- 30 Dec, 2022 3 commits
-
-
Zhaoheng Ni authored
Summary: The `root` path can be confusing to users without reading the document. The PR adds runtime error for a better understanding. Pull Request resolved: https://github.com/pytorch/audio/pull/2944 Reviewed By: mthrok Differential Revision: D42281034 Pulled By: nateanl fbshipit-source-id: 6e5f4bfb118583d678d6b7a2565ef263fe8e4a5a
-
moto authored
Summary: This commit refactors and optimizes functions that converts AVFrames of `yuv420p` and `nv12` into PyTorch's Tensor. The performance is improved about 30%. 1. Reduce the number of intermediate Tensors allocated. 2. Replace 2 calls to `repeat_interleave` with `F::interpolate`. * (`F::interpolate` is about 5x faster than `repeat_interleave`. ) <details><summary>code</summary> ```bash #!/usr/bin/env bash set -e python -c """ import torch import torch.nn.functional as F a = torch.arange(49, dtype=torch.uint8).reshape(7, 7).clone() val1 = a.repeat_interleave(2, -1).repeat_interleave(2, -2) val2 = F.interpolate(a.view((1, 1, 7, 7, 1)), size=[14, 14, 1], mode=\"nearest\") print(torch.sum(torch.abs(val1 - val2[0, 0, :, :, 0]))) """ python3 -m timeit \ --setup """ import torch a = torch.arange(49, dtype=torch.uint8).reshape(7, 7).clone() """ \ """ a.repeat_interleave(2, -1).repeat_interleave(2, -2) """ python3 -m timeit \ --setup """ import torch import torch.nn.functional as F a = torch.arange(49, dtype=torch.uint8).reshape(7, 7).clone() """ \ """ F.interpolate(a.view((1, 1, 7, 7, 1)), size=[14, 14, 1], mode=\"nearest\") """ ``` </details> ``` tensor(0) 10000 loops, best of 5: 38.3 usec per loop 50000 loops, best of 5: 7.1 usec per loop ``` ## Benchmark Result <details><summary>code</summary> ```bash #!/usr/bin/env bash set -e mkdir -p tmp for ext in avi mp4; do for duration in 1 5 10 30 60; do printf "Testing ${ext} ${duration} [sec]\n" test_data="tmp/test_${duration}.${ext}" if [ ! -f "${test_data}" ]; then printf "Generating test data\n" ffmpeg -hide_banner -f lavfi -t ${duration} -i testsrc "${test_data}" > /dev/null 2>&1 fi python -m timeit \ --setup="from torchaudio.io import StreamReader" \ """ r = StreamReader(\"${test_data}\") r.add_basic_video_stream(frames_per_chunk=-1, format=\"yuv420p\") r.process_all_packets() r.pop_chunks() """ done done ``` </details> 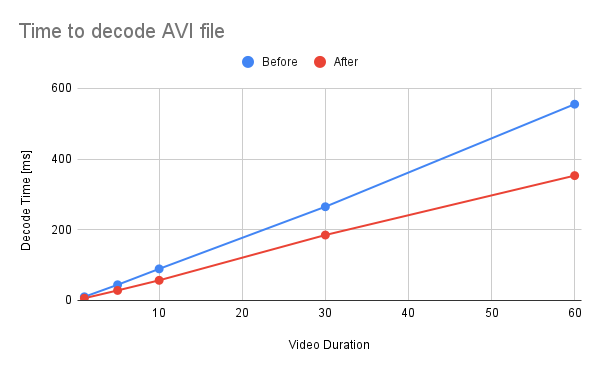 <details><summary>raw data</summary> Video Type - AVI Duration | Before | After -- | -- | -- 1 | 10.3 | 6.29 5 | 44.3 | 28.3 10 | 89.3 | 56.9 30 | 265 | 185 60 | 555 | 353 </details> 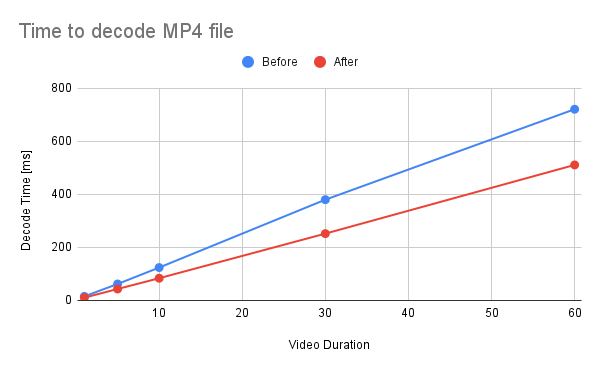 <details><summary>raw data</summary> Video Type - MP4 Duration | Before | After -- | -- | -- 1 | 15.3 | 10.5 5 | 62.1 | 43.2 10 | 124 | 83.8 30 | 380 | 252 60 | 721 | 511 </details> Pull Request resolved: https://github.com/pytorch/audio/pull/2945 Reviewed By: carolineechen Differential Revision: D42283269 Pulled By: mthrok fbshipit-source-id: 59840f943ff516b69ab8ad35fed7104c48a0bf0c -
moto authored
