
Merge pull request #200 from microsoft/master
merge master
Showing
{kind=link}

48.5 KB
{kind=link}
6.58 KB
{kind=link}
19.1 KB
{kind=link}
49.6 KB
{kind=link}
{kind=link}
| W: | H:
| W: | H:
{kind=link}
24.2 KB
{kind=link}
148 KB
{kind=link}
21.6 KB
{kind=link}
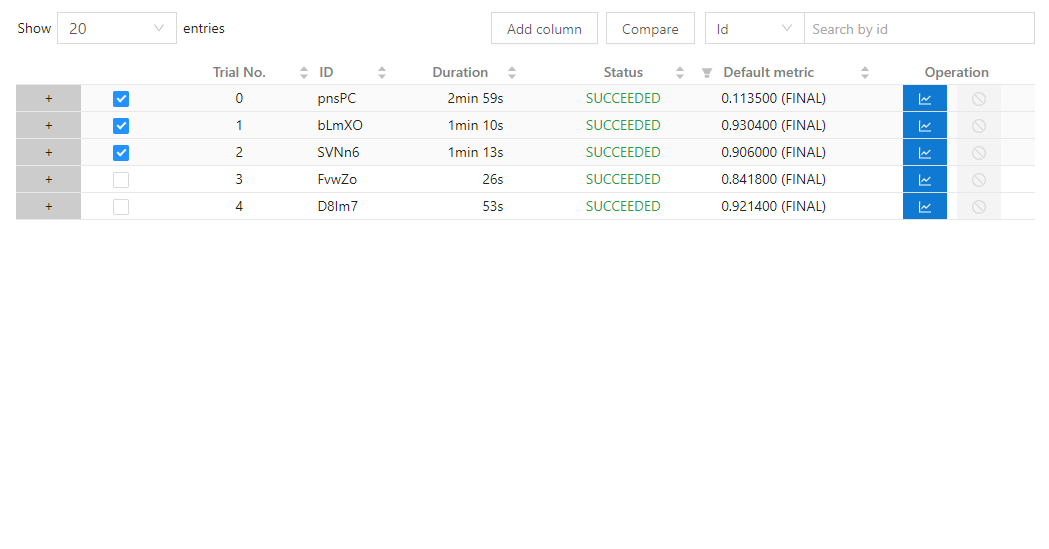
22.3 KB
{kind=link}
{kind=link}
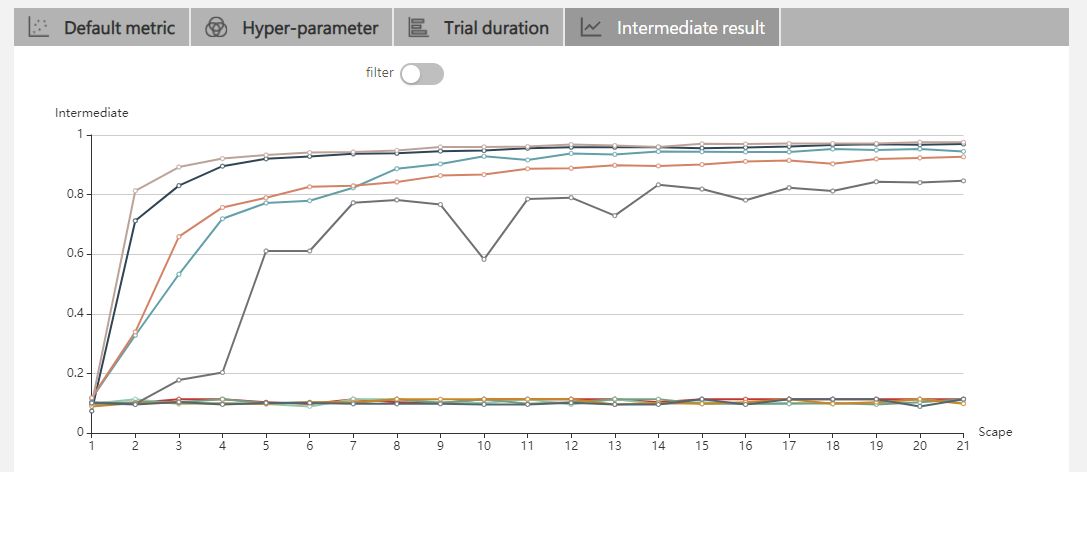
| W: | H:
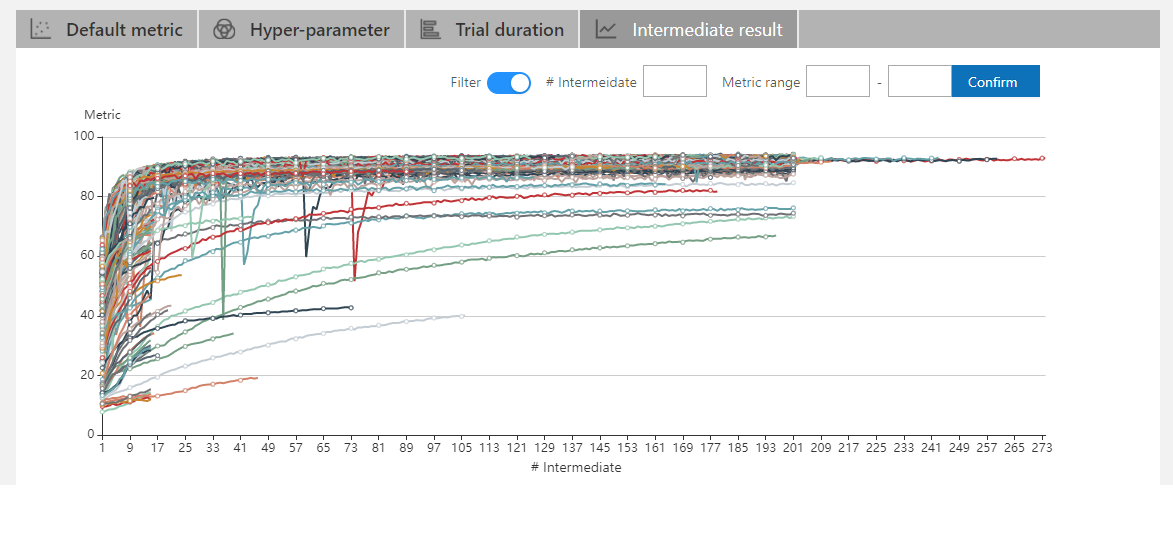
| W: | H:
File moved
File moved
File moved
File moved