55a95689b8c20b17b7c882070bc3e24706c44444
-
moto authored
Summary: Part of https://github.com/pytorch/audio/issues/1986. Splitting the PR for easier review. Add Buffer class that is responsible for converting `AVFrame` to `Tensor`. Note: The API to retrieve the buffered Tensors is tentative. For the overall architecture, see https://github.com/mthrok/audio/blob/ffmpeg/torchaudio/csrc/ffmpeg/README.md. Note: Without a change to build process, the code added here won't be compiled. The build process will be updated later. Needs to be imported after https://github.com/pytorch/audio/issues/2043. Pull Request resolved: https://github.com/pytorch/audio/pull/2044 Reviewed By: carolineechen Differential Revision: D32940553 Pulled By: mthrok fbshipit-source-id: 8b8b2222ad7b47edc17e9139420e8a71c00d726a
-
- 23 Dec, 2021 4 commits
-
-
moto authored
Summary: Part of https://github.com/pytorch/audio/issues/1986. Splitting the PR for easier review. Add FilterGraph class that is responsible for handling AVFilterGraph structure and the application of filters. For the overall architecture, see https://github.com/mthrok/audio/blob/ffmpeg/torchaudio/csrc/ffmpeg/README.md. Note: Without a change to build process, the code added here won't be compiled. The build process will be updated later. Needs to be imported after https://github.com/pytorch/audio/issues/2042. Pull Request resolved: https://github.com/pytorch/audio/pull/2043 Reviewed By: carolineechen Differential Revision: D32940535 Pulled By: mthrok fbshipit-source-id: 231e3ad17df2d67b6c7b323e5c89e718a3d48d0d
-
Caroline Chen authored
Summary: Part of https://github.com/pytorch/audio/issues/2072 -- splitting up PR for easier review This PR adds Python decoder API and basic README Pull Request resolved: https://github.com/pytorch/audio/pull/2089 Reviewed By: mthrok Differential Revision: D33299818 Pulled By: carolineechen fbshipit-source-id: 778ec3692331e95258d3734f0d4ab60b6618ddbc
-
Joao Gomes authored
Summary: Pull Request resolved: https://github.com/pytorch/audio/pull/2096 run: `arc lint --apply-patches --paths-cmd 'hg files -I "./**/*.py"'` Reviewed By: mthrok Differential Revision: D33297351 fbshipit-source-id: 7bf5956edf0717c5ca90219f72414ff4eeaf5aa8
-
moto authored
Summary: Follow-up of https://github.com/pytorch/audio/issues/2086 The CI job to download the third party code and cache daily has not been properly updated. Pull Request resolved: https://github.com/pytorch/audio/pull/2095 Reviewed By: hwangjeff Differential Revision: D33291738 Pulled By: mthrok fbshipit-source-id: 6fc61f76b35c6f032085eda9d6053eefd2a1e0a9
-





