- 23 Jan, 2023 1 commit
-
-
moto authored
Summary: This change fixes the issue where syntax highlighting is broken up par word. ## Plain Before <img width="243" alt="Screenshot 2023-01-20 at 1 28 48 PM" src="https://user-images.githubusercontent.com/855818/213778202-27ec8030-3f2f-4ef9-8210-bce7cfc3cb38.png"> After <img width="244" alt="Screenshot 2023-01-20 at 1 29 01 PM" src="https://user-images.githubusercontent.com/855818/213778231-61c52825-d63a-4913-b10d-a65f3b2cfbbb.png"> ## In articles Before <img width="786" alt="Screenshot 2023-01-20 at 1 34 12 PM" src="https://user-images.githubusercontent.com/855818/213779050-c21ba5e2-84b3-4935-bbab-6edcb7bc89ce.png"> After <img width="783" alt="Screenshot 2023-01-20 at 1 34 17 PM" src="https://user-images.githubusercontent.com/855818/213779069-f1406422-27a4-41cf-8ccd-5058f80860bd.png"> ## In tables Before <img width="813" alt="Screenshot 2023-01-20 at 1 27 35 PM" src="https://user-images.githubusercontent.com/855818/213778039-fede6f18-5a35-47f2-9e0b-a9be5716dc73.png"> After <img width="813" alt="Screenshot 2023-01-20 at 1 27 51 PM" src="https://user-images.githubusercontent.com/855818/213778073-e26275a9-d380-4601-aa92-84af7aeab00f.png"> Pull Request resolved: https://github.com/pytorch/audio/pull/3000 Reviewed By: xiaohui-zhang Differential Revision: D42642522 Pulled By: mthrok fbshipit-source-id: 6831bb90da005aff8d7f178ef768e967bc6d2640
-
- 22 Jan, 2023 1 commit
-
-
moto authored
Summary: This commit makes `StreamReader` report PTS (presentation time stamp) of the returned chunk as well. Example ```python from torchaudio.io import StreamReader s = StreamReader(...) s.add_video_stream(...) for (video_chunk, ) in s.stream(): # video_chunk is Torch tensor type but has extra attribute of PTS print(video_chunk.pts) # reports the PTS of the first frame of the video chunk. ``` For the backward compatibility, we introduce a `_ChunkTensor`, that is a composition of Tensor and metadata, but works like a normal tensor in PyTorch operations. The implementation of `_ChunkTensor` is based on [TrivialTensorViaComposition](https://github.com/albanD/subclass_zoo/blob/0eeb1d68fb59879029c610bc407f2997ae43ba0a/trivial_tensors.py#L83). It was also suggested to attach metadata directly to Tensor object, but the possibility to have the collision on torchaudio's metadata and new attributes introduced in PyTorch cannot be ignored, so we use Tensor subclass implementation. If any unexpected issue arise from metadata attribute name collision, client code can fetch the bare Tensor and continue. Pull Request resolved: https://github.com/pytorch/audio/pull/2975 Reviewed By: hwangjeff Differential Revision: D42526945 Pulled By: mthrok fbshipit-source-id: b4e9422e914ff328421b975120460f3001268f35
-
- 15 Jan, 2023 1 commit
-
-
Zhaoheng Ni authored
Summary: The PR adds three `Wav2Vec2Bundle ` pipeline objects for XLS-R models: - WAV2VEC2_XLSR_300M - WAV2VEC2_XLSR_1B - WAV2VEC2_XLSR_2B All three models use layer normalization in the feature extraction layers, hence `_normalize_waveform` is set to `True`. Pull Request resolved: https://github.com/pytorch/audio/pull/2978 Reviewed By: hwangjeff Differential Revision: D42501491 Pulled By: nateanl fbshipit-source-id: 2429ec880cc14798034843381e458e1b4664dac3