Summary: Artifact: [subtractive_synthesis_tutorial](https://output.circle-artifacts.com/output/job/4c1ce33f-834d-48e0-ba89-2e91acdcb572/artifacts/0/docs/tutorials/subtractive_synthesis_tutorial.html) Pull Request resolved: https://github.com/pytorch/audio/pull/2934 Reviewed By: carolineechen Differential Revision: D42284945 Pulled By: mthrok fbshipit-source-id: d255b8e8e2a601a19bc879f9e1c38edbeebaf9b3
-
- 29 Dec, 2022 3 commits
-
-
TruscaPetre authored
Summary: I have spent 2 hours because I read the documentation wrongly and trying to figure out why the I couldn't read the data from the dataset. The initial phrase was very confusing. Pull Request resolved: https://github.com/pytorch/audio/pull/2937 Reviewed By: mthrok Differential Revision: D42280738 Pulled By: nateanl fbshipit-source-id: a48b9bc27d44ca8106bd56f805294a5a0e3ede1b
-
moto authored
Summary: Pull Request resolved: https://github.com/pytorch/audio/pull/2930 Reviewed By: carolineechen, nateanl Differential Revision: D42280966 Pulled By: mthrok fbshipit-source-id: f9d5f1dc7c1a62d932fb2020aafb63734f2bf405
-
moto authored
Summary: * move helper functions to `detail` namespace. * move helper functions out of `buffer.h` Pull Request resolved: https://github.com/pytorch/audio/pull/2943 Reviewed By: carolineechen Differential Revision: D42271652 Pulled By: mthrok fbshipit-source-id: abbfc8e8bac97d4eeb34221d4c20763477bd982e
-
- 28 Dec, 2022 1 commit
-
-
moto authored
Summary: Refactor the two helper functions that convert AVFrame to torch::Tensor into separate buffer allocation and data copy. Pull Request resolved: https://github.com/pytorch/audio/pull/2940 Reviewed By: carolineechen Differential Revision: D42247915 Pulled By: mthrok fbshipit-source-id: 2f504d48674088205e6039e8aadd8856b3fe5eee
-
- 27 Dec, 2022 1 commit
-
-
moto authored
Summary: The `Buffer` class is responsible for converting `AVFrame` into `torch::Tensor` and storing the frames in accordance to `frames_per_chunk` and `buffer_chunk_size`. There are four operating modes of Buffer; [audio|video] x [chunked|unchunked]. Audio and video have a separate class implementations, but the behavior of chunked/unchunked depends on `frames_per_chunk<0` or not. Chunked mode is where frames should be returned by chunk of a unit number frames, while unchunked mode is where frames are returned as-is. When frames are accumulated, in chunked mode, old frames are dropped, while in unchunked mode all the frames are retained. Currently, the underlying buffer implementations are the same `std::dequeu<torch::Tensor>`. As we plan to make chunked-mode behavior more efficient by changing the underlying buffer container, it will be easier if the unchuked-mode behavior is kept as-is as a separate class. This commit makes the following changes. * Change `Buffer` class into pure virtual class (interface). * Split `AudioBuffer` into` UnchunkedAudioBuffer` and `ChunkedAudioBuffer`. * Split `VideoBuffer` into` UnchunkedVideoBuffer` and `ChunkedVideoBuffer`. Pull Request resolved: https://github.com/pytorch/audio/pull/2939 Reviewed By: carolineechen Differential Revision: D42247509 Pulled By: mthrok fbshipit-source-id: 7363e442a5b2db5dcbaaf0ffbfa702e088726d1b
-
- 22 Dec, 2022 1 commit
-
-
moto authored
