
updata lightx2v
Showing
Too many changes to show.
To preserve performance only 428 of 428+ files are displayed.
.gitignore
0 → 100644
.pre-commit-config.yaml
0 → 100644
LICENSE
0 → 100644
app/README.md
0 → 100644
app/gradio_demo.py
0 → 100644
app/gradio_demo_zh.py
0 → 100644
app/run_gradio.sh
0 → 100644
app/run_gradio_win.bat
0 → 100644
{kind=link}
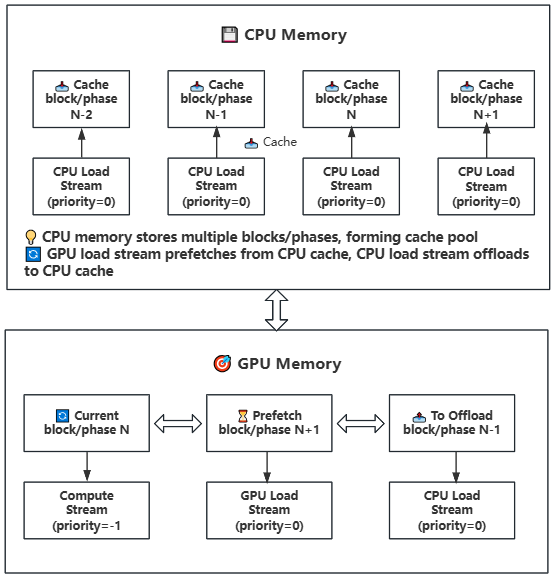
27.7 KB
{kind=link}
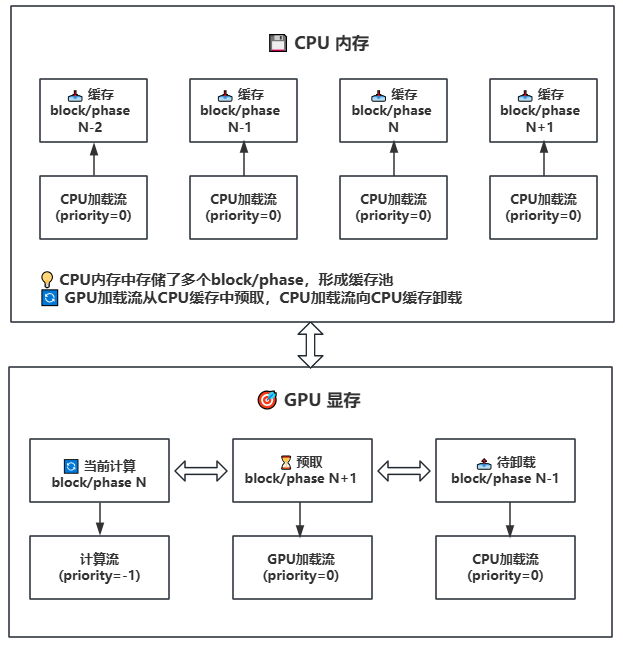
