diff --git a/.gitignore b/.gitignore
new file mode 100644
index 0000000000000000000000000000000000000000..77b7ba25dcb92f592bf0df5c8f500332d13187ab
--- /dev/null
+++ b/.gitignore
@@ -0,0 +1,30 @@
+*.pth
+*.pt
+*.onnx
+*.pk
+*.model
+*.zip
+*.tar
+*.pyc
+*.log
+*.o
+*.so
+*.a
+*.exe
+*.out
+.idea
+**.DS_Store**
+**/__pycache__/**
+**.swp
+.vscode/
+.env
+.log
+*.pid
+*.ipynb*
+*.mp4
+build/
+dist/
+.cache/
+server_cache/
+app/.gradio/
+*.pkl
diff --git a/.pre-commit-config.yaml b/.pre-commit-config.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..bdb356ab0608ea3a6145926c0d6906ad4217ee5c
--- /dev/null
+++ b/.pre-commit-config.yaml
@@ -0,0 +1,22 @@
+# Follow https://verdantfox.com/blog/how-to-use-git-pre-commit-hooks-the-hard-way-and-the-easy-way
+repos:
+ - repo: https://github.com/astral-sh/ruff-pre-commit
+ rev: v0.11.0
+ hooks:
+ - id: ruff
+ args: [--fix, --respect-gitignore, --config=pyproject.toml]
+ - id: ruff-format
+ args: [--config=pyproject.toml]
+
+ - repo: https://github.com/pre-commit/pre-commit-hooks
+ rev: v4.5.0
+ hooks:
+ - id: trailing-whitespace
+ - id: end-of-file-fixer
+ - id: check-yaml
+ - id: check-toml
+ - id: check-added-large-files
+ args: ['--maxkb=3000'] # Allow files up to 3MB
+ - id: check-case-conflict
+ - id: check-merge-conflict
+ - id: debug-statements
diff --git a/LICENSE b/LICENSE
new file mode 100644
index 0000000000000000000000000000000000000000..261eeb9e9f8b2b4b0d119366dda99c6fd7d35c64
--- /dev/null
+++ b/LICENSE
@@ -0,0 +1,201 @@
+ Apache License
+ Version 2.0, January 2004
+ http://www.apache.org/licenses/
+
+ TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
+
+ 1. Definitions.
+
+ "License" shall mean the terms and conditions for use, reproduction,
+ and distribution as defined by Sections 1 through 9 of this document.
+
+ "Licensor" shall mean the copyright owner or entity authorized by
+ the copyright owner that is granting the License.
+
+ "Legal Entity" shall mean the union of the acting entity and all
+ other entities that control, are controlled by, or are under common
+ control with that entity. For the purposes of this definition,
+ "control" means (i) the power, direct or indirect, to cause the
+ direction or management of such entity, whether by contract or
+ otherwise, or (ii) ownership of fifty percent (50%) or more of the
+ outstanding shares, or (iii) beneficial ownership of such entity.
+
+ "You" (or "Your") shall mean an individual or Legal Entity
+ exercising permissions granted by this License.
+
+ "Source" form shall mean the preferred form for making modifications,
+ including but not limited to software source code, documentation
+ source, and configuration files.
+
+ "Object" form shall mean any form resulting from mechanical
+ transformation or translation of a Source form, including but
+ not limited to compiled object code, generated documentation,
+ and conversions to other media types.
+
+ "Work" shall mean the work of authorship, whether in Source or
+ Object form, made available under the License, as indicated by a
+ copyright notice that is included in or attached to the work
+ (an example is provided in the Appendix below).
+
+ "Derivative Works" shall mean any work, whether in Source or Object
+ form, that is based on (or derived from) the Work and for which the
+ editorial revisions, annotations, elaborations, or other modifications
+ represent, as a whole, an original work of authorship. For the purposes
+ of this License, Derivative Works shall not include works that remain
+ separable from, or merely link (or bind by name) to the interfaces of,
+ the Work and Derivative Works thereof.
+
+ "Contribution" shall mean any work of authorship, including
+ the original version of the Work and any modifications or additions
+ to that Work or Derivative Works thereof, that is intentionally
+ submitted to Licensor for inclusion in the Work by the copyright owner
+ or by an individual or Legal Entity authorized to submit on behalf of
+ the copyright owner. For the purposes of this definition, "submitted"
+ means any form of electronic, verbal, or written communication sent
+ to the Licensor or its representatives, including but not limited to
+ communication on electronic mailing lists, source code control systems,
+ and issue tracking systems that are managed by, or on behalf of, the
+ Licensor for the purpose of discussing and improving the Work, but
+ excluding communication that is conspicuously marked or otherwise
+ designated in writing by the copyright owner as "Not a Contribution."
+
+ "Contributor" shall mean Licensor and any individual or Legal Entity
+ on behalf of whom a Contribution has been received by Licensor and
+ subsequently incorporated within the Work.
+
+ 2. Grant of Copyright License. Subject to the terms and conditions of
+ this License, each Contributor hereby grants to You a perpetual,
+ worldwide, non-exclusive, no-charge, royalty-free, irrevocable
+ copyright license to reproduce, prepare Derivative Works of,
+ publicly display, publicly perform, sublicense, and distribute the
+ Work and such Derivative Works in Source or Object form.
+
+ 3. Grant of Patent License. Subject to the terms and conditions of
+ this License, each Contributor hereby grants to You a perpetual,
+ worldwide, non-exclusive, no-charge, royalty-free, irrevocable
+ (except as stated in this section) patent license to make, have made,
+ use, offer to sell, sell, import, and otherwise transfer the Work,
+ where such license applies only to those patent claims licensable
+ by such Contributor that are necessarily infringed by their
+ Contribution(s) alone or by combination of their Contribution(s)
+ with the Work to which such Contribution(s) was submitted. If You
+ institute patent litigation against any entity (including a
+ cross-claim or counterclaim in a lawsuit) alleging that the Work
+ or a Contribution incorporated within the Work constitutes direct
+ or contributory patent infringement, then any patent licenses
+ granted to You under this License for that Work shall terminate
+ as of the date such litigation is filed.
+
+ 4. Redistribution. You may reproduce and distribute copies of the
+ Work or Derivative Works thereof in any medium, with or without
+ modifications, and in Source or Object form, provided that You
+ meet the following conditions:
+
+ (a) You must give any other recipients of the Work or
+ Derivative Works a copy of this License; and
+
+ (b) You must cause any modified files to carry prominent notices
+ stating that You changed the files; and
+
+ (c) You must retain, in the Source form of any Derivative Works
+ that You distribute, all copyright, patent, trademark, and
+ attribution notices from the Source form of the Work,
+ excluding those notices that do not pertain to any part of
+ the Derivative Works; and
+
+ (d) If the Work includes a "NOTICE" text file as part of its
+ distribution, then any Derivative Works that You distribute must
+ include a readable copy of the attribution notices contained
+ within such NOTICE file, excluding those notices that do not
+ pertain to any part of the Derivative Works, in at least one
+ of the following places: within a NOTICE text file distributed
+ as part of the Derivative Works; within the Source form or
+ documentation, if provided along with the Derivative Works; or,
+ within a display generated by the Derivative Works, if and
+ wherever such third-party notices normally appear. The contents
+ of the NOTICE file are for informational purposes only and
+ do not modify the License. You may add Your own attribution
+ notices within Derivative Works that You distribute, alongside
+ or as an addendum to the NOTICE text from the Work, provided
+ that such additional attribution notices cannot be construed
+ as modifying the License.
+
+ You may add Your own copyright statement to Your modifications and
+ may provide additional or different license terms and conditions
+ for use, reproduction, or distribution of Your modifications, or
+ for any such Derivative Works as a whole, provided Your use,
+ reproduction, and distribution of the Work otherwise complies with
+ the conditions stated in this License.
+
+ 5. Submission of Contributions. Unless You explicitly state otherwise,
+ any Contribution intentionally submitted for inclusion in the Work
+ by You to the Licensor shall be under the terms and conditions of
+ this License, without any additional terms or conditions.
+ Notwithstanding the above, nothing herein shall supersede or modify
+ the terms of any separate license agreement you may have executed
+ with Licensor regarding such Contributions.
+
+ 6. Trademarks. This License does not grant permission to use the trade
+ names, trademarks, service marks, or product names of the Licensor,
+ except as required for reasonable and customary use in describing the
+ origin of the Work and reproducing the content of the NOTICE file.
+
+ 7. Disclaimer of Warranty. Unless required by applicable law or
+ agreed to in writing, Licensor provides the Work (and each
+ Contributor provides its Contributions) on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
+ implied, including, without limitation, any warranties or conditions
+ of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
+ PARTICULAR PURPOSE. You are solely responsible for determining the
+ appropriateness of using or redistributing the Work and assume any
+ risks associated with Your exercise of permissions under this License.
+
+ 8. Limitation of Liability. In no event and under no legal theory,
+ whether in tort (including negligence), contract, or otherwise,
+ unless required by applicable law (such as deliberate and grossly
+ negligent acts) or agreed to in writing, shall any Contributor be
+ liable to You for damages, including any direct, indirect, special,
+ incidental, or consequential damages of any character arising as a
+ result of this License or out of the use or inability to use the
+ Work (including but not limited to damages for loss of goodwill,
+ work stoppage, computer failure or malfunction, or any and all
+ other commercial damages or losses), even if such Contributor
+ has been advised of the possibility of such damages.
+
+ 9. Accepting Warranty or Additional Liability. While redistributing
+ the Work or Derivative Works thereof, You may choose to offer,
+ and charge a fee for, acceptance of support, warranty, indemnity,
+ or other liability obligations and/or rights consistent with this
+ License. However, in accepting such obligations, You may act only
+ on Your own behalf and on Your sole responsibility, not on behalf
+ of any other Contributor, and only if You agree to indemnify,
+ defend, and hold each Contributor harmless for any liability
+ incurred by, or claims asserted against, such Contributor by reason
+ of your accepting any such warranty or additional liability.
+
+ END OF TERMS AND CONDITIONS
+
+ APPENDIX: How to apply the Apache License to your work.
+
+ To apply the Apache License to your work, attach the following
+ boilerplate notice, with the fields enclosed by brackets "[]"
+ replaced with your own identifying information. (Don't include
+ the brackets!) The text should be enclosed in the appropriate
+ comment syntax for the file format. We also recommend that a
+ file or class name and description of purpose be included on the
+ same "printed page" as the copyright notice for easier
+ identification within third-party archives.
+
+ Copyright [yyyy] [name of copyright owner]
+
+ Licensed under the Apache License, Version 2.0 (the "License");
+ you may not use this file except in compliance with the License.
+ You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing, software
+ distributed under the License is distributed on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ See the License for the specific language governing permissions and
+ limitations under the License.
diff --git a/README.md b/README.md
index 6b94e2481927b013b3776ef7cc011e9094341871..35408da19ac0a419ed5692305855e51124358fa7 100644
--- a/README.md
+++ b/README.md
@@ -1,2 +1,295 @@
-# LightX2V
+
+
⚡️ LightX2V:
轻量级视频生成推理框架
+

+
+[](https://opensource.org/licenses/Apache-2.0)
+[](https://deepwiki.com/ModelTC/lightx2v)
+[](https://lightx2v-en.readthedocs.io/en/latest)
+[](https://lightx2v-zhcn.readthedocs.io/zh-cn/latest)
+[](https://lightx2v-papers-zhcn.readthedocs.io/zh-cn/latest)
+[](https://hub.docker.com/r/lightx2v/lightx2v/tags)
+
+**\[ [English](README.md) | 中文 \]**
+
+
+由 LightX2V 团队用 ❤️ 构建
+
diff --git a/app/README.md b/app/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..2be884b7e04244e2fb210d27ea7b7978abc072b7
--- /dev/null
+++ b/app/README.md
@@ -0,0 +1,13 @@
+# Gradio Demo
+
+Please refer our gradio deployment doc:
+
+[English doc: Gradio Deployment](https://lightx2v-en.readthedocs.io/en/latest/deploy_guides/deploy_gradio.html)
+
+[中文文档: Gradio 部署](https://lightx2v-zhcn.readthedocs.io/zh-cn/latest/deploy_guides/deploy_gradio.html)
+
+## 🚀 Quick Start (快速开始)
+
+For Windows users, we provide a convenient one-click deployment solution with automatic environment configuration and intelligent parameter optimization. Please refer to the [One-Click Gradio Launch](https://lightx2v-en.readthedocs.io/en/latest/deploy_guides/deploy_local_windows.html) section for detailed instructions.
+
+对于Windows用户,我们提供了便捷的一键部署方式,支持自动环境配置和智能参数优化。详细操作请参考[一键启动Gradio](https://lightx2v-zhcn.readthedocs.io/zh-cn/latest/deploy_guides/deploy_local_windows.html)章节。
diff --git a/app/gradio_demo.py b/app/gradio_demo.py
new file mode 100644
index 0000000000000000000000000000000000000000..448ec3363692bae777afeccf3ef82c9450ffc53b
--- /dev/null
+++ b/app/gradio_demo.py
@@ -0,0 +1,1442 @@
+import argparse
+import gc
+import glob
+import importlib.util
+import json
+import os
+
+os.environ["PROFILING_DEBUG_LEVEL"] = "2"
+os.environ["PYTORCH_CUDA_ALLOC_CONF"] = "expandable_segments:True"
+os.environ["DTYPE"] = "BF16"
+import random
+from datetime import datetime
+
+import gradio as gr
+import psutil
+import torch
+from loguru import logger
+
+from lightx2v.utils.input_info import set_input_info
+from lightx2v.utils.set_config import get_default_config
+
+try:
+ from flashinfer.rope import apply_rope_with_cos_sin_cache_inplace
+except ImportError:
+ apply_rope_with_cos_sin_cache_inplace = None
+
+
+logger.add(
+ "inference_logs.log",
+ rotation="100 MB",
+ encoding="utf-8",
+ enqueue=True,
+ backtrace=True,
+ diagnose=True,
+)
+
+MAX_NUMPY_SEED = 2**32 - 1
+
+
+def scan_model_path_contents(model_path):
+ """Scan model_path directory and return available files and subdirectories"""
+ if not model_path or not os.path.exists(model_path):
+ return {"dirs": [], "files": [], "safetensors_dirs": [], "pth_files": []}
+
+ dirs = []
+ files = []
+ safetensors_dirs = []
+ pth_files = []
+
+ try:
+ for item in os.listdir(model_path):
+ item_path = os.path.join(model_path, item)
+ if os.path.isdir(item_path):
+ dirs.append(item)
+ # Check if directory contains safetensors files
+ if glob.glob(os.path.join(item_path, "*.safetensors")):
+ safetensors_dirs.append(item)
+ elif os.path.isfile(item_path):
+ files.append(item)
+ if item.endswith(".pth"):
+ pth_files.append(item)
+ except Exception as e:
+ logger.warning(f"Failed to scan directory: {e}")
+
+ return {
+ "dirs": sorted(dirs),
+ "files": sorted(files),
+ "safetensors_dirs": sorted(safetensors_dirs),
+ "pth_files": sorted(pth_files),
+ }
+
+
+def get_dit_choices(model_path, model_type="wan2.1"):
+ """Get Diffusion model options (filtered by model type)"""
+ contents = scan_model_path_contents(model_path)
+ excluded_keywords = ["vae", "tae", "clip", "t5", "high_noise", "low_noise"]
+ fp8_supported = is_fp8_supported_gpu()
+
+ if model_type == "wan2.1":
+ # wan2.1: filter files/dirs containing wan2.1 or Wan2.1
+ def is_valid(name):
+ name_lower = name.lower()
+ if "wan2.1" not in name_lower:
+ return False
+ if not fp8_supported and "fp8" in name_lower:
+ return False
+ return not any(kw in name_lower for kw in excluded_keywords)
+ else:
+ # wan2.2: filter files/dirs containing wan2.2 or Wan2.2
+ def is_valid(name):
+ name_lower = name.lower()
+ if "wan2.2" not in name_lower:
+ return False
+ if not fp8_supported and "fp8" in name_lower:
+ return False
+ return not any(kw in name_lower for kw in excluded_keywords)
+
+ # Filter matching directories and files
+ dir_choices = [d for d in contents["dirs"] if is_valid(d)]
+ file_choices = [f for f in contents["files"] if is_valid(f)]
+ choices = dir_choices + file_choices
+ return choices if choices else [""]
+
+
+def get_high_noise_choices(model_path):
+ """Get high noise model options (files/dirs containing high_noise)"""
+ contents = scan_model_path_contents(model_path)
+ fp8_supported = is_fp8_supported_gpu()
+
+ def is_valid(name):
+ name_lower = name.lower()
+ if not fp8_supported and "fp8" in name_lower:
+ return False
+ return "high_noise" in name_lower or "high-noise" in name_lower
+
+ dir_choices = [d for d in contents["dirs"] if is_valid(d)]
+ file_choices = [f for f in contents["files"] if is_valid(f)]
+ choices = dir_choices + file_choices
+ return choices if choices else [""]
+
+
+def get_low_noise_choices(model_path):
+ """Get low noise model options (files/dirs containing low_noise)"""
+ contents = scan_model_path_contents(model_path)
+ fp8_supported = is_fp8_supported_gpu()
+
+ def is_valid(name):
+ name_lower = name.lower()
+ if not fp8_supported and "fp8" in name_lower:
+ return False
+ return "low_noise" in name_lower or "low-noise" in name_lower
+
+ dir_choices = [d for d in contents["dirs"] if is_valid(d)]
+ file_choices = [f for f in contents["files"] if is_valid(f)]
+ choices = dir_choices + file_choices
+ return choices if choices else [""]
+
+
+def get_t5_choices(model_path):
+ """Get T5 model options (.pth or .safetensors files containing t5 keyword)"""
+ contents = scan_model_path_contents(model_path)
+ fp8_supported = is_fp8_supported_gpu()
+
+ # Filter from .pth files
+ pth_choices = [f for f in contents["pth_files"] if "t5" in f.lower() and (fp8_supported or "fp8" not in f.lower())]
+
+ # Filter from .safetensors files
+ safetensors_choices = [f for f in contents["files"] if f.endswith(".safetensors") and "t5" in f.lower() and (fp8_supported or "fp8" not in f.lower())]
+
+ # Filter from directories containing safetensors
+ safetensors_dir_choices = [d for d in contents["safetensors_dirs"] if "t5" in d.lower() and (fp8_supported or "fp8" not in d.lower())]
+
+ choices = pth_choices + safetensors_choices + safetensors_dir_choices
+ return choices if choices else [""]
+
+
+def get_clip_choices(model_path):
+ """Get CLIP model options (.pth or .safetensors files containing clip keyword)"""
+ contents = scan_model_path_contents(model_path)
+ fp8_supported = is_fp8_supported_gpu()
+
+ # Filter from .pth files
+ pth_choices = [f for f in contents["pth_files"] if "clip" in f.lower() and (fp8_supported or "fp8" not in f.lower())]
+
+ # Filter from .safetensors files
+ safetensors_choices = [f for f in contents["files"] if f.endswith(".safetensors") and "clip" in f.lower() and (fp8_supported or "fp8" not in f.lower())]
+
+ # Filter from directories containing safetensors
+ safetensors_dir_choices = [d for d in contents["safetensors_dirs"] if "clip" in d.lower() and (fp8_supported or "fp8" not in d.lower())]
+
+ choices = pth_choices + safetensors_choices + safetensors_dir_choices
+ return choices if choices else [""]
+
+
+def get_vae_choices(model_path):
+ """Get VAE model options (.pth or .safetensors files containing vae/VAE/tae keyword)"""
+ contents = scan_model_path_contents(model_path)
+ fp8_supported = is_fp8_supported_gpu()
+
+ # Filter from .pth files
+ pth_choices = [f for f in contents["pth_files"] if any(kw in f.lower() for kw in ["vae", "tae"]) and (fp8_supported or "fp8" not in f.lower())]
+
+ # Filter from .safetensors files
+ safetensors_choices = [f for f in contents["files"] if f.endswith(".safetensors") and any(kw in f.lower() for kw in ["vae", "tae"]) and (fp8_supported or "fp8" not in f.lower())]
+
+ # Filter from directories containing safetensors
+ safetensors_dir_choices = [d for d in contents["safetensors_dirs"] if any(kw in d.lower() for kw in ["vae", "tae"]) and (fp8_supported or "fp8" not in d.lower())]
+
+ choices = pth_choices + safetensors_choices + safetensors_dir_choices
+ return choices if choices else [""]
+
+
+def detect_quant_scheme(model_name):
+ """Automatically detect quantization scheme from model name
+ - If model name contains "int8" → "int8"
+ - If model name contains "fp8" and device supports → "fp8"
+ - Otherwise return None (no quantization)
+ """
+ if not model_name:
+ return None
+ name_lower = model_name.lower()
+ if "int8" in name_lower:
+ return "int8"
+ elif "fp8" in name_lower:
+ if is_fp8_supported_gpu():
+ return "fp8"
+ else:
+ # Device doesn't support fp8, return None (use default precision)
+ return None
+ return None
+
+
+def update_model_path_options(model_path, model_type="wan2.1"):
+ """Update all model path selectors when model_path or model_type changes"""
+ dit_choices = get_dit_choices(model_path, model_type)
+ high_noise_choices = get_high_noise_choices(model_path)
+ low_noise_choices = get_low_noise_choices(model_path)
+ t5_choices = get_t5_choices(model_path)
+ clip_choices = get_clip_choices(model_path)
+ vae_choices = get_vae_choices(model_path)
+
+ return (
+ gr.update(choices=dit_choices, value=dit_choices[0] if dit_choices else ""),
+ gr.update(choices=high_noise_choices, value=high_noise_choices[0] if high_noise_choices else ""),
+ gr.update(choices=low_noise_choices, value=low_noise_choices[0] if low_noise_choices else ""),
+ gr.update(choices=t5_choices, value=t5_choices[0] if t5_choices else ""),
+ gr.update(choices=clip_choices, value=clip_choices[0] if clip_choices else ""),
+ gr.update(choices=vae_choices, value=vae_choices[0] if vae_choices else ""),
+ )
+
+
+def generate_random_seed():
+ return random.randint(0, MAX_NUMPY_SEED)
+
+
+def is_module_installed(module_name):
+ try:
+ spec = importlib.util.find_spec(module_name)
+ return spec is not None
+ except ModuleNotFoundError:
+ return False
+
+
+def get_available_quant_ops():
+ available_ops = []
+
+ vllm_installed = is_module_installed("vllm")
+ if vllm_installed:
+ available_ops.append(("vllm", True))
+ else:
+ available_ops.append(("vllm", False))
+
+ sgl_installed = is_module_installed("sgl_kernel")
+ if sgl_installed:
+ available_ops.append(("sgl", True))
+ else:
+ available_ops.append(("sgl", False))
+
+ q8f_installed = is_module_installed("q8_kernels")
+ if q8f_installed:
+ available_ops.append(("q8f", True))
+ else:
+ available_ops.append(("q8f", False))
+
+ return available_ops
+
+
+def get_available_attn_ops():
+ available_ops = []
+
+ vllm_installed = is_module_installed("flash_attn")
+ if vllm_installed:
+ available_ops.append(("flash_attn2", True))
+ else:
+ available_ops.append(("flash_attn2", False))
+
+ sgl_installed = is_module_installed("flash_attn_interface")
+ if sgl_installed:
+ available_ops.append(("flash_attn3", True))
+ else:
+ available_ops.append(("flash_attn3", False))
+
+ sage_installed = is_module_installed("sageattention")
+ if sage_installed:
+ available_ops.append(("sage_attn2", True))
+ else:
+ available_ops.append(("sage_attn2", False))
+
+ sage3_installed = is_module_installed("sageattn3")
+ if sage3_installed:
+ available_ops.append(("sage_attn3", True))
+ else:
+ available_ops.append(("sage_attn3", False))
+
+ torch_installed = is_module_installed("torch")
+ if torch_installed:
+ available_ops.append(("torch_sdpa", True))
+ else:
+ available_ops.append(("torch_sdpa", False))
+
+ return available_ops
+
+
+def get_gpu_memory(gpu_idx=0):
+ if not torch.cuda.is_available():
+ return 0
+ try:
+ with torch.cuda.device(gpu_idx):
+ memory_info = torch.cuda.mem_get_info()
+ total_memory = memory_info[1] / (1024**3) # Convert bytes to GB
+ return total_memory
+ except Exception as e:
+ logger.warning(f"Failed to get GPU memory: {e}")
+ return 0
+
+
+def get_cpu_memory():
+ available_bytes = psutil.virtual_memory().available
+ return available_bytes / 1024**3
+
+
+def cleanup_memory():
+ gc.collect()
+
+ if torch.cuda.is_available():
+ torch.cuda.empty_cache()
+ torch.cuda.synchronize()
+
+ try:
+ import psutil
+
+ if hasattr(psutil, "virtual_memory"):
+ if os.name == "posix":
+ try:
+ os.system("sync")
+ except: # noqa
+ pass
+ except: # noqa
+ pass
+
+
+def generate_unique_filename(output_dir):
+ os.makedirs(output_dir, exist_ok=True)
+ timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
+ return os.path.join(output_dir, f"{timestamp}.mp4")
+
+
+def is_fp8_supported_gpu():
+ if not torch.cuda.is_available():
+ return False
+ compute_capability = torch.cuda.get_device_capability(0)
+ major, minor = compute_capability
+ return (major == 8 and minor == 9) or (major >= 9)
+
+
+def is_ada_architecture_gpu():
+ if not torch.cuda.is_available():
+ return False
+ try:
+ gpu_name = torch.cuda.get_device_name(0).upper()
+ ada_keywords = ["RTX 40", "RTX40", "4090", "4080", "4070", "4060"]
+ return any(keyword in gpu_name for keyword in ada_keywords)
+ except Exception as e:
+ logger.warning(f"Failed to get GPU name: {e}")
+ return False
+
+
+def get_quantization_options(model_path):
+ """Get quantization options dynamically based on model_path"""
+ import os
+
+ # Check subdirectories
+ subdirs = ["original", "fp8", "int8"]
+ has_subdirs = {subdir: os.path.exists(os.path.join(model_path, subdir)) for subdir in subdirs}
+
+ # Check original files in root directory
+ t5_bf16_exists = os.path.exists(os.path.join(model_path, "models_t5_umt5-xxl-enc-bf16.pth"))
+ clip_fp16_exists = os.path.exists(os.path.join(model_path, "models_clip_open-clip-xlm-roberta-large-vit-huge-14.pth"))
+
+ # Generate options
+ def get_choices(has_subdirs, original_type, fp8_type, int8_type, fallback_type, has_original_file=False):
+ choices = []
+ if has_subdirs["original"]:
+ choices.append(original_type)
+ if has_subdirs["fp8"]:
+ choices.append(fp8_type)
+ if has_subdirs["int8"]:
+ choices.append(int8_type)
+
+ # If no subdirectories but original file exists, add original type
+ if has_original_file:
+ if not choices or "original" not in choices:
+ choices.append(original_type)
+
+ # If no options at all, use default value
+ if not choices:
+ choices = [fallback_type]
+
+ return choices, choices[0]
+
+ # DIT options
+ dit_choices, dit_default = get_choices(has_subdirs, "bf16", "fp8", "int8", "bf16")
+
+ # T5 options - check if original file exists
+ t5_choices, t5_default = get_choices(has_subdirs, "bf16", "fp8", "int8", "bf16", t5_bf16_exists)
+
+ # CLIP options - check if original file exists
+ clip_choices, clip_default = get_choices(has_subdirs, "fp16", "fp8", "int8", "fp16", clip_fp16_exists)
+
+ return {"dit_choices": dit_choices, "dit_default": dit_default, "t5_choices": t5_choices, "t5_default": t5_default, "clip_choices": clip_choices, "clip_default": clip_default}
+
+
+def determine_model_cls(model_type, dit_name, high_noise_name):
+ """Determine model_cls based on model type and file name"""
+ # Determine file name to check
+ if model_type == "wan2.1":
+ check_name = dit_name.lower() if dit_name else ""
+ is_distill = "4step" in check_name
+ return "wan2.1_distill" if is_distill else "wan2.1"
+ else:
+ # wan2.2
+ check_name = high_noise_name.lower() if high_noise_name else ""
+ is_distill = "4step" in check_name
+ return "wan2.2_moe_distill" if is_distill else "wan2.2_moe"
+
+
+global_runner = None
+current_config = None
+cur_dit_path = None
+cur_t5_path = None
+cur_clip_path = None
+
+available_quant_ops = get_available_quant_ops()
+quant_op_choices = []
+for op_name, is_installed in available_quant_ops:
+ status_text = "✅ Installed" if is_installed else "❌ Not Installed"
+ display_text = f"{op_name} ({status_text})"
+ quant_op_choices.append((op_name, display_text))
+
+available_attn_ops = get_available_attn_ops()
+# Priority order
+attn_priority = ["sage_attn3", "sage_attn2", "flash_attn3", "flash_attn2", "torch_sdpa"]
+# Sort by priority, installed ones first, uninstalled ones last
+attn_op_choices = []
+attn_op_dict = dict(available_attn_ops)
+
+# Add installed ones first (by priority)
+for op_name in attn_priority:
+ if op_name in attn_op_dict and attn_op_dict[op_name]:
+ status_text = "✅ Installed"
+ display_text = f"{op_name} ({status_text})"
+ attn_op_choices.append((op_name, display_text))
+
+# Add uninstalled ones (by priority)
+for op_name in attn_priority:
+ if op_name in attn_op_dict and not attn_op_dict[op_name]:
+ status_text = "❌ Not Installed"
+ display_text = f"{op_name} ({status_text})"
+ attn_op_choices.append((op_name, display_text))
+
+# Add other operators not in priority list (installed ones first)
+other_ops = [(op_name, is_installed) for op_name, is_installed in available_attn_ops if op_name not in attn_priority]
+for op_name, is_installed in sorted(other_ops, key=lambda x: not x[1]): # Installed ones first
+ status_text = "✅ Installed" if is_installed else "❌ Not Installed"
+ display_text = f"{op_name} ({status_text})"
+ attn_op_choices.append((op_name, display_text))
+
+
+def run_inference(
+ prompt,
+ negative_prompt,
+ save_result_path,
+ infer_steps,
+ num_frames,
+ resolution,
+ seed,
+ sample_shift,
+ enable_cfg,
+ cfg_scale,
+ fps,
+ use_tiling_vae,
+ lazy_load,
+ cpu_offload,
+ offload_granularity,
+ t5_cpu_offload,
+ clip_cpu_offload,
+ vae_cpu_offload,
+ unload_modules,
+ attention_type,
+ quant_op,
+ rope_chunk,
+ rope_chunk_size,
+ clean_cuda_cache,
+ model_path_input,
+ model_type_input,
+ task_type_input,
+ dit_path_input,
+ high_noise_path_input,
+ low_noise_path_input,
+ t5_path_input,
+ clip_path_input,
+ vae_path_input,
+ image_path=None,
+):
+ cleanup_memory()
+
+ quant_op = quant_op.split("(")[0].strip()
+ attention_type = attention_type.split("(")[0].strip()
+
+ global global_runner, current_config, model_path, model_cls
+ global cur_dit_path, cur_t5_path, cur_clip_path
+
+ task = task_type_input
+ model_cls = determine_model_cls(model_type_input, dit_path_input, high_noise_path_input)
+ logger.info(f"Auto-determined model_cls: {model_cls} (Model type: {model_type_input})")
+
+ if model_type_input == "wan2.1":
+ dit_quant_detected = detect_quant_scheme(dit_path_input)
+ else:
+ dit_quant_detected = detect_quant_scheme(high_noise_path_input)
+ t5_quant_detected = detect_quant_scheme(t5_path_input)
+ clip_quant_detected = detect_quant_scheme(clip_path_input)
+ logger.info(f"Auto-detected quantization scheme - DIT: {dit_quant_detected}, T5: {t5_quant_detected}, CLIP: {clip_quant_detected}")
+
+ if model_path_input and model_path_input.strip():
+ model_path = model_path_input.strip()
+
+ if os.path.exists(os.path.join(model_path, "config.json")):
+ with open(os.path.join(model_path, "config.json"), "r") as f:
+ model_config = json.load(f)
+ else:
+ model_config = {}
+
+ save_result_path = generate_unique_filename(output_dir)
+
+ is_dit_quant = dit_quant_detected != "bf16"
+ is_t5_quant = t5_quant_detected != "bf16"
+ is_clip_quant = clip_quant_detected != "fp16"
+
+ dit_quantized_ckpt = None
+ dit_original_ckpt = None
+ high_noise_quantized_ckpt = None
+ low_noise_quantized_ckpt = None
+ high_noise_original_ckpt = None
+ low_noise_original_ckpt = None
+
+ if is_dit_quant:
+ dit_quant_scheme = f"{dit_quant_detected}-{quant_op}"
+ if "wan2.1" in model_cls:
+ dit_quantized_ckpt = os.path.join(model_path, dit_path_input)
+ else:
+ high_noise_quantized_ckpt = os.path.join(model_path, high_noise_path_input)
+ low_noise_quantized_ckpt = os.path.join(model_path, low_noise_path_input)
+ else:
+ dit_quantized_ckpt = "Default"
+ if "wan2.1" in model_cls:
+ dit_original_ckpt = os.path.join(model_path, dit_path_input)
+ else:
+ high_noise_original_ckpt = os.path.join(model_path, high_noise_path_input)
+ low_noise_original_ckpt = os.path.join(model_path, low_noise_path_input)
+
+ # Use frontend-selected T5 path
+ if is_t5_quant:
+ t5_quantized_ckpt = os.path.join(model_path, t5_path_input)
+ t5_quant_scheme = f"{t5_quant_detected}-{quant_op}"
+ t5_original_ckpt = None
+ else:
+ t5_quantized_ckpt = None
+ t5_quant_scheme = None
+ t5_original_ckpt = os.path.join(model_path, t5_path_input)
+
+ # Use frontend-selected CLIP path
+ if is_clip_quant:
+ clip_quantized_ckpt = os.path.join(model_path, clip_path_input)
+ clip_quant_scheme = f"{clip_quant_detected}-{quant_op}"
+ clip_original_ckpt = None
+ else:
+ clip_quantized_ckpt = None
+ clip_quant_scheme = None
+ clip_original_ckpt = os.path.join(model_path, clip_path_input)
+
+ if model_type_input == "wan2.1":
+ current_dit_path = dit_path_input
+ else:
+ current_dit_path = f"{high_noise_path_input}|{low_noise_path_input}" if high_noise_path_input and low_noise_path_input else None
+
+ current_t5_path = t5_path_input
+ current_clip_path = clip_path_input
+
+ needs_reinit = (
+ lazy_load
+ or unload_modules
+ or global_runner is None
+ or current_config is None
+ or cur_dit_path is None
+ or cur_dit_path != current_dit_path
+ or cur_t5_path is None
+ or cur_t5_path != current_t5_path
+ or cur_clip_path is None
+ or cur_clip_path != current_clip_path
+ )
+
+ if cfg_scale == 1:
+ enable_cfg = False
+ else:
+ enable_cfg = True
+
+ vae_name_lower = vae_path_input.lower() if vae_path_input else ""
+ use_tae = "tae" in vae_name_lower or "lighttae" in vae_name_lower
+ use_lightvae = "lightvae" in vae_name_lower
+ need_scaled = "lighttae" in vae_name_lower
+
+ logger.info(f"VAE configuration - use_tae: {use_tae}, use_lightvae: {use_lightvae}, need_scaled: {need_scaled} (VAE: {vae_path_input})")
+
+ config_graio = {
+ "infer_steps": infer_steps,
+ "target_video_length": num_frames,
+ "target_width": int(resolution.split("x")[0]),
+ "target_height": int(resolution.split("x")[1]),
+ "self_attn_1_type": attention_type,
+ "cross_attn_1_type": attention_type,
+ "cross_attn_2_type": attention_type,
+ "enable_cfg": enable_cfg,
+ "sample_guide_scale": cfg_scale,
+ "sample_shift": sample_shift,
+ "fps": fps,
+ "feature_caching": "NoCaching",
+ "do_mm_calib": False,
+ "parallel_attn_type": None,
+ "parallel_vae": False,
+ "max_area": False,
+ "vae_stride": (4, 8, 8),
+ "patch_size": (1, 2, 2),
+ "lora_path": None,
+ "strength_model": 1.0,
+ "use_prompt_enhancer": False,
+ "text_len": 512,
+ "denoising_step_list": [1000, 750, 500, 250],
+ "cpu_offload": True if "wan2.2" in model_cls else cpu_offload,
+ "offload_granularity": "phase" if "wan2.2" in model_cls else offload_granularity,
+ "t5_cpu_offload": t5_cpu_offload,
+ "clip_cpu_offload": clip_cpu_offload,
+ "vae_cpu_offload": vae_cpu_offload,
+ "dit_quantized": is_dit_quant,
+ "dit_quant_scheme": dit_quant_scheme,
+ "dit_quantized_ckpt": dit_quantized_ckpt,
+ "dit_original_ckpt": dit_original_ckpt,
+ "high_noise_quantized_ckpt": high_noise_quantized_ckpt,
+ "low_noise_quantized_ckpt": low_noise_quantized_ckpt,
+ "high_noise_original_ckpt": high_noise_original_ckpt,
+ "low_noise_original_ckpt": low_noise_original_ckpt,
+ "t5_original_ckpt": t5_original_ckpt,
+ "t5_quantized": is_t5_quant,
+ "t5_quantized_ckpt": t5_quantized_ckpt,
+ "t5_quant_scheme": t5_quant_scheme,
+ "clip_original_ckpt": clip_original_ckpt,
+ "clip_quantized": is_clip_quant,
+ "clip_quantized_ckpt": clip_quantized_ckpt,
+ "clip_quant_scheme": clip_quant_scheme,
+ "vae_path": os.path.join(model_path, vae_path_input),
+ "use_tiling_vae": use_tiling_vae,
+ "use_tae": use_tae,
+ "use_lightvae": use_lightvae,
+ "need_scaled": need_scaled,
+ "lazy_load": lazy_load,
+ "rope_chunk": rope_chunk,
+ "rope_chunk_size": rope_chunk_size,
+ "clean_cuda_cache": clean_cuda_cache,
+ "unload_modules": unload_modules,
+ "seq_parallel": False,
+ "warm_up_cpu_buffers": False,
+ "boundary_step_index": 2,
+ "boundary": 0.900,
+ "use_image_encoder": False if "wan2.2" in model_cls else True,
+ "rope_type": "flashinfer" if apply_rope_with_cos_sin_cache_inplace else "torch",
+ }
+
+ args = argparse.Namespace(
+ model_cls=model_cls,
+ seed=seed,
+ task=task,
+ model_path=model_path,
+ prompt_enhancer=None,
+ prompt=prompt,
+ negative_prompt=negative_prompt,
+ image_path=image_path,
+ save_result_path=save_result_path,
+ return_result_tensor=False,
+ )
+
+ config = get_default_config()
+ config.update({k: v for k, v in vars(args).items()})
+ config.update(model_config)
+ config.update(config_graio)
+
+ logger.info(f"Using model: {model_path}")
+ logger.info(f"Inference configuration:\n{json.dumps(config, indent=4, ensure_ascii=False)}")
+
+ # Initialize or reuse the runner
+ runner = global_runner
+ if needs_reinit:
+ if runner is not None:
+ del runner
+ torch.cuda.empty_cache()
+ gc.collect()
+
+ from lightx2v.infer import init_runner # noqa
+
+ runner = init_runner(config)
+ input_info = set_input_info(args)
+
+ current_config = config
+ cur_dit_path = current_dit_path
+ cur_t5_path = current_t5_path
+ cur_clip_path = current_clip_path
+
+ if not lazy_load:
+ global_runner = runner
+ else:
+ runner.config = config
+
+ runner.run_pipeline(input_info)
+ cleanup_memory()
+
+ return save_result_path
+
+
+def handle_lazy_load_change(lazy_load_enabled):
+ """Handle lazy_load checkbox change to automatically enable unload_modules"""
+ return gr.update(value=lazy_load_enabled)
+
+
+def auto_configure(resolution):
+ """Auto-configure inference options based on machine configuration and resolution"""
+ default_config = {
+ "lazy_load_val": False,
+ "rope_chunk_val": False,
+ "rope_chunk_size_val": 100,
+ "clean_cuda_cache_val": False,
+ "cpu_offload_val": False,
+ "offload_granularity_val": "block",
+ "t5_cpu_offload_val": False,
+ "clip_cpu_offload_val": False,
+ "vae_cpu_offload_val": False,
+ "unload_modules_val": False,
+ "attention_type_val": attn_op_choices[0][1],
+ "quant_op_val": quant_op_choices[0][1],
+ "use_tiling_vae_val": False,
+ }
+
+ gpu_memory = round(get_gpu_memory())
+ cpu_memory = round(get_cpu_memory())
+
+ attn_priority = ["sage_attn3", "sage_attn2", "flash_attn3", "flash_attn2", "torch_sdpa"]
+
+ if is_ada_architecture_gpu():
+ quant_op_priority = ["q8f", "vllm", "sgl"]
+ else:
+ quant_op_priority = ["vllm", "sgl", "q8f"]
+
+ for op in attn_priority:
+ if dict(available_attn_ops).get(op):
+ default_config["attention_type_val"] = dict(attn_op_choices)[op]
+ break
+
+ for op in quant_op_priority:
+ if dict(available_quant_ops).get(op):
+ default_config["quant_op_val"] = dict(quant_op_choices)[op]
+ break
+
+ if resolution in [
+ "1280x720",
+ "720x1280",
+ "1280x544",
+ "544x1280",
+ "1104x832",
+ "832x1104",
+ "960x960",
+ ]:
+ res = "720p"
+ elif resolution in [
+ "960x544",
+ "544x960",
+ ]:
+ res = "540p"
+ else:
+ res = "480p"
+
+ if res == "720p":
+ gpu_rules = [
+ (80, {}),
+ (40, {"cpu_offload_val": False, "t5_cpu_offload_val": True, "vae_cpu_offload_val": True, "clip_cpu_offload_val": True}),
+ (32, {"cpu_offload_val": True, "t5_cpu_offload_val": False, "vae_cpu_offload_val": False, "clip_cpu_offload_val": False}),
+ (
+ 24,
+ {
+ "cpu_offload_val": True,
+ "use_tiling_vae_val": True,
+ "t5_cpu_offload_val": True,
+ "vae_cpu_offload_val": True,
+ "clip_cpu_offload_val": True,
+ },
+ ),
+ (
+ 16,
+ {
+ "cpu_offload_val": True,
+ "t5_cpu_offload_val": True,
+ "vae_cpu_offload_val": True,
+ "clip_cpu_offload_val": True,
+ "use_tiling_vae_val": True,
+ "offload_granularity_val": "phase",
+ "rope_chunk_val": True,
+ "rope_chunk_size_val": 100,
+ },
+ ),
+ (
+ 8,
+ {
+ "cpu_offload_val": True,
+ "t5_cpu_offload_val": True,
+ "vae_cpu_offload_val": True,
+ "clip_cpu_offload_val": True,
+ "use_tiling_vae_val": True,
+ "offload_granularity_val": "phase",
+ "rope_chunk_val": True,
+ "rope_chunk_size_val": 100,
+ "clean_cuda_cache_val": True,
+ },
+ ),
+ ]
+
+ else:
+ gpu_rules = [
+ (80, {}),
+ (40, {"cpu_offload_val": False, "t5_cpu_offload_val": True, "vae_cpu_offload_val": True, "clip_cpu_offload_val": True}),
+ (32, {"cpu_offload_val": True, "t5_cpu_offload_val": False, "vae_cpu_offload_val": False, "clip_cpu_offload_val": False}),
+ (
+ 24,
+ {
+ "cpu_offload_val": True,
+ "t5_cpu_offload_val": True,
+ "vae_cpu_offload_val": True,
+ "clip_cpu_offload_val": True,
+ "use_tiling_vae_val": True,
+ },
+ ),
+ (
+ 16,
+ {
+ "cpu_offload_val": True,
+ "t5_cpu_offload_val": True,
+ "vae_cpu_offload_val": True,
+ "clip_cpu_offload_val": True,
+ "use_tiling_vae_val": True,
+ "offload_granularity_val": "phase",
+ },
+ ),
+ (
+ 8,
+ {
+ "cpu_offload_val": True,
+ "t5_cpu_offload_val": True,
+ "vae_cpu_offload_val": True,
+ "clip_cpu_offload_val": True,
+ "use_tiling_vae_val": True,
+ "offload_granularity_val": "phase",
+ },
+ ),
+ ]
+
+ cpu_rules = [
+ (128, {}),
+ (64, {}),
+ (32, {"unload_modules_val": True}),
+ (
+ 16,
+ {
+ "lazy_load_val": True,
+ "unload_modules_val": True,
+ },
+ ),
+ ]
+
+ for threshold, updates in gpu_rules:
+ if gpu_memory >= threshold:
+ default_config.update(updates)
+ break
+
+ for threshold, updates in cpu_rules:
+ if cpu_memory >= threshold:
+ default_config.update(updates)
+ break
+
+ return (
+ gr.update(value=default_config["lazy_load_val"]),
+ gr.update(value=default_config["rope_chunk_val"]),
+ gr.update(value=default_config["rope_chunk_size_val"]),
+ gr.update(value=default_config["clean_cuda_cache_val"]),
+ gr.update(value=default_config["cpu_offload_val"]),
+ gr.update(value=default_config["offload_granularity_val"]),
+ gr.update(value=default_config["t5_cpu_offload_val"]),
+ gr.update(value=default_config["clip_cpu_offload_val"]),
+ gr.update(value=default_config["vae_cpu_offload_val"]),
+ gr.update(value=default_config["unload_modules_val"]),
+ gr.update(value=default_config["attention_type_val"]),
+ gr.update(value=default_config["quant_op_val"]),
+ gr.update(value=default_config["use_tiling_vae_val"]),
+ )
+
+
+css = """
+ .main-content { max-width: 1600px; margin: auto; padding: 20px; }
+ .warning { color: #ff6b6b; font-weight: bold; }
+
+ /* Model configuration area styles */
+ .model-config {
+ margin-bottom: 20px !important;
+ border: 1px solid #e0e0e0;
+ border-radius: 12px;
+ padding: 15px;
+ background: linear-gradient(135deg, #f5f7fa 0%, #c3cfe2 100%);
+ }
+
+ /* Input parameters area styles */
+ .input-params {
+ margin-bottom: 20px !important;
+ border: 1px solid #e0e0e0;
+ border-radius: 12px;
+ padding: 15px;
+ background: linear-gradient(135deg, #fff5f5 0%, #ffeef0 100%);
+ }
+
+ /* Output video area styles */
+ .output-video {
+ border: 1px solid #e0e0e0;
+ border-radius: 12px;
+ padding: 20px;
+ background: linear-gradient(135deg, #e0f2fe 0%, #bae6fd 100%);
+ min-height: 400px;
+ }
+
+ /* Generate button styles */
+ .generate-btn {
+ width: 100%;
+ margin-top: 20px;
+ padding: 15px 30px !important;
+ font-size: 18px !important;
+ font-weight: bold !important;
+ background: linear-gradient(135deg, #667eea 0%, #764ba2 100%) !important;
+ border: none !important;
+ border-radius: 10px !important;
+ box-shadow: 0 4px 15px rgba(102, 126, 234, 0.4) !important;
+ transition: all 0.3s ease !important;
+ }
+ .generate-btn:hover {
+ transform: translateY(-2px);
+ box-shadow: 0 6px 20px rgba(102, 126, 234, 0.6) !important;
+ }
+
+ /* Accordion header styles */
+ .model-config .gr-accordion-header,
+ .input-params .gr-accordion-header,
+ .output-video .gr-accordion-header {
+ font-size: 20px !important;
+ font-weight: bold !important;
+ padding: 15px !important;
+ }
+
+ /* Optimize spacing */
+ .gr-row {
+ margin-bottom: 15px;
+ }
+
+ /* Video player styles */
+ .output-video video {
+ border-radius: 10px;
+ box-shadow: 0 4px 15px rgba(0, 0, 0, 0.1);
+ }
+ """
+
+
+def main():
+ with gr.Blocks(title="Lightx2v (Lightweight Video Inference and Generation Engine)") as demo:
+ gr.Markdown(f"# 🎬 LightX2V Video Generator")
+ gr.HTML(f"")
+ # Main layout: left and right columns
+ with gr.Row():
+ # Left: configuration and input area
+ with gr.Column(scale=5):
+ # Model configuration area
+ with gr.Accordion("🗂️ Model Configuration", open=True, elem_classes=["model-config"]):
+ # FP8 support notice
+ if not is_fp8_supported_gpu():
+ gr.Markdown("⚠️ **Your device does not support FP8 inference**. Models containing FP8 have been automatically hidden.")
+
+ # Hidden state components
+ model_path_input = gr.Textbox(value=model_path, visible=False)
+
+ # Model type + Task type
+ with gr.Row():
+ model_type_input = gr.Radio(
+ label="Model Type",
+ choices=["wan2.1", "wan2.2"],
+ value="wan2.1",
+ info="wan2.2 requires separate high noise and low noise models",
+ )
+ task_type_input = gr.Radio(
+ label="Task Type",
+ choices=["i2v", "t2v"],
+ value="i2v",
+ info="i2v: Image-to-video, t2v: Text-to-video",
+ )
+
+ # wan2.1: Diffusion model (single row)
+ with gr.Row() as wan21_row:
+ dit_path_input = gr.Dropdown(
+ label="🎨 Diffusion Model",
+ choices=get_dit_choices(model_path, "wan2.1"),
+ value=get_dit_choices(model_path, "wan2.1")[0] if get_dit_choices(model_path, "wan2.1") else "",
+ allow_custom_value=True,
+ visible=True,
+ )
+
+ # wan2.2 specific: high noise model + low noise model (hidden by default)
+ with gr.Row(visible=False) as wan22_row:
+ high_noise_path_input = gr.Dropdown(
+ label="🔊 High Noise Model",
+ choices=get_high_noise_choices(model_path),
+ value=get_high_noise_choices(model_path)[0] if get_high_noise_choices(model_path) else "",
+ allow_custom_value=True,
+ )
+ low_noise_path_input = gr.Dropdown(
+ label="🔇 Low Noise Model",
+ choices=get_low_noise_choices(model_path),
+ value=get_low_noise_choices(model_path)[0] if get_low_noise_choices(model_path) else "",
+ allow_custom_value=True,
+ )
+
+ # Text encoder (single row)
+ with gr.Row():
+ t5_path_input = gr.Dropdown(
+ label="📝 Text Encoder",
+ choices=get_t5_choices(model_path),
+ value=get_t5_choices(model_path)[0] if get_t5_choices(model_path) else "",
+ allow_custom_value=True,
+ )
+
+ # Image encoder + VAE decoder
+ with gr.Row():
+ clip_path_input = gr.Dropdown(
+ label="🖼️ Image Encoder",
+ choices=get_clip_choices(model_path),
+ value=get_clip_choices(model_path)[0] if get_clip_choices(model_path) else "",
+ allow_custom_value=True,
+ )
+ vae_path_input = gr.Dropdown(
+ label="🎞️ VAE Decoder",
+ choices=get_vae_choices(model_path),
+ value=get_vae_choices(model_path)[0] if get_vae_choices(model_path) else "",
+ allow_custom_value=True,
+ )
+
+ # Attention operator and quantization matrix multiplication operator
+ with gr.Row():
+ attention_type = gr.Dropdown(
+ label="⚡ Attention Operator",
+ choices=[op[1] for op in attn_op_choices],
+ value=attn_op_choices[0][1] if attn_op_choices else "",
+ info="Use appropriate attention operators to accelerate inference",
+ )
+ quant_op = gr.Dropdown(
+ label="Quantization Matmul Operator",
+ choices=[op[1] for op in quant_op_choices],
+ value=quant_op_choices[0][1],
+ info="Select quantization matrix multiplication operator to accelerate inference",
+ interactive=True,
+ )
+
+ # Determine if model is distill version
+ def is_distill_model(model_type, dit_path, high_noise_path):
+ """Determine if model is distill version based on model type and path"""
+ if model_type == "wan2.1":
+ check_name = dit_path.lower() if dit_path else ""
+ else:
+ check_name = high_noise_path.lower() if high_noise_path else ""
+ return "4step" in check_name
+
+ # Model type change event
+ def on_model_type_change(model_type, model_path_val):
+ if model_type == "wan2.2":
+ return gr.update(visible=False), gr.update(visible=True), gr.update()
+ else:
+ # Update wan2.1 Diffusion model options
+ dit_choices = get_dit_choices(model_path_val, "wan2.1")
+ return (
+ gr.update(visible=True),
+ gr.update(visible=False),
+ gr.update(choices=dit_choices, value=dit_choices[0] if dit_choices else ""),
+ )
+
+ model_type_input.change(
+ fn=on_model_type_change,
+ inputs=[model_type_input, model_path_input],
+ outputs=[wan21_row, wan22_row, dit_path_input],
+ )
+
+ # Input parameters area
+ with gr.Accordion("📥 Input Parameters", open=True, elem_classes=["input-params"]):
+ # Image input (shown for i2v)
+ with gr.Row(visible=True) as image_input_row:
+ image_path = gr.Image(
+ label="Input Image",
+ type="filepath",
+ height=300,
+ interactive=True,
+ )
+
+ # Task type change event
+ def on_task_type_change(task_type):
+ return gr.update(visible=(task_type == "i2v"))
+
+ task_type_input.change(
+ fn=on_task_type_change,
+ inputs=[task_type_input],
+ outputs=[image_input_row],
+ )
+
+ with gr.Row():
+ with gr.Column():
+ prompt = gr.Textbox(
+ label="Prompt",
+ lines=3,
+ placeholder="Describe the video content...",
+ max_lines=5,
+ )
+ with gr.Column():
+ negative_prompt = gr.Textbox(
+ label="Negative Prompt",
+ lines=3,
+ placeholder="What you don't want to appear in the video...",
+ max_lines=5,
+ value="Camera shake, bright tones, overexposed, static, blurred details, subtitles, style, works, paintings, images, static, overall gray, worst quality, low quality, JPEG compression residue, ugly, incomplete, extra fingers, poorly drawn hands, poorly drawn faces, deformed, disfigured, misshapen limbs, fused fingers, still picture, messy background, three legs, many people in the background, walking backwards",
+ )
+ with gr.Column():
+ resolution = gr.Dropdown(
+ choices=[
+ # 720p
+ ("1280x720 (16:9, 720p)", "1280x720"),
+ ("720x1280 (9:16, 720p)", "720x1280"),
+ ("1280x544 (21:9, 720p)", "1280x544"),
+ ("544x1280 (9:21, 720p)", "544x1280"),
+ ("1104x832 (4:3, 720p)", "1104x832"),
+ ("832x1104 (3:4, 720p)", "832x1104"),
+ ("960x960 (1:1, 720p)", "960x960"),
+ # 480p
+ ("960x544 (16:9, 540p)", "960x544"),
+ ("544x960 (9:16, 540p)", "544x960"),
+ ("832x480 (16:9, 480p)", "832x480"),
+ ("480x832 (9:16, 480p)", "480x832"),
+ ("832x624 (4:3, 480p)", "832x624"),
+ ("624x832 (3:4, 480p)", "624x832"),
+ ("720x720 (1:1, 480p)", "720x720"),
+ ("512x512 (1:1, 480p)", "512x512"),
+ ],
+ value="832x480",
+ label="Maximum Resolution",
+ )
+
+ with gr.Column(scale=9):
+ seed = gr.Slider(
+ label="Random Seed",
+ minimum=0,
+ maximum=MAX_NUMPY_SEED,
+ step=1,
+ value=generate_random_seed(),
+ )
+ with gr.Column():
+ default_dit = get_dit_choices(model_path, "wan2.1")[0] if get_dit_choices(model_path, "wan2.1") else ""
+ default_high_noise = get_high_noise_choices(model_path)[0] if get_high_noise_choices(model_path) else ""
+ default_is_distill = is_distill_model("wan2.1", default_dit, default_high_noise)
+
+ if default_is_distill:
+ infer_steps = gr.Slider(
+ label="Inference Steps",
+ minimum=1,
+ maximum=100,
+ step=1,
+ value=4,
+ info="Distill model inference steps default to 4.",
+ )
+ else:
+ infer_steps = gr.Slider(
+ label="Inference Steps",
+ minimum=1,
+ maximum=100,
+ step=1,
+ value=40,
+ info="Number of inference steps for video generation. Increasing steps may improve quality but reduce speed.",
+ )
+
+ # Dynamically update inference steps when model path changes
+ def update_infer_steps(model_type, dit_path, high_noise_path):
+ is_distill = is_distill_model(model_type, dit_path, high_noise_path)
+ if is_distill:
+ return gr.update(minimum=1, maximum=100, value=4, interactive=True)
+ else:
+ return gr.update(minimum=1, maximum=100, value=40, interactive=True)
+
+ # Listen to model path changes
+ dit_path_input.change(
+ fn=lambda mt, dp, hnp: update_infer_steps(mt, dp, hnp),
+ inputs=[model_type_input, dit_path_input, high_noise_path_input],
+ outputs=[infer_steps],
+ )
+ high_noise_path_input.change(
+ fn=lambda mt, dp, hnp: update_infer_steps(mt, dp, hnp),
+ inputs=[model_type_input, dit_path_input, high_noise_path_input],
+ outputs=[infer_steps],
+ )
+ model_type_input.change(
+ fn=lambda mt, dp, hnp: update_infer_steps(mt, dp, hnp),
+ inputs=[model_type_input, dit_path_input, high_noise_path_input],
+ outputs=[infer_steps],
+ )
+
+ # Set default CFG based on model class
+ # CFG scale factor: default to 1 for distill, otherwise 5
+ default_cfg_scale = 1 if default_is_distill else 5
+ # enable_cfg is not exposed to frontend, automatically set based on cfg_scale
+ # If cfg_scale == 1, then enable_cfg = False, otherwise enable_cfg = True
+ default_enable_cfg = False if default_cfg_scale == 1 else True
+ enable_cfg = gr.Checkbox(
+ label="Enable Classifier-Free Guidance",
+ value=default_enable_cfg,
+ visible=False, # Hidden, not exposed to frontend
+ )
+
+ with gr.Row():
+ sample_shift = gr.Slider(
+ label="Distribution Shift",
+ value=5,
+ minimum=0,
+ maximum=10,
+ step=1,
+ info="Controls the degree of distribution shift for samples. Larger values indicate more significant shifts.",
+ )
+ cfg_scale = gr.Slider(
+ label="CFG Scale Factor",
+ minimum=1,
+ maximum=10,
+ step=1,
+ value=default_cfg_scale,
+ info="Controls the influence strength of the prompt. Higher values give more influence to the prompt. When value is 1, CFG is automatically disabled.",
+ )
+
+ # Update enable_cfg based on cfg_scale
+ def update_enable_cfg(cfg_scale_val):
+ """Automatically set enable_cfg based on cfg_scale value"""
+ if cfg_scale_val == 1:
+ return gr.update(value=False)
+ else:
+ return gr.update(value=True)
+
+ # Dynamically update CFG scale factor and enable_cfg when model path changes
+ def update_cfg_scale(model_type, dit_path, high_noise_path):
+ is_distill = is_distill_model(model_type, dit_path, high_noise_path)
+ if is_distill:
+ new_cfg_scale = 1
+ else:
+ new_cfg_scale = 5
+ new_enable_cfg = False if new_cfg_scale == 1 else True
+ return gr.update(value=new_cfg_scale), gr.update(value=new_enable_cfg)
+
+ dit_path_input.change(
+ fn=lambda mt, dp, hnp: update_cfg_scale(mt, dp, hnp),
+ inputs=[model_type_input, dit_path_input, high_noise_path_input],
+ outputs=[cfg_scale, enable_cfg],
+ )
+ high_noise_path_input.change(
+ fn=lambda mt, dp, hnp: update_cfg_scale(mt, dp, hnp),
+ inputs=[model_type_input, dit_path_input, high_noise_path_input],
+ outputs=[cfg_scale, enable_cfg],
+ )
+ model_type_input.change(
+ fn=lambda mt, dp, hnp: update_cfg_scale(mt, dp, hnp),
+ inputs=[model_type_input, dit_path_input, high_noise_path_input],
+ outputs=[cfg_scale, enable_cfg],
+ )
+
+ cfg_scale.change(
+ fn=update_enable_cfg,
+ inputs=[cfg_scale],
+ outputs=[enable_cfg],
+ )
+
+ with gr.Row():
+ fps = gr.Slider(
+ label="Frames Per Second (FPS)",
+ minimum=8,
+ maximum=30,
+ step=1,
+ value=16,
+ info="Frames per second of the video. Higher FPS results in smoother videos.",
+ )
+ num_frames = gr.Slider(
+ label="Total Frames",
+ minimum=16,
+ maximum=120,
+ step=1,
+ value=81,
+ info="Total number of frames in the video. More frames result in longer videos.",
+ )
+
+ save_result_path = gr.Textbox(
+ label="Output Video Path",
+ value=generate_unique_filename(output_dir),
+ info="Must include .mp4 extension. If left blank or using the default value, a unique filename will be automatically generated.",
+ visible=False, # Hide output path, auto-generated
+ )
+
+ with gr.Column(scale=4):
+ with gr.Accordion("📤 Generated Video", open=True, elem_classes=["output-video"]):
+ output_video = gr.Video(
+ label="",
+ height=600,
+ autoplay=True,
+ show_label=False,
+ )
+
+ infer_btn = gr.Button("🎬 Generate Video", variant="primary", size="lg", elem_classes=["generate-btn"])
+
+ rope_chunk = gr.Checkbox(label="Chunked Rotary Position Embedding", value=False, visible=False)
+ rope_chunk_size = gr.Slider(label="Rotary Embedding Chunk Size", value=100, minimum=100, maximum=10000, step=100, visible=False)
+ unload_modules = gr.Checkbox(label="Unload Modules", value=False, visible=False)
+ clean_cuda_cache = gr.Checkbox(label="Clean CUDA Memory Cache", value=False, visible=False)
+ cpu_offload = gr.Checkbox(label="CPU Offloading", value=False, visible=False)
+ lazy_load = gr.Checkbox(label="Enable Lazy Loading", value=False, visible=False)
+ offload_granularity = gr.Dropdown(label="Dit Offload Granularity", choices=["block", "phase"], value="phase", visible=False)
+ t5_cpu_offload = gr.Checkbox(label="T5 CPU Offloading", value=False, visible=False)
+ clip_cpu_offload = gr.Checkbox(label="CLIP CPU Offloading", value=False, visible=False)
+ vae_cpu_offload = gr.Checkbox(label="VAE CPU Offloading", value=False, visible=False)
+ use_tiling_vae = gr.Checkbox(label="VAE Tiling Inference", value=False, visible=False)
+
+ resolution.change(
+ fn=auto_configure,
+ inputs=[resolution],
+ outputs=[
+ lazy_load,
+ rope_chunk,
+ rope_chunk_size,
+ clean_cuda_cache,
+ cpu_offload,
+ offload_granularity,
+ t5_cpu_offload,
+ clip_cpu_offload,
+ vae_cpu_offload,
+ unload_modules,
+ attention_type,
+ quant_op,
+ use_tiling_vae,
+ ],
+ )
+
+ demo.load(
+ fn=lambda res: auto_configure(res),
+ inputs=[resolution],
+ outputs=[
+ lazy_load,
+ rope_chunk,
+ rope_chunk_size,
+ clean_cuda_cache,
+ cpu_offload,
+ offload_granularity,
+ t5_cpu_offload,
+ clip_cpu_offload,
+ vae_cpu_offload,
+ unload_modules,
+ attention_type,
+ quant_op,
+ use_tiling_vae,
+ ],
+ )
+
+ infer_btn.click(
+ fn=run_inference,
+ inputs=[
+ prompt,
+ negative_prompt,
+ save_result_path,
+ infer_steps,
+ num_frames,
+ resolution,
+ seed,
+ sample_shift,
+ enable_cfg,
+ cfg_scale,
+ fps,
+ use_tiling_vae,
+ lazy_load,
+ cpu_offload,
+ offload_granularity,
+ t5_cpu_offload,
+ clip_cpu_offload,
+ vae_cpu_offload,
+ unload_modules,
+ attention_type,
+ quant_op,
+ rope_chunk,
+ rope_chunk_size,
+ clean_cuda_cache,
+ model_path_input,
+ model_type_input,
+ task_type_input,
+ dit_path_input,
+ high_noise_path_input,
+ low_noise_path_input,
+ t5_path_input,
+ clip_path_input,
+ vae_path_input,
+ image_path,
+ ],
+ outputs=output_video,
+ )
+
+ demo.launch(share=True, server_port=args.server_port, server_name=args.server_name, inbrowser=True, allowed_paths=[output_dir])
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser(description="Lightweight Video Generation")
+ parser.add_argument("--model_path", type=str, required=True, help="Model folder path")
+ parser.add_argument("--server_port", type=int, default=7862, help="Server port")
+ parser.add_argument("--server_name", type=str, default="0.0.0.0", help="Server IP")
+ parser.add_argument("--output_dir", type=str, default="./outputs", help="Output video save directory")
+ args = parser.parse_args()
+
+ global model_path, model_cls, output_dir
+ model_path = args.model_path
+ model_cls = "wan2.1"
+ output_dir = args.output_dir
+
+ main()
diff --git a/app/gradio_demo_zh.py b/app/gradio_demo_zh.py
new file mode 100644
index 0000000000000000000000000000000000000000..229409f7bf8df4cce3c056fbe334e680abd8fc7f
--- /dev/null
+++ b/app/gradio_demo_zh.py
@@ -0,0 +1,1442 @@
+import argparse
+import gc
+import glob
+import importlib.util
+import json
+import os
+
+os.environ["PROFILING_DEBUG_LEVEL"] = "2"
+os.environ["PYTORCH_CUDA_ALLOC_CONF"] = "expandable_segments:True"
+os.environ["DTYPE"] = "BF16"
+import random
+from datetime import datetime
+
+import gradio as gr
+import psutil
+import torch
+from loguru import logger
+
+from lightx2v.utils.input_info import set_input_info
+from lightx2v.utils.set_config import get_default_config
+
+try:
+ from flashinfer.rope import apply_rope_with_cos_sin_cache_inplace
+except ImportError:
+ apply_rope_with_cos_sin_cache_inplace = None
+
+
+logger.add(
+ "inference_logs.log",
+ rotation="100 MB",
+ encoding="utf-8",
+ enqueue=True,
+ backtrace=True,
+ diagnose=True,
+)
+
+MAX_NUMPY_SEED = 2**32 - 1
+
+
+def scan_model_path_contents(model_path):
+ """扫描 model_path 目录,返回可用的文件和子目录"""
+ if not model_path or not os.path.exists(model_path):
+ return {"dirs": [], "files": [], "safetensors_dirs": [], "pth_files": []}
+
+ dirs = []
+ files = []
+ safetensors_dirs = []
+ pth_files = []
+
+ try:
+ for item in os.listdir(model_path):
+ item_path = os.path.join(model_path, item)
+ if os.path.isdir(item_path):
+ dirs.append(item)
+ # 检查目录是否包含 safetensors 文件
+ if glob.glob(os.path.join(item_path, "*.safetensors")):
+ safetensors_dirs.append(item)
+ elif os.path.isfile(item_path):
+ files.append(item)
+ if item.endswith(".pth"):
+ pth_files.append(item)
+ except Exception as e:
+ logger.warning(f"扫描目录失败: {e}")
+
+ return {
+ "dirs": sorted(dirs),
+ "files": sorted(files),
+ "safetensors_dirs": sorted(safetensors_dirs),
+ "pth_files": sorted(pth_files),
+ }
+
+
+def get_dit_choices(model_path, model_type="wan2.1"):
+ """获取 Diffusion 模型可选项(根据模型类型筛选)"""
+ contents = scan_model_path_contents(model_path)
+ excluded_keywords = ["vae", "tae", "clip", "t5", "high_noise", "low_noise"]
+ fp8_supported = is_fp8_supported_gpu()
+
+ if model_type == "wan2.1":
+ # wan2.1: 筛选包含 wan2.1 或 Wan2.1 的文件/目录
+ def is_valid(name):
+ name_lower = name.lower()
+ if "wan2.1" not in name_lower:
+ return False
+ if not fp8_supported and "fp8" in name_lower:
+ return False
+ return not any(kw in name_lower for kw in excluded_keywords)
+ else:
+ # wan2.2: 筛选包含 wan2.2 或 Wan2.2 的文件/目录
+ def is_valid(name):
+ name_lower = name.lower()
+ if "wan2.2" not in name_lower:
+ return False
+ if not fp8_supported and "fp8" in name_lower:
+ return False
+ return not any(kw in name_lower for kw in excluded_keywords)
+
+ # 筛选符合条件的目录和文件
+ dir_choices = [d for d in contents["dirs"] if is_valid(d)]
+ file_choices = [f for f in contents["files"] if is_valid(f)]
+ choices = dir_choices + file_choices
+ return choices if choices else [""]
+
+
+def get_high_noise_choices(model_path):
+ """获取高噪模型可选项(包含 high_noise 的文件/目录)"""
+ contents = scan_model_path_contents(model_path)
+ fp8_supported = is_fp8_supported_gpu()
+
+ def is_valid(name):
+ name_lower = name.lower()
+ if not fp8_supported and "fp8" in name_lower:
+ return False
+ return "high_noise" in name_lower or "high-noise" in name_lower
+
+ dir_choices = [d for d in contents["dirs"] if is_valid(d)]
+ file_choices = [f for f in contents["files"] if is_valid(f)]
+ choices = dir_choices + file_choices
+ return choices if choices else [""]
+
+
+def get_low_noise_choices(model_path):
+ """获取低噪模型可选项(包含 low_noise 的文件/目录)"""
+ contents = scan_model_path_contents(model_path)
+ fp8_supported = is_fp8_supported_gpu()
+
+ def is_valid(name):
+ name_lower = name.lower()
+ if not fp8_supported and "fp8" in name_lower:
+ return False
+ return "low_noise" in name_lower or "low-noise" in name_lower
+
+ dir_choices = [d for d in contents["dirs"] if is_valid(d)]
+ file_choices = [f for f in contents["files"] if is_valid(f)]
+ choices = dir_choices + file_choices
+ return choices if choices else [""]
+
+
+def get_t5_choices(model_path):
+ """获取 T5 模型可选项(.pth 或 .safetensors 文件,包含 t5 关键字)"""
+ contents = scan_model_path_contents(model_path)
+ fp8_supported = is_fp8_supported_gpu()
+
+ # 从 .pth 文件中筛选
+ pth_choices = [f for f in contents["pth_files"] if "t5" in f.lower() and (fp8_supported or "fp8" not in f.lower())]
+
+ # 从 .safetensors 文件中筛选
+ safetensors_choices = [f for f in contents["files"] if f.endswith(".safetensors") and "t5" in f.lower() and (fp8_supported or "fp8" not in f.lower())]
+
+ # 从包含 safetensors 的目录中筛选
+ safetensors_dir_choices = [d for d in contents["safetensors_dirs"] if "t5" in d.lower() and (fp8_supported or "fp8" not in d.lower())]
+
+ choices = pth_choices + safetensors_choices + safetensors_dir_choices
+ return choices if choices else [""]
+
+
+def get_clip_choices(model_path):
+ """获取 CLIP 模型可选项(.pth 或 .safetensors 文件,包含 clip 关键字)"""
+ contents = scan_model_path_contents(model_path)
+ fp8_supported = is_fp8_supported_gpu()
+
+ # 从 .pth 文件中筛选
+ pth_choices = [f for f in contents["pth_files"] if "clip" in f.lower() and (fp8_supported or "fp8" not in f.lower())]
+
+ # 从 .safetensors 文件中筛选
+ safetensors_choices = [f for f in contents["files"] if f.endswith(".safetensors") and "clip" in f.lower() and (fp8_supported or "fp8" not in f.lower())]
+
+ # 从包含 safetensors 的目录中筛选
+ safetensors_dir_choices = [d for d in contents["safetensors_dirs"] if "clip" in d.lower() and (fp8_supported or "fp8" not in d.lower())]
+
+ choices = pth_choices + safetensors_choices + safetensors_dir_choices
+ return choices if choices else [""]
+
+
+def get_vae_choices(model_path):
+ """获取 VAE 模型可选项(.pth 或 .safetensors 文件,包含 vae/VAE/tae 关键字)"""
+ contents = scan_model_path_contents(model_path)
+ fp8_supported = is_fp8_supported_gpu()
+
+ # 从 .pth 文件中筛选
+ pth_choices = [f for f in contents["pth_files"] if any(kw in f.lower() for kw in ["vae", "tae"]) and (fp8_supported or "fp8" not in f.lower())]
+
+ # 从 .safetensors 文件中筛选
+ safetensors_choices = [f for f in contents["files"] if f.endswith(".safetensors") and any(kw in f.lower() for kw in ["vae", "tae"]) and (fp8_supported or "fp8" not in f.lower())]
+
+ # 从包含 safetensors 的目录中筛选
+ safetensors_dir_choices = [d for d in contents["safetensors_dirs"] if any(kw in d.lower() for kw in ["vae", "tae"]) and (fp8_supported or "fp8" not in d.lower())]
+
+ choices = pth_choices + safetensors_choices + safetensors_dir_choices
+ return choices if choices else [""]
+
+
+def detect_quant_scheme(model_name):
+ """根据模型名字自动检测量化精度
+ - 如果模型名字包含 "int8" → "int8"
+ - 如果模型名字包含 "fp8" 且设备支持 → "fp8"
+ - 否则返回 None(表示不使用量化)
+ """
+ if not model_name:
+ return None
+ name_lower = model_name.lower()
+ if "int8" in name_lower:
+ return "int8"
+ elif "fp8" in name_lower:
+ if is_fp8_supported_gpu():
+ return "fp8"
+ else:
+ # 设备不支持fp8,返回None(使用默认精度)
+ return None
+ return None
+
+
+def update_model_path_options(model_path, model_type="wan2.1"):
+ """当 model_path 或 model_type 改变时,更新所有模型路径选择器"""
+ dit_choices = get_dit_choices(model_path, model_type)
+ high_noise_choices = get_high_noise_choices(model_path)
+ low_noise_choices = get_low_noise_choices(model_path)
+ t5_choices = get_t5_choices(model_path)
+ clip_choices = get_clip_choices(model_path)
+ vae_choices = get_vae_choices(model_path)
+
+ return (
+ gr.update(choices=dit_choices, value=dit_choices[0] if dit_choices else ""),
+ gr.update(choices=high_noise_choices, value=high_noise_choices[0] if high_noise_choices else ""),
+ gr.update(choices=low_noise_choices, value=low_noise_choices[0] if low_noise_choices else ""),
+ gr.update(choices=t5_choices, value=t5_choices[0] if t5_choices else ""),
+ gr.update(choices=clip_choices, value=clip_choices[0] if clip_choices else ""),
+ gr.update(choices=vae_choices, value=vae_choices[0] if vae_choices else ""),
+ )
+
+
+def generate_random_seed():
+ return random.randint(0, MAX_NUMPY_SEED)
+
+
+def is_module_installed(module_name):
+ try:
+ spec = importlib.util.find_spec(module_name)
+ return spec is not None
+ except ModuleNotFoundError:
+ return False
+
+
+def get_available_quant_ops():
+ available_ops = []
+
+ vllm_installed = is_module_installed("vllm")
+ if vllm_installed:
+ available_ops.append(("vllm", True))
+ else:
+ available_ops.append(("vllm", False))
+
+ sgl_installed = is_module_installed("sgl_kernel")
+ if sgl_installed:
+ available_ops.append(("sgl", True))
+ else:
+ available_ops.append(("sgl", False))
+
+ q8f_installed = is_module_installed("q8_kernels")
+ if q8f_installed:
+ available_ops.append(("q8f", True))
+ else:
+ available_ops.append(("q8f", False))
+
+ return available_ops
+
+
+def get_available_attn_ops():
+ available_ops = []
+
+ vllm_installed = is_module_installed("flash_attn")
+ if vllm_installed:
+ available_ops.append(("flash_attn2", True))
+ else:
+ available_ops.append(("flash_attn2", False))
+
+ sgl_installed = is_module_installed("flash_attn_interface")
+ if sgl_installed:
+ available_ops.append(("flash_attn3", True))
+ else:
+ available_ops.append(("flash_attn3", False))
+
+ sage_installed = is_module_installed("sageattention")
+ if sage_installed:
+ available_ops.append(("sage_attn2", True))
+ else:
+ available_ops.append(("sage_attn2", False))
+
+ sage3_installed = is_module_installed("sageattn3")
+ if sage3_installed:
+ available_ops.append(("sage_attn3", True))
+ else:
+ available_ops.append(("sage_attn3", False))
+
+ torch_installed = is_module_installed("torch")
+ if torch_installed:
+ available_ops.append(("torch_sdpa", True))
+ else:
+ available_ops.append(("torch_sdpa", False))
+
+ return available_ops
+
+
+def get_gpu_memory(gpu_idx=0):
+ if not torch.cuda.is_available():
+ return 0
+ try:
+ with torch.cuda.device(gpu_idx):
+ memory_info = torch.cuda.mem_get_info()
+ total_memory = memory_info[1] / (1024**3) # Convert bytes to GB
+ return total_memory
+ except Exception as e:
+ logger.warning(f"获取GPU内存失败: {e}")
+ return 0
+
+
+def get_cpu_memory():
+ available_bytes = psutil.virtual_memory().available
+ return available_bytes / 1024**3
+
+
+def cleanup_memory():
+ gc.collect()
+
+ if torch.cuda.is_available():
+ torch.cuda.empty_cache()
+ torch.cuda.synchronize()
+
+ try:
+ import psutil
+
+ if hasattr(psutil, "virtual_memory"):
+ if os.name == "posix":
+ try:
+ os.system("sync")
+ except: # noqa
+ pass
+ except: # noqa
+ pass
+
+
+def generate_unique_filename(output_dir):
+ os.makedirs(output_dir, exist_ok=True)
+ timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
+ return os.path.join(output_dir, f"{timestamp}.mp4")
+
+
+def is_fp8_supported_gpu():
+ if not torch.cuda.is_available():
+ return False
+ compute_capability = torch.cuda.get_device_capability(0)
+ major, minor = compute_capability
+ return (major == 8 and minor == 9) or (major >= 9)
+
+
+def is_ada_architecture_gpu():
+ if not torch.cuda.is_available():
+ return False
+ try:
+ gpu_name = torch.cuda.get_device_name(0).upper()
+ ada_keywords = ["RTX 40", "RTX40", "4090", "4080", "4070", "4060"]
+ return any(keyword in gpu_name for keyword in ada_keywords)
+ except Exception as e:
+ logger.warning(f"Failed to get GPU name: {e}")
+ return False
+
+
+def get_quantization_options(model_path):
+ """根据model_path动态获取量化选项"""
+ import os
+
+ # 检查子目录
+ subdirs = ["original", "fp8", "int8"]
+ has_subdirs = {subdir: os.path.exists(os.path.join(model_path, subdir)) for subdir in subdirs}
+
+ # 检查根目录下的原始文件
+ t5_bf16_exists = os.path.exists(os.path.join(model_path, "models_t5_umt5-xxl-enc-bf16.pth"))
+ clip_fp16_exists = os.path.exists(os.path.join(model_path, "models_clip_open-clip-xlm-roberta-large-vit-huge-14.pth"))
+
+ # 生成选项
+ def get_choices(has_subdirs, original_type, fp8_type, int8_type, fallback_type, has_original_file=False):
+ choices = []
+ if has_subdirs["original"]:
+ choices.append(original_type)
+ if has_subdirs["fp8"]:
+ choices.append(fp8_type)
+ if has_subdirs["int8"]:
+ choices.append(int8_type)
+
+ # 如果没有子目录但有原始文件,添加原始类型
+ if has_original_file:
+ if not choices or "original" not in choices:
+ choices.append(original_type)
+
+ # 如果没有任何选项,使用默认值
+ if not choices:
+ choices = [fallback_type]
+
+ return choices, choices[0]
+
+ # DIT选项
+ dit_choices, dit_default = get_choices(has_subdirs, "bf16", "fp8", "int8", "bf16")
+
+ # T5选项 - 检查是否有原始文件
+ t5_choices, t5_default = get_choices(has_subdirs, "bf16", "fp8", "int8", "bf16", t5_bf16_exists)
+
+ # CLIP选项 - 检查是否有原始文件
+ clip_choices, clip_default = get_choices(has_subdirs, "fp16", "fp8", "int8", "fp16", clip_fp16_exists)
+
+ return {"dit_choices": dit_choices, "dit_default": dit_default, "t5_choices": t5_choices, "t5_default": t5_default, "clip_choices": clip_choices, "clip_default": clip_default}
+
+
+def determine_model_cls(model_type, dit_name, high_noise_name):
+ """根据模型类型和文件名确定 model_cls"""
+ # 确定要检查的文件名
+ if model_type == "wan2.1":
+ check_name = dit_name.lower() if dit_name else ""
+ is_distill = "4step" in check_name
+ return "wan2.1_distill" if is_distill else "wan2.1"
+ else:
+ # wan2.2
+ check_name = high_noise_name.lower() if high_noise_name else ""
+ is_distill = "4step" in check_name
+ return "wan2.2_moe_distill" if is_distill else "wan2.2_moe"
+
+
+global_runner = None
+current_config = None
+cur_dit_path = None
+cur_t5_path = None
+cur_clip_path = None
+
+available_quant_ops = get_available_quant_ops()
+quant_op_choices = []
+for op_name, is_installed in available_quant_ops:
+ status_text = "✅ 已安装" if is_installed else "❌ 未安装"
+ display_text = f"{op_name} ({status_text})"
+ quant_op_choices.append((op_name, display_text))
+
+available_attn_ops = get_available_attn_ops()
+# 优先级顺序
+attn_priority = ["sage_attn2", "flash_attn3", "flash_attn2", "torch_sdpa"]
+# 按优先级排序,已安装的在前,未安装的在后
+attn_op_choices = []
+attn_op_dict = dict(available_attn_ops)
+
+# 先添加已安装的(按优先级)
+for op_name in attn_priority:
+ if op_name in attn_op_dict and attn_op_dict[op_name]:
+ status_text = "✅ 已安装"
+ display_text = f"{op_name} ({status_text})"