Summary: This commit adds "filter_waveform" prototype function. This function can apply non-stationary filters across the time. It also performs cropping at the end to compensate the delay introduced by filtering. The figure bellow illustrates this. See [subtractive_synthesis_tutorial](https://output.circle-artifacts.com/output/job/5233fda9-dadb-4710-9389-7e8ac20a062f/artifacts/0/docs/tutorials/subtractive_synthesis_tutorial.html) for example usages. 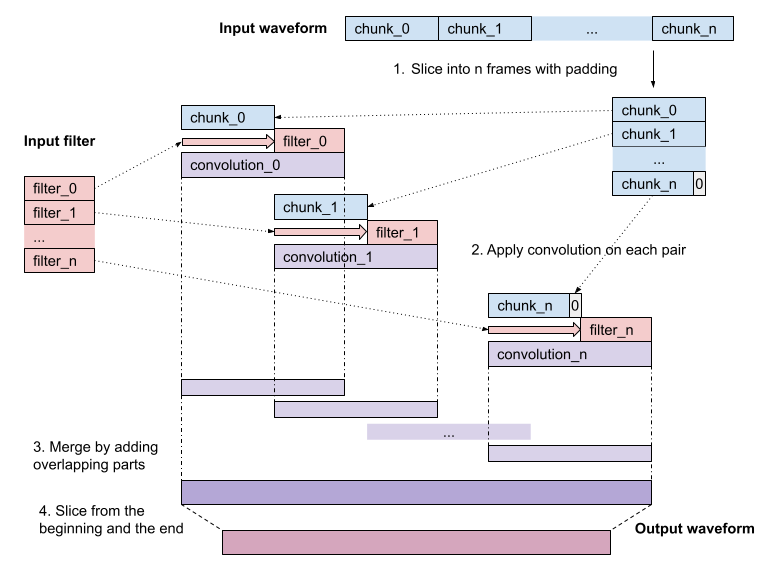 Pull Request resolved: https://github.com/pytorch/audio/pull/2928 Reviewed By: carolineechen Differential Revision: D42199955 Pulled By: mthrok fbshipit-source-id: e822510ab8df98393919bea33768f288f4d661b2
-
- 21 Dec, 2022 1 commit
-
-
moto authored
Summary: This commit makes the following changes to the C++ library organization - Move sox-related feature implementations from `libtorchaudio` to `libtorchaudio_sox`. - Remove C++ implementation of `is_sox_available` and `is_ffmpeg_available` as it is now sufficient to check the existence of `libtorchaudio_sox` and `libtorchaudio_ffmpeg` to check the availability. This makes `libtorchaudio_sox` and `libtorchaudio_ffmpeg` independent from `libtorchaudio`. - Move PyBind11-based bindings (`_torchaudio_sox`, `_torchaudio_ffmpeg`) into `torchaudio.lib` so that the built library structure is less cluttered. Background: Originally, when the `libsox` was the only C++ extension and `libtorchaudio` was supposed to contain all the C++ code. The things are different now. We have a bunch of C++ extensions and we need to make the code/build structure more modular. The new `libtorchaudio_sox` contains the implementations and `_torchaudio_sox` contains the PyBin11-based bindings. Pull Request resolved: https://github.com/pytorch/audio/pull/2929 Reviewed By: hwangjeff Differential Revision: D42159594 Pulled By: mthrok fbshipit-source-id: 1a0fbca9e4143137f6363fc001b2378ce6029aa7
-
- 20 Dec, 2022 1 commit
-
-
moto authored
Summary: If the input video has invalid PTS, the current precise seek fails except when seeking into t=0. This commit updates the discard mechanism to fallback to `best_effort_timestamp` in such cases. `best_effort_timestamp` is just the number of frames went through decoder starting from the beginning of the file. This means if the input file is very long, but seeking towards the end of the file, the StreamReader still decodes all the frames. For videos with valid PTS, `best_effort_timestamp` should be same as `pts`. [[src](https://ffmpeg.org/doxygen/4.1/decode_8c.html#a8d86329cf58a4adbd24ac840d47730cf)] Pull Request resolved: https://github.com/pytorch/audio/pull/2916 Reviewed By: YosuaMichael Differential Revision: D42170204 Pulled By: mthrok fbshipit-source-id: 80c04dc376e0f427d41eb9feb44c251a1648a998
-
- 19 Dec, 2022 2 commits
-
-
moto authored
Summary: `extra_archive` in `datasets.utils` does not distinguish the input type, and blindly treats it as tar, then zip in case of failure. This is an anti-pattern. All the dataset implementations know which archive type the downloaded files are. This commit splits extract_archive function into dedicated functions, and make each dataset use the correct one. Pull Request resolved: https://github.com/pytorch/audio/pull/2927 Reviewed By: carolineechen Differential Revision: D42154069 Pulled By: mthrok fbshipit-source-id: bc46cc2af26aa086ef49aa1f9a94b6dedb55f85e
