
Merge pull request #207 from microsoft/master
merge master
Showing
docs/en_US/Tuner/PPOTuner.md
0 → 100644
docs/img/agp_pruner.png
0 → 100644
{kind=link}
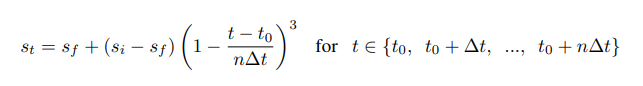
8.38 KB
{kind=link}
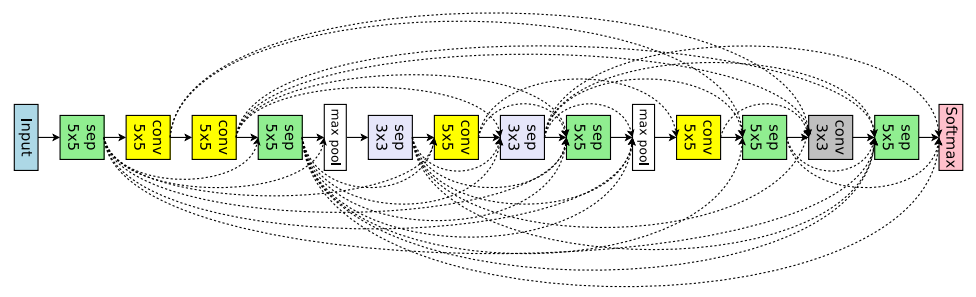
78.7 KB
docs/img/ppo_cifar10.png
0 → 100644
{kind=link}
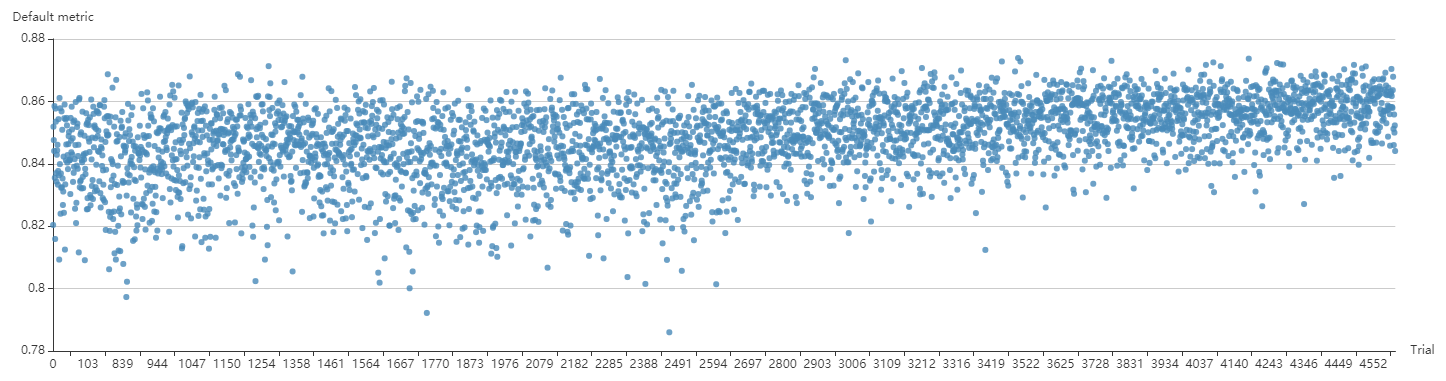
247 KB
docs/img/ppo_mnist.png
0 → 100644
{kind=link}
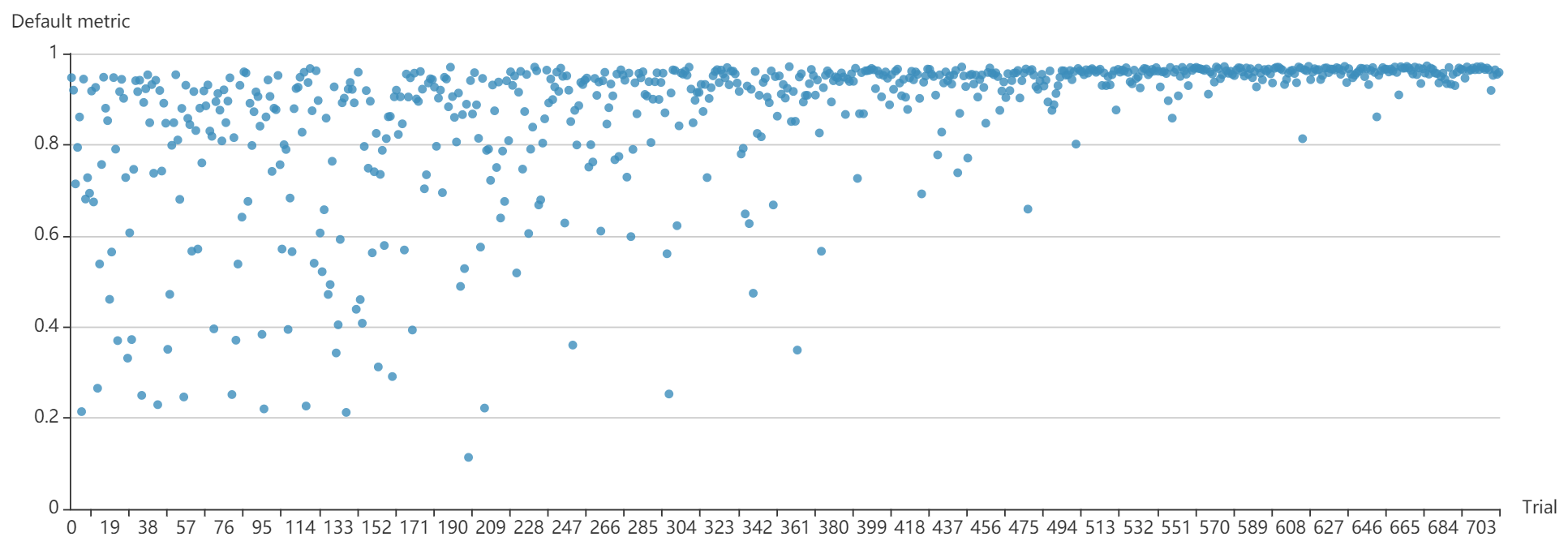
99 KB