+ attn_op_choices.append((op_name, display_text))
+
+# 再添加未安装的(按优先级)
+for op_name in attn_priority:
+ if op_name in attn_op_dict and not attn_op_dict[op_name]:
+ status_text = "❌ 未安装"
+ display_text = f"{op_name} ({status_text})"
+ attn_op_choices.append((op_name, display_text))
+
+# 添加其他不在优先级列表中的算子(已安装的在前)
+other_ops = [(op_name, is_installed) for op_name, is_installed in available_attn_ops if op_name not in attn_priority]
+for op_name, is_installed in sorted(other_ops, key=lambda x: not x[1]): # 已安装的在前
+ status_text = "✅ 已安装" if is_installed else "❌ 未安装"
+ display_text = f"{op_name} ({status_text})"
+ attn_op_choices.append((op_name, display_text))
+
+
+def run_inference(
+ prompt,
+ negative_prompt,
+ save_result_path,
+ infer_steps,
+ num_frames,
+ resolution,
+ seed,
+ sample_shift,
+ enable_cfg,
+ cfg_scale,
+ fps,
+ use_tiling_vae,
+ lazy_load,
+ cpu_offload,
+ offload_granularity,
+ t5_cpu_offload,
+ clip_cpu_offload,
+ vae_cpu_offload,
+ unload_modules,
+ attention_type,
+ quant_op,
+ rope_chunk,
+ rope_chunk_size,
+ clean_cuda_cache,
+ model_path_input,
+ model_type_input,
+ task_type_input,
+ dit_path_input,
+ high_noise_path_input,
+ low_noise_path_input,
+ t5_path_input,
+ clip_path_input,
+ vae_path_input,
+ image_path=None,
+):
+ cleanup_memory()
+
+ quant_op = quant_op.split("(")[0].strip()
+ attention_type = attention_type.split("(")[0].strip()
+
+ global global_runner, current_config, model_path, model_cls
+ global cur_dit_path, cur_t5_path, cur_clip_path
+
+ task = task_type_input
+ model_cls = determine_model_cls(model_type_input, dit_path_input, high_noise_path_input)
+ logger.info(f"自动确定 model_cls: {model_cls} (模型类型: {model_type_input})")
+
+ if model_type_input == "wan2.1":
+ dit_quant_detected = detect_quant_scheme(dit_path_input)
+ else:
+ dit_quant_detected = detect_quant_scheme(high_noise_path_input)
+ t5_quant_detected = detect_quant_scheme(t5_path_input)
+ clip_quant_detected = detect_quant_scheme(clip_path_input)
+ logger.info(f"自动检测量化精度 - DIT: {dit_quant_detected}, T5: {t5_quant_detected}, CLIP: {clip_quant_detected}")
+
+ if model_path_input and model_path_input.strip():
+ model_path = model_path_input.strip()
+
+ if os.path.exists(os.path.join(model_path, "config.json")):
+ with open(os.path.join(model_path, "config.json"), "r") as f:
+ model_config = json.load(f)
+ else:
+ model_config = {}
+
+ save_result_path = generate_unique_filename(output_dir)
+
+ is_dit_quant = dit_quant_detected != "bf16"
+ is_t5_quant = t5_quant_detected != "bf16"
+ is_clip_quant = clip_quant_detected != "fp16"
+
+ dit_quantized_ckpt = None
+ dit_original_ckpt = None
+ high_noise_quantized_ckpt = None
+ low_noise_quantized_ckpt = None
+ high_noise_original_ckpt = None
+ low_noise_original_ckpt = None
+
+ if is_dit_quant:
+ dit_quant_scheme = f"{dit_quant_detected}-{quant_op}"
+ if "wan2.1" in model_cls:
+ dit_quantized_ckpt = os.path.join(model_path, dit_path_input)
+ else:
+ high_noise_quantized_ckpt = os.path.join(model_path, high_noise_path_input)
+ low_noise_quantized_ckpt = os.path.join(model_path, low_noise_path_input)
+ else:
+ dit_quantized_ckpt = "Default"
+ if "wan2.1" in model_cls:
+ dit_original_ckpt = os.path.join(model_path, dit_path_input)
+ else:
+ high_noise_original_ckpt = os.path.join(model_path, high_noise_path_input)
+ low_noise_original_ckpt = os.path.join(model_path, low_noise_path_input)
+
+ # 使用前端选择的 T5 路径
+ if is_t5_quant:
+ t5_quantized_ckpt = os.path.join(model_path, t5_path_input)
+ t5_quant_scheme = f"{t5_quant_detected}-{quant_op}"
+ t5_original_ckpt = None
+ else:
+ t5_quantized_ckpt = None
+ t5_quant_scheme = None
+ t5_original_ckpt = os.path.join(model_path, t5_path_input)
+
+ # 使用前端选择的 CLIP 路径
+ if is_clip_quant:
+ clip_quantized_ckpt = os.path.join(model_path, clip_path_input)
+ clip_quant_scheme = f"{clip_quant_detected}-{quant_op}"
+ clip_original_ckpt = None
+ else:
+ clip_quantized_ckpt = None
+ clip_quant_scheme = None
+ clip_original_ckpt = os.path.join(model_path, clip_path_input)
+
+ if model_type_input == "wan2.1":
+ current_dit_path = dit_path_input
+ else:
+ current_dit_path = f"{high_noise_path_input}|{low_noise_path_input}" if high_noise_path_input and low_noise_path_input else None
+
+ current_t5_path = t5_path_input
+ current_clip_path = clip_path_input
+
+ needs_reinit = (
+ lazy_load
+ or unload_modules
+ or global_runner is None
+ or current_config is None
+ or cur_dit_path is None
+ or cur_dit_path != current_dit_path
+ or cur_t5_path is None
+ or cur_t5_path != current_t5_path
+ or cur_clip_path is None
+ or cur_clip_path != current_clip_path
+ )
+
+ if cfg_scale == 1:
+ enable_cfg = False
+ else:
+ enable_cfg = True
+
+ vae_name_lower = vae_path_input.lower() if vae_path_input else ""
+ use_tae = "tae" in vae_name_lower or "lighttae" in vae_name_lower
+ use_lightvae = "lightvae" in vae_name_lower
+ need_scaled = "lighttae" in vae_name_lower
+
+ logger.info(f"VAE 配置 - use_tae: {use_tae}, use_lightvae: {use_lightvae}, need_scaled: {need_scaled} (VAE: {vae_path_input})")
+
+ config_graio = {
+ "infer_steps": infer_steps,
+ "target_video_length": num_frames,
+ "target_width": int(resolution.split("x")[0]),
+ "target_height": int(resolution.split("x")[1]),
+ "self_attn_1_type": attention_type,
+ "cross_attn_1_type": attention_type,
+ "cross_attn_2_type": attention_type,
+ "enable_cfg": enable_cfg,
+ "sample_guide_scale": cfg_scale,
+ "sample_shift": sample_shift,
+ "fps": fps,
+ "feature_caching": "NoCaching",
+ "do_mm_calib": False,
+ "parallel_attn_type": None,
+ "parallel_vae": False,
+ "max_area": False,
+ "vae_stride": (4, 8, 8),
+ "patch_size": (1, 2, 2),
+ "lora_path": None,
+ "strength_model": 1.0,
+ "use_prompt_enhancer": False,
+ "text_len": 512,
+ "denoising_step_list": [1000, 750, 500, 250],
+ "cpu_offload": True if "wan2.2" in model_cls else cpu_offload,
+ "offload_granularity": "phase" if "wan2.2" in model_cls else offload_granularity,
+ "t5_cpu_offload": t5_cpu_offload,
+ "clip_cpu_offload": clip_cpu_offload,
+ "vae_cpu_offload": vae_cpu_offload,
+ "dit_quantized": is_dit_quant,
+ "dit_quant_scheme": dit_quant_scheme,
+ "dit_quantized_ckpt": dit_quantized_ckpt,
+ "dit_original_ckpt": dit_original_ckpt,
+ "high_noise_quantized_ckpt": high_noise_quantized_ckpt,
+ "low_noise_quantized_ckpt": low_noise_quantized_ckpt,
+ "high_noise_original_ckpt": high_noise_original_ckpt,
+ "low_noise_original_ckpt": low_noise_original_ckpt,
+ "t5_original_ckpt": t5_original_ckpt,
+ "t5_quantized": is_t5_quant,
+ "t5_quantized_ckpt": t5_quantized_ckpt,
+ "t5_quant_scheme": t5_quant_scheme,
+ "clip_original_ckpt": clip_original_ckpt,
+ "clip_quantized": is_clip_quant,
+ "clip_quantized_ckpt": clip_quantized_ckpt,
+ "clip_quant_scheme": clip_quant_scheme,
+ "vae_path": os.path.join(model_path, vae_path_input),
+ "use_tiling_vae": use_tiling_vae,
+ "use_tae": use_tae,
+ "use_lightvae": use_lightvae,
+ "need_scaled": need_scaled,
+ "lazy_load": lazy_load,
+ "rope_chunk": rope_chunk,
+ "rope_chunk_size": rope_chunk_size,
+ "clean_cuda_cache": clean_cuda_cache,
+ "unload_modules": unload_modules,
+ "seq_parallel": False,
+ "warm_up_cpu_buffers": False,
+ "boundary_step_index": 2,
+ "boundary": 0.900,
+ "use_image_encoder": False if "wan2.2" in model_cls else True,
+ "rope_type": "flashinfer" if apply_rope_with_cos_sin_cache_inplace else "torch",
+ }
+
+ args = argparse.Namespace(
+ model_cls=model_cls,
+ seed=seed,
+ task=task,
+ model_path=model_path,
+ prompt_enhancer=None,
+ prompt=prompt,
+ negative_prompt=negative_prompt,
+ image_path=image_path,
+ save_result_path=save_result_path,
+ return_result_tensor=False,
+ )
+
+ config = get_default_config()
+ config.update({k: v for k, v in vars(args).items()})
+ config.update(model_config)
+ config.update(config_graio)
+
+ logger.info(f"使用模型: {model_path}")
+ logger.info(f"推理配置:\n{json.dumps(config, indent=4, ensure_ascii=False)}")
+
+ # Initialize or reuse the runner
+ runner = global_runner
+ if needs_reinit:
+ if runner is not None:
+ del runner
+ torch.cuda.empty_cache()
+ gc.collect()
+
+ from lightx2v.infer import init_runner # noqa
+
+ runner = init_runner(config)
+ input_info = set_input_info(args)
+
+ current_config = config
+ cur_dit_path = current_dit_path
+ cur_t5_path = current_t5_path
+ cur_clip_path = current_clip_path
+
+ if not lazy_load:
+ global_runner = runner
+ else:
+ runner.config = config
+
+ runner.run_pipeline(input_info)
+ cleanup_memory()
+
+ return save_result_path
+
+
+def handle_lazy_load_change(lazy_load_enabled):
+ """Handle lazy_load checkbox change to automatically enable unload_modules"""
+ return gr.update(value=lazy_load_enabled)
+
+
+def auto_configure(resolution):
+ """根据机器配置和分辨率自动设置推理选项"""
+ default_config = {
+ "lazy_load_val": False,
+ "rope_chunk_val": False,
+ "rope_chunk_size_val": 100,
+ "clean_cuda_cache_val": False,
+ "cpu_offload_val": False,
+ "offload_granularity_val": "block",
+ "t5_cpu_offload_val": False,
+ "clip_cpu_offload_val": False,
+ "vae_cpu_offload_val": False,
+ "unload_modules_val": False,
+ "attention_type_val": attn_op_choices[0][1],
+ "quant_op_val": quant_op_choices[0][1],
+ "use_tiling_vae_val": False,
+ }
+
+ gpu_memory = round(get_gpu_memory())
+ cpu_memory = round(get_cpu_memory())
+
+ attn_priority = ["sage_attn3", "sage_attn2", "flash_attn3", "flash_attn2", "torch_sdpa"]
+
+ if is_ada_architecture_gpu():
+ quant_op_priority = ["q8f", "vllm", "sgl"]
+ else:
+ quant_op_priority = ["vllm", "sgl", "q8f"]
+
+ for op in attn_priority:
+ if dict(available_attn_ops).get(op):
+ default_config["attention_type_val"] = dict(attn_op_choices)[op]
+ break
+
+ for op in quant_op_priority:
+ if dict(available_quant_ops).get(op):
+ default_config["quant_op_val"] = dict(quant_op_choices)[op]
+ break
+
+ if resolution in [
+ "1280x720",
+ "720x1280",
+ "1280x544",
+ "544x1280",
+ "1104x832",
+ "832x1104",
+ "960x960",
+ ]:
+ res = "720p"
+ elif resolution in [
+ "960x544",
+ "544x960",
+ ]:
+ res = "540p"
+ else:
+ res = "480p"
+
+ if res == "720p":
+ gpu_rules = [
+ (80, {}),
+ (40, {"cpu_offload_val": False, "t5_cpu_offload_val": True, "vae_cpu_offload_val": True, "clip_cpu_offload_val": True}),
+ (32, {"cpu_offload_val": True, "t5_cpu_offload_val": False, "vae_cpu_offload_val": False, "clip_cpu_offload_val": False}),
+ (
+ 24,
+ {
+ "cpu_offload_val": True,
+ "use_tiling_vae_val": True,
+ "t5_cpu_offload_val": True,
+ "vae_cpu_offload_val": True,
+ "clip_cpu_offload_val": True,
+ },
+ ),
+ (
+ 16,
+ {
+ "cpu_offload_val": True,
+ "t5_cpu_offload_val": True,
+ "vae_cpu_offload_val": True,
+ "clip_cpu_offload_val": True,
+ "use_tiling_vae_val": True,
+ "offload_granularity_val": "phase",
+ "rope_chunk_val": True,
+ "rope_chunk_size_val": 100,
+ },
+ ),
+ (
+ 8,
+ {
+ "cpu_offload_val": True,
+ "t5_cpu_offload_val": True,
+ "vae_cpu_offload_val": True,
+ "clip_cpu_offload_val": True,
+ "use_tiling_vae_val": True,
+ "offload_granularity_val": "phase",
+ "rope_chunk_val": True,
+ "rope_chunk_size_val": 100,
+ "clean_cuda_cache_val": True,
+ },
+ ),
+ ]
+
+ else:
+ gpu_rules = [
+ (80, {}),
+ (40, {"cpu_offload_val": False, "t5_cpu_offload_val": True, "vae_cpu_offload_val": True, "clip_cpu_offload_val": True}),
+ (32, {"cpu_offload_val": True, "t5_cpu_offload_val": False, "vae_cpu_offload_val": False, "clip_cpu_offload_val": False}),
+ (
+ 24,
+ {
+ "cpu_offload_val": True,
+ "t5_cpu_offload_val": True,
+ "vae_cpu_offload_val": True,
+ "clip_cpu_offload_val": True,
+ "use_tiling_vae_val": True,
+ },
+ ),
+ (
+ 16,
+ {
+ "cpu_offload_val": True,
+ "t5_cpu_offload_val": True,
+ "vae_cpu_offload_val": True,
+ "clip_cpu_offload_val": True,
+ "use_tiling_vae_val": True,
+ "offload_granularity_val": "phase",
+ },
+ ),
+ (
+ 8,
+ {
+ "cpu_offload_val": True,
+ "t5_cpu_offload_val": True,
+ "vae_cpu_offload_val": True,
+ "clip_cpu_offload_val": True,
+ "use_tiling_vae_val": True,
+ "offload_granularity_val": "phase",
+ },
+ ),
+ ]
+
+ cpu_rules = [
+ (128, {}),
+ (64, {}),
+ (32, {"unload_modules_val": True}),
+ (
+ 16,
+ {
+ "lazy_load_val": True,
+ "unload_modules_val": True,
+ },
+ ),
+ ]
+
+ for threshold, updates in gpu_rules:
+ if gpu_memory >= threshold:
+ default_config.update(updates)
+ break
+
+ for threshold, updates in cpu_rules:
+ if cpu_memory >= threshold:
+ default_config.update(updates)
+ break
+
+ return (
+ gr.update(value=default_config["lazy_load_val"]),
+ gr.update(value=default_config["rope_chunk_val"]),
+ gr.update(value=default_config["rope_chunk_size_val"]),
+ gr.update(value=default_config["clean_cuda_cache_val"]),
+ gr.update(value=default_config["cpu_offload_val"]),
+ gr.update(value=default_config["offload_granularity_val"]),
+ gr.update(value=default_config["t5_cpu_offload_val"]),
+ gr.update(value=default_config["clip_cpu_offload_val"]),
+ gr.update(value=default_config["vae_cpu_offload_val"]),
+ gr.update(value=default_config["unload_modules_val"]),
+ gr.update(value=default_config["attention_type_val"]),
+ gr.update(value=default_config["quant_op_val"]),
+ gr.update(value=default_config["use_tiling_vae_val"]),
+ )
+
+
+css = """
+ .main-content { max-width: 1600px; margin: auto; padding: 20px; }
+ .warning { color: #ff6b6b; font-weight: bold; }
+
+ /* 模型配置区域样式 */
+ .model-config {
+ margin-bottom: 20px !important;
+ border: 1px solid #e0e0e0;
+ border-radius: 12px;
+ padding: 15px;
+ background: linear-gradient(135deg, #f5f7fa 0%, #c3cfe2 100%);
+ }
+
+ /* 输入参数区域样式 */
+ .input-params {
+ margin-bottom: 20px !important;
+ border: 1px solid #e0e0e0;
+ border-radius: 12px;
+ padding: 15px;
+ background: linear-gradient(135deg, #fff5f5 0%, #ffeef0 100%);
+ }
+
+ /* 输出视频区域样式 */
+ .output-video {
+ border: 1px solid #e0e0e0;
+ border-radius: 12px;
+ padding: 20px;
+ background: linear-gradient(135deg, #e0f2fe 0%, #bae6fd 100%);
+ min-height: 400px;
+ }
+
+ /* 生成按钮样式 */
+ .generate-btn {
+ width: 100%;
+ margin-top: 20px;
+ padding: 15px 30px !important;
+ font-size: 18px !important;
+ font-weight: bold !important;
+ background: linear-gradient(135deg, #667eea 0%, #764ba2 100%) !important;
+ border: none !important;
+ border-radius: 10px !important;
+ box-shadow: 0 4px 15px rgba(102, 126, 234, 0.4) !important;
+ transition: all 0.3s ease !important;
+ }
+ .generate-btn:hover {
+ transform: translateY(-2px);
+ box-shadow: 0 6px 20px rgba(102, 126, 234, 0.6) !important;
+ }
+
+ /* Accordion 标题样式 */
+ .model-config .gr-accordion-header,
+ .input-params .gr-accordion-header,
+ .output-video .gr-accordion-header {
+ font-size: 20px !important;
+ font-weight: bold !important;
+ padding: 15px !important;
+ }
+
+ /* 优化间距 */
+ .gr-row {
+ margin-bottom: 15px;
+ }
+
+ /* 视频播放器样式 */
+ .output-video video {
+ border-radius: 10px;
+ box-shadow: 0 4px 15px rgba(0, 0, 0, 0.1);
+ }
+ """
+
+
+def main():
+ with gr.Blocks(title="Lightx2v (轻量级视频推理和生成引擎)") as demo:
+ gr.Markdown(f"# 🎬 LightX2V 视频生成器")
+ gr.HTML(f"")
+ # 主布局:左右分栏
+ with gr.Row():
+ # 左侧:配置和输入区域
+ with gr.Column(scale=5):
+ # 模型配置区域
+ with gr.Accordion("🗂️ 模型配置", open=True, elem_classes=["model-config"]):
+ # FP8 支持提示
+ if not is_fp8_supported_gpu():
+ gr.Markdown("⚠️ **您的设备不支持fp8推理**,已自动隐藏包含fp8的模型选项。")
+
+ # 隐藏的状态组件
+ model_path_input = gr.Textbox(value=model_path, visible=False)
+
+ # 模型类型 + 任务类型
+ with gr.Row():
+ model_type_input = gr.Radio(
+ label="模型类型",
+ choices=["wan2.1", "wan2.2"],
+ value="wan2.1",
+ info="wan2.2 需要分别指定高噪模型和低噪模型",
+ )
+ task_type_input = gr.Radio(
+ label="任务类型",
+ choices=["i2v", "t2v"],
+ value="i2v",
+ info="i2v: 图生视频, t2v: 文生视频",
+ )
+
+ # wan2.1:Diffusion模型(单独一行)
+ with gr.Row() as wan21_row:
+ dit_path_input = gr.Dropdown(
+ label="🎨 Diffusion模型",
+ choices=get_dit_choices(model_path, "wan2.1"),
+ value=get_dit_choices(model_path, "wan2.1")[0] if get_dit_choices(model_path, "wan2.1") else "",
+ allow_custom_value=True,
+ visible=True,
+ )
+
+ # wan2.2 专用:高噪模型 + 低噪模型(默认隐藏)
+ with gr.Row(visible=False) as wan22_row:
+ high_noise_path_input = gr.Dropdown(
+ label="🔊 高噪模型",
+ choices=get_high_noise_choices(model_path),
+ value=get_high_noise_choices(model_path)[0] if get_high_noise_choices(model_path) else "",
+ allow_custom_value=True,
+ )
+ low_noise_path_input = gr.Dropdown(
+ label="🔇 低噪模型",
+ choices=get_low_noise_choices(model_path),
+ value=get_low_noise_choices(model_path)[0] if get_low_noise_choices(model_path) else "",
+ allow_custom_value=True,
+ )
+
+ # 文本编码器(单独一行)
+ with gr.Row():
+ t5_path_input = gr.Dropdown(
+ label="📝 文本编码器",
+ choices=get_t5_choices(model_path),
+ value=get_t5_choices(model_path)[0] if get_t5_choices(model_path) else "",
+ allow_custom_value=True,
+ )
+
+ # 图像编码器 + VAE解码器
+ with gr.Row():
+ clip_path_input = gr.Dropdown(
+ label="🖼️ 图像编码器",
+ choices=get_clip_choices(model_path),
+ value=get_clip_choices(model_path)[0] if get_clip_choices(model_path) else "",
+ allow_custom_value=True,
+ )
+ vae_path_input = gr.Dropdown(
+ label="🎞️ VAE解码器",
+ choices=get_vae_choices(model_path),
+ value=get_vae_choices(model_path)[0] if get_vae_choices(model_path) else "",
+ allow_custom_value=True,
+ )
+
+ # 注意力算子和量化矩阵乘法算子
+ with gr.Row():
+ attention_type = gr.Dropdown(
+ label="⚡ 注意力算子",
+ choices=[op[1] for op in attn_op_choices],
+ value=attn_op_choices[0][1] if attn_op_choices else "",
+ info="使用适当的注意力算子加速推理",
+ )
+ quant_op = gr.Dropdown(
+ label="量化矩阵乘法算子",
+ choices=[op[1] for op in quant_op_choices],
+ value=quant_op_choices[0][1],
+ info="选择量化矩阵乘法算子以加速推理",
+ interactive=True,
+ )
+
+ # 判断模型是否是 distill 版本
+ def is_distill_model(model_type, dit_path, high_noise_path):
+ """根据模型类型和路径判断是否是 distill 版本"""
+ if model_type == "wan2.1":
+ check_name = dit_path.lower() if dit_path else ""
+ else:
+ check_name = high_noise_path.lower() if high_noise_path else ""
+ return "4step" in check_name
+
+ # 模型类型切换事件
+ def on_model_type_change(model_type, model_path_val):
+ if model_type == "wan2.2":
+ return gr.update(visible=False), gr.update(visible=True), gr.update()
+ else:
+ # 更新 wan2.1 的 Diffusion 模型选项
+ dit_choices = get_dit_choices(model_path_val, "wan2.1")
+ return (
+ gr.update(visible=True),
+ gr.update(visible=False),
+ gr.update(choices=dit_choices, value=dit_choices[0] if dit_choices else ""),
+ )
+
+ model_type_input.change(
+ fn=on_model_type_change,
+ inputs=[model_type_input, model_path_input],
+ outputs=[wan21_row, wan22_row, dit_path_input],
+ )
+
+ # 输入参数区域
+ with gr.Accordion("📥 输入参数", open=True, elem_classes=["input-params"]):
+ # 图片输入(i2v 时显示)
+ with gr.Row(visible=True) as image_input_row:
+ image_path = gr.Image(
+ label="输入图像",
+ type="filepath",
+ height=300,
+ interactive=True,
+ )
+
+ # 任务类型切换事件
+ def on_task_type_change(task_type):
+ return gr.update(visible=(task_type == "i2v"))
+
+ task_type_input.change(
+ fn=on_task_type_change,
+ inputs=[task_type_input],
+ outputs=[image_input_row],
+ )
+
+ with gr.Row():
+ with gr.Column():
+ prompt = gr.Textbox(
+ label="提示词",
+ lines=3,
+ placeholder="描述视频内容...",
+ max_lines=5,
+ )
+ with gr.Column():
+ negative_prompt = gr.Textbox(
+ label="负向提示词",
+ lines=3,
+ placeholder="不希望出现在视频中的内容...",
+ max_lines=5,
+ value="镜头晃动,色调艳丽,过曝,静态,细节模糊不清,字幕,风格,作品,画作,画面,静止,整体发灰,最差质量,低质量,JPEG压缩残留,丑陋的,残缺的,多余的手指,画得不好的手部,画得不好的脸部,畸形的,毁容的,形态畸形的肢体,手指融合,静止不动的画面,杂乱的背景,三条腿,背景人很多,倒着走",
+ )
+ with gr.Column():
+ resolution = gr.Dropdown(
+ choices=[
+ # 720p
+ ("1280x720 (16:9, 720p)", "1280x720"),
+ ("720x1280 (9:16, 720p)", "720x1280"),
+ ("1280x544 (21:9, 720p)", "1280x544"),
+ ("544x1280 (9:21, 720p)", "544x1280"),
+ ("1104x832 (4:3, 720p)", "1104x832"),
+ ("832x1104 (3:4, 720p)", "832x1104"),
+ ("960x960 (1:1, 720p)", "960x960"),
+ # 480p
+ ("960x544 (16:9, 540p)", "960x544"),
+ ("544x960 (9:16, 540p)", "544x960"),
+ ("832x480 (16:9, 480p)", "832x480"),
+ ("480x832 (9:16, 480p)", "480x832"),
+ ("832x624 (4:3, 480p)", "832x624"),
+ ("624x832 (3:4, 480p)", "624x832"),
+ ("720x720 (1:1, 480p)", "720x720"),
+ ("512x512 (1:1, 480p)", "512x512"),
+ ],
+ value="832x480",
+ label="最大分辨率",
+ )
+
+ with gr.Column(scale=9):
+ seed = gr.Slider(
+ label="随机种子",
+ minimum=0,
+ maximum=MAX_NUMPY_SEED,
+ step=1,
+ value=generate_random_seed(),
+ )
+ with gr.Column():
+ default_dit = get_dit_choices(model_path, "wan2.1")[0] if get_dit_choices(model_path, "wan2.1") else ""
+ default_high_noise = get_high_noise_choices(model_path)[0] if get_high_noise_choices(model_path) else ""
+ default_is_distill = is_distill_model("wan2.1", default_dit, default_high_noise)
+
+ if default_is_distill:
+ infer_steps = gr.Slider(
+ label="推理步数",
+ minimum=1,
+ maximum=100,
+ step=1,
+ value=4,
+ info="蒸馏模型推理步数默认为4。",
+ )
+ else:
+ infer_steps = gr.Slider(
+ label="推理步数",
+ minimum=1,
+ maximum=100,
+ step=1,
+ value=40,
+ info="视频生成的推理步数。增加步数可能提高质量但降低速度。",
+ )
+
+ # 当模型路径改变时,动态更新推理步数
+ def update_infer_steps(model_type, dit_path, high_noise_path):
+ is_distill = is_distill_model(model_type, dit_path, high_noise_path)
+ if is_distill:
+ return gr.update(minimum=1, maximum=100, value=4, interactive=True)
+ else:
+ return gr.update(minimum=1, maximum=100, value=40, interactive=True)
+
+ # 监听模型路径变化
+ dit_path_input.change(
+ fn=lambda mt, dp, hnp: update_infer_steps(mt, dp, hnp),
+ inputs=[model_type_input, dit_path_input, high_noise_path_input],
+ outputs=[infer_steps],
+ )
+ high_noise_path_input.change(
+ fn=lambda mt, dp, hnp: update_infer_steps(mt, dp, hnp),
+ inputs=[model_type_input, dit_path_input, high_noise_path_input],
+ outputs=[infer_steps],
+ )
+ model_type_input.change(
+ fn=lambda mt, dp, hnp: update_infer_steps(mt, dp, hnp),
+ inputs=[model_type_input, dit_path_input, high_noise_path_input],
+ outputs=[infer_steps],
+ )
+
+ # 根据模型类别设置默认CFG
+ # CFG缩放因子:distill 时默认为 1,否则默认为 5
+ default_cfg_scale = 1 if default_is_distill else 5
+ # enable_cfg 不暴露到前端,根据 cfg_scale 自动设置
+ # 如果 cfg_scale == 1,则 enable_cfg = False,否则 enable_cfg = True
+ default_enable_cfg = False if default_cfg_scale == 1 else True
+ enable_cfg = gr.Checkbox(
+ label="启用无分类器引导",
+ value=default_enable_cfg,
+ visible=False, # 隐藏,不暴露到前端
+ )
+
+ with gr.Row():
+ sample_shift = gr.Slider(
+ label="分布偏移",
+ value=5,
+ minimum=0,
+ maximum=10,
+ step=1,
+ info="控制样本分布偏移的程度。值越大表示偏移越明显。",
+ )
+ cfg_scale = gr.Slider(
+ label="CFG缩放因子",
+ minimum=1,
+ maximum=10,
+ step=1,
+ value=default_cfg_scale,
+ info="控制提示词的影响强度。值越高,提示词的影响越大。当值为1时,自动禁用CFG。",
+ )
+
+ # 根据 cfg_scale 更新 enable_cfg
+ def update_enable_cfg(cfg_scale_val):
+ """根据 cfg_scale 的值自动设置 enable_cfg"""
+ if cfg_scale_val == 1:
+ return gr.update(value=False)
+ else:
+ return gr.update(value=True)
+
+ # 当模型路径改变时,动态更新 CFG 缩放因子和 enable_cfg
+ def update_cfg_scale(model_type, dit_path, high_noise_path):
+ is_distill = is_distill_model(model_type, dit_path, high_noise_path)
+ if is_distill:
+ new_cfg_scale = 1
+ else:
+ new_cfg_scale = 5
+ new_enable_cfg = False if new_cfg_scale == 1 else True
+ return gr.update(value=new_cfg_scale), gr.update(value=new_enable_cfg)
+
+ dit_path_input.change(
+ fn=lambda mt, dp, hnp: update_cfg_scale(mt, dp, hnp),
+ inputs=[model_type_input, dit_path_input, high_noise_path_input],
+ outputs=[cfg_scale, enable_cfg],
+ )
+ high_noise_path_input.change(
+ fn=lambda mt, dp, hnp: update_cfg_scale(mt, dp, hnp),
+ inputs=[model_type_input, dit_path_input, high_noise_path_input],
+ outputs=[cfg_scale, enable_cfg],
+ )
+ model_type_input.change(
+ fn=lambda mt, dp, hnp: update_cfg_scale(mt, dp, hnp),
+ inputs=[model_type_input, dit_path_input, high_noise_path_input],
+ outputs=[cfg_scale, enable_cfg],
+ )
+
+ cfg_scale.change(
+ fn=update_enable_cfg,
+ inputs=[cfg_scale],
+ outputs=[enable_cfg],
+ )
+
+ with gr.Row():
+ fps = gr.Slider(
+ label="每秒帧数(FPS)",
+ minimum=8,
+ maximum=30,
+ step=1,
+ value=16,
+ info="视频的每秒帧数。较高的FPS会产生更流畅的视频。",
+ )
+ num_frames = gr.Slider(
+ label="总帧数",
+ minimum=16,
+ maximum=120,
+ step=1,
+ value=81,
+ info="视频中的总帧数。更多帧数会产生更长的视频。",
+ )
+
+ save_result_path = gr.Textbox(
+ label="输出视频路径",
+ value=generate_unique_filename(output_dir),
+ info="必须包含.mp4扩展名。如果留空或使用默认值,将自动生成唯一文件名。",
+ visible=False, # 隐藏输出路径,自动生成
+ )
+
+ with gr.Column(scale=4):
+ with gr.Accordion("📤 生成的视频", open=True, elem_classes=["output-video"]):
+ output_video = gr.Video(
+ label="",
+ height=600,
+ autoplay=True,
+ show_label=False,
+ )
+
+ infer_btn = gr.Button("🎬 生成视频", variant="primary", size="lg", elem_classes=["generate-btn"])
+
+ rope_chunk = gr.Checkbox(label="分块旋转位置编码", value=False, visible=False)
+ rope_chunk_size = gr.Slider(label="旋转编码块大小", value=100, minimum=100, maximum=10000, step=100, visible=False)
+ unload_modules = gr.Checkbox(label="卸载模块", value=False, visible=False)
+ clean_cuda_cache = gr.Checkbox(label="清理CUDA内存缓存", value=False, visible=False)
+ cpu_offload = gr.Checkbox(label="CPU卸载", value=False, visible=False)
+ lazy_load = gr.Checkbox(label="启用延迟加载", value=False, visible=False)
+ offload_granularity = gr.Dropdown(label="Dit卸载粒度", choices=["block", "phase"], value="phase", visible=False)
+ t5_cpu_offload = gr.Checkbox(label="T5 CPU卸载", value=False, visible=False)
+ clip_cpu_offload = gr.Checkbox(label="CLIP CPU卸载", value=False, visible=False)
+ vae_cpu_offload = gr.Checkbox(label="VAE CPU卸载", value=False, visible=False)
+ use_tiling_vae = gr.Checkbox(label="VAE分块推理", value=False, visible=False)
+
+ resolution.change(
+ fn=auto_configure,
+ inputs=[resolution],
+ outputs=[
+ lazy_load,
+ rope_chunk,
+ rope_chunk_size,
+ clean_cuda_cache,
+ cpu_offload,
+ offload_granularity,
+ t5_cpu_offload,
+ clip_cpu_offload,
+ vae_cpu_offload,
+ unload_modules,
+ attention_type,
+ quant_op,
+ use_tiling_vae,
+ ],
+ )
+
+ demo.load(
+ fn=lambda res: auto_configure(res),
+ inputs=[resolution],
+ outputs=[
+ lazy_load,
+ rope_chunk,
+ rope_chunk_size,
+ clean_cuda_cache,
+ cpu_offload,
+ offload_granularity,
+ t5_cpu_offload,
+ clip_cpu_offload,
+ vae_cpu_offload,
+ unload_modules,
+ attention_type,
+ quant_op,
+ use_tiling_vae,
+ ],
+ )
+
+ infer_btn.click(
+ fn=run_inference,
+ inputs=[
+ prompt,
+ negative_prompt,
+ save_result_path,
+ infer_steps,
+ num_frames,
+ resolution,
+ seed,
+ sample_shift,
+ enable_cfg,
+ cfg_scale,
+ fps,
+ use_tiling_vae,
+ lazy_load,
+ cpu_offload,
+ offload_granularity,
+ t5_cpu_offload,
+ clip_cpu_offload,
+ vae_cpu_offload,
+ unload_modules,
+ attention_type,
+ quant_op,
+ rope_chunk,
+ rope_chunk_size,
+ clean_cuda_cache,
+ model_path_input,
+ model_type_input,
+ task_type_input,
+ dit_path_input,
+ high_noise_path_input,
+ low_noise_path_input,
+ t5_path_input,
+ clip_path_input,
+ vae_path_input,
+ image_path,
+ ],
+ outputs=output_video,
+ )
+
+ demo.launch(share=True, server_port=args.server_port, server_name=args.server_name, inbrowser=True, allowed_paths=[output_dir])
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser(description="轻量级视频生成")
+ parser.add_argument("--model_path", type=str, required=True, help="模型文件夹路径")
+ parser.add_argument("--server_port", type=int, default=7862, help="服务器端口")
+ parser.add_argument("--server_name", type=str, default="0.0.0.0", help="服务器IP")
+ parser.add_argument("--output_dir", type=str, default="./outputs", help="输出视频保存目录")
+ args = parser.parse_args()
+
+ global model_path, model_cls, output_dir
+ model_path = args.model_path
+ model_cls = "wan2.1"
+ output_dir = args.output_dir
+
+ main()
diff --git a/app/run_gradio.sh b/app/run_gradio.sh
new file mode 100644
index 0000000000000000000000000000000000000000..f5dbcc55605f33c7d6504a7e3f7e1da372236eb2
--- /dev/null
+++ b/app/run_gradio.sh
@@ -0,0 +1,181 @@
+#!/bin/bash
+
+# Lightx2v Gradio Demo Startup Script
+# Supports both Image-to-Video (i2v) and Text-to-Video (t2v) modes
+
+# ==================== Configuration Area ====================
+# ⚠️ Important: Please modify the following paths according to your actual environment
+
+# 🚨 Storage Performance Tips 🚨
+# 💾 Strongly recommend storing model files on SSD solid-state drives!
+# 📈 SSD can significantly improve model loading speed and inference performance
+# 🐌 Using mechanical hard drives (HDD) may cause slow model loading and affect overall experience
+
+
+# Lightx2v project root directory path
+# Example: /home/user/lightx2v or /data/video_gen/lightx2v
+lightx2v_path=/data/video_gen/lightx2v_debug/LightX2V
+
+# Model path configuration
+# Example: /path/to/Wan2.1-I2V-14B-720P-Lightx2v
+model_path=/models/
+
+# Server configuration
+server_name="0.0.0.0"
+server_port=8033
+
+# Output directory configuration
+output_dir="./outputs"
+
+# GPU configuration
+gpu_id=0
+
+# ==================== Environment Variables Setup ====================
+export CUDA_VISIBLE_DEVICES=$gpu_id
+export CUDA_LAUNCH_BLOCKING=1
+export PYTHONPATH=${lightx2v_path}:$PYTHONPATH
+export PROFILING_DEBUG_LEVEL=2
+export PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True
+
+# ==================== Parameter Parsing ====================
+# Default interface language
+lang="zh"
+
+# 解析命令行参数
+while [[ $# -gt 0 ]]; do
+ case $1 in
+ --lang)
+ lang="$2"
+ shift 2
+ ;;
+ --port)
+ server_port="$2"
+ shift 2
+ ;;
+ --gpu)
+ gpu_id="$2"
+ export CUDA_VISIBLE_DEVICES=$gpu_id
+ shift 2
+ ;;
+ --output_dir)
+ output_dir="$2"
+ shift 2
+ ;;
+ --model_path)
+ model_path="$2"
+ shift 2
+ ;;
+ --help)
+ echo "🎬 Lightx2v Gradio Demo Startup Script"
+ echo "=========================================="
+ echo "Usage: $0 [options]"
+ echo ""
+ echo "📋 Available options:"
+ echo " --lang zh|en Interface language (default: zh)"
+ echo " zh: Chinese interface"
+ echo " en: English interface"
+ echo " --port PORT Server port (default: 8032)"
+ echo " --gpu GPU_ID GPU device ID (default: 0)"
+ echo " --model_path PATH Model path (default: configured in script)"
+ echo " --output_dir DIR Output video save directory (default: ./outputs)"
+ echo " --help Show this help message"
+ echo ""
+ echo "📝 Notes:"
+ echo " - Task type (i2v/t2v) and model type are selected in the web UI"
+ echo " - Model class is auto-detected based on selected diffusion model"
+ echo " - Edit script to configure model paths before first use"
+ echo " - Ensure required Python dependencies are installed"
+ echo " - Recommended to use GPU with 8GB+ VRAM"
+ echo " - 🚨 Strongly recommend storing models on SSD for better performance"
+ exit 0
+ ;;
+ *)
+ echo "Unknown parameter: $1"
+ echo "Use --help to see help information"
+ exit 1
+ ;;
+ esac
+done
+
+# ==================== Parameter Validation ====================
+if [[ "$lang" != "zh" && "$lang" != "en" ]]; then
+ echo "Error: Language must be 'zh' or 'en'"
+ exit 1
+fi
+
+# Check if model path exists
+if [[ ! -d "$model_path" ]]; then
+ echo "❌ Error: Model path does not exist"
+ echo "📁 Path: $model_path"
+ echo "🔧 Solutions:"
+ echo " 1. Check model path configuration in script"
+ echo " 2. Ensure model files are properly downloaded"
+ echo " 3. Verify path permissions are correct"
+ echo " 4. 💾 Recommend storing models on SSD for faster loading"
+ exit 1
+fi
+
+# Select demo file based on language
+if [[ "$lang" == "zh" ]]; then
+ demo_file="gradio_demo_zh.py"
+ echo "🌏 Using Chinese interface"
+else
+ demo_file="gradio_demo.py"
+ echo "🌏 Using English interface"
+fi
+
+# Check if demo file exists
+if [[ ! -f "$demo_file" ]]; then
+ echo "❌ Error: Demo file does not exist"
+ echo "📄 File: $demo_file"
+ echo "🔧 Solutions:"
+ echo " 1. Ensure script is run in the correct directory"
+ echo " 2. Check if file has been renamed or moved"
+ echo " 3. Re-clone or download project files"
+ exit 1
+fi
+
+# ==================== System Information Display ====================
+echo "=========================================="
+echo "🚀 Lightx2v Gradio Demo Starting..."
+echo "=========================================="
+echo "📁 Project path: $lightx2v_path"
+echo "🤖 Model path: $model_path"
+echo "🌏 Interface language: $lang"
+echo "🖥️ GPU device: $gpu_id"
+echo "🌐 Server address: $server_name:$server_port"
+echo "📁 Output directory: $output_dir"
+echo "📝 Note: Task type and model class are selected in web UI"
+echo "=========================================="
+
+# Display system resource information
+echo "💻 System resource information:"
+free -h | grep -E "Mem|Swap"
+echo ""
+
+# Display GPU information
+if command -v nvidia-smi &> /dev/null; then
+ echo "🎮 GPU information:"
+ nvidia-smi --query-gpu=name,memory.total,memory.free --format=csv,noheader,nounits | head -1
+ echo ""
+fi
+
+# ==================== Start Demo ====================
+echo "🎬 Starting Gradio demo..."
+echo "📱 Please access in browser: http://$server_name:$server_port"
+echo "⏹️ Press Ctrl+C to stop service"
+echo "🔄 First startup may take several minutes to load resources..."
+echo "=========================================="
+
+# Start Python demo
+python $demo_file \
+ --model_path "$model_path" \
+ --server_name "$server_name" \
+ --server_port "$server_port" \
+ --output_dir "$output_dir"
+
+# Display final system resource usage
+echo ""
+echo "=========================================="
+echo "📊 Final system resource usage:"
+free -h | grep -E "Mem|Swap"
diff --git a/app/run_gradio_win.bat b/app/run_gradio_win.bat
new file mode 100644
index 0000000000000000000000000000000000000000..7ea43cd8ba0afa3e243731dd2c2d0acfc2c9e770
--- /dev/null
+++ b/app/run_gradio_win.bat
@@ -0,0 +1,196 @@
+@echo off
+chcp 65001 >nul
+echo 🎬 LightX2V Gradio Windows Startup Script
+echo ==========================================
+
+REM ==================== Configuration Area ====================
+REM ⚠️ Important: Please modify the following paths according to your actual environment
+
+REM 🚨 Storage Performance Tips 🚨
+REM 💾 Strongly recommend storing model files on SSD solid-state drives!
+REM 📈 SSD can significantly improve model loading speed and inference performance
+REM 🐌 Using mechanical hard drives (HDD) may cause slow model loading and affect overall experience
+
+REM LightX2V project root directory path
+REM Example: D:\LightX2V
+set lightx2v_path=/path/to/LightX2V
+
+REM Model path configuration
+REM Model root directory path
+REM Example: D:\models\LightX2V
+set model_path=/path/to/LightX2V
+
+REM Server configuration
+set server_name=127.0.0.1
+set server_port=8032
+
+REM Output directory configuration
+set output_dir=./outputs
+
+REM GPU configuration
+set gpu_id=0
+
+REM ==================== Environment Variables Setup ====================
+set CUDA_VISIBLE_DEVICES=%gpu_id%
+set PYTHONPATH=%lightx2v_path%;%PYTHONPATH%
+set PROFILING_DEBUG_LEVEL=2
+set PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True
+
+REM ==================== Parameter Parsing ====================
+REM Default interface language
+set lang=zh
+
+REM Parse command line arguments
+:parse_args
+if "%1"=="" goto :end_parse
+if "%1"=="--lang" (
+ set lang=%2
+ shift
+ shift
+ goto :parse_args
+)
+if "%1"=="--port" (
+ set server_port=%2
+ shift
+ shift
+ goto :parse_args
+)
+if "%1"=="--gpu" (
+ set gpu_id=%2
+ set CUDA_VISIBLE_DEVICES=%gpu_id%
+ shift
+ shift
+ goto :parse_args
+)
+if "%1"=="--output_dir" (
+ set output_dir=%2
+ shift
+ shift
+ goto :parse_args
+)
+if "%1"=="--help" (
+ echo 🎬 LightX2V Gradio Windows Startup Script
+ echo ==========================================
+ echo Usage: %0 [options]
+ echo.
+ echo 📋 Available options:
+ echo --lang zh^|en Interface language (default: zh)
+ echo zh: Chinese interface
+ echo en: English interface
+ echo --port PORT Server port (default: 8032)
+ echo --gpu GPU_ID GPU device ID (default: 0)
+ echo --output_dir OUTPUT_DIR
+ echo Output video save directory (default: ./outputs)
+ echo --help Show this help message
+ echo.
+ echo 🚀 Usage examples:
+ echo %0 # Default startup
+ echo %0 --lang zh --port 8032 # Start with specified parameters
+ echo %0 --lang en --port 7860 # English interface
+ echo %0 --gpu 1 --port 8032 # Use GPU 1
+ echo %0 --output_dir ./custom_output # Use custom output directory
+ echo.
+ echo 📝 Notes:
+ echo - Edit script to configure model path before first use
+ echo - Ensure required Python dependencies are installed
+ echo - Recommended to use GPU with 8GB+ VRAM
+ echo - 🚨 Strongly recommend storing models on SSD for better performance
+ pause
+ exit /b 0
+)
+echo Unknown parameter: %1
+echo Use --help to see help information
+pause
+exit /b 1
+
+:end_parse
+
+REM ==================== Parameter Validation ====================
+if "%lang%"=="zh" goto :valid_lang
+if "%lang%"=="en" goto :valid_lang
+echo Error: Language must be 'zh' or 'en'
+pause
+exit /b 1
+
+:valid_lang
+
+REM Check if model path exists
+if not exist "%model_path%" (
+ echo ❌ Error: Model path does not exist
+ echo 📁 Path: %model_path%
+ echo 🔧 Solutions:
+ echo 1. Check model path configuration in script
+ echo 2. Ensure model files are properly downloaded
+ echo 3. Verify path permissions are correct
+ echo 4. 💾 Recommend storing models on SSD for faster loading
+ pause
+ exit /b 1
+)
+
+REM Select demo file based on language
+if "%lang%"=="zh" (
+ set demo_file=gradio_demo_zh.py
+ echo 🌏 Using Chinese interface
+) else (
+ set demo_file=gradio_demo.py
+ echo 🌏 Using English interface
+)
+
+REM Check if demo file exists
+if not exist "%demo_file%" (
+ echo ❌ Error: Demo file does not exist
+ echo 📄 File: %demo_file%
+ echo 🔧 Solutions:
+ echo 1. Ensure script is run in the correct directory
+ echo 2. Check if file has been renamed or moved
+ echo 3. Re-clone or download project files
+ pause
+ exit /b 1
+)
+
+REM ==================== System Information Display ====================
+echo ==========================================
+echo 🚀 LightX2V Gradio Starting...
+echo ==========================================
+echo 📁 Project path: %lightx2v_path%
+echo 🤖 Model path: %model_path%
+echo 🌏 Interface language: %lang%
+echo 🖥️ GPU device: %gpu_id%
+echo 🌐 Server address: %server_name%:%server_port%
+echo 📁 Output directory: %output_dir%
+echo ==========================================
+
+REM Display system resource information
+echo 💻 System resource information:
+wmic OS get TotalVisibleMemorySize,FreePhysicalMemory /format:table
+
+REM Display GPU information
+nvidia-smi --query-gpu=name,memory.total,memory.free --format=csv,noheader,nounits 2>nul
+if errorlevel 1 (
+ echo 🎮 GPU information: Unable to get GPU info
+) else (
+ echo 🎮 GPU information:
+ nvidia-smi --query-gpu=name,memory.total,memory.free --format=csv,noheader,nounits
+)
+
+REM ==================== Start Demo ====================
+echo 🎬 Starting Gradio demo...
+echo 📱 Please access in browser: http://%server_name%:%server_port%
+echo ⏹️ Press Ctrl+C to stop service
+echo 🔄 First startup may take several minutes to load resources...
+echo ==========================================
+
+REM Start Python demo
+python %demo_file% ^
+ --model_path "%model_path%" ^
+ --server_name %server_name% ^
+ --server_port %server_port% ^
+ --output_dir "%output_dir%"
+
+REM Display final system resource usage
+echo.
+echo ==========================================
+echo 📊 Final system resource usage:
+wmic OS get TotalVisibleMemorySize,FreePhysicalMemory /format:table
+
+pause
diff --git a/assets/figs/offload/fig1_en.png b/assets/figs/offload/fig1_en.png
new file mode 100644
index 0000000000000000000000000000000000000000..acee7c1fa89bf9f8564dd47a844e8553480be9fe
Binary files /dev/null and b/assets/figs/offload/fig1_en.png differ
diff --git a/assets/figs/offload/fig1_zh.png b/assets/figs/offload/fig1_zh.png
new file mode 100644
index 0000000000000000000000000000000000000000..1e1bbe2d92787d27c34c8fe742e5076e70b19161
Binary files /dev/null and b/assets/figs/offload/fig1_zh.png differ
diff --git a/assets/figs/offload/fig2_en.png b/assets/figs/offload/fig2_en.png
new file mode 100644
index 0000000000000000000000000000000000000000..606523e857d192c9c21245b149eae4b63062e4c0
Binary files /dev/null and b/assets/figs/offload/fig2_en.png differ
diff --git a/assets/figs/offload/fig2_zh.png b/assets/figs/offload/fig2_zh.png
new file mode 100644
index 0000000000000000000000000000000000000000..bdabf44507c69b6ff099734e4d8eadf70edcf1f2
Binary files /dev/null and b/assets/figs/offload/fig2_zh.png differ
diff --git a/assets/figs/offload/fig3_en.png b/assets/figs/offload/fig3_en.png
new file mode 100644
index 0000000000000000000000000000000000000000..585c27930d499615d1809d5586c1f0f71554fc35
Binary files /dev/null and b/assets/figs/offload/fig3_en.png differ
diff --git a/assets/figs/offload/fig3_zh.png b/assets/figs/offload/fig3_zh.png
new file mode 100644
index 0000000000000000000000000000000000000000..b6147797b57b3a4c9fedd69dc1713a1a1e12e54e
Binary files /dev/null and b/assets/figs/offload/fig3_zh.png differ
diff --git a/assets/figs/offload/fig4_en.png b/assets/figs/offload/fig4_en.png
new file mode 100644
index 0000000000000000000000000000000000000000..9cc2a32c3a132c7ae2c174dd9de5f1852c0d933e
Binary files /dev/null and b/assets/figs/offload/fig4_en.png differ
diff --git a/assets/figs/offload/fig4_zh.png b/assets/figs/offload/fig4_zh.png
new file mode 100644
index 0000000000000000000000000000000000000000..7e3442295196f81522ab030e559f444e3288e1be
Binary files /dev/null and b/assets/figs/offload/fig4_zh.png differ
diff --git a/assets/figs/offload/fig5_en.png b/assets/figs/offload/fig5_en.png
new file mode 100644
index 0000000000000000000000000000000000000000..489e20f5b6a9574689a125cf7fecf7dbd82336de
Binary files /dev/null and b/assets/figs/offload/fig5_en.png differ
diff --git a/assets/figs/offload/fig5_zh.png b/assets/figs/offload/fig5_zh.png
new file mode 100644
index 0000000000000000000000000000000000000000..3cd30e007d973774b799c47ed83c1bcfce28dc27
Binary files /dev/null and b/assets/figs/offload/fig5_zh.png differ
diff --git a/assets/figs/portabl_windows/pic1.png b/assets/figs/portabl_windows/pic1.png
new file mode 100644
index 0000000000000000000000000000000000000000..04721dafb8ccd1f5ce5041dbbcc5b2c22c83ffc4
Binary files /dev/null and b/assets/figs/portabl_windows/pic1.png differ
diff --git a/assets/figs/portabl_windows/pic_gradio_en.png b/assets/figs/portabl_windows/pic_gradio_en.png
new file mode 100644
index 0000000000000000000000000000000000000000..f08fa4cf1b0797045ad24ae9e52a70577396f6f2
Binary files /dev/null and b/assets/figs/portabl_windows/pic_gradio_en.png differ
diff --git a/assets/figs/portabl_windows/pic_gradio_zh.png b/assets/figs/portabl_windows/pic_gradio_zh.png
new file mode 100644
index 0000000000000000000000000000000000000000..86441fa54ad0d12140a083439c608eb41d2b8a0b
Binary files /dev/null and b/assets/figs/portabl_windows/pic_gradio_zh.png differ
diff --git a/assets/figs/step_distill/fig_01.png b/assets/figs/step_distill/fig_01.png
new file mode 100644
index 0000000000000000000000000000000000000000..cdbca0a24540f1829376f132dbb66f4332d948a0
Binary files /dev/null and b/assets/figs/step_distill/fig_01.png differ
diff --git a/assets/img_lightx2v.png b/assets/img_lightx2v.png
new file mode 100644
index 0000000000000000000000000000000000000000..1067b67b49899403b4cb44b74de4c00683f63e98
Binary files /dev/null and b/assets/img_lightx2v.png differ
diff --git a/assets/inputs/audio/multi_person/config.json b/assets/inputs/audio/multi_person/config.json
new file mode 100644
index 0000000000000000000000000000000000000000..3e0cf1e4fbbccacfa099e4559fa6a31288d3108c
--- /dev/null
+++ b/assets/inputs/audio/multi_person/config.json
@@ -0,0 +1,12 @@
+{
+ "talk_objects": [
+ {
+ "audio": "p1.mp3",
+ "mask": "p1_mask.png"
+ },
+ {
+ "audio": "p2.mp3",
+ "mask": "p2_mask.png"
+ }
+ ]
+}
diff --git a/assets/inputs/audio/multi_person/config_multi_template.json b/assets/inputs/audio/multi_person/config_multi_template.json
new file mode 100644
index 0000000000000000000000000000000000000000..3e0cf1e4fbbccacfa099e4559fa6a31288d3108c
--- /dev/null
+++ b/assets/inputs/audio/multi_person/config_multi_template.json
@@ -0,0 +1,12 @@
+{
+ "talk_objects": [
+ {
+ "audio": "p1.mp3",
+ "mask": "p1_mask.png"
+ },
+ {
+ "audio": "p2.mp3",
+ "mask": "p2_mask.png"
+ }
+ ]
+}
diff --git a/assets/inputs/audio/multi_person/config_single_template.json b/assets/inputs/audio/multi_person/config_single_template.json
new file mode 100644
index 0000000000000000000000000000000000000000..306a61b465058f8265a3596acab24306622d0f30
--- /dev/null
+++ b/assets/inputs/audio/multi_person/config_single_template.json
@@ -0,0 +1,8 @@
+{
+ "talk_objects": [
+ {
+ "audio": "p1.mp3",
+ "mask": "p1_mask.png"
+ }
+ ]
+}
diff --git a/assets/inputs/audio/multi_person/p1.mp3 b/assets/inputs/audio/multi_person/p1.mp3
new file mode 100644
index 0000000000000000000000000000000000000000..41c1042f79cdecc04d2e87493067ea43142b2cad
Binary files /dev/null and b/assets/inputs/audio/multi_person/p1.mp3 differ
diff --git a/assets/inputs/audio/multi_person/p1_mask.png b/assets/inputs/audio/multi_person/p1_mask.png
new file mode 100644
index 0000000000000000000000000000000000000000..7cb8d84541a08927a71556f004b2b077a3d5a27a
Binary files /dev/null and b/assets/inputs/audio/multi_person/p1_mask.png differ
diff --git a/assets/inputs/audio/multi_person/p2.mp3 b/assets/inputs/audio/multi_person/p2.mp3
new file mode 100644
index 0000000000000000000000000000000000000000..a2ce0dd648bf43852ab9baaa1bb9dc45f095df98
Binary files /dev/null and b/assets/inputs/audio/multi_person/p2.mp3 differ
diff --git a/assets/inputs/audio/multi_person/p2_mask.png b/assets/inputs/audio/multi_person/p2_mask.png
new file mode 100644
index 0000000000000000000000000000000000000000..05c1265091bce025deb000e066263e7fe8e733f6
Binary files /dev/null and b/assets/inputs/audio/multi_person/p2_mask.png differ
diff --git a/assets/inputs/audio/multi_person/seko_input.png b/assets/inputs/audio/multi_person/seko_input.png
new file mode 100644
index 0000000000000000000000000000000000000000..db8bf104725b83ef60894f50b3211aa85847f373
Binary files /dev/null and b/assets/inputs/audio/multi_person/seko_input.png differ
diff --git a/assets/inputs/audio/seko_input.mp3 b/assets/inputs/audio/seko_input.mp3
new file mode 100644
index 0000000000000000000000000000000000000000..a09e2c90448a64dc8501b3eca6a9ceda376ef2e1
Binary files /dev/null and b/assets/inputs/audio/seko_input.mp3 differ
diff --git a/assets/inputs/audio/seko_input.png b/assets/inputs/audio/seko_input.png
new file mode 100644
index 0000000000000000000000000000000000000000..cefda29965efd3e3a3c68e142b1ce8f82dfc93da
Binary files /dev/null and b/assets/inputs/audio/seko_input.png differ
diff --git a/assets/inputs/imgs/flf2v_input_first_frame-fs8.png b/assets/inputs/imgs/flf2v_input_first_frame-fs8.png
new file mode 100644
index 0000000000000000000000000000000000000000..4c67ec443ea2c609ca9576be4168fd879c2d215b
Binary files /dev/null and b/assets/inputs/imgs/flf2v_input_first_frame-fs8.png differ
diff --git a/assets/inputs/imgs/flf2v_input_last_frame-fs8.png b/assets/inputs/imgs/flf2v_input_last_frame-fs8.png
new file mode 100644
index 0000000000000000000000000000000000000000..51f3fbc5233e4d4215cb4c536c6374a5058cd40a
Binary files /dev/null and b/assets/inputs/imgs/flf2v_input_last_frame-fs8.png differ
diff --git a/assets/inputs/imgs/girl.png b/assets/inputs/imgs/girl.png
new file mode 100644
index 0000000000000000000000000000000000000000..8174bf2122301340e7aa9ceb005e1964def965d2
Binary files /dev/null and b/assets/inputs/imgs/girl.png differ
diff --git a/assets/inputs/imgs/img_0.jpg b/assets/inputs/imgs/img_0.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..6f6dcced590cbd18f5eda26bc2362b76ed714847
Binary files /dev/null and b/assets/inputs/imgs/img_0.jpg differ
diff --git a/assets/inputs/imgs/img_1.jpg b/assets/inputs/imgs/img_1.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..2dee840820801bab1ebc05300952bbb9a4945d6a
Binary files /dev/null and b/assets/inputs/imgs/img_1.jpg differ
diff --git a/assets/inputs/imgs/img_2.jpg b/assets/inputs/imgs/img_2.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..944f15ab131c77613c11c668a0ced4d531c5f9f5
Binary files /dev/null and b/assets/inputs/imgs/img_2.jpg differ
diff --git a/assets/inputs/imgs/snake.png b/assets/inputs/imgs/snake.png
new file mode 100644
index 0000000000000000000000000000000000000000..19085802f5b04656357bf8de812181f3ed161152
Binary files /dev/null and b/assets/inputs/imgs/snake.png differ
diff --git a/configs/attentions/wan_i2v_flash.json b/configs/attentions/wan_i2v_flash.json
new file mode 100644
index 0000000000000000000000000000000000000000..24c7a57e9fb24deebb0b54632e99ab4b585321af
--- /dev/null
+++ b/configs/attentions/wan_i2v_flash.json
@@ -0,0 +1,13 @@
+{
+ "infer_steps": 40,
+ "target_video_length": 81,
+ "target_height": 480,
+ "target_width": 832,
+ "self_attn_1_type": "flash_attn3",
+ "cross_attn_1_type": "flash_attn3",
+ "cross_attn_2_type": "flash_attn3",
+ "sample_guide_scale": 5,
+ "sample_shift": 5,
+ "enable_cfg": true,
+ "cpu_offload": false
+}
diff --git a/configs/attentions/wan_i2v_nbhd_480p.json b/configs/attentions/wan_i2v_nbhd_480p.json
new file mode 100644
index 0000000000000000000000000000000000000000..2ca3bca552ae6df8085d78ced97b95c5c7540d9f
--- /dev/null
+++ b/configs/attentions/wan_i2v_nbhd_480p.json
@@ -0,0 +1,17 @@
+{
+ "infer_steps": 40,
+ "target_video_length": 81,
+ "target_height": 480,
+ "target_width": 832,
+ "self_attn_1_type": "nbhd_attn",
+ "nbhd_attn_setting": {
+ "coefficient": [1.0, 0.5, 0.25, 0.25],
+ "min_width": 2.0
+ },
+ "cross_attn_1_type": "flash_attn3",
+ "cross_attn_2_type": "flash_attn3",
+ "sample_guide_scale": 5,
+ "sample_shift": 3,
+ "enable_cfg": true,
+ "cpu_offload": false
+}
diff --git a/configs/attentions/wan_i2v_nbhd_720p.json b/configs/attentions/wan_i2v_nbhd_720p.json
new file mode 100644
index 0000000000000000000000000000000000000000..10a99cf101849807e53939898936d33d099cbf4f
--- /dev/null
+++ b/configs/attentions/wan_i2v_nbhd_720p.json
@@ -0,0 +1,17 @@
+{
+ "infer_steps": 40,
+ "target_video_length": 81,
+ "target_height": 720,
+ "target_width": 1280,
+ "self_attn_1_type": "nbhd_attn",
+ "nbhd_attn_setting": {
+ "coefficient": [1.0, 0.5, 0.25, 0.25],
+ "min_width": 2.0
+ },
+ "cross_attn_1_type": "flash_attn3",
+ "cross_attn_2_type": "flash_attn3",
+ "sample_guide_scale": 5,
+ "sample_shift": 3,
+ "enable_cfg": true,
+ "cpu_offload": false
+}
diff --git a/configs/attentions/wan_i2v_radial.json b/configs/attentions/wan_i2v_radial.json
new file mode 100644
index 0000000000000000000000000000000000000000..428517a9a0a9aa7e107f81814a7dd86063d7d403
--- /dev/null
+++ b/configs/attentions/wan_i2v_radial.json
@@ -0,0 +1,13 @@
+{
+ "infer_steps": 40,
+ "target_video_length": 81,
+ "target_height": 480,
+ "target_width": 832,
+ "self_attn_1_type": "radial_attn",
+ "cross_attn_1_type": "flash_attn3",
+ "cross_attn_2_type": "flash_attn3",
+ "sample_guide_scale": 5,
+ "sample_shift": 5,
+ "enable_cfg": true,
+ "cpu_offload": false
+}
diff --git a/configs/attentions/wan_i2v_sage.json b/configs/attentions/wan_i2v_sage.json
new file mode 100644
index 0000000000000000000000000000000000000000..9a278a507854d5bf33c79a8d601c5eaff9b848b7
--- /dev/null
+++ b/configs/attentions/wan_i2v_sage.json
@@ -0,0 +1,13 @@
+{
+ "infer_steps": 40,
+ "target_video_length": 81,
+ "target_height": 480,
+ "target_width": 832,
+ "self_attn_1_type": "sage_attn2",
+ "cross_attn_1_type": "sage_attn2",
+ "cross_attn_2_type": "sage_attn2",
+ "sample_guide_scale": 5,
+ "sample_shift": 5,
+ "enable_cfg": true,
+ "cpu_offload": false
+}
diff --git a/configs/attentions/wan_i2v_svg.json b/configs/attentions/wan_i2v_svg.json
new file mode 100644
index 0000000000000000000000000000000000000000..e3d677d3a50c9c373ef13bb1b1d8aeac99019973
--- /dev/null
+++ b/configs/attentions/wan_i2v_svg.json
@@ -0,0 +1,13 @@
+{
+ "infer_steps": 40,
+ "target_video_length": 81,
+ "target_height": 480,
+ "target_width": 832,
+ "self_attn_1_type": "svg_attn",
+ "cross_attn_1_type": "flash_attn3",
+ "cross_attn_2_type": "flash_attn3",
+ "sample_guide_scale": 5,
+ "sample_shift": 3,
+ "enable_cfg": true,
+ "cpu_offload": false
+}
diff --git a/configs/attentions/wan_i2v_svg2.json b/configs/attentions/wan_i2v_svg2.json
new file mode 100644
index 0000000000000000000000000000000000000000..4f707076b7a9fa88872a5a8be7c1c3a33d4d988b
--- /dev/null
+++ b/configs/attentions/wan_i2v_svg2.json
@@ -0,0 +1,13 @@
+{
+ "infer_steps": 40,
+ "target_video_length": 81,
+ "target_height": 480,
+ "target_width": 832,
+ "self_attn_1_type": "svg2_attn",
+ "cross_attn_1_type": "flash_attn3",
+ "cross_attn_2_type": "flash_attn3",
+ "sample_guide_scale": 5,
+ "sample_shift": 3,
+ "enable_cfg": true,
+ "cpu_offload": false
+}
diff --git a/configs/attentions/wan_t2v_sparge.json b/configs/attentions/wan_t2v_sparge.json
new file mode 100644
index 0000000000000000000000000000000000000000..64cce21b769c62bbb77dc509c3bc1abdcfaf948d
--- /dev/null
+++ b/configs/attentions/wan_t2v_sparge.json
@@ -0,0 +1,16 @@
+{
+ "infer_steps": 50,
+ "target_video_length": 81,
+ "text_len": 512,
+ "target_height": 480,
+ "target_width": 832,
+ "self_attn_1_type": "flash_attn3",
+ "cross_attn_1_type": "flash_attn3",
+ "cross_attn_2_type": "flash_attn3",
+ "sample_guide_scale": 6,
+ "sample_shift": 8,
+ "enable_cfg": true,
+ "cpu_offload": false,
+ "sparge": true,
+ "sparge_ckpt": "/path/to/sparge_wan2.1_t2v_1.3B.pt"
+}
diff --git a/configs/bench/lightx2v_1.json b/configs/bench/lightx2v_1.json
new file mode 100644
index 0000000000000000000000000000000000000000..9a278a507854d5bf33c79a8d601c5eaff9b848b7
--- /dev/null
+++ b/configs/bench/lightx2v_1.json
@@ -0,0 +1,13 @@
+{
+ "infer_steps": 40,
+ "target_video_length": 81,
+ "target_height": 480,
+ "target_width": 832,
+ "self_attn_1_type": "sage_attn2",
+ "cross_attn_1_type": "sage_attn2",
+ "cross_attn_2_type": "sage_attn2",
+ "sample_guide_scale": 5,
+ "sample_shift": 5,
+ "enable_cfg": true,
+ "cpu_offload": false
+}
diff --git a/configs/bench/lightx2v_2.json b/configs/bench/lightx2v_2.json
new file mode 100644
index 0000000000000000000000000000000000000000..9a278a507854d5bf33c79a8d601c5eaff9b848b7
--- /dev/null
+++ b/configs/bench/lightx2v_2.json
@@ -0,0 +1,13 @@
+{
+ "infer_steps": 40,
+ "target_video_length": 81,
+ "target_height": 480,
+ "target_width": 832,
+ "self_attn_1_type": "sage_attn2",
+ "cross_attn_1_type": "sage_attn2",
+ "cross_attn_2_type": "sage_attn2",
+ "sample_guide_scale": 5,
+ "sample_shift": 5,
+ "enable_cfg": true,
+ "cpu_offload": false
+}
diff --git a/configs/bench/lightx2v_3.json b/configs/bench/lightx2v_3.json
new file mode 100644
index 0000000000000000000000000000000000000000..2ef47231ff608ec6214e753accf7b9b04a980cfa
--- /dev/null
+++ b/configs/bench/lightx2v_3.json
@@ -0,0 +1,16 @@
+{
+ "infer_steps": 40,
+ "target_video_length": 81,
+ "target_height": 480,
+ "target_width": 832,
+ "self_attn_1_type": "sage_attn2",
+ "cross_attn_1_type": "sage_attn2",
+ "cross_attn_2_type": "sage_attn2",
+ "sample_guide_scale": 5,
+ "sample_shift": 5,
+ "enable_cfg": true,
+ "cpu_offload": false,
+ "dit_quantized": true,
+ "dit_quant_scheme": "fp8-sgl",
+ "use_tiling_vae": true
+}
diff --git a/configs/bench/lightx2v_3_distill.json b/configs/bench/lightx2v_3_distill.json
new file mode 100644
index 0000000000000000000000000000000000000000..7cc8d37b9d99646740ed67a872feac8ad67a720b
--- /dev/null
+++ b/configs/bench/lightx2v_3_distill.json
@@ -0,0 +1,22 @@
+{
+ "infer_steps": 4,
+ "target_video_length": 81,
+ "target_height": 480,
+ "target_width": 832,
+ "self_attn_1_type": "sage_attn2",
+ "cross_attn_1_type": "sage_attn2",
+ "cross_attn_2_type": "sage_attn2",
+ "sample_guide_scale": 5,
+ "sample_shift": 5,
+ "enable_cfg": false,
+ "cpu_offload": false,
+ "denoising_step_list": [
+ 1000,
+ 750,
+ 500,
+ 250
+ ],
+ "dit_quantized": true,
+ "dit_quant_scheme": "fp8-sgl",
+ "use_tiling_vae": true
+}
diff --git a/configs/bench/lightx2v_4.json b/configs/bench/lightx2v_4.json
new file mode 100644
index 0000000000000000000000000000000000000000..7d83a749111684490a6ea14210ef93f5bc9fd226
--- /dev/null
+++ b/configs/bench/lightx2v_4.json
@@ -0,0 +1,35 @@
+{
+ "infer_steps": 40,
+ "target_video_length": 81,
+ "target_height": 480,
+ "target_width": 832,
+ "self_attn_1_type": "sage_attn2",
+ "cross_attn_1_type": "sage_attn2",
+ "cross_attn_2_type": "sage_attn2",
+ "sample_guide_scale": 5,
+ "sample_shift": 5,
+ "enable_cfg": true,
+ "cpu_offload": false,
+ "dit_quantized": true,
+ "dit_quant_scheme": "fp8-sgl",
+ "feature_caching": "Tea",
+ "coefficients": [
+ [
+ 2.57151496e05,
+ -3.54229917e04,
+ 1.40286849e03,
+ -1.35890334e01,
+ 1.32517977e-01
+ ],
+ [
+ -3.02331670e02,
+ 2.23948934e02,
+ -5.25463970e01,
+ 5.87348440e00,
+ -2.01973289e-01
+ ]
+ ],
+ "use_ret_steps": false,
+ "teacache_thresh": 0.2,
+ "use_tiling_vae": true
+}
diff --git a/configs/bench/lightx2v_5.json b/configs/bench/lightx2v_5.json
new file mode 100644
index 0000000000000000000000000000000000000000..a9a72814b490f761e7045f27d7fa062fbf454b8a
--- /dev/null
+++ b/configs/bench/lightx2v_5.json
@@ -0,0 +1,19 @@
+{
+ "infer_steps": 40,
+ "target_video_length": 81,
+ "target_height": 480,
+ "target_width": 832,
+ "self_attn_1_type": "sage_attn2",
+ "cross_attn_1_type": "sage_attn2",
+ "cross_attn_2_type": "sage_attn2",
+ "sample_guide_scale": 5,
+ "sample_shift": 5,
+ "enable_cfg": true,
+ "cpu_offload": true,
+ "offload_granularity": "block",
+ "offload_ratio": 0.8,
+ "t5_cpu_offload": true,
+ "dit_quantized": true,
+ "dit_quant_scheme": "fp8-sgl",
+ "use_tiling_vae": true
+}
diff --git a/configs/bench/lightx2v_5_distill.json b/configs/bench/lightx2v_5_distill.json
new file mode 100644
index 0000000000000000000000000000000000000000..8d215c9a9b2ca1a7b28f9d596ad041147afe7956
--- /dev/null
+++ b/configs/bench/lightx2v_5_distill.json
@@ -0,0 +1,25 @@
+{
+ "infer_steps": 4,
+ "target_video_length": 81,
+ "target_height": 480,
+ "target_width": 832,
+ "self_attn_1_type": "sage_attn2",
+ "cross_attn_1_type": "sage_attn2",
+ "cross_attn_2_type": "sage_attn2",
+ "sample_guide_scale": 5,
+ "sample_shift": 5,
+ "enable_cfg": false,
+ "cpu_offload": true,
+ "offload_granularity": "block",
+ "offload_ratio": 0.8,
+ "t5_cpu_offload": true,
+ "denoising_step_list": [
+ 1000,
+ 750,
+ 500,
+ 250
+ ],
+ "dit_quantized": true,
+ "dit_quant_scheme": "fp8-sgl",
+ "use_tiling_vae": true
+}
diff --git a/configs/bench/lightx2v_6.json b/configs/bench/lightx2v_6.json
new file mode 100644
index 0000000000000000000000000000000000000000..a9a72814b490f761e7045f27d7fa062fbf454b8a
--- /dev/null
+++ b/configs/bench/lightx2v_6.json
@@ -0,0 +1,19 @@
+{
+ "infer_steps": 40,
+ "target_video_length": 81,
+ "target_height": 480,
+ "target_width": 832,
+ "self_attn_1_type": "sage_attn2",
+ "cross_attn_1_type": "sage_attn2",
+ "cross_attn_2_type": "sage_attn2",
+ "sample_guide_scale": 5,
+ "sample_shift": 5,
+ "enable_cfg": true,
+ "cpu_offload": true,
+ "offload_granularity": "block",
+ "offload_ratio": 0.8,
+ "t5_cpu_offload": true,
+ "dit_quantized": true,
+ "dit_quant_scheme": "fp8-sgl",
+ "use_tiling_vae": true
+}
diff --git a/configs/bench/lightx2v_6_distill.json b/configs/bench/lightx2v_6_distill.json
new file mode 100644
index 0000000000000000000000000000000000000000..8d215c9a9b2ca1a7b28f9d596ad041147afe7956
--- /dev/null
+++ b/configs/bench/lightx2v_6_distill.json
@@ -0,0 +1,25 @@
+{
+ "infer_steps": 4,
+ "target_video_length": 81,
+ "target_height": 480,
+ "target_width": 832,
+ "self_attn_1_type": "sage_attn2",
+ "cross_attn_1_type": "sage_attn2",
+ "cross_attn_2_type": "sage_attn2",
+ "sample_guide_scale": 5,
+ "sample_shift": 5,
+ "enable_cfg": false,
+ "cpu_offload": true,
+ "offload_granularity": "block",
+ "offload_ratio": 0.8,
+ "t5_cpu_offload": true,
+ "denoising_step_list": [
+ 1000,
+ 750,
+ 500,
+ 250
+ ],
+ "dit_quantized": true,
+ "dit_quant_scheme": "fp8-sgl",
+ "use_tiling_vae": true
+}
diff --git a/configs/caching/adacache/wan_i2v_ada.json b/configs/caching/adacache/wan_i2v_ada.json
new file mode 100644
index 0000000000000000000000000000000000000000..90e635c1eddf00aa0d1d922db8062222e04baa22
--- /dev/null
+++ b/configs/caching/adacache/wan_i2v_ada.json
@@ -0,0 +1,15 @@
+{
+ "infer_steps": 40,
+ "target_video_length": 81,
+ "target_height": 480,
+ "target_width": 832,
+ "self_attn_1_type": "flash_attn3",
+ "cross_attn_1_type": "flash_attn3",
+ "cross_attn_2_type": "flash_attn3",
+ "seed": 442,
+ "sample_guide_scale": 5,
+ "sample_shift": 3,
+ "enable_cfg": true,
+ "cpu_offload": false,
+ "feature_caching": "Ada"
+}
diff --git a/configs/caching/adacache/wan_t2v_ada.json b/configs/caching/adacache/wan_t2v_ada.json
new file mode 100644
index 0000000000000000000000000000000000000000..88ea1781cd26671dd3da2192a067dbd475fd99f0
--- /dev/null
+++ b/configs/caching/adacache/wan_t2v_ada.json
@@ -0,0 +1,15 @@
+{
+ "infer_steps": 50,
+ "target_video_length": 81,
+ "text_len": 512,
+ "target_height": 480,
+ "target_width": 832,
+ "self_attn_1_type": "flash_attn3",
+ "cross_attn_1_type": "flash_attn3",
+ "cross_attn_2_type": "flash_attn3",
+ "sample_guide_scale": 6,
+ "sample_shift": 8,
+ "enable_cfg": true,
+ "cpu_offload": false,
+ "feature_caching": "Ada"
+}
diff --git a/configs/caching/custom/wan_i2v_custom_480p.json b/configs/caching/custom/wan_i2v_custom_480p.json
new file mode 100644
index 0000000000000000000000000000000000000000..4980e8fdf84f4792948d647234d34448429e2660
--- /dev/null
+++ b/configs/caching/custom/wan_i2v_custom_480p.json
@@ -0,0 +1,21 @@
+{
+ "infer_steps": 40,
+ "target_video_length": 81,
+ "target_height": 480,
+ "target_width": 832,
+ "self_attn_1_type": "flash_attn3",
+ "cross_attn_1_type": "flash_attn3",
+ "cross_attn_2_type": "flash_attn3",
+ "seed": 442,
+ "sample_guide_scale": 5,
+ "sample_shift": 3,
+ "enable_cfg": true,
+ "cpu_offload": false,
+ "feature_caching": "Custom",
+ "coefficients": [
+ [2.57151496e05, -3.54229917e04, 1.40286849e03, -1.35890334e01, 1.32517977e-01],
+ [-3.02331670e02, 2.23948934e02, -5.25463970e01, 5.87348440e00, -2.01973289e-01]
+ ],
+ "use_ret_steps": false,
+ "teacache_thresh": 0.26
+}
diff --git a/configs/caching/custom/wan_i2v_custom_720p.json b/configs/caching/custom/wan_i2v_custom_720p.json
new file mode 100644
index 0000000000000000000000000000000000000000..7a72be1a3eb0793a099dbedeb338ef0cefbc5594
--- /dev/null
+++ b/configs/caching/custom/wan_i2v_custom_720p.json
@@ -0,0 +1,32 @@
+{
+ "infer_steps": 40,
+ "target_video_length": 81,
+ "target_height": 1280,
+ "target_width": 720,
+ "self_attn_1_type": "flash_attn3",
+ "cross_attn_1_type": "flash_attn3",
+ "cross_attn_2_type": "flash_attn3",
+ "sample_guide_scale": 5,
+ "sample_shift": 3,
+ "enable_cfg": true,
+ "cpu_offload": false,
+ "feature_caching": "Custom",
+ "coefficients": [
+ [
+ 8.10705460e03,
+ 2.13393892e03,
+ -3.72934672e02,
+ 1.66203073e01,
+ -4.17769401e-02
+ ],
+ [
+ -114.36346466,
+ 65.26524496,
+ -18.82220707,
+ 4.91518089,
+ -0.23412683
+ ]
+ ],
+ "use_ret_steps": false,
+ "teacache_thresh": 0.26
+}
diff --git a/configs/caching/custom/wan_t2v_custom_14b.json b/configs/caching/custom/wan_t2v_custom_14b.json
new file mode 100644
index 0000000000000000000000000000000000000000..cdd24283810ac1b9cf2b55bc3d1a50cd9924bea0
--- /dev/null
+++ b/configs/caching/custom/wan_t2v_custom_14b.json
@@ -0,0 +1,33 @@
+{
+ "infer_steps": 50,
+ "target_video_length": 81,
+ "text_len": 512,
+ "target_height": 480,
+ "target_width": 832,
+ "self_attn_1_type": "flash_attn3",
+ "cross_attn_1_type": "flash_attn3",
+ "cross_attn_2_type": "flash_attn3",
+ "sample_guide_scale": 6,
+ "sample_shift": 8,
+ "enable_cfg": true,
+ "cpu_offload": false,
+ "feature_caching": "Custom",
+ "coefficients": [
+ [
+ -3.03318725e05,
+ 4.90537029e04,
+ -2.65530556e03,
+ 5.87365115e01,
+ -3.15583525e-01
+ ],
+ [
+ -5784.54975374,
+ 5449.50911966,
+ -1811.16591783,
+ 256.27178429,
+ -13.02252404
+ ]
+ ],
+ "use_ret_steps": false,
+ "teacache_thresh": 0.26
+}
diff --git a/configs/caching/custom/wan_t2v_custom_1_3b.json b/configs/caching/custom/wan_t2v_custom_1_3b.json
new file mode 100644
index 0000000000000000000000000000000000000000..1412ba2544c25fb0659bc3bae7ebf6fa7b2674f5
--- /dev/null
+++ b/configs/caching/custom/wan_t2v_custom_1_3b.json
@@ -0,0 +1,33 @@
+{
+ "infer_steps": 50,
+ "target_video_length": 81,
+ "text_len": 512,
+ "target_height": 480,
+ "target_width": 832,
+ "self_attn_1_type": "flash_attn3",
+ "cross_attn_1_type": "flash_attn3",
+ "cross_attn_2_type": "flash_attn3",
+ "sample_guide_scale": 6,
+ "sample_shift": 8,
+ "enable_cfg": true,
+ "cpu_offload": false,
+ "feature_caching": "Custom",
+ "coefficients": [
+ [
+ -5.21862437e04,
+ 9.23041404e03,
+ -5.28275948e02,
+ 1.36987616e01,
+ -4.99875664e-02
+ ],
+ [
+ 2.39676752e03,
+ -1.31110545e03,
+ 2.01331979e02,
+ -8.29855975e00,
+ 1.37887774e-01
+ ]
+ ],
+ "use_ret_steps": false,
+ "teacache_thresh": 0.26
+}
diff --git a/configs/caching/dualblock/wan_t2v_1_3b.json b/configs/caching/dualblock/wan_t2v_1_3b.json
new file mode 100644
index 0000000000000000000000000000000000000000..f81f56ce85ef7fa3ac425e89abccce1ff9d52896
--- /dev/null
+++ b/configs/caching/dualblock/wan_t2v_1_3b.json
@@ -0,0 +1,17 @@
+{
+ "infer_steps": 50,
+ "target_video_length": 81,
+ "text_len": 512,
+ "target_height": 480,
+ "target_width": 832,
+ "self_attn_1_type": "flash_attn3",
+ "cross_attn_1_type": "flash_attn3",
+ "cross_attn_2_type": "flash_attn3",
+ "sample_guide_scale": 6,
+ "sample_shift": 8,
+ "enable_cfg": true,
+ "cpu_offload": false,
+ "feature_caching": "DualBlock",
+ "residual_diff_threshold": 0.03,
+ "downsample_factor": 2
+}
diff --git a/configs/caching/dynamicblock/wan_t2v_1_3b.json b/configs/caching/dynamicblock/wan_t2v_1_3b.json
new file mode 100644
index 0000000000000000000000000000000000000000..fa24ba9e8a66b303fff19ae49f0e1d93cd444ce2
--- /dev/null
+++ b/configs/caching/dynamicblock/wan_t2v_1_3b.json
@@ -0,0 +1,17 @@
+{
+ "infer_steps": 50,
+ "target_video_length": 81,
+ "text_len": 512,
+ "target_height": 480,
+ "target_width": 832,
+ "self_attn_1_type": "flash_attn3",
+ "cross_attn_1_type": "flash_attn3",
+ "cross_attn_2_type": "flash_attn3",
+ "sample_guide_scale": 6,
+ "sample_shift": 8,
+ "enable_cfg": true,
+ "cpu_offload": false,
+ "feature_caching": "DynamicBlock",
+ "residual_diff_threshold": 0.003,
+ "downsample_factor": 2
+}
diff --git a/configs/caching/firstblock/wan_t2v_1_3b.json b/configs/caching/firstblock/wan_t2v_1_3b.json
new file mode 100644
index 0000000000000000000000000000000000000000..7dd393d735831fcab6b0d96907a8f50c74739c10
--- /dev/null
+++ b/configs/caching/firstblock/wan_t2v_1_3b.json
@@ -0,0 +1,17 @@
+{
+ "infer_steps": 50,
+ "target_video_length": 81,
+ "text_len": 512,
+ "target_height": 480,
+ "target_width": 832,
+ "self_attn_1_type": "flash_attn3",
+ "cross_attn_1_type": "flash_attn3",
+ "cross_attn_2_type": "flash_attn3",
+ "sample_guide_scale": 6,
+ "sample_shift": 8,
+ "enable_cfg": true,
+ "cpu_offload": false,
+ "feature_caching": "FirstBlock",
+ "residual_diff_threshold": 0.02,
+ "downsample_factor": 2
+}
diff --git a/configs/caching/magcache/wan_i2v_dist_cfg_ulysses_mag_480p.json b/configs/caching/magcache/wan_i2v_dist_cfg_ulysses_mag_480p.json
new file mode 100644
index 0000000000000000000000000000000000000000..0c7329e19b9f2d3da1e3c14777fc2057f6726cea
--- /dev/null
+++ b/configs/caching/magcache/wan_i2v_dist_cfg_ulysses_mag_480p.json
@@ -0,0 +1,109 @@
+{
+ "infer_steps": 40,
+ "target_video_length": 81,
+ "target_height": 480,
+ "target_width": 832,
+ "self_attn_1_type": "flash_attn3",
+ "cross_attn_1_type": "flash_attn3",
+ "cross_attn_2_type": "flash_attn3",
+ "sample_guide_scale": 5,
+ "sample_shift": 5,
+ "enable_cfg": true,
+ "cpu_offload": false,
+ "parallel": {
+ "seq_p_size": 4,
+ "seq_p_attn_type": "ulysses",
+ "cfg_p_size": 2
+ },
+ "feature_caching": "Mag",
+ "magcache_calibration": false,
+ "magcache_K": 6,
+ "magcache_thresh": 0.24,
+ "magcache_retention_ratio": 0.2,
+ "magcache_ratios": [
+ [
+ 1.0,
+ 0.98783,
+ 0.97559,
+ 0.98311,
+ 0.98202,
+ 0.9888,
+ 0.98762,
+ 0.98957,
+ 0.99052,
+ 0.99383,
+ 0.98857,
+ 0.99065,
+ 0.98845,
+ 0.99057,
+ 0.98957,
+ 0.98601,
+ 0.98823,
+ 0.98756,
+ 0.98808,
+ 0.98721,
+ 0.98571,
+ 0.98543,
+ 0.98157,
+ 0.98411,
+ 0.97952,
+ 0.98149,
+ 0.9774,
+ 0.97825,
+ 0.97355,
+ 0.97085,
+ 0.97056,
+ 0.96588,
+ 0.96113,
+ 0.9567,
+ 0.94961,
+ 0.93973,
+ 0.93217,
+ 0.91878,
+ 0.90955,
+ 0.92617
+ ],
+ [
+ 1.0,
+ 0.98993,
+ 0.97593,
+ 0.98319,
+ 0.98225,
+ 0.98878,
+ 0.98759,
+ 0.98971,
+ 0.99043,
+ 0.99384,
+ 0.9886,
+ 0.99068,
+ 0.98847,
+ 0.99057,
+ 0.98961,
+ 0.9861,
+ 0.98823,
+ 0.98759,
+ 0.98814,
+ 0.98724,
+ 0.98572,
+ 0.98544,
+ 0.98165,
+ 0.98413,
+ 0.97953,
+ 0.9815,
+ 0.97742,
+ 0.97826,
+ 0.97361,
+ 0.97087,
+ 0.97055,
+ 0.96587,
+ 0.96124,
+ 0.95681,
+ 0.94969,
+ 0.93988,
+ 0.93224,
+ 0.91896,
+ 0.90954,
+ 0.92616
+ ]
+ ]
+}
diff --git a/configs/caching/magcache/wan_i2v_mag_480p.json b/configs/caching/magcache/wan_i2v_mag_480p.json
new file mode 100644
index 0000000000000000000000000000000000000000..c8588ac2a8124f57691cf7658740bf06fe4416bf
--- /dev/null
+++ b/configs/caching/magcache/wan_i2v_mag_480p.json
@@ -0,0 +1,104 @@
+{
+ "infer_steps": 40,
+ "target_video_length": 81,
+ "target_height": 480,
+ "target_width": 832,
+ "self_attn_1_type": "flash_attn3",
+ "cross_attn_1_type": "flash_attn3",
+ "cross_attn_2_type": "flash_attn3",
+ "sample_guide_scale": 5,
+ "sample_shift": 5,
+ "enable_cfg": true,
+ "cpu_offload": false,
+ "feature_caching": "Mag",
+ "magcache_calibration": false,
+ "magcache_K": 6,
+ "magcache_thresh": 0.24,
+ "magcache_retention_ratio": 0.2,
+ "magcache_ratios": [
+ [
+ 1.0,
+ 0.98783,
+ 0.97559,
+ 0.98311,
+ 0.98202,
+ 0.9888,
+ 0.98762,
+ 0.98957,
+ 0.99052,
+ 0.99383,
+ 0.98857,
+ 0.99065,
+ 0.98845,
+ 0.99057,
+ 0.98957,
+ 0.98601,
+ 0.98823,
+ 0.98756,
+ 0.98808,
+ 0.98721,
+ 0.98571,
+ 0.98543,
+ 0.98157,
+ 0.98411,
+ 0.97952,
+ 0.98149,
+ 0.9774,
+ 0.97825,
+ 0.97355,
+ 0.97085,
+ 0.97056,
+ 0.96588,
+ 0.96113,
+ 0.9567,
+ 0.94961,
+ 0.93973,
+ 0.93217,
+ 0.91878,
+ 0.90955,
+ 0.92617
+ ],
+ [
+ 1.0,
+ 0.98993,
+ 0.97593,
+ 0.98319,
+ 0.98225,
+ 0.98878,
+ 0.98759,
+ 0.98971,
+ 0.99043,
+ 0.99384,
+ 0.9886,
+ 0.99068,
+ 0.98847,
+ 0.99057,
+ 0.98961,
+ 0.9861,
+ 0.98823,
+ 0.98759,
+ 0.98814,
+ 0.98724,
+ 0.98572,
+ 0.98544,
+ 0.98165,
+ 0.98413,
+ 0.97953,
+ 0.9815,
+ 0.97742,
+ 0.97826,
+ 0.97361,
+ 0.97087,
+ 0.97055,
+ 0.96587,
+ 0.96124,
+ 0.95681,
+ 0.94969,
+ 0.93988,
+ 0.93224,
+ 0.91896,
+ 0.90954,
+ 0.92616
+ ]
+ ]
+}
diff --git a/configs/caching/magcache/wan_i2v_mag_calibration_480p.json b/configs/caching/magcache/wan_i2v_mag_calibration_480p.json
new file mode 100644
index 0000000000000000000000000000000000000000..d331d33abddb417661b0ef68112b73e3377ca5ae
--- /dev/null
+++ b/configs/caching/magcache/wan_i2v_mag_calibration_480p.json
@@ -0,0 +1,104 @@
+{
+ "infer_steps": 40,
+ "target_video_length": 81,
+ "target_height": 480,
+ "target_width": 832,
+ "self_attn_1_type": "flash_attn3",
+ "cross_attn_1_type": "flash_attn3",
+ "cross_attn_2_type": "flash_attn3",
+ "sample_guide_scale": 5,
+ "sample_shift": 5,
+ "enable_cfg": true,
+ "cpu_offload": false,
+ "feature_caching": "Mag",
+ "magcache_calibration": true,
+ "magcache_K": 6,
+ "magcache_thresh": 0.24,
+ "magcache_retention_ratio": 0.2,
+ "magcache_ratios": [
+ [
+ 1.0,
+ 0.98783,
+ 0.97559,
+ 0.98311,
+ 0.98202,
+ 0.9888,
+ 0.98762,
+ 0.98957,
+ 0.99052,
+ 0.99383,
+ 0.98857,
+ 0.99065,
+ 0.98845,
+ 0.99057,
+ 0.98957,
+ 0.98601,
+ 0.98823,
+ 0.98756,
+ 0.98808,
+ 0.98721,
+ 0.98571,
+ 0.98543,
+ 0.98157,
+ 0.98411,
+ 0.97952,
+ 0.98149,
+ 0.9774,
+ 0.97825,
+ 0.97355,
+ 0.97085,
+ 0.97056,
+ 0.96588,
+ 0.96113,
+ 0.9567,
+ 0.94961,
+ 0.93973,
+ 0.93217,
+ 0.91878,
+ 0.90955,
+ 0.92617
+ ],
+ [
+ 1.0,
+ 0.98993,
+ 0.97593,
+ 0.98319,
+ 0.98225,
+ 0.98878,
+ 0.98759,
+ 0.98971,
+ 0.99043,
+ 0.99384,
+ 0.9886,
+ 0.99068,
+ 0.98847,
+ 0.99057,
+ 0.98961,
+ 0.9861,
+ 0.98823,
+ 0.98759,
+ 0.98814,
+ 0.98724,
+ 0.98572,
+ 0.98544,
+ 0.98165,
+ 0.98413,
+ 0.97953,
+ 0.9815,
+ 0.97742,
+ 0.97826,
+ 0.97361,
+ 0.97087,
+ 0.97055,
+ 0.96587,
+ 0.96124,
+ 0.95681,
+ 0.94969,
+ 0.93988,
+ 0.93224,
+ 0.91896,
+ 0.90954,
+ 0.92616
+ ]
+ ]
+}
diff --git a/configs/caching/magcache/wan_t2v_dist_cfg_ulysses_mag_1_3b.json b/configs/caching/magcache/wan_t2v_dist_cfg_ulysses_mag_1_3b.json
new file mode 100644
index 0000000000000000000000000000000000000000..3c5c5f8710b3f1c62cc7712b0357f08d4b4f3237
--- /dev/null
+++ b/configs/caching/magcache/wan_t2v_dist_cfg_ulysses_mag_1_3b.json
@@ -0,0 +1,130 @@
+{
+ "infer_steps": 50,