-
moto authored
Summary: `stream_url`, `download_url` and `validate_file` are not used and not listed in documentation (`download_url` is marked as deprecated) so remove them. This will also fix the failing bandit workflow. Pull Request resolved: https://github.com/pytorch/audio/pull/2926 Reviewed By: carolineechen Differential Revision: D42153484 Pulled By: mthrok fbshipit-source-id: 0fccdc7b7e0e40db8046e12f46eb68de57d838ca
-
- 17 Dec, 2022 1 commit
-
-
moto authored
Summary: Adds filter design tutorial, which demonstrates `sinc_impulse_response` and `frequency_impulse_response`. Example: - [filter_design_tutorial](https://output.circle-artifacts.com/output/job/bd22c615-9215-4b17-a52c-b171a47f646c/artifacts/0/docs/tutorials/filter_design_tutorial.html) Pull Request resolved: https://github.com/pytorch/audio/pull/2894 Reviewed By: xiaohui-zhang Differential Revision: D42117658 Pulled By: mthrok fbshipit-source-id: f7dd04980e8557bb6f0e0ec26ac2c7f53314ea16
-
- 16 Dec, 2022 3 commits
-
-
Caroline Chen authored
Summary: resolves https://github.com/pytorch/audio/issues/2891 Rename `resampling_method` options to more accurately describe what is happening. Previously the methods were set to `sinc_interpolation` and `kaiser_window`, which can be confusing as both options actually use sinc interpolation methodology, but differ in the window function used. As a result, rename `sinc_interpolation` to `sinc_interp_hann` and `kaiser_window` to `sinc_interp_kaiser`. Using an old option will throw a warning, and those options will be deprecated in 2 released. The numerical behavior is unchanged. Pull Request resolved: https://github.com/pytorch/audio/pull/2922 Reviewed By: mthrok Differential Revision: D42083619 Pulled By: carolineechen fbshipit-source-id: 9a9a7ea2d2daeadc02d53dddfd26afe249459e70
-
moto authored
Summary: Updating the version to 2.0.0 to match PyTorch core Pull Request resolved: https://github.com/pytorch/audio/pull/2924 Reviewed By: carolineechen Differential Revision: D42098238 Pulled By: mthrok fbshipit-source-id: 19cb290e493293d1db4211f9bfcdcdffa3e96e45
-
moto authored
Summary: Pull Request resolved: https://github.com/pytorch/audio/pull/2923 Reviewed By: carolineechen Differential Revision: D42090164 Pulled By: mthrok fbshipit-source-id: 4816d9922cc54f42ad2137a3bba1a61f3be68f57
-
- 15 Dec, 2022 1 commit
-
-
DanilBaibak authored
Summary: Switch to Nova MacOS and M1 Wheels. This PR is a step in migrating from CircleCI to the Nova workflow. - [x] Disable the CircleCI builds for MacOS Wheel. - [x] Disable the CircleCI builds for M1 Wheel. - [x] Enable the Nova workflow for MacOS Wheel. - [x] Enable the Nova workflow for M1 Wheel. Pull Request resolved: https://github.com/pytorch/audio/pull/2907 Reviewed By: osalpekar, mthrok Differential Revision: D42040965 Pulled By: DanilBaibak fbshipit-source-id: b87f028cf5686bf97265109591fb0a8c1190324c
-
- 13 Dec, 2022 2 commits
-
-
atalman authored