-
- 13 Jan, 2023 1 commit
-
-
Zhaoheng Ni authored
Summary: XLSR (cross-lingual speech representation) are a set of cross-lingual self-supervised learning models for generating cross-lingual speech representation. It was first proposed in https://arxiv.org/pdf/2006.13979.pdf which is trained on 53 languages (so-called XLSR-53). This PR supports more XLS-R models from https://arxiv.org/pdf/2111.09296.pdf that have more parameters (300M, 1B, 2B) and are trained on 128 languages. Pull Request resolved: https://github.com/pytorch/audio/pull/2959 Reviewed By: mthrok Differential Revision: D42397643 Pulled By: nateanl fbshipit-source-id: 23e8e51a7cde0a226db4f4028db7df8f02b986ce
-
- 06 Jan, 2023 1 commit
-
-
Zhaoheng Ni authored
Summary: `InverseMelScale` is missing from the nightly documentation webpage. `MelScale` is better in Feature Extractions section. This PR moves both documents into Feature Extractions section. Pull Request resolved: https://github.com/pytorch/audio/pull/2967 Reviewed By: mthrok Differential Revision: D42387886 Pulled By: nateanl fbshipit-source-id: cdac020887817ea2530bfb26e8ed414ae4761420
-
- 05 Jan, 2023 2 commits
-
-
Zhaoheng Ni authored
Summary: The generator part of HiFiGAN model is a vocoder which converts mel spectrogram to waveform. It makes more sense to name it as vocoder for better understanding. Pull Request resolved: https://github.com/pytorch/audio/pull/2955 Reviewed By: carolineechen Differential Revision: D42348864 Pulled By: nateanl fbshipit-source-id: c45a2f8d8d205ee381178ae5d37e9790a257e1aa
-
Grigory Sizov authored
Summary: Closes [T138011314](https://www.internalfb.com/intern/tasks/?t=138011314) ## Description - Add bundle `HIFIGAN_GENERATOR_V3_LJSPEECH` to prototypes. The bundle contains pre-trained HiFiGAN generator weights from the [original HiFiGAN publication](https://github.com/jik876/hifi-gan#pretrained-model), converted slightly to fit our model - Add tests - unit tests checking that vocoder and mel-transform implementations in the bundle give the same results as the original ones. Part of the original HiFiGAN code is ported to this repo to enable these tests - integration test checking that waveform reconstructed from mel spectrogram by the bundle is close enough to the original - Add docs Pull Request resolved: https://github.com/pytorch/audio/pull/2921 Reviewed By: nateanl, mthrok Differential Revision: D42034761 Pulled By: sgrigory fbshipit-source-id: 8b0dadeed510b3c9371d6aa2c46ec7d8378f6048
-
- 04 Jan, 2023 1 commit
-
-
Jeff Hwang authored
Summary: Pull Request resolved: https://github.com/pytorch/audio/pull/2935 Reviewed By: mthrok Differential Revision: D42302275 Pulled By: hwangjeff fbshipit-source-id: d995d335bf17d63d3c1dda77d8ef596570853638
-
- 30 Dec, 2022 1 commit
-
-
moto authored
Summary: Artifact: [subtractive_synthesis_tutorial](https://output.circle-artifacts.com/output/job/4c1ce33f-834d-48e0-ba89-2e91acdcb572/artifacts/0/docs/tutorials/subtractive_synthesis_tutorial.html) Pull Request resolved: https://github.com/pytorch/audio/pull/2934 Reviewed By: carolineechen Differential Revision: D42284945 Pulled By: mthrok fbshipit-source-id: d255b8e8e2a601a19bc879f9e1c38edbeebaf9b3
-
- 22 Dec, 2022 1 commit
-
-
moto authored