+ "target_video_length": 81,
+ "text_len": 512,
+ "target_height": 480,
+ "target_width": 832,
+ "self_attn_1_type": "flash_attn3",
+ "cross_attn_1_type": "flash_attn3",
+ "cross_attn_2_type": "flash_attn3",
+ "sample_guide_scale": 6,
+ "sample_shift": 8,
+ "enable_cfg": true,
+ "cpu_offload": false,
+ "parallel": {
+ "seq_p_size": 4,
+ "seq_p_attn_type": "ulysses",
+ "cfg_p_size": 2
+ },
+ "feature_caching": "Mag",
+ "magcache_calibration": false,
+ "magcache_K": 4,
+ "magcache_thresh": 0.12,
+ "magcache_retention_ratio": 0.2,
+ "magcache_ratios": [
+ [
+ 1.0,
+ 1.0124,
+ 1.00166,
+ 0.99791,
+ 0.99682,
+ 0.99634,
+ 0.99567,
+ 0.99416,
+ 0.99578,
+ 0.9957,
+ 0.99511,
+ 0.99535,
+ 0.99552,
+ 0.99541,
+ 0.9954,
+ 0.99489,
+ 0.99518,
+ 0.99484,
+ 0.99481,
+ 0.99415,
+ 0.99419,
+ 0.99396,
+ 0.99388,
+ 0.99349,
+ 0.99309,
+ 0.9927,
+ 0.99228,
+ 0.99171,
+ 0.99137,
+ 0.99068,
+ 0.99005,
+ 0.98944,
+ 0.98849,
+ 0.98758,
+ 0.98644,
+ 0.98504,
+ 0.9836,
+ 0.98202,
+ 0.97977,
+ 0.97717,
+ 0.9741,
+ 0.97003,
+ 0.96538,
+ 0.9593,
+ 0.95086,
+ 0.94013,
+ 0.92402,
+ 0.90241,
+ 0.86821,
+ 0.81838
+ ],
+ [
+ 1.0,
+ 1.02213,
+ 1.0041,
+ 1.00061,
+ 0.99762,
+ 0.99685,
+ 0.99586,
+ 0.99422,
+ 0.99575,
+ 0.99563,
+ 0.99506,
+ 0.99531,
+ 0.99549,
+ 0.99539,
+ 0.99536,
+ 0.99485,
+ 0.99514,
+ 0.99478,
+ 0.99479,
+ 0.99413,
+ 0.99416,
+ 0.99393,
+ 0.99386,
+ 0.99349,
+ 0.99304,
+ 0.9927,
+ 0.99226,
+ 0.9917,
+ 0.99135,
+ 0.99063,
+ 0.99003,
+ 0.98942,
+ 0.98849,
+ 0.98757,
+ 0.98643,
+ 0.98503,
+ 0.98359,
+ 0.98201,
+ 0.97978,
+ 0.97718,
+ 0.97411,
+ 0.97002,
+ 0.96541,
+ 0.95933,
+ 0.95089,
+ 0.94019,
+ 0.92414,
+ 0.9026,
+ 0.86868,
+ 0.81939
+ ]
+ ]
+}
diff --git a/configs/caching/magcache/wan_t2v_mag_1_3b.json b/configs/caching/magcache/wan_t2v_mag_1_3b.json
new file mode 100644
index 0000000000000000000000000000000000000000..aaec17e20fb7d59ce854bbc611efcbf72413cf9f
--- /dev/null
+++ b/configs/caching/magcache/wan_t2v_mag_1_3b.json
@@ -0,0 +1,125 @@
+{
+ "infer_steps": 50,
+ "target_video_length": 81,
+ "text_len": 512,
+ "target_height": 480,
+ "target_width": 832,
+ "self_attn_1_type": "flash_attn3",
+ "cross_attn_1_type": "flash_attn3",
+ "cross_attn_2_type": "flash_attn3",
+ "sample_guide_scale": 6,
+ "sample_shift": 8,
+ "enable_cfg": true,
+ "cpu_offload": false,
+ "feature_caching": "Mag",
+ "magcache_calibration": false,
+ "magcache_K": 4,
+ "magcache_thresh": 0.12,
+ "magcache_retention_ratio": 0.2,
+ "magcache_ratios": [
+ [
+ 1.0,
+ 1.0124,
+ 1.00166,
+ 0.99791,
+ 0.99682,
+ 0.99634,
+ 0.99567,
+ 0.99416,
+ 0.99578,
+ 0.9957,
+ 0.99511,
+ 0.99535,
+ 0.99552,
+ 0.99541,
+ 0.9954,
+ 0.99489,
+ 0.99518,
+ 0.99484,
+ 0.99481,
+ 0.99415,
+ 0.99419,
+ 0.99396,
+ 0.99388,
+ 0.99349,
+ 0.99309,
+ 0.9927,
+ 0.99228,
+ 0.99171,
+ 0.99137,
+ 0.99068,
+ 0.99005,
+ 0.98944,
+ 0.98849,
+ 0.98758,
+ 0.98644,
+ 0.98504,
+ 0.9836,
+ 0.98202,
+ 0.97977,
+ 0.97717,
+ 0.9741,
+ 0.97003,
+ 0.96538,
+ 0.9593,
+ 0.95086,
+ 0.94013,
+ 0.92402,
+ 0.90241,
+ 0.86821,
+ 0.81838
+ ],
+ [
+ 1.0,
+ 1.02213,
+ 1.0041,
+ 1.00061,
+ 0.99762,
+ 0.99685,
+ 0.99586,
+ 0.99422,
+ 0.99575,
+ 0.99563,
+ 0.99506,
+ 0.99531,
+ 0.99549,
+ 0.99539,
+ 0.99536,
+ 0.99485,
+ 0.99514,
+ 0.99478,
+ 0.99479,
+ 0.99413,
+ 0.99416,
+ 0.99393,
+ 0.99386,
+ 0.99349,
+ 0.99304,
+ 0.9927,
+ 0.99226,
+ 0.9917,
+ 0.99135,
+ 0.99063,
+ 0.99003,
+ 0.98942,
+ 0.98849,
+ 0.98757,
+ 0.98643,
+ 0.98503,
+ 0.98359,
+ 0.98201,
+ 0.97978,
+ 0.97718,
+ 0.97411,
+ 0.97002,
+ 0.96541,
+ 0.95933,
+ 0.95089,
+ 0.94019,
+ 0.92414,
+ 0.9026,
+ 0.86868,
+ 0.81939
+ ]
+ ]
+}
diff --git a/configs/caching/magcache/wan_t2v_mag_calibration_1_3b.json b/configs/caching/magcache/wan_t2v_mag_calibration_1_3b.json
new file mode 100644
index 0000000000000000000000000000000000000000..ac5b5fc2b0fe73751ac4fb617077dde43c4cf95c
--- /dev/null
+++ b/configs/caching/magcache/wan_t2v_mag_calibration_1_3b.json
@@ -0,0 +1,125 @@
+{
+ "infer_steps": 50,
+ "target_video_length": 81,
+ "text_len": 512,
+ "target_height": 480,
+ "target_width": 832,
+ "self_attn_1_type": "flash_attn3",
+ "cross_attn_1_type": "flash_attn3",
+ "cross_attn_2_type": "flash_attn3",
+ "sample_guide_scale": 6,
+ "sample_shift": 8,
+ "enable_cfg": true,
+ "cpu_offload": false,
+ "feature_caching": "Mag",
+ "magcache_calibration": true,
+ "magcache_K": 4,
+ "magcache_thresh": 0.12,
+ "magcache_retention_ratio": 0.2,
+ "magcache_ratios": [
+ [
+ 1.0,
+ 1.0124,
+ 1.00166,
+ 0.99791,
+ 0.99682,
+ 0.99634,
+ 0.99567,
+ 0.99416,
+ 0.99578,
+ 0.9957,
+ 0.99511,
+ 0.99535,
+ 0.99552,
+ 0.99541,
+ 0.9954,
+ 0.99489,
+ 0.99518,
+ 0.99484,
+ 0.99481,
+ 0.99415,
+ 0.99419,
+ 0.99396,
+ 0.99388,
+ 0.99349,
+ 0.99309,
+ 0.9927,
+ 0.99228,
+ 0.99171,
+ 0.99137,
+ 0.99068,
+ 0.99005,
+ 0.98944,
+ 0.98849,
+ 0.98758,
+ 0.98644,
+ 0.98504,
+ 0.9836,
+ 0.98202,
+ 0.97977,
+ 0.97717,
+ 0.9741,
+ 0.97003,
+ 0.96538,
+ 0.9593,
+ 0.95086,
+ 0.94013,
+ 0.92402,
+ 0.90241,
+ 0.86821,
+ 0.81838
+ ],
+ [
+ 1.0,
+ 1.02213,
+ 1.0041,
+ 1.00061,
+ 0.99762,
+ 0.99685,
+ 0.99586,
+ 0.99422,
+ 0.99575,
+ 0.99563,
+ 0.99506,
+ 0.99531,
+ 0.99549,
+ 0.99539,
+ 0.99536,
+ 0.99485,
+ 0.99514,
+ 0.99478,
+ 0.99479,
+ 0.99413,
+ 0.99416,
+ 0.99393,
+ 0.99386,
+ 0.99349,
+ 0.99304,
+ 0.9927,
+ 0.99226,
+ 0.9917,
+ 0.99135,
+ 0.99063,
+ 0.99003,
+ 0.98942,
+ 0.98849,
+ 0.98757,
+ 0.98643,
+ 0.98503,
+ 0.98359,
+ 0.98201,
+ 0.97978,
+ 0.97718,
+ 0.97411,
+ 0.97002,
+ 0.96541,
+ 0.95933,
+ 0.95089,
+ 0.94019,
+ 0.92414,
+ 0.9026,
+ 0.86868,
+ 0.81939
+ ]
+ ]
+}
diff --git a/configs/caching/taylorseer/wan_t2v_taylorseer.json b/configs/caching/taylorseer/wan_t2v_taylorseer.json
new file mode 100644
index 0000000000000000000000000000000000000000..bb4b4414eaab046ce4452b4df7bfb79d6a6e60df
--- /dev/null
+++ b/configs/caching/taylorseer/wan_t2v_taylorseer.json
@@ -0,0 +1,15 @@
+{
+ "infer_steps": 50,
+ "target_video_length": 81,
+ "text_len": 512,
+ "target_height": 480,
+ "target_width": 832,
+ "self_attn_1_type": "flash_attn3",
+ "cross_attn_1_type": "flash_attn3",
+ "cross_attn_2_type": "flash_attn3",
+ "sample_guide_scale": 6,
+ "sample_shift": 8,
+ "enable_cfg": true,
+ "cpu_offload": false,
+ "feature_caching": "TaylorSeer"
+}
diff --git a/configs/caching/teacache/wan_i2v_tea_480p.json b/configs/caching/teacache/wan_i2v_tea_480p.json
new file mode 100644
index 0000000000000000000000000000000000000000..cde8fc6b465ac97743e6a0fd32c10b4fa6545f2a
--- /dev/null
+++ b/configs/caching/teacache/wan_i2v_tea_480p.json
@@ -0,0 +1,32 @@
+{
+ "infer_steps": 40,
+ "target_video_length": 81,
+ "target_height": 480,
+ "target_width": 832,
+ "self_attn_1_type": "flash_attn3",
+ "cross_attn_1_type": "flash_attn3",
+ "cross_attn_2_type": "flash_attn3",
+ "sample_guide_scale": 5,
+ "sample_shift": 5,
+ "enable_cfg": true,
+ "cpu_offload": false,
+ "feature_caching": "Tea",
+ "coefficients": [
+ [
+ 2.57151496e05,
+ -3.54229917e04,
+ 1.40286849e03,
+ -1.35890334e01,
+ 1.32517977e-01
+ ],
+ [
+ -3.02331670e02,
+ 2.23948934e02,
+ -5.25463970e01,
+ 5.87348440e00,
+ -2.01973289e-01
+ ]
+ ],
+ "use_ret_steps": true,
+ "teacache_thresh": 0.26
+}
diff --git a/configs/caching/teacache/wan_i2v_tea_720p.json b/configs/caching/teacache/wan_i2v_tea_720p.json
new file mode 100644
index 0000000000000000000000000000000000000000..2ff56d0135e7412c4cf0ec6372057e30bc5c6a3e
--- /dev/null
+++ b/configs/caching/teacache/wan_i2v_tea_720p.json
@@ -0,0 +1,32 @@
+{
+ "infer_steps": 40,
+ "target_video_length": 81,
+ "target_height": 1280,
+ "target_width": 720,
+ "self_attn_1_type": "flash_attn3",
+ "cross_attn_1_type": "flash_attn3",
+ "cross_attn_2_type": "flash_attn3",
+ "sample_guide_scale": 5,
+ "sample_shift": 5,
+ "enable_cfg": true,
+ "cpu_offload": false,
+ "feature_caching": "Tea",
+ "coefficients": [
+ [
+ 8.10705460e03,
+ 2.13393892e03,
+ -3.72934672e02,
+ 1.66203073e01,
+ -4.17769401e-02
+ ],
+ [
+ -114.36346466,
+ 65.26524496,
+ -18.82220707,
+ 4.91518089,
+ -0.23412683
+ ]
+ ],
+ "use_ret_steps": true,
+ "teacache_thresh": 0.26
+}
diff --git a/configs/caching/teacache/wan_t2v_1_3b_tea_480p.json b/configs/caching/teacache/wan_t2v_1_3b_tea_480p.json
new file mode 100644
index 0000000000000000000000000000000000000000..cdb266ecd46a79f90519e690c8e37fa4511427bd
--- /dev/null
+++ b/configs/caching/teacache/wan_t2v_1_3b_tea_480p.json
@@ -0,0 +1,33 @@
+{
+ "infer_steps": 50,
+ "target_video_length": 81,
+ "text_len": 512,
+ "target_height": 480,
+ "target_width": 832,
+ "self_attn_1_type": "flash_attn3",
+ "cross_attn_1_type": "flash_attn3",
+ "cross_attn_2_type": "flash_attn3",
+ "sample_guide_scale": 6,
+ "sample_shift": 8,
+ "enable_cfg": true,
+ "cpu_offload": false,
+ "feature_caching": "Tea",
+ "coefficients": [
+ [
+ -5.21862437e04,
+ 9.23041404e03,
+ -5.28275948e02,
+ 1.36987616e01,
+ -4.99875664e-02
+ ],
+ [
+ 2.39676752e03,
+ -1.31110545e03,
+ 2.01331979e02,
+ -8.29855975e00,
+ 1.37887774e-01
+ ]
+ ],
+ "use_ret_steps": true,
+ "teacache_thresh": 0.26
+}
diff --git a/configs/caching/teacache/wan_ti2v_tea_720p.json b/configs/caching/teacache/wan_ti2v_tea_720p.json
new file mode 100644
index 0000000000000000000000000000000000000000..1ea52413d71cb0f78be6a873690b95ee7c1a5659
--- /dev/null
+++ b/configs/caching/teacache/wan_ti2v_tea_720p.json
@@ -0,0 +1,25 @@
+{
+ "infer_steps": 50,
+ "target_video_length": 121,
+ "text_len": 512,
+ "target_height": 704,
+ "target_width": 1280,
+ "num_channels_latents": 48,
+ "vae_stride": [4, 16, 16],
+ "self_attn_1_type": "flash_attn3",
+ "cross_attn_1_type": "flash_attn3",
+ "cross_attn_2_type": "flash_attn3",
+ "sample_guide_scale": 5.0,
+ "sample_shift": 5.0,
+ "enable_cfg": true,
+ "cpu_offload": false,
+ "fps": 24,
+ "feature_caching": "Tea",
+ "coefficients": [
+ [],
+ [ 1.57472669e+05, -1.15702395e+05, 3.10761669e+04, -3.83116651e+03, 2.21608777e+02, -4.81179567e+00]
+ ],
+ "use_ret_steps": false,
+ "teacache_thresh": 0.26,
+ "use_image_encoder": false
+}
diff --git a/configs/causvid/wan_i2v_causvid.json b/configs/causvid/wan_i2v_causvid.json
new file mode 100644
index 0000000000000000000000000000000000000000..3a1acf127754861573e99d9b8e6d074abc56cd9f
--- /dev/null
+++ b/configs/causvid/wan_i2v_causvid.json
@@ -0,0 +1,29 @@
+{
+ "infer_steps": 20,
+ "target_video_length": 81,
+ "target_height": 480,
+ "target_width": 832,
+ "self_attn_1_type": "flash_attn3",
+ "cross_attn_1_type": "flash_attn3",
+ "cross_attn_2_type": "flash_attn3",
+ "sample_guide_scale": 6,
+ "sample_shift": 8,
+ "enable_cfg": false,
+ "cpu_offload": false,
+ "num_fragments": 3,
+ "num_frames": 21,
+ "num_frame_per_block": 7,
+ "num_blocks": 3,
+ "frame_seq_length": 1560,
+ "denoising_step_list": [
+ 999,
+ 934,
+ 862,
+ 756,
+ 603,
+ 410,
+ 250,
+ 140,
+ 74
+ ]
+}
diff --git a/configs/causvid/wan_t2v_causvid.json b/configs/causvid/wan_t2v_causvid.json
new file mode 100644
index 0000000000000000000000000000000000000000..253f453b44c1046aa496c109c49204d71e013ca7
--- /dev/null
+++ b/configs/causvid/wan_t2v_causvid.json
@@ -0,0 +1,29 @@
+{
+ "infer_steps": 9,
+ "target_video_length": 81,
+ "target_height": 480,
+ "target_width": 832,
+ "self_attn_1_type": "flash_attn3",
+ "cross_attn_1_type": "flash_attn3",
+ "cross_attn_2_type": "flash_attn3",
+ "sample_guide_scale": 6,
+ "sample_shift": 8,
+ "enable_cfg": false,
+ "cpu_offload": false,
+ "num_fragments": 3,
+ "num_frames": 21,
+ "num_frame_per_block": 3,
+ "num_blocks": 7,
+ "frame_seq_length": 1560,
+ "denoising_step_list": [
+ 999,
+ 934,
+ 862,
+ 756,
+ 603,
+ 410,
+ 250,
+ 140,
+ 74
+ ]
+}
diff --git a/configs/changing_resolution/wan_i2v.json b/configs/changing_resolution/wan_i2v.json
new file mode 100644
index 0000000000000000000000000000000000000000..7b828d461e7f8e13b6883dc1bf3fd0a83ca847e4
--- /dev/null
+++ b/configs/changing_resolution/wan_i2v.json
@@ -0,0 +1,20 @@
+{
+ "infer_steps": 40,
+ "target_video_length": 81,
+ "target_height": 480,
+ "target_width": 832,
+ "self_attn_1_type": "flash_attn3",
+ "cross_attn_1_type": "flash_attn3",
+ "cross_attn_2_type": "flash_attn3",
+ "sample_guide_scale": 5,
+ "sample_shift": 3,
+ "enable_cfg": true,
+ "cpu_offload": false,
+ "changing_resolution": true,
+ "resolution_rate": [
+ 0.75
+ ],
+ "changing_resolution_steps": [
+ 20
+ ]
+}
diff --git a/configs/changing_resolution/wan_i2v_U.json b/configs/changing_resolution/wan_i2v_U.json
new file mode 100644
index 0000000000000000000000000000000000000000..0f8077504b18376115300d505e527e8e6ad2403c
--- /dev/null
+++ b/configs/changing_resolution/wan_i2v_U.json
@@ -0,0 +1,22 @@
+{
+ "infer_steps": 40,
+ "target_video_length": 81,
+ "target_height": 480,
+ "target_width": 832,
+ "self_attn_1_type": "flash_attn3",
+ "cross_attn_1_type": "flash_attn3",
+ "cross_attn_2_type": "flash_attn3",
+ "sample_guide_scale": 5,
+ "sample_shift": 3,
+ "enable_cfg": true,
+ "cpu_offload": false,
+ "changing_resolution": true,
+ "resolution_rate": [
+ 1.0,
+ 0.75
+ ],
+ "changing_resolution_steps": [
+ 5,
+ 25
+ ]
+}
diff --git a/configs/changing_resolution/wan_t2v.json b/configs/changing_resolution/wan_t2v.json
new file mode 100644
index 0000000000000000000000000000000000000000..78782775cedb9e340bf00ba5e17903583635ffa7
--- /dev/null
+++ b/configs/changing_resolution/wan_t2v.json
@@ -0,0 +1,21 @@
+{
+ "infer_steps": 50,
+ "target_video_length": 81,
+ "text_len": 512,
+ "target_height": 480,
+ "target_width": 832,
+ "self_attn_1_type": "flash_attn3",
+ "cross_attn_1_type": "flash_attn3",
+ "cross_attn_2_type": "flash_attn3",
+ "sample_guide_scale": 6,
+ "sample_shift": 8,
+ "enable_cfg": true,
+ "cpu_offload": false,
+ "changing_resolution": true,
+ "resolution_rate": [
+ 0.75
+ ],
+ "changing_resolution_steps": [
+ 25
+ ]
+}
diff --git a/configs/changing_resolution/wan_t2v_U.json b/configs/changing_resolution/wan_t2v_U.json
new file mode 100644
index 0000000000000000000000000000000000000000..68531e6639263ba7f32e90c0612b7f7836d7ceab
--- /dev/null
+++ b/configs/changing_resolution/wan_t2v_U.json
@@ -0,0 +1,23 @@
+{
+ "infer_steps": 50,
+ "target_video_length": 81,
+ "text_len": 512,
+ "target_height": 480,
+ "target_width": 832,
+ "self_attn_1_type": "flash_attn3",
+ "cross_attn_1_type": "flash_attn3",
+ "cross_attn_2_type": "flash_attn3",
+ "sample_guide_scale": 6,
+ "sample_shift": 8,
+ "enable_cfg": true,
+ "cpu_offload": false,
+ "changing_resolution": true,
+ "resolution_rate": [
+ 1.0,
+ 0.75
+ ],
+ "changing_resolution_steps": [
+ 10,
+ 35
+ ]
+}
diff --git a/configs/changing_resolution/wan_t2v_U_teacache.json b/configs/changing_resolution/wan_t2v_U_teacache.json
new file mode 100644
index 0000000000000000000000000000000000000000..60ccc67a30176fd66cfbdeae2e568941c35984c3
--- /dev/null
+++ b/configs/changing_resolution/wan_t2v_U_teacache.json
@@ -0,0 +1,42 @@
+{
+ "infer_steps": 50,
+ "target_video_length": 81,
+ "text_len": 512,
+ "target_height": 480,
+ "target_width": 832,
+ "self_attn_1_type": "flash_attn3",
+ "cross_attn_1_type": "flash_attn3",
+ "cross_attn_2_type": "flash_attn3",
+ "sample_guide_scale": 6,
+ "sample_shift": 8,
+ "enable_cfg": true,
+ "cpu_offload": false,
+ "changing_resolution": true,
+ "resolution_rate": [
+ 1.0,
+ 0.75
+ ],
+ "changing_resolution_steps": [
+ 10,
+ 35
+ ],
+ "feature_caching": "Tea",
+ "coefficients": [
+ [
+ -5.21862437e04,
+ 9.23041404e03,
+ -5.28275948e02,
+ 1.36987616e01,
+ -4.99875664e-02
+ ],
+ [
+ 2.39676752e03,
+ -1.31110545e03,
+ 2.01331979e02,
+ -8.29855975e00,
+ 1.37887774e-01
+ ]
+ ],
+ "use_ret_steps": false,
+ "teacache_thresh": 0.1
+}
diff --git a/configs/deploy/wan_i2v.json b/configs/deploy/wan_i2v.json
new file mode 100644
index 0000000000000000000000000000000000000000..9f1fbde2bdc8507a2e14bb36eb45f62f282a5ce2
--- /dev/null
+++ b/configs/deploy/wan_i2v.json
@@ -0,0 +1,30 @@
+{
+ "infer_steps": 40,
+ "target_video_length": 81,
+ "target_height": 480,
+ "target_width": 832,
+ "self_attn_1_type": "flash_attn3",
+ "cross_attn_1_type": "flash_attn3",
+ "cross_attn_2_type": "flash_attn3",
+ "sample_guide_scale": 5,
+ "sample_shift": 5,
+ "enable_cfg": true,
+ "cpu_offload": false,
+ "sub_servers": {
+ "dit": [
+ "http://localhost:9000"
+ ],
+ "prompt_enhancer": [
+ "http://localhost:9001"
+ ],
+ "text_encoders": [
+ "http://localhost:9002"
+ ],
+ "image_encoder": [
+ "http://localhost:9003"
+ ],
+ "vae_model": [
+ "http://localhost:9004"
+ ]
+ }
+}
diff --git a/configs/deploy/wan_t2v.json b/configs/deploy/wan_t2v.json
new file mode 100644
index 0000000000000000000000000000000000000000..43656d7fa0a2c45125677ca2fb6e85ef37d9087a
--- /dev/null
+++ b/configs/deploy/wan_t2v.json
@@ -0,0 +1,31 @@
+{
+ "infer_steps": 50,
+ "target_video_length": 81,
+ "text_len": 512,
+ "target_height": 480,
+ "target_width": 832,
+ "self_attn_1_type": "flash_attn3",
+ "cross_attn_1_type": "flash_attn3",
+ "cross_attn_2_type": "flash_attn3",
+ "sample_guide_scale": 6,
+ "sample_shift": 8,
+ "enable_cfg": true,
+ "cpu_offload": false,
+ "sub_servers": {
+ "dit": [
+ "http://localhost:9000"
+ ],
+ "prompt_enhancer": [
+ "http://localhost:9001"
+ ],
+ "text_encoders": [
+ "http://localhost:9002"
+ ],
+ "image_encoder": [
+ "http://localhost:9003"
+ ],
+ "vae_model": [
+ "http://localhost:9004"
+ ]
+ }
+}
diff --git a/configs/dist_infer/wan22_moe_i2v_cfg.json b/configs/dist_infer/wan22_moe_i2v_cfg.json
new file mode 100644
index 0000000000000000000000000000000000000000..bafa409ea8077198c458db5a0496e7a726b75074
--- /dev/null
+++ b/configs/dist_infer/wan22_moe_i2v_cfg.json
@@ -0,0 +1,25 @@
+{
+ "infer_steps": 40,
+ "target_video_length": 81,
+ "text_len": 512,
+ "target_height": 720,
+ "target_width": 1280,
+ "self_attn_1_type": "flash_attn3",
+ "cross_attn_1_type": "flash_attn3",
+ "cross_attn_2_type": "flash_attn3",
+ "sample_guide_scale": [
+ 3.5,
+ 3.5
+ ],
+ "sample_shift": 5.0,
+ "enable_cfg": true,
+ "cpu_offload": true,
+ "offload_granularity": "model",
+ "t5_cpu_offload": false,
+ "vae_cpu_offload": false,
+ "boundary": 0.900,
+ "use_image_encoder": false,
+ "parallel": {
+ "cfg_p_size": 2
+ }
+}
diff --git a/configs/dist_infer/wan22_moe_i2v_cfg_ulysses.json b/configs/dist_infer/wan22_moe_i2v_cfg_ulysses.json
new file mode 100644
index 0000000000000000000000000000000000000000..91a15a0d6200a00e3f882079a8da2aac009b0fd8
--- /dev/null
+++ b/configs/dist_infer/wan22_moe_i2v_cfg_ulysses.json
@@ -0,0 +1,25 @@
+{
+ "infer_steps": 40,
+ "target_video_length": 81,
+ "text_len": 512,
+ "target_height": 720,
+ "target_width": 1280,
+ "self_attn_1_type": "flash_attn3",
+ "cross_attn_1_type": "flash_attn3",
+ "cross_attn_2_type": "flash_attn3",
+ "sample_guide_scale": [
+ 3.5,
+ 3.5
+ ],
+ "sample_shift": 5.0,
+ "enable_cfg": true,
+ "cpu_offload": true,
+ "offload_granularity": "model",
+ "boundary": 0.900,
+ "use_image_encoder": false,
+ "parallel": {
+ "seq_p_size": 4,
+ "seq_p_attn_type": "ulysses",
+ "cfg_p_size": 2
+ }
+}
diff --git a/configs/dist_infer/wan22_moe_i2v_ulysses.json b/configs/dist_infer/wan22_moe_i2v_ulysses.json
new file mode 100644
index 0000000000000000000000000000000000000000..eb0759b39a65be5f02f6e94bcd055de5c94ce406
--- /dev/null
+++ b/configs/dist_infer/wan22_moe_i2v_ulysses.json
@@ -0,0 +1,26 @@
+{
+ "infer_steps": 40,
+ "target_video_length": 81,
+ "text_len": 512,
+ "target_height": 720,
+ "target_width": 1280,
+ "self_attn_1_type": "flash_attn3",
+ "cross_attn_1_type": "flash_attn3",
+ "cross_attn_2_type": "flash_attn3",
+ "sample_guide_scale": [
+ 3.5,
+ 3.5
+ ],
+ "sample_shift": 5.0,
+ "enable_cfg": true,
+ "cpu_offload": true,
+ "offload_granularity": "model",
+ "t5_cpu_offload": false,
+ "vae_cpu_offload": false,
+ "boundary": 0.900,
+ "use_image_encoder": false,
+ "parallel": {
+ "seq_p_size": 4,
+ "seq_p_attn_type": "ulysses"
+ }
+}
diff --git a/configs/dist_infer/wan22_moe_t2v_cfg.json b/configs/dist_infer/wan22_moe_t2v_cfg.json
new file mode 100644
index 0000000000000000000000000000000000000000..f47aad82f81120969cb2b177dddb05280fda7968
--- /dev/null
+++ b/configs/dist_infer/wan22_moe_t2v_cfg.json
@@ -0,0 +1,24 @@
+{
+ "infer_steps": 40,
+ "target_video_length": 81,
+ "text_len": 512,
+ "target_height": 720,
+ "target_width": 1280,
+ "self_attn_1_type": "flash_attn3",
+ "cross_attn_1_type": "flash_attn3",
+ "cross_attn_2_type": "flash_attn3",
+ "sample_guide_scale": [
+ 4.0,
+ 3.0
+ ],
+ "sample_shift": 12.0,
+ "enable_cfg": true,
+ "cpu_offload": true,
+ "offload_granularity": "model",
+ "t5_cpu_offload": false,
+ "vae_cpu_offload": false,
+ "boundary": 0.875,
+ "parallel": {
+ "cfg_p_size": 2
+ }
+}
diff --git a/configs/dist_infer/wan22_moe_t2v_cfg_ulysses.json b/configs/dist_infer/wan22_moe_t2v_cfg_ulysses.json
new file mode 100644
index 0000000000000000000000000000000000000000..645e6d7f5216dc3033461427ad39f6a06f792c98
--- /dev/null
+++ b/configs/dist_infer/wan22_moe_t2v_cfg_ulysses.json
@@ -0,0 +1,26 @@
+{
+ "infer_steps": 40,
+ "target_video_length": 81,
+ "text_len": 512,
+ "target_height": 720,
+ "target_width": 1280,
+ "self_attn_1_type": "flash_attn3",
+ "cross_attn_1_type": "flash_attn3",
+ "cross_attn_2_type": "flash_attn3",
+ "sample_guide_scale": [
+ 4.0,
+ 3.0
+ ],
+ "sample_shift": 12.0,
+ "enable_cfg": true,
+ "cpu_offload": true,
+ "offload_granularity": "model",
+ "t5_cpu_offload": false,
+ "vae_cpu_offload": false,
+ "boundary": 0.875,
+ "parallel": {
+ "seq_p_size": 4,
+ "seq_p_attn_type": "ulysses",
+ "cfg_p_size": 2
+ }
+}
diff --git a/configs/dist_infer/wan22_moe_t2v_ulysses.json b/configs/dist_infer/wan22_moe_t2v_ulysses.json
new file mode 100644
index 0000000000000000000000000000000000000000..03aaf9246536c23330cb1f502c66f815abef8fe3
--- /dev/null
+++ b/configs/dist_infer/wan22_moe_t2v_ulysses.json
@@ -0,0 +1,25 @@
+{
+ "infer_steps": 40,
+ "target_video_length": 81,
+ "text_len": 512,
+ "target_height": 720,
+ "target_width": 1280,
+ "self_attn_1_type": "flash_attn3",
+ "cross_attn_1_type": "flash_attn3",
+ "cross_attn_2_type": "flash_attn3",
+ "sample_guide_scale": [
+ 4.0,
+ 3.0
+ ],
+ "sample_shift": 12.0,
+ "enable_cfg": true,
+ "cpu_offload": true,
+ "offload_granularity": "model",
+ "t5_cpu_offload": false,
+ "vae_cpu_offload": false,
+ "boundary": 0.875,
+ "parallel": {
+ "seq_p_size": 4,
+ "seq_p_attn_type": "ulysses"
+ }
+}
diff --git a/configs/dist_infer/wan22_ti2v_i2v_cfg.json b/configs/dist_infer/wan22_ti2v_i2v_cfg.json
new file mode 100644
index 0000000000000000000000000000000000000000..4754ff30d382e3dd0732bca8e3ba51f9613ac4a7
--- /dev/null
+++ b/configs/dist_infer/wan22_ti2v_i2v_cfg.json
@@ -0,0 +1,25 @@
+{
+ "infer_steps": 50,
+ "target_video_length": 121,
+ "text_len": 512,
+ "target_height": 704,
+ "target_width": 1280,
+ "num_channels_latents": 48,
+ "vae_stride": [
+ 4,
+ 16,
+ 16
+ ],
+ "self_attn_1_type": "flash_attn3",
+ "cross_attn_1_type": "flash_attn3",
+ "cross_attn_2_type": "flash_attn3",
+ "sample_guide_scale": 5.0,
+ "sample_shift": 5.0,
+ "enable_cfg": true,
+ "cpu_offload": false,
+ "fps": 24,
+ "use_image_encoder": false,
+ "parallel": {
+ "cfg_p_size": 2
+ }
+}
diff --git a/configs/dist_infer/wan22_ti2v_i2v_cfg_ulysses.json b/configs/dist_infer/wan22_ti2v_i2v_cfg_ulysses.json
new file mode 100644
index 0000000000000000000000000000000000000000..9e340f400f80ad10a579e07c3c294265cff18e94
--- /dev/null
+++ b/configs/dist_infer/wan22_ti2v_i2v_cfg_ulysses.json
@@ -0,0 +1,27 @@
+{
+ "infer_steps": 50,
+ "target_video_length": 121,
+ "text_len": 512,
+ "target_height": 704,
+ "target_width": 1280,
+ "num_channels_latents": 48,
+ "vae_stride": [
+ 4,
+ 16,
+ 16
+ ],
+ "self_attn_1_type": "flash_attn3",
+ "cross_attn_1_type": "flash_attn3",
+ "cross_attn_2_type": "flash_attn3",
+ "sample_guide_scale": 5.0,
+ "sample_shift": 5.0,
+ "enable_cfg": true,
+ "cpu_offload": false,
+ "fps": 24,
+ "use_image_encoder": false,
+ "parallel": {
+ "seq_p_size": 4,
+ "seq_p_attn_type": "ulysses",
+ "cfg_p_size": 2
+ }
+}
diff --git a/configs/dist_infer/wan22_ti2v_i2v_ulysses.json b/configs/dist_infer/wan22_ti2v_i2v_ulysses.json
new file mode 100644
index 0000000000000000000000000000000000000000..56d0f65e5aa66d7c7b42b2c7a651a4ab6c1c1930
--- /dev/null
+++ b/configs/dist_infer/wan22_ti2v_i2v_ulysses.json
@@ -0,0 +1,26 @@
+{
+ "infer_steps": 50,
+ "target_video_length": 121,
+ "text_len": 512,
+ "target_height": 704,
+ "target_width": 1280,
+ "num_channels_latents": 48,
+ "vae_stride": [
+ 4,
+ 16,
+ 16
+ ],
+ "self_attn_1_type": "flash_attn3",
+ "cross_attn_1_type": "flash_attn3",
+ "cross_attn_2_type": "flash_attn3",
+ "sample_guide_scale": 5.0,
+ "sample_shift": 5.0,
+ "enable_cfg": true,
+ "cpu_offload": false,
+ "fps": 24,
+ "use_image_encoder": false,
+ "parallel": {
+ "seq_p_size": 4,
+ "seq_p_attn_type": "ulysses"
+ }
+}
diff --git a/configs/dist_infer/wan22_ti2v_t2v_cfg.json b/configs/dist_infer/wan22_ti2v_t2v_cfg.json
new file mode 100644
index 0000000000000000000000000000000000000000..c88cb2a10144a23cda3daebf5bc06d341db5a5e0
--- /dev/null
+++ b/configs/dist_infer/wan22_ti2v_t2v_cfg.json
@@ -0,0 +1,24 @@
+{
+ "infer_steps": 50,
+ "target_video_length": 121,
+ "text_len": 512,
+ "target_height": 704,
+ "target_width": 1280,
+ "num_channels_latents": 48,
+ "vae_stride": [
+ 4,
+ 16,
+ 16
+ ],
+ "self_attn_1_type": "flash_attn3",
+ "cross_attn_1_type": "flash_attn3",
+ "cross_attn_2_type": "flash_attn3",
+ "sample_guide_scale": 5.0,
+ "sample_shift": 5.0,
+ "enable_cfg": true,
+ "cpu_offload": false,
+ "fps": 24,
+ "parallel": {
+ "cfg_p_size": 2
+ }
+}
diff --git a/configs/dist_infer/wan22_ti2v_t2v_cfg_ulysses.json b/configs/dist_infer/wan22_ti2v_t2v_cfg_ulysses.json
new file mode 100644
index 0000000000000000000000000000000000000000..79f4f03f0d1f16bf0825aabd1975c3105ea19fb6
--- /dev/null
+++ b/configs/dist_infer/wan22_ti2v_t2v_cfg_ulysses.json
@@ -0,0 +1,26 @@
+{
+ "infer_steps": 50,
+ "target_video_length": 121,
+ "text_len": 512,
+ "target_height": 704,
+ "target_width": 1280,
+ "num_channels_latents": 48,
+ "vae_stride": [
+ 4,
+ 16,
+ 16
+ ],
+ "self_attn_1_type": "flash_attn3",
+ "cross_attn_1_type": "flash_attn3",
+ "cross_attn_2_type": "flash_attn3",
+ "sample_guide_scale": 5.0,
+ "sample_shift": 5.0,
+ "enable_cfg": true,
+ "cpu_offload": false,
+ "fps": 24,
+ "parallel": {
+ "seq_p_size": 4,
+ "seq_p_attn_type": "ulysses",
+ "cfg_p_size": 2
+ }
+}
diff --git a/configs/dist_infer/wan22_ti2v_t2v_ulysses.json b/configs/dist_infer/wan22_ti2v_t2v_ulysses.json
new file mode 100644
index 0000000000000000000000000000000000000000..12b18509e0d98a2bbe9c89b054d96bfa79d66f5e
--- /dev/null
+++ b/configs/dist_infer/wan22_ti2v_t2v_ulysses.json
@@ -0,0 +1,25 @@
+{
+ "infer_steps": 50,
+ "target_video_length": 121,
+ "text_len": 512,
+ "target_height": 704,
+ "target_width": 1280,
+ "num_channels_latents": 48,
+ "vae_stride": [
+ 4,
+ 16,
+ 16
+ ],
+ "self_attn_1_type": "flash_attn3",
+ "cross_attn_1_type": "flash_attn3",
+ "cross_attn_2_type": "flash_attn3",
+ "sample_guide_scale": 5.0,
+ "sample_shift": 5.0,
+ "enable_cfg": true,
+ "cpu_offload": false,
+ "fps": 24,
+ "parallel": {
+ "seq_p_size": 4,
+ "seq_p_attn_type": "ulysses"
+ }
+}
diff --git a/configs/dist_infer/wan_i2v_dist_cfg_ulysses.json b/configs/dist_infer/wan_i2v_dist_cfg_ulysses.json
new file mode 100644
index 0000000000000000000000000000000000000000..001f1f0c6e813e6c3d3a7fcd1014a973037b91f5
--- /dev/null
+++ b/configs/dist_infer/wan_i2v_dist_cfg_ulysses.json
@@ -0,0 +1,18 @@
+{
+ "infer_steps": 40,
+ "target_video_length": 81,
+ "target_height": 480,
+ "target_width": 832,
+ "self_attn_1_type": "flash_attn3",
+ "cross_attn_1_type": "flash_attn3",
+ "cross_attn_2_type": "flash_attn3",
+ "sample_guide_scale": 5,
+ "sample_shift": 5,
+ "enable_cfg": true,
+ "cpu_offload": false,
+ "parallel": {
+ "seq_p_size": 4,
+ "seq_p_attn_type": "ulysses",
+ "cfg_p_size": 2
+ }
+}
diff --git a/configs/dist_infer/wan_i2v_dist_ring.json b/configs/dist_infer/wan_i2v_dist_ring.json
new file mode 100644
index 0000000000000000000000000000000000000000..fe2608aae5ed52a1873a3df346b00bf59e54e404
--- /dev/null
+++ b/configs/dist_infer/wan_i2v_dist_ring.json
@@ -0,0 +1,17 @@
+{
+ "infer_steps": 40,
+ "target_video_length": 81,
+ "target_height": 480,
+ "target_width": 832,
+ "self_attn_1_type": "flash_attn3",
+ "cross_attn_1_type": "flash_attn3",
+ "cross_attn_2_type": "flash_attn3",
+ "sample_guide_scale": 5,
+ "sample_shift": 5,
+ "enable_cfg": true,
+ "cpu_offload": false,
+ "parallel": {
+ "seq_p_size": 4,
+ "seq_p_attn_type": "ring"
+ }
+}
diff --git a/configs/dist_infer/wan_i2v_dist_ulysses.json b/configs/dist_infer/wan_i2v_dist_ulysses.json
new file mode 100644
index 0000000000000000000000000000000000000000..a8af87968ceb00ee70a3bd8a2608e52cb88ca738
--- /dev/null
+++ b/configs/dist_infer/wan_i2v_dist_ulysses.json
@@ -0,0 +1,17 @@
+{
+ "infer_steps": 40,
+ "target_video_length": 81,
+ "target_height": 480,
+ "target_width": 832,
+ "self_attn_1_type": "flash_attn3",
+ "cross_attn_1_type": "flash_attn3",
+ "cross_attn_2_type": "flash_attn3",
+ "sample_guide_scale": 5,
+ "sample_shift": 5,
+ "enable_cfg": true,
+ "cpu_offload": false,
+ "parallel": {
+ "seq_p_size": 4,
+ "seq_p_attn_type": "ulysses"
+ }
+}
diff --git a/configs/dist_infer/wan_t2v_dist_cfg.json b/configs/dist_infer/wan_t2v_dist_cfg.json
new file mode 100644
index 0000000000000000000000000000000000000000..49bc48161ab648cf7bdb9358b10e42b3376aba0e
--- /dev/null
+++ b/configs/dist_infer/wan_t2v_dist_cfg.json
@@ -0,0 +1,17 @@
+{
+ "infer_steps": 50,
+ "target_video_length": 81,
+ "text_len": 512,
+ "target_height": 480,
+ "target_width": 832,
+ "self_attn_1_type": "flash_attn3",
+ "cross_attn_1_type": "flash_attn3",
+ "cross_attn_2_type": "flash_attn3",
+ "sample_guide_scale": 6,
+ "sample_shift": 8,
+ "enable_cfg": true,
+ "cpu_offload": false,
+ "parallel": {
+ "cfg_p_size": 2
+ }
+}
diff --git a/configs/dist_infer/wan_t2v_dist_cfg_ring.json b/configs/dist_infer/wan_t2v_dist_cfg_ring.json
new file mode 100644
index 0000000000000000000000000000000000000000..50450f43e56cb27770305903996a3ee0674f0096
--- /dev/null
+++ b/configs/dist_infer/wan_t2v_dist_cfg_ring.json
@@ -0,0 +1,19 @@
+{
+ "infer_steps": 50,
+ "target_video_length": 81,
+ "text_len": 512,
+ "target_height": 480,
+ "target_width": 832,
+ "self_attn_1_type": "flash_attn3",
+ "cross_attn_1_type": "flash_attn3",
+ "cross_attn_2_type": "flash_attn3",
+ "sample_guide_scale": 6,
+ "sample_shift": 8,
+ "enable_cfg": true,
+ "cpu_offload": false,
+ "parallel": {
+ "seq_p_size": 4,
+ "seq_p_attn_type": "ring",
+ "cfg_p_size": 2
+ }
+}
diff --git a/configs/dist_infer/wan_t2v_dist_cfg_ulysses.json b/configs/dist_infer/wan_t2v_dist_cfg_ulysses.json
new file mode 100644
index 0000000000000000000000000000000000000000..bd6808dfd7c8c270221a966dea79da3ad54848be
--- /dev/null
+++ b/configs/dist_infer/wan_t2v_dist_cfg_ulysses.json
@@ -0,0 +1,19 @@
+{
+ "infer_steps": 50,
+ "target_video_length": 81,
+ "text_len": 512,
+ "target_height": 480,
+ "target_width": 832,
+ "self_attn_1_type": "flash_attn3",
+ "cross_attn_1_type": "flash_attn3",
+ "cross_attn_2_type": "flash_attn3",
+ "sample_guide_scale": 6,
+ "sample_shift": 8,
+ "enable_cfg": true,
+ "cpu_offload": false,
+ "parallel": {
+ "seq_p_size": 4,
+ "seq_p_attn_type": "ulysses",
+ "cfg_p_size": 2
+ }
+}
diff --git a/configs/dist_infer/wan_t2v_dist_ring.json b/configs/dist_infer/wan_t2v_dist_ring.json
new file mode 100644
index 0000000000000000000000000000000000000000..a28549bd6c930885adcc691e63d7024e041d7861
--- /dev/null
+++ b/configs/dist_infer/wan_t2v_dist_ring.json
@@ -0,0 +1,18 @@
+{
+ "infer_steps": 50,
+ "target_video_length": 81,
+ "text_len": 512,
+ "target_height": 480,
+ "target_width": 832,
+ "self_attn_1_type": "flash_attn3",
+ "cross_attn_1_type": "flash_attn3",
+ "cross_attn_2_type": "flash_attn3",
+ "sample_guide_scale": 6,
+ "sample_shift": 8,
+ "enable_cfg": true,
+ "cpu_offload": false,
+ "parallel": {
+ "seq_p_size": 4,
+ "seq_p_attn_type": "ring"
+ }
+}
diff --git a/configs/dist_infer/wan_t2v_dist_ulysses.json b/configs/dist_infer/wan_t2v_dist_ulysses.json
new file mode 100644
index 0000000000000000000000000000000000000000..c9b9bc2ec71a41ea5f468dc6cf09e072e764e248
--- /dev/null
+++ b/configs/dist_infer/wan_t2v_dist_ulysses.json
@@ -0,0 +1,18 @@
+{
+ "infer_steps": 50,
+ "target_video_length": 81,
+ "text_len": 512,
+ "target_height": 480,
+ "target_width": 832,
+ "self_attn_1_type": "flash_attn3",
+ "cross_attn_1_type": "flash_attn3",
+ "cross_attn_2_type": "flash_attn3",
+ "sample_guide_scale": 6,
+ "sample_shift": 8,
+ "enable_cfg": true,
+ "cpu_offload": false,
+ "parallel": {
+ "seq_p_size": 4,
+ "seq_p_attn_type": "ulysses"
+ }
+}
diff --git a/configs/distill/wan_i2v_distill_4step_cfg.json b/configs/distill/wan_i2v_distill_4step_cfg.json
new file mode 100644
index 0000000000000000000000000000000000000000..519f58a4ed1778b4a8b979482a9f7b7b34ea1571
--- /dev/null
+++ b/configs/distill/wan_i2v_distill_4step_cfg.json
@@ -0,0 +1,19 @@
+{
+ "infer_steps": 4,
+ "target_video_length": 81,
+ "target_height": 480,
+ "target_width": 832,
+ "self_attn_1_type": "flash_attn3",
+ "cross_attn_1_type": "flash_attn3",
+ "cross_attn_2_type": "flash_attn3",
+ "sample_guide_scale": 5,
+ "sample_shift": 5,
+ "enable_cfg": false,
+ "cpu_offload": false,
+ "denoising_step_list": [
+ 1000,
+ 750,
+ 500,
+ 250
+ ]
+}
diff --git a/configs/distill/wan_i2v_distill_4step_cfg_4090.json b/configs/distill/wan_i2v_distill_4step_cfg_4090.json
new file mode 100644
index 0000000000000000000000000000000000000000..c6863a558a5d1d9eafc8ce7825f64cfc2ee58be8
--- /dev/null
+++ b/configs/distill/wan_i2v_distill_4step_cfg_4090.json
@@ -0,0 +1,29 @@
+{
+ "infer_steps": 4,
+ "target_video_length": 81,
+ "target_height": 480,
+ "target_width": 832,
+ "self_attn_1_type": "sage_attn2",
+ "cross_attn_1_type": "sage_attn2",
+ "cross_attn_2_type": "sage_attn2",
+ "sample_guide_scale": 5,
+ "sample_shift": 5,
+ "enable_cfg": false,
+ "cpu_offload": true,
+ "offload_granularity": "block",
+ "t5_cpu_offload": false,
+ "vae_cpu_offload": false,
+ "clip_cpu_offload": false,
+ "denoising_step_list": [
+ 1000,
+ 750,
+ 500,
+ 250
+ ],
+ "dit_quantized": true,
+ "dit_quant_scheme": "fp8-q8f",
+ "t5_quantized": true,
+ "t5_quant_scheme": "fp8-q8f",
+ "clip_quantized": true,
+ "clip_quant_scheme": "fp8-q8f"
+}
diff --git a/configs/distill/wan_i2v_distill_4step_cfg_4090_lora.json b/configs/distill/wan_i2v_distill_4step_cfg_4090_lora.json
new file mode 100644
index 0000000000000000000000000000000000000000..100eb453da684c3c6c1e8dd751b68671b149af55
--- /dev/null
+++ b/configs/distill/wan_i2v_distill_4step_cfg_4090_lora.json
@@ -0,0 +1,35 @@
+{
+ "infer_steps": 4,
+ "target_video_length": 81,
+ "target_height": 480,
+ "target_width": 832,
+ "self_attn_1_type": "sage_attn2",
+ "cross_attn_1_type": "sage_attn2",
+ "cross_attn_2_type": "sage_attn2",
+ "sample_guide_scale": 5,
+ "sample_shift": 5,
+ "enable_cfg": false,
+ "cpu_offload": true,
+ "offload_granularity": "block",
+ "t5_cpu_offload": false,
+ "vae_cpu_offload": false,
+ "clip_cpu_offload": false,
+ "denoising_step_list": [
+ 1000,
+ 750,
+ 500,
+ 250
+ ],
+ "dit_quantized": true,
+ "dit_quant_scheme": "fp8-q8f",
+ "t5_quantized": true,
+ "t5_quant_scheme": "fp8-q8f",
+ "clip_quantized": true,
+ "clip_quant_scheme": "fp8-q8f",
+ "lora_configs": [
+ {
+ "path": "lightx2v/Wan2.1-Distill-Loras/wan2.1_i2v_lora_rank64_lightx2v_4step.safetensors",
+ "strength": 1.0
+ }
+ ]
+}
diff --git a/configs/distill/wan_i2v_distill_4step_cfg_lora.json b/configs/distill/wan_i2v_distill_4step_cfg_lora.json
new file mode 100644
index 0000000000000000000000000000000000000000..51797dd123006864bf4dedc81cf1c76b21751eaf
--- /dev/null
+++ b/configs/distill/wan_i2v_distill_4step_cfg_lora.json
@@ -0,0 +1,20 @@
+{
+ "infer_steps": 4,
+ "target_video_length": 81,
+ "target_height": 480,
+ "target_width": 832,
+ "self_attn_1_type": "flash_attn3",
+ "cross_attn_1_type": "flash_attn3",
+ "cross_attn_2_type": "flash_attn3",
+ "sample_guide_scale": 5,
+ "sample_shift": 5,
+ "enable_cfg": false,
+ "cpu_offload": false,
+ "denoising_step_list": [1000, 750, 500, 250],
+ "lora_configs": [
+ {
+ "path": "lightx2v/Wan2.1-Distill-Loras/wan2.1_i2v_lora_rank64_lightx2v_4step.safetensors",
+ "strength": 1.0
+ }
+ ]
+}
diff --git a/configs/distill/wan_t2v_distill_4step_cfg.json b/configs/distill/wan_t2v_distill_4step_cfg.json
new file mode 100644
index 0000000000000000000000000000000000000000..89ea0675604af80a6042cd0caa36a744b7d38098
--- /dev/null
+++ b/configs/distill/wan_t2v_distill_4step_cfg.json
@@ -0,0 +1,20 @@
+{
+ "infer_steps": 4,
+ "target_video_length": 81,
+ "text_len": 512,
+ "target_height": 480,
+ "target_width": 832,
+ "self_attn_1_type": "flash_attn3",
+ "cross_attn_1_type": "flash_attn3",
+ "cross_attn_2_type": "flash_attn3",
+ "sample_guide_scale": 6,
+ "sample_shift": 5,
+ "enable_cfg": false,
+ "cpu_offload": false,
+ "denoising_step_list": [
+ 1000,
+ 750,
+ 500,
+ 250
+ ]
+}
diff --git a/configs/distill/wan_t2v_distill_4step_cfg_4090.json b/configs/distill/wan_t2v_distill_4step_cfg_4090.json
new file mode 100644
index 0000000000000000000000000000000000000000..0255d0923a7f21a832b09d9943044e1c355d8efd
--- /dev/null
+++ b/configs/distill/wan_t2v_distill_4step_cfg_4090.json
@@ -0,0 +1,30 @@
+{
+ "infer_steps": 4,
+ "target_video_length": 81,
+ "text_len": 512,
+ "target_height": 480,
+ "target_width": 832,
+ "self_attn_1_type": "sage_attn2",
+ "cross_attn_1_type": "sage_attn2",
+ "cross_attn_2_type": "sage_attn2",
+ "sample_guide_scale": 6,
+ "sample_shift": 5,
+ "enable_cfg": false,
+ "cpu_offload": true,
+ "offload_granularity": "block",
+ "t5_cpu_offload": false,
+ "vae_cpu_offload": false,
+ "clip_cpu_offload": false,
+ "denoising_step_list": [
+ 1000,
+ 750,
+ 500,
+ 250
+ ],
+ "dit_quantized": true,
+ "dit_quant_scheme": "fp8-q8f",
+ "t5_quantized": true,
+ "t5_quant_scheme": "fp8-q8f",
+ "clip_quantized": true,
+ "clip_quant_scheme": "fp8-q8f"
+}
diff --git a/configs/distill/wan_t2v_distill_4step_cfg_dynamic.json b/configs/distill/wan_t2v_distill_4step_cfg_dynamic.json
new file mode 100644
index 0000000000000000000000000000000000000000..f05e7283308161084ab5280d32186c7ee06d9460
--- /dev/null
+++ b/configs/distill/wan_t2v_distill_4step_cfg_dynamic.json
@@ -0,0 +1,22 @@
+{
+ "infer_steps": 4,
+ "target_video_length": 81,
+ "text_len": 512,
+ "target_height": 480,
+ "target_width": 832,
+ "self_attn_1_type": "flash_attn3",
+ "cross_attn_1_type": "flash_attn3",
+ "cross_attn_2_type": "flash_attn3",
+ "sample_guide_scale": 6,
+ "sample_shift": 5,
+ "enable_cfg": false,
+ "enable_dynamic_cfg": true,
+ "cfg_scale": 4.0,
+ "cpu_offload": false,
+ "denoising_step_list": [
+ 1000,
+ 750,
+ 500,
+ 250
+ ]
+}
diff --git a/configs/distill/wan_t2v_distill_4step_cfg_lora.json b/configs/distill/wan_t2v_distill_4step_cfg_lora.json
new file mode 100644
index 0000000000000000000000000000000000000000..0388af4dd0c11cc2e7bd0c3668608e3ac9a2e946
--- /dev/null
+++ b/configs/distill/wan_t2v_distill_4step_cfg_lora.json
@@ -0,0 +1,21 @@
+{
+ "infer_steps": 4,
+ "target_video_length": 81,
+ "text_len": 512,
+ "target_height": 480,
+ "target_width": 832,
+ "self_attn_1_type": "flash_attn3",
+ "cross_attn_1_type": "flash_attn3",
+ "cross_attn_2_type": "flash_attn3",
+ "sample_guide_scale": 6,
+ "sample_shift": 5,
+ "enable_cfg": false,
+ "cpu_offload": false,
+ "denoising_step_list": [1000, 750, 500, 250],
+ "lora_configs": [
+ {
+ "path": "lightx2v/Wan2.1-Distill-Loras/wan2.1_t2v_14b_lora_rank64_lightx2v_4step.safetensors",
+ "strength": 1.0
+ }
+ ]
+}
diff --git a/configs/distill/wan_t2v_distill_4step_cfg_lora_4090.json b/configs/distill/wan_t2v_distill_4step_cfg_lora_4090.json
new file mode 100644
index 0000000000000000000000000000000000000000..5e87e18fdb3303202cb1e943785b15f728f42f88
--- /dev/null
+++ b/configs/distill/wan_t2v_distill_4step_cfg_lora_4090.json
@@ -0,0 +1,36 @@
+{
+ "infer_steps": 4,
+ "target_video_length": 81,
+ "text_len": 512,
+ "target_height": 480,
+ "target_width": 832,
+ "self_attn_1_type": "sage_attn2",
+ "cross_attn_1_type": "sage_attn2",
+ "cross_attn_2_type": "sage_attn2",
+ "sample_guide_scale": 6,
+ "sample_shift": 5,
+ "enable_cfg": false,
+ "cpu_offload": true,
+ "offload_granularity": "block",
+ "t5_cpu_offload": false,
+ "vae_cpu_offload": false,
+ "clip_cpu_offload": false,
+ "denoising_step_list": [
+ 1000,
+ 750,
+ 500,
+ 250
+ ],
+ "dit_quantized": true,
+ "dit_quant_scheme": "fp8-q8f",
+ "t5_quantized": true,
+ "t5_quant_scheme": "fp8-q8f",
+ "clip_quantized": true,
+ "clip_quant_scheme": "fp8-q8f",
+ "lora_configs": [
+ {
+ "path": "lightx2v/Wan2.1-Distill-Loras/wan2.1_t2v_14b_lora_rank64_lightx2v_4step.safetensors",
+ "strength": 1.0
+ }
+ ]
+}
diff --git a/configs/hunyuan_video_15/4090/hy15_t2v_480p_bf16.json b/configs/hunyuan_video_15/4090/hy15_t2v_480p_bf16.json
new file mode 100644
index 0000000000000000000000000000000000000000..ce108bbdce5d95a17bc39768648ec2f106b61fd9
--- /dev/null
+++ b/configs/hunyuan_video_15/4090/hy15_t2v_480p_bf16.json
@@ -0,0 +1,18 @@
+{
+ "infer_steps": 50,
+ "transformer_model_name": "480p_t2v",
+ "fps": 24,
+ "target_video_length": 121,
+ "aspect_ratio": "16:9",
+ "vae_stride": [4, 16, 16],
+ "sample_shift": 5.0,
+ "sample_guide_scale": 6.0,
+ "enable_cfg": true,
+ "attn_type": "sage_attn2",
+ "cpu_offload": true,
+ "offload_granularity": "block",
+ "vae_cpu_offload": false,
+ "byt5_cpu_offload": false,
+ "qwen25vl_cpu_offload": true,
+ "siglip_cpu_offload": false
+}
diff --git a/configs/hunyuan_video_15/4090/hy15_t2v_480p_bf16_dist.json b/configs/hunyuan_video_15/4090/hy15_t2v_480p_bf16_dist.json
new file mode 100644
index 0000000000000000000000000000000000000000..8049eda8d56f7eaa6fd0c52b5509c14a1fda38c9
--- /dev/null
+++ b/configs/hunyuan_video_15/4090/hy15_t2v_480p_bf16_dist.json
@@ -0,0 +1,16 @@
+{
+ "infer_steps": 50,
+ "transformer_model_name": "480p_t2v",
+ "fps": 24,
+ "target_video_length": 121,
+ "aspect_ratio": "16:9",
+ "vae_stride": [4, 16, 16],
+ "sample_shift": 7.0,
+ "sample_guide_scale": 6.0,
+ "enable_cfg": true,
+ "attn_type": "sage_attn2",
+ "parallel": {
+ "seq_p_attn_type": "ulysses-4090",
+ "seq_p_size": 8
+ }
+}
diff --git a/configs/hunyuan_video_15/4090/hy15_t2v_480p_fp8.json b/configs/hunyuan_video_15/4090/hy15_t2v_480p_fp8.json
new file mode 100644
index 0000000000000000000000000000000000000000..6096bf90a780e3f1eae249d4b5984071c2fbebf6
--- /dev/null
+++ b/configs/hunyuan_video_15/4090/hy15_t2v_480p_fp8.json
@@ -0,0 +1,24 @@
+{
+ "infer_steps": 50,
+ "transformer_model_name": "480p_t2v",
+ "fps": 24,
+ "target_video_length": 121,
+ "aspect_ratio": "16:9",
+ "vae_stride": [4, 16, 16],
+ "sample_shift": 5.0,
+ "sample_guide_scale": 6.0,
+ "enable_cfg": true,
+ "attn_type": "sage_attn2",
+ "cpu_offload": true,
+ "offload_granularity": "block",
+ "vae_cpu_offload": false,
+ "byt5_cpu_offload": false,
+ "qwen25vl_cpu_offload": true,
+ "siglip_cpu_offload": false,
+ "dit_quantized_ckpt": "/path/to/480p_t2v_fp8.safetensors",
+ "dit_quantized": true,
+ "dit_quant_scheme": "fp8-q8f",
+ "qwen25vl_quantized_ckpt": "/path/to/qwen25vl_fp8.safetensors",
+ "qwen25vl_quantized": true,
+ "qwen25vl_quant_scheme": "fp8-q8f"
+}
diff --git a/configs/hunyuan_video_15/5090/hy15_t2v_480p_bf16.json b/configs/hunyuan_video_15/5090/hy15_t2v_480p_bf16.json
new file mode 100644
index 0000000000000000000000000000000000000000..2668b2b0b42c937837bbf8a2ce96924e450eae65
--- /dev/null
+++ b/configs/hunyuan_video_15/5090/hy15_t2v_480p_bf16.json
@@ -0,0 +1,18 @@
+{
+ "infer_steps": 50,
+ "transformer_model_name": "480p_t2v",
+ "fps": 24,
+ "target_video_length": 121,
+ "aspect_ratio": "16:9",
+ "vae_stride": [4, 16, 16],
+ "sample_shift": 5.0,
+ "sample_guide_scale": 6.0,
+ "enable_cfg": true,
+ "attn_type": "sage_attn3",
+ "cpu_offload": true,
+ "offload_granularity": "block",
+ "vae_cpu_offload": false,
+ "byt5_cpu_offload": false,
+ "qwen25vl_cpu_offload": true,
+ "siglip_cpu_offload": false
+}
diff --git a/configs/hunyuan_video_15/5090/hy15_t2v_480p_bf16_dist.json b/configs/hunyuan_video_15/5090/hy15_t2v_480p_bf16_dist.json
new file mode 100644
index 0000000000000000000000000000000000000000..d39a77310efddbca9a3361e00cf1856cbe812108
--- /dev/null
+++ b/configs/hunyuan_video_15/5090/hy15_t2v_480p_bf16_dist.json
@@ -0,0 +1,22 @@
+{
+ "infer_steps": 50,
+ "transformer_model_name": "480p_t2v",
+ "fps": 24,
+ "target_video_length": 121,
+ "aspect_ratio": "16:9",
+ "vae_stride": [4, 16, 16],
+ "sample_shift": 5.0,
+ "sample_guide_scale": 6.0,
+ "enable_cfg": true,
+ "attn_type": "sage_attn3",
+ "cpu_offload": true,
+ "offload_granularity": "block",
+ "vae_cpu_offload": false,
+ "byt5_cpu_offload": false,
+ "qwen25vl_cpu_offload": true,
+ "siglip_cpu_offload": false,
+ "parallel": {
+ "seq_p_attn_type": "ulysses",
+ "seq_p_size": 8
+ }
+}
diff --git a/configs/hunyuan_video_15/5090/hy15_t2v_480p_fp8.json b/configs/hunyuan_video_15/5090/hy15_t2v_480p_fp8.json
new file mode 100644
index 0000000000000000000000000000000000000000..303adcd24821b3fd89bf2abd45df35b7498e5aca
--- /dev/null
+++ b/configs/hunyuan_video_15/5090/hy15_t2v_480p_fp8.json
@@ -0,0 +1,19 @@
+{
+ "infer_steps": 50,
+ "transformer_model_name": "480p_t2v",
+ "fps": 24,
+ "target_video_length": 121,
+ "aspect_ratio": "16:9",
+ "vae_stride": [4, 16, 16],
+ "sample_shift": 5.0,
+ "sample_guide_scale": 6.0,
+ "enable_cfg": true,
+ "attn_type": "sage_attn3",
+ "qwen25vl_cpu_offload": true,
+ "dit_quantized_ckpt": "/path/to/480p_t2v_fp8.safetensors",
+ "dit_quantized": true,
+ "dit_quant_scheme": "fp8-sgl",
+ "qwen25vl_quantized_ckpt": "/path/to/qwen25vl_fp8.safetensors",
+ "qwen25vl_quantized": true,
+ "qwen25vl_quant_scheme": "fp8-sgl"
+}
diff --git a/configs/hunyuan_video_15/cache/hy_15_i2v_480p_magcache.json b/configs/hunyuan_video_15/cache/hy_15_i2v_480p_magcache.json
new file mode 100644
index 0000000000000000000000000000000000000000..91fe4b27c668bc1f4512a793bb158394a8ff472d
--- /dev/null
+++ b/configs/hunyuan_video_15/cache/hy_15_i2v_480p_magcache.json
@@ -0,0 +1,17 @@
+{
+ "infer_steps": 50,
+ "transformer_model_name": "480p_i2v",
+ "fps": 24,
+ "target_video_length": 121,
+ "vae_stride": [4, 16, 16],
+ "sample_shift": 5.0,
+ "sample_guide_scale": 6.0,
+ "enable_cfg": true,
+ "attn_type": "sage_attn2",
+ "feature_caching": "Mag",
+ "magcache_calibration": false,
+ "magcache_K": 6,
+ "magcache_thresh": 0.24,
+ "magcache_retention_ratio": 0.2,
+ "magcache_ratios": [[1.0, 1.01562, 1.00781, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 0.99609, 1.0, 0.99609, 1.0, 0.99609, 1.0, 0.99609, 0.99609, 0.99609, 0.99609, 0.99609, 0.99609, 0.99609, 0.99609, 0.99609, 0.99609, 0.99609, 0.99609, 0.99609, 0.99609, 0.99219, 0.99219, 0.99219, 0.98828, 0.98828, 0.98828, 0.98828, 0.98438, 0.98438, 0.98047, 0.98047, 0.97656, 0.97266, 0.96484, 0.95703, 0.94922, 0.92969, 0.91016, 0.88672], [1.0, 1.02344, 1.00781, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 0.99609, 1.0, 0.99609, 1.0, 0.99609, 1.0, 0.99609, 0.99609, 0.99609, 0.99609, 0.99609, 0.99609, 0.99609, 0.99609, 0.99609, 0.99609, 0.99609, 0.99609, 0.99609, 0.99609, 0.99219, 0.99219, 0.99219, 0.99219, 0.98828, 0.98828, 0.98828, 0.98438, 0.98438, 0.98047, 0.98047, 0.97656, 0.97266, 0.96484, 0.95703, 0.94922, 0.93359, 0.91016, 0.88672]]
+}
diff --git a/configs/hunyuan_video_15/cache/hy_15_i2v_480p_magcache_calibration.json b/configs/hunyuan_video_15/cache/hy_15_i2v_480p_magcache_calibration.json
new file mode 100644
index 0000000000000000000000000000000000000000..ba180071145dccc2617387780b9d091188e9dd4e
--- /dev/null
+++ b/configs/hunyuan_video_15/cache/hy_15_i2v_480p_magcache_calibration.json
@@ -0,0 +1,13 @@
+{
+ "infer_steps": 50,
+ "transformer_model_name": "480p_i2v",
+ "fps": 24,
+ "target_video_length": 121,
+ "vae_stride": [4, 16, 16],
+ "sample_shift": 5.0,
+ "sample_guide_scale": 6.0,
+ "enable_cfg": true,
+ "attn_type": "sage_attn2",
+ "feature_caching": "Mag",
+ "magcache_calibration": true
+}
diff --git a/configs/hunyuan_video_15/cache/hy_15_i2v_480p_teacache.json b/configs/hunyuan_video_15/cache/hy_15_i2v_480p_teacache.json
new file mode 100644
index 0000000000000000000000000000000000000000..6872b0b2048a12b6b975133ee59e7f9cdea284df
--- /dev/null
+++ b/configs/hunyuan_video_15/cache/hy_15_i2v_480p_teacache.json
@@ -0,0 +1,20 @@
+{
+ "infer_steps": 50,
+ "transformer_model_name": "480p_i2v",
+ "fps": 24,
+ "target_video_length": 121,
+ "vae_stride": [4, 16, 16],
+ "sample_shift": 5.0,
+ "sample_guide_scale": 6.0,
+ "enable_cfg": true,
+ "attn_type": "flash_attn3",
+ "feature_caching": "Tea",
+ "coefficients": [8.08528429e+03 ,-2.44607178e+03, 2.49489589e+02, -9.10697865e+00, 1.20261379e-01],
+ "teacache_thresh": 0.15,
+ "cpu_offload": false,
+ "offload_granularity": "block",
+ "vae_cpu_offload": false,
+ "byt5_cpu_offload": false,
+ "qwen25vl_cpu_offload": true,
+ "siglip_cpu_offload": false
+}
diff --git a/configs/hunyuan_video_15/cache/hy_15_i2v_720p_teacache.json b/configs/hunyuan_video_15/cache/hy_15_i2v_720p_teacache.json
new file mode 100644
index 0000000000000000000000000000000000000000..252a80b9b3fdb57e4db219506631e56c27ffa98f
--- /dev/null
+++ b/configs/hunyuan_video_15/cache/hy_15_i2v_720p_teacache.json
@@ -0,0 +1,20 @@
+{
+ "infer_steps": 50,
+ "transformer_model_name": "720p_i2v",
+ "fps": 24,
+ "target_video_length": 121,
+ "vae_stride": [4, 16, 16],
+ "sample_shift": 7.0,
+ "sample_guide_scale": 6.0,
+ "enable_cfg": true,
+ "attn_type": "flash_attn3",
+ "feature_caching": "Tea",
+ "coefficients": [3.84300014e+03, -1.39247433e+03, 1.69167679e+02, -7.07679232e+00, 1.02419011e-01],
+ "teacache_thresh": 0.15,
+ "cpu_offload": false,
+ "offload_granularity": "block",
+ "vae_cpu_offload": false,
+ "byt5_cpu_offload": false,
+ "qwen25vl_cpu_offload": true,
+ "siglip_cpu_offload": false
+}
diff --git a/configs/hunyuan_video_15/cache/hy_15_t2v_480p_teacache.json b/configs/hunyuan_video_15/cache/hy_15_t2v_480p_teacache.json
new file mode 100644
index 0000000000000000000000000000000000000000..d2925d37deb8b0c068ace1f1b3b3bb8f38760bff
--- /dev/null
+++ b/configs/hunyuan_video_15/cache/hy_15_t2v_480p_teacache.json
@@ -0,0 +1,20 @@
+{
+ "infer_steps": 50,
+ "transformer_model_name": "480p_t2v",
+ "fps": 24,
+ "target_video_length": 121,
+ "vae_stride": [4, 16, 16],
+ "sample_shift": 5.0,
+ "sample_guide_scale": 6.0,
+ "enable_cfg": true,
+ "attn_type": "flash_attn3",
+ "feature_caching": "Tea",
+ "coefficients": [-2.97190924e+04, 2.22834983e+04, -4.37418360e+03, 3.39340251e+02, -1.01365855e+01, 1.29101768e-01],
+ "teacache_thresh": 0.15,
+ "cpu_offload": false,
+ "offload_granularity": "block",
+ "vae_cpu_offload": false,
+ "byt5_cpu_offload": false,
+ "qwen25vl_cpu_offload": true,
+ "siglip_cpu_offload": false
+}
diff --git a/configs/hunyuan_video_15/cache/hy_15_t2v_720p_teacache.json b/configs/hunyuan_video_15/cache/hy_15_t2v_720p_teacache.json
new file mode 100644
index 0000000000000000000000000000000000000000..97b24eac3dd07ae1047b20ea60fcef36fd021a40
--- /dev/null
+++ b/configs/hunyuan_video_15/cache/hy_15_t2v_720p_teacache.json
@@ -0,0 +1,20 @@
+{
+ "infer_steps": 50,
+ "transformer_model_name": "729p_t2v",
+ "fps": 24,
+ "target_video_length": 121,
+ "vae_stride": [4, 16, 16],
+ "sample_shift": 5.0,
+ "sample_guide_scale": 6.0,
+ "enable_cfg": true,
+ "attn_type": "flash_attn3",
+ "feature_caching": "Tea",
+ "coefficients": [-3.08907507e+04, 1.67786188e+04, -3.19178643e+03, 2.60740519e+02, -8.19205881e+00, 1.07913775e-01],
+ "teacache_thresh": 0.15,
+ "cpu_offload": false,
+ "offload_granularity": "block",
+ "vae_cpu_offload": false,
+ "byt5_cpu_offload": false,
+ "qwen25vl_cpu_offload": true,
+ "siglip_cpu_offload": false
+}
diff --git a/configs/hunyuan_video_15/fp8comm/hy15_i2v_480p_int8_offload_dist_fp8_comm.json b/configs/hunyuan_video_15/fp8comm/hy15_i2v_480p_int8_offload_dist_fp8_comm.json
new file mode 100644
index 0000000000000000000000000000000000000000..a9fc93364e7dbaaec0e8acef4804dcf13ed499c9
--- /dev/null
+++ b/configs/hunyuan_video_15/fp8comm/hy15_i2v_480p_int8_offload_dist_fp8_comm.json
@@ -0,0 +1,23 @@
+{
+ "infer_steps": 50,
+ "transformer_model_name": "480p_i2v",
+ "fps": 24,
+ "target_video_length": 121,
+ "vae_stride": [4, 16, 16],
+ "sample_shift": 5.0,
+ "sample_guide_scale": 6.0,
+ "enable_cfg": false,
+ "attn_type": "sage_attn3",
+ "vae_cpu_offload": false,
+ "byt5_cpu_offload": false,
+ "qwen25vl_cpu_offload": true,
+ "siglip_cpu_offload": false,
+ "dit_quantized_ckpt": "/path/to/quant_model.safetensors",
+ "dit_quantized": true,
+ "dit_quant_scheme": "int8-q8f",
+ "parallel": {
+ "seq_p_size": 8,
+ "seq_p_fp8_comm": true,
+ "seq_p_attn_type": "ulysses"
+ }
+}
diff --git a/configs/hunyuan_video_15/hunyuan_video_i2v_480p.json b/configs/hunyuan_video_15/hunyuan_video_i2v_480p.json
new file mode 100644
index 0000000000000000000000000000000000000000..32624592b19679d3dc50e2d8baf236232cbe2f57
--- /dev/null
+++ b/configs/hunyuan_video_15/hunyuan_video_i2v_480p.json
@@ -0,0 +1,11 @@
+{
+ "infer_steps": 50,
+ "transformer_model_name": "480p_i2v",
+ "fps": 24,
+ "target_video_length": 121,
+ "vae_stride": [4, 16, 16],
+ "sample_shift": 5.0,
+ "sample_guide_scale": 6.0,
+ "enable_cfg": true,
+ "attn_type": "sage_attn2"
+}
diff --git a/configs/hunyuan_video_15/hunyuan_video_i2v_720p.json b/configs/hunyuan_video_15/hunyuan_video_i2v_720p.json
new file mode 100644
index 0000000000000000000000000000000000000000..f993a5caeeb347c5e612aac024fc374e9b18c817
--- /dev/null
+++ b/configs/hunyuan_video_15/hunyuan_video_i2v_720p.json
@@ -0,0 +1,11 @@
+{
+ "infer_steps": 50,
+ "transformer_model_name": "720p_i2v",
+ "fps": 24,
+ "target_video_length": 121,
+ "vae_stride": [4, 16, 16],
+ "sample_shift": 7.0,
+ "sample_guide_scale": 6.0,
+ "enable_cfg": true,
+ "attn_type": "sage_attn2"
+}
diff --git a/configs/hunyuan_video_15/hunyuan_video_i2v_720p_cfg_distilled.json b/configs/hunyuan_video_15/hunyuan_video_i2v_720p_cfg_distilled.json
new file mode 100644
index 0000000000000000000000000000000000000000..a467d446b0071724c928c7583444b7da9614cfe0
--- /dev/null
+++ b/configs/hunyuan_video_15/hunyuan_video_i2v_720p_cfg_distilled.json
@@ -0,0 +1,11 @@
+{
+ "infer_steps": 50,
+ "transformer_model_name": "720p_i2v_distilled",
+ "fps": 24,
+ "target_video_length": 121,
+ "vae_stride": [4, 16, 16],
+ "sample_shift": 9.0,
+ "sample_guide_scale": 6.0,
+ "enable_cfg": false,
+ "attn_type": "sage_attn2"
+}
diff --git a/configs/hunyuan_video_15/hunyuan_video_t2v_480p.json b/configs/hunyuan_video_15/hunyuan_video_t2v_480p.json
new file mode 100644
index 0000000000000000000000000000000000000000..28ca4b9d6cf1da8530a4a17333942342b913ec90
--- /dev/null
+++ b/configs/hunyuan_video_15/hunyuan_video_t2v_480p.json
@@ -0,0 +1,12 @@
+{
+ "infer_steps": 50,
+ "transformer_model_name": "480p_t2v",
+ "fps": 24,
+ "target_video_length": 121,
+ "aspect_ratio": "16:9",
+ "vae_stride": [4, 16, 16],
+ "sample_shift": 5.0,
+ "sample_guide_scale": 6.0,
+ "enable_cfg": true,
+ "attn_type": "sage_attn2"
+}
diff --git a/configs/hunyuan_video_15/hunyuan_video_t2v_480p_distill.json b/configs/hunyuan_video_15/hunyuan_video_t2v_480p_distill.json
new file mode 100644
index 0000000000000000000000000000000000000000..f4d9ceb734956865d5a90a1cb30bdfe18a130f2a
--- /dev/null
+++ b/configs/hunyuan_video_15/hunyuan_video_t2v_480p_distill.json
@@ -0,0 +1,19 @@
+{
+ "infer_steps": 4,
+ "transformer_model_name": "480p_t2v",
+ "fps": 16,
+ "target_video_length": 81,
+ "aspect_ratio": "16:9",
+ "vae_stride": [4, 16, 16],
+ "sample_shift": 5.0,
+ "sample_guide_scale": -1.0,
+ "enable_cfg": false,
+ "attn_type": "sage_attn2",
+ "dit_original_ckpt": "hunyuanvideo-1.5/distill_models/480p_t2v/distill_model.safetensors",
+ "denoising_step_list": [
+ 1000,
+ 750,
+ 500,
+ 250
+ ]
+}
diff --git a/configs/hunyuan_video_15/hunyuan_video_t2v_720p.json b/configs/hunyuan_video_15/hunyuan_video_t2v_720p.json
new file mode 100644
index 0000000000000000000000000000000000000000..f8923c1520129693bbfcd0e92396014b357b2995
--- /dev/null
+++ b/configs/hunyuan_video_15/hunyuan_video_t2v_720p.json
@@ -0,0 +1,12 @@
+{
+ "infer_steps": 50,
+ "transformer_model_name": "720p_t2v",
+ "fps": 24,
+ "target_video_length": 121,
+ "aspect_ratio": "16:9",
+ "vae_stride": [4, 16, 16],
+ "sample_shift": 9.0,
+ "sample_guide_scale": 6.0,
+ "enable_cfg": true,
+ "attn_type": "sage_attn2"
+}
diff --git a/configs/hunyuan_video_15/lightae/hy15_t2v_480p_bf16.json b/configs/hunyuan_video_15/lightae/hy15_t2v_480p_bf16.json
new file mode 100644
index 0000000000000000000000000000000000000000..6fc26bdb0e4ce8009fb72d66e480d720cb00f138
--- /dev/null
+++ b/configs/hunyuan_video_15/lightae/hy15_t2v_480p_bf16.json
@@ -0,0 +1,14 @@
+{
+ "infer_steps": 50,
+ "transformer_model_name": "480p_t2v",
+ "fps": 24,
+ "target_video_length": 121,
+ "aspect_ratio": "16:9",
+ "vae_stride": [4, 16, 16],
+ "sample_shift": 7.0,
+ "sample_guide_scale": 6.0,
+ "enable_cfg": true,
+ "attn_type": "flash_attn3",
+ "use_tae": true,
+ "tae_path": "/path/to/lighttae"
+}
diff --git a/configs/hunyuan_video_15/offload/hy15_t2v_480p_bf16.json b/configs/hunyuan_video_15/offload/hy15_t2v_480p_bf16.json
new file mode 100644
index 0000000000000000000000000000000000000000..1055492b1922da21c4efb9c096f5d14e31c9c96e
--- /dev/null
+++ b/configs/hunyuan_video_15/offload/hy15_t2v_480p_bf16.json
@@ -0,0 +1,18 @@
+{
+ "infer_steps": 50,
+ "transformer_model_name": "480p_t2v",
+ "fps": 24,
+ "target_video_length": 121,
+ "aspect_ratio": "16:9",
+ "vae_stride": [4, 16, 16],
+ "sample_shift": 7.0,
+ "sample_guide_scale": 6.0,
+ "enable_cfg": true,
+ "attn_type": "sage_attn2",
+ "cpu_offload": true,
+ "offload_granularity": "block",
+ "vae_cpu_offload": false,
+ "byt5_cpu_offload": false,
+ "qwen25vl_cpu_offload": true,
+ "siglip_cpu_offload": false
+}
diff --git a/configs/hunyuan_video_15/quant/hy15_t2v_480p_fp8.json b/configs/hunyuan_video_15/quant/hy15_t2v_480p_fp8.json
new file mode 100644
index 0000000000000000000000000000000000000000..196a5b7eccfa5536daf34abd0aff5935498c0a9a
--- /dev/null
+++ b/configs/hunyuan_video_15/quant/hy15_t2v_480p_fp8.json
@@ -0,0 +1,15 @@
+{
+ "infer_steps": 50,
+ "transformer_model_name": "480p_t2v",
+ "fps": 24,
+ "target_video_length": 121,
+ "aspect_ratio": "16:9",
+ "vae_stride": [4, 16, 16],
+ "sample_shift": 7.0,
+ "sample_guide_scale": 6.0,
+ "enable_cfg": true,
+ "attn_type": "flash_attn3",
+ "dit_quantized_ckpt": "/path/to/quant_model.safetensors",
+ "dit_quantized": true,
+ "dit_quant_scheme": "fp8-sgl"
+}
diff --git a/configs/hunyuan_video_15/vsr/hy15_i2v_480p.json b/configs/hunyuan_video_15/vsr/hy15_i2v_480p.json
new file mode 100644
index 0000000000000000000000000000000000000000..4f774fff6b1380d224e838b7403ee79e1428492e
--- /dev/null
+++ b/configs/hunyuan_video_15/vsr/hy15_i2v_480p.json
@@ -0,0 +1,19 @@
+{
+ "infer_steps": 50,
+ "transformer_model_name": "480p_i2v",
+ "fps": 24,
+ "target_video_length": 121,
+ "vae_stride": [4, 16, 16],
+ "sample_shift": 5.0,
+ "sample_guide_scale": 6.0,
+ "enable_cfg": true,
+ "attn_type": "flash_attn3",
+ "video_super_resolution": {
+ "sr_version": "720p_sr_distilled",
+ "flow_shift": 2.0,
+ "base_resolution": "480p",
+ "guidance_scale": 1.0,
+ "num_inference_steps": 6,
+ "use_meanflow": true
+ }
+}
diff --git a/configs/matrix_game2/matrix_game2_gta_drive.json b/configs/matrix_game2/matrix_game2_gta_drive.json
new file mode 100644
index 0000000000000000000000000000000000000000..d1952d813a4f56557f55d588a7414f18599595fa
--- /dev/null
+++ b/configs/matrix_game2/matrix_game2_gta_drive.json
@@ -0,0 +1,72 @@
+{
+ "infer_steps": 50,
+ "target_video_length": 150,
+ "num_output_frames": 150,
+ "text_len": 512,
+ "target_height": 352,
+ "target_width": 640,
+ "self_attn_1_type": "flash_attn2",
+ "cross_attn_1_type": "flash_attn2",
+ "cross_attn_2_type": "flash_attn2",
+ "seed": 0,
+ "sample_guide_scale": 6,
+ "sample_shift": 8,
+ "enable_cfg": false,
+ "cpu_offload": false,
+ "sf_config": {
+ "local_attn_size": 6,
+ "shift": 5.0,
+ "num_frame_per_block": 3,
+ "num_transformer_blocks": 30,
+ "frame_seq_length": 880,
+ "num_output_frames": 150,
+ "num_inference_steps": 1000,
+ "denoising_step_list": [1000.0000, 908.8427, 713.9794]
+ },
+ "sub_model_folder": "gta_distilled_model",
+ "sub_model_name": "gta_keyboard2dim.safetensors",
+ "mode": "gta_drive",
+ "streaming": false,
+ "action_config": {
+ "blocks": [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14],
+ "enable_keyboard": true,
+ "enable_mouse": true,
+ "heads_num": 16,
+ "hidden_size": 128,
+ "img_hidden_size": 1536,
+ "keyboard_dim_in": 4,
+ "keyboard_hidden_dim": 1024,
+ "mouse_dim_in": 2,
+ "mouse_hidden_dim": 1024,
+ "mouse_qk_dim_list": [
+ 8,
+ 28,
+ 28
+ ],
+ "patch_size": [
+ 1,
+ 2,
+ 2
+ ],
+ "qk_norm": true,
+ "qkv_bias": false,
+ "rope_dim_list": [
+ 8,
+ 28,
+ 28
+ ],
+ "rope_theta": 256,
+ "vae_time_compression_ratio": 4,
+ "windows_size": 3
+ },
+ "dim": 1536,
+ "eps": 1e-06,
+ "ffn_dim": 8960,
+ "freq_dim": 256,
+ "in_dim": 36,
+ "inject_sample_info": false,
+ "model_type": "i2v",
+ "num_heads": 12,
+ "num_layers": 30,
+ "out_dim": 16
+}
diff --git a/configs/matrix_game2/matrix_game2_gta_drive_streaming.json b/configs/matrix_game2/matrix_game2_gta_drive_streaming.json
new file mode 100644
index 0000000000000000000000000000000000000000..584eab096d7c8c380d927c8518996c48f02c1119
--- /dev/null
+++ b/configs/matrix_game2/matrix_game2_gta_drive_streaming.json
@@ -0,0 +1,72 @@
+{
+ "infer_steps": 50,
+ "target_video_length": 360,
+ "num_output_frames": 360,
+ "text_len": 512,
+ "target_height": 352,
+ "target_width": 640,
+ "self_attn_1_type": "flash_attn2",
+ "cross_attn_1_type": "flash_attn2",
+ "cross_attn_2_type": "flash_attn2",
+ "seed": 0,
+ "sample_guide_scale": 6,
+ "sample_shift": 8,
+ "enable_cfg": false,
+ "cpu_offload": false,
+ "sf_config": {
+ "local_attn_size": 6,
+ "shift": 5.0,
+ "num_frame_per_block": 3,
+ "num_transformer_blocks": 30,
+ "frame_seq_length": 880,
+ "num_output_frames": 360,
+ "num_inference_steps": 1000,
+ "denoising_step_list": [1000.0000, 908.8427, 713.9794]
+ },
+ "sub_model_folder": "gta_distilled_model",
+ "sub_model_name": "gta_keyboard2dim.safetensors",
+ "mode": "gta_drive",
+ "streaming": true,
+ "action_config": {
+ "blocks": [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14],
+ "enable_keyboard": true,
+ "enable_mouse": true,
+ "heads_num": 16,
+ "hidden_size": 128,
+ "img_hidden_size": 1536,
+ "keyboard_dim_in": 4,
+ "keyboard_hidden_dim": 1024,
+ "mouse_dim_in": 2,
+ "mouse_hidden_dim": 1024,
+ "mouse_qk_dim_list": [
+ 8,
+ 28,
+ 28
+ ],
+ "patch_size": [
+ 1,
+ 2,
+ 2
+ ],
+ "qk_norm": true,
+ "qkv_bias": false,
+ "rope_dim_list": [
+ 8,
+ 28,
+ 28
+ ],
+ "rope_theta": 256,
+ "vae_time_compression_ratio": 4,
+ "windows_size": 3
+ },
+ "dim": 1536,
+ "eps": 1e-06,
+ "ffn_dim": 8960,
+ "freq_dim": 256,
+ "in_dim": 36,
+ "inject_sample_info": false,
+ "model_type": "i2v",
+ "num_heads": 12,
+ "num_layers": 30,
+ "out_dim": 16
+}
diff --git a/configs/matrix_game2/matrix_game2_templerun.json b/configs/matrix_game2/matrix_game2_templerun.json
new file mode 100644
index 0000000000000000000000000000000000000000..63f1aab5e4b5ff43535e6e2cf504beafd550f7a4
--- /dev/null
+++ b/configs/matrix_game2/matrix_game2_templerun.json
@@ -0,0 +1,65 @@
+{
+ "infer_steps": 50,
+ "target_video_length": 150,
+ "num_output_frames": 150,
+ "text_len": 512,
+ "target_height": 352,
+ "target_width": 640,
+ "self_attn_1_type": "flash_attn2",
+ "cross_attn_1_type": "flash_attn2",
+ "cross_attn_2_type": "flash_attn2",
+ "seed": 0,
+ "sample_guide_scale": 6,
+ "sample_shift": 8,
+ "enable_cfg": false,
+ "cpu_offload": false,
+ "sf_config": {
+ "local_attn_size": 6,
+ "shift": 5.0,
+ "num_frame_per_block": 3,
+ "num_transformer_blocks": 30,
+ "frame_seq_length": 880,
+ "num_output_frames": 150,
+ "num_inference_steps": 1000,
+ "denoising_step_list": [1000.0000, 908.8427, 713.9794]
+ },
+ "sub_model_folder": "templerun_distilled_model",
+ "sub_model_name": "templerun_7dim_onlykey.safetensors",
+ "mode": "templerun",
+ "streaming": false,
+ "action_config": {
+ "blocks": [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14],
+ "enable_keyboard": true,
+ "enable_mouse": false,
+ "heads_num": 16,
+ "hidden_size": 128,
+ "img_hidden_size": 1536,
+ "keyboard_dim_in": 7,
+ "keyboard_hidden_dim": 1024,
+ "patch_size": [
+ 1,
+ 2,
+ 2
+ ],
+ "qk_norm": true,
+ "qkv_bias": false,
+ "rope_dim_list": [
+ 8,
+ 28,
+ 28
+ ],
+ "rope_theta": 256,
+ "vae_time_compression_ratio": 4,
+ "windows_size": 3
+ },
+ "dim": 1536,
+ "eps": 1e-06,
+ "ffn_dim": 8960,
+ "freq_dim": 256,
+ "in_dim": 36,
+ "inject_sample_info": false,
+ "model_type": "i2v",
+ "num_heads": 12,
+ "num_layers": 30,
+ "out_dim": 16
+}
diff --git a/configs/matrix_game2/matrix_game2_templerun_streaming.json b/configs/matrix_game2/matrix_game2_templerun_streaming.json
new file mode 100644
index 0000000000000000000000000000000000000000..90fd2955856a5182c19deac209b9e87e789d8338
--- /dev/null
+++ b/configs/matrix_game2/matrix_game2_templerun_streaming.json
@@ -0,0 +1,72 @@
+{
+ "infer_steps": 50,
+ "target_video_length": 360,
+ "num_output_frames": 360,
+ "text_len": 512,
+ "target_height": 352,
+ "target_width": 640,
+ "self_attn_1_type": "flash_attn2",
+ "cross_attn_1_type": "flash_attn2",
+ "cross_attn_2_type": "flash_attn2",
+ "seed": 0,
+ "sample_guide_scale": 6,
+ "sample_shift": 8,
+ "enable_cfg": false,
+ "cpu_offload": false,
+ "sf_config": {
+ "local_attn_size": 6,
+ "shift": 5.0,
+ "num_frame_per_block": 3,
+ "num_transformer_blocks": 30,
+ "frame_seq_length": 880,
+ "num_output_frames": 360,
+ "num_inference_steps": 1000,
+ "denoising_step_list": [1000.0000, 908.8427, 713.9794]
+ },
+ "sub_model_folder": "templerun_distilled_model",
+ "sub_model_name": "templerun_7dim_onlykey.safetensors",
+ "mode": "templerun",
+ "streaming": true,
+ "action_config": {
+ "blocks": [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14],
+ "enable_keyboard": true,
+ "enable_mouse": true,
+ "heads_num": 16,
+ "hidden_size": 128,
+ "img_hidden_size": 1536,
+ "keyboard_dim_in": 4,
+ "keyboard_hidden_dim": 1024,
+ "mouse_dim_in": 2,
+ "mouse_hidden_dim": 1024,
+ "mouse_qk_dim_list": [
+ 8,
+ 28,
+ 28
+ ],
+ "patch_size": [
+ 1,
+ 2,
+ 2
+ ],
+ "qk_norm": true,
+ "qkv_bias": false,
+ "rope_dim_list": [
+ 8,
+ 28,
+ 28
+ ],
+ "rope_theta": 256,
+ "vae_time_compression_ratio": 4,
+ "windows_size": 3
+ },
+ "dim": 1536,
+ "eps": 1e-06,
+ "ffn_dim": 8960,
+ "freq_dim": 256,
+ "in_dim": 36,
+ "inject_sample_info": false,
+ "model_type": "i2v",
+ "num_heads": 12,
+ "num_layers": 30,
+ "out_dim": 16
+}
diff --git a/configs/matrix_game2/matrix_game2_universal.json b/configs/matrix_game2/matrix_game2_universal.json
new file mode 100644
index 0000000000000000000000000000000000000000..0b801d8492b19a9d7567534f775bb3804af53a1d
--- /dev/null
+++ b/configs/matrix_game2/matrix_game2_universal.json
@@ -0,0 +1,72 @@
+{
+ "infer_steps": 50,
+ "target_video_length": 150,
+ "num_output_frames": 150,
+ "text_len": 512,
+ "target_height": 352,
+ "target_width": 640,
+ "self_attn_1_type": "flash_attn2",
+ "cross_attn_1_type": "flash_attn2",
+ "cross_attn_2_type": "flash_attn2",
+ "seed": 0,
+ "sample_guide_scale": 6,
+ "sample_shift": 8,
+ "enable_cfg": false,
+ "cpu_offload": false,
+ "sf_config": {
+ "local_attn_size": 6,
+ "shift": 5.0,
+ "num_frame_per_block": 3,
+ "num_transformer_blocks": 30,
+ "frame_seq_length": 880,
+ "num_output_frames": 150,
+ "num_inference_steps": 1000,
+ "denoising_step_list": [1000.0000, 908.8427, 713.9794]
+ },
+ "sub_model_folder": "base_distilled_model",
+ "sub_model_name": "base_distill.safetensors",
+ "mode": "universal",
+ "streaming": false,
+ "action_config": {
+ "blocks": [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14],
+ "enable_keyboard": true,
+ "enable_mouse": true,
+ "heads_num": 16,
+ "hidden_size": 128,
+ "img_hidden_size": 1536,
+ "keyboard_dim_in": 4,
+ "keyboard_hidden_dim": 1024,
+ "mouse_dim_in": 2,
+ "mouse_hidden_dim": 1024,
+ "mouse_qk_dim_list": [
+ 8,
+ 28,
+ 28
+ ],
+ "patch_size": [
+ 1,
+ 2,
+ 2
+ ],
+ "qk_norm": true,
+ "qkv_bias": false,
+ "rope_dim_list": [
+ 8,
+ 28,
+ 28
+ ],
+ "rope_theta": 256,
+ "vae_time_compression_ratio": 4,
+ "windows_size": 3
+ },
+ "dim": 1536,
+ "eps": 1e-06,
+ "ffn_dim": 8960,
+ "freq_dim": 256,
+ "in_dim": 36,
+ "inject_sample_info": false,
+ "model_type": "i2v",
+ "num_heads": 12,
+ "num_layers": 30,
+ "out_dim": 16
+}
diff --git a/configs/matrix_game2/matrix_game2_universal_streaming.json b/configs/matrix_game2/matrix_game2_universal_streaming.json
new file mode 100644
index 0000000000000000000000000000000000000000..f2c4575a78dfe3fed7f02819ad6f70758b637866
--- /dev/null
+++ b/configs/matrix_game2/matrix_game2_universal_streaming.json
@@ -0,0 +1,72 @@
+{
+ "infer_steps": 50,
+ "target_video_length": 360,
+ "num_output_frames": 360,
+ "text_len": 512,
+ "target_height": 352,
+ "target_width": 640,
+ "self_attn_1_type": "flash_attn2",
+ "cross_attn_1_type": "flash_attn2",
+ "cross_attn_2_type": "flash_attn2",
+ "seed": 0,
+ "sample_guide_scale": 6,
+ "sample_shift": 8,
+ "enable_cfg": false,
+ "cpu_offload": false,
+ "sf_config": {
+ "local_attn_size": 6,
+ "shift": 5.0,
+ "num_frame_per_block": 3,
+ "num_transformer_blocks": 30,
+ "frame_seq_length": 880,
+ "num_output_frames": 360,
+ "num_inference_steps": 1000,
+ "denoising_step_list": [1000.0000, 908.8427, 713.9794]
+ },
+ "sub_model_folder": "base_distilled_model",
+ "sub_model_name": "base_distill.safetensors",
+ "mode": "universal",
+ "streaming": true,
+ "action_config": {
+ "blocks": [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14],
+ "enable_keyboard": true,
+ "enable_mouse": true,
+ "heads_num": 16,
+ "hidden_size": 128,
+ "img_hidden_size": 1536,
+ "keyboard_dim_in": 4,
+ "keyboard_hidden_dim": 1024,
+ "mouse_dim_in": 2,
+ "mouse_hidden_dim": 1024,
+ "mouse_qk_dim_list": [
+ 8,
+ 28,
+ 28
+ ],
+ "patch_size": [
+ 1,
+ 2,
+ 2
+ ],
+ "qk_norm": true,
+ "qkv_bias": false,
+ "rope_dim_list": [
+ 8,
+ 28,
+ 28
+ ],
+ "rope_theta": 256,
+ "vae_time_compression_ratio": 4,
+ "windows_size": 3
+ },
+ "dim": 1536,
+ "eps": 1e-06,
+ "ffn_dim": 8960,
+ "freq_dim": 256,
+ "in_dim": 36,
+ "inject_sample_info": false,
+ "model_type": "i2v",
+ "num_heads": 12,
+ "num_layers": 30,
+ "out_dim": 16
+}
diff --git a/configs/model_pipeline.json b/configs/model_pipeline.json
new file mode 100644
index 0000000000000000000000000000000000000000..7f2f62b0a4f9f360e03b7ce3969e46ec1d5c65df
--- /dev/null
+++ b/configs/model_pipeline.json
@@ -0,0 +1,179 @@
+{
+ "data":
+ {
+ "t2v": {
+ "wan2.1-1.3B": {
+ "single_stage": {
+ "pipeline": {
+ "inputs": [],
+ "outputs": ["output_video"]
+ }
+ },
+ "multi_stage": {
+ "text_encoder": {
+ "inputs": [],
+ "outputs": ["text_encoder_output"]
+ },
+ "dit": {
+ "inputs": ["text_encoder_output"],
+ "outputs": ["latents"]
+ },
+ "vae_decoder": {
+ "inputs": ["latents"],
+ "outputs": ["output_video"]
+ }
+ }
+ },
+ "self-forcing-dmd": {
+ "single_stage": {
+ "pipeline": {
+ "inputs": [],
+ "outputs": ["output_video"]
+ }
+ }
+ }
+ },
+ "i2v": {
+ "wan2.1-14B-480P": {
+ "single_stage": {
+ "pipeline": {
+ "inputs": ["input_image"],
+ "outputs": ["output_video"]
+ }
+ },
+ "multi_stage": {
+ "text_encoder": {
+ "inputs": ["input_image"],
+ "outputs": ["text_encoder_output"]
+ },
+ "image_encoder": {
+ "inputs": ["input_image"],
+ "outputs": ["clip_encoder_output"]
+ },
+ "vae_encoder": {
+ "inputs": ["input_image"],
+ "outputs": ["vae_encoder_output"]
+ },
+ "dit": {
+ "inputs": [
+ "clip_encoder_output",
+ "vae_encoder_output",
+ "text_encoder_output"
+ ],
+ "outputs": ["latents"]
+ },
+ "vae_decoder": {
+ "inputs": ["latents"],
+ "outputs": ["output_video"]
+ }
+ }
+ },
+ "matrix-game2-gta-drive": {
+ "single_stage": {
+ "pipeline": {
+ "inputs": ["input_image"],
+ "outputs": ["output_video"]
+ }
+ }
+ },
+ "matrix-game2-universal": {
+ "single_stage": {
+ "pipeline": {
+ "inputs": ["input_image"],
+ "outputs": ["output_video"]
+ }
+ }
+ },
+ "matrix-game2-templerun": {
+ "single_stage": {
+ "pipeline": {
+ "inputs": ["input_image"],
+ "outputs": ["output_video"]
+ }
+ }
+ }
+ },
+ "s2v": {
+ "SekoTalk": {
+ "single_stage": {
+ "pipeline": {
+ "inputs": ["input_image", "input_audio"],
+ "outputs": ["output_video"]
+ }
+ },
+ "multi_stage": {
+ "text_encoder": {
+ "inputs": ["input_image"],
+ "outputs": ["text_encoder_output"]