Summary: Return version from cuda version check so that we can display it in the test details Pull Request resolved: https://github.com/pytorch/audio/pull/2919 Reviewed By: mthrok Differential Revision: D42001252 Pulled By: atalman fbshipit-source-id: 0d8fc3812a13fe098cdf8e0f3df7b66161ba3f95
-
DanilBaibak authored
Summary: Switch to Nova Linux Wheel build. - [x] Disable the CircleCI builds for Linux Wheel. - [x] Enable the Nova workflow for Linux Wheel. ~The Linux Wheel Python3.8 build has been kept because it is a dependency for the `docstring_parameters_sync` job.~ As Omkar pointed out, Docstring Parameters Sync also runs on GHA (https://github.com/pytorch/audio/actions/runs/3638187635/jobs/6140090209). So, we completely switched to the Nova Linux Wheel build. Pull Request resolved: https://github.com/pytorch/audio/pull/2896 Reviewed By: mthrok Differential Revision: D41994993 Pulled By: DanilBaibak fbshipit-source-id: 2bafdbe1b62ef8fa194ce96f4d4667a3ed3dc44f
-
- 12 Dec, 2022 1 commit
-
-
moto authored
Summary: It was reported that when videos with invalid PTS values are fed to StreamReader, StreamReader returns only the last frame. https://github.com/pytorch/vision/blob/677fc939b21a8893f07db4c1f90482b648b6573f/test/assets/videos/RATRACE_wave_f_nm_np1_fr_goo_37.avi ``` import torchaudio src = "RATRACE_wave_f_nm_np1_fr_goo_37.avi" streamer = torchaudio.io.StreamReader(src=src) streamer.add_basic_video_stream(frames_per_chunk=-1) streamer.process_all_packets() video, = streamer.pop_chunks() print(video.size(0)) # prints 1, but there are more than 70 frames ``` The reason why all the frames are not returned is due to invalid PTS values. All the frames's PTS values are `-9223372036854775808` so the internal mechanism discards them. The reason why the last frame is output is because when entering drain mode, the discard value of -1 is used, which is interpreted as no discard. For the second issue, the discard behavior should be consistent across regular decoding and drain mode. For the first issue, although the normal behavior is not guaranteed for such invalid input, we can support the case where one reads video from start (or when one seeks into t=0) --- This commits make the following changes to address the above two. 1. Define the discard_before_pts attribtue on StreamProcessor, so that StreamProcessor is aware of the discard behavior without being told by StreamReader, and its behavior is consistent between regular decoding and drain. This gets rid of the discard_before_pts computation that is currently happening at the every time a frame is processed, so this should improve the peformance a bit. 2. Change the meaning of discard_before_pts, so that when it's 0, no discard happens. With this change, the negative value is not necessary so we put it a UB status. Note: Even with those changes seeking videos with invalid PTS is not plausible, client codes can implement a fallback which decodes frames first and discard undesired ones. Pull Request resolved: https://github.com/pytorch/audio/pull/2915 Reviewed By: nateanl Differential Revision: D41957784 Pulled By: mthrok fbshipit-source-id: 2dafdbada5aa33bfc81c986306f80642ba6277df
-
- 11 Dec, 2022 1 commit
-
-
Caroline Chen authored