Summary: This commit adds "filter_waveform" prototype function. This function can apply non-stationary filters across the time. It also performs cropping at the end to compensate the delay introduced by filtering. The figure bellow illustrates this. See [subtractive_synthesis_tutorial](https://output.circle-artifacts.com/output/job/5233fda9-dadb-4710-9389-7e8ac20a062f/artifacts/0/docs/tutorials/subtractive_synthesis_tutorial.html) for example usages. 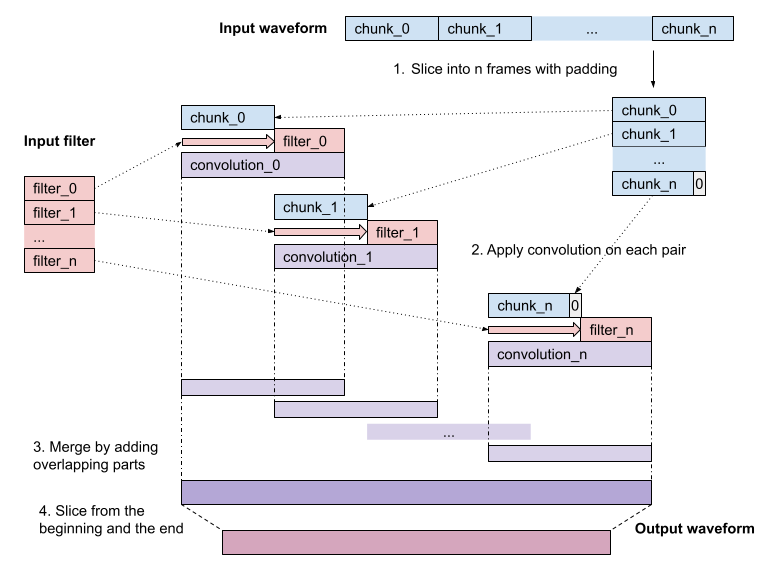 Pull Request resolved: https://github.com/pytorch/audio/pull/2928 Reviewed By: carolineechen Differential Revision: D42199955 Pulled By: mthrok fbshipit-source-id: e822510ab8df98393919bea33768f288f4d661b2
-
- 17 Dec, 2022 1 commit
-
-
moto authored
Summary: Adds filter design tutorial, which demonstrates `sinc_impulse_response` and `frequency_impulse_response`. Example: - [filter_design_tutorial](https://output.circle-artifacts.com/output/job/bd22c615-9215-4b17-a52c-b171a47f646c/artifacts/0/docs/tutorials/filter_design_tutorial.html) Pull Request resolved: https://github.com/pytorch/audio/pull/2894 Reviewed By: xiaohui-zhang Differential Revision: D42117658 Pulled By: mthrok fbshipit-source-id: f7dd04980e8557bb6f0e0ec26ac2c7f53314ea16
-
- 10 Dec, 2022 1 commit
-
-
moto authored
Summary: Currently, the documentation page for `torchaudio.models` have separate sections for model definitions and factory functions. The relationships between models and factory functions are not immediately clear. This commit moves the list of factory functions to the list of models. After: - https://output.circle-artifacts.com/output/job/242a9521-7460-4043-895b-9995bf5093b5/artifacts/0/docs/generated/torchaudio.models.Wav2Vec2Model.html <img width="1171" alt="Screen Shot 2022-12-08 at 8 41 03 PM" src="https://user-images.githubusercontent.com/855818/206603743-74a6e368-c3cf-4b87-b854-518a95893f06.png"> Pull Request resolved: https://github.com/pytorch/audio/pull/2902 Reviewed By: carolineechen Differential Revision: D41897800 Pulled By: mthrok fbshipit-source-id: a3c01d28d80e755596a9bc37c951960eb84870b9
-
- 08 Dec, 2022 2 commits
-
-
Grigory Sizov authored
Summary: Addressed mthrok's comments in https://github.com/pytorch/audio/pull/2833: - Moved model type from `_params` directly into the bundle definition. For now I defined model type as "WavLM" for WavLM bundles and "Wav2Vec2" for everything else. We can also distinguish between different Wav2Vec2 falvours - Hubert, VoxPopuli etc, but at the moment this won't imply any functional differences, so I didn't do it - Expanded the title underline to match the title length Pull Request resolved: https://github.com/pytorch/audio/pull/2895 Reviewed By: nateanl, mthrok Differential Revision: D41799875 Pulled By: sgrigory fbshipit-source-id: 0730d4f91ed60e900643bb74d6cccdd7aa5d7b39
-
Grigory Sizov authored