+ },
+ "image_encoder": {
+ "inputs": ["input_image"],
+ "outputs": ["clip_encoder_output"]
+ },
+ "vae_encoder": {
+ "inputs": ["input_image"],
+ "outputs": ["vae_encoder_output"]
+ },
+ "segment_dit": {
+ "inputs": [
+ "input_audio",
+ "clip_encoder_output",
+ "vae_encoder_output",
+ "text_encoder_output"
+ ],
+ "outputs": ["output_video"]
+ }
+ }
+ }
+ },
+ "animate": {
+ "wan2.2_animate": {
+ "single_stage": {
+ "pipeline": {
+ "inputs": ["input_image","input_video"],
+ "outputs": ["output_video"]
+ }
+ }
+ }
+ }
+
+ },
+ "meta": {
+ "special_types": {
+ "input_image": "IMAGE",
+ "input_audio": "AUDIO",
+ "input_video": "VIDEO",
+ "latents": "TENSOR",
+ "output_video": "VIDEO"
+ },
+ "model_name_inner_to_outer": {
+ "seko_talk": "SekoTalk"
+ },
+ "model_name_outer_to_inner": {},
+ "monitor": {
+ "subtask_created_timeout": 1800,
+ "subtask_pending_timeout": 1800,
+ "subtask_running_timeouts": {
+ "t2v-wan2.1-1.3B-multi_stage-dit": 300,
+ "t2v-wan2.1-1.3B-single_stage-pipeline": 300,
+ "t2v-self-forcing-dmd-single_stage-pipeline": 300,
+ "i2v-wan2.1-14B-480P-multi_stage-dit": 600,
+ "i2v-wan2.1-14B-480P-single_stage-pipeline": 600,
+ "i2v-SekoTalk-Distill-single_stage-pipeline": 3600,
+ "i2v-SekoTalk-Distill-multi_stage-segment_dit": 3600
+ },
+ "worker_avg_window": 20,
+ "worker_offline_timeout": 5,
+ "worker_min_capacity": 20,
+ "worker_min_cnt": 1,
+ "worker_max_cnt": 10,
+ "task_timeout": 3600,
+ "schedule_ratio_high": 0.25,
+ "schedule_ratio_low": 0.02,
+ "ping_timeout": 30,
+ "user_max_active_tasks": 3,
+ "user_max_daily_tasks": 100,
+ "user_visit_frequency": 0.05
+ }
+ }
+}
diff --git a/configs/offload/block/qwen_image_i2i_2509_block.json b/configs/offload/block/qwen_image_i2i_2509_block.json
new file mode 100644
index 0000000000000000000000000000000000000000..7859a0a71e918004a639dfcd4efc68eda4a85b67
--- /dev/null
+++ b/configs/offload/block/qwen_image_i2i_2509_block.json
@@ -0,0 +1,66 @@
+{
+ "batchsize": 1,
+ "num_channels_latents": 16,
+ "vae_scale_factor": 8,
+ "infer_steps": 40,
+ "guidance_embeds": false,
+ "num_images_per_prompt": 1,
+ "vae_latents_mean": [
+ -0.7571,
+ -0.7089,
+ -0.9113,
+ 0.1075,
+ -0.1745,
+ 0.9653,
+ -0.1517,
+ 1.5508,
+ 0.4134,
+ -0.0715,
+ 0.5517,
+ -0.3632,
+ -0.1922,
+ -0.9497,
+ 0.2503,
+ -0.2921
+ ],
+ "vae_latents_std": [
+ 2.8184,
+ 1.4541,
+ 2.3275,
+ 2.6558,
+ 1.2196,
+ 1.7708,
+ 2.6052,
+ 2.0743,
+ 3.2687,
+ 2.1526,
+ 2.8652,
+ 1.5579,
+ 1.6382,
+ 1.1253,
+ 2.8251,
+ 1.916
+ ],
+ "vae_z_dim": 16,
+ "feature_caching": "NoCaching",
+ "transformer_in_channels": 64,
+ "prompt_template_encode": "<|im_start|>system\nDescribe the key features of the input image (color, shape, size, texture, objects, background), then explain how the user's text instruction should alter or modify the image. Generate a new image that meets the user's requirements while maintaining consistency with the original input where appropriate.<|im_end|>\n<|im_start|>user\n{}<|im_end|>\n<|im_start|>assistant\n",
+ "prompt_template_encode_start_idx": 64,
+ "_auto_resize": true,
+ "num_layers": 60,
+ "attention_out_dim": 3072,
+ "attention_dim_head": 128,
+ "axes_dims_rope": [
+ 16,
+ 56,
+ 56
+ ],
+ "_comment_attn": "in [torch_sdpa, flash_attn3, sage_attn2]",
+ "attn_type": "sage_attn2",
+ "do_true_cfg": true,
+ "true_cfg_scale": 4.0,
+ "cpu_offload": true,
+ "offload_granularity": "block",
+ "CONDITION_IMAGE_SIZE": 147456,
+ "USE_IMAGE_ID_IN_PROMPT": true
+}
diff --git a/configs/offload/block/qwen_image_i2i_block.json b/configs/offload/block/qwen_image_i2i_block.json
new file mode 100644
index 0000000000000000000000000000000000000000..7153b4a37070914f5d73c4f3ab4a87cdcd988949
--- /dev/null
+++ b/configs/offload/block/qwen_image_i2i_block.json
@@ -0,0 +1,66 @@
+{
+ "batchsize": 1,
+ "num_channels_latents": 16,
+ "vae_scale_factor": 8,
+ "infer_steps": 50,
+ "guidance_embeds": false,
+ "num_images_per_prompt": 1,
+ "vae_latents_mean": [
+ -0.7571,
+ -0.7089,
+ -0.9113,
+ 0.1075,
+ -0.1745,
+ 0.9653,
+ -0.1517,
+ 1.5508,
+ 0.4134,
+ -0.0715,
+ 0.5517,
+ -0.3632,
+ -0.1922,
+ -0.9497,
+ 0.2503,
+ -0.2921
+ ],
+ "vae_latents_std": [
+ 2.8184,
+ 1.4541,
+ 2.3275,
+ 2.6558,
+ 1.2196,
+ 1.7708,
+ 2.6052,
+ 2.0743,
+ 3.2687,
+ 2.1526,
+ 2.8652,
+ 1.5579,
+ 1.6382,
+ 1.1253,
+ 2.8251,
+ 1.916
+ ],
+ "vae_z_dim": 16,
+ "feature_caching": "NoCaching",
+ "transformer_in_channels": 64,
+ "prompt_template_encode": "<|im_start|>system\nDescribe the key features of the input image (color, shape, size, texture, objects, background), then explain how the user's text instruction should alter or modify the image. Generate a new image that meets the user's requirements while maintaining consistency with the original input where appropriate.<|im_end|>\n<|im_start|>user\n{}<|im_end|>\n<|im_start|>assistant\n",
+ "prompt_template_encode_start_idx": 64,
+ "_auto_resize": true,
+ "num_layers": 60,
+ "attention_out_dim": 3072,
+ "attention_dim_head": 128,
+ "axes_dims_rope": [
+ 16,
+ 56,
+ 56
+ ],
+ "_comment_attn": "in [torch_sdpa, flash_attn3, sage_attn2]",
+ "attn_type": "flash_attn3",
+ "do_true_cfg": true,
+ "true_cfg_scale": 4.0,
+ "cpu_offload": true,
+ "offload_granularity": "block",
+ "CONDITION_IMAGE_SIZE": 1048576,
+ "USE_IMAGE_ID_IN_PROMPT": false
+}
diff --git a/configs/offload/block/qwen_image_t2i_block.json b/configs/offload/block/qwen_image_t2i_block.json
new file mode 100644
index 0000000000000000000000000000000000000000..5b6313fcad6338c255398ed94932b0de01489362
--- /dev/null
+++ b/configs/offload/block/qwen_image_t2i_block.json
@@ -0,0 +1,86 @@
+{
+ "batchsize": 1,
+ "_comment": "格式: '宽高比': [width, height]",
+ "aspect_ratios": {
+ "1:1": [
+ 1328,
+ 1328
+ ],
+ "16:9": [
+ 1664,
+ 928
+ ],
+ "9:16": [
+ 928,
+ 1664
+ ],
+ "4:3": [
+ 1472,
+ 1140
+ ],
+ "3:4": [
+ 142,
+ 184
+ ]
+ },
+ "aspect_ratio": "16:9",
+ "num_channels_latents": 16,
+ "vae_scale_factor": 8,
+ "infer_steps": 50,
+ "guidance_embeds": false,
+ "num_images_per_prompt": 1,
+ "vae_latents_mean": [
+ -0.7571,
+ -0.7089,
+ -0.9113,
+ 0.1075,
+ -0.1745,
+ 0.9653,
+ -0.1517,
+ 1.5508,
+ 0.4134,
+ -0.0715,
+ 0.5517,
+ -0.3632,
+ -0.1922,
+ -0.9497,
+ 0.2503,
+ -0.2921
+ ],
+ "vae_latents_std": [
+ 2.8184,
+ 1.4541,
+ 2.3275,
+ 2.6558,
+ 1.2196,
+ 1.7708,
+ 2.6052,
+ 2.0743,
+ 3.2687,
+ 2.1526,
+ 2.8652,
+ 1.5579,
+ 1.6382,
+ 1.1253,
+ 2.8251,
+ 1.916
+ ],
+ "vae_z_dim": 16,
+ "feature_caching": "NoCaching",
+ "prompt_template_encode": "<|im_start|>system\nDescribe the image by detailing the color, shape, size, texture, quantity, text, spatial relationships of the objects and background:<|im_end|>\n<|im_start|>user\n{}<|im_end|>\n<|im_start|>assistant\n",
+ "prompt_template_encode_start_idx": 34,
+ "_auto_resize": false,
+ "num_layers": 60,
+ "attention_out_dim": 3072,
+ "attention_dim_head": 128,
+ "axes_dims_rope": [
+ 16,
+ 56,
+ 56
+ ],
+ "_comment_attn": "in [torch_sdpa, flash_attn3, sage_attn2]",
+ "attn_type": "flash_attn3",
+ "do_true_cfg": false,
+ "cpu_offload": true,
+ "offload_granularity": "block"
+}
diff --git a/configs/offload/block/wan_i2v_block.json b/configs/offload/block/wan_i2v_block.json
new file mode 100644
index 0000000000000000000000000000000000000000..4363093b7e5270d4d7bafbce10fe3b2546900001
--- /dev/null
+++ b/configs/offload/block/wan_i2v_block.json
@@ -0,0 +1,23 @@
+{
+ "infer_steps": 40,
+ "target_video_length": 81,
+ "target_height": 480,
+ "target_width": 832,
+ "self_attn_1_type": "flash_attn3",
+ "cross_attn_1_type": "flash_attn3",
+ "cross_attn_2_type": "flash_attn3",
+ "sample_guide_scale": 5,
+ "sample_shift": 5,
+ "enable_cfg": true,
+ "dit_quantized": true,
+ "dit_quant_scheme": "fp8-q8f",
+ "t5_quantized": true,
+ "t5_quant_scheme": "fp8-q8f",
+ "clip_quantized": true,
+ "clip_quant_scheme": "fp8-q8f",
+ "cpu_offload": true,
+ "offload_granularity": "block",
+ "t5_cpu_offload": false,
+ "vae_cpu_offload": false,
+ "clip_cpu_offload": false
+}
diff --git a/configs/offload/block/wan_t2v_1_3b.json b/configs/offload/block/wan_t2v_1_3b.json
new file mode 100644
index 0000000000000000000000000000000000000000..e03f8a7e776510bac40ae743004eb3b416a19125
--- /dev/null
+++ b/configs/offload/block/wan_t2v_1_3b.json
@@ -0,0 +1,17 @@
+{
+ "infer_steps": 4,
+ "target_video_length": 81,
+ "target_height": 480,
+ "target_width": 832,
+ "self_attn_1_type": "sage_attn2",
+ "cross_attn_1_type": "sage_attn2",
+ "cross_attn_2_type": "sage_attn2",
+ "sample_guide_scale": 5,
+ "sample_shift": 5,
+ "enable_cfg": true,
+ "t5_cpu_offload": true,
+ "t5_quantized": true,
+ "t5_quant_scheme": "fp8-sgl",
+ "unload_modules": false,
+ "use_tiling_vae": false
+}
diff --git a/configs/offload/block/wan_t2v_block.json b/configs/offload/block/wan_t2v_block.json
new file mode 100644
index 0000000000000000000000000000000000000000..2f926bce9b84b77afd81ae3df585e3a3563346f1
--- /dev/null
+++ b/configs/offload/block/wan_t2v_block.json
@@ -0,0 +1,24 @@
+{
+ "infer_steps": 50,
+ "target_video_length": 81,
+ "text_len": 512,
+ "target_height": 480,
+ "target_width": 832,
+ "self_attn_1_type": "flash_attn3",
+ "cross_attn_1_type": "flash_attn3",
+ "cross_attn_2_type": "flash_attn3",
+ "sample_guide_scale": 6,
+ "sample_shift": 8,
+ "enable_cfg": true,
+ "dit_quantized": true,
+ "dit_quant_scheme": "fp8-q8f",
+ "t5_quantized": true,
+ "t5_quant_scheme": "fp8-q8f",
+ "clip_quantized": true,
+ "clip_quant_scheme": "fp8-q8f",
+ "cpu_offload": true,
+ "offload_granularity": "block",
+ "t5_cpu_offload": false,
+ "vae_cpu_offload": false,
+ "clip_cpu_offload": false
+}
diff --git a/configs/offload/disk/wan_i2v_phase_lazy_load_480p.json b/configs/offload/disk/wan_i2v_phase_lazy_load_480p.json
new file mode 100644
index 0000000000000000000000000000000000000000..fa0348eed97babb7b09e4f52ca1a205d628b32f6
--- /dev/null
+++ b/configs/offload/disk/wan_i2v_phase_lazy_load_480p.json
@@ -0,0 +1,28 @@
+{
+ "infer_steps": 40,
+ "target_video_length": 81,
+ "target_height": 480,
+ "target_width": 832,
+ "self_attn_1_type": "sage_attn2",
+ "cross_attn_1_type": "sage_attn2",
+ "cross_attn_2_type": "sage_attn2",
+ "sample_guide_scale": 5,
+ "sample_shift": 5,
+ "enable_cfg": true,
+ "cpu_offload": true,
+ "offload_granularity": "phase",
+ "dit_quantized_ckpt": "/path/to/dit_quant_model",
+ "dit_quantized": true,
+ "dit_quant_scheme": "fp8-vllm",
+ "t5_cpu_offload": true,
+ "t5_quantized": true,
+ "t5_quantized_ckpt": "/path/to/models_t5_umt5-xxl-enc-fp8.pth",
+ "t5_quant_scheme": "fp8",
+ "clip_quantized": true,
+ "clip_quantized_ckpt": "/path/to/clip-fp8.pth",
+ "clip_quant_scheme": "fp8",
+ "use_tiling_vae": true,
+ "use_tae": true,
+ "tae_path": "/path/to/taew2_1.pth",
+ "lazy_load": true
+}
diff --git a/configs/offload/disk/wan_i2v_phase_lazy_load_720p.json b/configs/offload/disk/wan_i2v_phase_lazy_load_720p.json
new file mode 100644
index 0000000000000000000000000000000000000000..0516a9572af23f0dd91013fc9b011b5343e80731
--- /dev/null
+++ b/configs/offload/disk/wan_i2v_phase_lazy_load_720p.json
@@ -0,0 +1,30 @@
+{
+ "infer_steps": 40,
+ "target_video_length": 81,
+ "target_height": 1280,
+ "target_width": 720,
+ "self_attn_1_type": "sage_attn2",
+ "cross_attn_1_type": "sage_attn2",
+ "cross_attn_2_type": "sage_attn2",
+ "sample_guide_scale": 5,
+ "sample_shift": 5,
+ "enable_cfg": false,
+ "cpu_offload": true,
+ "offload_granularity": "phase",
+ "dit_quantized_ckpt": "/path/to/dit_quant_model",
+ "dit_quantized": true,
+ "dit_quant_scheme": "fp8-vllm",
+ "t5_cpu_offload": true,
+ "t5_quantized": true,
+ "t5_quantized_ckpt": "/path/to/models_t5_umt5-xxl-enc-fp8.pth",
+ "t5_quant_scheme": "fp8",
+ "clip_quantized": true,
+ "clip_quantized_ckpt": "/path/to/clip-fp8.pth",
+ "clip_quant_scheme": "fp8",
+ "use_tiling_vae": true,
+ "use_tae": true,
+ "tae_path": "/path/to/taew2_1.pth",
+ "lazy_load": true,
+ "rotary_chunk": true,
+ "clean_cuda_cache": true
+}
diff --git a/configs/offload/phase/wan_i2v_phase.json b/configs/offload/phase/wan_i2v_phase.json
new file mode 100644
index 0000000000000000000000000000000000000000..c5bd698bd4345f99ed4d9f721fff98fd394c8311
--- /dev/null
+++ b/configs/offload/phase/wan_i2v_phase.json
@@ -0,0 +1,24 @@
+{
+ "infer_steps": 40,
+ "target_video_length": 81,
+ "target_height": 480,
+ "target_width": 832,
+ "self_attn_1_type": "sage_attn2",
+ "cross_attn_1_type": "sage_attn2",
+ "cross_attn_2_type": "sage_attn2",
+ "sample_guide_scale": 5,
+ "sample_shift": 5,
+ "enable_cfg": true,
+ "cpu_offload": true,
+ "offload_granularity": "phase",
+ "t5_cpu_offload": false,
+ "clip_cpu_offload": false,
+ "vae_cpu_offload": false,
+ "use_tiling_vae": false,
+ "dit_quantized": true,
+ "dit_quant_scheme": "fp8-q8f",
+ "t5_quantized": true,
+ "t5_quant_scheme": "fp8-q8f",
+ "clip_quantized": true,
+ "clip_quant_scheme": "fp8-q8f"
+}
diff --git a/configs/offload/phase/wan_t2v_phase.json b/configs/offload/phase/wan_t2v_phase.json
new file mode 100644
index 0000000000000000000000000000000000000000..b12036aa844b36b349f17b14ad7d0129faabcc45
--- /dev/null
+++ b/configs/offload/phase/wan_t2v_phase.json
@@ -0,0 +1,25 @@
+{
+ "infer_steps": 50,
+ "target_video_length": 81,
+ "text_len": 512,
+ "target_height": 480,
+ "target_width": 832,
+ "self_attn_1_type": "sage_attn2",
+ "cross_attn_1_type": "sage_attn2",
+ "cross_attn_2_type": "sage_attn2",
+ "sample_guide_scale": 6,
+ "sample_shift": 8,
+ "enable_cfg": true,
+ "cpu_offload": true,
+ "offload_granularity": "phase",
+ "t5_cpu_offload": false,
+ "clip_cpu_offload": false,
+ "vae_cpu_offload": false,
+ "use_tiling_vae": false,
+ "dit_quantized": true,
+ "dit_quant_scheme": "fp8-q8f",
+ "t5_quantized": true,
+ "t5_quant_scheme": "fp8-q8f",
+ "clip_quantized": true,
+ "clip_quant_scheme": "fp8-q8f"
+}
diff --git a/configs/quantization/gguf/wan_i2v_q4_k.json b/configs/quantization/gguf/wan_i2v_q4_k.json
new file mode 100644
index 0000000000000000000000000000000000000000..e92f6b216c83dafca6e4e404851265f552d5ae81
--- /dev/null
+++ b/configs/quantization/gguf/wan_i2v_q4_k.json
@@ -0,0 +1,16 @@
+{
+ "infer_steps": 4,
+ "target_video_length": 81,
+ "target_height": 480,
+ "target_width": 832,
+ "self_attn_1_type": "sage_attn2",
+ "cross_attn_1_type": "sage_attn2",
+ "cross_attn_2_type": "sage_attn2",
+ "sample_guide_scale": 5,
+ "sample_shift": 5,
+ "enable_cfg": true,
+ "cpu_offload": true,
+ "offload_granularity": "model",
+ "dit_quantized": true,
+ "dit_quant_scheme": "gguf-Q4_K_S"
+}
diff --git a/configs/quantization/wan_i2v.json b/configs/quantization/wan_i2v.json
new file mode 100644
index 0000000000000000000000000000000000000000..7624495e62fc56b9824d09303a91668c3b959eed
--- /dev/null
+++ b/configs/quantization/wan_i2v.json
@@ -0,0 +1,16 @@
+{
+ "infer_steps": 40,
+ "target_video_length": 81,
+ "target_height": 480,
+ "target_width": 832,
+ "self_attn_1_type": "sage_attn2",
+ "cross_attn_1_type": "sage_attn2",
+ "cross_attn_2_type": "sage_attn2",
+ "sample_guide_scale": 5,
+ "sample_shift": 5,
+ "enable_cfg": true,
+ "cpu_offload": false,
+ "dit_quantized_ckpt": "/path/to/int8/model",
+ "dit_quantized": true,
+ "dit_quant_scheme": "int8-vllm"
+}
diff --git a/configs/quantization/wan_i2v_q8f.json b/configs/quantization/wan_i2v_q8f.json
new file mode 100644
index 0000000000000000000000000000000000000000..15c5b1245e88dc225f6c5e3e8f3d484e2ddb26ce
--- /dev/null
+++ b/configs/quantization/wan_i2v_q8f.json
@@ -0,0 +1,19 @@
+{
+ "infer_steps": 4,
+ "target_video_length": 81,
+ "target_height": 480,
+ "target_width": 832,
+ "self_attn_1_type": "sage_attn2",
+ "cross_attn_1_type": "sage_attn2",
+ "cross_attn_2_type": "sage_attn2",
+ "sample_guide_scale": 5,
+ "sample_shift": 5,
+ "enable_cfg": false,
+ "cpu_offload": false,
+ "dit_quantized": true,
+ "dit_quant_scheme": "int8-q8f",
+ "t5_quantized": true,
+ "t5_quant_scheme": "int8-q8f",
+ "clip_quantized": true,
+ "clip_quant_scheme": "int8-q8f"
+}
diff --git a/configs/quantization/wan_i2v_torchao.json b/configs/quantization/wan_i2v_torchao.json
new file mode 100644
index 0000000000000000000000000000000000000000..ca561b87cc079e6c43a7b2d11f38c8c92cc485e6
--- /dev/null
+++ b/configs/quantization/wan_i2v_torchao.json
@@ -0,0 +1,19 @@
+{
+ "infer_steps": 4,
+ "target_video_length": 81,
+ "target_height": 480,
+ "target_width": 832,
+ "self_attn_1_type": "sage_attn2",
+ "cross_attn_1_type": "sage_attn2",
+ "cross_attn_2_type": "sage_attn2",
+ "sample_guide_scale": 5,
+ "sample_shift": 5,
+ "enable_cfg": false,
+ "cpu_offload": false,
+ "dit_quantized": true,
+ "dit_quant_scheme": "int8-torchao",
+ "t5_quantized": true,
+ "t5_quant_scheme": "int8-torchao",
+ "clip_quantized": true,
+ "clip_quant_scheme": "int8-torchao"
+}
diff --git a/configs/qwen_image/qwen_image_i2i.json b/configs/qwen_image/qwen_image_i2i.json
new file mode 100644
index 0000000000000000000000000000000000000000..0e0fd3881b53caeab6abc17b903f7241fffbfee2
--- /dev/null
+++ b/configs/qwen_image/qwen_image_i2i.json
@@ -0,0 +1,64 @@
+{
+ "batchsize": 1,
+ "num_channels_latents": 16,
+ "vae_scale_factor": 8,
+ "infer_steps": 50,
+ "guidance_embeds": false,
+ "num_images_per_prompt": 1,
+ "vae_latents_mean": [
+ -0.7571,
+ -0.7089,
+ -0.9113,
+ 0.1075,
+ -0.1745,
+ 0.9653,
+ -0.1517,
+ 1.5508,
+ 0.4134,
+ -0.0715,
+ 0.5517,
+ -0.3632,
+ -0.1922,
+ -0.9497,
+ 0.2503,
+ -0.2921
+ ],
+ "vae_latents_std": [
+ 2.8184,
+ 1.4541,
+ 2.3275,
+ 2.6558,
+ 1.2196,
+ 1.7708,
+ 2.6052,
+ 2.0743,
+ 3.2687,
+ 2.1526,
+ 2.8652,
+ 1.5579,
+ 1.6382,
+ 1.1253,
+ 2.8251,
+ 1.916
+ ],
+ "vae_z_dim": 16,
+ "feature_caching": "NoCaching",
+ "transformer_in_channels": 64,
+ "prompt_template_encode": "<|im_start|>system\nDescribe the key features of the input image (color, shape, size, texture, objects, background), then explain how the user's text instruction should alter or modify the image. Generate a new image that meets the user's requirements while maintaining consistency with the original input where appropriate.<|im_end|>\n<|im_start|>user\n{}<|im_end|>\n<|im_start|>assistant\n",
+ "prompt_template_encode_start_idx": 64,
+ "_auto_resize": true,
+ "num_layers": 60,
+ "attention_out_dim": 3072,
+ "attention_dim_head": 128,
+ "axes_dims_rope": [
+ 16,
+ 56,
+ 56
+ ],
+ "_comment_attn": "in [torch_sdpa, flash_attn3, sage_attn2]",
+ "attn_type": "flash_attn3",
+ "do_true_cfg": true,
+ "true_cfg_scale": 4.0,
+ "CONDITION_IMAGE_SIZE": 1048576,
+ "USE_IMAGE_ID_IN_PROMPT": false
+}
diff --git a/configs/qwen_image/qwen_image_i2i_2509.json b/configs/qwen_image/qwen_image_i2i_2509.json
new file mode 100644
index 0000000000000000000000000000000000000000..974988e428650ab9320852bd4edbb9f5551e092b
--- /dev/null
+++ b/configs/qwen_image/qwen_image_i2i_2509.json
@@ -0,0 +1,64 @@
+{
+ "batchsize": 1,
+ "num_channels_latents": 16,
+ "vae_scale_factor": 8,
+ "infer_steps": 40,
+ "guidance_embeds": false,
+ "num_images_per_prompt": 1,
+ "vae_latents_mean": [
+ -0.7571,
+ -0.7089,
+ -0.9113,
+ 0.1075,
+ -0.1745,
+ 0.9653,
+ -0.1517,
+ 1.5508,
+ 0.4134,
+ -0.0715,
+ 0.5517,
+ -0.3632,
+ -0.1922,
+ -0.9497,
+ 0.2503,
+ -0.2921
+ ],
+ "vae_latents_std": [
+ 2.8184,
+ 1.4541,
+ 2.3275,
+ 2.6558,
+ 1.2196,
+ 1.7708,
+ 2.6052,
+ 2.0743,
+ 3.2687,
+ 2.1526,
+ 2.8652,
+ 1.5579,
+ 1.6382,
+ 1.1253,
+ 2.8251,
+ 1.916
+ ],
+ "vae_z_dim": 16,
+ "feature_caching": "NoCaching",
+ "transformer_in_channels": 64,
+ "prompt_template_encode": "<|im_start|>system\nDescribe the key features of the input image (color, shape, size, texture, objects, background), then explain how the user's text instruction should alter or modify the image. Generate a new image that meets the user's requirements while maintaining consistency with the original input where appropriate.<|im_end|>\n<|im_start|>user\n{}<|im_end|>\n<|im_start|>assistant\n",
+ "prompt_template_encode_start_idx": 64,
+ "_auto_resize": true,
+ "num_layers": 60,
+ "attention_out_dim": 3072,
+ "attention_dim_head": 128,
+ "axes_dims_rope": [
+ 16,
+ 56,
+ 56
+ ],
+ "_comment_attn": "in [torch_sdpa, flash_attn3, sage_attn2]",
+ "attn_type": "flash_attn3",
+ "do_true_cfg": true,
+ "true_cfg_scale": 4.0,
+ "CONDITION_IMAGE_SIZE": 147456,
+ "USE_IMAGE_ID_IN_PROMPT": true
+}
diff --git a/configs/qwen_image/qwen_image_i2i_2509_quant.json b/configs/qwen_image/qwen_image_i2i_2509_quant.json
new file mode 100644
index 0000000000000000000000000000000000000000..c6e73581288181269c5da3a917190d591db8986a
--- /dev/null
+++ b/configs/qwen_image/qwen_image_i2i_2509_quant.json
@@ -0,0 +1,67 @@
+{
+ "batchsize": 1,
+ "num_channels_latents": 16,
+ "vae_scale_factor": 8,
+ "infer_steps": 40,
+ "guidance_embeds": false,
+ "num_images_per_prompt": 1,
+ "vae_latents_mean": [
+ -0.7571,
+ -0.7089,
+ -0.9113,
+ 0.1075,
+ -0.1745,
+ 0.9653,
+ -0.1517,
+ 1.5508,
+ 0.4134,
+ -0.0715,
+ 0.5517,
+ -0.3632,
+ -0.1922,
+ -0.9497,
+ 0.2503,
+ -0.2921
+ ],
+ "vae_latents_std": [
+ 2.8184,
+ 1.4541,
+ 2.3275,
+ 2.6558,
+ 1.2196,
+ 1.7708,
+ 2.6052,
+ 2.0743,
+ 3.2687,
+ 2.1526,
+ 2.8652,
+ 1.5579,
+ 1.6382,
+ 1.1253,
+ 2.8251,
+ 1.916
+ ],
+ "vae_z_dim": 16,
+ "feature_caching": "NoCaching",
+ "transformer_in_channels": 64,
+ "prompt_template_encode": "<|im_start|>system\nDescribe the key features of the input image (color, shape, size, texture, objects, background), then explain how the user's text instruction should alter or modify the image. Generate a new image that meets the user's requirements while maintaining consistency with the original input where appropriate.<|im_end|>\n<|im_start|>user\n{}<|im_end|>\n<|im_start|>assistant\n",
+ "prompt_template_encode_start_idx": 64,
+ "_auto_resize": true,
+ "num_layers": 60,
+ "attention_out_dim": 3072,
+ "attention_dim_head": 128,
+ "axes_dims_rope": [
+ 16,
+ 56,
+ 56
+ ],
+ "_comment_attn": "in [torch_sdpa, flash_attn3, sage_attn2]",
+ "attn_type": "flash_attn3",
+ "do_true_cfg": true,
+ "true_cfg_scale": 4.0,
+ "CONDITION_IMAGE_SIZE": 147456,
+ "USE_IMAGE_ID_IN_PROMPT": true,
+ "dit_quantized": true,
+ "dit_quantized_ckpt": "/path/to/qwen_2509_fp8.safetensors",
+ "dit_quant_scheme": "fp8-sgl"
+}
diff --git a/configs/qwen_image/qwen_image_i2i_lora.json b/configs/qwen_image/qwen_image_i2i_lora.json
new file mode 100644
index 0000000000000000000000000000000000000000..b0bbc49282aef7b54fe32d09729b495ae697b5aa
--- /dev/null
+++ b/configs/qwen_image/qwen_image_i2i_lora.json
@@ -0,0 +1,70 @@
+{
+ "batchsize": 1,
+ "num_channels_latents": 16,
+ "vae_scale_factor": 8,
+ "infer_steps": 8,
+ "guidance_embeds": false,
+ "num_images_per_prompt": 1,
+ "vae_latents_mean": [
+ -0.7571,
+ -0.7089,
+ -0.9113,
+ 0.1075,
+ -0.1745,
+ 0.9653,
+ -0.1517,
+ 1.5508,
+ 0.4134,
+ -0.0715,
+ 0.5517,
+ -0.3632,
+ -0.1922,
+ -0.9497,
+ 0.2503,
+ -0.2921
+ ],
+ "vae_latents_std": [
+ 2.8184,
+ 1.4541,
+ 2.3275,
+ 2.6558,
+ 1.2196,
+ 1.7708,
+ 2.6052,
+ 2.0743,
+ 3.2687,
+ 2.1526,
+ 2.8652,
+ 1.5579,
+ 1.6382,
+ 1.1253,
+ 2.8251,
+ 1.916
+ ],
+ "vae_z_dim": 16,
+ "feature_caching": "NoCaching",
+ "transformer_in_channels": 64,
+ "prompt_template_encode": "<|im_start|>system\nDescribe the key features of the input image (color, shape, size, texture, objects, background), then explain how the user's text instruction should alter or modify the image. Generate a new image that meets the user's requirements while maintaining consistency with the original input where appropriate.<|im_end|>\n<|im_start|>user\n{}<|im_end|>\n<|im_start|>assistant\n",
+ "prompt_template_encode_start_idx": 64,
+ "_auto_resize": true,
+ "num_layers": 60,
+ "attention_out_dim": 3072,
+ "attention_dim_head": 128,
+ "axes_dims_rope": [
+ 16,
+ 56,
+ 56
+ ],
+ "_comment_attn": "in [torch_sdpa, flash_attn3, sage_attn2]",
+ "attn_type": "flash_attn3",
+ "do_true_cfg": true,
+ "true_cfg_scale": 4.0,
+ "CONDITION_IMAGE_SIZE": 1048576,
+ "USE_IMAGE_ID_IN_PROMPT": false,
+ "lora_configs": [
+ {
+ "path": "/path/to/Qwen-Image-Edit-Lightning-4steps-V1.0.safetensors",
+ "strength": 1.0
+ }
+ ]
+}
diff --git a/configs/qwen_image/qwen_image_t2i.json b/configs/qwen_image/qwen_image_t2i.json
new file mode 100644
index 0000000000000000000000000000000000000000..5581d50a2d5637396485114385b5dc40e9568461
--- /dev/null
+++ b/configs/qwen_image/qwen_image_t2i.json
@@ -0,0 +1,85 @@
+{
+ "batchsize": 1,
+ "_comment": "格式: '宽高比': [width, height]",
+ "aspect_ratios": {
+ "1:1": [
+ 1328,
+ 1328
+ ],
+ "16:9": [
+ 1664,
+ 928
+ ],
+ "9:16": [
+ 928,
+ 1664
+ ],
+ "4:3": [
+ 1472,
+ 1140
+ ],
+ "3:4": [
+ 142,
+ 184
+ ]
+ },
+ "aspect_ratio": "16:9",
+ "num_channels_latents": 16,
+ "vae_scale_factor": 8,
+ "infer_steps": 50,
+ "guidance_embeds": false,
+ "num_images_per_prompt": 1,
+ "vae_latents_mean": [
+ -0.7571,
+ -0.7089,
+ -0.9113,
+ 0.1075,
+ -0.1745,
+ 0.9653,
+ -0.1517,
+ 1.5508,
+ 0.4134,
+ -0.0715,
+ 0.5517,
+ -0.3632,
+ -0.1922,
+ -0.9497,
+ 0.2503,
+ -0.2921
+ ],
+ "vae_latents_std": [
+ 2.8184,
+ 1.4541,
+ 2.3275,
+ 2.6558,
+ 1.2196,
+ 1.7708,
+ 2.6052,
+ 2.0743,
+ 3.2687,
+ 2.1526,
+ 2.8652,
+ 1.5579,
+ 1.6382,
+ 1.1253,
+ 2.8251,
+ 1.916
+ ],
+ "vae_z_dim": 16,
+ "feature_caching": "NoCaching",
+ "prompt_template_encode": "<|im_start|>system\nDescribe the image by detailing the color, shape, size, texture, quantity, text, spatial relationships of the objects and background:<|im_end|>\n<|im_start|>user\n{}<|im_end|>\n<|im_start|>assistant\n",
+ "prompt_template_encode_start_idx": 34,
+ "_auto_resize": false,
+ "num_layers": 60,
+ "attention_out_dim": 3072,
+ "attention_dim_head": 128,
+ "axes_dims_rope": [
+ 16,
+ 56,
+ 56
+ ],
+ "_comment_attn": "in [torch_sdpa, flash_attn3, sage_attn2]",
+ "attn_type": "flash_attn3",
+ "do_true_cfg": true,
+ "true_cfg_scale": 4.0
+}
diff --git a/configs/seko_talk/5090/seko_talk_5090_bf16.json b/configs/seko_talk/5090/seko_talk_5090_bf16.json
new file mode 100644
index 0000000000000000000000000000000000000000..a6cab78438410e463f554427fb9c6653d19875be
--- /dev/null
+++ b/configs/seko_talk/5090/seko_talk_5090_bf16.json
@@ -0,0 +1,23 @@
+{
+ "infer_steps": 4,
+ "target_fps": 16,
+ "video_duration": 360,
+ "audio_sr": 16000,
+ "target_video_length": 81,
+ "resize_mode": "adaptive",
+ "self_attn_1_type": "sage_attn3",
+ "cross_attn_1_type": "sage_attn3",
+ "cross_attn_2_type": "sage_attn3",
+ "sample_guide_scale": 1,
+ "sample_shift": 5,
+ "enable_cfg": false,
+ "use_31_block": false,
+ "cpu_offload": true,
+ "offload_granularity": "block",
+ "offload_ratio": 1,
+ "t5_cpu_offload": true,
+ "clip_cpu_offload": false,
+ "audio_encoder_cpu_offload": false,
+ "audio_adapter_cpu_offload": false,
+ "vae_cpu_offload": false
+}
diff --git a/configs/seko_talk/5090/seko_talk_5090_int8.json b/configs/seko_talk/5090/seko_talk_5090_int8.json
new file mode 100644
index 0000000000000000000000000000000000000000..664983b908669400d34f1ff8bcb14683a6e1d1c9
--- /dev/null
+++ b/configs/seko_talk/5090/seko_talk_5090_int8.json
@@ -0,0 +1,29 @@
+{
+ "infer_steps": 4,
+ "target_fps": 16,
+ "video_duration": 360,
+ "audio_sr": 16000,
+ "target_video_length": 81,
+ "resize_mode": "adaptive",
+ "self_attn_1_type": "sage_attn3",
+ "cross_attn_1_type": "sage_attn3",
+ "cross_attn_2_type": "sage_attn3",
+ "sample_guide_scale": 1,
+ "sample_shift": 5,
+ "enable_cfg": false,
+ "use_31_block": false,
+ "cpu_offload": true,
+ "offload_granularity": "block",
+ "offload_ratio": 1,
+ "t5_cpu_offload": false,
+ "clip_cpu_offload": false,
+ "audio_encoder_cpu_offload": false,
+ "audio_adapter_cpu_offload": false,
+ "vae_cpu_offload": false,
+ "dit_quantized": true,
+ "dit_quant_scheme": "int8-q8f",
+ "adapter_quantized": true,
+ "adapter_quant_scheme": "int8-q8f",
+ "t5_quantized": true,
+ "t5_quant_scheme": "int8-q8f"
+}
diff --git a/configs/seko_talk/5090/seko_talk_5090_int8_8gpu.json b/configs/seko_talk/5090/seko_talk_5090_int8_8gpu.json
new file mode 100644
index 0000000000000000000000000000000000000000..3dfc9d533204841113ddd21db22f9095f34a7ae7
--- /dev/null
+++ b/configs/seko_talk/5090/seko_talk_5090_int8_8gpu.json
@@ -0,0 +1,34 @@
+
+{
+ "infer_steps": 4,
+ "target_fps": 16,
+ "video_duration": 360,
+ "audio_sr": 16000,
+ "target_video_length": 81,
+ "resize_mode": "adaptive",
+ "self_attn_1_type": "sage_attn3",
+ "cross_attn_1_type": "sage_attn3",
+ "cross_attn_2_type": "sage_attn3",
+ "sample_guide_scale": 1,
+ "sample_shift": 5,
+ "enable_cfg": false,
+ "use_31_block": false,
+ "cpu_offload": true,
+ "offload_granularity": "block",
+ "offload_ratio": 1,
+ "t5_cpu_offload": false,
+ "clip_cpu_offload": false,
+ "audio_encoder_cpu_offload": false,
+ "audio_adapter_cpu_offload": false,
+ "vae_cpu_offload": false,
+ "dit_quantized": true,
+ "dit_quant_scheme": "int8-q8f",
+ "adapter_quantized": true,
+ "adapter_quant_scheme": "int8-q8f",
+ "t5_quantized": true,
+ "t5_quant_scheme": "int8-q8f",
+ "parallel": {
+ "seq_p_size": 8,
+ "seq_p_attn_type": "ulysses-4090"
+ }
+}
diff --git a/configs/seko_talk/A800/seko_talk_A800_int8.json b/configs/seko_talk/A800/seko_talk_A800_int8.json
new file mode 100644
index 0000000000000000000000000000000000000000..a5da24c2a907ea377a3403d4fb14b826814d07cf
--- /dev/null
+++ b/configs/seko_talk/A800/seko_talk_A800_int8.json
@@ -0,0 +1,22 @@
+{
+ "infer_steps": 4,
+ "target_fps": 16,
+ "video_duration": 360,
+ "audio_sr": 16000,
+ "target_video_length": 81,
+ "resize_mode": "adaptive",
+ "self_attn_1_type": "flash_attn3",
+ "cross_attn_1_type": "flash_attn3",
+ "cross_attn_2_type": "flash_attn3",
+ "sample_guide_scale": 1.0,
+ "sample_shift": 5,
+ "enable_cfg": false,
+ "cpu_offload": false,
+ "use_31_block": false,
+ "dit_quantized": true,
+ "dit_quant_scheme": "int8-vllm",
+ "adapter_quantized": true,
+ "adapter_quant_scheme": "int8-vllm",
+ "t5_quantized": true,
+ "t5_quant_scheme": "int8-vllm"
+}
diff --git a/configs/seko_talk/A800/seko_talk_A800_int8_dist_2gpu.json b/configs/seko_talk/A800/seko_talk_A800_int8_dist_2gpu.json
new file mode 100644
index 0000000000000000000000000000000000000000..f99ba12190fcc7dbc58b4dd9d60dacfa7f66e970
--- /dev/null
+++ b/configs/seko_talk/A800/seko_talk_A800_int8_dist_2gpu.json
@@ -0,0 +1,26 @@
+{
+ "infer_steps": 4,
+ "target_fps": 16,
+ "video_duration": 360,
+ "audio_sr": 16000,
+ "target_video_length": 81,
+ "resize_mode": "adaptive",
+ "self_attn_1_type": "flash_attn3",
+ "cross_attn_1_type": "flash_attn3",
+ "cross_attn_2_type": "flash_attn3",
+ "sample_guide_scale": 1.0,
+ "sample_shift": 5,
+ "enable_cfg": false,
+ "cpu_offload": false,
+ "use_31_block": false,
+ "dit_quantized": true,
+ "dit_quant_scheme": "int8-vllm",
+ "adapter_quantized": true,
+ "adapter_quant_scheme": "int8-vllm",
+ "t5_quantized": true,
+ "t5_quant_scheme": "int8-vllm",
+ "parallel": {
+ "seq_p_size": 2,
+ "seq_p_attn_type": "ulysses"
+ }
+}
diff --git a/configs/seko_talk/A800/seko_talk_A800_int8_dist_4gpu.json b/configs/seko_talk/A800/seko_talk_A800_int8_dist_4gpu.json
new file mode 100644
index 0000000000000000000000000000000000000000..c0d0c45df8bf7061170987f1815047c38ec72ec0
--- /dev/null
+++ b/configs/seko_talk/A800/seko_talk_A800_int8_dist_4gpu.json
@@ -0,0 +1,26 @@
+{
+ "infer_steps": 4,
+ "target_fps": 16,
+ "video_duration": 360,
+ "audio_sr": 16000,
+ "target_video_length": 81,
+ "resize_mode": "adaptive",
+ "self_attn_1_type": "flash_attn3",
+ "cross_attn_1_type": "flash_attn3",
+ "cross_attn_2_type": "flash_attn3",
+ "sample_guide_scale": 1.0,
+ "sample_shift": 5,
+ "enable_cfg": false,
+ "cpu_offload": false,
+ "use_31_block": false,
+ "dit_quantized": true,
+ "dit_quant_scheme": "int8-vllm",
+ "adapter_quantized": true,
+ "adapter_quant_scheme": "int8-vllm",
+ "t5_quantized": true,
+ "t5_quant_scheme": "int8-vllm",
+ "parallel": {
+ "seq_p_size": 4,
+ "seq_p_attn_type": "ulysses"
+ }
+}
diff --git a/configs/seko_talk/A800/seko_talk_A800_int8_dist_8gpu.json b/configs/seko_talk/A800/seko_talk_A800_int8_dist_8gpu.json
new file mode 100644
index 0000000000000000000000000000000000000000..278d37664a0e79c0b76492c1e03982cdb291dd68
--- /dev/null
+++ b/configs/seko_talk/A800/seko_talk_A800_int8_dist_8gpu.json
@@ -0,0 +1,26 @@
+{
+ "infer_steps": 4,
+ "target_fps": 16,
+ "video_duration": 360,
+ "audio_sr": 16000,
+ "target_video_length": 81,
+ "resize_mode": "adaptive",
+ "self_attn_1_type": "flash_attn3",
+ "cross_attn_1_type": "flash_attn3",
+ "cross_attn_2_type": "flash_attn3",
+ "sample_guide_scale": 1.0,
+ "sample_shift": 5,
+ "enable_cfg": false,
+ "cpu_offload": false,
+ "use_31_block": false,
+ "dit_quantized": true,
+ "dit_quant_scheme": "int8-vllm",
+ "adapter_quantized": true,
+ "adapter_quant_scheme": "int8-vllm",
+ "t5_quantized": true,
+ "t5_quant_scheme": "int8-vllm",
+ "parallel": {
+ "seq_p_size": 8,
+ "seq_p_attn_type": "ulysses"
+ }
+}
diff --git a/configs/seko_talk/L40s/1gpu/seko_talk_bf16.json b/configs/seko_talk/L40s/1gpu/seko_talk_bf16.json
new file mode 100644
index 0000000000000000000000000000000000000000..fd1afa4d23e8d77779d02481c081fb2ab6d16a87
--- /dev/null
+++ b/configs/seko_talk/L40s/1gpu/seko_talk_bf16.json
@@ -0,0 +1,23 @@
+{
+ "infer_steps": 4,
+ "target_fps": 16,
+ "video_duration": 360,
+ "audio_sr": 16000,
+ "target_video_length": 81,
+ "resize_mode": "adaptive",
+ "self_attn_1_type": "sage_attn2",
+ "cross_attn_1_type": "sage_attn2",
+ "cross_attn_2_type": "sage_attn2",
+ "sample_guide_scale": 1.0,
+ "sample_shift": 5,
+ "enable_cfg": false,
+ "use_31_block": false,
+ "cpu_offload": true,
+ "offload_granularity": "block",
+ "offload_ratio": 0.8,
+ "t5_cpu_offload": false,
+ "clip_cpu_offload": false,
+ "vae_cpu_offload": false,
+ "audio_encoder_cpu_offload": false,
+ "audio_adapter_cpu_offload": false
+}
diff --git a/configs/seko_talk/L40s/1gpu/seko_talk_fp8.json b/configs/seko_talk/L40s/1gpu/seko_talk_fp8.json
new file mode 100644
index 0000000000000000000000000000000000000000..d88f4542282f4e1e2b3fc2b37c1f37d3cfbf8e60
--- /dev/null
+++ b/configs/seko_talk/L40s/1gpu/seko_talk_fp8.json
@@ -0,0 +1,27 @@
+{
+ "infer_steps": 4,
+ "target_fps": 16,
+ "video_duration": 360,
+ "audio_sr": 16000,
+ "target_video_length": 81,
+ "resize_mode": "adaptive",
+ "self_attn_1_type": "sage_attn2",
+ "cross_attn_1_type": "sage_attn2",
+ "cross_attn_2_type": "sage_attn2",
+ "sample_guide_scale": 1.0,
+ "sample_shift": 5,
+ "enable_cfg": false,
+ "use_31_block": false,
+ "t5_quantized": true,
+ "t5_quant_scheme": "fp8-q8f",
+ "dit_quantized": true,
+ "dit_quant_scheme": "fp8-q8f",
+ "adapter_quantized": true,
+ "adapter_quant_scheme": "fp8",
+ "cpu_offload": false,
+ "t5_cpu_offload": true,
+ "clip_cpu_offload": true,
+ "vae_cpu_offload": true,
+ "audio_encoder_cpu_offload": true,
+ "audio_adapter_cpu_offload": true
+}
diff --git a/configs/seko_talk/L40s/2gpu/seko_talk_bf16.json b/configs/seko_talk/L40s/2gpu/seko_talk_bf16.json
new file mode 100644
index 0000000000000000000000000000000000000000..4cd8a3f099a5a887ad9d500224a22ef24c396740
--- /dev/null
+++ b/configs/seko_talk/L40s/2gpu/seko_talk_bf16.json
@@ -0,0 +1,25 @@
+{
+ "infer_steps": 4,
+ "target_fps": 16,
+ "video_duration": 360,
+ "audio_sr": 16000,
+ "target_video_length": 81,
+ "resize_mode": "adaptive",
+ "self_attn_1_type": "sage_attn2",
+ "cross_attn_1_type": "sage_attn2",
+ "cross_attn_2_type": "sage_attn2",
+ "sample_guide_scale": 1.0,
+ "sample_shift": 5,
+ "enable_cfg": false,
+ "use_31_block": false,
+ "cpu_offload": false,
+ "t5_cpu_offload": true,
+ "clip_cpu_offload": true,
+ "vae_cpu_offload": true,
+ "audio_encoder_cpu_offload": true,
+ "audio_adapter_cpu_offload": true,
+ "parallel": {
+ "seq_p_size": 2,
+ "seq_p_attn_type": "ulysses"
+ }
+}
diff --git a/configs/seko_talk/L40s/2gpu/seko_talk_fp8.json b/configs/seko_talk/L40s/2gpu/seko_talk_fp8.json
new file mode 100644
index 0000000000000000000000000000000000000000..b45e87f0d8786fc3797dcf21c4e0fd7562f6fb08
--- /dev/null
+++ b/configs/seko_talk/L40s/2gpu/seko_talk_fp8.json
@@ -0,0 +1,31 @@
+{
+ "infer_steps": 4,
+ "target_fps": 16,
+ "video_duration": 360,
+ "audio_sr": 16000,
+ "target_video_length": 81,
+ "resize_mode": "adaptive",
+ "self_attn_1_type": "sage_attn2",
+ "cross_attn_1_type": "sage_attn2",
+ "cross_attn_2_type": "sage_attn2",
+ "sample_guide_scale": 1.0,
+ "sample_shift": 5,
+ "enable_cfg": false,
+ "use_31_block": false,
+ "t5_quantized": true,
+ "t5_quant_scheme": "fp8-q8f",
+ "dit_quantized": true,
+ "dit_quant_scheme": "fp8-q8f",
+ "adapter_quantized": true,
+ "adapter_quant_scheme": "fp8",
+ "cpu_offload": false,
+ "t5_cpu_offload": true,
+ "clip_cpu_offload": true,
+ "vae_cpu_offload": true,
+ "audio_encoder_cpu_offload": true,
+ "audio_adapter_cpu_offload": true,
+ "parallel": {
+ "seq_p_size": 2,
+ "seq_p_attn_type": "ulysses"
+ }
+}
diff --git a/configs/seko_talk/L40s/4gpu/seko_talk_bf16.json b/configs/seko_talk/L40s/4gpu/seko_talk_bf16.json
new file mode 100644
index 0000000000000000000000000000000000000000..a3f7b6fb3b38f135dc2f2ead5514f3eebfac2526
--- /dev/null
+++ b/configs/seko_talk/L40s/4gpu/seko_talk_bf16.json
@@ -0,0 +1,25 @@
+{
+ "infer_steps": 4,
+ "target_fps": 16,
+ "video_duration": 360,
+ "audio_sr": 16000,
+ "target_video_length": 81,
+ "resize_mode": "adaptive",
+ "self_attn_1_type": "sage_attn2",
+ "cross_attn_1_type": "sage_attn2",
+ "cross_attn_2_type": "sage_attn2",
+ "sample_guide_scale": 1.0,
+ "sample_shift": 5,
+ "enable_cfg": false,
+ "use_31_block": false,
+ "cpu_offload": false,
+ "t5_cpu_offload": true,
+ "clip_cpu_offload": true,
+ "vae_cpu_offload": true,
+ "audio_encoder_cpu_offload": true,
+ "audio_adapter_cpu_offload": true,
+ "parallel": {
+ "seq_p_size": 4,
+ "seq_p_attn_type": "ulysses"
+ }
+}
diff --git a/configs/seko_talk/L40s/4gpu/seko_talk_fp8.json b/configs/seko_talk/L40s/4gpu/seko_talk_fp8.json
new file mode 100644
index 0000000000000000000000000000000000000000..ec682a6e0a48c7be36c4769435d2d3a004cd8f5d
--- /dev/null
+++ b/configs/seko_talk/L40s/4gpu/seko_talk_fp8.json
@@ -0,0 +1,31 @@
+{
+ "infer_steps": 4,
+ "target_fps": 16,
+ "video_duration": 360,
+ "audio_sr": 16000,
+ "target_video_length": 81,
+ "resize_mode": "adaptive",
+ "self_attn_1_type": "sage_attn2",
+ "cross_attn_1_type": "sage_attn2",
+ "cross_attn_2_type": "sage_attn2",
+ "sample_guide_scale": 1.0,
+ "sample_shift": 5,
+ "enable_cfg": false,
+ "use_31_block": false,
+ "t5_quantized": true,
+ "t5_quant_scheme": "fp8-q8f",
+ "dit_quantized": true,
+ "dit_quant_scheme": "fp8-q8f",
+ "adapter_quantized": true,
+ "adapter_quant_scheme": "fp8",
+ "cpu_offload": false,
+ "t5_cpu_offload": true,
+ "clip_cpu_offload": true,
+ "vae_cpu_offload": true,
+ "audio_encoder_cpu_offload": true,
+ "audio_adapter_cpu_offload": true,
+ "parallel": {
+ "seq_p_size": 4,
+ "seq_p_attn_type": "ulysses"
+ }
+}
diff --git a/configs/seko_talk/L40s/8gpu/seko_talk_bf16.json b/configs/seko_talk/L40s/8gpu/seko_talk_bf16.json
new file mode 100644
index 0000000000000000000000000000000000000000..079439fe1b3fee28435fecb837f3638145814422
--- /dev/null
+++ b/configs/seko_talk/L40s/8gpu/seko_talk_bf16.json
@@ -0,0 +1,25 @@
+{
+ "infer_steps": 4,
+ "target_fps": 16,
+ "video_duration": 360,
+ "audio_sr": 16000,
+ "target_video_length": 81,
+ "resize_mode": "adaptive",
+ "self_attn_1_type": "sage_attn2",
+ "cross_attn_1_type": "sage_attn2",
+ "cross_attn_2_type": "sage_attn2",
+ "sample_guide_scale": 1.0,
+ "sample_shift": 5,
+ "enable_cfg": false,
+ "use_31_block": false,
+ "cpu_offload": false,
+ "t5_cpu_offload": true,
+ "clip_cpu_offload": true,
+ "vae_cpu_offload": true,
+ "audio_encoder_cpu_offload": true,
+ "audio_adapter_cpu_offload": true,
+ "parallel": {
+ "seq_p_size": 8,
+ "seq_p_attn_type": "ulysses"
+ }
+}
diff --git a/configs/seko_talk/L40s/8gpu/seko_talk_fp8.json b/configs/seko_talk/L40s/8gpu/seko_talk_fp8.json
new file mode 100644
index 0000000000000000000000000000000000000000..d50f7ebb896e29d762830b20e67d0c14a30c318e
--- /dev/null
+++ b/configs/seko_talk/L40s/8gpu/seko_talk_fp8.json
@@ -0,0 +1,31 @@
+{
+ "infer_steps": 4,
+ "target_fps": 16,
+ "video_duration": 360,
+ "audio_sr": 16000,
+ "target_video_length": 81,
+ "resize_mode": "adaptive",
+ "self_attn_1_type": "sage_attn2",
+ "cross_attn_1_type": "sage_attn2",
+ "cross_attn_2_type": "sage_attn2",
+ "sample_guide_scale": 1.0,
+ "sample_shift": 5,
+ "enable_cfg": false,
+ "use_31_block": false,
+ "t5_quantized": true,
+ "t5_quant_scheme": "fp8-q8f",
+ "dit_quantized": true,
+ "dit_quant_scheme": "fp8-q8f",
+ "adapter_quantized": true,
+ "adapter_quant_scheme": "fp8",
+ "cpu_offload": false,
+ "t5_cpu_offload": true,
+ "clip_cpu_offload": true,
+ "vae_cpu_offload": true,
+ "audio_encoder_cpu_offload": true,
+ "audio_adapter_cpu_offload": true,
+ "parallel": {
+ "seq_p_size": 8,
+ "seq_p_attn_type": "ulysses"
+ }
+}
diff --git a/configs/seko_talk/mlu/seko_talk_bf16.json b/configs/seko_talk/mlu/seko_talk_bf16.json
new file mode 100644
index 0000000000000000000000000000000000000000..71741879328b0e9425bc00a9fc3c0c339791dc9e
--- /dev/null
+++ b/configs/seko_talk/mlu/seko_talk_bf16.json
@@ -0,0 +1,18 @@
+{
+ "infer_steps": 4,
+ "target_fps": 16,
+ "video_duration": 360,
+ "audio_sr": 16000,
+ "target_video_length": 81,
+ "resize_mode": "adaptive",
+ "self_attn_1_type": "mlu_sage_attn",
+ "cross_attn_1_type": "mlu_sage_attn",
+ "cross_attn_2_type": "mlu_sage_attn",
+ "sample_guide_scale": 1.0,
+ "sample_shift": 5,
+ "enable_cfg": false,
+ "cpu_offload": false,
+ "use_31_block": false,
+ "rope_type": "torch",
+ "modulate_type": "torch"
+}
diff --git a/configs/seko_talk/mlu/seko_talk_int8.json b/configs/seko_talk/mlu/seko_talk_int8.json
new file mode 100644
index 0000000000000000000000000000000000000000..673acf8619199f07eb251a5f9a5a08296f07e2d3
--- /dev/null
+++ b/configs/seko_talk/mlu/seko_talk_int8.json
@@ -0,0 +1,29 @@
+{
+ "infer_steps": 4,
+ "target_fps": 16,
+ "video_duration": 360,
+ "audio_sr": 16000,
+ "target_video_length": 81,
+ "resize_mode": "adaptive",
+ "self_attn_1_type": "mlu_sage_attn",
+ "cross_attn_1_type": "mlu_sage_attn",
+ "cross_attn_2_type": "mlu_sage_attn",
+ "seed": 42,
+ "sample_guide_scale": 1.0,
+ "sample_shift": 5,
+ "enable_cfg": false,
+ "cpu_offload": false,
+ "use_31_block": false,
+ "clip_quantized": false,
+ "clip_quant_scheme": "int8-tmo",
+ "dit_quantized": true,
+ "dit_quant_scheme": "int8-tmo",
+ "adapter_quantized": true,
+ "adapter_quant_scheme": "int8-tmo",
+ "t5_quantized": true,
+ "t5_quant_scheme": "int8-tmo",
+ "modulate_type": "torch",
+ "rope_type": "torch",
+ "ln_type": "Default",
+ "rms_type": "Default"
+}
diff --git a/configs/seko_talk/mlu/seko_talk_int8_dist.json b/configs/seko_talk/mlu/seko_talk_int8_dist.json
new file mode 100644
index 0000000000000000000000000000000000000000..fe5f515260e81d5f1d444be919afcd8f04b1493f
--- /dev/null
+++ b/configs/seko_talk/mlu/seko_talk_int8_dist.json
@@ -0,0 +1,33 @@
+{
+ "infer_steps": 4,
+ "target_fps": 16,
+ "video_duration": 360,
+ "audio_sr": 16000,
+ "target_video_length": 81,
+ "resize_mode": "adaptive",
+ "self_attn_1_type": "mlu_sage_attn",
+ "cross_attn_1_type": "mlu_sage_attn",
+ "cross_attn_2_type": "mlu_sage_attn",
+ "seed": 42,
+ "sample_guide_scale": 1.0,
+ "sample_shift": 5,
+ "enable_cfg": false,
+ "cpu_offload": false,
+ "use_31_block": false,
+ "clip_quantized": false,
+ "clip_quant_scheme": "int8-tmo",
+ "dit_quantized": true,
+ "dit_quant_scheme": "int8-tmo",
+ "adapter_quantized": true,
+ "adapter_quant_scheme": "int8-tmo",
+ "t5_quantized": true,
+ "t5_quant_scheme": "int8-tmo",
+ "modulate_type": "torch",
+ "rope_type": "torch",
+ "ln_type": "Default",
+ "rms_type": "Default",
+ "parallel": {
+ "seq_p_size": 8,
+ "seq_p_attn_type": "ulysses"
+ }
+}
diff --git a/configs/seko_talk/multi_person/01_base.json b/configs/seko_talk/multi_person/01_base.json
new file mode 100644
index 0000000000000000000000000000000000000000..417f62ce1caa0175ba79a13f76634a7224b0a621
--- /dev/null
+++ b/configs/seko_talk/multi_person/01_base.json
@@ -0,0 +1,16 @@
+{
+ "infer_steps": 4,
+ "target_fps": 16,
+ "video_duration": 360,
+ "audio_sr": 16000,
+ "target_video_length": 81,
+ "resize_mode": "adaptive",
+ "self_attn_1_type": "flash_attn3",
+ "cross_attn_1_type": "flash_attn3",
+ "cross_attn_2_type": "flash_attn3",
+ "sample_guide_scale": 1.0,
+ "sample_shift": 5,
+ "enable_cfg": false,
+ "cpu_offload": false,
+ "use_31_block": false
+}
diff --git a/configs/seko_talk/multi_person/02_base_fp8.json b/configs/seko_talk/multi_person/02_base_fp8.json
new file mode 100644
index 0000000000000000000000000000000000000000..232b3987ea72a1979dd1d3af77252006847a5644
--- /dev/null
+++ b/configs/seko_talk/multi_person/02_base_fp8.json
@@ -0,0 +1,22 @@
+{
+ "infer_steps": 4,
+ "target_fps": 16,
+ "video_duration": 360,
+ "audio_sr": 16000,
+ "target_video_length": 81,
+ "resize_mode": "adaptive",
+ "self_attn_1_type": "sage_attn2",
+ "cross_attn_1_type": "sage_attn2",
+ "cross_attn_2_type": "sage_attn2",
+ "sample_guide_scale": 1.0,
+ "sample_shift": 5,
+ "enable_cfg": false,
+ "cpu_offload": false,
+ "use_31_block": false,
+ "dit_quantized": true,
+ "dit_quant_scheme": "fp8-sgl",
+ "adapter_quantized": true,
+ "adapter_quant_scheme": "fp8",
+ "t5_quantized": true,
+ "t5_quant_scheme": "fp8"
+}
diff --git a/configs/seko_talk/multi_person/03_dist.json b/configs/seko_talk/multi_person/03_dist.json
new file mode 100644
index 0000000000000000000000000000000000000000..5cc4cbd6e57a42c61b4683ed63e3d20ebdc237eb
--- /dev/null
+++ b/configs/seko_talk/multi_person/03_dist.json
@@ -0,0 +1,20 @@
+{
+ "infer_steps": 4,
+ "target_fps": 16,
+ "video_duration": 360,
+ "audio_sr": 16000,
+ "target_video_length": 81,
+ "resize_mode": "adaptive",
+ "self_attn_1_type": "sage_attn2",
+ "cross_attn_1_type": "sage_attn2",
+ "cross_attn_2_type": "sage_attn2",
+ "sample_guide_scale": 1.0,
+ "sample_shift": 5,
+ "enable_cfg": false,
+ "cpu_offload": false,
+ "use_31_block": false,
+ "parallel": {
+ "seq_p_size": 4,
+ "seq_p_attn_type": "ulysses"
+ }
+}
diff --git a/configs/seko_talk/multi_person/04_dist_fp8.json b/configs/seko_talk/multi_person/04_dist_fp8.json
new file mode 100644
index 0000000000000000000000000000000000000000..f91b3fd57af5084d443a207607f59d18044609b3
--- /dev/null
+++ b/configs/seko_talk/multi_person/04_dist_fp8.json
@@ -0,0 +1,26 @@
+{
+ "infer_steps": 4,
+ "target_fps": 16,
+ "video_duration": 360,
+ "audio_sr": 16000,
+ "target_video_length": 81,
+ "resize_mode": "adaptive",
+ "self_attn_1_type": "sage_attn2",
+ "cross_attn_1_type": "sage_attn2",
+ "cross_attn_2_type": "sage_attn2",
+ "sample_guide_scale": 1.0,
+ "sample_shift": 5,
+ "enable_cfg": false,
+ "cpu_offload": false,
+ "use_31_block": false,
+ "dit_quantized": true,
+ "dit_quant_scheme": "fp8-sgl",
+ "adapter_quantized": true,
+ "adapter_quant_scheme": "fp8",
+ "t5_quantized": true,
+ "t5_quant_scheme": "fp8",
+ "parallel": {
+ "seq_p_size": 4,
+ "seq_p_attn_type": "ulysses"
+ }
+}
diff --git a/configs/seko_talk/multi_person/15_base_compile.json b/configs/seko_talk/multi_person/15_base_compile.json
new file mode 100644
index 0000000000000000000000000000000000000000..73cb92aacc0ecf1556d67c49a2fc8342777f3b37
--- /dev/null
+++ b/configs/seko_talk/multi_person/15_base_compile.json
@@ -0,0 +1,27 @@
+{
+ "infer_steps": 4,
+ "target_fps": 16,
+ "video_duration": 360,
+ "audio_sr": 16000,
+ "target_video_length": 81,
+ "resize_mode": "adaptive",
+ "self_attn_1_type": "flash_attn3",
+ "cross_attn_1_type": "flash_attn3",
+ "cross_attn_2_type": "flash_attn3",
+ "sample_guide_scale": 1.0,
+ "sample_shift": 5,
+ "enable_cfg": false,
+ "cpu_offload": false,
+ "use_31_block": false,
+ "compile": true,
+ "compile_shapes": [
+ [
+ 480,
+ 832
+ ],
+ [
+ 720,
+ 1280
+ ]
+ ]
+}
diff --git a/configs/seko_talk/seko_talk_01_base.json b/configs/seko_talk/seko_talk_01_base.json
new file mode 100644
index 0000000000000000000000000000000000000000..417f62ce1caa0175ba79a13f76634a7224b0a621
--- /dev/null
+++ b/configs/seko_talk/seko_talk_01_base.json
@@ -0,0 +1,16 @@
+{
+ "infer_steps": 4,
+ "target_fps": 16,
+ "video_duration": 360,
+ "audio_sr": 16000,
+ "target_video_length": 81,
+ "resize_mode": "adaptive",
+ "self_attn_1_type": "flash_attn3",
+ "cross_attn_1_type": "flash_attn3",
+ "cross_attn_2_type": "flash_attn3",
+ "sample_guide_scale": 1.0,
+ "sample_shift": 5,
+ "enable_cfg": false,
+ "cpu_offload": false,
+ "use_31_block": false
+}
diff --git a/configs/seko_talk/seko_talk_02_fp8.json b/configs/seko_talk/seko_talk_02_fp8.json
new file mode 100644
index 0000000000000000000000000000000000000000..15cdbc046e57090cb3265f0b9489806e55438d21
--- /dev/null
+++ b/configs/seko_talk/seko_talk_02_fp8.json
@@ -0,0 +1,24 @@
+{
+ "infer_steps": 4,
+ "target_fps": 16,
+ "video_duration": 360,
+ "audio_sr": 16000,
+ "target_video_length": 81,
+ "resize_mode": "adaptive",
+ "self_attn_1_type": "sage_attn2",
+ "cross_attn_1_type": "sage_attn2",
+ "cross_attn_2_type": "sage_attn2",
+ "sample_guide_scale": 1.0,
+ "sample_shift": 5,
+ "enable_cfg": false,
+ "cpu_offload": false,
+ "use_31_block": false,
+ "clip_quantized": true,
+ "clip_quant_scheme": "fp8-sgl",
+ "dit_quantized": true,
+ "dit_quant_scheme": "fp8-sgl",
+ "adapter_quantized": true,
+ "adapter_quant_scheme": "fp8-sgl",
+ "t5_quantized": true,
+ "t5_quant_scheme": "fp8-sgl"
+}
diff --git a/configs/seko_talk/seko_talk_03_dist.json b/configs/seko_talk/seko_talk_03_dist.json
new file mode 100644
index 0000000000000000000000000000000000000000..f7543370eac394efa72ed618ff65bd4389c62ffe
--- /dev/null
+++ b/configs/seko_talk/seko_talk_03_dist.json
@@ -0,0 +1,20 @@
+{
+ "infer_steps": 4,
+ "target_fps": 16,
+ "video_duration": 360,
+ "audio_sr": 16000,
+ "target_video_length": 81,
+ "resize_mode": "adaptive",
+ "self_attn_1_type": "flash_attn3",
+ "cross_attn_1_type": "flash_attn3",
+ "cross_attn_2_type": "flash_attn3",
+ "sample_guide_scale": 1.0,
+ "sample_shift": 5,
+ "enable_cfg": false,
+ "cpu_offload": false,
+ "use_31_block": false,
+ "parallel": {
+ "seq_p_size": 8,
+ "seq_p_attn_type": "ulysses"
+ }
+}
diff --git a/configs/seko_talk/seko_talk_04_fp8_dist.json b/configs/seko_talk/seko_talk_04_fp8_dist.json
new file mode 100644
index 0000000000000000000000000000000000000000..443295169fec8be2aaaa07e89f898092db61bb6d
--- /dev/null
+++ b/configs/seko_talk/seko_talk_04_fp8_dist.json
@@ -0,0 +1,26 @@
+{
+ "infer_steps": 4,
+ "target_fps": 16,
+ "video_duration": 360,
+ "audio_sr": 16000,
+ "target_video_length": 81,
+ "resize_mode": "adaptive",
+ "self_attn_1_type": "sage_attn2",
+ "cross_attn_1_type": "sage_attn2",
+ "cross_attn_2_type": "sage_attn2",
+ "sample_guide_scale": 1.0,
+ "sample_shift": 5,
+ "enable_cfg": false,
+ "cpu_offload": false,
+ "use_31_block": false,
+ "parallel": {
+ "seq_p_size": 8,
+ "seq_p_attn_type": "ulysses"
+ },
+ "dit_quantized": true,
+ "dit_quant_scheme": "fp8-sgl",
+ "adapter_quantized": true,
+ "adapter_quant_scheme": "fp8-sgl",
+ "t5_quantized": true,
+ "t5_quant_scheme": "fp8-sgl"
+}
diff --git a/configs/seko_talk/seko_talk_05_offload_fp8_4090.json b/configs/seko_talk/seko_talk_05_offload_fp8_4090.json
new file mode 100644
index 0000000000000000000000000000000000000000..96f8629d1c3a2e7614ed54eb51b0a8171784743a
--- /dev/null
+++ b/configs/seko_talk/seko_talk_05_offload_fp8_4090.json
@@ -0,0 +1,32 @@
+{
+ "infer_steps": 4,
+ "target_fps": 16,
+ "video_duration": 360,
+ "audio_sr": 16000,
+ "target_video_length": 81,
+ "resize_mode": "adaptive",
+ "self_attn_1_type": "sage_attn2",
+ "cross_attn_1_type": "sage_attn2",
+ "cross_attn_2_type": "sage_attn2",
+ "sample_guide_scale": 1,
+ "sample_shift": 5,
+ "enable_cfg": false,
+ "use_31_block": false,
+ "cpu_offload": true,
+ "offload_granularity": "block",
+ "offload_ratio": 1,
+ "t5_cpu_offload": false,
+ "t5_quantized": true,
+ "t5_quant_scheme": "fp8-q8f",
+ "clip_cpu_offload": false,
+ "clip_quantized": true,
+ "clip_quant_scheme": "fp8-q8f",
+ "audio_encoder_cpu_offload": false,
+ "audio_adapter_cpu_offload": false,
+ "adapter_quantized": true,
+ "adapter_quant_scheme": "fp8-q8f",
+ "vae_cpu_offload": false,
+ "use_tiling_vae": false,
+ "dit_quantized": true,
+ "dit_quant_scheme": "fp8-q8f"
+}
diff --git a/configs/seko_talk/seko_talk_05_offload_fp8_4090_dist.json b/configs/seko_talk/seko_talk_05_offload_fp8_4090_dist.json
new file mode 100644
index 0000000000000000000000000000000000000000..a2d66f64d4c78b4b131960624780c83f8ed4fa22
--- /dev/null
+++ b/configs/seko_talk/seko_talk_05_offload_fp8_4090_dist.json
@@ -0,0 +1,36 @@
+{
+ "infer_steps": 4,
+ "target_fps": 16,
+ "video_duration": 360,
+ "audio_sr": 16000,
+ "target_video_length": 81,
+ "resize_mode": "adaptive",
+ "self_attn_1_type": "sage_attn2",
+ "cross_attn_1_type": "sage_attn2",
+ "cross_attn_2_type": "sage_attn2",
+ "sample_guide_scale": 1,
+ "sample_shift": 5,
+ "enable_cfg": false,
+ "use_31_block": false,
+ "cpu_offload": true,
+ "offload_granularity": "block",
+ "offload_ratio": 1,
+ "t5_cpu_offload": false,
+ "t5_quantized": true,
+ "t5_quant_scheme": "fp8-q8f",
+ "clip_cpu_offload": false,
+ "clip_quantized": true,
+ "clip_quant_scheme": "fp8-q8f",
+ "audio_encoder_cpu_offload": false,
+ "audio_adapter_cpu_offload": false,
+ "adapter_quantized": true,
+ "adapter_quant_scheme": "fp8-q8f",
+ "vae_cpu_offload": false,
+ "use_tiling_vae": false,
+ "dit_quantized": true,
+ "dit_quant_scheme": "fp8-q8f",
+ "parallel": {
+ "seq_p_size": 8,
+ "seq_p_attn_type": "ulysses-4090"
+ }
+}
diff --git a/configs/seko_talk/seko_talk_06_offload_fp8_H100.json b/configs/seko_talk/seko_talk_06_offload_fp8_H100.json
new file mode 100644
index 0000000000000000000000000000000000000000..d5a5ae9b3948234a362576a886ead22a2e0a43df
--- /dev/null
+++ b/configs/seko_talk/seko_talk_06_offload_fp8_H100.json
@@ -0,0 +1,30 @@
+{
+ "infer_steps": 4,
+ "target_fps": 16,
+ "video_duration": 360,
+ "audio_sr": 16000,
+ "target_video_length": 81,
+ "resize_mode": "adaptive",
+ "self_attn_1_type": "sage_attn2",
+ "cross_attn_1_type": "sage_attn2",
+ "cross_attn_2_type": "sage_attn2",
+ "sample_guide_scale": 1,
+ "sample_shift": 5,
+ "enable_cfg": false,
+ "use_31_block": false,
+ "cpu_offload": true,
+ "offload_granularity": "block",
+ "offload_ratio": 1,
+ "t5_cpu_offload": true,
+ "t5_quantized": true,
+ "t5_quant_scheme": "fp8-sgl",
+ "clip_cpu_offload": false,
+ "audio_encoder_cpu_offload": false,
+ "audio_adapter_cpu_offload": false,
+ "adapter_quantized": true,
+ "adapter_quant_scheme": "fp8-sgl",
+ "vae_cpu_offload": false,
+ "use_tiling_vae": false,
+ "dit_quantized": true,
+ "dit_quant_scheme": "fp8-sgl"
+}
diff --git a/configs/seko_talk/seko_talk_07_dist_offload.json b/configs/seko_talk/seko_talk_07_dist_offload.json
new file mode 100644
index 0000000000000000000000000000000000000000..b6a64eaa5c67e2b1c83b6cb0287b85496a9816bf
--- /dev/null
+++ b/configs/seko_talk/seko_talk_07_dist_offload.json
@@ -0,0 +1,28 @@
+{
+ "infer_steps": 4,
+ "target_fps": 16,
+ "video_duration": 360,
+ "audio_sr": 16000,
+ "target_video_length": 81,
+ "resize_mode": "adaptive",
+ "self_attn_1_type": "flash_attn3",
+ "cross_attn_1_type": "flash_attn3",
+ "cross_attn_2_type": "flash_attn3",
+ "sample_guide_scale": 1.0,
+ "sample_shift": 5,
+ "enable_cfg": false,
+ "use_31_block": false,
+ "parallel": {
+ "seq_p_size": 4,
+ "seq_p_attn_type": "ulysses"
+ },
+ "cpu_offload": true,
+ "offload_granularity": "block",
+ "t5_cpu_offload": true,
+ "clip_cpu_offload": false,
+ "vae_cpu_offload": false,
+ "offload_ratio": 1,
+ "use_tiling_vae": true,
+ "audio_encoder_cpu_offload": true,
+ "audio_adapter_cpu_offload": false
+}
diff --git a/configs/seko_talk/seko_talk_08_5B_base.json b/configs/seko_talk/seko_talk_08_5B_base.json
new file mode 100644
index 0000000000000000000000000000000000000000..855670fd5827e2ad0e39c8f557b28e2f444d01df
--- /dev/null
+++ b/configs/seko_talk/seko_talk_08_5B_base.json
@@ -0,0 +1,31 @@
+{
+ "infer_steps": 4,
+ "target_fps": 24,
+ "video_duration": 360,
+ "audio_sr": 16000,
+ "target_video_length": 121,
+ "resize_mode": "adaptive",
+ "text_len": 512,
+ "num_channels_latents": 48,
+ "vae_stride": [
+ 4,
+ 16,
+ 16
+ ],
+ "self_attn_1_type": "flash_attn3",
+ "cross_attn_1_type": "flash_attn3",
+ "cross_attn_2_type": "flash_attn3",
+ "sample_guide_scale": 1.0,
+ "sample_shift": 5.0,
+ "enable_cfg": false,
+ "cpu_offload": false,
+ "fps": 24,
+ "use_image_encoder": false,
+ "use_31_block": false,
+ "lora_configs": [
+ {
+ "path": "/mnt/aigc/rtxiang/pretrain/qianhai_weights/lora_model.safetensors",
+ "strength": 0.125
+ }
+ ]
+}
diff --git a/configs/seko_talk/seko_talk_09_base_fixed_min_area.json b/configs/seko_talk/seko_talk_09_base_fixed_min_area.json
new file mode 100644
index 0000000000000000000000000000000000000000..2b04ae5ee3c1c4f6a0b54a3c8f9044e05cd2ea0e
--- /dev/null
+++ b/configs/seko_talk/seko_talk_09_base_fixed_min_area.json
@@ -0,0 +1,16 @@
+{
+ "infer_steps": 4,
+ "target_fps": 16,
+ "video_duration": 360,
+ "audio_sr": 16000,
+ "target_video_length": 81,
+ "resize_mode": "fixed_min_area",
+ "self_attn_1_type": "flash_attn3",
+ "cross_attn_1_type": "flash_attn3",
+ "cross_attn_2_type": "flash_attn3",
+ "sample_guide_scale": 1.0,
+ "sample_shift": 5,
+ "enable_cfg": false,
+ "cpu_offload": false,
+ "use_31_block": false
+}
diff --git a/configs/seko_talk/seko_talk_10_fp8_dist_fixed_min_area.json b/configs/seko_talk/seko_talk_10_fp8_dist_fixed_min_area.json
new file mode 100644
index 0000000000000000000000000000000000000000..27f8afe412df886de87aff1dbcd1a9bb465a1037
--- /dev/null
+++ b/configs/seko_talk/seko_talk_10_fp8_dist_fixed_min_area.json
@@ -0,0 +1,26 @@
+{
+ "infer_steps": 4,
+ "target_fps": 16,
+ "video_duration": 360,
+ "audio_sr": 16000,
+ "target_video_length": 81,
+ "resize_mode": "fixed_min_area",
+ "self_attn_1_type": "sage_attn2",
+ "cross_attn_1_type": "sage_attn2",
+ "cross_attn_2_type": "sage_attn2",
+ "sample_guide_scale": 1.0,
+ "sample_shift": 5,
+ "enable_cfg": false,
+ "cpu_offload": false,
+ "use_31_block": false,
+ "parallel": {
+ "seq_p_size": 4,
+ "seq_p_attn_type": "ulysses"
+ },
+ "dit_quantized": true,
+ "dit_quant_scheme": "fp8-sgl",
+ "adapter_quantized": true,
+ "adapter_quant_scheme": "fp8-sgl",
+ "t5_quantized": true,
+ "t5_quant_scheme": "fp8-sgl"
+}
diff --git a/configs/seko_talk/seko_talk_11_fp8_dist_fixed_shape.json b/configs/seko_talk/seko_talk_11_fp8_dist_fixed_shape.json
new file mode 100644
index 0000000000000000000000000000000000000000..0ea9de6f852dd2b09cce33976b77181a9de949c6
--- /dev/null
+++ b/configs/seko_talk/seko_talk_11_fp8_dist_fixed_shape.json
@@ -0,0 +1,30 @@
+{
+ "infer_steps": 4,
+ "target_fps": 16,
+ "video_duration": 360,
+ "audio_sr": 16000,
+ "target_video_length": 81,
+ "resize_mode": "fixed_shape",
+ "fixed_shape": [
+ 240,
+ 320
+ ],
+ "self_attn_1_type": "sage_attn2",
+ "cross_attn_1_type": "sage_attn2",
+ "cross_attn_2_type": "sage_attn2",
+ "sample_guide_scale": 1.0,
+ "sample_shift": 5,
+ "enable_cfg": false,
+ "cpu_offload": false,
+ "use_31_block": false,
+ "parallel": {
+ "seq_p_size": 4,
+ "seq_p_attn_type": "ulysses"
+ },
+ "dit_quantized": true,
+ "dit_quant_scheme": "fp8-sgl",
+ "adapter_quantized": true,
+ "adapter_quant_scheme": "fp8-sgl",
+ "t5_quantized": true,
+ "t5_quant_scheme": "fp8-sgl"
+}
diff --git a/configs/seko_talk/seko_talk_12_fp8_dist_fixed_shape_8gpus_1s.json b/configs/seko_talk/seko_talk_12_fp8_dist_fixed_shape_8gpus_1s.json
new file mode 100644
index 0000000000000000000000000000000000000000..6952e86f1e592926ee0546af99efc82ffad678c0
--- /dev/null
+++ b/configs/seko_talk/seko_talk_12_fp8_dist_fixed_shape_8gpus_1s.json
@@ -0,0 +1,31 @@
+{
+ "infer_steps": 4,
+ "target_fps": 16,
+ "video_duration": 360,
+ "audio_sr": 16000,
+ "target_video_length": 17,
+ "prev_frame_length": 1,
+ "resize_mode": "fixed_shape",
+ "fixed_shape": [
+ 480,
+ 480
+ ],
+ "self_attn_1_type": "flash_attn3",
+ "cross_attn_1_type": "flash_attn3",
+ "cross_attn_2_type": "flash_attn3",
+ "sample_guide_scale": 1.0,
+ "sample_shift": 5,
+ "enable_cfg": false,
+ "cpu_offload": false,
+ "use_31_block": false,
+ "parallel": {
+ "seq_p_size": 8,
+ "seq_p_attn_type": "ulysses"
+ },
+ "dit_quantized": true,
+ "dit_quant_scheme": "fp8-sgl",
+ "adapter_quantized": true,
+ "adapter_quant_scheme": "fp8-sgl",
+ "t5_quantized": true,
+ "t5_quant_scheme": "fp8-sgl"
+}
diff --git a/configs/seko_talk/seko_talk_13_fp8_dist_bucket_shape_8gpus_5s_realtime.json b/configs/seko_talk/seko_talk_13_fp8_dist_bucket_shape_8gpus_5s_realtime.json
new file mode 100644
index 0000000000000000000000000000000000000000..7c9abea232a2894375a0a8186d0881df8864c2ab
--- /dev/null
+++ b/configs/seko_talk/seko_talk_13_fp8_dist_bucket_shape_8gpus_5s_realtime.json
@@ -0,0 +1,62 @@
+{
+ "infer_steps": 4,
+ "target_fps": 16,
+ "video_duration": 360,
+ "audio_sr": 16000,
+ "target_video_length": 81,
+ "resize_mode": "adaptive",
+ "bucket_shape": {
+ "0.667": [
+ [
+ 480,
+ 832
+ ],
+ [
+ 544,
+ 960
+ ]
+ ],
+ "1.500": [
+ [
+ 832,
+ 480
+ ],
+ [
+ 960,
+ 544
+ ]
+ ],
+ "1.000": [
+ [
+ 480,
+ 480
+ ],
+ [
+ 576,
+ 576
+ ],
+ [
+ 704,
+ 704
+ ]
+ ]
+ },
+ "self_attn_1_type": "sage_attn2",
+ "cross_attn_1_type": "sage_attn2",
+ "cross_attn_2_type": "sage_attn2",
+ "sample_guide_scale": 1.0,
+ "sample_shift": 5,
+ "enable_cfg": false,
+ "cpu_offload": false,
+ "use_31_block": false,
+ "parallel": {
+ "seq_p_size": 8,
+ "seq_p_attn_type": "ulysses"
+ },
+ "dit_quantized": true,
+ "dit_quant_scheme": "fp8-sgl",
+ "adapter_quantized": true,
+ "adapter_quant_scheme": "fp8-sgl",
+ "t5_quantized": true,
+ "t5_quant_scheme": "fp8-sgl"
+}
diff --git a/configs/seko_talk/seko_talk_14_fp8_dist_bucket_shape_8gpus_1s_realtime.json b/configs/seko_talk/seko_talk_14_fp8_dist_bucket_shape_8gpus_1s_realtime.json
new file mode 100644
index 0000000000000000000000000000000000000000..9ad4fd7330a0f71d17c9100ca54cb96430fb0cd8
--- /dev/null
+++ b/configs/seko_talk/seko_talk_14_fp8_dist_bucket_shape_8gpus_1s_realtime.json
@@ -0,0 +1,63 @@
+{
+ "infer_steps": 4,
+ "target_fps": 16,
+ "video_duration": 360,
+ "audio_sr": 16000,
+ "target_video_length": 17,
+ "prev_frame_length": 1,
+ "resize_mode": "adaptive",
+ "bucket_shape": {
+ "0.667": [
+ [
+ 480,
+ 832
+ ],
+ [
+ 544,
+ 960
+ ]
+ ],
+ "1.500": [
+ [
+ 832,
+ 480
+ ],
+ [
+ 960,
+ 544
+ ]
+ ],
+ "1.000": [
+ [
+ 480,
+ 480
+ ],
+ [
+ 576,
+ 576
+ ],
+ [
+ 704,
+ 704
+ ]
+ ]
+ },
+ "self_attn_1_type": "flash_attn3",
+ "cross_attn_1_type": "flash_attn3",
+ "cross_attn_2_type": "flash_attn3",
+ "sample_guide_scale": 1.0,
+ "sample_shift": 5,
+ "enable_cfg": false,
+ "cpu_offload": false,
+ "use_31_block": false,
+ "parallel": {
+ "seq_p_size": 8,
+ "seq_p_attn_type": "ulysses"
+ },
+ "dit_quantized": true,
+ "dit_quant_scheme": "fp8-sgl",
+ "adapter_quantized": true,
+ "adapter_quant_scheme": "fp8-sgl",
+ "t5_quantized": true,
+ "t5_quant_scheme": "fp8-sgl"
+}
diff --git a/configs/seko_talk/seko_talk_15_base_compile.json b/configs/seko_talk/seko_talk_15_base_compile.json
new file mode 100644
index 0000000000000000000000000000000000000000..19547bc498b76474a1904ef6a8c095143153c795
--- /dev/null
+++ b/configs/seko_talk/seko_talk_15_base_compile.json
@@ -0,0 +1,59 @@
+{
+ "infer_steps": 4,
+ "target_fps": 16,
+ "video_duration": 360,
+ "audio_sr": 16000,
+ "target_video_length": 81,
+ "resize_mode": "adaptive",
+ "self_attn_1_type": "flash_attn3",
+ "cross_attn_1_type": "flash_attn3",
+ "cross_attn_2_type": "flash_attn3",
+ "sample_guide_scale": 1.0,
+ "sample_shift": 5,
+ "enable_cfg": false,
+ "cpu_offload": false,
+ "use_31_block": false,
+ "compile": true,
+ "compile_shapes": [
+ [
+ 480,
+ 832
+ ],
+ [
+ 544,
+ 960
+ ],
+ [
+ 720,
+ 1280
+ ],
+ [
+ 832,
+ 480
+ ],
+ [
+ 960,
+ 544
+ ],
+ [
+ 1280,
+ 720
+ ],
+ [
+ 480,
+ 480
+ ],
+ [
+ 576,
+ 576
+ ],
+ [
+ 704,
+ 704
+ ],
+ [
+ 960,
+ 960
+ ]
+ ]
+}
diff --git a/configs/seko_talk/seko_talk_16_fp8_dist_compile.json b/configs/seko_talk/seko_talk_16_fp8_dist_compile.json
new file mode 100644
index 0000000000000000000000000000000000000000..f2ef9e412c96358f7343ac3a938fe77a06658cfc
--- /dev/null
+++ b/configs/seko_talk/seko_talk_16_fp8_dist_compile.json
@@ -0,0 +1,71 @@
+{
+ "infer_steps": 4,
+ "target_fps": 16,
+ "video_duration": 360,
+ "audio_sr": 16000,
+ "target_video_length": 81,
+ "resize_mode": "adaptive",
+ "self_attn_1_type": "sage_attn2",
+ "cross_attn_1_type": "sage_attn2",
+ "cross_attn_2_type": "sage_attn2",
+ "sample_guide_scale": 1.0,
+ "sample_shift": 5,
+ "enable_cfg": false,
+ "cpu_offload": false,
+ "use_31_block": false,
+ "parallel": {
+ "seq_p_size": 8,
+ "seq_p_attn_type": "ulysses"
+ },
+ "clip_quantized": true,
+ "clip_quant_scheme": "fp8-sgl",
+ "dit_quantized": true,
+ "dit_quant_scheme": "fp8-sgl",
+ "adapter_quantized": true,
+ "adapter_quant_scheme": "fp8-sgl",
+ "t5_quantized": true,
+ "t5_quant_scheme": "fp8-sgl",
+ "compile": true,
+ "compile_shapes": [
+ [
+ 480,
+ 832
+ ],
+ [
+ 544,
+ 960
+ ],
+ [
+ 720,
+ 1280
+ ],
+ [
+ 832,
+ 480
+ ],
+ [
+ 960,
+ 544
+ ],
+ [
+ 1280,
+ 720
+ ],
+ [
+ 480,
+ 480
+ ],
+ [
+ 576,
+ 576
+ ],
+ [
+ 704,
+ 704
+ ],
+ [
+ 960,
+ 960
+ ]
+ ]
+}
diff --git a/configs/seko_talk/seko_talk_17_base_vsr.json b/configs/seko_talk/seko_talk_17_base_vsr.json
new file mode 100644
index 0000000000000000000000000000000000000000..7f39cc56842a2d68120419afdb67cef7ad5df105
--- /dev/null
+++ b/configs/seko_talk/seko_talk_17_base_vsr.json
@@ -0,0 +1,25 @@
+{
+ "infer_steps": 2,
+ "target_fps": 25,
+ "video_duration": 1,
+ "audio_sr": 16000,
+ "target_video_length": 25,
+ "resize_mode": "fixed_shape",
+ "fixed_shape": [
+ 192,
+ 320
+ ],
+ "self_attn_1_type": "flash_attn3",
+ "cross_attn_1_type": "flash_attn3",
+ "cross_attn_2_type": "flash_attn3",
+ "sample_guide_scale": 1.0,
+ "sample_shift": 5,
+ "enable_cfg": false,
+ "cpu_offload": false,
+ "use_31_block": false,
+ "video_super_resolution": {
+ "scale": 2.0,
+ "seed": 0,
+ "model_path": "/base_code/FlashVSR/examples/WanVSR/FlashVSR"
+ }
+}
diff --git a/configs/seko_talk/seko_talk_22_nbhd_attn.json b/configs/seko_talk/seko_talk_22_nbhd_attn.json
new file mode 100644
index 0000000000000000000000000000000000000000..f1ad262450f66f208c2b019c30ef6eeda79b8b79
--- /dev/null
+++ b/configs/seko_talk/seko_talk_22_nbhd_attn.json
@@ -0,0 +1,16 @@
+{
+ "infer_steps": 4,
+ "target_fps": 16,
+ "video_duration": 360,
+ "audio_sr": 16000,
+ "target_video_length": 81,
+ "resize_mode": "adaptive",
+ "self_attn_1_type": "nbhd_attn",
+ "cross_attn_1_type": "flash_attn3",
+ "cross_attn_2_type": "flash_attn3",
+ "sample_guide_scale": 1.0,
+ "sample_shift": 5,
+ "enable_cfg": false,
+ "cpu_offload": false,
+ "use_31_block": false
+}
diff --git a/configs/seko_talk/seko_talk_23_fp8_dist_nbhd_attn.json b/configs/seko_talk/seko_talk_23_fp8_dist_nbhd_attn.json
new file mode 100644
index 0000000000000000000000000000000000000000..fba7ca4b8cf73f75501f2ac0476cc7afd045cdf4
--- /dev/null
+++ b/configs/seko_talk/seko_talk_23_fp8_dist_nbhd_attn.json
@@ -0,0 +1,28 @@
+{
+ "infer_steps": 4,
+ "target_fps": 16,
+ "video_duration": 360,
+ "audio_sr": 16000,
+ "target_video_length": 81,
+ "resize_mode": "adaptive",
+ "self_attn_1_type": "nbhd_attn",
+ "cross_attn_1_type": "flash_attn3",
+ "cross_attn_2_type": "flash_attn3",
+ "sample_guide_scale": 1.0,
+ "sample_shift": 5,
+ "enable_cfg": false,
+ "cpu_offload": false,
+ "use_31_block": false,
+ "parallel": {
+ "seq_p_size": 8,
+ "seq_p_attn_type": "ulysses"
+ },
+ "clip_quantized": true,
+ "clip_quant_scheme": "fp8-sgl",
+ "dit_quantized": true,
+ "dit_quant_scheme": "fp8-sgl",
+ "adapter_quantized": true,
+ "adapter_quant_scheme": "fp8-sgl",
+ "t5_quantized": true,
+ "t5_quant_scheme": "fp8-sgl"
+}
diff --git a/configs/seko_talk/seko_talk_24_fp8_dist_compile_nbhd_attn.json b/configs/seko_talk/seko_talk_24_fp8_dist_compile_nbhd_attn.json
new file mode 100644
index 0000000000000000000000000000000000000000..cc812be7e4d0a6343edb55d4e594716edaefd41b
--- /dev/null
+++ b/configs/seko_talk/seko_talk_24_fp8_dist_compile_nbhd_attn.json
@@ -0,0 +1,74 @@
+{
+ "infer_steps": 4,
+ "target_fps": 16,
+ "video_duration": 360,
+ "audio_sr": 16000,
+ "target_video_length": 81,
+ "resize_mode": "adaptive",
+ "self_attn_1_type": "nbhd_attn",
+ "nbhd_attn_setting": {
+ "coefficient": [1.0, 0.25, 0.056]
+ },
+ "cross_attn_1_type": "flash_attn3",
+ "cross_attn_2_type": "flash_attn3",
+ "sample_guide_scale": 1.0,
+ "sample_shift": 5,
+ "enable_cfg": false,
+ "cpu_offload": false,
+ "use_31_block": false,
+ "parallel": {
+ "seq_p_size": 8,
+ "seq_p_attn_type": "ulysses"
+ },
+ "clip_quantized": true,
+ "clip_quant_scheme": "fp8-sgl",
+ "dit_quantized": true,
+ "dit_quant_scheme": "fp8-sgl",
+ "adapter_quantized": true,
+ "adapter_quant_scheme": "fp8-sgl",
+ "t5_quantized": true,
+ "t5_quant_scheme": "fp8-sgl",
+ "compile": true,
+ "compile_shapes": [
+ [
+ 480,
+ 832
+ ],
+ [
+ 544,
+ 960
+ ],
+ [
+ 720,
+ 1280
+ ],
+ [
+ 832,
+ 480
+ ],
+ [
+ 960,
+ 544
+ ],
+ [
+ 1280,
+ 720
+ ],
+ [
+ 480,
+ 480
+ ],
+ [
+ 576,
+ 576
+ ],
+ [
+ 704,
+ 704
+ ],
+ [
+ 960,
+ 960
+ ]
+ ]
+}
diff --git a/configs/seko_talk/seko_talk_25_int8_dist_fp8_comm.json b/configs/seko_talk/seko_talk_25_int8_dist_fp8_comm.json
new file mode 100644
index 0000000000000000000000000000000000000000..a509d5efbf96c91c46808b069ec7e59435b14493
--- /dev/null
+++ b/configs/seko_talk/seko_talk_25_int8_dist_fp8_comm.json
@@ -0,0 +1,40 @@
+{
+ "infer_steps": 2,
+ "target_fps": 16,
+ "video_duration": 5,
+ "audio_sr": 16000,
+ "target_video_length": 81,
+ "self_attn_1_type": "sage_attn2",
+ "cross_attn_1_type": "sage_attn2",
+ "cross_attn_2_type": "sage_attn2",
+ "sample_guide_scale": 1,
+ "sample_shift": 5,
+ "enable_cfg": false,
+ "use_31_block": false,
+ "cpu_offload": false,
+ "offload_granularity": "block",
+ "offload_ratio": 1,
+ "t5_cpu_offload": true,
+ "t5_quantized": true,
+ "t5_quant_scheme": "int8-q8f",
+ "clip_cpu_offload": true,
+ "clip_quantized": false,
+ "audio_encoder_cpu_offload": true,
+ "audio_adapter_cpu_offload": true,
+ "adapter_quantized": true,
+ "adapter_quant_scheme": "int8-q8f",
+ "vae_cpu_offload": true,
+ "use_tiling_vae": false,
+ "dit_quantized": true,
+ "dit_quant_scheme": "int8-q8f",
+ "resize_mode": "fixed_shape",
+ "fixed_shape": [
+ 832,
+ 480
+ ],
+ "parallel": {
+ "seq_p_size": 8,
+ "seq_p_fp8_comm": true,
+ "seq_p_attn_type": "ulysses-4090"
+ }
+}
diff --git a/configs/seko_talk/seko_talk_28_f2v.json b/configs/seko_talk/seko_talk_28_f2v.json
new file mode 100644
index 0000000000000000000000000000000000000000..cf9bebdfa90eb0efd164da7924f2cd022446b03a
--- /dev/null
+++ b/configs/seko_talk/seko_talk_28_f2v.json
@@ -0,0 +1,24 @@
+{
+ "infer_steps": 4,
+ "target_fps": 16,
+ "video_duration": 12,
+ "audio_sr": 16000,
+ "target_video_length": 81,
+ "prev_frame_length": 1,
+ "resize_mode": "adaptive",
+ "self_attn_1_type": "flash_attn3",
+ "cross_attn_1_type": "flash_attn3",
+ "cross_attn_2_type": "flash_attn3",
+ "sample_guide_scale": 1.0,
+ "sample_shift": 5,
+ "enable_cfg": false,
+ "cpu_offload": false,
+ "use_31_block": false,
+ "f2v_process": true,
+ "lora_configs": [
+ {
+ "path": "lightx2v_I2V_14B_480p_cfg_step_distill_rank32_bf16.safetensors",
+ "strength": 1.0
+ }
+ ]
+}
diff --git a/configs/self_forcing/wan_t2v_sf.json b/configs/self_forcing/wan_t2v_sf.json
new file mode 100644
index 0000000000000000000000000000000000000000..df541f92c8fbf80554fef6a7227648d59ded74f4
--- /dev/null
+++ b/configs/self_forcing/wan_t2v_sf.json
@@ -0,0 +1,26 @@
+{
+ "infer_steps": 50,
+ "target_video_length": 81,
+ "text_len": 512,
+ "target_height": 480,
+ "target_width": 832,
+ "self_attn_1_type": "flash_attn2",
+ "cross_attn_1_type": "flash_attn2",
+ "cross_attn_2_type": "flash_attn2",
+ "seed": 0,
+ "sample_guide_scale": 6,
+ "sample_shift": 8,
+ "enable_cfg": false,
+ "cpu_offload": false,
+ "sf_config": {
+ "sf_type": "dmd",
+ "local_attn_size": -1,
+ "shift": 5.0,
+ "num_frame_per_block": 3,
+ "num_transformer_blocks": 30,
+ "frame_seq_length": 1560,
+ "num_output_frames": 21,
+ "num_inference_steps": 1000,
+ "denoising_step_list": [1000.0000, 937.5000, 833.3333, 625.0000]
+ }
+}
diff --git a/configs/sparse_attn/spas_sage_attn/wan_i2v.json b/configs/sparse_attn/spas_sage_attn/wan_i2v.json
new file mode 100644
index 0000000000000000000000000000000000000000..5fffe94bb689118c5123c486d2849559d2174b55
--- /dev/null
+++ b/configs/sparse_attn/spas_sage_attn/wan_i2v.json
@@ -0,0 +1,13 @@
+{
+ "infer_steps": 40,
+ "target_video_length": 81,
+ "target_height": 480,
+ "target_width": 832,
+ "self_attn_1_type": "sage_attn",
+ "cross_attn_1_type": "sage_attn",
+ "cross_attn_2_type": "sage_attn",