Summary: replace "example" primary label with "tutorial" and "recipe" cc pytorch/team-audio-core Pull Request resolved: https://github.com/pytorch/audio/pull/2912 Reviewed By: nateanl, mthrok Differential Revision: D41897772 Pulled By: carolineechen fbshipit-source-id: e20540c6f302b5dcc56663a2c074b14a48e4d3e1
-
- 10 Dec, 2022 2 commits
-
-
Zhaoheng Ni authored
Summary: The `src` or `dst` argument can be `str` or `file-like object`. Setting it to `str` in type annotation will confuse users that it only accepts `str` type. Pull Request resolved: https://github.com/pytorch/audio/pull/2913 Reviewed By: mthrok Differential Revision: D41896668 Pulled By: nateanl fbshipit-source-id: 1446a9f84186a0376cdbe4c61817fae4d5eaaab4
-
moto authored
Summary: Currently, the documentation page for `torchaudio.models` have separate sections for model definitions and factory functions. The relationships between models and factory functions are not immediately clear. This commit moves the list of factory functions to the list of models. After: - https://output.circle-artifacts.com/output/job/242a9521-7460-4043-895b-9995bf5093b5/artifacts/0/docs/generated/torchaudio.models.Wav2Vec2Model.html <img width="1171" alt="Screen Shot 2022-12-08 at 8 41 03 PM" src="https://user-images.githubusercontent.com/855818/206603743-74a6e368-c3cf-4b87-b854-518a95893f06.png"> Pull Request resolved: https://github.com/pytorch/audio/pull/2902 Reviewed By: carolineechen Differential Revision: D41897800 Pulled By: mthrok fbshipit-source-id: a3c01d28d80e755596a9bc37c951960eb84870b9
-
- 09 Dec, 2022 5 commits
-
-
Zhaoheng Ni authored
Summary: After https://github.com/pytorch/audio/issues/2873, the pre-trained Wav2Vec2 models with larger datasets can get better performances. The PR fixes the integration test of bundle `WAV2VEC2_ASR_LARGE_LV60K_10M` which predicts the word `CURIOUSITY` to `CURIOUSSITY` before but now to `CURIOUSITY` correctly. Pull Request resolved: https://github.com/pytorch/audio/pull/2910 Reviewed By: mthrok Differential Revision: D41881919 Pulled By: nateanl fbshipit-source-id: 236fd00b983a5205c731f3efa31033a6b8257cab
-
moto authored
Summary: Pull Request resolved: https://github.com/pytorch/audio/pull/2911 Reviewed By: carolineechen Differential Revision: D41887854 Pulled By: mthrok fbshipit-source-id: eb91773ec67b4cda2d70733df450956d83742509
-
Moto Hira authored
Summary: Pull Request resolved: https://github.com/pytorch/audio/pull/2906 The correct way to create AVFormatContext* for output is to pass an address of an uninitialized *AVFormatContext struct to `avformat_alloc_output_context2` function. The current code pre-allocates AVFormatContext* with `avformat_alloc_context`, then this allocated object is lost inside of `avformat_alloc_output_context2`. Reviewed By: xiaohui-zhang Differential Revision: D41865685 fbshipit-source-id: 9a9dc83b5acfe9b450f191fe716c85ebb5a5d842
-
Moto Hira authored