Summary: Part 1 of [T138011314](https://www.internalfb.com/intern/tasks/?t=138011314) This PR ports the generator part of [HiFi GAN](https://arxiv.org/abs/2010.05646v2) from [the original implementation](https://github.com/jik876/hifi-gan/blob/4769534d45265d52a904b850da5a622601885777/models.py#L75) Adds tests: - Smoke tests for architectures V1, V2, V3 - Check that output shapes are correct - Check that the model is torchscriptable and scripting doesn't change the output - Check that our code's output matches the original implementation. Here I clone the original repo inside `/tmp` and import necessary objects from inside the test function. On test teardown I restore `PATH`, but don't remove the cloned code, so that it can be reused on subsequent runs - let me know if removing it would be a better practice There are no quantization tests, because the model consists mainly of `Conv1d` and `ConvTransposed1d`, and they are [not supported by dynamic quantization](https://pytorch.org/docs/stable/quantization.html) Pull Request resolved: https://github.com/pytorch/audio/pull/2860 Reviewed By: nateanl Differential Revision: D41433416 Pulled By: sgrigory fbshipit-source-id: f135c560df20f5138f01e3efdd182621edabb4f5
-
- 07 Dec, 2022 2 commits
-
-
hwangjeff authored
Summary: Pull Request resolved: https://github.com/pytorch/audio/pull/2889 Reviewed By: xiaohui-zhang Differential Revision: D41760084 Pulled By: hwangjeff fbshipit-source-id: d2f5253e1fae7e7aafa9fa6043c6a7045c5b33a0
-
hwangjeff authored
Summary: Introduces the MUSAN dataset (https://www.openslr.org/17/), which contains music, speech, and noise recordings. Pull Request resolved: https://github.com/pytorch/audio/pull/2888 Reviewed By: xiaohui-zhang Differential Revision: D41762164 Pulled By: hwangjeff fbshipit-source-id: 14d5baaa4d40f065dd5d99bf7f2e0a73aa6c31a9
-
- 06 Dec, 2022 1 commit
-
-
moto authored
Summary: This commit adds `frequency_impulse_response` function, which generates filter from desired frequency response. [Example](https://output.circle-artifacts.com/output/job/5233fda9-dadb-4710-9389-7e8ac20a062f/artifacts/0/docs/tutorials/filter_design_tutorial.html#frequency-sampling) Pull Request resolved: https://github.com/pytorch/audio/pull/2879 Reviewed By: hwangjeff Differential Revision: D41767787 Pulled By: mthrok fbshipit-source-id: 6d5e44c6390e8cf3028994a1b1de590ff3aaf6c2
-
- 02 Dec, 2022 1 commit
-
-
hwangjeff authored
Summary: Adds pre-emphasis and de-emphasis functions. Pull Request resolved: https://github.com/pytorch/audio/pull/2871 Reviewed By: carolineechen Differential Revision: D41651097 Pulled By: hwangjeff fbshipit-source-id: 7a3cf6ce68b6ce1b9ae315ddd8bd8ed71acccdf1
-
- 30 Nov, 2022 1 commit
-
-
hwangjeff authored
Summary: Adds functions and transforms for speed and speed perturbation (https://www.isca-speech.org/archive/interspeech_2015/ko15_interspeech.html). Pull Request resolved: https://github.com/pytorch/audio/pull/2829 Reviewed By: xiaohui-zhang Differential Revision: D41285114 Pulled By: hwangjeff fbshipit-source-id: 114740507698e01f35d4beb2c568a2479e847506
-
- 29 Nov, 2022 3 commits
-
-
moto authored
Summary: This commit adds `sinc_impulse_response`, which generates windowed-sinc low-pass filters for given cutoff frequencies. Example usage: - [Filter Design Tutorial](https://output.circle-artifacts.com/output/job/c0085baa-5345-4aeb-bd44-448034caa9e1/artifacts/0/docs/tutorials/filter_design_tutorial.html) Pull Request resolved: https://github.com/pytorch/audio/pull/2875 Reviewed By: carolineechen Differential Revision: D41586631 Pulled By: mthrok fbshipit-source-id: a9991dbe5b137b0b4679228ec37072a1da7e50bb
-
moto authored