31.4 KB
{kind=link}
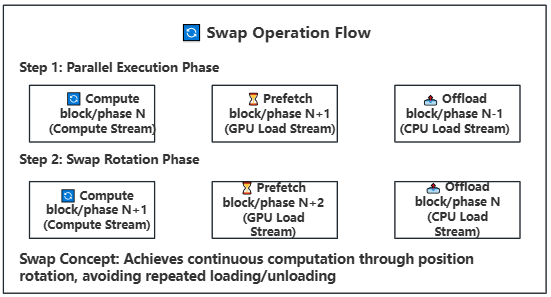
21.2 KB
{kind=link}
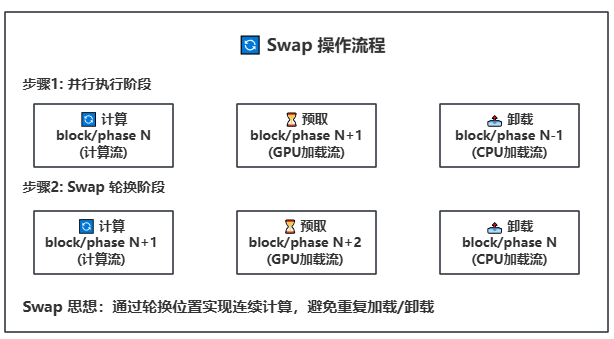
22.5 KB
{kind=link}

24.4 KB
{kind=link}
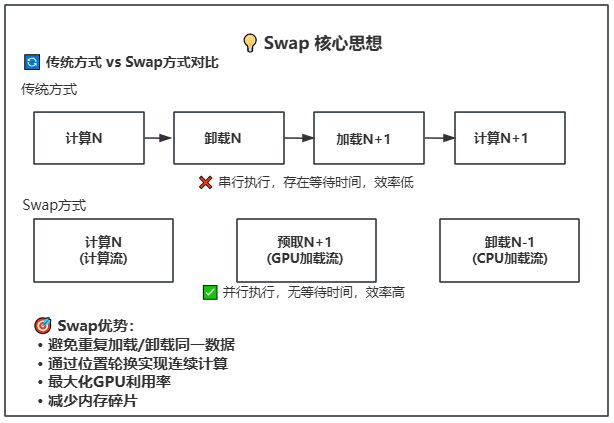
25.1 KB
{kind=link}

45.1 KB
{kind=link}
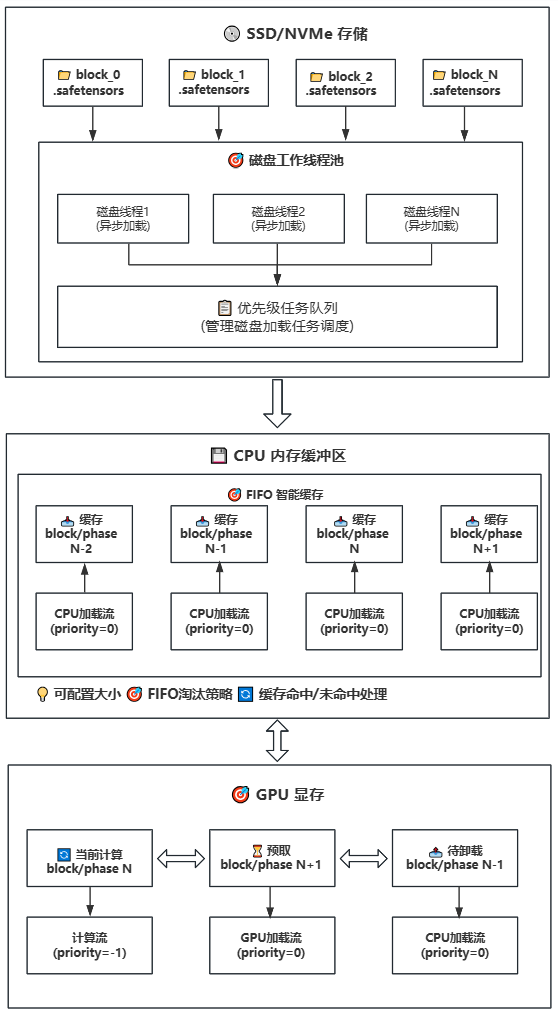
43.7 KB
{kind=link}
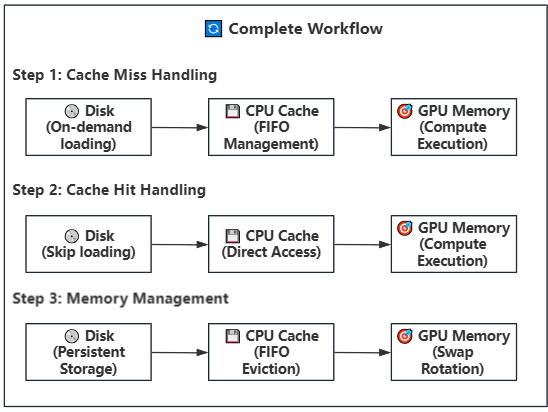
27.8 KB
{kind=link}
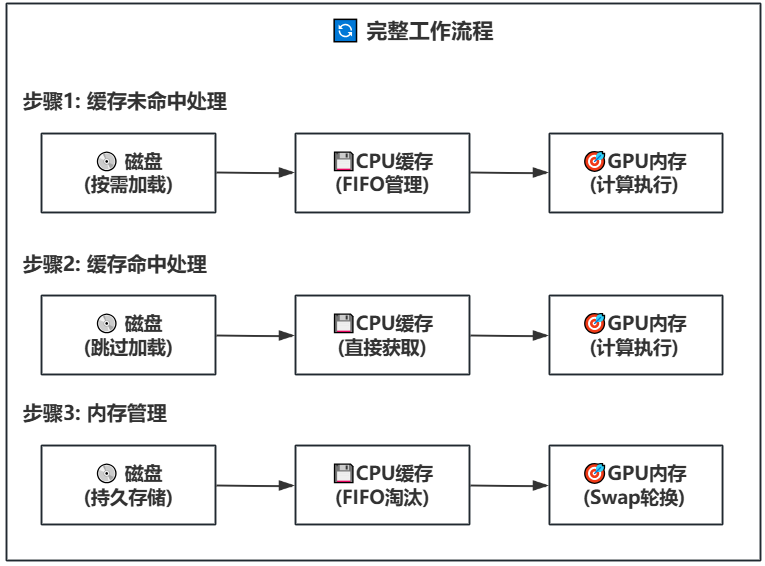
52.3 KB
{kind=link}
369 KB