Summary: Pull Request resolved: https://github.com/pytorch/audio/pull/2905 In StreamWriter, if the tensor format is different from the encoding format, then a FilterGraph object is automatically inserted to convert the format. The FilterGraph object operates on AVFrames. The input AVFrame must be allocated by us, but the output AVFrames is filled by FilterGraph, thus no need to allocate it. Now the output AVFrame is used as input to encoder regardless of whether FilterGraph was inserted. Thus the output AVFrame has to be manually allocated by us when FilterGraph is not used. The current code flips this condition and incorrectly allocates AVFrame when FilterGraph is present and does not allocate otherwise. This commit fix that. Reviewed By: xiaohui-zhang Differential Revision: D41866198 fbshipit-source-id: 40799c147dc8166a979ecfb58ed8e502539a6aed
-
atalman authored
Summary: Toggle on/off ffmpeg test if needed By default it ON, hence should not affect any current tests. To toggle ON no change required. To toggle OFF use: ``` smoke_test.py --no-ffmpeg ``` To be used when calling from builder currently. Since we do not install ffmpeg currently. Pull Request resolved: https://github.com/pytorch/audio/pull/2901 Reviewed By: carolineechen, mthrok Differential Revision: D41874976 Pulled By: atalman fbshipit-source-id: c57b19f37c63a1f476f93a5211550e980e67d9c7
-
- 08 Dec, 2022 4 commits
-
-
Grigory Sizov authored
Summary: Addressed mthrok's comments in https://github.com/pytorch/audio/pull/2833: - Moved model type from `_params` directly into the bundle definition. For now I defined model type as "WavLM" for WavLM bundles and "Wav2Vec2" for everything else. We can also distinguish between different Wav2Vec2 falvours - Hubert, VoxPopuli etc, but at the moment this won't imply any functional differences, so I didn't do it - Expanded the title underline to match the title length Pull Request resolved: https://github.com/pytorch/audio/pull/2895 Reviewed By: nateanl, mthrok Differential Revision: D41799875 Pulled By: sgrigory fbshipit-source-id: 0730d4f91ed60e900643bb74d6cccdd7aa5d7b39
-
Caroline Chen authored
Summary: cc mthrok Pull Request resolved: https://github.com/pytorch/audio/pull/2900 Reviewed By: mthrok Differential Revision: D41839924 Pulled By: carolineechen fbshipit-source-id: ba3ada7d04a86d99e08c9044de05a1c48b05d036
-
Grigory Sizov authored
Summary: Part 1 of [T138011314](https://www.internalfb.com/intern/tasks/?t=138011314) This PR ports the generator part of [HiFi GAN](https://arxiv.org/abs/2010.05646v2) from [the original implementation](https://github.com/jik876/hifi-gan/blob/4769534d45265d52a904b850da5a622601885777/models.py#L75) Adds tests: - Smoke tests for architectures V1, V2, V3 - Check that output shapes are correct - Check that the model is torchscriptable and scripting doesn't change the output - Check that our code's output matches the original implementation. Here I clone the original repo inside `/tmp` and import necessary objects from inside the test function. On test teardown I restore `PATH`, but don't remove the cloned code, so that it can be reused on subsequent runs - let me know if removing it would be a better practice There are no quantization tests, because the model consists mainly of `Conv1d` and `ConvTransposed1d`, and they are [not supported by dynamic quantization](https://pytorch.org/docs/stable/quantization.html) Pull Request resolved: https://github.com/pytorch/audio/pull/2860 Reviewed By: nateanl Differential Revision: D41433416 Pulled By: sgrigory fbshipit-source-id: f135c560df20f5138f01e3efdd182621edabb4f5