Summary: This commit adds the tutorial for additive synthesis, using torchaudio's prototype DSP ops. [Review here](https://output.circle-artifacts.com/output/job/3dc83322-832a-4272-9c13-df752c97b660/artifacts/0/docs/tutorials/additive_synthesis_tutorial.html) Pull Request resolved: https://github.com/pytorch/audio/pull/2877 Reviewed By: carolineechen Differential Revision: D41585425 Pulled By: mthrok fbshipit-source-id: b81283b90e4779c8054fd030a1d8c3d39d676bbd
-
Caroline Chen authored
Summary: modeled after [paper](https://arxiv.org/pdf/2110.07313.pdf) and internal flow f288347302 internal comparison tests: D40080919 Pull Request resolved: https://github.com/pytorch/audio/pull/2827 Reviewed By: nateanl Differential Revision: D41569046 Pulled By: carolineechen fbshipit-source-id: 43c5313074af05972d93da55b2029c746b75c380
-
- 28 Nov, 2022 2 commits
-
-
moto authored
Summary: This commits add tutorial for oscillator_bank and adsr_envelope, which will be a basis for DDSP. - [Review here](https://output.circle-artifacts.com/output/job/cf1d3001-88e5-418b-8cf8-ae22b4445dba/artifacts/0/docs/tutorials/oscillator_tutorial.html) Pull Request resolved: https://github.com/pytorch/audio/pull/2862 Reviewed By: carolineechen Differential Revision: D41559503 Pulled By: mthrok fbshipit-source-id: 3f1689186db7d246de14f228fc2f91bf37db98cd
-
moto authored
Summary: Add `extend_pitch` function that can be used for augmenting fundamental frequencies with its harmonic overtones or inharmonic partials. it can be use for amplitude as well. For example usages, see https://output.circle-artifacts.com/output/job/4ad0c29a-d75a-4244-baad-f5499f11d94b/artifacts/0/docs/tutorials/synthesis_tutorial.html Part of https://github.com/pytorch/audio/issues/2835 Extracted from https://github.com/pytorch/audio/issues/2808 Pull Request resolved: https://github.com/pytorch/audio/pull/2863 Reviewed By: carolineechen Differential Revision: D41543880 Pulled By: mthrok fbshipit-source-id: 4f20e55770b0b3bee825ec07c73f9ec7cb181109
-
- 18 Nov, 2022 1 commit
-
-
Zhaoheng Ni authored
Summary: Pull Request resolved: https://github.com/pytorch/audio/pull/2836 Reviewed By: carolineechen Differential Revision: D41208630 Pulled By: nateanl fbshipit-source-id: 625e1651f0b8a6e20876409739cf7084cb7c748b
-
- 17 Nov, 2022 2 commits
-
-
moto authored
Summary: Add adsr_envelope op, which generates ADSR envelope * Supports generation of the envelope on GPU * Supports optional Hold * Supports polynomial decay <image src='https://download.pytorch.org/torchaudio/doc-assets/adsr_examples.png'> Pull Request resolved: https://github.com/pytorch/audio/pull/2859 Reviewed By: nateanl Differential Revision: D41379601 Pulled By: mthrok fbshipit-source-id: 3717a6e0360d2a24913c2a836c57c5edec1d7b31
-
moto authored
Summary: This commit adds `oscillator_bank` op, which is the core of (differential) digital signal processing ops. The implementation itself is pretty simple, sum instantaneous frequencies, take sin and multiply with amplitudes. Following the magenta implementation, amplitudes for frequency range outside of [-Nyquist, Nyquist] \ are suppressed. The differentiability is tested within frequency range of [- Nyquist, Nyquist], and amplitude range of [-5, 5], which should be enough. For example usages: - https://output.circle-artifacts.com/output/job/129f3e21-41ce-406b-bc6b-833efb3c3141/artifacts/0/docs/tutorials/oscillator_tutorial.html - https://output.circle-artifacts.com/output/job/129f3e21-41ce-406b-bc6b-833efb3c3141/artifacts/0/docs/tutorials/synthesis_tutorial.html Part of https://github.com/pytorch/audio/issues/2835 Extracted from https://github.com/pytorch/audio/issues/2808 Pull Request resolved: https://github.com/pytorch/audio/pull/2848 Reviewed By: carolineechen Differential Revision: D41353075 Pulled By: mthrok fbshipit-source-id: 80e60772fb555760f2396f7df40458803c280225
-
- 15 Nov, 2022 2 commits
-
-
Grigory Sizov authored
Summary: Closes T136364380, follow-up to https://github.com/pytorch/audio/issues/2822 - Added "base", "base+", and "large" bundles for WavLM - Expanded `wav2vec2_pipeline_test.py` to include the new bundles - Added the new bundles to docs in `pipelines.rst` Pull Request resolved: https://github.com/pytorch/audio/pull/2833 Reviewed By: nateanl Differential Revision: D41194796 Pulled By: sgrigory fbshipit-source-id: bf8e96c05b6a81ac5c5a014c46adeeac12685328
-
moto authored
Summary: * Add the new official torchaudio logo to documentation/README. * Add a page for download logo. https://output.circle-artifacts.com/output/job/e9eb1292-7c10-4fef-adc3-ad568802aa59/artifacts/0/docs/index.html <img width="1068" alt="Screen Shot 2022-11-14 at 10 30 27 AM" src="https://user-images.githubusercontent.com/855818/201738349-9e248f15-dce2-4931-9066-aa898a53d6ad.png"> https://output.circle-artifacts.com/output/job/e9eb1292-7c10-4fef-adc3-ad568802aa59/artifacts/0/docs/logo.html <img width="617" alt="Screen Shot 2022-11-14 at 10 30 47 AM" src="https://user-images.githubusercontent.com/855818/201738420-ad0fda2f-f310-4802-851c-bbdf6c84c045.png"> Pull Request resolved: https://github.com/pytorch/audio/pull/2802 Reviewed By: carolineechen Differential Revision: D41295277 Pulled By: mthrok fbshipit-source-id: 6615d00799c9611f875e8485459d800e350b3486
-
- 14 Nov, 2022 1 commit
-
-
Caroline Chen authored
Summary: follow up to https://github.com/pytorch/audio/issues/2823 - move bark spectrogram to prototype - decrease autograd test tolerance (passing on circle ci) - add diagram for bark fbanks cc jdariasl Pull Request resolved: https://github.com/pytorch/audio/pull/2843 Reviewed By: nateanl Differential Revision: D41199522 Pulled By: carolineechen fbshipit-source-id: 8e6c2e20fb7b14f39477683b3c6ed8356359a213
-
- 10 Nov, 2022 2 commits
-
-
Julián D. Arias-Londoño authored
Summary: I have added BarkScale transform, which can transform a regular Spectrogram into a BarkSpectrograms similar to MelScale. ahmed-fau opened this requirement in December 2021 with the number (https://github.com/pytorch/audio/issues/2103). The new functionality includes three different well-known approximations of the Bark scale. Pull Request resolved: https://github.com/pytorch/audio/pull/2823 Reviewed By: nateanl Differential Revision: D41162100 Pulled By: carolineechen fbshipit-source-id: b2670c4972e49c9ef424da5d5982576f7a4df831
-
Caroline Chen authored
Summary: internal comparison tests: D40080919 follow up PR for pretrained models https://github.com/pytorch/audio/issues/2827 Pull Request resolved: https://github.com/pytorch/audio/pull/2826 Reviewed By: nateanl Differential Revision: D41160061 Pulled By: carolineechen fbshipit-source-id: f3c478b28c235af53d1d8e21b573c53684a63ac4