+ "sample_guide_scale": 5,
+ "sample_shift": 3,
+ "enable_cfg": true,
+ "cpu_offload": false
+}
diff --git a/configs/sparse_attn/spas_sage_attn/wan_t2v.json b/configs/sparse_attn/spas_sage_attn/wan_t2v.json
new file mode 100644
index 0000000000000000000000000000000000000000..d2d045647a86d2d3afef015936936c3867b66b43
--- /dev/null
+++ b/configs/sparse_attn/spas_sage_attn/wan_t2v.json
@@ -0,0 +1,14 @@
+{
+ "infer_steps": 50,
+ "target_video_length": 81,
+ "text_len": 512,
+ "target_height": 480,
+ "target_width": 832,
+ "self_attn_1_type": "spas_sage_attn",
+ "cross_attn_1_type": "spas_sage_attn",
+ "cross_attn_2_type": "spas_sage_attn",
+ "sample_guide_scale": 6,
+ "sample_shift": 8,
+ "enable_cfg": true,
+ "cpu_offload": false
+}
diff --git a/configs/video_frame_interpolation/wan_t2v.json b/configs/video_frame_interpolation/wan_t2v.json
new file mode 100644
index 0000000000000000000000000000000000000000..02cc5498142a3f1be298cf02cba5faf615fe7e1b
--- /dev/null
+++ b/configs/video_frame_interpolation/wan_t2v.json
@@ -0,0 +1,19 @@
+{
+ "infer_steps": 50,
+ "target_video_length": 81,
+ "text_len": 512,
+ "target_height": 480,
+ "target_width": 832,
+ "self_attn_1_type": "flash_attn3",
+ "cross_attn_1_type": "flash_attn3",
+ "cross_attn_2_type": "flash_attn3",
+ "sample_guide_scale": 6,
+ "sample_shift": 8,
+ "enable_cfg": true,
+ "cpu_offload": false,
+ "video_frame_interpolation": {
+ "algo": "rife",
+ "target_fps": 24,
+ "model_path": "/path to flownet.pkl"
+ }
+}
diff --git a/configs/volcengine_voices_list.json b/configs/volcengine_voices_list.json
new file mode 100644
index 0000000000000000000000000000000000000000..51316103a23d05e99cfdfa6328104c94dcc9b13b
--- /dev/null
+++ b/configs/volcengine_voices_list.json
@@ -0,0 +1,4727 @@
+{
+ "voices": [
+ {
+ "name": "Vivi 2.0",
+ "voice_type": "zh_female_vv_uranus_bigtts",
+ "gender": "female",
+ "version": "2.0",
+ "resource_id": "seed-tts-2.0",
+ "voice_category": "general",
+ "scene": "通用场景",
+ "language": [
+ "chinese",
+ "en_us"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "可爱女生",
+ "voice_type": "ICL_zh_female_keainvsheng_tob",
+ "gender": "female",
+ "version": "2.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "大壹",
+ "voice_type": "zh_male_dayi_saturn_bigtts",
+ "gender": "male",
+ "version": "2.0",
+ "resource_id": "seed-tts-2.0",
+ "voice_category": "video_dubbing",
+ "scene": "视频配音",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "魅力女友",
+ "voice_type": "ICL_zh_female_tiaopigongzhu_tob",
+ "gender": "female",
+ "version": "2.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "黑猫侦探社咪仔",
+ "voice_type": "zh_female_mizai_saturn_bigtts",
+ "gender": "female",
+ "version": "2.0",
+ "resource_id": "seed-tts-2.0",
+ "voice_category": "video_dubbing",
+ "scene": "视频配音",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "爽朗少年",
+ "voice_type": "ICL_zh_male_shuanglangshaonian_tob",
+ "gender": "male",
+ "version": "2.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "鸡汤女",
+ "voice_type": "zh_female_jitangnv_saturn_bigtts",
+ "gender": "female",
+ "version": "2.0",
+ "resource_id": "seed-tts-2.0",
+ "voice_category": "video_dubbing",
+ "scene": "视频配音",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "天才同桌",
+ "voice_type": "ICL_zh_male_tiancaitongzhuo_tob",
+ "gender": "male",
+ "version": "2.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "魅力女友",
+ "voice_type": "zh_female_meilinvyou_saturn_bigtts",
+ "gender": "female",
+ "version": "2.0",
+ "resource_id": "seed-tts-2.0",
+ "voice_category": "video_dubbing",
+ "scene": "视频配音",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "流畅女声",
+ "voice_type": "zh_female_santongyongns_saturn_bigtts",
+ "gender": "female",
+ "version": "2.0",
+ "resource_id": "seed-tts-2.0",
+ "voice_category": "video_dubbing",
+ "scene": "视频配音",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "儒雅逸辰",
+ "voice_type": "zh_male_ruyayichen_saturn_bigtts",
+ "gender": "male",
+ "version": "2.0",
+ "resource_id": "seed-tts-2.0",
+ "voice_category": "video_dubbing",
+ "scene": "视频配音",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "知性灿灿",
+ "voice_type": "saturn_zh_female_cancan_tob",
+ "gender": "female",
+ "version": "2.0",
+ "resource_id": "seed-tts-2.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "温柔女神",
+ "voice_type": "ICL_zh_female_wenrounvshen_239eff5e8ffa_tob",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "general",
+ "scene": "通用场景",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "沪普男",
+ "voice_type": "zh_male_hupunan_mars_bigtts",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "accent",
+ "scene": "趣味口音",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "纯真少女",
+ "voice_type": "ICL_zh_female_chunzhenshaonv_e588402fb8ad_tob",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "冷酷哥哥",
+ "voice_type": "zh_male_lengkugege_emo_v2_mars_bigtts",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "multi_emotion",
+ "scene": "多情感",
+ "language": [
+ "chinese"
+ ],
+ "emotions": [
+ "happy",
+ "sad",
+ "angry",
+ "fear",
+ "hate",
+ "coldness",
+ "neutral",
+ "depressed"
+ ]
+ },
+ {
+ "name": "理性圆子",
+ "voice_type": "ICL_zh_female_lixingyuanzi_cs",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "customer_service",
+ "scene": "客服场景",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "Tina老师",
+ "voice_type": "zh_female_yingyujiaoyu_mars_bigtts",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "general",
+ "scene": "教育场景",
+ "language": [
+ "chinese",
+ "en_gb"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "Lauren",
+ "voice_type": "en_female_lauren_moon_bigtts",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "multi_language",
+ "scene": "多语种",
+ "language": [
+ "en_us"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "内敛才俊",
+ "voice_type": "ICL_zh_male_neiliancaijun_e991be511569_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "audiobook",
+ "scene": "有声阅读",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "悠悠君子",
+ "voice_type": "zh_male_M100_conversation_wvae_bigtts",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "video_dubbing",
+ "scene": "视频配音",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "Vivi",
+ "voice_type": "zh_female_vv_mars_bigtts",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "general",
+ "scene": "通用场景",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "粤语小溏",
+ "voice_type": "zh_female_yueyunv_mars_bigtts",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "accent",
+ "scene": "趣味口音",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "奶气小生",
+ "voice_type": "ICL_zh_male_xiaonaigou_edf58cf28b8b_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "甜心小美",
+ "voice_type": "zh_female_tianxinxiaomei_emo_v2_mars_bigtts",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "multi_emotion",
+ "scene": "多情感",
+ "language": [
+ "chinese"
+ ],
+ "emotions": [
+ "sad",
+ "fear",
+ "hate",
+ "neutral"
+ ]
+ },
+ {
+ "name": "清甜桃桃",
+ "voice_type": "ICL_zh_female_qingtiantaotao_cs",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "customer_service",
+ "scene": "客服场景",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "Energetic Male II",
+ "voice_type": "en_male_campaign_jamal_moon_bigtts",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "multi_language",
+ "scene": "多语种",
+ "language": [
+ "en_us"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "温暖少年",
+ "voice_type": "ICL_zh_male_yangyang_v1_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "audiobook",
+ "scene": "有声阅读",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "文静毛毛",
+ "voice_type": "zh_female_maomao_conversation_wvae_bigtts",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "video_dubbing",
+ "scene": "视频配音",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "亲切女声",
+ "voice_type": "zh_female_qinqienvsheng_moon_bigtts",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "general",
+ "scene": "通用场景",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "鲁班七号",
+ "voice_type": "zh_male_lubanqihao_mars_bigtts",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "accent",
+ "scene": "趣味口音",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "精灵向导",
+ "voice_type": "ICL_zh_female_jinglingxiangdao_1beb294a9e3e_tob",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "高冷御姐",
+ "voice_type": "zh_female_gaolengyujie_emo_v2_mars_bigtts",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "multi_emotion",
+ "scene": "多情感",
+ "language": [
+ "chinese"
+ ],
+ "emotions": [
+ "happy",
+ "sad",
+ "angry",
+ "surprised",
+ "fear",
+ "hate",
+ "excited",
+ "coldness",
+ "neutral"
+ ]
+ },
+ {
+ "name": "清晰小雪",
+ "voice_type": "ICL_zh_female_qingxixiaoxue_cs",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "customer_service",
+ "scene": "客服场景",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "Gotham Hero",
+ "voice_type": "en_male_chris_moon_bigtts",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "multi_language",
+ "scene": "多语种",
+ "language": [
+ "en_us"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "儒雅公子",
+ "voice_type": "ICL_zh_male_flc_v1_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "audiobook",
+ "scene": "有声阅读",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "倾心少女",
+ "voice_type": "ICL_zh_female_qiuling_v1_tob",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "video_dubbing",
+ "scene": "视频配音",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "机灵小伙",
+ "voice_type": "ICL_zh_male_shenmi_v1_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "general",
+ "scene": "通用场景",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "林潇",
+ "voice_type": "zh_female_yangmi_mars_bigtts",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "accent",
+ "scene": "趣味口音",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "闷油瓶小哥",
+ "voice_type": "ICL_zh_male_menyoupingxiaoge_ffed9fc2fee7_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "傲娇霸总",
+ "voice_type": "zh_male_aojiaobazong_emo_v2_mars_bigtts",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "multi_emotion",
+ "scene": "多情感",
+ "language": [
+ "chinese"
+ ],
+ "emotions": [
+ "happy",
+ "angry",
+ "hate",
+ "neutral"
+ ]
+ },
+ {
+ "name": "清甜莓莓",
+ "voice_type": "ICL_zh_female_qingtianmeimei_cs",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "customer_service",
+ "scene": "客服场景",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "Flirty Female",
+ "voice_type": "en_female_product_darcie_moon_bigtts",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "multi_language",
+ "scene": "多语种",
+ "language": [
+ "en_us"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "悬疑解说",
+ "voice_type": "zh_male_changtianyi_mars_bigtts",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "audiobook",
+ "scene": "有声阅读",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "醇厚低音",
+ "voice_type": "ICL_zh_male_buyan_v1_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "video_dubbing",
+ "scene": "视频配音",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "元气甜妹",
+ "voice_type": "ICL_zh_female_wuxi_tob",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "general",
+ "scene": "通用场景",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "玲玲姐姐",
+ "voice_type": "zh_female_linzhiling_mars_bigtts",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "accent",
+ "scene": "趣味口音",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "黯刃秦主",
+ "voice_type": "ICL_zh_male_anrenqinzhu_cd62e63dcdab_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "广州德哥",
+ "voice_type": "zh_male_guangzhoudege_emo_mars_bigtts",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "multi_emotion",
+ "scene": "多情感",
+ "language": [
+ "chinese"
+ ],
+ "emotions": [
+ "angry",
+ "fear",
+ "neutral"
+ ]
+ },
+ {
+ "name": "开朗婷婷",
+ "voice_type": "ICL_zh_female_kailangtingting_cs",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "customer_service",
+ "scene": "客服场景",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "Peaceful Female",
+ "voice_type": "en_female_emotional_moon_bigtts",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "multi_language",
+ "scene": "多语种",
+ "language": [
+ "en_us"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "儒雅青年",
+ "voice_type": "zh_male_ruyaqingnian_mars_bigtts",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "audiobook",
+ "scene": "有声阅读",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "咆哮小哥",
+ "voice_type": "ICL_zh_male_BV144_paoxiaoge_v1_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "video_dubbing",
+ "scene": "视频配音",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "知心姐姐",
+ "voice_type": "ICL_zh_female_wenyinvsheng_v1_tob",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "general",
+ "scene": "通用场景",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "春日部姐姐",
+ "voice_type": "zh_female_jiyejizi2_mars_bigtts",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "accent",
+ "scene": "趣味口音",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "霸道总裁",
+ "voice_type": "ICL_zh_male_badaozongcai_v1_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "京腔侃爷",
+ "voice_type": "zh_male_jingqiangkanye_emo_mars_bigtts",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "multi_emotion",
+ "scene": "多情感",
+ "language": [
+ "chinese"
+ ],
+ "emotions": [
+ "happy",
+ "angry",
+ "surprised",
+ "hate",
+ "neutral"
+ ]
+ },
+ {
+ "name": "清新沐沐",
+ "voice_type": "ICL_zh_male_qingxinmumu_cs",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "customer_service",
+ "scene": "客服场景",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "Nara",
+ "voice_type": "en_female_nara_moon_bigtts",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "multi_language",
+ "scene": "多语种",
+ "language": [
+ "en_us"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "霸气青叔",
+ "voice_type": "zh_male_baqiqingshu_mars_bigtts",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "audiobook",
+ "scene": "有声阅读",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "和蔼奶奶",
+ "voice_type": "ICL_zh_female_heainainai_tob",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "video_dubbing",
+ "scene": "视频配音",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "阳光阿辰",
+ "voice_type": "zh_male_qingyiyuxuan_mars_bigtts",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "general",
+ "scene": "通用场景",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "唐僧",
+ "voice_type": "zh_male_tangseng_mars_bigtts",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "accent",
+ "scene": "趣味口音",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "妩媚可人",
+ "voice_type": "ICL_zh_female_ganli_v1_tob",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "邻居阿姨",
+ "voice_type": "zh_female_linjuayi_emo_v2_mars_bigtts",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "multi_emotion",
+ "scene": "多情感",
+ "language": [
+ "chinese"
+ ],
+ "emotions": [
+ "angry",
+ "surprised",
+ "coldness",
+ "neutral",
+ "depressed"
+ ]
+ },
+ {
+ "name": "爽朗小阳",
+ "voice_type": "ICL_zh_male_shuanglangxiaoyang_cs",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "customer_service",
+ "scene": "客服场景",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "Bruce",
+ "voice_type": "en_male_bruce_moon_bigtts",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "multi_language",
+ "scene": "多语种",
+ "language": [
+ "en_us"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "擎苍",
+ "voice_type": "zh_male_qingcang_mars_bigtts",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "audiobook",
+ "scene": "有声阅读",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "邻居阿姨",
+ "voice_type": "ICL_zh_female_linjuayi_tob",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "video_dubbing",
+ "scene": "视频配音",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "快乐小东",
+ "voice_type": "zh_male_xudong_conversation_wvae_bigtts",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "general",
+ "scene": "通用场景",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "庄周",
+ "voice_type": "zh_male_zhuangzhou_mars_bigtts",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "accent",
+ "scene": "趣味口音",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "邪魅御姐",
+ "voice_type": "ICL_zh_female_xiangliangya_v1_tob",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "优柔公子",
+ "voice_type": "zh_male_yourougongzi_emo_v2_mars_bigtts",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "multi_emotion",
+ "scene": "多情感",
+ "language": [
+ "chinese"
+ ],
+ "emotions": [
+ "happy",
+ "angry",
+ "fear",
+ "hate",
+ "excited",
+ "neutral",
+ "depressed"
+ ]
+ },
+ {
+ "name": "清新波波",
+ "voice_type": "ICL_zh_male_qingxinbobo_cs",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "customer_service",
+ "scene": "客服场景",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "Michael",
+ "voice_type": "en_male_michael_moon_bigtts",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "multi_language",
+ "scene": "多语种",
+ "language": [
+ "en_us"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "活力小哥",
+ "voice_type": "zh_male_yangguangqingnian_mars_bigtts",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "audiobook",
+ "scene": "有声阅读",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "温柔小雅",
+ "voice_type": "zh_female_wenrouxiaoya_moon_bigtts",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "video_dubbing",
+ "scene": "视频配音",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "冷酷哥哥",
+ "voice_type": "ICL_zh_male_lengkugege_v1_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "general",
+ "scene": "通用场景",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "猪八戒",
+ "voice_type": "zh_male_zhubajie_mars_bigtts",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "accent",
+ "scene": "趣味口音",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "嚣张小哥",
+ "voice_type": "ICL_zh_male_ms_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "儒雅男友",
+ "voice_type": "zh_male_ruyayichen_emo_v2_mars_bigtts",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "multi_emotion",
+ "scene": "多情感",
+ "language": [
+ "chinese"
+ ],
+ "emotions": [
+ "happy",
+ "sad",
+ "angry",
+ "fear",
+ "excited",
+ "coldness",
+ "neutral"
+ ]
+ },
+ {
+ "name": "温婉珊珊",
+ "voice_type": "ICL_zh_female_wenwanshanshan_cs",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "customer_service",
+ "scene": "客服场景",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "Cartoon Chef",
+ "voice_type": "ICL_en_male_cc_sha_v1_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "multi_language",
+ "scene": "多语种",
+ "language": [
+ "en_us"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "古风少御",
+ "voice_type": "zh_female_gufengshaoyu_mars_bigtts",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "audiobook",
+ "scene": "有声阅读",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "天才童声",
+ "voice_type": "zh_male_tiancaitongsheng_mars_bigtts",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "video_dubbing",
+ "scene": "视频配音",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "纯澈女生",
+ "voice_type": "ICL_zh_female_feicui_v1_tob",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "general",
+ "scene": "通用场景",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "感冒电音姐姐",
+ "voice_type": "zh_female_ganmaodianyin_mars_bigtts",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "accent",
+ "scene": "趣味口音",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "油腻大叔",
+ "voice_type": "ICL_zh_male_you_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "俊朗男友",
+ "voice_type": "zh_male_junlangnanyou_emo_v2_mars_bigtts",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "multi_emotion",
+ "scene": "多情感",
+ "language": [
+ "chinese"
+ ],
+ "emotions": [
+ "happy",
+ "sad",
+ "angry",
+ "surprised",
+ "fear",
+ "neutral"
+ ]
+ },
+ {
+ "name": "甜美小雨",
+ "voice_type": "ICL_zh_female_tianmeixiaoyu_cs_tob",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "customer_service",
+ "scene": "客服场景",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "Lucas",
+ "voice_type": "zh_male_M100_conversation_wvae_bigtts",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "multi_language",
+ "scene": "多语种",
+ "language": [
+ "en_us"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "温柔淑女",
+ "voice_type": "zh_female_wenroushunv_mars_bigtts",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "audiobook",
+ "scene": "有声阅读",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "猴哥",
+ "voice_type": "zh_male_sunwukong_mars_bigtts",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "video_dubbing",
+ "scene": "视频配音",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "初恋女友",
+ "voice_type": "ICL_zh_female_yuxin_v1_tob",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "general",
+ "scene": "通用场景",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "直率英子",
+ "voice_type": "zh_female_naying_mars_bigtts",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "accent",
+ "scene": "趣味口音",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "孤傲公子",
+ "voice_type": "ICL_zh_male_guaogongzi_v1_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "北京小爷",
+ "voice_type": "zh_male_beijingxiaoye_emo_v2_mars_bigtts",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "multi_emotion",
+ "scene": "多情感",
+ "language": [
+ "chinese"
+ ],
+ "emotions": [
+ "angry",
+ "surprised",
+ "fear",
+ "excited",
+ "coldness",
+ "neutral"
+ ]
+ },
+ {
+ "name": "热情艾娜",
+ "voice_type": "ICL_zh_female_reqingaina_cs_tob",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "customer_service",
+ "scene": "客服场景",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "Sophie",
+ "voice_type": "zh_female_sophie_conversation_wvae_bigtts",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "multi_language",
+ "scene": "多语种",
+ "language": [
+ "en_us"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "反卷青年",
+ "voice_type": "zh_male_fanjuanqingnian_mars_bigtts",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "audiobook",
+ "scene": "有声阅读",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "熊二",
+ "voice_type": "zh_male_xionger_mars_bigtts",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "video_dubbing",
+ "scene": "视频配音",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "贴心闺蜜",
+ "voice_type": "ICL_zh_female_xnx_tob",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "general",
+ "scene": "通用场景",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "女雷神",
+ "voice_type": "zh_female_leidian_mars_bigtts",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "accent",
+ "scene": "趣味口音",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "胡子叔叔",
+ "voice_type": "ICL_zh_male_huzi_v1_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "柔美女友",
+ "voice_type": "zh_female_roumeinvyou_emo_v2_mars_bigtts",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "multi_emotion",
+ "scene": "多情感",
+ "language": [
+ "chinese"
+ ],
+ "emotions": [
+ "happy",
+ "sad",
+ "angry",
+ "surprised",
+ "fear",
+ "hate",
+ "excited",
+ "coldness",
+ "neutral"
+ ]
+ },
+ {
+ "name": "甜美小橘",
+ "voice_type": "ICL_zh_female_tianmeixiaoju_cs_tob",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "customer_service",
+ "scene": "客服场景",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "Daisy",
+ "voice_type": "en_female_dacey_conversation_wvae_bigtts",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "multi_language",
+ "scene": "多语种",
+ "language": [
+ "en_us"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "佩奇猪",
+ "voice_type": "zh_female_peiqi_mars_bigtts",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "video_dubbing",
+ "scene": "视频配音",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "温柔白月光",
+ "voice_type": "ICL_zh_female_yry_tob",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "general",
+ "scene": "通用场景",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "豫州子轩",
+ "voice_type": "zh_male_yuzhouzixuan_moon_bigtts",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "accent",
+ "scene": "趣味口音",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "性感魅惑",
+ "voice_type": "ICL_zh_female_luoqing_v1_tob",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "阳光青年",
+ "voice_type": "zh_male_yangguangqingnian_emo_v2_mars_bigtts",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "multi_emotion",
+ "scene": "多情感",
+ "language": [
+ "chinese"
+ ],
+ "emotions": [
+ "happy",
+ "sad",
+ "angry",
+ "fear",
+ "excited",
+ "coldness",
+ "neutral"
+ ]
+ },
+ {
+ "name": "沉稳明仔",
+ "voice_type": "ICL_zh_male_chenwenmingzai_cs_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "customer_service",
+ "scene": "客服场景",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "Owen",
+ "voice_type": "en_male_charlie_conversation_wvae_bigtts",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "multi_language",
+ "scene": "多语种",
+ "language": [
+ "en_us"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "武则天",
+ "voice_type": "zh_female_wuzetian_mars_bigtts",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "video_dubbing",
+ "scene": "视频配音",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "开朗学长",
+ "voice_type": "en_male_jason_conversation_wvae_bigtts",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "general",
+ "scene": "通用场景",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "呆萌川妹",
+ "voice_type": "zh_female_daimengchuanmei_moon_bigtts",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "accent",
+ "scene": "趣味口音",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "病弱公子",
+ "voice_type": "ICL_zh_male_bingruogongzi_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "魅力女友",
+ "voice_type": "zh_female_meilinvyou_emo_v2_mars_bigtts",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "multi_emotion",
+ "scene": "多情感",
+ "language": [
+ "chinese"
+ ],
+ "emotions": [
+ "sad",
+ "fear",
+ "neutral"
+ ]
+ },
+ {
+ "name": "亲切小卓",
+ "voice_type": "ICL_zh_male_qinqiexiaozhuo_cs_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "customer_service",
+ "scene": "客服场景",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "Luna",
+ "voice_type": "en_female_sarah_new_conversation_wvae_bigtts",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "multi_language",
+ "scene": "多语种",
+ "language": [
+ "en_us"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "顾姐",
+ "voice_type": "zh_female_gujie_mars_bigtts",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "video_dubbing",
+ "scene": "视频配音",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "魅力苏菲",
+ "voice_type": "zh_female_sophie_conversation_wvae_bigtts",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "general",
+ "scene": "通用场景",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "广西远舟",
+ "voice_type": "zh_male_guangxiyuanzhou_moon_bigtts",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "accent",
+ "scene": "趣味口音",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "邪魅女王",
+ "voice_type": "ICL_zh_female_bingjiao3_tob",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "爽快思思",
+ "voice_type": "zh_female_shuangkuaisisi_emo_v2_mars_bigtts",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "multi_emotion",
+ "scene": "多情感",
+ "language": [
+ "chinese",
+ "en_gb"
+ ],
+ "emotions": [
+ "happy",
+ "sad",
+ "angry",
+ "surprised",
+ "excited",
+ "coldness",
+ "neutral"
+ ]
+ },
+ {
+ "name": "灵动欣欣",
+ "voice_type": "ICL_zh_female_lingdongxinxin_cs_tob",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "customer_service",
+ "scene": "客服场景",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "Michael",
+ "voice_type": "ICL_en_male_michael_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "multi_language",
+ "scene": "多语种",
+ "language": [
+ "en_us"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "樱桃丸子",
+ "voice_type": "zh_female_yingtaowanzi_mars_bigtts",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "video_dubbing",
+ "scene": "视频配音",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "贴心妹妹",
+ "voice_type": "ICL_zh_female_yilin_tob",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "general",
+ "scene": "通用场景",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "双节棍小哥",
+ "voice_type": "zh_male_zhoujielun_emo_v2_mars_bigtts",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "accent",
+ "scene": "趣味口音",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "傲慢青年",
+ "voice_type": "ICL_zh_male_aomanqingnian_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "Candice",
+ "voice_type": "en_female_candice_emo_v2_mars_bigtts",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "multi_emotion",
+ "scene": "多情感",
+ "language": [
+ "en_us"
+ ],
+ "emotions": [
+ "angry",
+ "neutral",
+ "ASMR",
+ "happy",
+ "chat",
+ "chat",
+ "warm",
+ "affectionate"
+ ]
+ },
+ {
+ "name": "乖巧可儿",
+ "voice_type": "ICL_zh_female_guaiqiaokeer_cs_tob",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "customer_service",
+ "scene": "客服场景",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "Charlie",
+ "voice_type": "ICL_en_female_cc_cm_v1_tob",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "multi_language",
+ "scene": "多语种",
+ "language": [
+ "en_us"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "广告解说",
+ "voice_type": "zh_male_chunhui_mars_bigtts",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "video_dubbing",
+ "scene": "视频配音",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "甜美桃子",
+ "voice_type": "zh_female_tianmeitaozi_mars_bigtts",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "general",
+ "scene": "通用场景",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "湾湾小何",
+ "voice_type": "zh_female_wanwanxiaohe_moon_bigtts",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "accent",
+ "scene": "趣味口音",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "醋精男生",
+ "voice_type": "ICL_zh_male_cujingnansheng_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "Serena",
+ "voice_type": "en_female_skye_emo_v2_mars_bigtts",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "multi_emotion",
+ "scene": "多情感",
+ "language": [
+ "en_us"
+ ],
+ "emotions": [
+ "sad",
+ "angry",
+ "neutral",
+ "ASMR",
+ "happy",
+ "chat",
+ "chat",
+ "warm",
+ "affectionate"
+ ]
+ },
+ {
+ "name": "暖心茜茜",
+ "voice_type": "ICL_zh_female_nuanxinqianqian_cs_tob",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "customer_service",
+ "scene": "客服场景",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "Big Boogie",
+ "voice_type": "ICL_en_male_oogie2_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "multi_language",
+ "scene": "多语种",
+ "language": [
+ "en_us"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "少儿故事",
+ "voice_type": "zh_female_shaoergushi_mars_bigtts",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "video_dubbing",
+ "scene": "视频配音",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "清新女声",
+ "voice_type": "zh_female_qingxinnvsheng_mars_bigtts",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "general",
+ "scene": "通用场景",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "湾区大叔",
+ "voice_type": "zh_female_wanqudashu_moon_bigtts",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "accent",
+ "scene": "趣味口音",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "撒娇男友",
+ "voice_type": "ICL_zh_male_sajiaonanyou_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "Glen",
+ "voice_type": "en_male_glen_emo_v2_mars_bigtts",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "multi_emotion",
+ "scene": "多情感",
+ "language": [
+ "en_us"
+ ],
+ "emotions": [
+ "sad",
+ "angry",
+ "neutral",
+ "ASMR",
+ "happy",
+ "chat",
+ "chat",
+ "warm",
+ "affectionate"
+ ]
+ },
+ {
+ "name": "软萌团子",
+ "voice_type": "ICL_zh_female_ruanmengtuanzi_cs_tob",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "customer_service",
+ "scene": "客服场景",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "Frosty Man",
+ "voice_type": "ICL_en_male_frosty1_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "multi_language",
+ "scene": "多语种",
+ "language": [
+ "en_us"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "四郎",
+ "voice_type": "zh_male_silang_mars_bigtts",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "video_dubbing",
+ "scene": "视频配音",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "知性女声",
+ "voice_type": "zh_female_zhixingnvsheng_mars_bigtts",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "general",
+ "scene": "通用场景",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "广州德哥",
+ "voice_type": "zh_male_guozhoudege_moon_bigtts",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "accent",
+ "scene": "趣味口音",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "温柔男友",
+ "voice_type": "ICL_zh_male_wenrounanyou_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "Sylus",
+ "voice_type": "en_male_sylus_emo_v2_mars_bigtts",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "multi_emotion",
+ "scene": "多情感",
+ "language": [
+ "en_us"
+ ],
+ "emotions": [
+ "sad",
+ "angry",
+ "neutral",
+ "ASMR",
+ "happy",
+ "chat",
+ "chat",
+ "warm",
+ "affectionate",
+ "authoritative"
+ ]
+ },
+ {
+ "name": "阳光洋洋",
+ "voice_type": "ICL_zh_male_yangguangyangyang_cs_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "customer_service",
+ "scene": "客服场景",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "The Grinch",
+ "voice_type": "ICL_en_male_grinch2_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "multi_language",
+ "scene": "多语种",
+ "language": [
+ "en_us"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "俏皮女声",
+ "voice_type": "zh_female_qiaopinvsheng_mars_bigtts",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "video_dubbing",
+ "scene": "视频配音",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "清爽男大",
+ "voice_type": "zh_male_qingshuangnanda_mars_bigtts",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "general",
+ "scene": "通用场景",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "浩宇小哥",
+ "voice_type": "zh_male_haoyuxiaoge_moon_bigtts",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "accent",
+ "scene": "趣味口音",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "温顺少年",
+ "voice_type": "ICL_zh_male_wenshunshaonian_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "Corey",
+ "voice_type": "en_male_corey_emo_v2_mars_bigtts",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "multi_emotion",
+ "scene": "多情感",
+ "language": [
+ "en_gb"
+ ],
+ "emotions": [
+ "sad",
+ "angry",
+ "neutral",
+ "ASMR",
+ "happy",
+ "chat",
+ "chat",
+ "warm",
+ "affectionate",
+ "authoritative"
+ ]
+ },
+ {
+ "name": "软萌糖糖",
+ "voice_type": "ICL_zh_female_ruanmengtangtang_cs_tob",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "customer_service",
+ "scene": "客服场景",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "Zayne",
+ "voice_type": "ICL_en_male_zayne_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "multi_language",
+ "scene": "多语种",
+ "language": [
+ "en_us"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "懒音绵宝",
+ "voice_type": "zh_male_lanxiaoyang_mars_bigtts",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "video_dubbing",
+ "scene": "视频配音",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "邻家女孩",
+ "voice_type": "zh_female_linjianvhai_moon_bigtts",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "general",
+ "scene": "通用场景",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "北京小爷",
+ "voice_type": "zh_male_beijingxiaoye_moon_bigtts",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "accent",
+ "scene": "趣味口音",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "粘人男友",
+ "voice_type": "ICL_zh_male_naigounanyou_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "Nadia",
+ "voice_type": "en_female_nadia_tips_emo_v2_mars_bigtts",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "multi_emotion",
+ "scene": "多情感",
+ "language": [
+ "en_gb"
+ ],
+ "emotions": [
+ "sad",
+ "angry",
+ "neutral",
+ "ASMR",
+ "happy",
+ "chat",
+ "chat",
+ "warm",
+ "affectionate"
+ ]
+ },
+ {
+ "name": "秀丽倩倩",
+ "voice_type": "ICL_zh_female_xiuliqianqian_cs_tob",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "customer_service",
+ "scene": "客服场景",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "Jigsaw",
+ "voice_type": "ICL_en_male_cc_jigsaw_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "multi_language",
+ "scene": "多语种",
+ "language": [
+ "en_us"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "亮嗓萌仔",
+ "voice_type": "zh_male_dongmanhaimian_mars_bigtts",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "video_dubbing",
+ "scene": "视频配音",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "渊博小叔",
+ "voice_type": "zh_male_yuanboxiaoshu_moon_bigtts",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "general",
+ "scene": "通用场景",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "京腔侃爷/Harmony",
+ "voice_type": "zh_male_jingqiangkanye_moon_bigtts",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "accent",
+ "scene": "趣味口音",
+ "language": [
+ "chinese",
+ "en_us"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "撒娇男生",
+ "voice_type": "ICL_zh_male_sajiaonansheng_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "开心小鸿",
+ "voice_type": "ICL_zh_female_kaixinxiaohong_cs_tob",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "customer_service",
+ "scene": "客服场景",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "Chucky",
+ "voice_type": "ICL_en_male_cc_chucky_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "multi_language",
+ "scene": "多语种",
+ "language": [
+ "en_us"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "磁性解说男声/Morgan",
+ "voice_type": "zh_male_jieshuonansheng_mars_bigtts",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "video_dubbing",
+ "scene": "视频配音",
+ "language": [
+ "chinese",
+ "en_us"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "阳光青年",
+ "voice_type": "zh_male_yangguangqingnian_moon_bigtts",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "general",
+ "scene": "通用场景",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "妹坨洁儿",
+ "voice_type": "zh_female_meituojieer_moon_bigtts",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "accent",
+ "scene": "趣味口音",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "活泼男友",
+ "voice_type": "ICL_zh_male_huoponanyou_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "轻盈朵朵",
+ "voice_type": "ICL_zh_female_qingyingduoduo_cs_tob",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "customer_service",
+ "scene": "客服场景",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "Clown Man",
+ "voice_type": "ICL_en_male_cc_penny_v1_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "multi_language",
+ "scene": "多语种",
+ "language": [
+ "en_us"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "鸡汤妹妹/Hope",
+ "voice_type": "zh_female_jitangmeimei_mars_bigtts",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "video_dubbing",
+ "scene": "视频配音",
+ "language": [
+ "chinese",
+ "en_us"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "甜美小源",
+ "voice_type": "zh_female_tianmeixiaoyuan_moon_bigtts",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "general",
+ "scene": "通用场景",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "甜系男友",
+ "voice_type": "ICL_zh_male_tianxinanyou_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "暖阳女声",
+ "voice_type": "zh_female_kefunvsheng_mars_bigtts",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "customer_service",
+ "scene": "客服场景",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "Kevin McCallister",
+ "voice_type": "ICL_en_male_kevin2_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "multi_language",
+ "scene": "多语种",
+ "language": [
+ "en_us"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "贴心女声/Candy",
+ "voice_type": "zh_female_tiexinnvsheng_mars_bigtts",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "video_dubbing",
+ "scene": "视频配音",
+ "language": [
+ "chinese",
+ "en_us"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "清澈梓梓",
+ "voice_type": "zh_female_qingchezizi_moon_bigtts",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "general",
+ "scene": "通用场景",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "活力青年",
+ "voice_type": "ICL_zh_male_huoliqingnian_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "Xavier",
+ "voice_type": "ICL_en_male_xavier1_v1_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "multi_language",
+ "scene": "多语种",
+ "language": [
+ "en_us"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "萌丫头/Cutey",
+ "voice_type": "zh_female_mengyatou_mars_bigtts",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "video_dubbing",
+ "scene": "视频配音",
+ "language": [
+ "chinese",
+ "en_us"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "解说小明",
+ "voice_type": "zh_male_jieshuoxiaoming_moon_bigtts",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "general",
+ "scene": "通用场景",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "开朗青年",
+ "voice_type": "ICL_zh_male_kailangqingnian_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "Noah",
+ "voice_type": "ICL_en_male_cc_dracula_v1_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "multi_language",
+ "scene": "多语种",
+ "language": [
+ "en_us"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "开朗姐姐",
+ "voice_type": "zh_female_kailangjiejie_moon_bigtts",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "general",
+ "scene": "通用场景",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "冷漠兄长",
+ "voice_type": "ICL_zh_male_lengmoxiongzhang_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "Adam",
+ "voice_type": "en_male_adam_mars_bigtts",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "multi_language",
+ "scene": "多语种",
+ "language": [
+ "en_us"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "邻家男孩",
+ "voice_type": "zh_male_linjiananhai_moon_bigtts",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "general",
+ "scene": "通用场景",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "翩翩公子",
+ "voice_type": "ICL_zh_male_pianpiangongzi_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "Amanda",
+ "voice_type": "en_female_amanda_mars_bigtts",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "multi_language",
+ "scene": "多语种",
+ "language": [
+ "en_us"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "甜美悦悦",
+ "voice_type": "zh_female_tianmeiyueyue_moon_bigtts",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "general",
+ "scene": "通用场景",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "懵懂青年",
+ "voice_type": "ICL_zh_male_mengdongqingnian_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "Jackson",
+ "voice_type": "en_male_jackson_mars_bigtts",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "multi_language",
+ "scene": "多语种",
+ "language": [
+ "en_us"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "心灵鸡汤",
+ "voice_type": "zh_female_xinlingjitang_moon_bigtts",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "general",
+ "scene": "通用场景",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "冷脸兄长",
+ "voice_type": "ICL_zh_male_lenglianxiongzhang_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "Delicate Girl",
+ "voice_type": "en_female_daisy_moon_bigtts",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "multi_language",
+ "scene": "多语种",
+ "language": [
+ "en_gb"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "知性温婉",
+ "voice_type": "ICL_zh_female_zhixingwenwan_tob",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "general",
+ "scene": "通用场景",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "病娇少年",
+ "voice_type": "ICL_zh_male_bingjiaoshaonian_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "Dave",
+ "voice_type": "en_male_dave_moon_bigtts",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "multi_language",
+ "scene": "多语种",
+ "language": [
+ "en_gb"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "暖心体贴",
+ "voice_type": "ICL_zh_male_nuanxintitie_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "general",
+ "scene": "通用场景",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "病娇男友",
+ "voice_type": "ICL_zh_male_bingjiaonanyou_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "Hades",
+ "voice_type": "en_male_hades_moon_bigtts",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "multi_language",
+ "scene": "多语种",
+ "language": [
+ "en_gb"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "开朗轻快",
+ "voice_type": "ICL_zh_male_kailangqingkuai_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "general",
+ "scene": "通用场景",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "病弱少年",
+ "voice_type": "ICL_zh_male_bingruoshaonian_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "Onez",
+ "voice_type": "en_female_onez_moon_bigtts",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "multi_language",
+ "scene": "多语种",
+ "language": [
+ "en_gb"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "活泼爽朗",
+ "voice_type": "ICL_zh_male_huoposhuanglang_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "general",
+ "scene": "通用场景",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "意气少年",
+ "voice_type": "ICL_zh_male_yiqishaonian_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "Emily",
+ "voice_type": "en_female_emily_mars_bigtts",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "multi_language",
+ "scene": "多语种",
+ "language": [
+ "en_gb"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "率真小伙",
+ "voice_type": "ICL_zh_male_shuaizhenxiaohuo_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "general",
+ "scene": "通用场景",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "干净少年",
+ "voice_type": "ICL_zh_male_ganjingshaonian_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "Daniel",
+ "voice_type": "zh_male_xudong_conversation_wvae_bigtts",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "multi_language",
+ "scene": "多语种",
+ "language": [
+ "en_gb"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "温柔小哥",
+ "voice_type": "zh_male_wenrouxiaoge_mars_bigtts",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "general",
+ "scene": "通用场景",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "冷漠男友",
+ "voice_type": "ICL_zh_male_lengmonanyou_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "Alastor",
+ "voice_type": "ICL_en_male_cc_alastor_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "multi_language",
+ "scene": "多语种",
+ "language": [
+ "en_gb"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "灿灿/Shiny",
+ "voice_type": "zh_female_cancan_mars_bigtts",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "general",
+ "scene": "通用场景",
+ "language": [
+ "chinese",
+ "en_us"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "精英青年",
+ "voice_type": "ICL_zh_male_jingyingqingnian_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "Smith",
+ "voice_type": "en_male_smith_mars_bigtts",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "multi_language",
+ "scene": "多语种",
+ "language": [
+ "en_gb"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "爽快思思/Skye",
+ "voice_type": "zh_female_shuangkuaisisi_moon_bigtts",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "general",
+ "scene": "通用场景",
+ "language": [
+ "chinese",
+ "en_us"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "热血少年",
+ "voice_type": "ICL_zh_male_rexueshaonian_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "Anna",
+ "voice_type": "en_female_anna_mars_bigtts",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "multi_language",
+ "scene": "多语种",
+ "language": [
+ "en_gb"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "温暖阿虎/Alvin",
+ "voice_type": "zh_male_wennuanahu_moon_bigtts",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "general",
+ "scene": "通用场景",
+ "language": [
+ "chinese",
+ "en_us"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "清爽少年",
+ "voice_type": "ICL_zh_male_qingshuangshaonian_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "Ethan",
+ "voice_type": "ICL_en_male_aussie_v1_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "multi_language",
+ "scene": "多语种",
+ "language": [
+ "en_au"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "少年梓辛/Brayan",
+ "voice_type": "zh_male_shaonianzixin_moon_bigtts",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "general",
+ "scene": "通用场景",
+ "language": [
+ "chinese",
+ "en_us"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "中二青年",
+ "voice_type": "ICL_zh_male_zhongerqingnian_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "Sarah",
+ "voice_type": "en_female_sarah_mars_bigtts",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "multi_language",
+ "scene": "多语种",
+ "language": [
+ "en_au"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "温柔文雅",
+ "voice_type": "ICL_zh_female_wenrouwenya_tob",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "general",
+ "scene": "通用场景",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "凌云青年",
+ "voice_type": "ICL_zh_male_lingyunqingnian_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "Dryw",
+ "voice_type": "en_male_dryw_mars_bigtts",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "multi_language",
+ "scene": "多语种",
+ "language": [
+ "en_au"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "自负青年",
+ "voice_type": "ICL_zh_male_zifuqingnian_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "Diana",
+ "voice_type": "multi_female_maomao_conversation_wvae_bigtts",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "multi_language",
+ "scene": "多语种",
+ "language": [
+ "es"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "不羁青年",
+ "voice_type": "ICL_zh_male_bujiqingnian_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "Lucía",
+ "voice_type": "multi_male_M100_conversation_wvae_bigtts",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "multi_language",
+ "scene": "多语种",
+ "language": [
+ "es"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "儒雅君子",
+ "voice_type": "ICL_zh_male_ruyajunzi_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "Sofía",
+ "voice_type": "multi_female_sophie_conversation_wvae_bigtts",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "multi_language",
+ "scene": "多语种",
+ "language": [
+ "es"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "低音沉郁",
+ "voice_type": "ICL_zh_male_diyinchenyu_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "Daníel",
+ "voice_type": "multi_male_xudong_conversation_wvae_bigtts",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "multi_language",
+ "scene": "多语种",
+ "language": [
+ "es"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "冷脸学霸",
+ "voice_type": "ICL_zh_male_lenglianxueba_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "ひかる(光)",
+ "voice_type": "multi_zh_male_youyoujunzi_moon_bigtts",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "multi_language",
+ "scene": "多语种",
+ "language": [
+ "ja"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "儒雅总裁",
+ "voice_type": "ICL_zh_male_ruyazongcai_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "さとみ(智美)",
+ "voice_type": "multi_female_sophie_conversation_wvae_bigtts",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "multi_language",
+ "scene": "多语种",
+ "language": [
+ "ja"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "深沉总裁",
+ "voice_type": "ICL_zh_male_shenchenzongcai_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "まさお(正男)",
+ "voice_type": "multi_male_xudong_conversation_wvae_bigtts",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "multi_language",
+ "scene": "多语种",
+ "language": [
+ "ja"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "小侯爷",
+ "voice_type": "ICL_zh_male_xiaohouye_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "つき(月)",
+ "voice_type": "multi_female_maomao_conversation_wvae_bigtts",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "multi_language",
+ "scene": "多语种",
+ "language": [
+ "ja"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "孤高公子",
+ "voice_type": "ICL_zh_male_gugaogongzi_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "あけみ(朱美)",
+ "voice_type": "multi_female_gaolengyujie_moon_bigtts",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "multi_language",
+ "scene": "多语种",
+ "language": [
+ "ja"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "仗剑君子",
+ "voice_type": "ICL_zh_male_zhangjianjunzi_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "かずね(和音)/Javier or Álvaro",
+ "voice_type": "multi_male_jingqiangkanye_moon_bigtts",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "multi_language",
+ "scene": "多语种",
+ "language": [
+ "ja",
+ "es"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "温润学者",
+ "voice_type": "ICL_zh_male_wenrunxuezhe_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "はるこ(晴子)/Esmeralda",
+ "voice_type": "multi_female_shuangkuaisisi_moon_bigtts",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "multi_language",
+ "scene": "多语种",
+ "language": [
+ "ja",
+ "es"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "亲切青年",
+ "voice_type": "ICL_zh_male_qinqieqingnian_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "ひろし(広志)/Roberto",
+ "voice_type": "multi_male_wanqudashu_moon_bigtts",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "multi_language",
+ "scene": "多语种",
+ "language": [
+ "ja",
+ "es"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "温柔学长",
+ "voice_type": "ICL_zh_male_wenrouxuezhang_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "高冷总裁",
+ "voice_type": "ICL_zh_male_gaolengzongcai_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "冷峻高智",
+ "voice_type": "ICL_zh_male_lengjungaozhi_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "孱弱少爷",
+ "voice_type": "ICL_zh_male_chanruoshaoye_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "自信青年",
+ "voice_type": "ICL_zh_male_zixinqingnian_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "青涩青年",
+ "voice_type": "ICL_zh_male_qingseqingnian_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "学霸同桌",
+ "voice_type": "ICL_zh_male_xuebatongzhuo_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "冷傲总裁",
+ "voice_type": "ICL_zh_male_lengaozongcai_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "元气少年",
+ "voice_type": "ICL_zh_male_yuanqishaonian_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "洒脱青年",
+ "voice_type": "ICL_zh_male_satuoqingnian_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "直率青年",
+ "voice_type": "ICL_zh_male_zhishuaiqingnian_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "斯文青年",
+ "voice_type": "ICL_zh_male_siwenqingnian_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "俊逸公子",
+ "voice_type": "ICL_zh_male_junyigongzi_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "仗剑侠客",
+ "voice_type": "ICL_zh_male_zhangjianxiake_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "机甲智能",
+ "voice_type": "ICL_zh_male_jijiaozhineng_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "奶气萌娃",
+ "voice_type": "zh_male_naiqimengwa_mars_bigtts",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "婆婆",
+ "voice_type": "zh_female_popo_mars_bigtts",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "高冷御姐",
+ "voice_type": "zh_female_gaolengyujie_moon_bigtts",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "傲娇霸总",
+ "voice_type": "zh_male_aojiaobazong_moon_bigtts",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "魅力女友",
+ "voice_type": "zh_female_meilinvyou_moon_bigtts",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "深夜播客",
+ "voice_type": "zh_male_shenyeboke_moon_bigtts",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "柔美女友",
+ "voice_type": "zh_female_sajiaonvyou_moon_bigtts",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "撒娇学妹",
+ "voice_type": "zh_female_yuanqinvyou_moon_bigtts",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "病弱少女",
+ "voice_type": "ICL_zh_female_bingruoshaonv_tob",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "活泼女孩",
+ "voice_type": "ICL_zh_female_huoponvhai_tob",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "东方浩然",
+ "voice_type": "zh_male_dongfanghaoran_moon_bigtts",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "绿茶小哥",
+ "voice_type": "ICL_zh_male_lvchaxiaoge_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "娇弱萝莉",
+ "voice_type": "ICL_zh_female_jiaoruoluoli_tob",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "冷淡疏离",
+ "voice_type": "ICL_zh_male_lengdanshuli_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "憨厚敦实",
+ "voice_type": "ICL_zh_male_hanhoudunshi_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "活泼刁蛮",
+ "voice_type": "ICL_zh_female_huopodiaoman_tob",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "固执病娇",
+ "voice_type": "ICL_zh_male_guzhibingjiao_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "撒娇粘人",
+ "voice_type": "ICL_zh_male_sajiaonianren_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "傲慢娇声",
+ "voice_type": "ICL_zh_female_aomanjiaosheng_tob",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "潇洒随性",
+ "voice_type": "ICL_zh_male_xiaosasuixing_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "诡异神秘",
+ "voice_type": "ICL_zh_male_guiyishenmi_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "儒雅才俊",
+ "voice_type": "ICL_zh_male_ruyacaijun_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "正直青年",
+ "voice_type": "ICL_zh_male_zhengzhiqingnian_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "娇憨女王",
+ "voice_type": "ICL_zh_female_jiaohannvwang_tob",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "病娇萌妹",
+ "voice_type": "ICL_zh_female_bingjiaomengmei_tob",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "青涩小生",
+ "voice_type": "ICL_zh_male_qingsenaigou_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "纯真学弟",
+ "voice_type": "ICL_zh_male_chunzhenxuedi_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "优柔帮主",
+ "voice_type": "ICL_zh_male_youroubangzhu_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "优柔公子",
+ "voice_type": "ICL_zh_male_yourougongzi_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "贴心男友",
+ "voice_type": "ICL_zh_male_tiexinnanyou_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "少年将军",
+ "voice_type": "ICL_zh_male_shaonianjiangjun_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "病娇哥哥",
+ "voice_type": "ICL_zh_male_bingjiaogege_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "学霸男同桌",
+ "voice_type": "ICL_zh_male_xuebanantongzhuo_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "幽默叔叔",
+ "voice_type": "ICL_zh_male_youmoshushu_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "假小子",
+ "voice_type": "ICL_zh_female_jiaxiaozi_tob",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "温柔男同桌",
+ "voice_type": "ICL_zh_male_wenrounantongzhuo_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "幽默大爷",
+ "voice_type": "ICL_zh_male_youmodaye_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "枕边低语",
+ "voice_type": "ICL_zh_male_asmryexiu_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "神秘法师",
+ "voice_type": "ICL_zh_male_shenmifashi_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "娇喘女声",
+ "voice_type": "zh_female_jiaochuan_mars_bigtts",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "开朗弟弟",
+ "voice_type": "zh_male_livelybro_mars_bigtts",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "谄媚女声",
+ "voice_type": "zh_female_flattery_mars_bigtts",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "冷峻上司",
+ "voice_type": "ICL_zh_male_lengjunshangsi_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "醋精男友",
+ "voice_type": "ICL_zh_male_cujingnanyou_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "风发少年",
+ "voice_type": "ICL_zh_male_fengfashaonian_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "磁性男嗓",
+ "voice_type": "ICL_zh_male_cixingnansang_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "成熟总裁",
+ "voice_type": "ICL_zh_male_chengshuzongcai_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "傲娇精英",
+ "voice_type": "ICL_zh_male_aojiaojingying_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "傲娇公子",
+ "voice_type": "ICL_zh_male_aojiaogongzi_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "霸道少爷",
+ "voice_type": "ICL_zh_male_badaoshaoye_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "腹黑公子",
+ "voice_type": "ICL_zh_male_fuheigongzi_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "暖心学姐",
+ "voice_type": "ICL_zh_female_nuanxinxuejie_tob",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "成熟姐姐",
+ "voice_type": "ICL_zh_female_chengshujiejie_tob",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "病娇姐姐",
+ "voice_type": "ICL_zh_female_bingjiaojiejie_tob",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "妩媚御姐",
+ "voice_type": "ICL_zh_female_wumeiyujie_tob",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "傲娇女友",
+ "voice_type": "ICL_zh_female_aojiaonvyou_tob",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "贴心女友",
+ "voice_type": "ICL_zh_female_tiexinnvyou_tob",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "性感御姐",
+ "voice_type": "ICL_zh_female_xingganyujie_tob",
+ "gender": "female",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "病娇弟弟",
+ "voice_type": "ICL_zh_male_bingjiaodidi_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "傲慢少爷",
+ "voice_type": "ICL_zh_male_aomanshaoye_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "傲气凌人",
+ "voice_type": "ICL_zh_male_aiqilingren_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ },
+ {
+ "name": "病娇白莲",
+ "voice_type": "ICL_zh_male_bingjiaobailian_tob",
+ "gender": "male",
+ "version": "1.0",
+ "resource_id": "seed-tts-1.0",
+ "voice_category": "roleplay",
+ "scene": "角色扮演",
+ "language": [
+ "chinese"
+ ],
+ "emotions": []
+ }
+ ],
+ "languages": [
+ {
+ "name": "chinese",
+ "zh": "中文",
+ "en": "Chinese"
+ },
+ {
+ "name": "en_au",
+ "zh": "澳洲英语",
+ "en": "Australian English"
+ },
+ {
+ "name": "en_gb",
+ "zh": "英式英语",
+ "en": "British English"
+ },
+ {
+ "name": "en_us",
+ "zh": "美式英语",
+ "en": "American English"
+ },
+ {
+ "name": "es",
+ "zh": "西语",
+ "en": "Spanish"
+ },
+ {
+ "name": "ja",
+ "zh": "日语",
+ "en": "Japanese"
+ }
+ ],
+ "emotions": [
+ {
+ "name": "ASMR",
+ "zh": "低语",
+ "en": "ASMR"
+ },
+ {
+ "name": "affectionate",
+ "zh": "深情",
+ "en": "affectionate"
+ },
+ {
+ "name": "angry",
+ "zh": "生气",
+ "en": "angry"
+ },
+ {
+ "name": "authoritative",
+ "zh": "权威",
+ "en": "authoritative"
+ },
+ {
+ "name": "chat",
+ "zh": "对话",
+ "en": "chat"
+ },
+ {
+ "name": "coldness",
+ "zh": "冷漠",
+ "en": "coldness"
+ },
+ {
+ "name": "depressed",
+ "zh": "沮丧",
+ "en": "depressed"
+ },
+ {
+ "name": "excited",
+ "zh": "激动",
+ "en": "excited"
+ },
+ {
+ "name": "fear",
+ "zh": "恐惧",
+ "en": "fear"
+ },
+ {
+ "name": "happy",
+ "zh": "开心",
+ "en": "happy"
+ },
+ {
+ "name": "hate",
+ "zh": "厌恶",
+ "en": "hate"
+ },
+ {
+ "name": "neutral",
+ "zh": "中性",
+ "en": "neutral"
+ },
+ {
+ "name": "sad",
+ "zh": "悲伤",
+ "en": "sad"
+ },
+ {
+ "name": "surprised",
+ "zh": "惊讶",
+ "en": "surprised"
+ },
+ {
+ "name": "warm",
+ "zh": "温暖",
+ "en": "warm"
+ }
+ ]
+}
diff --git a/configs/wan/wan_flf2v.json b/configs/wan/wan_flf2v.json
new file mode 100644
index 0000000000000000000000000000000000000000..998f38f05a73f6ce0bd74116764c6ea317f5391d
--- /dev/null
+++ b/configs/wan/wan_flf2v.json
@@ -0,0 +1,13 @@
+{
+ "infer_steps": 50,
+ "target_video_length": 81,
+ "target_height": 720,
+ "target_width": 1280,
+ "self_attn_1_type": "sage_attn2",
+ "cross_attn_1_type": "sage_attn2",
+ "cross_attn_2_type": "sage_attn2",
+ "sample_guide_scale": 5,
+ "sample_shift": 16,
+ "enable_cfg": true,
+ "cpu_offload": false
+}
diff --git a/configs/wan/wan_i2v.json b/configs/wan/wan_i2v.json
new file mode 100644
index 0000000000000000000000000000000000000000..6c2107083c6b94f2dcd36e9eec30664292e3ba9a
--- /dev/null
+++ b/configs/wan/wan_i2v.json
@@ -0,0 +1,13 @@
+{
+ "infer_steps": 40,
+ "target_video_length": 81,
+ "target_height": 480,
+ "target_width": 832,
+ "self_attn_1_type": "flash_attn3",
+ "cross_attn_1_type": "flash_attn3",
+ "cross_attn_2_type": "flash_attn3",
+ "sample_guide_scale": 5,
+ "sample_shift": 3,
+ "enable_cfg": true,
+ "cpu_offload": false
+}
diff --git a/configs/wan/wan_t2v.json b/configs/wan/wan_t2v.json
new file mode 100644
index 0000000000000000000000000000000000000000..2e2825047a1d4ad72ae661befd729f26162dbabe
--- /dev/null
+++ b/configs/wan/wan_t2v.json
@@ -0,0 +1,14 @@
+{
+ "infer_steps": 50,
+ "target_video_length": 81,
+ "text_len": 512,
+ "target_height": 480,
+ "target_width": 832,
+ "self_attn_1_type": "flash_attn3",
+ "cross_attn_1_type": "flash_attn3",
+ "cross_attn_2_type": "flash_attn3",
+ "sample_guide_scale": 6,
+ "sample_shift": 8,
+ "enable_cfg": true,
+ "cpu_offload": false
+}
diff --git a/configs/wan/wan_t2v_enhancer.json b/configs/wan/wan_t2v_enhancer.json
new file mode 100644
index 0000000000000000000000000000000000000000..b27afdfbf5f645eabc9c9e179358b02c5cacf8e9
--- /dev/null
+++ b/configs/wan/wan_t2v_enhancer.json
@@ -0,0 +1,19 @@
+{
+ "infer_steps": 50,
+ "target_video_length": 81,
+ "text_len": 512,
+ "target_height": 480,
+ "target_width": 832,
+ "self_attn_1_type": "flash_attn3",
+ "cross_attn_1_type": "flash_attn3",
+ "cross_attn_2_type": "flash_attn3",
+ "sample_guide_scale": 6,
+ "sample_shift": 8,
+ "enable_cfg": true,
+ "cpu_offload": false,
+ "sub_servers": {
+ "prompt_enhancer": [
+ "http://localhost:9001"
+ ]
+ }
+}
diff --git a/configs/wan/wan_vace.json b/configs/wan/wan_vace.json
new file mode 100644
index 0000000000000000000000000000000000000000..23fbff233a7243bb032e46d3013c6dce5be5b0b8
--- /dev/null
+++ b/configs/wan/wan_vace.json
@@ -0,0 +1,13 @@
+{
+ "infer_steps": 50,
+ "target_video_length": 81,
+ "target_height": 480,
+ "target_width": 832,
+ "self_attn_1_type": "flash_attn3",
+ "cross_attn_1_type": "flash_attn3",
+ "cross_attn_2_type": "flash_attn3",
+ "sample_guide_scale": 5,
+ "sample_shift": 16,
+ "enable_cfg": true,
+ "cpu_offload": false
+}
diff --git a/configs/wan22/wan_animate.json b/configs/wan22/wan_animate.json
new file mode 100644
index 0000000000000000000000000000000000000000..c4c3d59b32eb406c2c30fab6474fd23d74363b49
--- /dev/null
+++ b/configs/wan22/wan_animate.json
@@ -0,0 +1,18 @@
+{
+ "infer_steps": 20,
+ "target_video_length": 77,
+ "text_len": 512,
+ "target_height": 720,
+ "target_width": 1280,
+ "self_attn_1_type": "flash_attn3",
+ "cross_attn_1_type": "flash_attn3",
+ "cross_attn_2_type": "flash_attn3",
+ "adapter_attn_type": "flash_attn3",
+ "sample_shift": 5.0,
+ "sample_guide_scale": 5.0,
+ "enable_cfg": false,
+ "cpu_offload": false,
+ "refert_num": 1,
+ "replace_flag": false,
+ "fps": 30
+}
diff --git a/configs/wan22/wan_animate_4090.json b/configs/wan22/wan_animate_4090.json
new file mode 100644
index 0000000000000000000000000000000000000000..e0f89657ddea8ca989d2e33d51076cc6e2e3af95
--- /dev/null
+++ b/configs/wan22/wan_animate_4090.json
@@ -0,0 +1,25 @@
+{
+ "infer_steps": 20,
+ "target_video_length": 77,
+ "text_len": 512,
+ "target_height": 720,
+ "target_width": 1280,
+ "self_attn_1_type": "sage_attn2",
+ "cross_attn_1_type": "sage_attn2",
+ "cross_attn_2_type": "sage_attn2",
+ "adapter_attn_type": "sage_attn2",
+ "sample_shift": 5.0,
+ "sample_guide_scale": 5.0,
+ "enable_cfg": false,
+ "cpu_offload": true,
+ "offload_granularity": "phase",
+ "refert_num": 1,
+ "replace_flag": false,
+ "fps": 30,
+ "dit_quantized": true,
+ "dit_quant_scheme": "fp8-sgl",
+ "t5_quantized": true,
+ "t5_quant_scheme": "fp8",
+ "clip_quantized": true,
+ "clip_quant_scheme": "fp8"
+}
diff --git a/configs/wan22/wan_animate_lora.json b/configs/wan22/wan_animate_lora.json
new file mode 100644
index 0000000000000000000000000000000000000000..0e1c8059cf0b716a7778d9665d8409574331a603
--- /dev/null
+++ b/configs/wan22/wan_animate_lora.json
@@ -0,0 +1,24 @@
+{
+ "infer_steps": 4,
+ "target_video_length": 77,
+ "text_len": 512,
+ "target_height": 720,
+ "target_width": 1280,
+ "self_attn_1_type": "flash_attn3",
+ "cross_attn_1_type": "flash_attn3",
+ "cross_attn_2_type": "flash_attn3",
+ "adapter_attn_type": "flash_attn3",
+ "sample_shift": 5.0,
+ "sample_guide_scale": 1.0,
+ "enable_cfg": false,
+ "cpu_offload": false,
+ "refert_num": 1,
+ "replace_flag": false,
+ "fps": 30,
+ "lora_configs": [
+ {
+ "path": "lightx2v_I2V_14B_480p_cfg_step_distill_rank32_bf16.safetensors",
+ "strength": 1.0
+ }
+ ]
+}
diff --git a/configs/wan22/wan_animate_replace.json b/configs/wan22/wan_animate_replace.json
new file mode 100644
index 0000000000000000000000000000000000000000..c4805a471386291791fdca873c0fc34d9df257d4
--- /dev/null
+++ b/configs/wan22/wan_animate_replace.json
@@ -0,0 +1,18 @@
+{
+ "infer_steps": 20,
+ "target_video_length": 77,
+ "text_len": 512,
+ "target_height": 720,
+ "target_width": 1280,
+ "self_attn_1_type": "flash_attn3",
+ "cross_attn_1_type": "flash_attn3",
+ "cross_attn_2_type": "flash_attn3",
+ "adapter_attn_type": "flash_attn3",
+ "sample_shift": 5.0,
+ "sample_guide_scale": 5.0,
+ "enable_cfg": false,
+ "cpu_offload": false,
+ "refert_num": 1,
+ "fps": 30,
+ "replace_flag": true
+}
diff --git a/configs/wan22/wan_animate_replace_4090.json b/configs/wan22/wan_animate_replace_4090.json
new file mode 100644
index 0000000000000000000000000000000000000000..fab2908b784cfc657d35853ea16e65a7706727cd
--- /dev/null
+++ b/configs/wan22/wan_animate_replace_4090.json
@@ -0,0 +1,25 @@
+{
+ "infer_steps": 20,
+ "target_video_length": 77,
+ "text_len": 512,
+ "target_height": 720,
+ "target_width": 1280,
+ "self_attn_1_type": "sage_attn2",
+ "cross_attn_1_type": "sage_attn2",
+ "cross_attn_2_type": "sage_attn2",
+ "adapter_attn_type": "sage_attn2",
+ "sample_shift": 5.0,
+ "sample_guide_scale": 5.0,
+ "enable_cfg": false,
+ "cpu_offload": true,
+ "offload_granularity": "phase",
+ "refert_num": 1,
+ "fps": 30,
+ "replace_flag": true,
+ "dit_quantized": true,
+ "dit_quant_scheme": "fp8-q8f",
+ "t5_quantized": true,
+ "t5_quant_scheme": "fp8-q8f",
+ "clip_quantized": true,
+ "clip_quant_scheme": "fp8-q8f"
+}
diff --git a/configs/wan22/wan_distill_moe_flf2v.json b/configs/wan22/wan_distill_moe_flf2v.json
new file mode 100644
index 0000000000000000000000000000000000000000..d3f90018fa5a2ada4174f18972be495ed4b9d39f
--- /dev/null
+++ b/configs/wan22/wan_distill_moe_flf2v.json
@@ -0,0 +1,28 @@
+{
+ "infer_steps": 4,
+ "target_video_length": 81,
+ "text_len": 512,
+ "target_height": 720,
+ "target_width": 1280,
+ "self_attn_1_type": "sage_attn2",
+ "cross_attn_1_type": "sage_attn2",
+ "cross_attn_2_type": "sage_attn2",
+ "sample_guide_scale": [
+ 3.5,
+ 3.5
+ ],
+ "sample_shift": 16,
+ "enable_cfg": false,
+ "cpu_offload": true,
+ "offload_granularity": "block",
+ "t5_cpu_offload": false,
+ "vae_cpu_offload": false,
+ "use_image_encoder": false,
+ "boundary_step_index": 2,
+ "denoising_step_list": [
+ 1000,
+ 750,
+ 500,
+ 250
+ ]
+}
diff --git a/configs/wan22/wan_distill_moe_flf2v_fp8.json b/configs/wan22/wan_distill_moe_flf2v_fp8.json
new file mode 100644
index 0000000000000000000000000000000000000000..2e982f38b0bb5299a4c84b5b708be625f79fae26
--- /dev/null
+++ b/configs/wan22/wan_distill_moe_flf2v_fp8.json
@@ -0,0 +1,32 @@
+{
+ "infer_steps": 4,
+ "target_video_length": 81,
+ "text_len": 512,
+ "target_height": 720,
+ "target_width": 1280,
+ "self_attn_1_type": "sage_attn2",
+ "cross_attn_1_type": "sage_attn2",
+ "cross_attn_2_type": "sage_attn2",
+ "sample_guide_scale": [
+ 3.5,
+ 3.5
+ ],
+ "sample_shift": 16,
+ "enable_cfg": false,
+ "cpu_offload": true,
+ "offload_granularity": "block",
+ "t5_cpu_offload": false,
+ "vae_cpu_offload": false,
+ "use_image_encoder": false,
+ "boundary_step_index": 2,
+ "denoising_step_list": [
+ 1000,
+ 750,
+ 500,
+ 250
+ ],
+ "dit_quantized": true,
+ "dit_quant_scheme": "fp8-sgl",
+ "t5_quantized": true,
+ "t5_quant_scheme": "fp8"
+}
diff --git a/configs/wan22/wan_distill_moe_flf2v_int8.json b/configs/wan22/wan_distill_moe_flf2v_int8.json
new file mode 100644
index 0000000000000000000000000000000000000000..c3489b04395f9884582810be50778d3fa55f5d80
--- /dev/null
+++ b/configs/wan22/wan_distill_moe_flf2v_int8.json
@@ -0,0 +1,32 @@
+{
+ "infer_steps": 4,