-
hwangjeff authored
Summary: Adds feature badges to preemphasis and deemphasis functions Pull Request resolved: https://github.com/pytorch/audio/pull/2892 Reviewed By: carolineechen Differential Revision: D41830782 Pulled By: hwangjeff fbshipit-source-id: 487ce9afa8dc8fe321aa9e02cc88bb1453985d39
-
- 07 Dec, 2022 3 commits
-
-
hwangjeff authored
Summary: Pull Request resolved: https://github.com/pytorch/audio/pull/2889 Reviewed By: xiaohui-zhang Differential Revision: D41760084 Pulled By: hwangjeff fbshipit-source-id: d2f5253e1fae7e7aafa9fa6043c6a7045c5b33a0
-
hwangjeff authored
Summary: Introduces the MUSAN dataset (https://www.openslr.org/17/), which contains music, speech, and noise recordings. Pull Request resolved: https://github.com/pytorch/audio/pull/2888 Reviewed By: xiaohui-zhang Differential Revision: D41762164 Pulled By: hwangjeff fbshipit-source-id: 14d5baaa4d40f065dd5d99bf7f2e0a73aa6c31a9
-
Jithun Nair authored
Summary: Dependent on PR https://github.com/pytorch/pytorch/pull/89101 Pull Request resolved: https://github.com/pytorch/audio/pull/2853 Reviewed By: atalman, osalpekar Differential Revision: D41737634 Pulled By: malfet fbshipit-source-id: 715a97a2da8ef309cea78d971b47c07463495683
-
- 06 Dec, 2022 1 commit
-
-
moto authored
Summary: This commit adds `frequency_impulse_response` function, which generates filter from desired frequency response. [Example](https://output.circle-artifacts.com/output/job/5233fda9-dadb-4710-9389-7e8ac20a062f/artifacts/0/docs/tutorials/filter_design_tutorial.html#frequency-sampling) Pull Request resolved: https://github.com/pytorch/audio/pull/2879 Reviewed By: hwangjeff Differential Revision: D41767787 Pulled By: mthrok fbshipit-source-id: 6d5e44c6390e8cf3028994a1b1de590ff3aaf6c2
-
- 04 Dec, 2022 1 commit
-
-
Zhaoheng Ni authored
Summary: address https://github.com/pytorch/audio/issues/2885 In `_init_hubert_pretrain_model ` method which initialize the hubert pretrain models, `kaiming_normal_` should be applied on `ConvLayerBlock` instead of `LayerNorm` layer. This PR fixes it and adds more unit tests. Pull Request resolved: https://github.com/pytorch/audio/pull/2886 Reviewed By: hwangjeff Differential Revision: D41713801 Pulled By: nateanl fbshipit-source-id: ed199baf7504d06bbf2d31c522ae708a75426a2d
-
- 02 Dec, 2022 1 commit
-
-
hwangjeff authored
Summary: Adds pre-emphasis and de-emphasis functions. Pull Request resolved: https://github.com/pytorch/audio/pull/2871 Reviewed By: carolineechen Differential Revision: D41651097 Pulled By: hwangjeff fbshipit-source-id: 7a3cf6ce68b6ce1b9ae315ddd8bd8ed71acccdf1
-
- 30 Nov, 2022 1 commit
-
-
hwangjeff authored
Summary: Adds functions and transforms for speed and speed perturbation (https://www.isca-speech.org/archive/interspeech_2015/ko15_interspeech.html). Pull Request resolved: https://github.com/pytorch/audio/pull/2829 Reviewed By: xiaohui-zhang Differential Revision: D41285114 Pulled By: hwangjeff fbshipit-source-id: 114740507698e01f35d4beb2c568a2479e847506
-