-
- 09 Nov, 2022 1 commit
-
-
Grigory Sizov authored
Summary: Closes T136364380 Added [WavLM Model](https://github.com/microsoft/UniSpeech/tree/main/WavLM): - Added `WavLMSelfAttention` class (from [original implementation](https://github.com/microsoft/UniSpeech/blob/2e9dde8bf815a5f5fd958e3435e5641f59f96928/WavLM/modules.py)) and adjusted existing Encoder and Transformer classes to be compatible with it - Added factory functions `wavlm_model`, `wavlm_base`, `wavlm_large` to `models/wav2vec2/model.py` - Added bundles for base and large models to pipelines. **TODO**: pre-trained model weights are not yet uploaded to `download.pytorch.org`, permissions not granted yet. ## Tests - Expanded HuggingFace integration tests to cover WavLM. For there tests, added JSON configs for base and large models from HF ([base](https://huggingface.co/microsoft/wavlm-base/blob/main/config.json), [large](https://huggingface.co/microsoft/wavlm-large/blob/main/config.json)) into test assets - Expanded TorchScript and quantization tests to cover WavLM ## Comments There are a few workarounds I had to introduce: - Quantization tests for WavLM were breaking down at [`torch.cat`](https://github.com/pytorch/audio/pull/2822/files#diff-6f1486901c94320ec0610a460dc674638fab9d104a61564ff7b59353a8b8547cR466) ~~until I excluded the arguments of `torch.cat` from quantization [here](https://github.com/pytorch/audio/pull/2822/files#diff-6f1486901c94320ec0610a460dc674638fab9d104a61564ff7b59353a8b8547cR368-R369). I haven't found a better way to fix it, let me know if there is one~~ The reason for this seems to be that quantization replaces `.bias` and `.weight` attributes of a `Linear` module with methods. Since we are using weights and biases directly, the code was break. The final solution suggested by nateanl was to define attention weights and biases directly in `WavLMSelfAttention`, skipping the `Linear` layers - ~~WavLM uses position embedding in the first layer of encoder, but not in the subsequent ones. So [UniSpeech](https://github.com/microsoft/UniSpeech/blob/2e9dde8bf815a5f5fd958e3435e5641f59f96928/WavLM/modules.py#L342) and [HF](https://github.com/huggingface/transformers/blob/b047472650cba259621549ac27b18fd2066ce18e/src/transformers/models/wavlm/modeling_wavlm.py#L441-L442) implementations only create this embedding module in the layers where it's used. However, we can't do this here because it breaks TorchScript. So as a solution I add a dummy `Identity` module to `WavLMSelfAttention` when the actual embedding is not needed: [here](https://github.com/pytorch/audio/pull/2822/files#diff-6f1486901c94320ec0610a460dc674638fab9d104a61564ff7b59353a8b8547cR361-R368).~~ Thanks nateanl for resolving this! - I had to add dummy `position_bias` and `key_padding_mask` arguments to `SelfAttention.forward` to make TorchScript tests pass. Since both `SelfAttention` and `WavLMSelfAttention` are called from `EncoderLayer`, they need to have compatible signatures. Having a variable number of arguments with `**kwargs` or checking object class doesn't seem to work with TorchScript, so I instead made both types of attention accept `position_bias` and `key_padding_mask` arguments. Nit: do we still need to specify `__all__` if there are no wildcard imports in `__init__.py`, e.g. in `torchaudio/models/__init__.py`? Pull Request resolved: https://github.com/pytorch/audio/pull/2822 Reviewed By: nateanl Differential Revision: D41121855 Pulled By: sgrigory fbshipit-source-id: 9f4f787e5810010de4e74cb704063a26c66767d7