+ "target_video_length": 81,
+ "text_len": 512,
+ "target_height": 720,
+ "target_width": 1280,
+ "self_attn_1_type": "sage_attn2",
+ "cross_attn_1_type": "sage_attn2",
+ "cross_attn_2_type": "sage_attn2",
+ "sample_guide_scale": [
+ 3.5,
+ 3.5
+ ],
+ "sample_shift": 16,
+ "enable_cfg": false,
+ "cpu_offload": true,
+ "offload_granularity": "block",
+ "t5_cpu_offload": false,
+ "vae_cpu_offload": false,
+ "use_image_encoder": false,
+ "boundary_step_index": 2,
+ "denoising_step_list": [
+ 1000,
+ 750,
+ 500,
+ 250
+ ],
+ "dit_quantized": true,
+ "dit_quant_scheme": "int8-vllm",
+ "t5_quantized": true,
+ "t5_quant_scheme": "int8"
+}
diff --git a/configs/wan22/wan_distill_moe_flf2v_with_lora.json b/configs/wan22/wan_distill_moe_flf2v_with_lora.json
new file mode 100644
index 0000000000000000000000000000000000000000..445ca8fe2dd7c356080a5dd08414faa6e5a096da
--- /dev/null
+++ b/configs/wan22/wan_distill_moe_flf2v_with_lora.json
@@ -0,0 +1,40 @@
+{
+ "infer_steps": 4,
+ "target_video_length": 81,
+ "text_len": 512,
+ "target_height": 720,
+ "target_width": 1280,
+ "self_attn_1_type": "sage_attn2",
+ "cross_attn_1_type": "sage_attn2",
+ "cross_attn_2_type": "sage_attn2",
+ "sample_guide_scale": [
+ 3.5,
+ 3.5
+ ],
+ "sample_shift": 16,
+ "enable_cfg": false,
+ "cpu_offload": true,
+ "offload_granularity": "model",
+ "t5_cpu_offload": false,
+ "vae_cpu_offload": false,
+ "use_image_encoder": false,
+ "boundary_step_index": 2,
+ "denoising_step_list": [
+ 1000,
+ 750,
+ 500,
+ 250
+ ],
+ "lora_configs": [
+ {
+ "name": "low_noise_model",
+ "path": "/path/to/low_noise_lora",
+ "strength": 1.0
+ },
+ {
+ "name": "high_noise_model",
+ "path": "/path/to/high_noise_lora",
+ "strength": 1.0
+ }
+ ]
+}
diff --git a/configs/wan22/wan_moe_flf2v.json b/configs/wan22/wan_moe_flf2v.json
new file mode 100644
index 0000000000000000000000000000000000000000..73879fc935900abc1a81b3dc840ca057a122a21e
--- /dev/null
+++ b/configs/wan22/wan_moe_flf2v.json
@@ -0,0 +1,21 @@
+{
+ "infer_steps": 40,
+ "target_video_length": 81,
+ "target_height": 720,
+ "target_width": 1280,
+ "self_attn_1_type": "sage_attn2",
+ "cross_attn_1_type": "sage_attn2",
+ "cross_attn_2_type": "sage_attn2",
+ "sample_shift": 16,
+ "enable_cfg": true,
+ "cpu_offload": true,
+ "sample_guide_scale": [
+ 3.5,
+ 3.5
+ ],
+ "offload_granularity": "model",
+ "t5_cpu_offload": false,
+ "vae_cpu_offload": false,
+ "boundary": 0.900,
+ "use_image_encoder": false
+}
diff --git a/configs/wan22/wan_moe_i2v.json b/configs/wan22/wan_moe_i2v.json
new file mode 100644
index 0000000000000000000000000000000000000000..eb29bfe8cefa414cedd0edd352028fd628f96dbb
--- /dev/null
+++ b/configs/wan22/wan_moe_i2v.json
@@ -0,0 +1,20 @@
+{
+ "infer_steps": 40,
+ "target_video_length": 81,
+ "text_len": 512,
+ "target_height": 720,
+ "target_width": 1280,
+ "self_attn_1_type": "flash_attn3",
+ "cross_attn_1_type": "flash_attn3",
+ "cross_attn_2_type": "flash_attn3",
+ "sample_guide_scale": [
+ 3.5,
+ 3.5
+ ],
+ "sample_shift": 5.0,
+ "enable_cfg": true,
+ "cpu_offload": true,
+ "offload_granularity": "model",
+ "boundary": 0.900,
+ "use_image_encoder": false
+}
diff --git a/configs/wan22/wan_moe_i2v_4090.json b/configs/wan22/wan_moe_i2v_4090.json
new file mode 100644
index 0000000000000000000000000000000000000000..d37b9289257dece6a4f5cbcc7a2d49d44b4d1f49
--- /dev/null
+++ b/configs/wan22/wan_moe_i2v_4090.json
@@ -0,0 +1,27 @@
+{
+ "infer_steps": 40,
+ "target_video_length": 81,
+ "text_len": 512,
+ "target_height": 720,
+ "target_width": 1280,
+ "self_attn_1_type": "flash_attn3",
+ "cross_attn_1_type": "flash_attn3",
+ "cross_attn_2_type": "flash_attn3",
+ "sample_guide_scale": [
+ 3.5,
+ 3.5
+ ],
+ "sample_shift": 5.0,
+ "enable_cfg": false,
+ "cpu_offload": true,
+ "offload_granularity": "phase",
+ "boundary": 0.900,
+ "use_image_encoder": false,
+ "boundary_step_index": 2,
+ "denoising_step_list": [
+ 1000,
+ 750,
+ 500,
+ 250
+ ]
+}
diff --git a/configs/wan22/wan_moe_i2v_audio.json b/configs/wan22/wan_moe_i2v_audio.json
new file mode 100644
index 0000000000000000000000000000000000000000..a0deb7ce7e08975da20a3e5e5e70d6eb21be8dec
--- /dev/null
+++ b/configs/wan22/wan_moe_i2v_audio.json
@@ -0,0 +1,38 @@
+{
+ "infer_steps": 6,
+ "target_fps": 16,
+ "video_duration": 16,
+ "audio_sr": 16000,
+ "text_len": 512,
+ "target_video_length": 81,
+ "target_height": 720,
+ "target_width": 1280,
+ "self_attn_1_type": "flash_attn3",
+ "cross_attn_1_type": "flash_attn3",
+ "cross_attn_2_type": "flash_attn3",
+ "sample_guide_scale": [
+ 1.0,
+ 1.0
+ ],
+ "sample_shift": 5.0,
+ "enable_cfg": false,
+ "cpu_offload": true,
+ "offload_granularity": "model",
+ "t5_cpu_offload": false,
+ "vae_cpu_offload": false,
+ "boundary": 0.900,
+ "use_image_encoder": false,
+ "use_31_block": false,
+ "lora_configs": [
+ {
+ "name": "high_noise_model",
+ "path": "/mnt/Text2Video/wuzhuguanyu/Wan21_T2V_14B_lightx2v_cfg_step_distill_lora_rank64.safetensors",
+ "strength": 1.0
+ },
+ {
+ "name": "low_noise_model",
+ "path": "/mnt/Text2Video/wuzhuguanyu/Wan21_T2V_14B_lightx2v_cfg_step_distill_lora_rank64.safetensors",
+ "strength": 1.0
+ }
+ ]
+}
diff --git a/configs/wan22/wan_moe_i2v_distill.json b/configs/wan22/wan_moe_i2v_distill.json
new file mode 100644
index 0000000000000000000000000000000000000000..92f3360d75a3801a359e1b403deba77a57d8c166
--- /dev/null
+++ b/configs/wan22/wan_moe_i2v_distill.json
@@ -0,0 +1,28 @@
+{
+ "infer_steps": 4,
+ "target_video_length": 81,
+ "text_len": 512,
+ "target_height": 720,
+ "target_width": 1280,
+ "self_attn_1_type": "flash_attn3",
+ "cross_attn_1_type": "flash_attn3",
+ "cross_attn_2_type": "flash_attn3",
+ "sample_guide_scale": [
+ 3.5,
+ 3.5
+ ],
+ "sample_shift": 5.0,
+ "enable_cfg": false,
+ "cpu_offload": true,
+ "offload_granularity": "block",
+ "t5_cpu_offload": false,
+ "vae_cpu_offload": false,
+ "use_image_encoder": false,
+ "boundary_step_index": 2,
+ "denoising_step_list": [
+ 1000,
+ 750,
+ 500,
+ 250
+ ]
+}
diff --git a/configs/wan22/wan_moe_i2v_distill_4090.json b/configs/wan22/wan_moe_i2v_distill_4090.json
new file mode 100644
index 0000000000000000000000000000000000000000..279a0f25e88954426b732d70388d216b0c01a643
--- /dev/null
+++ b/configs/wan22/wan_moe_i2v_distill_4090.json
@@ -0,0 +1,32 @@
+{
+ "infer_steps": 4,
+ "target_video_length": 81,
+ "text_len": 512,
+ "target_height": 720,
+ "target_width": 1280,
+ "self_attn_1_type": "sage_attn2",
+ "cross_attn_1_type": "sage_attn2",
+ "cross_attn_2_type": "sage_attn2",
+ "sample_guide_scale": [
+ 3.5,
+ 3.5
+ ],
+ "sample_shift": 5.0,
+ "enable_cfg": false,
+ "cpu_offload": true,
+ "offload_granularity": "block",
+ "t5_cpu_offload": false,
+ "vae_cpu_offload": false,
+ "use_image_encoder": false,
+ "boundary_step_index": 2,
+ "denoising_step_list": [
+ 1000,
+ 750,
+ 500,
+ 250
+ ],
+ "dit_quantized": true,
+ "dit_quant_scheme": "fp8-q8f",
+ "t5_quantized": true,
+ "t5_quant_scheme": "fp8-q8f"
+}
diff --git a/configs/wan22/wan_moe_i2v_distill_5090.json b/configs/wan22/wan_moe_i2v_distill_5090.json
new file mode 100644
index 0000000000000000000000000000000000000000..04494c2234874188f86c3aac7e2d92d9f311ad68
--- /dev/null
+++ b/configs/wan22/wan_moe_i2v_distill_5090.json
@@ -0,0 +1,32 @@
+{
+ "infer_steps": 4,
+ "target_video_length": 81,
+ "text_len": 512,
+ "target_height": 720,
+ "target_width": 1280,
+ "self_attn_1_type": "sage_attn3",
+ "cross_attn_1_type": "sage_attn3",
+ "cross_attn_2_type": "sage_attn3",
+ "sample_guide_scale": [
+ 3.5,
+ 3.5
+ ],
+ "sample_shift": 5.0,
+ "enable_cfg": false,
+ "cpu_offload": true,
+ "offload_granularity": "block",
+ "t5_cpu_offload": false,
+ "vae_cpu_offload": false,
+ "use_image_encoder": false,
+ "boundary_step_index": 2,
+ "denoising_step_list": [
+ 1000,
+ 750,
+ 500,
+ 250
+ ],
+ "dit_quantized": true,
+ "dit_quant_scheme": "int8-q8f",
+ "t5_quantized": true,
+ "t5_quant_scheme": "int8-q8f"
+}
diff --git a/configs/wan22/wan_moe_i2v_distill_quant.json b/configs/wan22/wan_moe_i2v_distill_quant.json
new file mode 100644
index 0000000000000000000000000000000000000000..ce4e1c4aeb8524304b2e87c95909d713116cab84
--- /dev/null
+++ b/configs/wan22/wan_moe_i2v_distill_quant.json
@@ -0,0 +1,32 @@
+{
+ "infer_steps": 4,
+ "target_video_length": 81,
+ "text_len": 512,
+ "target_height": 720,
+ "target_width": 1280,
+ "self_attn_1_type": "flash_attn3",
+ "cross_attn_1_type": "flash_attn3",
+ "cross_attn_2_type": "flash_attn3",
+ "sample_guide_scale": [
+ 3.5,
+ 3.5
+ ],
+ "sample_shift": 5.0,
+ "enable_cfg": false,
+ "cpu_offload": true,
+ "offload_granularity": "block",
+ "t5_cpu_offload": false,
+ "vae_cpu_offload": false,
+ "use_image_encoder": false,
+ "boundary_step_index": 2,
+ "denoising_step_list": [
+ 1000,
+ 750,
+ 500,
+ 250
+ ],
+ "dit_quantized": true,
+ "dit_quant_scheme": "fp8-sgl",
+ "t5_quantized": true,
+ "t5_quant_scheme": "fp8-sgl"
+}
diff --git a/configs/wan22/wan_moe_i2v_distill_with_lora.json b/configs/wan22/wan_moe_i2v_distill_with_lora.json
new file mode 100644
index 0000000000000000000000000000000000000000..f28ddc45126899e4ad8f5365546bca0bf3fb745d
--- /dev/null
+++ b/configs/wan22/wan_moe_i2v_distill_with_lora.json
@@ -0,0 +1,40 @@
+{
+ "infer_steps": 4,
+ "target_video_length": 81,
+ "text_len": 512,
+ "target_height": 720,
+ "target_width": 1280,
+ "self_attn_1_type": "sage_attn2",
+ "cross_attn_1_type": "sage_attn2",
+ "cross_attn_2_type": "sage_attn2",
+ "sample_guide_scale": [
+ 3.5,
+ 3.5
+ ],
+ "sample_shift": 5.0,
+ "enable_cfg": false,
+ "cpu_offload": true,
+ "offload_granularity": "block",
+ "t5_cpu_offload": false,
+ "vae_cpu_offload": false,
+ "use_image_encoder": false,
+ "boundary_step_index": 2,
+ "denoising_step_list": [
+ 1000,
+ 750,
+ 500,
+ 250
+ ],
+ "lora_configs": [
+ {
+ "name": "high_noise_model",
+ "path": "lightx2v/Wan2.2-Distill-Loras/wan2.2_i2v_A14b_high_noise_lora_rank64_lightx2v_4step_1022.safetensors",
+ "strength": 1.0
+ },
+ {
+ "name": "low_noise_model",
+ "path": "lightx2v/Wan2.2-Distill-Loras/wan2.2_i2v_A14b_low_noise_lora_rank64_lightx2v_4step_1022.safetensors",
+ "strength": 1.0
+ }
+ ]
+}
diff --git a/configs/wan22/wan_moe_t2v.json b/configs/wan22/wan_moe_t2v.json
new file mode 100644
index 0000000000000000000000000000000000000000..d8be0d1078ba45f9b915b3e44899ac04fe05c38c
--- /dev/null
+++ b/configs/wan22/wan_moe_t2v.json
@@ -0,0 +1,21 @@
+{
+ "infer_steps": 40,
+ "target_video_length": 81,
+ "text_len": 512,
+ "target_height": 720,
+ "target_width": 1280,
+ "self_attn_1_type": "flash_attn3",
+ "cross_attn_1_type": "flash_attn3",
+ "cross_attn_2_type": "flash_attn3",
+ "sample_guide_scale": [
+ 4.0,
+ 3.0
+ ],
+ "sample_shift": 12.0,
+ "enable_cfg": true,
+ "cpu_offload": true,
+ "offload_granularity": "model",
+ "t5_cpu_offload": false,
+ "vae_cpu_offload": false,
+ "boundary": 0.875
+}
diff --git a/configs/wan22/wan_moe_t2v_distill.json b/configs/wan22/wan_moe_t2v_distill.json
new file mode 100644
index 0000000000000000000000000000000000000000..eabdf11a0c2232a0bc43e1d7bb1bf76e4ae44455
--- /dev/null
+++ b/configs/wan22/wan_moe_t2v_distill.json
@@ -0,0 +1,34 @@
+{
+ "infer_steps": 4,
+ "target_video_length": 81,
+ "text_len": 512,
+ "target_height": 480,
+ "target_width": 832,
+ "self_attn_1_type": "flash_attn3",
+ "cross_attn_1_type": "flash_attn3",
+ "cross_attn_2_type": "flash_attn3",
+ "sample_guide_scale": [
+ 4.0,
+ 3.0
+ ],
+ "sample_shift": 5.0,
+ "enable_cfg": false,
+ "cpu_offload": true,
+ "offload_granularity": "model",
+ "t5_cpu_offload": false,
+ "vae_cpu_offload": false,
+ "boundary_step_index": 2,
+ "denoising_step_list": [
+ 1000,
+ 750,
+ 500,
+ 250
+ ],
+ "lora_configs": [
+ {
+ "name": "low_noise_model",
+ "path": "Wan2.1-T2V-14B/loras/Wan21_T2V_14B_lightx2v_cfg_step_distill_lora_rank64.safetensors",
+ "strength": 1.0
+ }
+ ]
+}
diff --git a/configs/wan22/wan_ti2v_i2v.json b/configs/wan22/wan_ti2v_i2v.json
new file mode 100644
index 0000000000000000000000000000000000000000..44e9c4e334de58491bc6d4b6ce9e40acdc3628a6
--- /dev/null
+++ b/configs/wan22/wan_ti2v_i2v.json
@@ -0,0 +1,25 @@
+{
+ "infer_steps": 50,
+ "target_video_length": 121,
+ "text_len": 512,
+ "target_height": 704,
+ "target_width": 1280,
+ "num_channels_latents": 48,
+ "vae_stride": [
+ 4,
+ 16,
+ 16
+ ],
+ "self_attn_1_type": "flash_attn3",
+ "cross_attn_1_type": "flash_attn3",
+ "cross_attn_2_type": "flash_attn3",
+ "sample_guide_scale": 5.0,
+ "sample_shift": 5.0,
+ "enable_cfg": true,
+ "cpu_offload": false,
+ "offload_granularity": "model",
+ "t5_cpu_offload": false,
+ "vae_cpu_offload": false,
+ "fps": 24,
+ "use_image_encoder": false
+}
diff --git a/configs/wan22/wan_ti2v_i2v_4090.json b/configs/wan22/wan_ti2v_i2v_4090.json
new file mode 100644
index 0000000000000000000000000000000000000000..742f8ab16d3de6d5bb29abdd116bf84604e5c3a7
--- /dev/null
+++ b/configs/wan22/wan_ti2v_i2v_4090.json
@@ -0,0 +1,26 @@
+{
+ "infer_steps": 50,
+ "target_video_length": 121,
+ "text_len": 512,
+ "target_height": 704,
+ "target_width": 1280,
+ "num_channels_latents": 48,
+ "vae_stride": [
+ 4,
+ 16,
+ 16
+ ],
+ "self_attn_1_type": "flash_attn3",
+ "cross_attn_1_type": "flash_attn3",
+ "cross_attn_2_type": "flash_attn3",
+ "sample_guide_scale": 5.0,
+ "sample_shift": 5.0,
+ "enable_cfg": true,
+ "fps": 24,
+ "use_image_encoder": false,
+ "cpu_offload": true,
+ "offload_granularity": "model",
+ "t5_cpu_offload": false,
+ "vae_cpu_offload": false,
+ "vae_offload_cache": true
+}
diff --git a/configs/wan22/wan_ti2v_t2v.json b/configs/wan22/wan_ti2v_t2v.json
new file mode 100644
index 0000000000000000000000000000000000000000..a1541e808a1d54508efc83757613619cf16dc6d7
--- /dev/null
+++ b/configs/wan22/wan_ti2v_t2v.json
@@ -0,0 +1,24 @@
+{
+ "infer_steps": 50,
+ "target_video_length": 121,
+ "text_len": 512,
+ "target_height": 704,
+ "target_width": 1280,
+ "num_channels_latents": 48,
+ "vae_stride": [
+ 4,
+ 16,
+ 16
+ ],
+ "self_attn_1_type": "flash_attn3",
+ "cross_attn_1_type": "flash_attn3",
+ "cross_attn_2_type": "flash_attn3",
+ "sample_guide_scale": 5.0,
+ "sample_shift": 5.0,
+ "enable_cfg": true,
+ "cpu_offload": false,
+ "offload_granularity": "model",
+ "t5_cpu_offload": false,
+ "vae_cpu_offload": false,
+ "fps": 24
+}
diff --git a/configs/wan22/wan_ti2v_t2v_4090.json b/configs/wan22/wan_ti2v_t2v_4090.json
new file mode 100644
index 0000000000000000000000000000000000000000..c1e5c49aced9fc2d3426aa6f5cc21a0defdc1f32
--- /dev/null
+++ b/configs/wan22/wan_ti2v_t2v_4090.json
@@ -0,0 +1,25 @@
+{
+ "infer_steps": 50,
+ "target_video_length": 121,
+ "text_len": 512,
+ "target_height": 704,
+ "target_width": 1280,
+ "num_channels_latents": 48,
+ "vae_stride": [
+ 4,
+ 16,
+ 16
+ ],
+ "self_attn_1_type": "flash_attn3",
+ "cross_attn_1_type": "flash_attn3",
+ "cross_attn_2_type": "flash_attn3",
+ "sample_guide_scale": 5.0,
+ "sample_shift": 5.0,
+ "enable_cfg": true,
+ "fps": 24,
+ "cpu_offload": true,
+ "offload_granularity": "model",
+ "t5_cpu_offload": false,
+ "vae_cpu_offload": false,
+ "vae_offload_cache": true
+}
diff --git a/dockerfiles/Dockerfile b/dockerfiles/Dockerfile
new file mode 100644
index 0000000000000000000000000000000000000000..ca883dcf14053ba7daeca5f6f65ff83a2c925607
--- /dev/null
+++ b/dockerfiles/Dockerfile
@@ -0,0 +1,105 @@
+FROM pytorch/pytorch:2.8.0-cuda12.8-cudnn9-devel AS base
+
+WORKDIR /app
+
+ENV DEBIAN_FRONTEND=noninteractive
+ENV LANG=C.UTF-8
+ENV LC_ALL=C.UTF-8
+ENV LD_LIBRARY_PATH=/usr/local/lib/x86_64-linux-gnu:$LD_LIBRARY_PATH
+
+RUN apt-get update && apt-get install -y vim tmux zip unzip bzip2 wget git git-lfs build-essential libibverbs-dev ca-certificates \
+ curl iproute2 libsm6 libxext6 kmod ccache libnuma-dev libssl-dev flex bison libgtk-3-dev libpango1.0-dev \
+ libsoup2.4-dev libnice-dev libopus-dev libvpx-dev libx264-dev libsrtp2-dev libglib2.0-dev libdrm-dev libjpeg-dev libpng-dev \
+ && apt-get clean && rm -rf /var/lib/apt/lists/* && git lfs install
+
+RUN conda install conda-forge::ffmpeg=8.0.0 -y && conda clean -all -y
+
+RUN pip install --no-cache-dir packaging ninja cmake scikit-build-core uv meson ruff pre-commit fastapi uvicorn requests -U
+
+RUN git clone https://github.com/vllm-project/vllm.git && cd vllm \
+ && python use_existing_torch.py && pip install --no-cache-dir -r requirements/build.txt \
+ && pip install --no-cache-dir --no-build-isolation -v -e .
+
+RUN git clone https://github.com/sgl-project/sglang.git && cd sglang/sgl-kernel \
+ && make build && make clean
+
+RUN pip install --no-cache-dir diffusers transformers tokenizers accelerate safetensors opencv-python numpy imageio \
+ imageio-ffmpeg einops loguru qtorch ftfy av decord matplotlib debugpy
+
+RUN git clone https://github.com/Dao-AILab/flash-attention.git --recursive
+
+RUN cd flash-attention && python setup.py install && rm -rf build
+
+RUN cd flash-attention/hopper && python setup.py install && rm -rf build
+
+RUN git clone https://github.com/ModelTC/SageAttention.git --depth 1
+
+RUN cd SageAttention && CUDA_ARCHITECTURES="8.0,8.6,8.9,9.0,12.0" EXT_PARALLEL=4 NVCC_APPEND_FLAGS="--threads 8" MAX_JOBS=32 pip install --no-cache-dir -v -e .
+
+RUN git clone https://github.com/ModelTC/SageAttention-1104.git --depth 1
+
+RUN cd SageAttention-1104/sageattention3_blackwell && python setup.py install && rm -rf build
+
+RUN git clone https://github.com/SandAI-org/MagiAttention.git --recursive
+
+RUN cd MagiAttention && TORCH_CUDA_ARCH_LIST="9.0" pip install --no-cache-dir --no-build-isolation -v -e .
+
+RUN git clone https://github.com/ModelTC/FlashVSR.git --depth 1
+
+RUN cd FlashVSR && pip install --no-cache-dir -v -e .
+
+COPY lightx2v_kernel /app/lightx2v_kernel
+
+RUN git clone https://github.com/NVIDIA/cutlass.git --depth 1 && cd /app/lightx2v_kernel && MAX_JOBS=32 && CMAKE_BUILD_PARALLEL_LEVEL=4 \
+ uv build --wheel \
+ -Cbuild-dir=build . \
+ -Ccmake.define.CUTLASS_PATH=/app/cutlass \
+ --verbose \
+ --color=always \
+ --no-build-isolation \
+ && pip install dist/*whl --force-reinstall --no-deps \
+ && rm -rf /app/lightx2v_kernel && rm -rf /app/cutlass
+
+# cloud deploy
+RUN pip install --no-cache-dir aio-pika asyncpg>=0.27.0 aioboto3>=12.0.0 PyJWT alibabacloud_dypnsapi20170525==1.2.2 redis==6.4.0 tos
+
+RUN curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh -s -- -y --default-toolchain stable
+ENV PATH=/root/.cargo/bin:$PATH
+
+RUN cd /opt \
+ && wget https://mirrors.tuna.tsinghua.edu.cn/gnu/libiconv/libiconv-1.15.tar.gz \
+ && tar zxvf libiconv-1.15.tar.gz \
+ && cd libiconv-1.15 \
+ && ./configure \
+ && make \
+ && make install \
+ && rm -rf /opt/libiconv-1.15
+
+RUN cd /opt \
+ && git clone https://github.com/GStreamer/gstreamer.git -b 1.27.2 --depth 1 \
+ && cd gstreamer \
+ && meson setup builddir \
+ && meson compile -C builddir \
+ && meson install -C builddir \
+ && ldconfig \
+ && rm -rf /opt/gstreamer
+
+RUN cd /opt \
+ && git clone https://github.com/GStreamer/gst-plugins-rs.git -b gstreamer-1.27.2 --depth 1 \
+ && cd gst-plugins-rs \
+ && cargo build --package gst-plugin-webrtchttp --release \
+ && install -m 644 target/release/libgstwebrtchttp.so $(pkg-config --variable=pluginsdir gstreamer-1.0)/ \
+ && rm -rf /opt/gst-plugins-rs
+
+RUN ldconfig
+
+
+# q8f for base docker
+RUN git clone https://github.com/KONAKONA666/q8_kernels.git --depth 1
+RUN cd q8_kernels && git submodule init && git submodule update && python setup.py install && rm -rf build
+
+# q8f for 5090 docker
+# RUN git clone https://github.com/ModelTC/LTX-Video-Q8-Kernels.git --depth 1
+# RUN cd LTX-Video-Q8-Kernels && git submodule init && git submodule update && python setup.py install && rm -rf build
+
+WORKDIR /workspace
diff --git a/dockerfiles/Dockerfile_5090 b/dockerfiles/Dockerfile_5090
new file mode 100644
index 0000000000000000000000000000000000000000..c8bce20aa53f5a010e98c1dbdbc8f7351382b164
--- /dev/null
+++ b/dockerfiles/Dockerfile_5090
@@ -0,0 +1,105 @@
+FROM pytorch/pytorch:2.8.0-cuda12.8-cudnn9-devel AS base
+
+WORKDIR /app
+
+ENV DEBIAN_FRONTEND=noninteractive
+ENV LANG=C.UTF-8
+ENV LC_ALL=C.UTF-8
+ENV LD_LIBRARY_PATH=/usr/local/lib/x86_64-linux-gnu:$LD_LIBRARY_PATH
+
+RUN apt-get update && apt-get install -y vim tmux zip unzip bzip2 wget git git-lfs build-essential libibverbs-dev ca-certificates \
+ curl iproute2 libsm6 libxext6 kmod ccache libnuma-dev libssl-dev flex bison libgtk-3-dev libpango1.0-dev \
+ libsoup2.4-dev libnice-dev libopus-dev libvpx-dev libx264-dev libsrtp2-dev libglib2.0-dev libdrm-dev libjpeg-dev libpng-dev \
+ && apt-get clean && rm -rf /var/lib/apt/lists/* && git lfs install
+
+RUN conda install conda-forge::ffmpeg=8.0.0 -y && conda clean -all -y
+
+RUN pip install --no-cache-dir packaging ninja cmake scikit-build-core uv meson ruff pre-commit fastapi uvicorn requests -U
+
+RUN git clone https://github.com/vllm-project/vllm.git && cd vllm \
+ && python use_existing_torch.py && pip install --no-cache-dir -r requirements/build.txt \
+ && pip install --no-cache-dir --no-build-isolation -v -e .
+
+RUN git clone https://github.com/sgl-project/sglang.git && cd sglang/sgl-kernel \
+ && make build && make clean
+
+RUN pip install --no-cache-dir diffusers transformers tokenizers accelerate safetensors opencv-python numpy imageio \
+ imageio-ffmpeg einops loguru qtorch ftfy av decord matplotlib debugpy
+
+RUN git clone https://github.com/Dao-AILab/flash-attention.git --recursive
+
+RUN cd flash-attention && python setup.py install && rm -rf build
+
+RUN cd flash-attention/hopper && python setup.py install && rm -rf build
+
+RUN git clone https://github.com/ModelTC/SageAttention.git --depth 1
+
+RUN cd SageAttention && CUDA_ARCHITECTURES="8.0,8.6,8.9,9.0,12.0" EXT_PARALLEL=4 NVCC_APPEND_FLAGS="--threads 8" MAX_JOBS=32 pip install --no-cache-dir -v -e .
+
+RUN git clone https://github.com/ModelTC/SageAttention-1104.git --depth 1
+
+RUN cd SageAttention-1104/sageattention3_blackwell && python setup.py install && rm -rf build
+
+RUN git clone https://github.com/SandAI-org/MagiAttention.git --recursive
+
+RUN cd MagiAttention && TORCH_CUDA_ARCH_LIST="9.0" pip install --no-cache-dir --no-build-isolation -v -e .
+
+RUN git clone https://github.com/ModelTC/FlashVSR.git --depth 1
+
+RUN cd FlashVSR && pip install --no-cache-dir -v -e .
+
+COPY lightx2v_kernel /app/lightx2v_kernel
+
+RUN git clone https://github.com/NVIDIA/cutlass.git --depth 1 && cd /app/lightx2v_kernel && MAX_JOBS=32 && CMAKE_BUILD_PARALLEL_LEVEL=4 \
+ uv build --wheel \
+ -Cbuild-dir=build . \
+ -Ccmake.define.CUTLASS_PATH=/app/cutlass \
+ --verbose \
+ --color=always \
+ --no-build-isolation \
+ && pip install dist/*whl --force-reinstall --no-deps \
+ && rm -rf /app/lightx2v_kernel && rm -rf /app/cutlass
+
+# cloud deploy
+RUN pip install --no-cache-dir aio-pika asyncpg>=0.27.0 aioboto3>=12.0.0 PyJWT alibabacloud_dypnsapi20170525==1.2.2 redis==6.4.0 tos
+
+RUN curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh -s -- -y --default-toolchain stable
+ENV PATH=/root/.cargo/bin:$PATH
+
+RUN cd /opt \
+ && wget https://mirrors.tuna.tsinghua.edu.cn/gnu/libiconv/libiconv-1.15.tar.gz \
+ && tar zxvf libiconv-1.15.tar.gz \
+ && cd libiconv-1.15 \
+ && ./configure \
+ && make \
+ && make install \
+ && rm -rf /opt/libiconv-1.15
+
+RUN cd /opt \
+ && git clone https://github.com/GStreamer/gstreamer.git -b 1.27.2 --depth 1 \
+ && cd gstreamer \
+ && meson setup builddir \
+ && meson compile -C builddir \
+ && meson install -C builddir \
+ && ldconfig \
+ && rm -rf /opt/gstreamer
+
+RUN cd /opt \
+ && git clone https://github.com/GStreamer/gst-plugins-rs.git -b gstreamer-1.27.2 --depth 1 \
+ && cd gst-plugins-rs \
+ && cargo build --package gst-plugin-webrtchttp --release \
+ && install -m 644 target/release/libgstwebrtchttp.so $(pkg-config --variable=pluginsdir gstreamer-1.0)/ \
+ && rm -rf /opt/gst-plugins-rs
+
+RUN ldconfig
+
+
+# q8f for base docker
+# RUN git clone https://github.com/KONAKONA666/q8_kernels.git --depth 1
+# RUN cd q8_kernels && git submodule init && git submodule update && python setup.py install && rm -rf build
+
+# q8f for 5090 docker
+RUN git clone https://github.com/ModelTC/LTX-Video-Q8-Kernels.git --depth 1
+RUN cd LTX-Video-Q8-Kernels && git submodule init && git submodule update && python setup.py install && rm -rf build
+
+WORKDIR /workspace
diff --git a/dockerfiles/Dockerfile_cambricon_mlu590 b/dockerfiles/Dockerfile_cambricon_mlu590
new file mode 100644
index 0000000000000000000000000000000000000000..3cfa0278ea2199a52d39a2c79b3a7dd412f00281
--- /dev/null
+++ b/dockerfiles/Dockerfile_cambricon_mlu590
@@ -0,0 +1,31 @@
+FROM cambricon-base/pytorch:v25.10.0-torch2.8.0-torchmlu1.29.1-ubuntu22.04-py310 AS base
+
+WORKDIR /workspace/LightX2V
+
+# Set envs
+ENV PYTHONPATH=/workspace/LightX2V
+ENV LD_LIBRARY_PATH=/usr/local/neuware/lib64:${LD_LIBRARY_PATH}
+
+# Install deps
+RUN apt-get update && apt-get install -y --no-install-recommends ffmpeg && \
+ pip install --no-cache-dir \
+ ftfy \
+ imageio \
+ imageio-ffmpeg \
+ loguru \
+ aiohttp \
+ gguf \
+ diffusers \
+ peft==0.17.0 \
+ transformers==4.57.1 &&
+
+# Copy files
+COPY app app
+COPY assets assets
+COPY configs configs
+COPY lightx2v lightx2v
+COPY lightx2v_kernel lightx2v_kernel
+COPY lightx2v_platform lightx2v_platform
+COPY scripts scripts
+COPY test_cases test_cases
+COPY tools tools
diff --git a/dockerfiles/Dockerfile_cu124 b/dockerfiles/Dockerfile_cu124
new file mode 100644
index 0000000000000000000000000000000000000000..ada01a3b841603e1663229882635bb716a0996bc
--- /dev/null
+++ b/dockerfiles/Dockerfile_cu124
@@ -0,0 +1,76 @@
+FROM pytorch/pytorch:2.6.0-cuda12.4-cudnn9-devel AS base
+
+WORKDIR /app
+
+ENV DEBIAN_FRONTEND=noninteractive
+ENV LANG=C.UTF-8
+ENV LC_ALL=C.UTF-8
+ENV LD_LIBRARY_PATH=/usr/local/lib/x86_64-linux-gnu:$LD_LIBRARY_PATH
+
+RUN apt-get update && apt-get install -y vim tmux zip unzip wget git git-lfs build-essential libibverbs-dev ca-certificates \
+ curl iproute2 libsm6 libxext6 kmod ccache libnuma-dev libssl-dev flex bison libgtk-3-dev libpango1.0-dev \
+ libsoup2.4-dev libnice-dev libopus-dev libvpx-dev libx264-dev libsrtp2-dev libglib2.0-dev libdrm-dev\
+ && apt-get clean && rm -rf /var/lib/apt/lists/* && git lfs install
+
+RUN pip install --no-cache-dir packaging ninja cmake scikit-build-core uv meson ruff pre-commit fastapi uvicorn requests -U
+
+RUN git clone https://github.com/vllm-project/vllm.git -b v0.10.0 && cd vllm \
+ && python use_existing_torch.py && pip install -r requirements/build.txt \
+ && pip install --no-cache-dir --no-build-isolation -v -e .
+
+RUN git clone https://github.com/sgl-project/sglang.git -b v0.4.10 && cd sglang/sgl-kernel \
+ && make build && make clean
+
+RUN pip install --no-cache-dir diffusers transformers tokenizers accelerate safetensors opencv-python numpy imageio \
+ imageio-ffmpeg einops loguru qtorch ftfy av decord
+
+RUN conda install conda-forge::ffmpeg=8.0.0 -y && ln -s /opt/conda/bin/ffmpeg /usr/bin/ffmpeg && conda clean -all -y
+
+RUN git clone https://github.com/Dao-AILab/flash-attention.git -b v2.8.3 --recursive
+
+RUN cd flash-attention && python setup.py install && rm -rf build
+
+RUN cd flash-attention/hopper && python setup.py install && rm -rf build
+
+RUN git clone https://github.com/ModelTC/SageAttention.git
+
+RUN cd SageAttention && CUDA_ARCHITECTURES="8.0,8.6,8.9,9.0" EXT_PARALLEL=4 NVCC_APPEND_FLAGS="--threads 8" MAX_JOBS=32 pip install --no-cache-dir -v -e .
+
+RUN git clone https://github.com/KONAKONA666/q8_kernels.git
+
+RUN cd q8_kernels && git submodule init && git submodule update && python setup.py install && rm -rf build
+
+# cloud deploy
+RUN pip install --no-cache-dir aio-pika asyncpg>=0.27.0 aioboto3>=12.0.0 PyJWT alibabacloud_dypnsapi20170525==1.2.2 redis==6.4.0 tos
+
+RUN curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh -s -- -y --default-toolchain stable
+ENV PATH=/root/.cargo/bin:$PATH
+
+RUN cd /opt \
+ && wget https://mirrors.tuna.tsinghua.edu.cn/gnu//libiconv/libiconv-1.15.tar.gz \
+ && tar zxvf libiconv-1.15.tar.gz \
+ && cd libiconv-1.15 \
+ && ./configure \
+ && make \
+ && make install \
+ && rm -rf /opt/libiconv-1.15
+
+RUN cd /opt \
+ && git clone https://github.com/GStreamer/gstreamer.git -b 1.24.12 --depth 1 \
+ && cd gstreamer \
+ && meson setup builddir \
+ && meson compile -C builddir \
+ && meson install -C builddir \
+ && ldconfig \
+ && rm -rf /opt/gstreamer
+
+RUN cd /opt \
+ && git clone https://github.com/GStreamer/gst-plugins-rs.git -b gstreamer-1.24.12 --depth 1 \
+ && cd gst-plugins-rs \
+ && cargo build --package gst-plugin-webrtchttp --release \
+ && install -m 644 target/release/libgstwebrtchttp.so $(pkg-config --variable=pluginsdir gstreamer-1.0)/ \
+ && rm -rf /opt/gst-plugins-rs
+
+RUN ldconfig
+
+WORKDIR /workspace
diff --git a/dockerfiles/Dockerfile_deploy b/dockerfiles/Dockerfile_deploy
new file mode 100644
index 0000000000000000000000000000000000000000..ee4b1fa068483f8bcafc636b572b557e36a23250
--- /dev/null
+++ b/dockerfiles/Dockerfile_deploy
@@ -0,0 +1,32 @@
+FROM node:alpine3.21 AS frontend_builder
+COPY lightx2v /opt/lightx2v
+
+RUN cd /opt/lightx2v/deploy/server/frontend \
+ && npm install \
+ && npm run build
+
+FROM lightx2v/lightx2v:25111101-cu128 AS base
+
+RUN mkdir /workspace/LightX2V
+WORKDIR /workspace/LightX2V
+ENV PYTHONPATH=/workspace/LightX2V
+
+# for multi-person & animate
+RUN pip install ultralytics moviepy pydub pyannote.audio onnxruntime decord peft onnxruntime pandas matplotlib loguru sentencepiece
+
+RUN export COMMIT=0e78a118995e66bb27d78518c4bd9a3e95b4e266 \
+ && export TORCH_CUDA_ARCH_LIST="9.0" \
+ && git clone --depth 1 https://github.com/facebookresearch/sam2.git \
+ && cd sam2 \
+ && git fetch --depth 1 origin $COMMIT \
+ && git checkout $COMMIT \
+ && python setup.py install
+
+COPY tools tools
+COPY assets assets
+COPY configs configs
+COPY lightx2v lightx2v
+COPY lightx2v_kernel lightx2v_kernel
+COPY lightx2v_platform lightx2v_platform
+
+COPY --from=frontend_builder /opt/lightx2v/deploy/server/frontend/dist lightx2v/deploy/server/frontend/dist
diff --git a/docs/EN/.readthedocs.yaml b/docs/EN/.readthedocs.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..dda16a6b056a96ef6afe797884912090a612f567
--- /dev/null
+++ b/docs/EN/.readthedocs.yaml
@@ -0,0 +1,17 @@
+version: 2
+
+# Set the version of Python and other tools you might need
+build:
+ os: ubuntu-20.04
+ tools:
+ python: "3.10"
+
+formats:
+ - epub
+
+sphinx:
+ configuration: docs/EN/source/conf.py
+
+python:
+ install:
+ - requirements: requirements-docs.txt
diff --git a/docs/EN/Makefile b/docs/EN/Makefile
new file mode 100644
index 0000000000000000000000000000000000000000..d0c3cbf1020d5c292abdedf27627c6abe25e2293
--- /dev/null
+++ b/docs/EN/Makefile
@@ -0,0 +1,20 @@
+# Minimal makefile for Sphinx documentation
+#
+
+# You can set these variables from the command line, and also
+# from the environment for the first two.
+SPHINXOPTS ?=
+SPHINXBUILD ?= sphinx-build
+SOURCEDIR = source
+BUILDDIR = build
+
+# Put it first so that "make" without argument is like "make help".
+help:
+ @$(SPHINXBUILD) -M help "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
+
+.PHONY: help Makefile
+
+# Catch-all target: route all unknown targets to Sphinx using the new
+# "make mode" option. $(O) is meant as a shortcut for $(SPHINXOPTS).
+%: Makefile
+ @$(SPHINXBUILD) -M $@ "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
diff --git a/docs/EN/make.bat b/docs/EN/make.bat
new file mode 100644
index 0000000000000000000000000000000000000000..dc1312ab09ca6fb0267dee6b28a38e69c253631a
--- /dev/null
+++ b/docs/EN/make.bat
@@ -0,0 +1,35 @@
+@ECHO OFF
+
+pushd %~dp0
+
+REM Command file for Sphinx documentation
+
+if "%SPHINXBUILD%" == "" (
+ set SPHINXBUILD=sphinx-build
+)
+set SOURCEDIR=source
+set BUILDDIR=build
+
+%SPHINXBUILD% >NUL 2>NUL
+if errorlevel 9009 (
+ echo.
+ echo.The 'sphinx-build' command was not found. Make sure you have Sphinx
+ echo.installed, then set the SPHINXBUILD environment variable to point
+ echo.to the full path of the 'sphinx-build' executable. Alternatively you
+ echo.may add the Sphinx directory to PATH.
+ echo.
+ echo.If you don't have Sphinx installed, grab it from
+ echo.https://www.sphinx-doc.org/
+ exit /b 1
+)
+
+if "%1" == "" goto help
+
+%SPHINXBUILD% -M %1 %SOURCEDIR% %BUILDDIR% %SPHINXOPTS% %O%
+goto end
+
+:help
+%SPHINXBUILD% -M help %SOURCEDIR% %BUILDDIR% %SPHINXOPTS% %O%
+
+:end
+popd
diff --git a/docs/EN/source/conf.py b/docs/EN/source/conf.py
new file mode 100644
index 0000000000000000000000000000000000000000..25f127e5b6e95951e941d510fce9cf6788bbaab9
--- /dev/null
+++ b/docs/EN/source/conf.py
@@ -0,0 +1,128 @@
+# Configuration file for the Sphinx documentation builder.
+#
+# This file only contains a selection of the most common options. For a full
+# list see the documentation:
+# https://www.sphinx-doc.org/en/master/usage/configuration.html
+
+# -- Path setup --------------------------------------------------------------
+
+# If extensions (or modules to document with autodoc) are in another directory,
+# add these directories to sys.path here. If the directory is relative to the
+# documentation root, use os.path.abspath to make it absolute, like shown here.
+
+import logging
+import os
+import sys
+from typing import List
+
+import sphinxcontrib.redoc
+from sphinx.ext import autodoc
+
+logger = logging.getLogger(__name__)
+sys.path.append(os.path.abspath("../.."))
+
+# -- Project information -----------------------------------------------------
+
+project = "Lightx2v"
+copyright = "2025, Lightx2v Team"
+author = "the Lightx2v Team"
+
+# -- General configuration ---------------------------------------------------
+
+# Add any Sphinx extension module names here, as strings. They can be
+# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom
+# ones.
+extensions = [
+ "sphinx.ext.napoleon",
+ "sphinx.ext.viewcode",
+ "sphinx.ext.intersphinx",
+ "sphinx_copybutton",
+ "sphinx.ext.autodoc",
+ "sphinx.ext.autosummary",
+ "sphinx.ext.mathjax",
+ "myst_parser",
+ "sphinxarg.ext",
+ "sphinxcontrib.redoc",
+ "sphinxcontrib.openapi",
+]
+
+myst_enable_extensions = [
+ "dollarmath",
+ "amsmath",
+]
+
+html_static_path = ["_static"]
+
+# Add any paths that contain templates here, relative to this directory.
+templates_path = ["_templates"]
+
+# List of patterns, relative to source directory, that match files and
+# directories to ignore when looking for source files.
+# This pattern also affects html_static_path and html_extra_path.
+exclude_patterns: List[str] = ["**/*.template.rst"]
+
+# Exclude the prompt "$" when copying code
+copybutton_prompt_text = r"\$ "
+copybutton_prompt_is_regexp = True
+
+# -- Options for HTML output -------------------------------------------------
+
+# The theme to use for HTML and HTML Help pages. See the documentation for
+# a list of builtin themes.
+#
+html_title = project
+html_theme = "sphinx_book_theme"
+# html_theme = 'sphinx_rtd_theme'
+html_logo = "../../../assets/img_lightx2v.png"
+html_theme_options = {
+ "path_to_docs": "docs/EN/source",
+ "repository_url": "https://github.com/ModelTC/lightx2v",
+ "use_repository_button": True,
+}
+
+# Add any paths that contain custom static files (such as style sheets) here,
+# relative to this directory. They are copied after the builtin static files,
+# so a file named "default.css" will overwrite the builtin "default.css".
+# html_static_path = ['_static']
+
+
+# Generate additional rst documentation here.
+def setup(app):
+ # from docs.source.generate_examples import generate_examples
+ # generate_examples()
+ pass
+
+
+# Mock out external dependencies here.
+autodoc_mock_imports = [
+ "cpuinfo",
+ "torch",
+ "transformers",
+ "psutil",
+ "prometheus_client",
+ "sentencepiece",
+ "lightllmnumpy",
+ "tqdm",
+ "tensorizer",
+]
+
+for mock_target in autodoc_mock_imports:
+ if mock_target in sys.modules:
+ logger.info(
+ "Potentially problematic mock target (%s) found; autodoc_mock_imports cannot mock modules that have already been loaded into sys.modules when the sphinx build starts.",
+ mock_target,
+ )
+
+
+class MockedClassDocumenter(autodoc.ClassDocumenter):
+ """Remove note about base class when a class is derived from object."""
+
+ def add_line(self, line: str, source: str, *lineno: int) -> None:
+ if line == " Bases: :py:class:`object`":
+ return
+ super().add_line(line, source, *lineno)
+
+
+autodoc.ClassDocumenter = MockedClassDocumenter
+
+navigation_with_keys = False
diff --git a/docs/EN/source/deploy_guides/deploy_comfyui.md b/docs/EN/source/deploy_guides/deploy_comfyui.md
new file mode 100644
index 0000000000000000000000000000000000000000..afde7bd5307eda6874432a204da335a4fa733909
--- /dev/null
+++ b/docs/EN/source/deploy_guides/deploy_comfyui.md
@@ -0,0 +1,25 @@
+# ComfyUI Deployment
+
+## ComfyUI-Lightx2vWrapper
+
+The official ComfyUI integration nodes for LightX2V are now available in a dedicated repository, providing a complete modular configuration system and optimization features.
+
+### Project Repository
+
+- GitHub: [https://github.com/ModelTC/ComfyUI-Lightx2vWrapper](https://github.com/ModelTC/ComfyUI-Lightx2vWrapper)
+
+### Key Features
+
+- Modular Configuration System: Separate nodes for each aspect of video generation
+- Support for both Text-to-Video (T2V) and Image-to-Video (I2V) generation modes
+- Advanced Optimizations:
+ - TeaCache acceleration (up to 3x speedup)
+ - Quantization support (int8, fp8)
+ - Memory optimization with CPU offloading
+ - Lightweight VAE options
+- LoRA Support: Chain multiple LoRA models for customization
+- Multiple Model Support: wan2.1, hunyuan architectures
+
+### Installation and Usage
+
+Please visit the GitHub repository above for detailed installation instructions, usage tutorials, and example workflows.
diff --git a/docs/EN/source/deploy_guides/deploy_gradio.md b/docs/EN/source/deploy_guides/deploy_gradio.md
new file mode 100644
index 0000000000000000000000000000000000000000..5be510feee143be743e73149024b456c40d91c96
--- /dev/null
+++ b/docs/EN/source/deploy_guides/deploy_gradio.md
@@ -0,0 +1,240 @@
+# Gradio Deployment Guide
+
+## 📖 Overview
+
+Lightx2v is a lightweight video inference and generation engine that provides a web interface based on Gradio, supporting both Image-to-Video and Text-to-Video generation modes.
+
+For Windows systems, we provide a convenient one-click deployment solution with automatic environment configuration and intelligent parameter optimization. Please refer to the [One-Click Gradio Startup (Recommended)](./deploy_local_windows.md/#one-click-gradio-startup-recommended) section for detailed instructions.
+
+
+
+## 📁 File Structure
+
+```
+LightX2V/app/
+├── gradio_demo.py # English interface demo
+├── gradio_demo_zh.py # Chinese interface demo
+├── run_gradio.sh # Startup script
+├── README.md # Documentation
+├── outputs/ # Generated video save directory
+└── inference_logs.log # Inference logs
+```
+
+This project contains two main demo files:
+- `gradio_demo.py` - English interface version
+- `gradio_demo_zh.py` - Chinese interface version
+
+## 🚀 Quick Start
+
+### Environment Requirements
+
+Follow the [Quick Start Guide](../getting_started/quickstart.md) to install the environment
+
+#### Recommended Optimization Library Configuration
+
+- ✅ [Flash attention](https://github.com/Dao-AILab/flash-attention)
+- ✅ [Sage attention](https://github.com/thu-ml/SageAttention)
+- ✅ [vllm-kernel](https://github.com/vllm-project/vllm)
+- ✅ [sglang-kernel](https://github.com/sgl-project/sglang/tree/main/sgl-kernel)
+- ✅ [q8-kernel](https://github.com/KONAKONA666/q8_kernels) (only supports ADA architecture GPUs)
+
+Install according to the project homepage tutorials for each operator as needed.
+
+### 📥 Model Download
+
+Refer to the [Model Structure Documentation](../getting_started/model_structure.md) to download complete models (including quantized and non-quantized versions) or download only quantized/non-quantized versions.
+
+#### wan2.1 Model Directory Structure
+
+```
+models/
+├── wan2.1_i2v_720p_lightx2v_4step.safetensors # Original precision
+├── wan2.1_i2v_720p_scaled_fp8_e4m3_lightx2v_4step.safetensors # FP8 quantization
+├── wan2.1_i2v_720p_int8_lightx2v_4step.safetensors # INT8 quantization
+├── wan2.1_i2v_720p_int8_lightx2v_4step_split # INT8 quantization block storage directory
+├── wan2.1_i2v_720p_scaled_fp8_e4m3_lightx2v_4step_split # FP8 quantization block storage directory
+├── Other weights (e.g., t2v)
+├── t5/clip/xlm-roberta-large/google # text and image encoder
+├── vae/lightvae/lighttae # vae
+└── config.json # Model configuration file
+```
+
+#### wan2.2 Model Directory Structure
+
+```
+models/
+├── wan2.2_i2v_A14b_high_noise_lightx2v_4step_1030.safetensors # high noise original precision
+├── wan2.2_i2v_A14b_high_noise_fp8_e4m3_lightx2v_4step_1030.safetensors # high noise FP8 quantization
+├── wan2.2_i2v_A14b_high_noise_int8_lightx2v_4step_1030.safetensors # high noise INT8 quantization
+├── wan2.2_i2v_A14b_high_noise_int8_lightx2v_4step_1030_split # high noise INT8 quantization block storage directory
+├── wan2.2_i2v_A14b_low_noise_lightx2v_4step.safetensors # low noise original precision
+├── wan2.2_i2v_A14b_low_noise_fp8_e4m3_lightx2v_4step.safetensors # low noise FP8 quantization
+├── wan2.2_i2v_A14b_low_noise_int8_lightx2v_4step.safetensors # low noise INT8 quantization
+├── wan2.2_i2v_A14b_low_noise_int8_lightx2v_4step_split # low noise INT8 quantization block storage directory
+├── t5/clip/xlm-roberta-large/google # text and image encoder
+├── vae/lightvae/lighttae # vae
+└── config.json # Model configuration file
+```
+
+**📝 Download Instructions**:
+
+- Model weights can be downloaded from HuggingFace:
+ - [Wan2.1-Distill-Models](https://huggingface.co/lightx2v/Wan2.1-Distill-Models)
+ - [Wan2.2-Distill-Models](https://huggingface.co/lightx2v/Wan2.2-Distill-Models)
+- Text and Image Encoders can be downloaded from [Encoders](https://huggingface.co/lightx2v/Encoders)
+- VAE can be downloaded from [Autoencoders](https://huggingface.co/lightx2v/Autoencoders)
+- For `xxx_split` directories (e.g., `wan2.1_i2v_720p_scaled_fp8_e4m3_lightx2v_4step_split`), which store multiple safetensors by block, suitable for devices with insufficient memory. For example, devices with 16GB or less memory should download according to their own situation.
+
+### Startup Methods
+
+#### Method 1: Using Startup Script (Recommended)
+
+**Linux Environment:**
+```bash
+# 1. Edit the startup script to configure relevant paths
+cd app/
+vim run_gradio.sh
+
+# Configuration items that need to be modified:
+# - lightx2v_path: Lightx2v project root directory path
+# - model_path: Model root directory path (contains all model files)
+
+# 💾 Important note: Recommend pointing model paths to SSD storage locations
+# Example: /mnt/ssd/models/ or /data/ssd/models/
+
+# 2. Run the startup script
+bash run_gradio.sh
+
+# 3. Or start with parameters
+bash run_gradio.sh --lang en --port 8032
+bash run_gradio.sh --lang zh --port 7862
+```
+
+**Windows Environment:**
+```cmd
+# 1. Edit the startup script to configure relevant paths
+cd app\
+notepad run_gradio_win.bat
+
+# Configuration items that need to be modified:
+# - lightx2v_path: Lightx2v project root directory path
+# - model_path: Model root directory path (contains all model files)
+
+# 💾 Important note: Recommend pointing model paths to SSD storage locations
+# Example: D:\models\ or E:\models\
+
+# 2. Run the startup script
+run_gradio_win.bat
+
+# 3. Or start with parameters
+run_gradio_win.bat --lang en --port 8032
+run_gradio_win.bat --lang zh --port 7862
+```
+
+#### Method 2: Direct Command Line Startup
+
+```bash
+pip install -v git+https://github.com/ModelTC/LightX2V.git
+```
+
+**Linux Environment:**
+
+**English Interface Version:**
+```bash
+python gradio_demo.py \
+ --model_path /path/to/models \
+ --server_name 0.0.0.0 \
+ --server_port 7862
+```
+
+**Chinese Interface Version:**
+```bash
+python gradio_demo_zh.py \
+ --model_path /path/to/models \
+ --server_name 0.0.0.0 \
+ --server_port 7862
+```
+
+**Windows Environment:**
+
+**English Interface Version:**
+```cmd
+python gradio_demo.py ^
+ --model_path D:\models ^
+ --server_name 127.0.0.1 ^
+ --server_port 7862
+```
+
+**Chinese Interface Version:**
+```cmd
+python gradio_demo_zh.py ^
+ --model_path D:\models ^
+ --server_name 127.0.0.1 ^
+ --server_port 7862
+```
+
+**💡 Tip**: Model type (wan2.1/wan2.2), task type (i2v/t2v), and specific model file selection are all configured in the Web interface.
+
+## 📋 Command Line Parameters
+
+| Parameter | Type | Required | Default | Description |
+|-----------|------|----------|---------|-------------|
+| `--model_path` | str | ✅ | - | Model root directory path (directory containing all model files) |
+| `--server_port` | int | ❌ | 7862 | Server port |
+| `--server_name` | str | ❌ | 0.0.0.0 | Server IP address |
+| `--output_dir` | str | ❌ | ./outputs | Output video save directory |
+
+**💡 Note**: Model type (wan2.1/wan2.2), task type (i2v/t2v), and specific model file selection are all configured in the Web interface.
+
+## 🎯 Features
+
+### Model Configuration
+
+- **Model Type**: Supports wan2.1 and wan2.2 model architectures
+- **Task Type**: Supports Image-to-Video (i2v) and Text-to-Video (t2v) generation modes
+- **Model Selection**: Frontend automatically identifies and filters available model files, supports automatic quantization precision detection
+- **Encoder Configuration**: Supports selection of T5 text encoder, CLIP image encoder, and VAE decoder
+- **Operator Selection**: Supports multiple attention operators and quantization matrix multiplication operators, system automatically sorts by installation status
+
+### Input Parameters
+
+- **Prompt**: Describe the expected video content
+- **Negative Prompt**: Specify elements you don't want to appear
+- **Input Image**: Upload input image required in i2v mode
+- **Resolution**: Supports multiple preset resolutions (480p/540p/720p)
+- **Random Seed**: Controls the randomness of generation results
+- **Inference Steps**: Affects the balance between generation quality and speed (defaults to 4 steps for distilled models)
+
+### Video Parameters
+
+- **FPS**: Frames per second
+- **Total Frames**: Video length
+- **CFG Scale Factor**: Controls prompt influence strength (1-10, defaults to 1 for distilled models)
+- **Distribution Shift**: Controls generation style deviation degree (0-10)
+
+## 🔧 Auto-Configuration Feature
+
+The system automatically configures optimal inference options based on your hardware configuration (GPU VRAM and CPU memory) without manual adjustment. The best configuration is automatically applied on startup, including:
+
+- **GPU Memory Optimization**: Automatically enables CPU offloading, VAE tiling inference, etc. based on VRAM size
+- **CPU Memory Optimization**: Automatically enables lazy loading, module unloading, etc. based on system memory
+- **Operator Selection**: Automatically selects the best installed operators (sorted by priority)
+- **Quantization Configuration**: Automatically detects and applies quantization precision based on model file names
+
+
+### Log Viewing
+
+```bash
+# View inference logs
+tail -f inference_logs.log
+
+# View GPU usage
+nvidia-smi
+
+# View system resources
+htop
+```
+
+Welcome to submit Issues and Pull Requests to improve this project!
+
+**Note**: Please comply with relevant laws and regulations when using videos generated by this tool, and do not use them for illegal purposes.
diff --git a/docs/EN/source/deploy_guides/deploy_local_windows.md b/docs/EN/source/deploy_guides/deploy_local_windows.md
new file mode 100644
index 0000000000000000000000000000000000000000..e675f9c5af1bae7d2220747a85219a8ccbfab291
--- /dev/null
+++ b/docs/EN/source/deploy_guides/deploy_local_windows.md
@@ -0,0 +1,127 @@
+# Windows Local Deployment Guide
+
+## 📖 Overview
+
+This document provides detailed instructions for deploying LightX2V locally on Windows environments, including batch file inference, Gradio Web interface inference, and other usage methods.
+
+## 🚀 Quick Start
+
+### Environment Requirements
+
+#### Hardware Requirements
+- **GPU**: NVIDIA GPU, recommended 8GB+ VRAM
+- **Memory**: Recommended 16GB+ RAM
+- **Storage**: Strongly recommended to use SSD solid-state drives, mechanical hard drives will cause slow model loading
+
+
+## 🎯 Usage Methods
+
+### Method 1: Using Batch File Inference
+
+Refer to [Quick Start Guide](../getting_started/quickstart.md) to install environment, and use [batch files](https://github.com/ModelTC/LightX2V/tree/main/scripts/win) to run.
+
+### Method 2: Using Gradio Web Interface Inference
+
+#### Manual Gradio Configuration
+
+Refer to [Quick Start Guide](../getting_started/quickstart.md) to install environment, refer to [Gradio Deployment Guide](./deploy_gradio.md)
+
+#### One-Click Gradio Startup (Recommended)
+
+**📦 Download Software Package**
+- [Quark Cloud](https://pan.quark.cn/s/8af1162d7a15)
+
+**📁 Directory Structure**
+After extraction, ensure the directory structure is as follows:
+
+```
+├── env/ # LightX2V environment directory
+├── LightX2V/ # LightX2V project directory
+├── start_lightx2v.bat # One-click startup script
+├── lightx2v_config.txt # Configuration file
+├── LightX2V使用说明.txt # LightX2V usage instructions
+├── outputs/ # Generated video save directory
+└── models/ # Model storage directory
+```
+
+**📥 Model Download**:
+
+Refer to [Model Structure Documentation](../getting_started/model_structure.md) or [Gradio Deployment Guide](./deploy_gradio.md) to download complete models (including quantized and non-quantized versions) or download only quantized/non-quantized versions.
+
+
+**📋 Configuration Parameters**
+
+Edit the `lightx2v_config.txt` file and modify the following parameters as needed:
+
+```ini
+
+# Interface language (zh: Chinese, en: English)
+lang=en
+
+# Server port
+port=8032
+
+# GPU device ID (0, 1, 2...)
+gpu=0
+
+# Model path
+model_path=models/
+```
+
+**🚀 Start Service**
+
+Double-click to run the `start_lightx2v.bat` file, the script will:
+1. Automatically read configuration file
+2. Verify model paths and file integrity
+3. Start Gradio Web interface
+4. Automatically open browser to access service
+
+
+
+
+**⚠️ Important Notes**:
+- **Display Issues**: If the webpage opens blank or displays abnormally, please run `pip install --upgrade gradio` to upgrade the Gradio version.
+
+### Method 3: Using ComfyUI Inference
+
+This guide will instruct you on how to download and use the portable version of the Lightx2v-ComfyUI environment, so you can avoid manual environment configuration steps. This is suitable for users who want to quickly start experiencing accelerated video generation with Lightx2v on Windows systems.
+
+#### Download the Windows Portable Environment:
+
+- [Baidu Cloud Download](https://pan.baidu.com/s/1FVlicTXjmXJA1tAVvNCrBw?pwd=wfid), extraction code: wfid
+
+The portable environment already packages all Python runtime dependencies, including the code and dependencies for ComfyUI and LightX2V. After downloading, simply extract to use.
+
+After extraction, the directory structure is as follows:
+
+```shell
+lightx2v_env
+├──📂 ComfyUI # ComfyUI code
+├──📂 portable_python312_embed # Standalone Python environment
+└── run_nvidia_gpu.bat # Windows startup script (double-click to start)
+```
+
+#### Start ComfyUI
+
+Directly double-click the run_nvidia_gpu.bat file. The system will open a Command Prompt window and run the program. The first startup may take a while, please be patient. After startup is complete, the browser will automatically open and display the ComfyUI frontend interface.
+
+
+
+The plugin used by LightX2V-ComfyUI is [ComfyUI-Lightx2vWrapper](https://github.com/ModelTC/ComfyUI-Lightx2vWrapper). Example workflows can be obtained from this project.
+
+#### Tested Graphics Cards (offload mode)
+
+- Tested model: `Wan2.1-I2V-14B-480P`
+
+| GPU Model | Task Type | VRAM Capacity | Actual Max VRAM Usage | Actual Max RAM Usage |
+|:-----------|:------------|:--------------|:---------------------|:---------------------|
+| 3090Ti | I2V | 24G | 6.1G | 7.1G |
+| 3080Ti | I2V | 12G | 6.1G | 7.1G |
+| 3060Ti | I2V | 8G | 6.1G | 7.1G |
+| 4070Ti Super | I2V | 16G | 6.1G | 7.1G |
+| 4070 | I2V | 12G | 6.1G | 7.1G |
+| 4060 | I2V | 8G | 6.1G | 7.1G |
+
+#### Environment Packaging and Usage Reference
+- [ComfyUI](https://github.com/comfyanonymous/ComfyUI)
+- [Portable-Windows-ComfyUI-Docs](https://docs.comfy.org/zh-CN/installation/comfyui_portable_windows#portable-%E5%8F%8A%E8%87%AA%E9%83%A8%E7%BD%B2)
diff --git a/docs/EN/source/deploy_guides/deploy_service.md b/docs/EN/source/deploy_guides/deploy_service.md
new file mode 100644
index 0000000000000000000000000000000000000000..b34b349622d77ba874b394404794976652547a01
--- /dev/null
+++ b/docs/EN/source/deploy_guides/deploy_service.md
@@ -0,0 +1,88 @@
+# Service Deployment
+
+lightx2v provides asynchronous service functionality. The code entry point is [here](https://github.com/ModelTC/lightx2v/blob/main/lightx2v/api_server.py)
+
+### Start the Service
+
+```shell
+# Modify the paths in the script
+bash scripts/start_server.sh
+```
+
+The `--port 8000` option means the service will bind to port `8000` on the local machine. You can change this as needed.
+
+### Client Sends Request
+
+```shell
+python scripts/post.py
+```
+
+The service endpoint is: `/v1/tasks/`
+
+The `message` parameter in `scripts/post.py` is as follows:
+
+```python
+message = {
+ "prompt": "Two anthropomorphic cats in comfy boxing gear and bright gloves fight intensely on a spotlighted stage.",
+ "negative_prompt": "镜头晃动,色调艳丽,过曝,静态,细节模糊不清,字幕,风格,作品,画作,画面,静止,整体发灰,最差质量,低质量,JPEG压缩残留,丑陋的,残缺的,多余的手指,画得不好的手部,画得不好的脸部,畸形的,毁容的,形态畸形的肢体,手指融合,静止不动的画面,杂乱的背景,三条腿,背景人很多,倒着走",
+ "image_path": "",
+}
+```
+
+1. `prompt`, `negative_prompt`, and `image_path` are basic inputs for video generation. `image_path` can be an empty string, indicating no image input is needed.
+
+
+### Client Checks Server Status
+
+```shell
+python scripts/check_status.py
+```
+
+The service endpoints include:
+
+1. `/v1/service/status` is used to check the status of the service. It returns whether the service is `busy` or `idle`. The service only accepts new requests when it is `idle`.
+
+2. `/v1/tasks/` is used to get all tasks received and completed by the server.
+
+3. `/v1/tasks/{task_id}/status` is used to get the status of a specified `task_id`. It returns whether the task is `processing` or `completed`.
+
+### Client Stops the Current Task on the Server at Any Time
+
+```shell
+python scripts/stop_running_task.py
+```
+
+The service endpoint is: `/v1/tasks/running`
+
+After terminating the task, the server will not exit but will return to waiting for new requests.
+
+### Starting Multiple Services on a Single Node
+
+On a single node, you can start multiple services using `scripts/start_server.sh` (Note that the port numbers under the same IP must be different for each service), or you can start multiple services at once using `scripts/start_multi_servers.sh`:
+
+```shell
+num_gpus=8 bash scripts/start_multi_servers.sh
+```
+
+Where `num_gpus` indicates the number of services to start; the services will run on consecutive ports starting from `--start_port`.
+
+### Scheduling Between Multiple Services
+
+```shell
+python scripts/post_multi_servers.py
+```
+
+`post_multi_servers.py` will schedule multiple client requests based on the idle status of the services.
+
+### API Endpoints Summary
+
+| Endpoint | Method | Description |
+|----------|--------|-------------|
+| `/v1/tasks/` | POST | Create video generation task |
+| `/v1/tasks/form` | POST | Create video generation task via form |
+| `/v1/tasks/` | GET | Get all task list |
+| `/v1/tasks/{task_id}/status` | GET | Get status of specified task |
+| `/v1/tasks/{task_id}/result` | GET | Get result video file of specified task |
+| `/v1/tasks/running` | DELETE | Stop currently running task |
+| `/v1/files/download/{file_path}` | GET | Download file |
+| `/v1/service/status` | GET | Get service status |
diff --git a/docs/EN/source/deploy_guides/for_low_latency.md b/docs/EN/source/deploy_guides/for_low_latency.md
new file mode 100644
index 0000000000000000000000000000000000000000..5e8df8a467452ff0223c9f62295e8c74b73b0002
--- /dev/null
+++ b/docs/EN/source/deploy_guides/for_low_latency.md
@@ -0,0 +1,41 @@
+# Deployment for Low Latency Scenarios
+
+In low latency scenarios, we pursue faster speed, ignoring issues such as video memory and RAM overhead. We provide two solutions:
+
+## 💡 Solution 1: Inference with Step Distillation Model
+
+This solution can refer to the [Step Distillation Documentation](https://lightx2v-en.readthedocs.io/en/latest/method_tutorials/step_distill.html)
+
+🧠 **Step Distillation** is a very direct acceleration inference solution for video generation models. By distilling from 50 steps to 4 steps, the time consumption will be reduced to 4/50 of the original. At the same time, under this solution, it can still be combined with the following solutions:
+1. [Efficient Attention Mechanism Solution](https://lightx2v-en.readthedocs.io/en/latest/method_tutorials/attention.html)
+2. [Model Quantization](https://lightx2v-en.readthedocs.io/en/latest/method_tutorials/quantization.html)
+
+## 💡 Solution 2: Inference with Non-Step Distillation Model
+
+Step distillation requires relatively large training resources, and the model after step distillation may have degraded video dynamic range.
+
+For the original model without step distillation, we can use the following solutions or a combination of multiple solutions for acceleration:
+
+1. [Parallel Inference](https://lightx2v-en.readthedocs.io/en/latest/method_tutorials/parallel.html) for multi-GPU parallel acceleration.
+2. [Feature Caching](https://lightx2v-en.readthedocs.io/en/latest/method_tutorials/cache.html) to reduce the actual inference steps.
+3. [Efficient Attention Mechanism Solution](https://lightx2v-en.readthedocs.io/en/latest/method_tutorials/attention.html) to accelerate Attention inference.
+4. [Model Quantization](https://lightx2v-en.readthedocs.io/en/latest/method_tutorials/quantization.html) to accelerate Linear layer inference.
+5. [Variable Resolution Inference](https://lightx2v-en.readthedocs.io/en/latest/method_tutorials/changing_resolution.html) to reduce the resolution of intermediate inference steps.
+
+## 💡 Using Tiny VAE
+
+In some cases, the VAE component can be time-consuming. You can use a lightweight VAE for acceleration, which can also reduce some GPU memory usage.
+
+```python
+{
+ "use_tae": true,
+ "tae_path": "/path to taew2_1.pth"
+}
+```
+The taew2_1.pth weights can be downloaded from [here](https://github.com/madebyollin/taehv/raw/refs/heads/main/taew2_1.pth)
+
+## ⚠️ Note
+
+Some acceleration solutions currently cannot be used together, and we are working to resolve this issue.
+
+If you have any questions, feel free to report bugs or request features in [🐛 GitHub Issues](https://github.com/ModelTC/lightx2v/issues)
diff --git a/docs/EN/source/deploy_guides/for_low_resource.md b/docs/EN/source/deploy_guides/for_low_resource.md
new file mode 100644
index 0000000000000000000000000000000000000000..ad11c7489ff6f5748dcfd2b482bfd93600d9437f
--- /dev/null
+++ b/docs/EN/source/deploy_guides/for_low_resource.md
@@ -0,0 +1,219 @@
+# Lightx2v Low-Resource Deployment Guide
+
+## 📋 Overview
+
+This guide is specifically designed for hardware resource-constrained environments, particularly configurations with **8GB VRAM + 16/32GB RAM**, providing detailed instructions on how to successfully run Lightx2v 14B models for 480p and 720p video generation.
+
+Lightx2v is a powerful video generation model, but it requires careful optimization to run smoothly in resource-constrained environments. This guide provides a complete solution from hardware selection to software configuration, ensuring you can achieve the best video generation experience under limited hardware conditions.
+
+## 🎯 Target Hardware Configuration
+
+### Recommended Hardware Specifications
+
+**GPU Requirements**:
+- **VRAM**: 8GB (RTX 3060/3070/4060/4060Ti, etc.)
+- **Architecture**: NVIDIA graphics cards with CUDA support
+
+**System Memory**:
+- **Minimum**: 16GB DDR4
+- **Recommended**: 32GB DDR4/DDR5
+- **Memory Speed**: 3200MHz or higher recommended
+
+**Storage Requirements**:
+- **Type**: NVMe SSD strongly recommended
+- **Capacity**: At least 50GB available space
+- **Speed**: Read speed of 3000MB/s or higher recommended
+
+**CPU Requirements**:
+- **Cores**: 8 cores or more recommended
+- **Frequency**: 3.0GHz or higher recommended
+- **Architecture**: Support for AVX2 instruction set
+
+## ⚙️ Core Optimization Strategies
+
+### 1. Environment Optimization
+
+Before running Lightx2v, it's recommended to set the following environment variables to optimize performance:
+
+```bash
+# CUDA memory allocation optimization
+export PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True
+
+# Enable CUDA Graph mode to improve inference performance
+export ENABLE_GRAPH_MODE=true
+
+# Use BF16 precision for inference to reduce VRAM usage (default FP32 precision)
+export DTYPE=BF16
+```
+
+**Optimization Details**:
+- `expandable_segments:True`: Allows dynamic expansion of CUDA memory segments, reducing memory fragmentation
+- `ENABLE_GRAPH_MODE=true`: Enables CUDA Graph to reduce kernel launch overhead
+- `DTYPE=BF16`: Uses BF16 precision to reduce VRAM usage while maintaining quality
+
+### 2. Quantization Strategy
+
+Quantization is a key optimization technique in low-resource environments, reducing memory usage by lowering model precision.
+
+#### Quantization Scheme Comparison
+
+**FP8 Quantization** (Recommended for RTX 40 series):
+```python
+# Suitable for GPUs supporting FP8, providing better precision
+dit_quant_scheme = "fp8" # DIT model quantization
+t5_quant_scheme = "fp8" # T5 text encoder quantization
+clip_quant_scheme = "fp8" # CLIP visual encoder quantization
+```
+
+**INT8 Quantization** (Universal solution):
+```python
+# Suitable for all GPUs, minimal memory usage
+dit_quant_scheme = "int8" # 8-bit integer quantization
+t5_quant_scheme = "int8" # Text encoder quantization
+clip_quant_scheme = "int8" # Visual encoder quantization
+```
+
+### 3. Efficient Operator Selection Guide
+
+Choosing the right operators can significantly improve inference speed and reduce memory usage.
+
+#### Attention Operator Selection
+
+**Recommended Priority**:
+1. **[Sage Attention](https://github.com/thu-ml/SageAttention)** (Highest priority)
+
+2. **[Flash Attention](https://github.com/Dao-AILab/flash-attention)** (Universal solution)
+
+#### Matrix Multiplication Operator Selection
+
+**ADA Architecture GPUs** (RTX 40 series):
+
+Recommended priority:
+1. **[q8-kernel](https://github.com/KONAKONA666/q8_kernels)** (Highest performance, ADA architecture only)
+2. **[sglang-kernel](https://github.com/sgl-project/sglang/tree/main/sgl-kernel)** (Balanced solution)
+3. **[vllm-kernel](https://github.com/vllm-project/vllm)** (Universal solution)
+
+**Other Architecture GPUs**:
+1. **[sglang-kernel](https://github.com/sgl-project/sglang/tree/main/sgl-kernel)** (Recommended)
+2. **[vllm-kernel](https://github.com/vllm-project/vllm)** (Alternative)
+
+### 4. Parameter Offloading Strategy
+
+Parameter offloading technology allows models to dynamically schedule parameters between CPU and disk, breaking through VRAM limitations.
+
+#### Three-Level Offloading Architecture
+
+```python
+# Disk-CPU-GPU three-level offloading configuration
+cpu_offload=True # Enable CPU offloading
+t5_cpu_offload=True # Enable T5 encoder CPU offloading
+offload_granularity=phase # DIT model fine-grained offloading
+t5_offload_granularity=block # T5 encoder fine-grained offloading
+lazy_load = True # Enable lazy loading mechanism
+num_disk_workers = 2 # Disk I/O worker threads
+```
+
+#### Offloading Strategy Details
+
+**Lazy Loading Mechanism**:
+- Model parameters are loaded from disk to CPU on demand
+- Reduces runtime memory usage
+- Supports large models running with limited memory
+
+**Disk Storage Optimization**:
+- Use high-speed SSD to store model parameters
+- Store model files grouped by blocks
+- Refer to conversion script [documentation](https://github.com/ModelTC/lightx2v/tree/main/tools/convert/readme.md), specify `--save_by_block` parameter during conversion
+
+### 5. VRAM Optimization Techniques
+
+VRAM optimization strategies for 720p video generation.
+
+#### CUDA Memory Management
+
+```python
+# CUDA memory cleanup configuration
+clean_cuda_cache = True # Timely cleanup of GPU cache
+rotary_chunk = True # Rotary position encoding chunked computation
+rotary_chunk_size = 100 # Chunk size, adjustable based on VRAM
+```
+
+#### Chunked Computation Strategy
+
+**Rotary Position Encoding Chunking**:
+- Process long sequences in small chunks
+- Reduce peak VRAM usage
+- Maintain computational precision
+
+### 6. VAE Optimization
+
+VAE (Variational Autoencoder) is a key component in video generation, and optimizing VAE can significantly improve performance.
+
+#### VAE Chunked Inference
+
+```python
+# VAE optimization configuration
+use_tiling_vae = True # Enable VAE chunked inference
+```
+
+#### Lightweight VAE
+
+```python
+# VAE optimization configuration
+use_tae = True # Use lightweight VAE
+tae_path = "/path to taew2_1.pth"
+```
+You can download taew2_1.pth [here](https://github.com/madebyollin/taehv/blob/main/taew2_1.pth)
+
+**VAE Optimization Effects**:
+- Standard VAE: Baseline performance, 100% quality retention
+- Standard VAE chunked: Reduces VRAM usage, increases inference time, 100% quality retention
+- Lightweight VAE: Extremely low VRAM usage, video quality loss
+
+### 7. Model Selection Strategy
+
+Choosing the right model version is crucial for low-resource environments.
+
+#### Recommended Model Comparison
+
+**Distilled Models** (Strongly recommended):
+- ✅ **[Wan2.1-I2V-14B-480P-StepDistill-CfgDistill-Lightx2v](https://huggingface.co/lightx2v/Wan2.1-I2V-14B-480P-StepDistill-CfgDistill-Lightx2v)**
+
+- ✅ **[Wan2.1-I2V-14B-720P-StepDistill-CfgDistill-Lightx2v](https://huggingface.co/lightx2v/Wan2.1-I2V-14B-720P-StepDistill-CfgDistill-Lightx2v)**
+
+#### Performance Optimization Suggestions
+
+When using the above distilled models, you can further optimize performance:
+- Disable CFG: `"enable_cfg": false`
+- Reduce inference steps: `infer_step: 4`
+- Reference configuration files: [config](https://github.com/ModelTC/LightX2V/tree/main/configs/distill)
+
+## 🚀 Complete Configuration Examples
+
+### Pre-configured Templates
+
+- **[14B Model 480p Video Generation Configuration](https://github.com/ModelTC/lightx2v/tree/main/configs/offload/disk/wan_i2v_phase_lazy_load_480p.json)**
+
+- **[14B Model 720p Video Generation Configuration](https://github.com/ModelTC/lightx2v/tree/main/configs/offload/disk/wan_i2v_phase_lazy_load_720p.json)**
+
+- **[1.3B Model 720p Video Generation Configuration](https://github.com/ModelTC/LightX2V/tree/main/configs/offload/block/wan_t2v_1_3b.json)**
+ - The inference bottleneck for 1.3B models is the T5 encoder, so the configuration file specifically optimizes for T5
+
+**[Launch Script](https://github.com/ModelTC/LightX2V/tree/main/scripts/wan/run_wan_i2v_lazy_load.sh)**
+
+## 📚 Reference Resources
+
+- [Parameter Offloading Mechanism Documentation](../method_tutorials/offload.md) - In-depth understanding of offloading technology principles
+- [Quantization Technology Guide](../method_tutorials/quantization.md) - Detailed explanation of quantization technology
+- [Gradio Deployment Guide](deploy_gradio.md) - Detailed Gradio deployment instructions
+
+## ⚠️ Important Notes
+
+1. **Hardware Requirements**: Ensure your hardware meets minimum configuration requirements
+2. **Driver Version**: Recommend using the latest NVIDIA drivers (535+)
+3. **CUDA Version**: Ensure CUDA version is compatible with PyTorch (recommend CUDA 11.8+)
+4. **Storage Space**: Reserve sufficient disk space for model caching (at least 50GB)
+5. **Network Environment**: Stable network connection required for initial model download
+6. **Environment Variables**: Be sure to set the recommended environment variables to optimize performance
+
+**Technical Support**: If you encounter issues, please submit an Issue to the project repository.
diff --git a/docs/EN/source/deploy_guides/lora_deploy.md b/docs/EN/source/deploy_guides/lora_deploy.md
new file mode 100644
index 0000000000000000000000000000000000000000..769d1d57b4f3c620f36e077fe35dbb4145196cc2
--- /dev/null
+++ b/docs/EN/source/deploy_guides/lora_deploy.md
@@ -0,0 +1,214 @@
+# LoRA Model Deployment and Related Tools
+
+LoRA (Low-Rank Adaptation) is an efficient model fine-tuning technique that significantly reduces the number of trainable parameters through low-rank matrix decomposition. LightX2V fully supports LoRA technology, including LoRA inference, LoRA extraction, and LoRA merging functions.
+
+## 🎯 LoRA Technical Features
+
+- **Efficient Fine-tuning**: Dramatically reduces training parameters through low-rank adaptation
+- **Flexible Deployment**: Supports dynamic loading and removal of LoRA weights
+- **Multiple Formats**: Supports various LoRA weight formats and naming conventions
+- **Comprehensive Tools**: Provides complete LoRA extraction and merging toolchain
+
+## 📜 LoRA Inference Deployment
+
+### Configuration File Method
+
+Specify LoRA path in configuration file:
+
+```json
+{
+ "lora_configs": [
+ {
+ "path": "/path/to/your/lora.safetensors",
+ "strength": 1.0
+ }
+ ]
+}
+```
+
+**Configuration Parameter Description:**
+
+- `lora_path`: LoRA weight file path list, supports loading multiple LoRAs simultaneously
+- `strength_model`: LoRA strength coefficient (alpha), controls LoRA's influence on the original model
+
+### Command Line Method
+
+Specify LoRA path directly in command line (supports loading single LoRA only):
+
+```bash
+python -m lightx2v.infer \
+ --model_cls wan2.1 \
+ --task t2v \
+ --model_path /path/to/model \
+ --config_json /path/to/config.json \
+ --lora_path /path/to/your/lora.safetensors \
+ --lora_strength 0.8 \
+ --prompt "Your prompt here"
+```
+
+### Multiple LoRAs Configuration
+
+To use multiple LoRAs with different strengths, specify them in the config JSON file:
+
+```json
+{
+ "lora_configs": [
+ {
+ "path": "/path/to/first_lora.safetensors",
+ "strength": 0.8
+ },
+ {
+ "path": "/path/to/second_lora.safetensors",
+ "strength": 0.5
+ }
+ ]
+}
+```
+
+### Supported LoRA Formats
+
+LightX2V supports multiple LoRA weight naming conventions:
+
+| Format Type | Weight Naming | Description |
+|-------------|---------------|-------------|
+| **Standard LoRA** | `lora_A.weight`, `lora_B.weight` | Standard LoRA matrix decomposition format |
+| **Down/Up Format** | `lora_down.weight`, `lora_up.weight` | Another common naming convention |
+| **Diff Format** | `diff` | `weight` difference values |
+| **Bias Diff** | `diff_b` | `bias` weight difference values |
+| **Modulation Diff** | `diff_m` | `modulation` weight difference values |
+
+### Inference Script Examples
+
+**Step Distillation LoRA Inference:**
+
+```bash
+# T2V LoRA Inference
+bash scripts/wan/run_wan_t2v_distill_4step_cfg_lora.sh
+
+# I2V LoRA Inference
+bash scripts/wan/run_wan_i2v_distill_4step_cfg_lora.sh
+```
+
+**Audio-Driven LoRA Inference:**
+
+```bash
+bash scripts/wan/run_wan_i2v_audio.sh
+```
+
+### Using LoRA in API Service
+
+Specify through [config file](wan_t2v_distill_4step_cfg_lora.json), modify the startup command in [scripts/server/start_server.sh](https://github.com/ModelTC/lightx2v/blob/main/scripts/server/start_server.sh):
+
+```bash
+python -m lightx2v.api_server \
+ --model_cls wan2.1_distill \
+ --task t2v \
+ --model_path $model_path \
+ --config_json ${lightx2v_path}/configs/distill/wan_t2v_distill_4step_cfg_lora.json \
+ --port 8000 \
+ --nproc_per_node 1
+```
+
+## 🔧 LoRA Extraction Tool
+
+Use `tools/extract/lora_extractor.py` to extract LoRA weights from the difference between two models.