-
- 08 Nov, 2022 1 commit
-
-
hwangjeff authored
Summary: Adds `torch.nn.Module`-based implementations for convolution and FFT convolution. Pull Request resolved: https://github.com/pytorch/audio/pull/2811 Reviewed By: carolineechen Differential Revision: D40881937 Pulled By: hwangjeff fbshipit-source-id: bfe8969e6178ad4f58981efd4b2720ac006be8de
-
- 03 Nov, 2022 1 commit
-
-
moto authored
Summary: Pull Request resolved: https://github.com/pytorch/audio/pull/2825 Reviewed By: carolineechen Differential Revision: D40954522 Pulled By: mthrok fbshipit-source-id: 433fb856a74a340af4d49e5c65a6270f0b00c835
-
- 02 Nov, 2022 2 commits
-
-
moto authored
Summary: PyTorch logo is included in pytorch doc theme, (and cannot be changed without custom CSS) so no need to have them here. Pull Request resolved: https://github.com/pytorch/audio/pull/2824 Reviewed By: carolineechen Differential Revision: D40954564 Pulled By: mthrok fbshipit-source-id: 5e9a91fddcc92c141baf1996f721c09c037fb003
-
moto authored
Summary: <img width="756" alt="Screen Shot 2022-11-01 at 3 32 58 PM" src="https://user-images.githubusercontent.com/855818/199173348-f463ae71-438c-4dad-a481-b65522a8e52f.png"> Pull Request resolved: https://github.com/pytorch/audio/pull/2812 Reviewed By: carolineechen Differential Revision: D40919942 Pulled By: mthrok fbshipit-source-id: 18e5a709c262fb0b15ada0d303f1d0dee033beb1
-
- 28 Oct, 2022 1 commit
-
-
moto authored
Summary: This commit re-organizes the tutorials. 1. Put all the tutorials in the left bar and make the section **folded by default**. 2. Add pytorch/tutorials-like cards in index 3. Move feature classifications to a dedicated page. https://output.circle-artifacts.com/output/job/1f1a04a5-137e-428d-9da4-c46f59eeffa4/artifacts/0/docs/index.html <img width="1073" alt="Screen Shot 2022-10-28 at 7 34 29 AM" src="https://user-images.githubusercontent.com/855818/198410686-3ef40ad2-c9c9-443c-800e-6e51e1b6a491.png"> Pull Request resolved: https://github.com/pytorch/audio/pull/2767 Reviewed By: carolineechen Differential Revision: D40627547 Pulled By: mthrok fbshipit-source-id: 098b825f242e91919126014abdab27852304ae64
-
- 20 Oct, 2022 1 commit
-
-
Zhaoheng Ni authored
Summary: address https://github.com/pytorch/audio/issues/2780 Pull Request resolved: https://github.com/pytorch/audio/pull/2781 Reviewed By: carolineechen, mthrok Differential Revision: D40556794 Pulled By: nateanl fbshipit-source-id: b24912489d41e5663b4b4dcfb8be743fb962097e
-
- 13 Oct, 2022 1 commit
-
-
moto authored
Summary: * Document `__call__` instead of `__init__` * List CTCHypothesis first as it is used in combination with CTCDecoder * Fix indentation of score method docstring Pull Request resolved: https://github.com/pytorch/audio/pull/2766 Reviewed By: carolineechen Differential Revision: D40349388 Pulled By: mthrok fbshipit-source-id: 5e512e6c2b29d3533eb62d09b289154ccd1abf4c
-