+
+### Basic Usage
+
+```bash
+python tools/extract/lora_extractor.py \
+ --source-model /path/to/base/model \
+ --target-model /path/to/finetuned/model \
+ --output /path/to/extracted/lora.safetensors \
+ --rank 32
+```
+
+### Parameter Description
+
+| Parameter | Type | Required | Default | Description |
+|-----------|------|----------|---------|-------------|
+| `--source-model` | str | ✅ | - | Base model path |
+| `--target-model` | str | ✅ | - | Fine-tuned model path |
+| `--output` | str | ✅ | - | Output LoRA file path |
+| `--source-type` | str | ❌ | `safetensors` | Base model format (`safetensors`/`pytorch`) |
+| `--target-type` | str | ❌ | `safetensors` | Fine-tuned model format (`safetensors`/`pytorch`) |
+| `--output-format` | str | ❌ | `safetensors` | Output format (`safetensors`/`pytorch`) |
+| `--rank` | int | ❌ | `32` | LoRA rank value |
+| `--output-dtype` | str | ❌ | `bf16` | Output data type |
+| `--diff-only` | bool | ❌ | `False` | Save weight differences only, without LoRA decomposition |
+
+### Advanced Usage Examples
+
+**Extract High-Rank LoRA:**
+
+```bash
+python tools/extract/lora_extractor.py \
+ --source-model /path/to/base/model \
+ --target-model /path/to/finetuned/model \
+ --output /path/to/high_rank_lora.safetensors \
+ --rank 64 \
+ --output-dtype fp16
+```
+
+**Save Weight Differences Only:**
+
+```bash
+python tools/extract/lora_extractor.py \
+ --source-model /path/to/base/model \
+ --target-model /path/to/finetuned/model \
+ --output /path/to/weight_diff.safetensors \
+ --diff-only
+```
+
+## 🔀 LoRA Merging Tool
+
+Use `tools/extract/lora_merger.py` to merge LoRA weights into the base model for subsequent quantization and other operations.
+
+### Basic Usage
+
+```bash
+python tools/extract/lora_merger.py \
+ --source-model /path/to/base/model \
+ --lora-model /path/to/lora.safetensors \
+ --output /path/to/merged/model.safetensors \
+ --alpha 1.0
+```
+
+### Parameter Description
+
+| Parameter | Type | Required | Default | Description |
+|-----------|------|----------|---------|-------------|
+| `--source-model` | str | ✅ | - | Base model path |
+| `--lora-model` | str | ✅ | - | LoRA weights path |
+| `--output` | str | ✅ | - | Output merged model path |
+| `--source-type` | str | ❌ | `safetensors` | Base model format |
+| `--lora-type` | str | ❌ | `safetensors` | LoRA weights format |
+| `--output-format` | str | ❌ | `safetensors` | Output format |
+| `--alpha` | float | ❌ | `1.0` | LoRA merge strength |
+| `--output-dtype` | str | ❌ | `bf16` | Output data type |
+
+### Advanced Usage Examples
+
+**Partial Strength Merging:**
+
+```bash
+python tools/extract/lora_merger.py \
+ --source-model /path/to/base/model \
+ --lora-model /path/to/lora.safetensors \
+ --output /path/to/merged_model.safetensors \
+ --alpha 0.7 \
+ --output-dtype fp32
+```
+
+**Multi-Format Support:**
+
+```bash
+python tools/extract/lora_merger.py \
+ --source-model /path/to/base/model.pt \
+ --source-type pytorch \
+ --lora-model /path/to/lora.safetensors \
+ --lora-type safetensors \
+ --output /path/to/merged_model.safetensors \
+ --output-format safetensors \
+ --alpha 1.0
+```
diff --git a/docs/EN/source/getting_started/benchmark.md b/docs/EN/source/getting_started/benchmark.md
new file mode 100644
index 0000000000000000000000000000000000000000..ecc8dc95e801f4e6a6f77e5888e014c0e0e4b846
--- /dev/null
+++ b/docs/EN/source/getting_started/benchmark.md
@@ -0,0 +1,3 @@
+# Benchmark
+
+For a better display of video playback effects and detailed performance comparisons, you can get better presentation and corresponding documentation content on this [🔗 page](https://github.com/ModelTC/LightX2V/blob/main/docs/EN/source/getting_started/benchmark_source.md).
diff --git a/docs/EN/source/getting_started/benchmark_source.md b/docs/EN/source/getting_started/benchmark_source.md
new file mode 100644
index 0000000000000000000000000000000000000000..35bafdfef46fc56020302b701724199ea5c16117
--- /dev/null
+++ b/docs/EN/source/getting_started/benchmark_source.md
@@ -0,0 +1,149 @@
+# 🚀 Benchmark
+
+> This document showcases the performance test results of LightX2V across different hardware environments, including detailed comparison data for H200 and RTX 4090 platforms.
+
+---
+
+## 🖥️ H200 Environment (~140GB VRAM)
+
+### 📋 Software Environment Configuration
+
+| Component | Version |
+|:----------|:--------|
+| **Python** | 3.11 |
+| **PyTorch** | 2.7.1+cu128 |
+| **SageAttention** | 2.2.0 |
+| **vLLM** | 0.9.2 |
+| **sgl-kernel** | 0.1.8 |
+
+---
+
+### 🎬 480P 5s Video Test
+
+**Test Configuration:**
+- **Model**: [Wan2.1-I2V-14B-480P-Lightx2v](https://huggingface.co/lightx2v/Wan2.1-I2V-14B-480P-Lightx2v)
+- **Parameters**: `infer_steps=40`, `seed=42`, `enable_cfg=True`
+
+#### 📊 Performance Comparison Table
+
+| Configuration | Inference Time(s) | GPU Memory(GB) | Speedup | Video Effect |
+|:-------------|:-----------------:|:--------------:|:-------:|:------------:|
+| **Wan2.1 Official** | 366 | 71 | 1.0x | |
+| **FastVideo** | 292 | 26 | **1.25x** | |
+| **LightX2V_1** | 250 | 53 | **1.46x** | |
+| **LightX2V_2** | 216 | 50 | **1.70x** | |
+| **LightX2V_3** | 191 | 35 | **1.92x** | |
+| **LightX2V_3-Distill** | 14 | 35 | **🏆 20.85x** | |
+| **LightX2V_4** | 107 | 35 | **3.41x** | |
+
+---
+
+### 🎬 720P 5s Video Test
+
+**Test Configuration:**
+- **Model**: [Wan2.1-I2V-14B-720P-Lightx2v](https://huggingface.co/lightx2v/Wan2.1-I2V-14B-720P-Lightx2v)
+- **Parameters**: `infer_steps=40`, `seed=1234`, `enable_cfg=True`
+
+#### 📊 Performance Comparison Table
+
+| Configuration | Inference Time(s) | GPU Memory(GB) | Speedup | Video Effect |
+|:-------------|:-----------------:|:--------------:|:-------:|:------------:|
+| **Wan2.1 Official** | 974 | 81 | 1.0x | |
+| **FastVideo** | 914 | 40 | **1.07x** | |
+| **LightX2V_1** | 807 | 65 | **1.21x** | |
+| **LightX2V_2** | 751 | 57 | **1.30x** | |
+| **LightX2V_3** | 671 | 43 | **1.45x** | |
+| **LightX2V_3-Distill** | 44 | 43 | **🏆 22.14x** | |
+| **LightX2V_4** | 344 | 46 | **2.83x** | |
+
+---
+
+## 🖥️ RTX 4090 Environment (~24GB VRAM)
+
+### 📋 Software Environment Configuration
+
+| Component | Version |
+|:----------|:--------|
+| **Python** | 3.9.16 |
+| **PyTorch** | 2.5.1+cu124 |
+| **SageAttention** | 2.1.0 |
+| **vLLM** | 0.6.6 |
+| **sgl-kernel** | 0.0.5 |
+| **q8-kernels** | 0.0.0 |
+
+---
+
+### 🎬 480P 5s Video Test
+
+**Test Configuration:**
+- **Model**: [Wan2.1-I2V-14B-480P-Lightx2v](https://huggingface.co/lightx2v/Wan2.1-I2V-14B-480P-Lightx2v)
+- **Parameters**: `infer_steps=40`, `seed=42`, `enable_cfg=True`
+
+#### 📊 Performance Comparison Table
+
+| Configuration | Inference Time(s) | GPU Memory(GB) | Speedup | Video Effect |
+|:-------------|:-----------------:|:--------------:|:-------:|:------------:|
+| **Wan2GP(profile=3)** | 779 | 20 | **1.0x** | |
+| **LightX2V_5** | 738 | 16 | **1.05x** | |
+| **LightX2V_5-Distill** | 68 | 16 | **11.45x** | |
+| **LightX2V_6** | 630 | 12 | **1.24x** | |
+| **LightX2V_6-Distill** | 63 | 12 | **🏆 12.36x** |
+
+---
+
+### 🎬 720P 5s Video Test
+
+**Test Configuration:**
+- **Model**: [Wan2.1-I2V-14B-720P-Lightx2v](https://huggingface.co/lightx2v/Wan2.1-I2V-14B-720P-Lightx2v)
+- **Parameters**: `infer_steps=40`, `seed=1234`, `enable_cfg=True`
+
+#### 📊 Performance Comparison Table
+
+| Configuration | Inference Time(s) | GPU Memory(GB) | Speedup | Video Effect |
+|:-------------|:-----------------:|:--------------:|:-------:|:------------:|
+| **Wan2GP(profile=3)** | -- | OOM | -- | |
+| **LightX2V_5** | 2473 | 23 | -- | |
+| **LightX2V_5-Distill** | 183 | 23 | -- | |
+| **LightX2V_6** | 2169 | 18 | -- | |
+| **LightX2V_6-Distill** | 171 | 18 | -- | |
+
+---
+
+## 📖 Configuration Descriptions
+
+### 🖥️ H200 Environment Configuration Descriptions
+
+| Configuration | Technical Features |
+|:--------------|:------------------|
+| **Wan2.1 Official** | Based on [Wan2.1 official repository](https://github.com/Wan-Video/Wan2.1) original implementation |
+| **FastVideo** | Based on [FastVideo official repository](https://github.com/hao-ai-lab/FastVideo), using SageAttention2 backend optimization |
+| **LightX2V_1** | Uses SageAttention2 to replace native attention mechanism, adopts DIT BF16+FP32 (partial sensitive layers) mixed precision computation, improving computational efficiency while maintaining precision |
+| **LightX2V_2** | Unified BF16 precision computation, further reducing memory usage and computational overhead while maintaining generation quality |
+| **LightX2V_3** | Introduces FP8 quantization technology to significantly reduce computational precision requirements, combined with Tiling VAE technology to optimize memory usage |
+| **LightX2V_3-Distill** | Based on LightX2V_3 using 4-step distillation model(`infer_steps=4`, `enable_cfg=False`), further reducing inference steps while maintaining generation quality |
+| **LightX2V_4** | Based on LightX2V_3 with TeaCache(teacache_thresh=0.2) caching reuse technology, achieving acceleration through intelligent redundant computation skipping |
+
+### 🖥️ RTX 4090 Environment Configuration Descriptions
+
+| Configuration | Technical Features |
+|:--------------|:------------------|
+| **Wan2GP(profile=3)** | Implementation based on [Wan2GP repository](https://github.com/deepbeepmeep/Wan2GP), using MMGP optimization technology. Profile=3 configuration is suitable for RTX 3090/4090 environments with at least 32GB RAM and 24GB VRAM, adapting to limited memory resources by sacrificing VRAM. Uses quantized models: [480P model](https://huggingface.co/DeepBeepMeep/Wan2.1/blob/main/wan2.1_image2video_480p_14B_quanto_mbf16_int8.safetensors) and [720P model](https://huggingface.co/DeepBeepMeep/Wan2.1/blob/main/wan2.1_image2video_720p_14B_quanto_mbf16_int8.safetensors) |
+| **LightX2V_5** | Uses SageAttention2 to replace native attention mechanism, adopts DIT FP8+FP32 (partial sensitive layers) mixed precision computation, enables CPU offload technology, executes partial sensitive layers with FP32 precision, asynchronously offloads DIT inference process data to CPU, saves VRAM, with block-level offload granularity |
+| **LightX2V_5-Distill** | Based on LightX2V_5 using 4-step distillation model(`infer_steps=4`, `enable_cfg=False`), further reducing inference steps while maintaining generation quality |
+| **LightX2V_6** | Based on LightX2V_3 with CPU offload technology enabled, executes partial sensitive layers with FP32 precision, asynchronously offloads DIT inference process data to CPU, saves VRAM, with block-level offload granularity |
+| **LightX2V_6-Distill** | Based on LightX2V_6 using 4-step distillation model(`infer_steps=4`, `enable_cfg=False`), further reducing inference steps while maintaining generation quality |
+
+---
+
+## 📁 Configuration Files Reference
+
+Benchmark-related configuration files and execution scripts are available at:
+
+| Type | Link | Description |
+|:-----|:-----|:------------|
+| **Configuration Files** | [configs/bench](https://github.com/ModelTC/LightX2V/tree/main/configs/bench) | Contains JSON files with various optimization configurations |
+| **Execution Scripts** | [scripts/bench](https://github.com/ModelTC/LightX2V/tree/main/scripts/bench) | Contains benchmark execution scripts |
+
+---
+
+> 💡 **Tip**: It is recommended to choose the appropriate optimization solution based on your hardware configuration to achieve the best performance.
diff --git a/docs/EN/source/getting_started/model_structure.md b/docs/EN/source/getting_started/model_structure.md
new file mode 100644
index 0000000000000000000000000000000000000000..6edfc288bfc916392d91ee2205d3b4a3a71736b9
--- /dev/null
+++ b/docs/EN/source/getting_started/model_structure.md
@@ -0,0 +1,573 @@
+# Model Format and Loading Guide
+
+## 📖 Overview
+
+LightX2V is a flexible video generation inference framework that supports multiple model sources and formats, providing users with rich options:
+
+- ✅ **Wan Official Models**: Directly compatible with officially released complete models from Wan2.1 and Wan2.2
+- ✅ **Single-File Models**: Supports single-file format models released by LightX2V (including quantized versions)
+- ✅ **LoRA Models**: Supports loading distilled LoRAs released by LightX2V
+
+This document provides detailed instructions on how to use various model formats, configuration parameters, and best practices.
+
+---
+
+## 🗂️ Format 1: Wan Official Models
+
+### Model Repositories
+- [Wan2.1 Collection](https://huggingface.co/collections/Wan-AI/wan21-68ac4ba85372ae5a8e282a1b)
+- [Wan2.2 Collection](https://huggingface.co/collections/Wan-AI/wan22-68ac4ae80a8b477e79636fc8)
+
+### Model Features
+- **Official Guarantee**: Complete models officially released by Wan-AI with highest quality
+- **Complete Components**: Includes all necessary components (DIT, T5, CLIP, VAE)
+- **Original Precision**: Uses BF16/FP32 precision with no quantization loss
+- **Strong Compatibility**: Fully compatible with Wan official toolchain
+
+### Wan2.1 Official Models
+
+#### Directory Structure
+
+Using [Wan2.1-I2V-14B-720P](https://huggingface.co/Wan-AI/Wan2.1-I2V-14B-720P) as an example:
+
+```
+Wan2.1-I2V-14B-720P/
+├── diffusion_pytorch_model-00001-of-00007.safetensors # DIT model shard 1
+├── diffusion_pytorch_model-00002-of-00007.safetensors # DIT model shard 2
+├── diffusion_pytorch_model-00003-of-00007.safetensors # DIT model shard 3
+├── diffusion_pytorch_model-00004-of-00007.safetensors # DIT model shard 4
+├── diffusion_pytorch_model-00005-of-00007.safetensors # DIT model shard 5
+├── diffusion_pytorch_model-00006-of-00007.safetensors # DIT model shard 6
+├── diffusion_pytorch_model-00007-of-00007.safetensors # DIT model shard 7
+├── diffusion_pytorch_model.safetensors.index.json # Shard index file
+├── models_t5_umt5-xxl-enc-bf16.pth # T5 text encoder
+├── models_clip_open-clip-xlm-roberta-large-vit-huge-14.pth # CLIP encoder
+├── Wan2.1_VAE.pth # VAE encoder/decoder
+├── config.json # Model configuration
+├── xlm-roberta-large/ # CLIP tokenizer
+├── google/ # T5 tokenizer
+├── assets/
+└── examples/
+```
+
+#### Usage
+
+```bash
+# Download model
+huggingface-cli download Wan-AI/Wan2.1-I2V-14B-720P \
+ --local-dir ./models/Wan2.1-I2V-14B-720P
+
+# Configure launch script
+model_path=./models/Wan2.1-I2V-14B-720P
+lightx2v_path=/path/to/LightX2V
+
+# Run inference
+cd LightX2V/scripts
+bash wan/run_wan_i2v.sh
+```
+
+### Wan2.2 Official Models
+
+#### Directory Structure
+
+Using [Wan2.2-I2V-A14B](https://huggingface.co/Wan-AI/Wan2.2-I2V-A14B) as an example:
+
+```
+Wan2.2-I2V-A14B/
+├── high_noise_model/ # High-noise model directory
+│ ├── diffusion_pytorch_model-00001-of-00009.safetensors
+│ ├── diffusion_pytorch_model-00002-of-00009.safetensors
+│ ├── ...
+│ ├── diffusion_pytorch_model-00009-of-00009.safetensors
+│ └── diffusion_pytorch_model.safetensors.index.json
+├── low_noise_model/ # Low-noise model directory
+│ ├── diffusion_pytorch_model-00001-of-00009.safetensors
+│ ├── diffusion_pytorch_model-00002-of-00009.safetensors
+│ ├── ...
+│ ├── diffusion_pytorch_model-00009-of-00009.safetensors
+│ └── diffusion_pytorch_model.safetensors.index.json
+├── models_t5_umt5-xxl-enc-bf16.pth # T5 text encoder
+├── Wan2.1_VAE.pth # VAE encoder/decoder
+├── configuration.json # Model configuration
+├── google/ # T5 tokenizer
+├── assets/ # Example assets (optional)
+└── examples/ # Example files (optional)
+```
+
+#### Usage
+
+```bash
+# Download model
+huggingface-cli download Wan-AI/Wan2.2-I2V-A14B \
+ --local-dir ./models/Wan2.2-I2V-A14B
+
+# Configure launch script
+model_path=./models/Wan2.2-I2V-A14B
+lightx2v_path=/path/to/LightX2V
+
+# Run inference
+cd LightX2V/scripts
+bash wan22/run_wan22_moe_i2v.sh
+```
+
+### Available Model List
+
+#### Wan2.1 Official Model List
+
+| Model Name | Download Link |
+|---------|----------|
+| Wan2.1-I2V-14B-720P | [Link](https://huggingface.co/Wan-AI/Wan2.1-I2V-14B-720P) |
+| Wan2.1-I2V-14B-480P | [Link](https://huggingface.co/Wan-AI/Wan2.1-I2V-14B-480P) |
+| Wan2.1-T2V-14B | [Link](https://huggingface.co/Wan-AI/Wan2.1-T2V-14B) |
+| Wan2.1-T2V-1.3B | [Link](https://huggingface.co/Wan-AI/Wan2.1-T2V-1.3B) |
+| Wan2.1-FLF2V-14B-720P | [Link](https://huggingface.co/Wan-AI/Wan2.1-FLF2V-14B-720P) |
+| Wan2.1-VACE-14B | [Link](https://huggingface.co/Wan-AI/Wan2.1-VACE-14B) |
+| Wan2.1-VACE-1.3B | [Link](https://huggingface.co/Wan-AI/Wan2.1-VACE-1.3B) |
+
+#### Wan2.2 Official Model List
+
+| Model Name | Download Link |
+|---------|----------|
+| Wan2.2-I2V-A14B | [Link](https://huggingface.co/Wan-AI/Wan2.2-I2V-A14B) |
+| Wan2.2-T2V-A14B | [Link](https://huggingface.co/Wan-AI/Wan2.2-T2V-A14B) |
+| Wan2.2-TI2V-5B | [Link](https://huggingface.co/Wan-AI/Wan2.2-TI2V-5B) |
+| Wan2.2-Animate-14B | [Link](https://huggingface.co/Wan-AI/Wan2.2-Animate-14B) |
+
+### Usage Tips
+
+> 💡 **Quantized Model Usage**: To use quantized models, refer to the [Model Conversion Script](https://github.com/ModelTC/LightX2V/blob/main/tools/convert/readme_zh.md) for conversion, or directly use pre-converted quantized models in Format 2 below
+>
+> 💡 **Memory Optimization**: For devices with RTX 4090 24GB or smaller memory, it's recommended to combine quantization techniques with CPU offload features:
+> - Quantization Configuration: Refer to [Quantization Documentation](../method_tutorials/quantization.md)
+> - CPU Offload: Refer to [Parameter Offload Documentation](../method_tutorials/offload.md)
+> - Wan2.1 Configuration: Refer to [offload config files](https://github.com/ModelTC/LightX2V/tree/main/configs/offload)
+> - Wan2.2 Configuration: Refer to [wan22 config files](https://github.com/ModelTC/LightX2V/tree/main/configs/wan22) with `4090` suffix
+
+---
+
+## 🗂️ Format 2: LightX2V Single-File Models (Recommended)
+
+### Model Repositories
+- [Wan2.1-LightX2V](https://huggingface.co/lightx2v/Wan2.1-Distill-Models)
+- [Wan2.2-LightX2V](https://huggingface.co/lightx2v/Wan2.2-Distill-Models)
+
+### Model Features
+- **Single-File Management**: Single safetensors file, easy to manage and deploy
+- **Multi-Precision Support**: Provides original precision, FP8, INT8, and other precision versions
+- **Distillation Acceleration**: Supports 4-step fast inference
+- **Tool Compatibility**: Compatible with ComfyUI and other tools
+
+**Examples**:
+- `wan2.1_i2v_720p_lightx2v_4step.safetensors` - 720P I2V original precision
+- `wan2.1_i2v_720p_scaled_fp8_e4m3_lightx2v_4step.safetensors` - 720P I2V FP8 quantization
+- `wan2.1_i2v_480p_int8_lightx2v_4step.safetensors` - 480P I2V INT8 quantization
+- ...
+
+### Wan2.1 Single-File Models
+
+#### Scenario A: Download Single Model File
+
+**Step 1: Select and Download Model**
+
+```bash
+# Create model directory
+mkdir -p ./models/wan2.1_i2v_720p
+
+# Download 720P I2V FP8 quantized model
+huggingface-cli download lightx2v/Wan2.1-Distill-Models \
+ --local-dir ./models/wan2.1_i2v_720p \
+ --include "wan2.1_i2v_720p_lightx2v_4step.safetensors"
+```
+
+**Step 2: Manually Organize Other Components**
+
+Directory structure as follows:
+```
+wan2.1_i2v_720p/
+├── wan2.1_i2v_720p_lightx2v_4step.safetensors # Original precision
+└── t5/clip/vae/config.json/xlm-roberta-large/google and other components # Need manual organization
+```
+
+**Step 3: Configure Launch Script**
+
+```bash
+# Set in launch script (point to directory containing model file)
+model_path=./models/wan2.1_i2v_720p
+lightx2v_path=/path/to/LightX2V
+
+# Run script
+cd LightX2V/scripts
+bash wan/run_wan_i2v_distill_4step_cfg.sh
+```
+
+> 💡 **Tip**: When there's only one model file in the directory, LightX2V will automatically load it.
+
+#### Scenario B: Download Multiple Model Files
+
+When you download multiple models with different precisions to the same directory, you need to explicitly specify which model to use in the configuration file.
+
+**Step 1: Download Multiple Models**
+
+```bash
+# Create model directory
+mkdir -p ./models/wan2.1_i2v_720p_multi
+
+# Download original precision model
+huggingface-cli download lightx2v/Wan2.1-Distill-Models \
+ --local-dir ./models/wan2.1_i2v_720p_multi \
+ --include "wan2.1_i2v_720p_lightx2v_4step.safetensors"
+
+# Download FP8 quantized model
+huggingface-cli download lightx2v/Wan2.1-Distill-Models \
+ --local-dir ./models/wan2.1_i2v_720p_multi \
+ --include "wan2.1_i2v_720p_scaled_fp8_e4m3_lightx2v_4step.safetensors"
+
+# Download INT8 quantized model
+huggingface-cli download lightx2v/Wan2.1-Distill-Models \
+ --local-dir ./models/wan2.1_i2v_720p_multi \
+ --include "wan2.1_i2v_720p_int8_lightx2v_4step.safetensors"
+```
+
+**Step 2: Manually Organize Other Components**
+
+Directory structure as follows:
+
+```
+wan2.1_i2v_720p_multi/
+├── wan2.1_i2v_720p_lightx2v_4step.safetensors # Original precision
+├── wan2.1_i2v_720p_scaled_fp8_e4m3_lightx2v_4step.safetensors # FP8 quantization
+└── wan2.1_i2v_720p_int8_lightx2v_4step.safetensors # INT8 quantization
+└── t5/clip/vae/config.json/xlm-roberta-large/google and other components # Need manual organization
+```
+
+**Step 3: Specify Model in Configuration File**
+
+Edit configuration file (e.g., `configs/distill/wan_i2v_distill_4step_cfg.json`):
+
+```json
+{
+ // Use original precision model
+ "dit_original_ckpt": "./models/wan2.1_i2v_720p_multi/wan2.1_i2v_720p_lightx2v_4step.safetensors",
+
+ // Or use FP8 quantized model
+ // "dit_quantized_ckpt": "./models/wan2.1_i2v_720p_multi/wan2.1_i2v_720p_scaled_fp8_e4m3_lightx2v_4step.safetensors",
+ // "dit_quantized": true,
+ // "dit_quant_scheme": "fp8-vllm",
+
+ // Or use INT8 quantized model
+ // "dit_quantized_ckpt": "./models/wan2.1_i2v_720p_multi/wan2.1_i2v_720p_int8_lightx2v_4step.safetensors",
+ // "dit_quantized": true,
+ // "dit_quant_scheme": "int8-vllm",
+
+ // Other configurations...
+}
+```
+### Usage Tips
+
+> 💡 **Configuration Parameter Description**:
+> - **dit_original_ckpt**: Used to specify the path to original precision models (BF16/FP32/FP16)
+> - **dit_quantized_ckpt**: Used to specify the path to quantized models (FP8/INT8), must be used with `dit_quantized` and `dit_quant_scheme` parameters
+
+**Step 4: Start Inference**
+
+```bash
+cd LightX2V/scripts
+bash wan/run_wan_i2v_distill_4step_cfg.sh
+```
+
+> 💡 **Tip**: Other components (T5, CLIP, VAE, tokenizer, etc.) need to be manually organized into the model directory
+
+### Wan2.2 Single-File Models
+
+#### Directory Structure Requirements
+
+When using Wan2.2 single-file models, you need to manually create a specific directory structure:
+
+```
+wan2.2_models/
+├── high_noise_model/ # High-noise model directory (required)
+│ └── wan2.2_i2v_A14b_high_noise_lightx2v_4step.safetensors
+├── low_noise_model/ # Low-noise model directory (required)
+│ └── wan2.2_i2v_A14b_low_noise_lightx2v_4step.safetensors
+└── t5/clip/vae/config.json/... # Other components (manually organized)
+```
+
+#### Scenario A: Only One Model File Per Directory
+
+```bash
+# Create required subdirectories
+mkdir -p ./models/wan2.2_models/high_noise_model
+mkdir -p ./models/wan2.2_models/low_noise_model
+
+# Download high-noise model to corresponding directory
+huggingface-cli download lightx2v/Wan2.2-Distill-Models \
+ --local-dir ./models/wan2.2_models/high_noise_model \
+ --include "wan2.2_i2v_A14b_high_noise_scaled_fp8_e4m3_lightx2v_4step.safetensors"
+
+# Download low-noise model to corresponding directory
+huggingface-cli download lightx2v/Wan2.2-Distill-Models \
+ --local-dir ./models/wan2.2_models/low_noise_model \
+ --include "wan2.2_i2v_A14b_low_noise_scaled_fp8_e4m3_lightx2v_4step.safetensors"
+
+# Configure launch script (point to parent directory)
+model_path=./models/wan2.2_models
+lightx2v_path=/path/to/LightX2V
+
+# Run script
+cd LightX2V/scripts
+bash wan22/run_wan22_moe_i2v_distill.sh
+```
+
+> 💡 **Tip**: When there's only one model file in each subdirectory, LightX2V will automatically load it.
+
+#### Scenario B: Multiple Model Files Per Directory
+
+When you place multiple models with different precisions in both `high_noise_model/` and `low_noise_model/` directories, you need to explicitly specify them in the configuration file.
+
+```bash
+# Create directories
+mkdir -p ./models/wan2.2_models_multi/high_noise_model
+mkdir -p ./models/wan2.2_models_multi/low_noise_model
+
+# Download multiple versions of high-noise model
+huggingface-cli download lightx2v/Wan2.2-Distill-Models \
+ --local-dir ./models/wan2.2_models_multi/high_noise_model \
+ --include "wan2.2_i2v_A14b_high_noise_*.safetensors"
+
+# Download multiple versions of low-noise model
+huggingface-cli download lightx2v/Wan2.2-Distill-Models \
+ --local-dir ./models/wan2.2_models_multi/low_noise_model \
+ --include "wan2.2_i2v_A14b_low_noise_*.safetensors"
+```
+
+**Directory Structure**:
+
+```
+wan2.2_models_multi/
+├── high_noise_model/
+│ ├── wan2.2_i2v_A14b_high_noise_lightx2v_4step.safetensors # Original precision
+│ ├── wan2.2_i2v_A14b_high_noise_fp8_e4m3_lightx2v_4step.safetensors # FP8 quantization
+│ └── wan2.2_i2v_A14b_high_noise_int8_lightx2v_4step.safetensors # INT8 quantization
+└── low_noise_model/
+│ ├── wan2.2_i2v_A14b_low_noise_lightx2v_4step.safetensors # Original precision
+│ ├── wan2.2_i2v_A14b_low_noise_fp8_e4m3_lightx2v_4step.safetensors # FP8 quantization
+│ └── wan2.2_i2v_A14b_low_noise_int8_lightx2v_4step.safetensors # INT8 quantization
+└── t5/vae/config.json/xlm-roberta-large/google and other components # Need manual organization
+```
+
+**Configuration File Settings**:
+
+```json
+{
+ // Use original precision model
+ "high_noise_original_ckpt": "./models/wan2.2_models_multi/high_noise_model/wan2.2_i2v_A14b_high_noise_lightx2v_4step.safetensors",
+ "low_noise_original_ckpt": "./models/wan2.2_models_multi/low_noise_model/wan2.2_i2v_A14b_low_noise_lightx2v_4step.safetensors",
+
+ // Or use FP8 quantized model
+ // "high_noise_quantized_ckpt": "./models/wan2.2_models_multi/high_noise_model/wan2.2_i2v_A14b_high_noise_fp8_e4m3_lightx2v_4step.safetensors",
+ // "low_noise_quantized_ckpt": "./models/wan2.2_models_multi/low_noise_model/wan2.2_i2v_A14b_low_noise_fp8_e4m3_lightx2v_4step.safetensors",
+ // "dit_quantized": true,
+ // "dit_quant_scheme": "fp8-vllm"
+
+ // Or use INT8 quantized model
+ // "high_noise_quantized_ckpt": "./models/wan2.2_models_multi/high_noise_model/wan2.2_i2v_A14b_high_noise_int8_lightx2v_4step.safetensors",
+ // "low_noise_quantized_ckpt": "./models/wan2.2_models_multi/low_noise_model/wan2.2_i2v_A14b_low_noise_int8_lightx2v_4step.safetensors",
+ // "dit_quantized": true,
+ // "dit_quant_scheme": "int8-vllm"
+}
+```
+
+### Usage Tips
+
+> 💡 **Configuration Parameter Description**:
+> - **high_noise_original_ckpt** / **low_noise_original_ckpt**: Used to specify the path to original precision models (BF16/FP32/FP16)
+> - **high_noise_quantized_ckpt** / **low_noise_quantized_ckpt**: Used to specify the path to quantized models (FP8/INT8), must be used with `dit_quantized` and `dit_quant_scheme` parameters
+
+
+### Available Model List
+
+#### Wan2.1 Single-File Model List
+
+**Image-to-Video Models (I2V)**
+
+| Filename | Precision | Description |
+|--------|------|------|
+| `wan2.1_i2v_480p_lightx2v_4step.safetensors` | BF16 | 4-step model original precision |
+| `wan2.1_i2v_480p_scaled_fp8_e4m3_lightx2v_4step.safetensors` | FP8 | 4-step model FP8 quantization |
+| `wan2.1_i2v_480p_int8_lightx2v_4step.safetensors` | INT8 | 4-step model INT8 quantization |
+| `wan2.1_i2v_480p_scaled_fp8_e4m3_lightx2v_4step_comfyui.safetensors` | FP8 | 4-step model ComfyUI format |
+| `wan2.1_i2v_720p_lightx2v_4step.safetensors` | BF16 | 4-step model original precision |
+| `wan2.1_i2v_720p_scaled_fp8_e4m3_lightx2v_4step.safetensors` | FP8 | 4-step model FP8 quantization |
+| `wan2.1_i2v_720p_int8_lightx2v_4step.safetensors` | INT8 | 4-step model INT8 quantization |
+| `wan2.1_i2v_720p_scaled_fp8_e4m3_lightx2v_4step_comfyui.safetensors` | FP8 | 4-step model ComfyUI format |
+
+**Text-to-Video Models (T2V)**
+
+| Filename | Precision | Description |
+|--------|------|------|
+| `wan2.1_t2v_14b_lightx2v_4step.safetensors` | BF16 | 4-step model original precision |
+| `wan2.1_t2v_14b_scaled_fp8_e4m3_lightx2v_4step.safetensors` | FP8 | 4-step model FP8 quantization |
+| `wan2.1_t2v_14b_int8_lightx2v_4step.safetensors` | INT8 | 4-step model INT8 quantization |
+| `wan2.1_t2v_14b_scaled_fp8_e4m3_lightx2v_4step_comfyui.safetensors` | FP8 | 4-step model ComfyUI format |
+
+#### Wan2.2 Single-File Model List
+
+**Image-to-Video Models (I2V) - A14B Series**
+
+| Filename | Precision | Description |
+|--------|------|------|
+| `wan2.2_i2v_A14b_high_noise_lightx2v_4step.safetensors` | BF16 | High-noise model - 4-step original precision |
+| `wan2.2_i2v_A14b_high_noise_scaled_fp8_e4m3_lightx2v_4step.safetensors` | FP8 | High-noise model - 4-step FP8 quantization |
+| `wan2.2_i2v_A14b_high_noise_int8_lightx2v_4step.safetensors` | INT8 | High-noise model - 4-step INT8 quantization |
+| `wan2.2_i2v_A14b_low_noise_lightx2v_4step.safetensors` | BF16 | Low-noise model - 4-step original precision |
+| `wan2.2_i2v_A14b_low_noise_scaled_fp8_e4m3_lightx2v_4step.safetensors` | FP8 | Low-noise model - 4-step FP8 quantization |
+| `wan2.2_i2v_A14b_low_noise_int8_lightx2v_4step.safetensors` | INT8 | Low-noise model - 4-step INT8 quantization |
+
+> 💡 **Usage Tips**:
+> - Wan2.2 models use a dual-noise architecture, requiring both high-noise and low-noise models to be downloaded
+> - Refer to the "Wan2.2 Single-File Models" section above for detailed directory organization
+
+---
+
+## 🗂️ Format 3: LightX2V LoRA Models
+
+LoRA (Low-Rank Adaptation) models provide a lightweight model fine-tuning solution that enables customization for specific effects without modifying the base model.
+
+### Model Repositories
+
+- **Wan2.1 LoRA Models**: [lightx2v/Wan2.1-Distill-Loras](https://huggingface.co/lightx2v/Wan2.1-Distill-Loras)
+- **Wan2.2 LoRA Models**: [lightx2v/Wan2.2-Distill-Loras](https://huggingface.co/lightx2v/Wan2.2-Distill-Loras)
+
+### Usage Methods
+
+#### Method 1: Offline Merging
+
+Merge LoRA weights offline into the base model to generate a new complete model file.
+
+**Steps**:
+
+Refer to the [Model Conversion Documentation](https://github.com/ModelTC/lightx2v/tree/main/tools/convert/readme_zh.md) for offline merging.
+
+**Advantages**:
+- ✅ No need to load LoRA during inference
+- ✅ Better performance
+
+**Disadvantages**:
+- ❌ Requires additional storage space
+- ❌ Switching different LoRAs requires re-merging
+
+#### Method 2: Online Loading
+
+Dynamically load LoRA weights during inference without modifying the base model.
+
+**LoRA Application Principle**:
+
+```python
+# LoRA weight application formula
+# lora_scale = (alpha / rank)
+# W' = W + lora_scale * B @ A
+# Where: B = up_proj (out_features, rank)
+# A = down_proj (rank, in_features)
+
+if weights_dict["alpha"] is not None:
+ lora_scale = weights_dict["alpha"] / lora_down.shape[0]
+elif alpha is not None:
+ lora_scale = alpha / lora_down.shape[0]
+else:
+ lora_scale = 1.0
+```
+
+**Configuration Method**:
+
+**Wan2.1 LoRA Configuration**:
+
+```json
+{
+ "lora_configs": [
+ {
+ "path": "wan2.1_i2v_lora_rank64_lightx2v_4step.safetensors",
+ "strength": 1.0,
+ "alpha": null
+ }
+ ]
+}
+```
+
+**Wan2.2 LoRA Configuration**:
+
+Since Wan2.2 uses a dual-model architecture (high-noise/low-noise), LoRA needs to be configured separately for both models:
+
+```json
+{
+ "lora_configs": [
+ {
+ "name": "low_noise_model",
+ "path": "wan2.2_i2v_A14b_low_noise_lora_rank64_lightx2v_4step.safetensors",
+ "strength": 1.0,
+ "alpha": null
+ },
+ {
+ "name": "high_noise_model",
+ "path": "wan2.2_i2v_A14b_high_noise_lora_rank64_lightx2v_4step.safetensors",
+ "strength": 1.0,
+ "alpha": null
+ }
+ ]
+}
+```
+
+**Parameter Description**:
+
+| Parameter | Description | Default |
+|------|------|--------|
+| `path` | LoRA model file path | Required |
+| `strength` | LoRA strength coefficient, range [0.0, 1.0] | 1.0 |
+| `alpha` | LoRA scaling factor, uses model's built-in value when `null` | null |
+| `name` | (Wan2.2 only) Specifies which model to apply to | Required |
+
+**Advantages**:
+- ✅ Flexible switching between different LoRAs
+- ✅ Saves storage space
+- ✅ Can dynamically adjust LoRA strength
+
+**Disadvantages**:
+- ❌ Additional loading time during inference
+- ❌ Slightly increases memory usage
+
+---
+
+## 📚 Related Resources
+
+### Official Repositories
+- [LightX2V GitHub](https://github.com/ModelTC/LightX2V)
+- [LightX2V Single-File Model Repository](https://huggingface.co/lightx2v/Wan2.1-Distill-Models)
+- [Wan-AI Official Model Repository](https://huggingface.co/Wan-AI)
+
+### Model Download Links
+
+**Wan2.1 Series**
+- [Wan2.1 Collection](https://huggingface.co/collections/Wan-AI/wan21-68ac4ba85372ae5a8e282a1b)
+
+**Wan2.2 Series**
+- [Wan2.2 Collection](https://huggingface.co/collections/Wan-AI/wan22-68ac4ae80a8b477e79636fc8)
+
+**LightX2V Single-File Models**
+- [Wan2.1-Distill-Models](https://huggingface.co/lightx2v/Wan2.1-Distill-Models)
+- [Wan2.2-Distill-Models](https://huggingface.co/lightx2v/Wan2.2-Distill-Models)
+
+### Documentation Links
+- [Quantization Documentation](../method_tutorials/quantization.md)
+- [Parameter Offload Documentation](../method_tutorials/offload.md)
+- [Configuration File Examples](https://github.com/ModelTC/LightX2V/tree/main/configs)
+
+---
+
+Through this document, you should be able to:
+
+✅ Understand all model formats supported by LightX2V
+✅ Select appropriate models and precisions based on your needs
+✅ Correctly download and organize model files
+✅ Configure launch parameters and successfully run inference
+✅ Resolve common model loading issues
+
+If you have other questions, feel free to ask in [GitHub Issues](https://github.com/ModelTC/LightX2V/issues).
diff --git a/docs/EN/source/getting_started/quickstart.md b/docs/EN/source/getting_started/quickstart.md
new file mode 100644
index 0000000000000000000000000000000000000000..799959e4ae2cd6dcbf0f8ad262c276a87370806b
--- /dev/null
+++ b/docs/EN/source/getting_started/quickstart.md
@@ -0,0 +1,349 @@
+# LightX2V Quick Start Guide
+
+Welcome to LightX2V! This guide will help you quickly set up the environment and start using LightX2V for video generation.
+
+## 📋 Table of Contents
+
+- [System Requirements](#system-requirements)
+- [Linux Environment Setup](#linux-environment-setup)
+ - [Docker Environment (Recommended)](#docker-environment-recommended)
+ - [Conda Environment Setup](#conda-environment-setup)
+- [Windows Environment Setup](#windows-environment-setup)
+- [Inference Usage](#inference-usage)
+
+## 🚀 System Requirements
+
+- **Operating System**: Linux (Ubuntu 18.04+) or Windows 10/11
+- **Python**: 3.10 or higher
+- **GPU**: NVIDIA GPU with CUDA support, at least 8GB VRAM
+- **Memory**: 16GB or more recommended
+- **Storage**: At least 50GB available space
+
+## 🐧 Linux Environment Setup
+
+### 🐳 Docker Environment (Recommended)
+
+We strongly recommend using the Docker environment, which is the simplest and fastest installation method.
+
+#### 1. Pull Image
+
+Visit LightX2V's [Docker Hub](https://hub.docker.com/r/lightx2v/lightx2v/tags), select a tag with the latest date, such as `25111101-cu128`:
+
+```bash
+docker pull lightx2v/lightx2v:25111101-cu128
+```
+
+We recommend using the `cuda128` environment for faster inference speed. If you need to use the `cuda124` environment, you can use image versions with the `-cu124` suffix:
+
+```bash
+docker pull lightx2v/lightx2v:25101501-cu124
+```
+
+#### 2. Run Container
+
+```bash
+docker run --gpus all -itd --ipc=host --name [container_name] -v [mount_settings] --entrypoint /bin/bash [image_id]
+```
+
+#### 3. China Mirror Source (Optional)
+
+For mainland China, if the network is unstable when pulling images, you can pull from Alibaba Cloud:
+
+```bash
+# cuda128
+docker pull registry.cn-hangzhou.aliyuncs.com/yongyang/lightx2v:25111101-cu128
+
+# cuda124
+docker pull registry.cn-hangzhou.aliyuncs.com/yongyang/lightx2v:25101501-cu124
+```
+
+### 🐍 Conda Environment Setup
+
+If you prefer to set up the environment yourself using Conda, please follow these steps:
+
+#### Step 1: Clone Repository
+
+```bash
+# Download project code
+git clone https://github.com/ModelTC/LightX2V.git
+cd LightX2V
+```
+
+#### Step 2: Create Conda Virtual Environment
+
+```bash
+# Create and activate conda environment
+conda create -n lightx2v python=3.11 -y
+conda activate lightx2v
+```
+
+#### Step 3: Install Dependencies
+
+```bash
+pip install -v -e .
+```
+
+#### Step 4: Install Attention Operators
+
+**Option A: Flash Attention 2**
+```bash
+git clone https://github.com/Dao-AILab/flash-attention.git --recursive
+cd flash-attention && python setup.py install
+```
+
+**Option B: Flash Attention 3 (for Hopper architecture GPUs)**
+```bash
+cd flash-attention/hopper && python setup.py install
+```
+
+**Option C: SageAttention 2 (Recommended)**
+```bash
+git clone https://github.com/thu-ml/SageAttention.git
+cd SageAttention && CUDA_ARCHITECTURES="8.0,8.6,8.9,9.0,12.0" EXT_PARALLEL=4 NVCC_APPEND_FLAGS="--threads 8" MAX_JOBS=32 pip install -v -e .
+```
+
+#### Step 4: Install Quantization Operators (Optional)
+
+Quantization operators are used to support model quantization, which can significantly reduce memory usage and accelerate inference. Choose the appropriate quantization operator based on your needs:
+
+**Option A: VLLM Kernels (Recommended)**
+Suitable for various quantization schemes, supports FP8 and other quantization formats.
+
+```bash
+pip install vllm
+```
+
+Or install from source for the latest features:
+
+```bash
+git clone https://github.com/vllm-project/vllm.git
+cd vllm
+uv pip install -e .
+```
+
+**Option B: SGL Kernels**
+Suitable for SGL quantization scheme, requires torch == 2.8.0.
+
+```bash
+pip install sgl-kernel --upgrade
+```
+
+**Option C: Q8 Kernels**
+Suitable for Ada architecture GPUs (such as RTX 4090, L40S, etc.).
+
+```bash
+git clone https://github.com/KONAKONA666/q8_kernels.git
+cd q8_kernels && git submodule init && git submodule update
+python setup.py install
+```
+
+> 💡 **Note**:
+> - You can skip this step if you don't need quantization functionality
+> - Quantized models can be downloaded from [LightX2V HuggingFace](https://huggingface.co/lightx2v)
+> - For more quantization information, please refer to the [Quantization Documentation](method_tutorials/quantization.html)
+
+#### Step 5: Verify Installation
+
+```python
+import lightx2v
+print(f"LightX2V Version: {lightx2v.__version__}")
+```
+
+## 🪟 Windows Environment Setup
+
+Windows systems only support Conda environment setup. Please follow these steps:
+
+### 🐍 Conda Environment Setup
+
+#### Step 1: Check CUDA Version
+
+First, confirm your GPU driver and CUDA version:
+
+```cmd
+nvidia-smi
+```
+
+Record the **CUDA Version** information in the output, which needs to be consistent in subsequent installations.
+
+#### Step 2: Create Python Environment
+
+```cmd
+# Create new environment (Python 3.12 recommended)
+conda create -n lightx2v python=3.12 -y
+
+# Activate environment
+conda activate lightx2v
+```
+
+> 💡 **Note**: Python 3.10 or higher is recommended for best compatibility.
+
+#### Step 3: Install PyTorch Framework
+
+**Method 1: Download Official Wheel Package (Recommended)**
+
+1. Visit the [PyTorch Official Download Page](https://download.pytorch.org/whl/torch/)
+2. Select the corresponding version wheel package, paying attention to matching:
+ - **Python Version**: Consistent with your environment
+ - **CUDA Version**: Matches your GPU driver
+ - **Platform**: Select Windows version
+
+**Example (Python 3.12 + PyTorch 2.6 + CUDA 12.4):**
+
+```cmd
+# Download and install PyTorch
+pip install torch-2.6.0+cu124-cp312-cp312-win_amd64.whl
+
+# Install supporting packages
+pip install torchvision==0.21.0 torchaudio==2.6.0
+```
+
+**Method 2: Direct Installation via pip**
+
+```cmd
+# CUDA 12.4 version example
+pip install torch==2.6.0+cu124 torchvision==0.21.0+cu124 torchaudio==2.6.0+cu124 --index-url https://download.pytorch.org/whl/cu124
+```
+
+#### Step 4: Install Windows Version vLLM
+
+Download the corresponding wheel package from [vllm-windows releases](https://github.com/SystemPanic/vllm-windows/releases).
+
+**Version Matching Requirements:**
+- Python version matching
+- PyTorch version matching
+- CUDA version matching
+
+```cmd
+# Install vLLM (please adjust according to actual filename)
+pip install vllm-0.9.1+cu124-cp312-cp312-win_amd64.whl
+```
+
+#### Step 5: Install Attention Mechanism Operators
+
+**Option A: Flash Attention 2**
+
+```cmd
+pip install flash-attn==2.7.2.post1
+```
+
+**Option B: SageAttention 2 (Strongly Recommended)**
+
+**Download Sources:**
+- [Windows Special Version 1](https://github.com/woct0rdho/SageAttention/releases)
+- [Windows Special Version 2](https://github.com/sdbds/SageAttention-for-windows/releases)
+
+```cmd
+# Install SageAttention (please adjust according to actual filename)
+pip install sageattention-2.1.1+cu126torch2.6.0-cp312-cp312-win_amd64.whl
+```
+
+> ⚠️ **Note**: SageAttention's CUDA version doesn't need to be strictly aligned, but Python and PyTorch versions must match.
+
+#### Step 6: Clone Repository
+
+```cmd
+# Clone project code
+git clone https://github.com/ModelTC/LightX2V.git
+cd LightX2V
+
+# Install Windows-specific dependencies
+pip install -r requirements_win.txt
+pip install -v -e .
+```
+
+#### Step 7: Install Quantization Operators (Optional)
+
+Quantization operators are used to support model quantization, which can significantly reduce memory usage and accelerate inference.
+
+**Install VLLM (Recommended):**
+
+Download the corresponding wheel package from [vllm-windows releases](https://github.com/SystemPanic/vllm-windows/releases) and install it.
+
+```cmd
+# Install vLLM (please adjust according to actual filename)
+pip install vllm-0.9.1+cu124-cp312-cp312-win_amd64.whl
+```
+
+> 💡 **Note**:
+> - You can skip this step if you don't need quantization functionality
+> - Quantized models can be downloaded from [LightX2V HuggingFace](https://huggingface.co/lightx2v)
+> - For more quantization information, please refer to the [Quantization Documentation](method_tutorials/quantization.html)
+
+## 🎯 Inference Usage
+
+### 📥 Model Preparation
+
+Before starting inference, you need to download the model files in advance. We recommend:
+
+- **Download Source**: Download models from [LightX2V Official Hugging Face](https://huggingface.co/lightx2v/) or other open-source model repositories
+- **Storage Location**: It's recommended to store models on SSD disks for better read performance
+- **Available Models**: Including Wan2.1-I2V, Wan2.1-T2V, and other models supporting different resolutions and functionalities
+
+### 📁 Configuration Files and Scripts
+
+The configuration files used for inference are available [here](https://github.com/ModelTC/LightX2V/tree/main/configs), and scripts are available [here](https://github.com/ModelTC/LightX2V/tree/main/scripts).
+
+You need to configure the downloaded model path in the run script. In addition to the input arguments in the script, there are also some necessary parameters in the configuration file specified by `--config_json`. You can modify them as needed.
+
+### 🚀 Start Inference
+
+#### Linux Environment
+
+```bash
+# Run after modifying the path in the script
+bash scripts/wan/run_wan_t2v.sh
+```
+
+#### Windows Environment
+
+```cmd
+# Use Windows batch script
+scripts\win\run_wan_t2v.bat
+```
+
+#### Python Script Launch
+
+```python
+from lightx2v import LightX2VPipeline
+
+pipe = LightX2VPipeline(
+ model_path="/path/to/Wan2.1-T2V-14B",
+ model_cls="wan2.1",
+ task="t2v",
+)
+
+pipe.create_generator(
+ attn_mode="sage_attn2",
+ infer_steps=50,
+ height=480, # 720
+ width=832, # 1280
+ num_frames=81,
+ guidance_scale=5.0,
+ sample_shift=5.0,
+)
+
+seed = 42
+prompt = "Two anthropomorphic cats in comfy boxing gear and bright gloves fight intensely on a spotlighted stage."
+negative_prompt = "镜头晃动,色调艳丽,过曝,静态,细节模糊不清,字幕,风格,作品,画作,画面,静止,整体发灰,最差质量,低质量,JPEG压缩残留,丑陋的,残缺的,多余的手指,画得不好的手部,画得不好的脸部,畸形的,毁容的,形态畸形的肢体,手指融合,静止不动的画面,杂乱的背景,三条腿,背景人很多,倒着走"
+save_result_path="/path/to/save_results/output.mp4"
+
+pipe.generate(
+ seed=seed,
+ prompt=prompt,
+ negative_prompt=negative_prompt,
+ save_result_path=save_result_path,
+)
+```
+
+> 💡 **More Examples**: For more usage examples including quantization, offloading, caching, and other advanced configurations, please refer to the [examples directory](https://github.com/ModelTC/LightX2V/tree/main/examples).
+
+## 📞 Get Help
+
+If you encounter problems during installation or usage, please:
+
+1. Search for related issues in [GitHub Issues](https://github.com/ModelTC/LightX2V/issues)
+2. Submit a new Issue describing your problem
+
+---
+
+🎉 **Congratulations!** You have successfully set up the LightX2V environment and can now start enjoying video generation!
diff --git a/docs/EN/source/index.rst b/docs/EN/source/index.rst
new file mode 100644
index 0000000000000000000000000000000000000000..3e244e62ab26025fc1d5ae328eaf29205a5cf254
--- /dev/null
+++ b/docs/EN/source/index.rst
@@ -0,0 +1,67 @@
+Welcome to Lightx2v!
+==================
+
+.. figure:: ../../../assets/img_lightx2v.png
+ :width: 80%
+ :align: center
+ :alt: Lightx2v
+ :class: no-scaled-link
+
+.. raw:: html
+
+
+
+
+ LightX2V: Light Video Generation Inference Framework
+
+
+LightX2V is a lightweight video generation inference framework designed to provide an inference tool that leverages multiple advanced video generation inference techniques. As a unified inference platform, this framework supports various generation tasks such as text-to-video (T2V) and image-to-video (I2V) across different models. X2V means transforming different input modalities (such as text or images) to video output.
+
+GitHub: https://github.com/ModelTC/lightx2v
+
+HuggingFace: https://huggingface.co/lightx2v
+
+Documentation
+-------------
+
+.. toctree::
+ :maxdepth: 1
+ :caption: Quick Start
+
+ Quick Start
+ Model Structure
+ Benchmark
+
+.. toctree::
+ :maxdepth: 1
+ :caption: Method Tutorials
+
+ Model Quantization
+ Feature Caching
+ Attention Module
+ Offload
+ Parallel Inference
+ Changing Resolution Inference
+ Step Distill
+ Autoregressive Distill
+ Video Frame Interpolation
+
+.. toctree::
+ :maxdepth: 1
+ :caption: Deployment Guides
+
+ Low Latency Deployment
+ Low Resource Deployment
+ Lora Deployment
+ Service Deployment
+ Gradio Deployment
+ ComfyUI Deployment
+ Local Windows Deployment
diff --git a/docs/EN/source/method_tutorials/attention.md b/docs/EN/source/method_tutorials/attention.md
new file mode 100644
index 0000000000000000000000000000000000000000..1396140c74bd7af94b7dc6ccb6f5bb867ed05794
--- /dev/null
+++ b/docs/EN/source/method_tutorials/attention.md
@@ -0,0 +1,35 @@
+# Attention Mechanisms
+
+## Attention Mechanisms Supported by LightX2V
+
+| Name | Type Name | GitHub Link |
+|--------------------|------------------|-------------|
+| Flash Attention 2 | `flash_attn2` | [flash-attention v2](https://github.com/Dao-AILab/flash-attention) |
+| Flash Attention 3 | `flash_attn3` | [flash-attention v3](https://github.com/Dao-AILab/flash-attention) |
+| Sage Attention 2 | `sage_attn2` | [SageAttention](https://github.com/thu-ml/SageAttention) |
+| Radial Attention | `radial_attn` | [Radial Attention](https://github.com/mit-han-lab/radial-attention) |
+| Sparge Attention | `sparge_ckpt` | [Sparge Attention](https://github.com/thu-ml/SpargeAttn) |
+
+---
+
+## Configuration Examples
+
+The configuration files for attention mechanisms are located [here](https://github.com/ModelTC/lightx2v/tree/main/configs/attentions)
+
+By specifying --config_json to a specific config file, you can test different attention mechanisms.
+
+For example, for radial_attn, the configuration is as follows:
+
+```json
+{
+ "self_attn_1_type": "radial_attn",
+ "cross_attn_1_type": "flash_attn3",
+ "cross_attn_2_type": "flash_attn3"
+}
+```
+
+To switch to other types, simply replace the corresponding values with the type names from the table above.
+
+Tips: radial_attn can only be used in self attention due to the limitations of its sparse algorithm principle.
+
+For further customization of attention mechanism behavior, please refer to the official documentation or implementation code of each attention library.
diff --git a/docs/EN/source/method_tutorials/autoregressive_distill.md b/docs/EN/source/method_tutorials/autoregressive_distill.md
new file mode 100644
index 0000000000000000000000000000000000000000..32b9ed50ad551f69e283ff062a825906e6b8a8fe
--- /dev/null
+++ b/docs/EN/source/method_tutorials/autoregressive_distill.md
@@ -0,0 +1,53 @@
+# Autoregressive Distillation
+
+Autoregressive distillation is a technical exploration in LightX2V. By training distilled models, it reduces inference steps from the original 40-50 steps to **8 steps**, achieving inference acceleration while enabling infinite-length video generation through KV Cache technology.
+
+> ⚠️ Warning: Currently, autoregressive distillation has mediocre effects and the acceleration improvement has not met expectations, but it can serve as a long-term research project. Currently, LightX2V only supports autoregressive models for T2V.
+
+## 🔍 Technical Principle
+
+Autoregressive distillation is implemented through [CausVid](https://github.com/tianweiy/CausVid) technology. CausVid performs step distillation and CFG distillation on 1.3B autoregressive models. LightX2V extends it with a series of enhancements:
+
+1. **Larger Models**: Supports autoregressive distillation training for 14B models;
+2. **More Complete Data Processing Pipeline**: Generates a training dataset of 50,000 prompt-video pairs;
+
+For detailed implementation, refer to [CausVid-Plus](https://github.com/GoatWu/CausVid-Plus).
+
+## 🛠️ Configuration Files
+
+### Configuration File
+
+Configuration options are provided in the [configs/causvid/](https://github.com/ModelTC/lightx2v/tree/main/configs/causvid) directory:
+
+| Configuration File | Model Address |
+|-------------------|---------------|
+| [wan_t2v_causvid.json](https://github.com/ModelTC/lightx2v/blob/main/configs/causvid/wan_t2v_causvid.json) | https://huggingface.co/lightx2v/Wan2.1-T2V-14B-CausVid |
+
+### Key Configuration Parameters
+
+```json
+{
+ "enable_cfg": false, // Disable CFG for speed improvement
+ "num_fragments": 3, // Number of video segments generated at once, 5s each
+ "num_frames": 21, // Frames per video segment, modify with caution!
+ "num_frame_per_block": 3, // Frames per autoregressive block, modify with caution!
+ "num_blocks": 7, // Autoregressive blocks per video segment, modify with caution!
+ "frame_seq_length": 1560, // Encoding length per frame, modify with caution!
+ "denoising_step_list": [ // Denoising timestep list
+ 999, 934, 862, 756, 603, 410, 250, 140, 74
+ ]
+}
+```
+
+## 📜 Usage
+
+### Model Preparation
+
+Place the downloaded model (`causal_model.pt` or `causal_model.safetensors`) in the `causvid_models/` folder under the Wan model root directory:
+- For T2V: `Wan2.1-T2V-14B/causvid_models/`
+
+### Inference Script
+
+```bash
+bash scripts/wan/run_wan_t2v_causvid.sh
+```
diff --git a/docs/EN/source/method_tutorials/cache.md b/docs/EN/source/method_tutorials/cache.md
new file mode 100644
index 0000000000000000000000000000000000000000..953c36af8a7ec604ecf98f12fb401ecb1803307e
--- /dev/null
+++ b/docs/EN/source/method_tutorials/cache.md
@@ -0,0 +1,3 @@
+# Feature Cache
+
+To demonstrate some video playback effects, you can get better display effects and corresponding documentation content on this [🔗 page](https://github.com/ModelTC/LightX2V/blob/main/docs/EN/source/method_tutorials/cache_source.md).
diff --git a/docs/EN/source/method_tutorials/cache_source.md b/docs/EN/source/method_tutorials/cache_source.md
new file mode 100644
index 0000000000000000000000000000000000000000..3fd14c010867058f64644e43a07a625a438840b2
--- /dev/null
+++ b/docs/EN/source/method_tutorials/cache_source.md
@@ -0,0 +1,139 @@
+# Feature Caching
+
+## Cache Acceleration Algorithm
+- In the inference process of diffusion models, cache reuse is an important acceleration algorithm.
+- The core idea is to skip redundant computations at certain time steps by reusing historical cache results to improve inference efficiency.
+- The key to the algorithm is how to decide which time steps to perform cache reuse, usually based on dynamic judgment of model state changes or error thresholds.
+- During inference, key content such as intermediate features, residuals, and attention outputs need to be cached. When entering reusable time steps, the cached content is directly utilized, and the current output is reconstructed through approximation methods like Taylor expansion, thereby reducing repeated calculations and achieving efficient inference.
+
+### TeaCache
+The core idea of `TeaCache` is to accumulate the **relative L1** distance between adjacent time step inputs. When the accumulated distance reaches a set threshold, it determines that the current time step should not use cache reuse; conversely, when the accumulated distance does not reach the set threshold, cache reuse is used to accelerate the inference process.
+- Specifically, the algorithm calculates the relative L1 distance between the current input and the previous step input at each inference step and accumulates it.
+- When the accumulated distance does not exceed the threshold, it indicates that the model state change is not obvious, so the most recently cached content is directly reused, skipping some redundant calculations. This can significantly reduce the number of forward computations of the model and improve inference speed.
+
+In practical effects, TeaCache achieves significant acceleration while ensuring generation quality. On a single H200 card, the time consumption and video comparison before and after acceleration are as follows:
+
+
+
+ |
+ Before acceleration: 58s
+ |
+
+ After acceleration: 17.9s
+ |
+
+
+ |
+
+ |
+
+
+ |
+
+
+
+
+- Acceleration ratio: **3.24**
+- Config: [wan_t2v_1_3b_tea_480p.json](https://github.com/ModelTC/lightx2v/tree/main/configs/caching/teacache/wan_t2v_1_3b_tea_480p.json)
+- Reference paper: [https://arxiv.org/abs/2411.19108](https://arxiv.org/abs/2411.19108)
+
+### TaylorSeer Cache
+The core of `TaylorSeer Cache` lies in using Taylor's formula to recalculate cached content as residual compensation for cache reuse time steps.
+- The specific approach is to not only simply reuse historical cache at cache reuse time steps, but also approximately reconstruct the current output through Taylor expansion. This can further improve output accuracy while reducing computational load.
+- Taylor expansion can effectively capture minor changes in model state, allowing errors caused by cache reuse to be compensated, thereby ensuring generation quality while accelerating.
+
+`TaylorSeer Cache` is suitable for scenarios with high output accuracy requirements and can further improve model inference performance based on cache reuse.
+
+
+
+ |
+ Before acceleration: 57.7s
+ |
+
+ After acceleration: 41.3s
+ |
+
+
+ |
+
+ |
+
+
+ |
+
+
+
+
+- Acceleration ratio: **1.39**
+- Config: [wan_t2v_taylorseer](https://github.com/ModelTC/lightx2v/tree/main/configs/caching/taylorseer/wan_t2v_taylorseer.json)
+- Reference paper: [https://arxiv.org/abs/2503.06923](https://arxiv.org/abs/2503.06923)
+
+### AdaCache
+The core idea of `AdaCache` is to dynamically adjust the step size of cache reuse based on partial cached content in specified block chunks.
+- The algorithm analyzes feature differences between two adjacent time steps within specific blocks and adaptively determines the next cache reuse time step interval based on the difference magnitude.
+- When model state changes are small, the step size automatically increases, reducing cache update frequency; when state changes are large, the step size decreases to ensure output quality.
+
+This allows flexible adjustment of caching strategies based on dynamic changes in the actual inference process, achieving more efficient acceleration and better generation results. AdaCache is suitable for application scenarios that have high requirements for both inference speed and generation quality.
+
+
+
+ |
+ Before acceleration: 227s
+ |
+
+ After acceleration: 83s
+ |
+
+
+ |
+
+ |
+
+
+ |
+
+
+
+
+- Acceleration ratio: **2.73**
+- Config: [wan_i2v_ada](https://github.com/ModelTC/lightx2v/tree/main/configs/caching/adacache/wan_i2v_ada.json)
+- Reference paper: [https://arxiv.org/abs/2411.02397](https://arxiv.org/abs/2411.02397)
+
+### CustomCache
+`CustomCache` combines the advantages of `TeaCache` and `TaylorSeer Cache`.
+- It combines the real-time and reasonable cache decision-making of `TeaCache`, determining when to perform cache reuse through dynamic thresholds.
+- At the same time, it utilizes `TaylorSeer`'s Taylor expansion method to make use of cached content.
+
+This not only efficiently determines the timing of cache reuse but also maximizes the utilization of cached content, improving output accuracy and generation quality. Actual testing shows that `CustomCache` produces video quality superior to using `TeaCache`, `TaylorSeer Cache`, or `AdaCache` alone across multiple content generation tasks, making it one of the currently optimal comprehensive cache acceleration algorithms.
+
+
+
+ |
+ Before acceleration: 57.9s
+ |
+
+ After acceleration: 16.6s
+ |
+
+
+ |
+
+ |
+
+
+ |
+
+
+
+
+- Acceleration ratio: **3.49**
+- Config: [wan_t2v_custom_1_3b](https://github.com/ModelTC/lightx2v/tree/main/configs/caching/custom/wan_t2v_custom_1_3b.json)
+
+
+## Usage
+
+The config files for feature caching are located [here](https://github.com/ModelTC/lightx2v/tree/main/configs/caching)
+
+By specifying --config_json to the specific config file, you can test different cache algorithms.
+
+[Here](https://github.com/ModelTC/lightx2v/tree/main/scripts/cache) are some running scripts for use.
diff --git a/docs/EN/source/method_tutorials/changing_resolution.md b/docs/EN/source/method_tutorials/changing_resolution.md
new file mode 100644
index 0000000000000000000000000000000000000000..9c936949efc29464dfa313454844618b34d80ef3
--- /dev/null
+++ b/docs/EN/source/method_tutorials/changing_resolution.md
@@ -0,0 +1,66 @@
+# Variable Resolution Inference
+
+## Overview
+
+Variable resolution inference is a technical strategy for optimizing the denoising process. It improves computational efficiency while maintaining generation quality by using different resolutions at different stages of the denoising process. The core idea of this method is to use lower resolution for coarse denoising in the early stages and switch to normal resolution for fine processing in the later stages.
+
+## Technical Principles
+
+### Multi-stage Denoising Strategy
+
+Variable resolution inference is based on the following observations:
+
+- **Early-stage denoising**: Mainly handles coarse noise and overall structure, requiring less detailed information
+- **Late-stage denoising**: Focuses on detail optimization and high-frequency information recovery, requiring complete resolution information
+
+### Resolution Switching Mechanism
+
+1. **Low-resolution stage** (early stage)
+ - Downsample the input to a lower resolution (e.g., 0.75x of original size)
+ - Execute initial denoising steps
+ - Quickly remove most noise and establish basic structure
+
+2. **Normal resolution stage** (late stage)
+ - Upsample the denoising result from the first step back to original resolution
+ - Continue executing remaining denoising steps
+ - Restore detailed information and complete fine processing
+
+### U-shaped Resolution Strategy
+
+If resolution is reduced at the very beginning of the denoising steps, it may cause significant differences between the final generated video and the video generated through normal inference. Therefore, a U-shaped resolution strategy can be adopted, where the original resolution is maintained for the first few steps, then resolution is reduced for inference.
+
+## Usage
+
+The config files for variable resolution inference are located [here](https://github.com/ModelTC/LightX2V/tree/main/configs/changing_resolution)
+
+You can test variable resolution inference by specifying --config_json to the specific config file.
+
+You can refer to the scripts [here](https://github.com/ModelTC/LightX2V/blob/main/scripts/changing_resolution) to run.
+
+### Example 1:
+```
+{
+ "infer_steps": 50,
+ "changing_resolution": true,
+ "resolution_rate": [0.75],
+ "changing_resolution_steps": [25]
+}
+```
+
+This means a total of 50 steps, with resolution at 0.75x original resolution from step 1 to 25, and original resolution from step 26 to the final step.
+
+### Example 2:
+```
+{
+ "infer_steps": 50,
+ "changing_resolution": true,
+ "resolution_rate": [1.0, 0.75],
+ "changing_resolution_steps": [10, 35]
+}
+```
+
+This means a total of 50 steps, with original resolution from step 1 to 10, 0.75x original resolution from step 11 to 35, and original resolution from step 36 to the final step.
+
+Generally, if `changing_resolution_steps` is [A, B, C], the denoising starts at step 1, and the total number of steps is X, then the inference process will be divided into four segments.
+
+Specifically, these segments are (0, A], (A, B], (B, C], and (C, X], where each segment is a left-open, right-closed interval.
diff --git a/docs/EN/source/method_tutorials/offload.md b/docs/EN/source/method_tutorials/offload.md
new file mode 100644
index 0000000000000000000000000000000000000000..0fff2dc569d02bd6c669ab52112d4c70d5f9c03d
--- /dev/null
+++ b/docs/EN/source/method_tutorials/offload.md
@@ -0,0 +1,177 @@
+# Parameter Offload
+
+## 📖 Overview
+
+LightX2V implements an advanced parameter offload mechanism specifically designed for large model inference under limited hardware resources. The system provides an excellent speed-memory balance by intelligently managing model weights across different memory hierarchies.
+
+**Core Features:**
+- **Block/Phase-level Offload**: Efficiently manages model weights in block/phase units for optimal memory usage
+ - **Block**: The basic computational unit of Transformer models, containing complete Transformer layers (self-attention, cross-attention, feedforward networks, etc.), serving as a larger memory management unit
+ - **Phase**: Finer-grained computational stages within blocks, containing individual computational components (such as self-attention, cross-attention, feedforward networks, etc.), providing more precise memory control
+- **Multi-tier Storage Support**: GPU → CPU → Disk hierarchy with intelligent caching
+- **Asynchronous Operations**: Overlaps computation and data transfer using CUDA streams
+- **Disk/NVMe Serialization**: Supports secondary storage when memory is insufficient
+
+## 🎯 Offload Strategies
+
+### Strategy 1: GPU-CPU Block/Phase Offload
+
+**Use Case**: Insufficient GPU memory but sufficient system memory
+
+**How It Works**: Manages model weights in block or phase units between GPU and CPU memory, utilizing CUDA streams to overlap computation and data transfer. Blocks contain complete Transformer layers, while Phases are individual computational components within blocks.
+
+
+
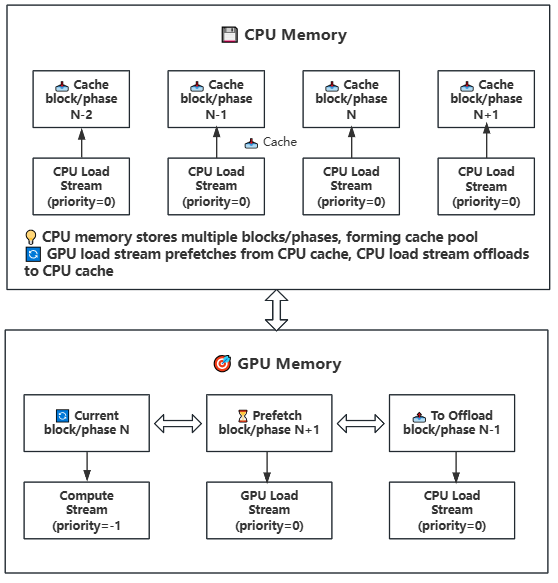
+
+
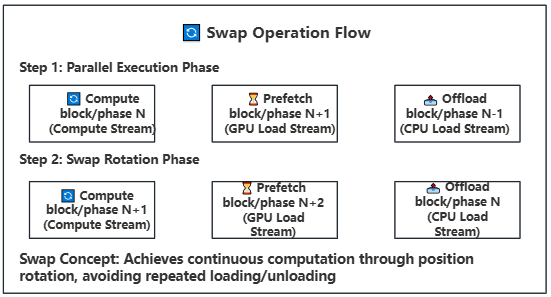
+
+
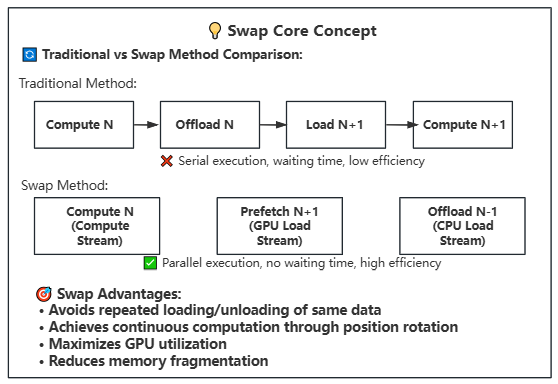
+
+
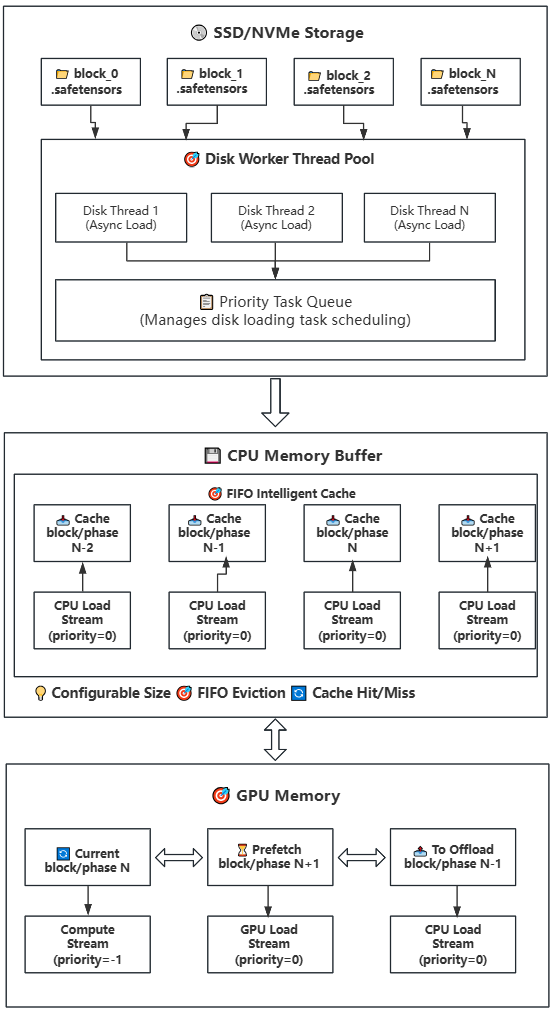
+
+
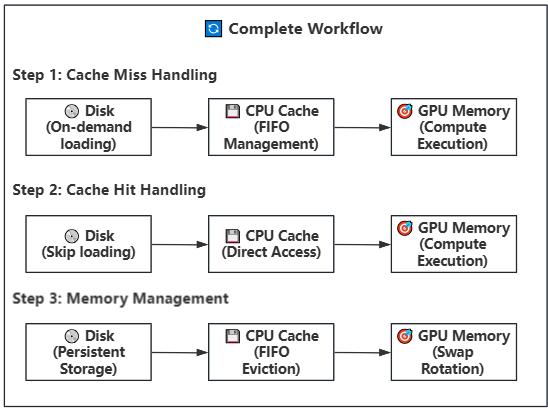
+
+
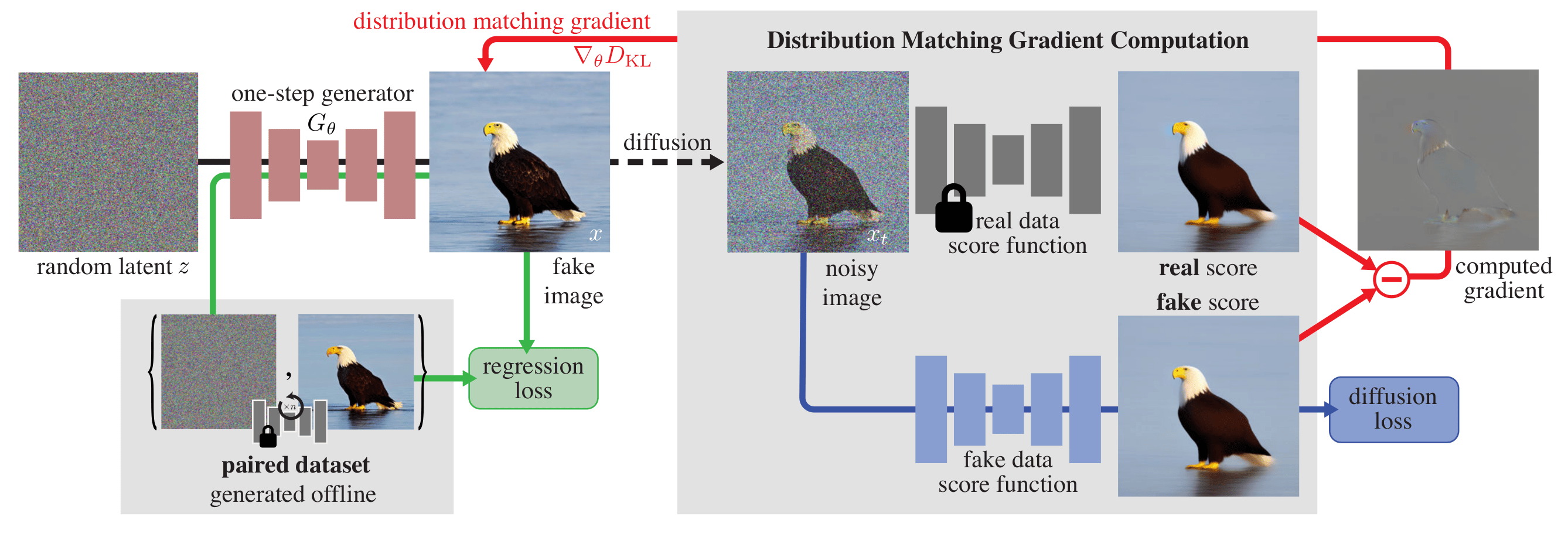
+
+ LightX2V: 一个轻量级的视频生成推理框架
+
+
+
+LightX2V 是一个轻量级的视频生成推理框架。这里是我们维护的一个视频生成推理加速相关的论文收藏集,帮助你快速了解视频生成推理加速相关的经典方法和最新进展。
+
+GitHub: https://github.com/ModelTC/lightx2v
+
+HuggingFace: https://huggingface.co/lightx2v
+
+论文收藏集
+-------------
+
+.. toctree::
+ :maxdepth: 1
+ :caption: 论文分类
+
+ 图像视频生成基础
+ 开源模型
+ 模型量化
+ 特征缓存
+ 注意力机制
+ 参数卸载
+ 并行推理
+ 变分辨率推理
+ 步数蒸馏
+ 自回归模型
+ vae加速
+ prompt增强
+ 强化学习
diff --git a/docs/PAPERS_ZH_CN/source/papers/RL.md b/docs/PAPERS_ZH_CN/source/papers/RL.md
new file mode 100644
index 0000000000000000000000000000000000000000..0081f92328a9fe548654098b76adc5815aba6171
--- /dev/null
+++ b/docs/PAPERS_ZH_CN/source/papers/RL.md
@@ -0,0 +1,3 @@
+# 强化学习
+
+xxx
diff --git a/docs/PAPERS_ZH_CN/source/papers/attention.md b/docs/PAPERS_ZH_CN/source/papers/attention.md
new file mode 100644
index 0000000000000000000000000000000000000000..a17d295b51fb08e97f2a41c7c79bd5a1831cddfc
--- /dev/null
+++ b/docs/PAPERS_ZH_CN/source/papers/attention.md
@@ -0,0 +1,113 @@
+# 注意力机制
+
+### Sparse VideoGen: Accelerating Video Diffusion Transformers with Spatial-Temporal Sparsity
+
+[paper](https://arxiv.org/abs/2502.01776) | [code](https://github.com/svg-project/Sparse-VideoGen)
+
+### Sparse VideoGen2: Accelerate Video Generation with Sparse Attention via Semantic-Aware Permutation
+
+[paper](https://arxiv.org/abs/2505.18875)
+
+### Training-free and Adaptive Sparse Attention for Efficient Long Video Generation
+
+[paper](https://arxiv.org/abs/2502.21079)
+
+### DSV: Exploiting Dynamic Sparsity to Accelerate Large-Scale Video DiT Training
+
+[paper](https://arxiv.org/abs/2502.07590)
+
+### MMInference: Accelerating Pre-filling for Long-Context VLMs via Modality-Aware Permutation Sparse Attention
+
+[paper](https://github.com/microsoft/MInference)
+
+### FPSAttention: Training-Aware FP8 and Sparsity Co-Design for Fast Video Diffusion
+
+[paper](https://arxiv.org/abs/2506.04648)
+
+### VORTA: Efficient Video Diffusion via Routing Sparse Attention
+
+[paper](https://arxiv.org/abs/2505.18809)
+
+### Training-Free Efficient Video Generation via Dynamic Token Carving
+
+[paper](https://arxiv.org/abs/2505.16864)
+
+### RainFusion: Adaptive Video Generation Acceleration via Multi-Dimensional Visual Redundancy
+
+[paper](https://arxiv.org/abs/2505.21036)
+
+### Radial Attention: O(nlogn) Sparse Attention with Energy Decay for Long Video Generation
+
+[paper](https://arxiv.org/abs/2506.19852)
+
+### VMoBA: Mixture-of-Block Attention for Video Diffusion Models
+
+[paper](https://arxiv.org/abs/2506.23858)
+
+### SpargeAttention: Accurate and Training-free Sparse Attention Accelerating Any Model Inference
+
+[paper](https://arxiv.org/abs/2502.18137) | [code](https://github.com/thu-ml/SpargeAttn)
+
+### Fast Video Generation with Sliding Tile Attention
+
+[paper](https://arxiv.org/abs/2502.04507) | [code](https://github.com/hao-ai-lab/FastVideo)
+
+### PAROAttention: Pattern-Aware ReOrdering for Efficient Sparse and Quantized Attention in Visual Generation Models
+
+[paper](https://arxiv.org/abs/2506.16054)
+
+### Generalized Neighborhood Attention: Multi-dimensional Sparse Attention at the Speed of Light
+
+[paper](https://arxiv.org/abs/2504.16922)
+
+### Astraea: A GPU-Oriented Token-wise Acceleration Framework for Video Diffusion Transformers
+
+[paper](https://arxiv.org/abs/2506.05096)
+
+### ∇NABLA: Neighborhood Adaptive Block-Level Attention
+
+[paper](https://arxiv.org/abs/2507.13546v1) [code](https://github.com/gen-ai-team/Wan2.1-NABLA)
+
+### Compact Attention: Exploiting Structured Spatio-Temporal Sparsity for Fast Video Generation
+
+[paper](https://arxiv.org/abs/2508.12969)
+
+### A Survey of Efficient Attention Methods: Hardware-efficient, Sparse, Compact, and Linear Attention
+
+[paper](https://attention-survey.github.io/files/Attention_Survey.pdf)
+
+### Bidirectional Sparse Attention for Faster Video Diffusion Training
+
+[paper](https://arxiv.org/abs/2509.01085)
+
+### Mixture of Contexts for Long Video Generation
+
+[paper](https://arxiv.org/abs/2508.21058)
+
+### LoViC: Efficient Long Video Generation with Context Compression
+
+[paper](https://arxiv.org/abs/2507.12952)
+
+### MagiAttention: A Distributed Attention Towards Linear Scalability for Ultra-Long Context, Heterogeneous Mask Training
+
+[paper](https://sandai-org.github.io/MagiAttention/blog/) [code](https://github.com/SandAI-org/MagiAttention)
+
+### DraftAttention: Fast Video Diffusion via Low-Resolution Attention Guidance
+
+[paper](https://arxiv.org/abs/2505.14708) [code](https://github.com/shawnricecake/draft-attention)
+
+### XAttention: Block Sparse Attention with Antidiagonal Scoring
+
+[paper](https://arxiv.org/abs/2503.16428) [code](https://github.com/mit-han-lab/x-attention)
+
+### VSA: Faster Video Diffusion with Trainable Sparse Attention
+
+[paper](https://arxiv.org/abs/2505.13389) [code](https://github.com/hao-ai-lab/FastVideo)
+
+### QuantSparse: Comprehensively Compressing Video Diffusion Transformer with Model Quantization and Attention Sparsification
+
+[paper](https://arxiv.org/abs/2509.23681)
+
+### SLA: Beyond Sparsity in Diffusion Transformers via Fine-Tunable Sparse-Linear Attention
+
+[paper](https://arxiv.org/abs/2509.24006)
diff --git a/docs/PAPERS_ZH_CN/source/papers/autoregressive.md b/docs/PAPERS_ZH_CN/source/papers/autoregressive.md
new file mode 100644
index 0000000000000000000000000000000000000000..27c2d1dad269960325ee64c86df155622f2410c8
--- /dev/null
+++ b/docs/PAPERS_ZH_CN/source/papers/autoregressive.md
@@ -0,0 +1,3 @@
+# 自回归模型
+
+xxx
diff --git a/docs/PAPERS_ZH_CN/source/papers/cache.md b/docs/PAPERS_ZH_CN/source/papers/cache.md
new file mode 100644
index 0000000000000000000000000000000000000000..661ef10213cbf5af62d0f3443a8ab774285f4be4
--- /dev/null
+++ b/docs/PAPERS_ZH_CN/source/papers/cache.md
@@ -0,0 +1,3 @@
+# 特征缓存
+
+xxx
diff --git a/docs/PAPERS_ZH_CN/source/papers/changing_resolution.md b/docs/PAPERS_ZH_CN/source/papers/changing_resolution.md
new file mode 100644
index 0000000000000000000000000000000000000000..175eea9e79dc2936404ad276ffe96f86ae8b7a35
--- /dev/null
+++ b/docs/PAPERS_ZH_CN/source/papers/changing_resolution.md
@@ -0,0 +1,3 @@
+# 变分辨率推理
+
+xxx
diff --git a/docs/PAPERS_ZH_CN/source/papers/generation_basics.md b/docs/PAPERS_ZH_CN/source/papers/generation_basics.md
new file mode 100644
index 0000000000000000000000000000000000000000..6d5b97f72edf792e6f670998849da9a2a3e7d96d
--- /dev/null
+++ b/docs/PAPERS_ZH_CN/source/papers/generation_basics.md
@@ -0,0 +1,3 @@
+# 图像视频生成基础
+
+xxx
diff --git a/docs/PAPERS_ZH_CN/source/papers/models.md b/docs/PAPERS_ZH_CN/source/papers/models.md
new file mode 100644
index 0000000000000000000000000000000000000000..de9e00c69d9b1d02e35766addcc9df106604b842
--- /dev/null
+++ b/docs/PAPERS_ZH_CN/source/papers/models.md
@@ -0,0 +1,276 @@
+
+
+
+# Open-Source Models
+
+📢: Collections of Awesome Open-Source Model Resources.
+
+
+
+
+## 📚 *Contents*
+
+- Open-Source Models
+ - [Foundation Models](#foundation-models)
+ - [World Models](#world-models)
+
+
+### Foundation Models:
+
+- **Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets**, Technical Report 2023.
+
+ *Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, et al.*
+
+ [[Paper](https://arxiv.org/abs/2311.15127)] [[Code](https://github.com/Stability-AI/generative-models)]   
+
+ BibTex
+
+ ```text
+ @article{blattmann2023stable,
+ title={Stable video diffusion: Scaling latent video diffusion models to large datasets},
+ author={Blattmann, Andreas and Dockhorn, Tim and Kulal, Sumith and Mendelevitch, Daniel and Kilian, Maciej and Lorenz, Dominik and Levi, Yam and English, Zion and Voleti, Vikram and Letts, Adam and others},
+ journal={arXiv preprint arXiv:2311.15127},
+ year={2023}
+ }
+ ```
+
+
+- **Wan: Open and Advanced Large-Scale Video Generative Models**, Technical Report 2025.
+
+ *Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, et al.*
+
+ [[Paper](https://arxiv.org/abs/2503.20314)] [[Code](https://github.com/Wan-Video/Wan2.1)]   
+
+ BibTex
+
+ ```text
+ @article{wan2025wan,
+ title={Wan: Open and advanced large-scale video generative models},
+ author={Wan, Team and Wang, Ang and Ai, Baole and Wen, Bin and Mao, Chaojie and Xie, Chen-Wei and Chen, Di and Yu, Feiwu and Zhao, Haiming and Yang, Jianxiao and others},
+ journal={arXiv preprint arXiv:2503.20314},
+ year={2025}
+ }
+ ```
+
+
+- **HunyuanVideo: A Systematic Framework For Large Video Generation Model**, Technical Report 2024.
+
+ *Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, et al.*
+
+ [[Paper](https://arxiv.org/abs/2412.03603)] [[Code](https://github.com/Tencent-Hunyuan/HunyuanVideo)]   
+
+ BibTex
+
+ ```text
+ @article{kong2024hunyuanvideo,
+ title={Hunyuanvideo: A systematic framework for large video generative models},
+ author={Kong, Weijie and Tian, Qi and Zhang, Zijian and Min, Rox and Dai, Zuozhuo and Zhou, Jin and Xiong, Jiangfeng and Li, Xin and Wu, Bo and Zhang, Jianwei and others},
+ journal={arXiv preprint arXiv:2412.03603},
+ year={2024}
+ }
+ ```
+
+
+- **CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer**, ICLR 2025.
+
+ *Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, et al.*
+
+ [[Paper](https://arxiv.org/abs/2408.06072)] [[Code](https://github.com/zai-org/CogVideo)]   
+
+ BibTex
+
+ ```text
+ @article{yang2024cogvideox,
+ title={Cogvideox: Text-to-video diffusion models with an expert transformer},
+ author={Yang, Zhuoyi and Teng, Jiayan and Zheng, Wendi and Ding, Ming and Huang, Shiyu and Xu, Jiazheng and Yang, Yuanming and Hong, Wenyi and Zhang, Xiaohan and Feng, Guanyu and others},
+ journal={arXiv preprint arXiv:2408.06072},
+ year={2024}
+ }
+ ```
+
+
+
+- **SkyReels V2: Infinite-Length Film Generative Model**, Technical Report 2025.
+
+ *Guibin Chen, Dixuan Lin, Jiangping Yang, Chunze Lin, Junchen Zhu, Mingyuan Fan, et al.*
+
+ [[Paper](https://arxiv.org/abs/2504.13074)] [[Code](https://github.com/SkyworkAI/SkyReels-V2)]   
+
+ BibTex
+
+ ```text
+ @misc{chen2025skyreelsv2infinitelengthfilmgenerative,
+ title={SkyReels-V2: Infinite-length Film Generative Model},
+ author={Guibin Chen and Dixuan Lin and Jiangping Yang and Chunze Lin and Junchen Zhu and Mingyuan Fan and Hao Zhang and Sheng Chen and Zheng Chen and Chengcheng Ma and Weiming Xiong and Wei Wang and Nuo Pang and Kang Kang and Zhiheng Xu and Yuzhe Jin and Yupeng Liang and Yubing Song and Peng Zhao and Boyuan Xu and Di Qiu and Debang Li and Zhengcong Fei and Yang Li and Yahui Zhou},
+ year={2025},
+ eprint={2504.13074},
+ archivePrefix={arXiv},
+ primaryClass={cs.CV},
+ url={https://arxiv.org/abs/2504.13074},
+ }
+ ```
+
+
+
+- **Open-Sora: Democratizing Efficient Video Production for All**, Technical Report 2025.
+
+ *Xiangyu Peng, Zangwei Zheng, Chenhui Shen, Tom Young, Xinying Guo, et al.*
+
+ [[Paper](https://arxiv.org/abs/2503.09642v2)] [[Code](https://github.com/hpcaitech/Open-Sora)]    
+
+ BibTex
+
+ ```text
+ @article{peng2025open,
+ title={Open-sora 2.0: Training a commercial-level video generation model in $200 k},
+ author={Peng, Xiangyu and Zheng, Zangwei and Shen, Chenhui and Young, Tom and Guo, Xinying and Wang, Binluo and Xu, Hang and Liu, Hongxin and Jiang, Mingyan and Li, Wenjun and others},
+ journal={arXiv preprint arXiv:2503.09642},
+ year={2025}
+ }
+ ```
+
+
+- **Pyramidal Flow Matching for Efficient Video Generative Modeling**, Technical Report 2024.
+
+ *Yang Jin, Zhicheng Sun, Ningyuan Li, Kun Xu, Kun Xu, et al.*
+
+ [[Paper](https://arxiv.org/abs/2410.05954)] [[Code](https://github.com/jy0205/Pyramid-Flow)]   
+ BibTex
+
+ ```text
+ @article{jin2024pyramidal,
+ title={Pyramidal flow matching for efficient video generative modeling},
+ author={Jin, Yang and Sun, Zhicheng and Li, Ningyuan and Xu, Kun and Jiang, Hao and Zhuang, Nan and Huang, Quzhe and Song, Yang and Mu, Yadong and Lin, Zhouchen},
+ journal={arXiv preprint arXiv:2410.05954},
+ year={2024}
+ }
+ ```
+
+
+- **MAGI-1: Autoregressive Video Generation at Scale**, Technical Report 2025.
+
+ *Sand.ai, Hansi Teng, Hongyu Jia, Lei Sun, Lingzhi Li, Maolin Li, Mingqiu Tang, et al.*
+
+ [[Paper](https://arxiv.org/pdf/2505.13211)] [[Code](https://github.com/SandAI-org/Magi-1)]    
+ BibTex
+
+ ```text
+ @article{teng2025magi,
+ title={MAGI-1: Autoregressive Video Generation at Scale},
+ author={Teng, Hansi and Jia, Hongyu and Sun, Lei and Li, Lingzhi and Li, Maolin and Tang, Mingqiu and Han, Shuai and Zhang, Tianning and Zhang, WQ and Luo, Weifeng and others},
+ journal={arXiv preprint arXiv:2505.13211},
+ year={2025}
+ }
+ ```
+
+
+- **From Slow Bidirectional to Fast Autoregressive Video Diffusion Models**, CVPR 2025.
+
+ *Tianwei Yin, Qiang Zhang, Richard Zhang, William T. Freeman, Fredo Durand, et al.*
+
+ [[Paper](http://arxiv.org/abs/2412.07772)] [[Code](https://github.com/tianweiy/CausVid)]   
+ BibTex
+
+ ```text
+ @inproceedings{yin2025slow,
+ title={From slow bidirectional to fast autoregressive video diffusion models},
+ author={Yin, Tianwei and Zhang, Qiang and Zhang, Richard and Freeman, William T and Durand, Fredo and Shechtman, Eli and Huang, Xun},
+ booktitle={Proceedings of the Computer Vision and Pattern Recognition Conference},
+ pages={22963--22974},
+ year={2025}
+ }
+ ```
+
+
+- **Packing Input Frame Context in Next-Frame Prediction Models for Video Generation**, arxiv 2025.
+
+ *Lvmin Zhang, Maneesh Agrawala.*
+
+ [[Paper](https://arxiv.org/abs/2504.12626)] [[Code](https://github.com/lllyasviel/FramePack)]   
+ BibTex
+
+ ```text
+ @article{zhang2025packing,
+ title={Packing input frame context in next-frame prediction models for video generation},
+ author={Zhang, Lvmin and Agrawala, Maneesh},
+ journal={arXiv preprint arXiv:2504.12626},
+ year={2025}
+ }
+ ```
+
+
+### World Models:
+
+- **Matrix-Game 2.0: An Open-Source, Real-Time, and Streaming Interactive World Model**, Technical Report 2025.
+
+ *Xianglong He, Chunli Peng, Zexiang Liu, Boyang Wang, Yifan Zhang, et al.*
+
+ [[Paper](https://arxiv.org/abs/2508.13009)] [[Code](https://matrix-game-v2.github.io/)]   
+ BibTex
+
+ ```text
+ @article{he2025matrix,
+ title={Matrix-Game 2.0: An Open-Source, Real-Time, and Streaming Interactive World Model},
+ author={He, Xianglong and Peng, Chunli and Liu, Zexiang and Wang, Boyang and Zhang, Yifan and Cui, Qi and Kang, Fei and Jiang, Biao and An, Mengyin and Ren, Yangyang and others},
+ journal={arXiv preprint arXiv:2508.13009},
+ year={2025}
+ }
+ ```
+
+
+- **HunyuanWorld 1.0: Generating Immersive, Explorable, and Interactive 3D Worlds from Words or Pixels**, Technical Report 2025.
+
+ *HunyuanWorld Team, Zhenwei Wang, Yuhao Liu, Junta Wu, Zixiao Gu, Haoyuan Wang, et al.*
+
+ [[Paper](https://arxiv.org/abs/2507.21809)] [[Code](https://github.com/Tencent-Hunyuan/HunyuanWorld-1.0)]   
+ BibTex
+
+ ```text
+ @article{team2025hunyuanworld,
+ title={HunyuanWorld 1.0: Generating Immersive, Explorable, and Interactive 3D Worlds from Words or Pixels},
+ author={Team, HunyuanWorld and Wang, Zhenwei and Liu, Yuhao and Wu, Junta and Gu, Zixiao and Wang, Haoyuan and Zuo, Xuhui and Huang, Tianyu and Li, Wenhuan and Zhang, Sheng and others},
+ journal={arXiv preprint arXiv:2507.21809},
+ year={2025}
+ }
+ ```
+
+
+- **Cosmos-Drive-Dreams: Scalable Synthetic Driving Data Generation with World Foundation Models**, Technical Report 2025.
+
+ *Xuanchi Ren, Yifan Lu, Tianshi Cao, Ruiyuan Gao, Shengyu Huang, Amirmojtaba Sabour, et al.*
+
+ [[Paper](https://arxiv.org/abs/2506.09042)] [[Code](https://research.nvidia.com/labs/toronto-ai/cosmos_drive_dreams)]  
+ BibTex
+
+ ```text
+ @article{ren2025cosmos,
+ title={Cosmos-Drive-Dreams: Scalable Synthetic Driving Data Generation with World Foundation Models},
+ author={Ren, Xuanchi and Lu, Yifan and Cao, Tianshi and Gao, Ruiyuan and Huang, Shengyu and Sabour, Amirmojtaba and Shen, Tianchang and Pfaff, Tobias and Wu, Jay Zhangjie and Chen, Runjian and others},
+ journal={arXiv preprint arXiv:2506.09042},
+ year={2025}
+ }
+ ```
+
+
+- **Genie 3: A new frontier for world models**, Blog 2025.
+
+ *Google DeepMind*
+
+ [[Blog](https://deepmind.google/discover/blog/genie-3-a-new-frontier-for-world-models/)]  
+
+- **GAIA-2: A Controllable Multi-View Generative World Model for Autonomous Driving.**, Technical Report 2025.
+
+ *Lloyd Russell, Anthony Hu, Lorenzo Bertoni, George Fedoseev, Jamie Shotton, et al.*
+
+ [[Paper](https://arxiv.org/abs/2503.20523)] [[Code](https://github.com/Tencent-Hunyuan/HunyuanWorld-1.0)]  
+ BibTex
+
+ ```text
+ @article{russell2025gaia,
+ title={Gaia-2: A controllable multi-view generative world model for autonomous driving},
+ author={Russell, Lloyd and Hu, Anthony and Bertoni, Lorenzo and Fedoseev, George and Shotton, Jamie and Arani, Elahe and Corrado, Gianluca},
+ journal={arXiv preprint arXiv:2503.20523},
+ year={2025}
+ }
+ ```
+
diff --git a/docs/PAPERS_ZH_CN/source/papers/offload.md b/docs/PAPERS_ZH_CN/source/papers/offload.md
new file mode 100644
index 0000000000000000000000000000000000000000..302f0b6869df1d6263f2748a7dfd11bd7dae4f1e
--- /dev/null
+++ b/docs/PAPERS_ZH_CN/source/papers/offload.md
@@ -0,0 +1,3 @@
+# 参数卸载
+
+xxx
diff --git a/docs/PAPERS_ZH_CN/source/papers/parallel.md b/docs/PAPERS_ZH_CN/source/papers/parallel.md
new file mode 100644
index 0000000000000000000000000000000000000000..b68de1c0ebdc89c76e3155a1c22daed2ee3a7a8d
--- /dev/null
+++ b/docs/PAPERS_ZH_CN/source/papers/parallel.md
@@ -0,0 +1,3 @@
+# 并行推理
+
+xxx
diff --git a/docs/PAPERS_ZH_CN/source/papers/prompt_enhance.md b/docs/PAPERS_ZH_CN/source/papers/prompt_enhance.md
new file mode 100644
index 0000000000000000000000000000000000000000..d51d77bf8a8338c6eb04de88a09eb7cf65d01681
--- /dev/null
+++ b/docs/PAPERS_ZH_CN/source/papers/prompt_enhance.md
@@ -0,0 +1,3 @@
+# prompt增强
+
+xxx
diff --git a/docs/PAPERS_ZH_CN/source/papers/quantization.md b/docs/PAPERS_ZH_CN/source/papers/quantization.md
new file mode 100644
index 0000000000000000000000000000000000000000..d29d8f6af2e8e44f9a179d7a33150286ec500504
--- /dev/null
+++ b/docs/PAPERS_ZH_CN/source/papers/quantization.md
@@ -0,0 +1,3 @@
+# 模型量化
+
+xxx
diff --git a/docs/PAPERS_ZH_CN/source/papers/step_distill.md b/docs/PAPERS_ZH_CN/source/papers/step_distill.md
new file mode 100644
index 0000000000000000000000000000000000000000..e5e772f9a881bdce0e42f0a2862741da9c630830
--- /dev/null
+++ b/docs/PAPERS_ZH_CN/source/papers/step_distill.md
@@ -0,0 +1,3 @@
+# 步数蒸馏
+
+xxx
diff --git a/docs/PAPERS_ZH_CN/source/papers/vae.md b/docs/PAPERS_ZH_CN/source/papers/vae.md
new file mode 100644
index 0000000000000000000000000000000000000000..914d54db1b4b307acceba09a66d1eb5bcd9bbee3
--- /dev/null
+++ b/docs/PAPERS_ZH_CN/source/papers/vae.md
@@ -0,0 +1,3 @@
+# vae加速
+
+xxx
diff --git a/docs/ZH_CN/.readthedocs.yaml b/docs/ZH_CN/.readthedocs.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..c3677c6092fd6559cf83d4663cfcf32df98d891a
--- /dev/null
+++ b/docs/ZH_CN/.readthedocs.yaml
@@ -0,0 +1,17 @@
+version: 2
+
+# Set the version of Python and other tools you might need
+build:
+ os: ubuntu-20.04
+ tools:
+ python: "3.10"
+
+formats:
+ - epub
+
+sphinx:
+ configuration: docs/ZH_CN/source/conf.py
+
+python:
+ install:
+ - requirements: requirements-docs.txt
diff --git a/docs/ZH_CN/Makefile b/docs/ZH_CN/Makefile
new file mode 100644
index 0000000000000000000000000000000000000000..d0c3cbf1020d5c292abdedf27627c6abe25e2293
--- /dev/null
+++ b/docs/ZH_CN/Makefile
@@ -0,0 +1,20 @@
+# Minimal makefile for Sphinx documentation
+#
+
+# You can set these variables from the command line, and also
+# from the environment for the first two.
+SPHINXOPTS ?=
+SPHINXBUILD ?= sphinx-build
+SOURCEDIR = source
+BUILDDIR = build
+
+# Put it first so that "make" without argument is like "make help".
+help:
+ @$(SPHINXBUILD) -M help "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
+
+.PHONY: help Makefile
+
+# Catch-all target: route all unknown targets to Sphinx using the new
+# "make mode" option. $(O) is meant as a shortcut for $(SPHINXOPTS).
+%: Makefile
+ @$(SPHINXBUILD) -M $@ "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
diff --git a/docs/ZH_CN/make.bat b/docs/ZH_CN/make.bat
new file mode 100644
index 0000000000000000000000000000000000000000..dc1312ab09ca6fb0267dee6b28a38e69c253631a
--- /dev/null
+++ b/docs/ZH_CN/make.bat
@@ -0,0 +1,35 @@
+@ECHO OFF
+
+pushd %~dp0
+
+REM Command file for Sphinx documentation
+
+if "%SPHINXBUILD%" == "" (
+ set SPHINXBUILD=sphinx-build
+)
+set SOURCEDIR=source
+set BUILDDIR=build
+
+%SPHINXBUILD% >NUL 2>NUL
+if errorlevel 9009 (
+ echo.
+ echo.The 'sphinx-build' command was not found. Make sure you have Sphinx
+ echo.installed, then set the SPHINXBUILD environment variable to point
+ echo.to the full path of the 'sphinx-build' executable. Alternatively you
+ echo.may add the Sphinx directory to PATH.
+ echo.
+ echo.If you don't have Sphinx installed, grab it from
+ echo.https://www.sphinx-doc.org/
+ exit /b 1
+)
+
+if "%1" == "" goto help
+
+%SPHINXBUILD% -M %1 %SOURCEDIR% %BUILDDIR% %SPHINXOPTS% %O%
+goto end
+
+:help
+%SPHINXBUILD% -M help %SOURCEDIR% %BUILDDIR% %SPHINXOPTS% %O%
+
+:end
+popd
diff --git a/docs/ZH_CN/source/conf.py b/docs/ZH_CN/source/conf.py
new file mode 100644
index 0000000000000000000000000000000000000000..659c3130dff364844704bfed3350f0ff797fd9f0
--- /dev/null
+++ b/docs/ZH_CN/source/conf.py
@@ -0,0 +1,128 @@
+# Configuration file for the Sphinx documentation builder.
+#
+# This file only contains a selection of the most common options. For a full
+# list see the documentation:
+# https://www.sphinx-doc.org/en/master/usage/configuration.html
+
+# -- Path setup --------------------------------------------------------------
+
+# If extensions (or modules to document with autodoc) are in another directory,
+# add these directories to sys.path here. If the directory is relative to the
+# documentation root, use os.path.abspath to make it absolute, like shown here.
+
+import logging
+import os
+import sys
+from typing import List
+
+import sphinxcontrib.redoc
+from sphinx.ext import autodoc
+
+logger = logging.getLogger(__name__)
+sys.path.append(os.path.abspath("../.."))
+
+# -- Project information -----------------------------------------------------
+
+project = "Lightx2v"
+copyright = "2025, Lightx2v Team"
+author = "the Lightx2v Team"
+
+# -- General configuration ---------------------------------------------------
+
+# Add any Sphinx extension module names here, as strings. They can be
+# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom
+# ones.
+extensions = [
+ "sphinx.ext.napoleon",
+ "sphinx.ext.viewcode",
+ "sphinx.ext.intersphinx",
+ "sphinx_copybutton",
+ "sphinx.ext.autodoc",
+ "sphinx.ext.autosummary",
+ "sphinx.ext.mathjax",
+ "myst_parser",
+ "sphinxarg.ext",
+ "sphinxcontrib.redoc",
+ "sphinxcontrib.openapi",
+]
+
+myst_enable_extensions = [
+ "dollarmath",
+ "amsmath",
+]
+
+html_static_path = ["_static"]
+
+# Add any paths that contain templates here, relative to this directory.
+templates_path = ["_templates"]
+
+# List of patterns, relative to source directory, that match files and
+# directories to ignore when looking for source files.
+# This pattern also affects html_static_path and html_extra_path.
+exclude_patterns: List[str] = ["**/*.template.rst"]
+
+# Exclude the prompt "$" when copying code
+copybutton_prompt_text = r"\$ "
+copybutton_prompt_is_regexp = True
+
+# -- Options for HTML output -------------------------------------------------
+
+# The theme to use for HTML and HTML Help pages. See the documentation for
+# a list of builtin themes.
+#
+html_title = project
+html_theme = "sphinx_book_theme"
+# html_theme = 'sphinx_rtd_theme'
+html_logo = "../../../assets/img_lightx2v.png"
+html_theme_options = {
+ "path_to_docs": "docs/ZH_CN/source",
+ "repository_url": "https://github.com/ModelTC/lightx2v",
+ "use_repository_button": True,
+}
+
+# Add any paths that contain custom static files (such as style sheets) here,
+# relative to this directory. They are copied after the builtin static files,
+# so a file named "default.css" will overwrite the builtin "default.css".
+# html_static_path = ['_static']
+
+
+# Generate additional rst documentation here.
+def setup(app):
+ # from docs.source.generate_examples import generate_examples
+ # generate_examples()
+ pass
+
+
+# Mock out external dependencies here.
+autodoc_mock_imports = [
+ "cpuinfo",
+ "torch",
+ "transformers",
+ "psutil",
+ "prometheus_client",
+ "sentencepiece",
+ "lightllmnumpy",
+ "tqdm",
+ "tensorizer",
+]
+
+for mock_target in autodoc_mock_imports:
+ if mock_target in sys.modules:
+ logger.info(
+ "Potentially problematic mock target (%s) found; autodoc_mock_imports cannot mock modules that have already been loaded into sys.modules when the sphinx build starts.",
+ mock_target,
+ )
+
+
+class MockedClassDocumenter(autodoc.ClassDocumenter):
+ """Remove note about base class when a class is derived from object."""
+
+ def add_line(self, line: str, source: str, *lineno: int) -> None:
+ if line == " Bases: :py:class:`object`":
+ return
+ super().add_line(line, source, *lineno)
+
+
+autodoc.ClassDocumenter = MockedClassDocumenter
+
+navigation_with_keys = False
diff --git a/docs/ZH_CN/source/deploy_guides/deploy_comfyui.md b/docs/ZH_CN/source/deploy_guides/deploy_comfyui.md
new file mode 100644
index 0000000000000000000000000000000000000000..9355731c754462092d18b36cc46dca1c0761f8c4
--- /dev/null
+++ b/docs/ZH_CN/source/deploy_guides/deploy_comfyui.md
@@ -0,0 +1,25 @@
+# ComfyUI 部署
+
+## ComfyUI-Lightx2vWrapper
+
+LightX2V 的官方 ComfyUI 集成节点已经发布在独立仓库中,提供了完整的模块化配置系统和优化功能。
+
+### 项目地址
+
+- GitHub: [https://github.com/ModelTC/ComfyUI-Lightx2vWrapper](https://github.com/ModelTC/ComfyUI-Lightx2vWrapper)
+
+### 主要特性
+
+- 模块化配置系统:为视频生成的各个方面提供独立节点
+- 支持文生视频(T2V)和图生视频(I2V)两种生成模式
+- 高级优化功能:
+ - TeaCache 加速(最高 3 倍加速)
+ - 量化支持(int8、fp8)
+ - CPU 卸载内存优化
+ - 轻量级 VAE 选项
+- LoRA 支持:可链式组合多个 LoRA 模型
+- 多模型支持:wan2.1、hunyuan 等架构
+
+### 安装和使用
+
+请访问上述 GitHub 仓库查看详细的安装说明、使用教程和示例工作流。
diff --git a/docs/ZH_CN/source/deploy_guides/deploy_gradio.md b/docs/ZH_CN/source/deploy_guides/deploy_gradio.md
new file mode 100644
index 0000000000000000000000000000000000000000..a2f16b57c8144ace18a01bd7001dddc2a1dc69a5
--- /dev/null
+++ b/docs/ZH_CN/source/deploy_guides/deploy_gradio.md
@@ -0,0 +1,241 @@
+# Gradio 部署指南
+
+## 📖 概述
+
+Lightx2v 是一个轻量级的视频推理和生成引擎,提供基于 Gradio 的 Web 界面,支持图像到视频(Image-to-Video)和文本到视频(Text-to-Video)两种生成模式。
+
+对于Windows系统,我们提供了便捷的一键部署方式,支持自动环境配置和智能参数优化。详细操作请参考[一键启动Gradio](./deploy_local_windows.md/#一键启动gradio推荐)章节。
+
+
+
+## 📁 文件结构
+
+```
+LightX2V/app/
+├── gradio_demo.py # 英文界面演示
+├── gradio_demo_zh.py # 中文界面演示
+├── run_gradio.sh # 启动脚本
+├── README.md # 说明文档
+├── outputs/ # 生成视频保存目录
+└── inference_logs.log # 推理日志
+```
+
+本项目包含两个主要演示文件:
+- `gradio_demo.py` - 英文界面版本
+- `gradio_demo_zh.py` - 中文界面版本
+
+## 🚀 快速开始
+
+### 环境要求
+
+按照[快速开始文档](../getting_started/quickstart.md)安装环境
+
+#### 推荐优化库配置
+
+- ✅ [Flash attention](https://github.com/Dao-AILab/flash-attention)
+- ✅ [Sage attention](https://github.com/thu-ml/SageAttention)
+- ✅ [vllm-kernel](https://github.com/vllm-project/vllm)
+- ✅ [sglang-kernel](https://github.com/sgl-project/sglang/tree/main/sgl-kernel)
+- ✅ [q8-kernel](https://github.com/KONAKONA666/q8_kernels) (仅支持ADA架构的GPU)
+
+可根据需要,按照各算子的项目主页教程进行安装。
+
+### 📥 模型下载
+
+可参考[模型结构文档](../getting_started/model_structure.md)下载完整模型(包含量化和非量化版本)或仅下载量化/非量化版本。
+
+#### wan2.1 模型目录结构
+
+```
+models/
+├── wan2.1_i2v_720p_lightx2v_4step.safetensors # 原始精度
+├── wan2.1_i2v_720p_scaled_fp8_e4m3_lightx2v_4step.safetensors # FP8 量化
+├── wan2.1_i2v_720p_int8_lightx2v_4step.safetensors # INT8 量化
+├── wan2.1_i2v_720p_int8_lightx2v_4step_split # INT8 量化分block存储目录
+├── wan2.1_i2v_720p_scaled_fp8_e4m3_lightx2v_4step_split # FP8 量化分block存储目录
+├── 其他权重(例如t2v)
+├── t5/clip/xlm-roberta-large/google # text和image encoder
+├── vae/lightvae/lighttae # vae
+└── config.json # 模型配置文件
+```
+
+#### wan2.2 模型目录结构
+
+```
+models/
+├── wan2.2_i2v_A14b_high_noise_lightx2v_4step_1030.safetensors # high noise 原始精度
+├── wan2.2_i2v_A14b_high_noise_fp8_e4m3_lightx2v_4step_1030.safetensors # high noise FP8 量化
+├── wan2.2_i2v_A14b_high_noise_int8_lightx2v_4step_1030.safetensors # high noise INT8 量化
+├── wan2.2_i2v_A14b_high_noise_int8_lightx2v_4step_1030_split # high noise INT8 量化分block存储目录
+├── wan2.2_i2v_A14b_low_noise_lightx2v_4step.safetensors # low noise 原始精度
+├── wan2.2_i2v_A14b_low_noise_fp8_e4m3_lightx2v_4step.safetensors # low noise FP8 量化
+├── wan2.2_i2v_A14b_low_noise_int8_lightx2v_4step.safetensors # low noise INT8 量化
+├── wan2.2_i2v_A14b_low_noise_int8_lightx2v_4step_split # low noise INT8 量化分block存储目录
+├── t5/clip/xlm-roberta-large/google # text和image encoder
+├── vae/lightvae/lighttae # vae
+└── config.json # 模型配置文件
+```
+
+**📝 下载说明**:
+
+- 模型权重可从 HuggingFace 下载:
+ - [Wan2.1-Distill-Models](https://huggingface.co/lightx2v/Wan2.1-Distill-Models)
+ - [Wan2.2-Distill-Models](https://huggingface.co/lightx2v/Wan2.2-Distill-Models)
+- Text 和 Image Encoder 可从 [Encoders](https://huggingface.co/lightx2v/Encoders) 下载
+- VAE 可从 [Autoencoders](https://huggingface.co/lightx2v/Autoencoders) 下载
+- 对于 `xxx_split` 目录(例如 `wan2.1_i2v_720p_scaled_fp8_e4m3_lightx2v_4step_split`),即按照 block 存储的多个 safetensors,适用于内存不足的设备。例如内存 16GB 以内,请根据自身情况下载
+
+
+### 启动方式
+
+#### 方式一:使用启动脚本(推荐)
+
+**Linux 环境:**
+```bash
+# 1. 编辑启动脚本,配置相关路径
+cd app/
+vim run_gradio.sh
+
+# 需要修改的配置项:
+# - lightx2v_path: Lightx2v项目根目录路径
+# - model_path: 模型根目录路径(包含所有模型文件)
+
+# 💾 重要提示:建议将模型路径指向SSD存储位置
+# 例如:/mnt/ssd/models/ 或 /data/ssd/models/
+
+# 2. 运行启动脚本
+bash run_gradio.sh
+
+# 3. 或使用参数启动
+bash run_gradio.sh --lang zh --port 8032
+bash run_gradio.sh --lang en --port 7862
+```
+
+**Windows 环境:**
+```cmd
+# 1. 编辑启动脚本,配置相关路径
+cd app\
+notepad run_gradio_win.bat
+
+# 需要修改的配置项:
+# - lightx2v_path: Lightx2v项目根目录路径
+# - model_path: 模型根目录路径(包含所有模型文件)
+
+# 💾 重要提示:建议将模型路径指向SSD存储位置
+# 例如:D:\models\ 或 E:\models\
+
+# 2. 运行启动脚本
+run_gradio_win.bat
+
+# 3. 或使用参数启动
+run_gradio_win.bat --lang zh --port 8032
+run_gradio_win.bat --lang en --port 7862
+```
+
+#### 方式二:直接命令行启动
+
+```bash
+pip install -v git+https://github.com/ModelTC/LightX2V.git
+```
+
+**Linux 环境:**
+
+**中文界面版本:**
+```bash
+python gradio_demo_zh.py \
+ --model_path /path/to/models \
+ --server_name 0.0.0.0 \
+ --server_port 7862
+```
+
+**英文界面版本:**
+```bash
+python gradio_demo.py \
+ --model_path /path/to/models \
+ --server_name 0.0.0.0 \
+ --server_port 7862
+```
+
+**Windows 环境:**
+
+**中文界面版本:**
+```cmd
+python gradio_demo_zh.py ^
+ --model_path D:\models ^
+ --server_name 127.0.0.1 ^
+ --server_port 7862
+```
+
+**英文界面版本:**
+```cmd
+python gradio_demo.py ^
+ --model_path D:\models ^
+ --server_name 127.0.0.1 ^
+ --server_port 7862
+```
+
+**💡 提示**:模型类型(wan2.1/wan2.2)、任务类型(i2v/t2v)以及具体的模型文件选择均在 Web 界面中进行配置。
+
+## 📋 命令行参数
+
+| 参数 | 类型 | 必需 | 默认值 | 说明 |
+|------|------|------|--------|------|
+| `--model_path` | str | ✅ | - | 模型根目录路径(包含所有模型文件的目录) |
+| `--server_port` | int | ❌ | 7862 | 服务器端口 |
+| `--server_name` | str | ❌ | 0.0.0.0 | 服务器IP地址 |
+| `--output_dir` | str | ❌ | ./outputs | 输出视频保存目录 |
+
+**💡 说明**:模型类型(wan2.1/wan2.2)、任务类型(i2v/t2v)以及具体的模型文件选择均在 Web 界面中进行配置。
+
+## 🎯 功能特性
+
+### 模型配置
+
+- **模型类型**: 支持 wan2.1 和 wan2.2 两种模型架构
+- **任务类型**: 支持图像到视频(i2v)和文本到视频(t2v)两种生成模式
+- **模型选择**: 前端自动识别并筛选可用的模型文件,支持自动检测量化精度
+- **编码器配置**: 支持选择 T5 文本编码器、CLIP 图像编码器和 VAE 解码器
+- **算子选择**: 支持多种注意力算子和量化矩阵乘法算子,系统会根据安装状态自动排序
+
+### 输入参数
+
+- **提示词 (Prompt)**: 描述期望的视频内容
+- **负向提示词 (Negative Prompt)**: 指定不希望出现的元素
+- **输入图像**: i2v 模式下需要上传输入图像
+- **分辨率**: 支持多种预设分辨率(480p/540p/720p)
+- **随机种子**: 控制生成结果的随机性
+- **推理步数**: 影响生成质量和速度的平衡(蒸馏模型默认为 4 步)
+
+### 视频参数
+
+- **FPS**: 每秒帧数
+- **总帧数**: 视频长度
+- **CFG缩放因子**: 控制提示词影响强度(1-10,蒸馏模型默认为 1)
+- **分布偏移**: 控制生成风格偏离程度(0-10)
+
+## 🔧 自动配置功能
+
+系统会根据您的硬件配置(GPU 显存和 CPU 内存)自动配置最优推理选项,无需手动调整。启动时会自动应用最佳配置,包括:
+
+- **GPU 内存优化**: 根据显存大小自动启用 CPU 卸载、VAE 分块推理等
+- **CPU 内存优化**: 根据系统内存自动启用延迟加载、模块卸载等
+- **算子选择**: 自动选择已安装的最优算子(按优先级排序)
+- **量化配置**: 根据模型文件名自动检测并应用量化精度
+
+
+### 日志查看
+
+```bash
+# 查看推理日志
+tail -f inference_logs.log
+
+# 查看GPU使用情况
+nvidia-smi
+
+# 查看系统资源
+htop
+```
+
+欢迎提交Issue和Pull Request来改进这个项目!
+
+**注意**: 使用本工具生成的视频内容请遵守相关法律法规,不得用于非法用途。
diff --git a/docs/ZH_CN/source/deploy_guides/deploy_local_windows.md b/docs/ZH_CN/source/deploy_guides/deploy_local_windows.md
new file mode 100644
index 0000000000000000000000000000000000000000..e2baabbe703a7df6fbe68e7f51c140248b7be527
--- /dev/null
+++ b/docs/ZH_CN/source/deploy_guides/deploy_local_windows.md
@@ -0,0 +1,129 @@
+# Windows 本地部署指南
+
+## 📖 概述
+
+本文档将详细指导您在Windows环境下完成LightX2V的本地部署配置,包括批处理文件推理、Gradio Web界面推理等多种使用方式。
+
+## 🚀 快速开始
+
+### 环境要求
+
+#### 硬件要求
+- **GPU**: NVIDIA GPU,建议 8GB+ VRAM
+- **内存**: 建议 16GB+ RAM
+- **存储**: 强烈建议使用 SSD 固态硬盘,机械硬盘会导致模型加载缓慢
+
+## 🎯 使用方式
+
+### 方式一:使用批处理文件推理
+
+参考[快速开始文档](../getting_started/quickstart.md)安装环境,并使用[批处理文件](https://github.com/ModelTC/LightX2V/tree/main/scripts/win)运行。
+
+### 方式二:使用Gradio Web界面推理
+
+#### 手动配置Gradio
+
+参考[快速开始文档](../getting_started/quickstart.md)安装环境,参考[Gradio部署指南](./deploy_gradio.md)
+
+#### 一键启动Gradio(推荐)
+
+**📦 下载软件包**
+- [夸克网盘](https://pan.quark.cn/s/8af1162d7a15)
+
+**📁 目录结构**
+解压后,确保目录结构如下:
+
+```
+├── env/ # LightX2V 环境目录
+├── LightX2V/ # LightX2V 项目目录
+├── start_lightx2v.bat # 一键启动脚本
+├── lightx2v_config.txt # 配置文件
+├── LightX2V使用说明.txt # LightX2V使用说明
+├── outputs/ # 生成的视频保存目录
+└── models/ # 模型存放目录
+```
+
+**📥 下载模型**:
+
+可参考[模型结构文档](../getting_started/model_structure.md)或者[gradio部署文档](./deploy_gradio.md)下载完整模型(包含量化和非量化版本)或仅下载量化/非量化版本。
+
+
+**📋 配置参数**
+
+编辑 `lightx2v_config.txt` 文件,根据需要修改以下参数:
+
+```ini
+
+# 界面语言 (zh: 中文, en: 英文)
+lang=zh
+
+# 服务器端口
+port=8032
+
+# GPU设备ID (0, 1, 2...)
+gpu=0
+
+# 模型路径
+model_path=models/
+```
+
+**🚀 启动服务**
+
+双击运行 `start_lightx2v.bat` 文件,脚本将:
+1. 自动读取配置文件
+2. 验证模型路径和文件完整性
+3. 启动 Gradio Web 界面
+4. 自动打开浏览器访问服务
+
+
+
+
+**⚠️ 重要提示**:
+- **页面显示问题**: 如果网页打开空白或显示异常,请运行 `pip install --upgrade gradio` 升级Gradio版本。
+
+
+### 方式三:使用ComfyUI推理
+
+此说明将指导您如何下载与使用便携版的Lightx2v-ComfyUI环境,如此可以免去手动配置环境的步骤,适用于想要在Windows系统下快速开始体验使用Lightx2v加速视频生成的用户。
+
+#### 下载Windows便携环境:
+
+- [百度网盘下载](https://pan.baidu.com/s/1FVlicTXjmXJA1tAVvNCrBw?pwd=wfid),提取码:wfid
+
+便携环境中已经打包了所有Python运行相关的依赖,也包括ComfyUI和LightX2V的代码及其相关依赖,下载后解压即可使用。
+
+解压后对应的文件目录说明如下:
+
+```shell
+lightx2v_env
+├──📂 ComfyUI # ComfyUI代码
+├──📂 portable_python312_embed # 独立的Python环境
+└── run_nvidia_gpu.bat # Windows启动脚本(双击启动)
+```
+
+#### 启动ComfyUI
+
+直接双击run_nvidia_gpu.bat文件,系统会打开一个Command Prompt窗口并运行程序,一般第一次启动时间会比较久,请耐心等待,启动完成后会自动打开浏览器并出现ComfyUI的前端界面。
+
+
+
+LightX2V-ComfyUI的插件使用的是,[ComfyUI-Lightx2vWrapper](https://github.com/ModelTC/ComfyUI-Lightx2vWrapper),示例工作流可以从此项目中获取。
+
+#### 已测试显卡(offload模式)
+
+- 测试模型`Wan2.1-I2V-14B-480P`
+
+| 显卡型号 | 任务类型 | 显存容量 | 实际最大显存占用 | 实际最大内存占用 |
+|:----------|:-----------|:-----------|:-------- |:---------- |
+| 3090Ti | I2V | 24G | 6.1G | 7.1G |
+| 3080Ti | I2V | 12G | 6.1G | 7.1G |
+| 3060Ti | I2V | 8G | 6.1G | 7.1G |
+| 4070Ti Super | I2V | 16G | 6.1G | 7.1G |
+| 4070 | I2V | 12G | 6.1G | 7.1G |
+| 4060 | I2V | 8G | 6.1G | 7.1G |
+
+
+
+#### 环境打包和使用参考
+- [ComfyUI](https://github.com/comfyanonymous/ComfyUI)
+- [Portable-Windows-ComfyUI-Docs](https://docs.comfy.org/zh-CN/installation/comfyui_portable_windows#portable-%E5%8F%8A%E8%87%AA%E9%83%A8%E7%BD%B2)
diff --git a/docs/ZH_CN/source/deploy_guides/deploy_service.md b/docs/ZH_CN/source/deploy_guides/deploy_service.md
new file mode 100644
index 0000000000000000000000000000000000000000..b0111b32e8186661f862ecd339f0a2e59649b058
--- /dev/null
+++ b/docs/ZH_CN/source/deploy_guides/deploy_service.md
@@ -0,0 +1,88 @@
+# 服务化部署
+
+lightx2v 提供异步服务功能。代码入口点在 [这里](https://github.com/ModelTC/lightx2v/blob/main/lightx2v/api_server.py)
+
+### 启动服务
+
+```shell
+# 修改脚本中的路径
+bash scripts/start_server.sh
+```
+
+`--port 8000` 选项表示服务将绑定到本地机器的 `8000` 端口。您可以根据需要更改此端口。
+
+### 客户端发送请求
+
+```shell
+python scripts/post.py
+```
+
+服务端点:`/v1/tasks/`
+
+`scripts/post.py` 中的 `message` 参数如下:
+
+```python
+message = {
+ "prompt": "Two anthropomorphic cats in comfy boxing gear and bright gloves fight intensely on a spotlighted stage.",
+ "negative_prompt": "镜头晃动,色调艳丽,过曝,静态,细节模糊不清,字幕,风格,作品,画作,画面,静止,整体发灰,最差质量,低质量,JPEG压缩残留,丑陋的,残缺的,多余的手指,画得不好的手部,画得不好的脸部,畸形的,毁容的,形态畸形的肢体,手指融合,静止不动的画面,杂乱的背景,三条腿,背景人很多,倒着走",
+ "image_path": ""
+}
+```
+
+1. `prompt`、`negative_prompt` 和 `image_path` 是视频生成的基本输入。`image_path` 可以是空字符串,表示不需要图像输入。
+
+
+### 客户端检查服务器状态
+
+```shell
+python scripts/check_status.py
+```
+
+服务端点包括:
+
+1. `/v1/service/status` 用于检查服务状态。返回服务是 `busy` 还是 `idle`。服务只有在 `idle` 时才接受新请求。
+
+2. `/v1/tasks/` 用于获取服务器接收和完成的所有任务。
+
+3. `/v1/tasks/{task_id}/status` 用于获取指定 `task_id` 的任务状态。返回任务是 `processing` 还是 `completed`。
+
+### 客户端随时停止服务器上的当前任务
+
+```shell
+python scripts/stop_running_task.py
+```
+
+服务端点:`/v1/tasks/running`
+
+终止任务后,服务器不会退出,而是返回等待新请求的状态。
+
+### 在单个节点上启动多个服务
+
+在单个节点上,您可以使用 `scripts/start_server.sh` 启动多个服务(注意同一 IP 下的端口号必须不同),或者可以使用 `scripts/start_multi_servers.sh` 同时启动多个服务:
+
+```shell
+num_gpus=8 bash scripts/start_multi_servers.sh
+```
+
+其中 `num_gpus` 表示要启动的服务数量;服务将从 `--start_port` 开始在连续端口上运行。
+
+### 多个服务之间的调度
+
+```shell
+python scripts/post_multi_servers.py
+```
+
+`post_multi_servers.py` 将根据服务的空闲状态调度多个客户端请求。
+
+### API 端点总结
+
+| 端点 | 方法 | 描述 |
+|------|------|------|
+| `/v1/tasks/` | POST | 创建视频生成任务 |
+| `/v1/tasks/form` | POST | 通过表单创建视频生成任务 |
+| `/v1/tasks/` | GET | 获取所有任务列表 |
+| `/v1/tasks/{task_id}/status` | GET | 获取指定任务状态 |
+| `/v1/tasks/{task_id}/result` | GET | 获取指定任务的结果视频文件 |
+| `/v1/tasks/running` | DELETE | 停止当前运行的任务 |
+| `/v1/files/download/{file_path}` | GET | 下载文件 |
+| `/v1/service/status` | GET | 获取服务状态 |
diff --git a/docs/ZH_CN/source/deploy_guides/for_low_latency.md b/docs/ZH_CN/source/deploy_guides/for_low_latency.md
new file mode 100644
index 0000000000000000000000000000000000000000..b101f6494a579773cf80ba0e886e42f802357646
--- /dev/null
+++ b/docs/ZH_CN/source/deploy_guides/for_low_latency.md
@@ -0,0 +1,42 @@
+# 低延迟场景部署
+
+在低延迟的场景,我们会追求更快的速度,忽略显存和内存开销等问题。我们提供两套方案:
+
+## 💡 方案一:步数蒸馏模型的推理
+
+该方案可以参考[步数蒸馏文档](https://lightx2v-zhcn.readthedocs.io/zh-cn/latest/method_tutorials/step_distill.html)
+
+🧠 **步数蒸馏**是非常直接的视频生成模型的加速推理方案。从50步蒸馏到4步,耗时将缩短到原来的4/50。同时,该方案下,仍然可以和以下方案结合使用:
+1. [高效注意力机制方案](https://lightx2v-zhcn.readthedocs.io/zh-cn/latest/method_tutorials/attention.html)
+2. [模型量化](https://lightx2v-zhcn.readthedocs.io/zh-cn/latest/method_tutorials/quantization.html)
+
+## 💡 方案二:非步数蒸馏模型的推理
+
+步数蒸馏需要比较大的训练资源,以及步数蒸馏后的模型,可能会出现视频动态范围变差的问题。
+
+对于非步数蒸馏的原始模型,我们可以使用以下方案或者多种方案结合的方式进行加速:
+
+1. [并行推理](https://lightx2v-zhcn.readthedocs.io/zh-cn/latest/method_tutorials/parallel.html) 进行多卡并行加速。
+2. [特征缓存](https://lightx2v-zhcn.readthedocs.io/zh-cn/latest/method_tutorials/cache.html) 降低实际推理步数。
+3. [高效注意力机制方案](https://lightx2v-zhcn.readthedocs.io/zh-cn/latest/method_tutorials/attention.html) 加速 Attention 的推理。
+4. [模型量化](https://lightx2v-zhcn.readthedocs.io/zh-cn/latest/method_tutorials/quantization.html) 加速 Linear 层的推理。
+5. [变分辨率推理](https://lightx2v-zhcn.readthedocs.io/zh-cn/latest/method_tutorials/changing_resolution.html) 降低中间推理步的分辨率。
+
+## 💡 使用Tiny VAE
+
+在某些情况下,VAE部分耗时会比较大,可以使用轻量级VAE进行加速,同时也可以降低一部分显存。
+
+```python
+{
+ "use_tae": true,
+ "tae_path": "/path to taew2_1.pth"
+}
+```
+taew2_1.pth 权重可以从[这里](https://github.com/madebyollin/taehv/raw/refs/heads/main/taew2_1.pth)下载
+
+
+## ⚠️ 注意
+
+有一部分的加速方案之间目前无法结合使用,我们目前正在致力于解决这一问题。
+
+如有问题,欢迎在 [🐛 GitHub Issues](https://github.com/ModelTC/lightx2v/issues) 中进行错误报告或者功能请求
diff --git a/docs/ZH_CN/source/deploy_guides/for_low_resource.md b/docs/ZH_CN/source/deploy_guides/for_low_resource.md
new file mode 100644
index 0000000000000000000000000000000000000000..c5e50dea8edddd5242bfc0c08bfbc1109e867438
--- /dev/null
+++ b/docs/ZH_CN/source/deploy_guides/for_low_resource.md
@@ -0,0 +1,223 @@
+# Lightx2v 低资源部署指南
+
+## 📋 概述
+
+本指南专门针对硬件资源受限的环境,特别是**8GB显存 + 16/32GB内存**的配置,详细说明如何成功运行Lightx2v 14B模型进行480p和720p视频生成。
+
+Lightx2v是一个强大的视频生成模型,但在资源受限的环境下需要精心优化才能流畅运行。本指南将为您提供从硬件选择到软件配置的完整解决方案,确保您能够在有限的硬件条件下获得最佳的视频生成体验。
+
+## 🎯 目标硬件配置详解
+
+### 推荐硬件规格
+
+**GPU要求**:
+- **显存**: 8GB (RTX 3060/3070/4060/4060Ti 等)
+- **架构**: 支持CUDA的NVIDIA显卡
+
+**系统内存**:
+- **最低要求**: 16GB DDR4
+- **推荐配置**: 32GB DDR4/DDR5
+- **内存速度**: 建议3200MHz及以上
+
+**存储要求**:
+- **类型**: 强烈推荐NVMe SSD
+- **容量**: 至少50GB可用空间
+- **速度**: 读取速度建议3000MB/s以上
+
+**CPU要求**:
+- **核心数**: 建议8核心及以上
+- **频率**: 建议3.0GHz及以上
+- **架构**: 支持AVX2指令集
+
+## ⚙️ 核心优化策略详解
+
+### 1. 环境优化
+
+在运行Lightx2v之前,建议设置以下环境变量以优化性能:
+
+```bash
+# CUDA内存分配优化
+export PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True
+
+# 启用CUDA Graph模式,提升推理性能
+export ENABLE_GRAPH_MODE=true
+
+# 使用BF16精度推理,减少显存占用(默认FP32精度)
+export DTYPE=BF16
+```
+
+**优化说明**:
+- `expandable_segments:True`: 允许CUDA内存段动态扩展,减少内存碎片
+- `ENABLE_GRAPH_MODE=true`: 启用CUDA Graph,减少内核启动开销
+- `DTYPE=BF16`: 使用BF16精度,在保持质量的同时减少显存占用
+
+### 2. 量化策略
+
+量化是低资源环境下的关键优化技术,通过降低模型精度来减少内存占用。
+
+#### 量化方案对比
+
+**FP8量化** (推荐用于RTX 40系列):
+```python
+# 适用于支持FP8的GPU,提供更好的精度
+dit_quant_scheme = "fp8" # DIT模型量化
+t5_quant_scheme = "fp8" # T5文本编码器量化
+clip_quant_scheme = "fp8" # CLIP视觉编码器量化
+```
+
+**INT8量化** (通用方案):
+```python
+# 适用于所有GPU,内存占用最小
+dit_quant_scheme = "int8" # 8位整数量化
+t5_quant_scheme = "int8" # 文本编码器量化
+clip_quant_scheme = "int8" # 视觉编码器量化
+```
+### 3. 高效算子选择指南
+
+选择合适的算子可以显著提升推理速度和减少内存占用。
+
+#### 注意力算子选择
+
+**推荐优先级**:
+1. **[Sage Attention](https://github.com/thu-ml/SageAttention)** (最高优先级)
+
+2. **[Flash Attention](https://github.com/Dao-AILab/flash-attention)** (通用方案)
+
+
+#### 矩阵乘算子选择
+
+**ADA架构显卡** (RTX 40系列):
+
+推荐优先级:
+1. **[q8-kernel](https://github.com/KONAKONA666/q8_kernels)** (最高性能,仅支持ADA架构)
+2. **[sglang-kernel](https://github.com/sgl-project/sglang/tree/main/sgl-kernel)** (平衡方案)
+3. **[vllm-kernel](https://github.com/vllm-project/vllm)** (通用方案)
+
+**其他架构显卡**:
+1. **[sglang-kernel](https://github.com/sgl-project/sglang/tree/main/sgl-kernel)** (推荐)
+2. **[vllm-kernel](https://github.com/vllm-project/vllm)** (备选)
+
+### 4. 参数卸载策略详解
+
+参数卸载技术允许模型在CPU和磁盘之间动态调度参数,突破显存限制。
+
+#### 三级卸载架构
+
+```python
+# 磁盘-CPU-GPU三级卸载配置
+cpu_offload=True # 启用CPU卸载
+t5_cpu_offload=True # 启用T5编码器CPU卸载
+offload_granularity=phase # DIT模型细粒度卸载
+t5_offload_granularity=block # T5编码器细粒度卸载
+lazy_load = True # 启用延迟加载机制
+num_disk_workers = 2 # 磁盘I/O工作线程数
+```
+
+#### 卸载策略详解
+
+**延迟加载机制**:
+- 模型参数按需从磁盘加载到CPU
+- 减少运行时内存占用
+- 支持大模型在有限内存下运行
+
+**磁盘存储优化**:
+- 使用高速SSD存储模型参数
+- 按照block分组存储模型文件
+- 参考转换脚本[文档](https://github.com/ModelTC/lightx2v/tree/main/tools/convert/readme_zh.md),转换时指定`--save_by_block`参数
+
+### 5. 显存优化技术详解
+
+针对720p视频生成的显存优化策略。
+
+#### CUDA内存管理
+
+```python
+# CUDA内存清理配置
+clean_cuda_cache = True # 及时清理GPU缓存
+rotary_chunk = True # 旋转位置编码分块计算
+rotary_chunk_size = 100 # 分块大小,可根据显存调整
+```
+
+#### 分块计算策略
+
+**旋转位置编码分块**:
+- 将长序列分成小块处理
+- 减少峰值显存占用
+- 保持计算精度
+
+### 6. VAE优化详解
+
+VAE (变分自编码器) 是视频生成的关键组件,优化VAE可以显著提升性能。
+
+#### VAE分块推理
+
+```python
+# VAE优化配置
+use_tiling_vae = True # 启用VAE分块推理
+```
+
+#### 轻量级VAE
+
+```python
+# VAE优化配置
+use_tae = True
+tae_path = "/path to taew2_1.pth"
+```
+taew2_1.pth 权重可以从[这里](https://github.com/madebyollin/taehv/raw/refs/heads/main/taew2_1.pth)下载
+
+**VAE优化效果**:
+- 标准VAE: 基准性能,100%质量保持
+- 标准VAE分块: 降低显存,增加推理时间,100%质量保持
+- 轻量VAE: 极低显存,视频质量有损
+
+
+### 7. 模型选择策略
+
+选择合适的模型版本对低资源环境至关重要。
+
+#### 推荐模型对比
+
+**蒸馏模型** (强烈推荐):
+- ✅ **[Wan2.1-I2V-14B-480P-StepDistill-CfgDistill-Lightx2v](https://huggingface.co/lightx2v/Wan2.1-I2V-14B-480P-StepDistill-CfgDistill-Lightx2v)**
+
+- ✅ **[Wan2.1-I2V-14B-720P-StepDistill-CfgDistill-Lightx2v](https://huggingface.co/lightx2v/Wan2.1-I2V-14B-720P-StepDistill-CfgDistill-Lightx2v)**
+
+
+#### 性能优化建议
+
+使用上述蒸馏模型时,可以进一步优化性能:
+- 关闭CFG: `"enable_cfg": false`
+- 减少推理步数: `infer_step: 4`
+- 参考配置文件: [config](https://github.com/ModelTC/LightX2V/tree/main/configs/distill)
+
+## 🚀 完整配置示例
+
+### 预配置模板
+
+- **[14B模型480p视频生成配置](https://github.com/ModelTC/lightx2v/tree/main/configs/offload/disk/wan_i2v_phase_lazy_load_480p.json)**
+
+- **[14B模型720p视频生成配置](https://github.com/ModelTC/lightx2v/tree/main/configs/offload/disk/wan_i2v_phase_lazy_load_720p.json)**
+
+- **[1.3B模型720p视频生成配置](https://github.com/ModelTC/LightX2V/tree/main/configs/offload/block/wan_t2v_1_3b.json)**
+ - 1.3B模型推理瓶颈是T5 encoder,配置文件专门针对T5进行优化
+
+**[启动脚本](https://github.com/ModelTC/LightX2V/tree/main/scripts/wan/run_wan_i2v_lazy_load.sh)**
+
+
+## 📚 参考资源
+
+- [参数卸载机制文档](../method_tutorials/offload.md) - 深入了解卸载技术原理
+- [量化技术指南](../method_tutorials/quantization.md) - 量化技术详细说明
+- [Gradio部署指南](deploy_gradio.md) - Gradio部署详细说明
+
+## ⚠️ 重要注意事项
+
+1. **硬件要求**: 确保您的硬件满足最低配置要求
+2. **驱动版本**: 建议使用最新的NVIDIA驱动 (535+)
+3. **CUDA版本**: 确保CUDA版本与PyTorch兼容 (建议CUDA 11.8+)
+4. **存储空间**: 预留足够的磁盘空间用于模型缓存 (至少50GB)
+5. **网络环境**: 首次下载模型需要稳定的网络连接
+6. **环境变量**: 务必设置推荐的环境变量以优化性能
+
+
+**技术支持**: 如遇到问题,请提交Issue到项目仓库。
diff --git a/docs/ZH_CN/source/deploy_guides/lora_deploy.md b/docs/ZH_CN/source/deploy_guides/lora_deploy.md
new file mode 100644
index 0000000000000000000000000000000000000000..c75b71dc88c0d2a7f042ad2d06d77de10295f455
--- /dev/null
+++ b/docs/ZH_CN/source/deploy_guides/lora_deploy.md
@@ -0,0 +1,213 @@
+# LoRA 模型部署与相关工具
+
+LoRA (Low-Rank Adaptation) 是一种高效的模型微调技术,通过低秩矩阵分解显著减少可训练参数数量。LightX2V 全面支持 LoRA 技术,包括 LoRA 推理、LoRA 提取和 LoRA 合并等功能。
+
+## 🎯 LoRA 技术特性
+
+- **灵活部署**:支持动态加载和移除 LoRA 权重
+- **多种格式**:支持多种 LoRA 权重格式和命名约定
+- **工具完善**:提供完整的 LoRA 提取、合并工具链
+
+## 📜 LoRA 推理部署
+
+### 配置文件方式
+
+在配置文件中指定 LoRA 路径:
+
+```json
+{
+ "lora_configs": [
+ {
+ "path": "/path/to/your/lora.safetensors",
+ "strength": 1.0
+ }
+ ]
+}
+```
+
+**配置参数说明:**
+
+- `lora_path`: LoRA 权重文件路径列表,支持多个 LoRA 同时加载
+- `strength_model`: LoRA 强度系数 (alpha),控制 LoRA 对原模型的影响程度
+
+### 命令行方式
+
+直接在命令行中指定 LoRA 路径(仅支持加载单个 LoRA):
+
+```bash
+python -m lightx2v.infer \
+ --model_cls wan2.1 \
+ --task t2v \
+ --model_path /path/to/model \
+ --config_json /path/to/config.json \
+ --lora_path /path/to/your/lora.safetensors \
+ --lora_strength 0.8 \
+ --prompt "Your prompt here"
+```
+
+### 多LoRA配置
+
+要使用多个具有不同强度的LoRA,请在配置JSON文件中指定:
+
+```json
+{
+ "lora_configs": [
+ {
+ "path": "/path/to/first_lora.safetensors",
+ "strength": 0.8
+ },
+ {
+ "path": "/path/to/second_lora.safetensors",
+ "strength": 0.5
+ }
+ ]
+}
+```
+
+### 支持的 LoRA 格式
+
+LightX2V 支持多种 LoRA 权重命名约定:
+
+| 格式类型 | 权重命名 | 说明 |
+|----------|----------|------|
+| **标准 LoRA** | `lora_A.weight`, `lora_B.weight` | 标准的 LoRA 矩阵分解格式 |
+| **Down/Up 格式** | `lora_down.weight`, `lora_up.weight` | 另一种常见的命名约定 |
+| **差值格式** | `diff` | `weight` 权重差值 |
+| **偏置差值** | `diff_b` | `bias` 权重差值 |
+| **调制差值** | `diff_m` | `modulation` 权重差值 |
+
+### 推理脚本示例
+
+**步数蒸馏 LoRA 推理:**
+
+```bash
+# T2V LoRA 推理
+bash scripts/wan/run_wan_t2v_distill_4step_cfg_lora.sh
+
+# I2V LoRA 推理
+bash scripts/wan/run_wan_i2v_distill_4step_cfg_lora.sh
+```
+
+**音频驱动 LoRA 推理:**
+
+```bash
+bash scripts/wan/run_wan_i2v_audio.sh
+```
+
+### API 服务中使用 LoRA
+
+在 API 服务中通过 [config 文件](wan_t2v_distill_4step_cfg_lora.json) 指定,对 [scripts/server/start_server.sh](https://github.com/ModelTC/lightx2v/blob/main/scripts/server/start_server.sh) 中的启动命令进行修改:
+
+```bash
+python -m lightx2v.api_server \
+ --model_cls wan2.1_distill \
+ --task t2v \
+ --model_path $model_path \
+ --config_json ${lightx2v_path}/configs/distill/wan_t2v_distill_4step_cfg_lora.json \
+ --port 8000 \
+ --nproc_per_node 1
+```
+
+## 🔧 LoRA 提取工具
+
+使用 `tools/extract/lora_extractor.py` 从两个模型的差异中提取 LoRA 权重。
+
+### 基本用法
+
+```bash
+python tools/extract/lora_extractor.py \
+ --source-model /path/to/base/model \
+ --target-model /path/to/finetuned/model \
+ --output /path/to/extracted/lora.safetensors \
+ --rank 32
+```
+
+### 参数说明
+
+| 参数 | 类型 | 必需 | 默认值 | 说明 |
+|------|------|------|--------|------|
+| `--source-model` | str | ✅ | - | 基础模型路径 |
+| `--target-model` | str | ✅ | - | 微调后模型路径 |
+| `--output` | str | ✅ | - | 输出 LoRA 文件路径 |
+| `--source-type` | str | ❌ | `safetensors` | 基础模型格式 (`safetensors`/`pytorch`) |
+| `--target-type` | str | ❌ | `safetensors` | 微调模型格式 (`safetensors`/`pytorch`) |
+| `--output-format` | str | ❌ | `safetensors` | 输出格式 (`safetensors`/`pytorch`) |
+| `--rank` | int | ❌ | `32` | LoRA 秩值 |
+| `--output-dtype` | str | ❌ | `bf16` | 输出数据类型 |
+| `--diff-only` | bool | ❌ | `False` | 仅保存权重差值,不进行 LoRA 分解 |
+
+### 高级用法示例
+
+**提取高秩 LoRA:**
+
+```bash
+python tools/extract/lora_extractor.py \
+ --source-model /path/to/base/model \
+ --target-model /path/to/finetuned/model \
+ --output /path/to/high_rank_lora.safetensors \
+ --rank 64 \
+ --output-dtype fp16
+```
+
+**仅保存权重差值:**
+
+```bash
+python tools/extract/lora_extractor.py \
+ --source-model /path/to/base/model \
+ --target-model /path/to/finetuned/model \
+ --output /path/to/weight_diff.safetensors \
+ --diff-only
+```
+
+## 🔀 LoRA 合并工具
+
+使用 `tools/extract/lora_merger.py` 将 LoRA 权重合并到基础模型中,以进行后续量化等操作。
+
+### 基本用法
+
+```bash
+python tools/extract/lora_merger.py \
+ --source-model /path/to/base/model \
+ --lora-model /path/to/lora.safetensors \
+ --output /path/to/merged/model.safetensors \
+ --alpha 1.0
+```
+
+### 参数说明
+
+| 参数 | 类型 | 必需 | 默认值 | 说明 |
+|------|------|------|--------|------|
+| `--source-model` | str | ✅ | 无 | 基础模型路径 |
+| `--lora-model` | str | ✅ | 无 | LoRA 权重路径 |
+| `--output` | str | ✅ | 无 | 输出合并模型路径 |
+| `--source-type` | str | ❌ | `safetensors` | 基础模型格式 |
+| `--lora-type` | str | ❌ | `safetensors` | LoRA 权重格式 |
+| `--output-format` | str | ❌ | `safetensors` | 输出格式 |
+| `--alpha` | float | ❌ | `1.0` | LoRA 合并强度 |
+| `--output-dtype` | str | ❌ | `bf16` | 输出数据类型 |
+
+### 高级用法示例
+
+**部分强度合并:**
+
+```bash
+python tools/extract/lora_merger.py \
+ --source-model /path/to/base/model \
+ --lora-model /path/to/lora.safetensors \
+ --output /path/to/merged_model.safetensors \
+ --alpha 0.7 \
+ --output-dtype fp32
+```
+
+**多格式支持:**
+
+```bash
+python tools/extract/lora_merger.py \
+ --source-model /path/to/base/model.pt \
+ --source-type pytorch \
+ --lora-model /path/to/lora.safetensors \
+ --lora-type safetensors \
+ --output /path/to/merged_model.safetensors \
+ --output-format safetensors \
+ --alpha 1.0
+```
diff --git a/docs/ZH_CN/source/getting_started/benchmark.md b/docs/ZH_CN/source/getting_started/benchmark.md
new file mode 100644
index 0000000000000000000000000000000000000000..6adc116c38878349b9175f2e23c39cc67606c5a8
--- /dev/null
+++ b/docs/ZH_CN/source/getting_started/benchmark.md
@@ -0,0 +1,3 @@
+# 基准测试
+
+由于要展示一些视频的播放效果和详细的性能对比,您可以在这个[🔗 页面](https://github.com/ModelTC/LightX2V/blob/main/docs/ZH_CN/source/getting_started/benchmark_source.md)获得更好的展示效果以及相对应的文档内容。
diff --git a/docs/ZH_CN/source/getting_started/benchmark_source.md b/docs/ZH_CN/source/getting_started/benchmark_source.md
new file mode 100644
index 0000000000000000000000000000000000000000..c399d1837cee6a435b042f30b2af5b870cb53503
--- /dev/null
+++ b/docs/ZH_CN/source/getting_started/benchmark_source.md
@@ -0,0 +1,149 @@
+# 🚀 基准测试
+
+> 本文档展示了LightX2V在不同硬件环境下的性能测试结果,包括H200和RTX 4090平台的详细对比数据。
+
+---
+
+## 🖥️ H200 环境 (~140GB显存)
+
+### 📋 软件环境配置
+
+| 组件 | 版本 |
+|:-----|:-----|
+| **Python** | 3.11 |
+| **PyTorch** | 2.7.1+cu128 |
+| **SageAttention** | 2.2.0 |
+| **vLLM** | 0.9.2 |
+| **sgl-kernel** | 0.1.8 |
+
+---
+
+### 🎬 480P 5s视频测试
+
+**测试配置:**
+- **模型**: [Wan2.1-I2V-14B-480P-Lightx2v](https://huggingface.co/lightx2v/Wan2.1-I2V-14B-480P-Lightx2v)
+- **参数**: `infer_steps=40`, `seed=42`, `enable_cfg=True`
+
+#### 📊 性能对比表
+
+| 配置 | 推理时间(s) | GPU显存占用(GB) | 加速比 | 视频效果 |
+|:-----|:----------:|:---------------:|:------:|:--------:|
+| **Wan2.1 Official** | 366 | 71 | 1.0x | |
+| **FastVideo** | 292 | 26 | **1.25x** | |
+| **LightX2V_1** | 250 | 53 | **1.46x** | |
+| **LightX2V_2** | 216 | 50 | **1.70x** | |
+| **LightX2V_3** | 191 | 35 | **1.92x** | |
+| **LightX2V_3-Distill** | 14 | 35 | **🏆 20.85x** | |
+| **LightX2V_4** | 107 | 35 | **3.41x** | |
+
+---
+
+### 🎬 720P 5s视频测试
+
+**测试配置:**
+- **模型**: [Wan2.1-I2V-14B-720P-Lightx2v](https://huggingface.co/lightx2v/Wan2.1-I2V-14B-720P-Lightx2v)
+- **参数**: `infer_steps=40`, `seed=1234`, `enable_cfg=True`
+
+#### 📊 性能对比表
+
+| 配置 | 推理时间(s) | GPU显存占用(GB) | 加速比 | 视频效果 |
+|:-----|:----------:|:---------------:|:------:|:--------:|
+| **Wan2.1 Official** | 974 | 81 | 1.0x | |
+| **FastVideo** | 914 | 40 | **1.07x** | |
+| **LightX2V_1** | 807 | 65 | **1.21x** | |
+| **LightX2V_2** | 751 | 57 | **1.30x** | |
+| **LightX2V_3** | 671 | 43 | **1.45x** | |
+| **LightX2V_3-Distill** | 44 | 43 | **🏆 22.14x** | |
+| **LightX2V_4** | 344 | 46 | **2.83x** | |
+
+---
+
+## 🖥️ RTX 4090 环境 (~24GB显存)
+
+### 📋 软件环境配置
+
+| 组件 | 版本 |
+|:-----|:-----|
+| **Python** | 3.9.16 |
+| **PyTorch** | 2.5.1+cu124 |
+| **SageAttention** | 2.1.0 |
+| **vLLM** | 0.6.6 |
+| **sgl-kernel** | 0.0.5 |
+| **q8-kernels** | 0.0.0 |
+
+---
+
+### 🎬 480P 5s视频测试
+
+**测试配置:**
+- **模型**: [Wan2.1-I2V-14B-480P-Lightx2v](https://huggingface.co/lightx2v/Wan2.1-I2V-14B-480P-Lightx2v)
+- **参数**: `infer_steps=40`, `seed=42`, `enable_cfg=True`
+
+#### 📊 性能对比表
+
+| 配置 | 推理时间(s) | GPU显存占用(GB) | 加速比 | 视频效果 |
+|:-----|:----------:|:---------------:|:------:|:--------:|
+| **Wan2GP(profile=3)** | 779 | 20 | **1.0x** | |
+| **LightX2V_5** | 738 | 16 | **1.05x** | |
+| **LightX2V_5-Distill** | 68 | 16 | **11.45x** | |
+| **LightX2V_6** | 630 | 12 | **1.24x** | |
+| **LightX2V_6-Distill** | 63 | 12 | **🏆 12.36x** | |
+
+---
+
+### 🎬 720P 5s视频测试
+
+**测试配置:**
+- **模型**: [Wan2.1-I2V-14B-720P-Lightx2v](https://huggingface.co/lightx2v/Wan2.1-I2V-14B-720P-Lightx2v)
+- **参数**: `infer_steps=40`, `seed=1234`, `enable_cfg=True`
+
+#### 📊 性能对比表
+
+| 配置 | 推理时间(s) | GPU显存占用(GB) | 加速比 | 视频效果 |
+|:-----|:----------:|:---------------:|:------:|:--------:|
+| **Wan2GP(profile=3)** | -- | OOM | -- | |
+| **LightX2V_5** | 2473 | 23 | -- | |
+| **LightX2V_5-Distill** | 183 | 23 | -- | |
+| **LightX2V_6** | 2169 | 18 | -- | |
+| **LightX2V_6-Distill** | 171 | 18 | -- | |
+
+---
+
+## 📖 配置说明
+
+### 🖥️ H200 环境配置说明
+
+| 配置 | 技术特点 |
+|:-----|:---------|
+| **Wan2.1 Official** | 基于[Wan2.1官方仓库](https://github.com/Wan-Video/Wan2.1)的原始实现 |
+| **FastVideo** | 基于[FastVideo官方仓库](https://github.com/hao-ai-lab/FastVideo),使用SageAttention2后端优化 |
+| **LightX2V_1** | 使用SageAttention2替换原生注意力机制,采用DIT BF16+FP32(部分敏感层)混合精度计算,在保持精度的同时提升计算效率 |
+| **LightX2V_2** | 统一使用BF16精度计算,进一步减少显存占用和计算开销,同时保持生成质量 |
+| **LightX2V_3** | 引入FP8量化技术显著减少计算精度要求,结合Tiling VAE技术优化显存使用 |
+| **LightX2V_3-Distill** | 在LightX2V_3基础上使用4步蒸馏模型(`infer_steps=4`, `enable_cfg=False`),进一步减少推理步数并保持生成质量 |
+| **LightX2V_4** | 在LightX2V_3基础上加入TeaCache(teacache_thresh=0.2)缓存复用技术,通过智能跳过冗余计算实现加速 |
+
+### 🖥️ RTX 4090 环境配置说明
+
+| 配置 | 技术特点 |
+|:-----|:---------|
+| **Wan2GP(profile=3)** | 基于[Wan2GP仓库](https://github.com/deepbeepmeep/Wan2GP)实现,使用MMGP优化技术。profile=3配置适用于至少32GB内存和24GB显存的RTX 3090/4090环境,通过牺牲显存来适应有限的内存资源。使用量化模型:[480P模型](https://huggingface.co/DeepBeepMeep/Wan2.1/blob/main/wan2.1_image2video_480p_14B_quanto_mbf16_int8.safetensors)和[720P模型](https://huggingface.co/DeepBeepMeep/Wan2.1/blob/main/wan2.1_image2video_720p_14B_quanto_mbf16_int8.safetensors) |
+| **LightX2V_5** | 使用SageAttention2替换原生注意力机制,采用DIT FP8+FP32(部分敏感层)混合精度计算,启用CPU offload技术,将部分敏感层执行FP32精度计算,将DIT推理过程中异步数据卸载到CPU上,节省显存,offload粒度为block级别 |
+| **LightX2V_5-Distill** | 在LightX2V_5基础上使用4步蒸馏模型(`infer_steps=4`, `enable_cfg=False`),进一步减少推理步数并保持生成质量 |
+| **LightX2V_6** | 在LightX2V_3基础上启用CPU offload技术,将部分敏感层执行FP32精度计算,将DIT推理过程中异步数据卸载到CPU上,节省显存,offload粒度为block级别 |
+| **LightX2V_6-Distill** | 在LightX2V_6基础上使用4步蒸馏模型(`infer_steps=4`, `enable_cfg=False`),进一步减少推理步数并保持生成质量 |
+
+---
+
+## 📁 配置文件参考
+
+基准测试相关的配置文件和运行脚本可在以下位置获取:
+
+| 类型 | 链接 | 说明 |
+|:-----|:-----|:-----|
+| **配置文件** | [configs/bench](https://github.com/ModelTC/LightX2V/tree/main/configs/bench) | 包含各种优化配置的JSON文件 |
+| **运行脚本** | [scripts/bench](https://github.com/ModelTC/LightX2V/tree/main/scripts/bench) | 包含基准测试的执行脚本 |
+
+---
+
+> 💡 **提示**: 建议根据您的硬件配置选择合适的优化方案,以获得最佳的性能表现。
diff --git a/docs/ZH_CN/source/getting_started/model_structure.md b/docs/ZH_CN/source/getting_started/model_structure.md
new file mode 100644
index 0000000000000000000000000000000000000000..8ceb48a107ef321c12829b487b2c5b1e9dcd1154
--- /dev/null
+++ b/docs/ZH_CN/source/getting_started/model_structure.md
@@ -0,0 +1,571 @@
+# 模型格式与加载指南
+
+## 📖 概述
+
+LightX2V 是一个灵活的视频生成推理框架,支持多种模型来源和格式,为用户提供丰富的选择:
+
+- ✅ **Wan 官方模型**:直接兼容 Wan2.1 和 Wan2.2 官方发布的完整模型
+- ✅ **单文件模型**:支持 LightX2V 发布的单文件格式模型(包含量化版本)
+- ✅ **LoRA 模型**:支持加载 LightX2V 发布的蒸馏 LoRA
+
+本文档将详细介绍各种模型格式的使用方法、配置参数和最佳实践。
+
+---
+
+## 🗂️ 格式一:Wan 官方模型
+
+### 模型仓库
+- [Wan2.1 Collection](https://huggingface.co/collections/Wan-AI/wan21-68ac4ba85372ae5a8e282a1b)
+- [Wan2.2 Collection](https://huggingface.co/collections/Wan-AI/wan22-68ac4ae80a8b477e79636fc8)
+
+### 模型特点
+- **官方保证**:Wan-AI 官方发布的完整模型,质量最高
+- **完整组件**:包含所有必需的组件(DIT、T5、CLIP、VAE)
+- **原始精度**:使用 BF16/FP32 精度,无量化损失
+- **兼容性强**:与 Wan 官方工具链完全兼容
+
+### Wan2.1 官方模型
+
+#### 目录结构
+
+以 [Wan2.1-I2V-14B-720P](https://huggingface.co/Wan-AI/Wan2.1-I2V-14B-720P) 为例:
+
+```
+Wan2.1-I2V-14B-720P/
+├── diffusion_pytorch_model-00001-of-00007.safetensors # DIT 模型分片 1
+├── diffusion_pytorch_model-00002-of-00007.safetensors # DIT 模型分片 2
+├── diffusion_pytorch_model-00003-of-00007.safetensors # DIT 模型分片 3
+├── diffusion_pytorch_model-00004-of-00007.safetensors # DIT 模型分片 4
+├── diffusion_pytorch_model-00005-of-00007.safetensors # DIT 模型分片 5
+├── diffusion_pytorch_model-00006-of-00007.safetensors # DIT 模型分片 6
+├── diffusion_pytorch_model-00007-of-00007.safetensors # DIT 模型分片 7
+├── diffusion_pytorch_model.safetensors.index.json # 分片索引文件
+├── models_t5_umt5-xxl-enc-bf16.pth # T5 文本编码器
+├── models_clip_open-clip-xlm-roberta-large-vit-huge-14.pth # CLIP 编码器
+├── Wan2.1_VAE.pth # VAE 编解码器
+├── config.json # 模型配置
+├── xlm-roberta-large/ # CLIP tokenizer
+├── google/ # T5 tokenizer
+├── assets/
+└── examples/
+```
+
+#### 使用方法
+
+```bash
+# 下载模型
+huggingface-cli download Wan-AI/Wan2.1-I2V-14B-720P \
+ --local-dir ./models/Wan2.1-I2V-14B-720P
+
+# 配置启动脚本
+model_path=./models/Wan2.1-I2V-14B-720P
+lightx2v_path=/path/to/LightX2V
+
+# 运行推理
+cd LightX2V/scripts
+bash wan/run_wan_i2v.sh
+```
+
+### Wan2.2 官方模型
+
+#### 目录结构
+
+以 [Wan2.2-I2V-A14B](https://huggingface.co/Wan-AI/Wan2.2-I2V-A14B) 为例:
+
+```
+Wan2.2-I2V-A14B/
+├── high_noise_model/ # 高噪声模型目录
+│ ├── diffusion_pytorch_model-00001-of-00009.safetensors
+│ ├── diffusion_pytorch_model-00002-of-00009.safetensors
+│ ├── ...
+│ ├── diffusion_pytorch_model-00009-of-00009.safetensors
+│ └── diffusion_pytorch_model.safetensors.index.json
+├── low_noise_model/ # 低噪声模型目录
+│ ├── diffusion_pytorch_model-00001-of-00009.safetensors
+│ ├── diffusion_pytorch_model-00002-of-00009.safetensors
+│ ├── ...
+│ ├── diffusion_pytorch_model-00009-of-00009.safetensors
+│ └── diffusion_pytorch_model.safetensors.index.json
+├── models_t5_umt5-xxl-enc-bf16.pth # T5 文本编码器
+├── Wan2.1_VAE.pth # VAE 编解码器
+├── configuration.json # 模型配置
+├── google/ # T5 tokenizer
+├── assets/ # 示例资源(可选)
+└── examples/ # 示例文件(可选)
+```
+
+#### 使用方法
+
+```bash
+# 下载模型
+huggingface-cli download Wan-AI/Wan2.2-I2V-A14B \
+ --local-dir ./models/Wan2.2-I2V-A14B
+
+# 配置启动脚本
+model_path=./models/Wan2.2-I2V-A14B
+lightx2v_path=/path/to/LightX2V
+
+# 运行推理
+cd LightX2V/scripts
+bash wan22/run_wan22_moe_i2v.sh
+```
+
+### 可用模型列表
+
+#### Wan2.1 官方模型列表
+
+| 模型名称 | 下载链接 |
+|---------|----------|
+| Wan2.1-I2V-14B-720P | [链接](https://huggingface.co/Wan-AI/Wan2.1-I2V-14B-720P) |
+| Wan2.1-I2V-14B-480P | [链接](https://huggingface.co/Wan-AI/Wan2.1-I2V-14B-480P) |
+| Wan2.1-T2V-14B | [链接](https://huggingface.co/Wan-AI/Wan2.1-T2V-14B) |
+| Wan2.1-T2V-1.3B | [链接](https://huggingface.co/Wan-AI/Wan2.1-T2V-1.3B) |
+| Wan2.1-FLF2V-14B-720P | [链接](https://huggingface.co/Wan-AI/Wan2.1-FLF2V-14B-720P) |
+| Wan2.1-VACE-14B | [链接](https://huggingface.co/Wan-AI/Wan2.1-VACE-14B) |
+| Wan2.1-VACE-1.3B | [链接](https://huggingface.co/Wan-AI/Wan2.1-VACE-1.3B) |
+
+#### Wan2.2 官方模型列表
+
+| 模型名称 | 下载链接 |
+|---------|----------|
+| Wan2.2-I2V-A14B | [链接](https://huggingface.co/Wan-AI/Wan2.2-I2V-A14B) |
+| Wan2.2-T2V-A14B | [链接](https://huggingface.co/Wan-AI/Wan2.2-T2V-A14B) |
+| Wan2.2-TI2V-5B | [链接](https://huggingface.co/Wan-AI/Wan2.2-TI2V-5B) |
+| Wan2.2-Animate-14B | [链接](https://huggingface.co/Wan-AI/Wan2.2-Animate-14B) |
+
+### 使用提示
+
+> 💡 **量化模型使用**:如需使用量化模型,可参考[模型转换脚本](https://github.com/ModelTC/LightX2V/blob/main/tools/convert/readme_zh.md)进行转换,或直接使用下方格式二中的预转换量化模型
+>
+> 💡 **显存优化**:对于 RTX 4090 24GB 或更小显存的设备,建议结合量化技术和 CPU 卸载功能:
+> - 量化配置:参考[量化技术文档](../method_tutorials/quantization.md)
+> - CPU 卸载:参考[参数卸载文档](../method_tutorials/offload.md)
+> - Wan2.1 配置:参考 [offload 配置文件](https://github.com/ModelTC/LightX2V/tree/main/configs/offload)
+> - Wan2.2 配置:参考 [wan22 配置文件](https://github.com/ModelTC/LightX2V/tree/main/configs/wan22) 中以 `4090` 结尾的配置
+
+---
+
+## 🗂️ 格式二:LightX2V 单文件模型(推荐)
+
+### 模型仓库
+- [Wan2.1-LightX2V](https://huggingface.co/lightx2v/Wan2.1-Distill-Models)
+- [Wan2.2-LightX2V](https://huggingface.co/lightx2v/Wan2.2-Distill-Models)
+
+### 模型特点
+- **单文件管理**:单个 safetensors 文件,易于管理和部署
+- **多精度支持**:提供原始精度、FP8、INT8 等多种精度版本
+- **蒸馏加速**:支持 4-step 快速推理
+- **工具兼容**:兼容 ComfyUI 等其他工具
+
+**示例**:
+- `wan2.1_i2v_720p_lightx2v_4step.safetensors` - 720P 图生视频原始精度
+- `wan2.1_i2v_720p_scaled_fp8_e4m3_lightx2v_4step.safetensors` - 720P 图生视频 FP8 量化
+- `wan2.1_i2v_480p_int8_lightx2v_4step.safetensors` - 480P 图生视频 INT8 量化
+- ...
+
+### Wan2.1 单文件模型
+
+#### 场景 A:下载单个模型文件
+
+**步骤 1:选择并下载模型**
+
+```bash
+# 创建模型目录
+mkdir -p ./models/wan2.1_i2v_720p
+
+# 下载 720P 图生视频 FP8 量化模型
+huggingface-cli download lightx2v/Wan2.1-Distill-Models \
+ --local-dir ./models/wan2.1_i2v_720p \
+ --include "wan2.1_i2v_720p_lightx2v_4step.safetensors"
+```
+
+**步骤 2:手动组织其他模块**
+
+目录结构如下
+```
+wan2.1_i2v_720p/
+├── wan2.1_i2v_720p_lightx2v_4step.safetensors # 原始精度
+└── t5/clip/vae/config.json/xlm-roberta-large/google等其他组件 # 需要手动组织
+```
+
+**步骤 3:配置启动脚本**
+
+```bash
+# 在启动脚本中设置(指向包含模型文件的目录)
+model_path=./models/wan2.1_i2v_720p
+lightx2v_path=/path/to/LightX2V
+
+# 运行脚本
+cd LightX2V/scripts
+bash wan/run_wan_i2v_distill_4step_cfg.sh
+```
+
+> 💡 **提示**:当目录下只有一个模型文件时,LightX2V 会自动加载该文件。
+
+#### 场景 B:下载多个模型文件
+
+当您下载了多个不同精度的模型到同一目录时,需要在配置文件中明确指定使用哪个模型。
+
+**步骤 1:下载多个模型**
+
+```bash
+# 创建模型目录
+mkdir -p ./models/wan2.1_i2v_720p_multi
+
+# 下载原始精度模型
+huggingface-cli download lightx2v/Wan2.1-Distill-Models \
+ --local-dir ./models/wan2.1_i2v_720p_multi \
+ --include "wan2.1_i2v_720p_lightx2v_4step.safetensors"
+
+# 下载 FP8 量化模型
+huggingface-cli download lightx2v/Wan2.1-Distill-Models \
+ --local-dir ./models/wan2.1_i2v_720p_multi \
+ --include "wan2.1_i2v_720p_scaled_fp8_e4m3_lightx2v_4step.safetensors"
+
+# 下载 INT8 量化模型
+huggingface-cli download lightx2v/Wan2.1-Distill-Models \
+ --local-dir ./models/wan2.1_i2v_720p_multi \
+ --include "wan2.1_i2v_720p_int8_lightx2v_4step.safetensors"
+```
+
+**步骤 2:手动组织其他模块**
+
+目录结构如下:
+
+```
+wan2.1_i2v_720p_multi/
+├── wan2.1_i2v_720p_lightx2v_4step.safetensors # 原始精度
+├── wan2.1_i2v_720p_scaled_fp8_e4m3_lightx2v_4step.safetensors # FP8 量化
+└── wan2.1_i2v_720p_int8_lightx2v_4step.safetensors # INT8 量化
+└── t5/clip/vae/config.json/xlm-roberta-large/google等其他组件 # 需要手动组织
+```
+
+**步骤 3:在配置文件中指定模型**
+
+编辑配置文件(如 `configs/distill/wan_i2v_distill_4step_cfg.json`):
+
+```json
+{
+ // 使用原始精度模型
+ "dit_original_ckpt": "./models/wan2.1_i2v_720p_multi/wan2.1_i2v_720p_lightx2v_4step.safetensors",
+
+ // 或使用 FP8 量化模型
+ // "dit_quantized_ckpt": "./models/wan2.1_i2v_720p_multi/wan2.1_i2v_720p_scaled_fp8_e4m3_lightx2v_4step.safetensors",
+ // "dit_quantized": true,
+ // "dit_quant_scheme": "fp8-vllm",
+
+ // 或使用 INT8 量化模型
+ // "dit_quantized_ckpt": "./models/wan2.1_i2v_720p_multi/wan2.1_i2v_720p_int8_lightx2v_4step.safetensors",
+ // "dit_quantized": true,
+ // "dit_quant_scheme": "int8-vllm",
+
+ // 其他配置...
+}
+```
+### 使用提示
+
+> 💡 **配置参数说明**:
+> - **dit_original_ckpt**:用于指定原始精度模型(BF16/FP32/FP16)的路径
+> - **dit_quantized_ckpt**:用于指定量化模型(FP8/INT8)的路径,需配合 `dit_quantized` 和 `dit_quant_scheme` 参数使用
+
+**步骤 4:启动推理**
+
+```bash
+cd LightX2V/scripts
+bash wan/run_wan_i2v_distill_4step_cfg.sh
+```
+
+### Wan2.2 单文件模型
+
+#### 目录结构要求
+
+使用 Wan2.2 单文件模型时,需要手动创建特定的目录结构:
+
+```
+wan2.2_models/
+├── high_noise_model/ # 高噪声模型目录(必须)
+│ └── wan2.2_i2v_A14b_high_noise_lightx2v_4step.safetensors # 高噪声模型文件
+└── low_noise_model/ # 低噪声模型目录(必须)
+│ └── wan2.2_i2v_A14b_low_noise_lightx2v_4step.safetensors # 低噪声模型文件
+└── t5/vae/config.json/xlm-roberta-large/google等其他组件 # 需要手动组织
+```
+
+#### 场景 A:每个目录下只有一个模型文件
+
+```bash
+# 创建必需的子目录
+mkdir -p ./models/wan2.2_models/high_noise_model
+mkdir -p ./models/wan2.2_models/low_noise_model
+
+# 下载高噪声模型到对应目录
+huggingface-cli download lightx2v/Wan2.2-Distill-Models \
+ --local-dir ./models/wan2.2_models/high_noise_model \
+ --include "wan2.2_i2v_A14b_high_noise_scaled_fp8_e4m3_lightx2v_4step.safetensors"
+
+# 下载低噪声模型到对应目录
+huggingface-cli download lightx2v/Wan2.2-Distill-Models \
+ --local-dir ./models/wan2.2_models/low_noise_model \
+ --include "wan2.2_i2v_A14b_low_noise_scaled_fp8_e4m3_lightx2v_4step.safetensors"
+
+# 配置启动脚本(指向父目录)
+model_path=./models/wan2.2_models
+lightx2v_path=/path/to/LightX2V
+
+# 运行脚本
+cd LightX2V/scripts
+bash wan22/run_wan22_moe_i2v_distill.sh
+```
+
+> 💡 **提示**:当每个子目录下只有一个模型文件时,LightX2V 会自动加载。
+
+#### 场景 B:每个目录下有多个模型文件
+
+当您在 `high_noise_model/` 和 `low_noise_model/` 目录下分别放置了多个不同精度的模型时,需要在配置文件中明确指定。
+
+```bash
+# 创建目录
+mkdir -p ./models/wan2.2_models_multi/high_noise_model
+mkdir -p ./models/wan2.2_models_multi/low_noise_model
+
+# 下载高噪声模型的多个版本
+huggingface-cli download lightx2v/Wan2.2-Distill-Models \
+ --local-dir ./models/wan2.2_models_multi/high_noise_model \
+ --include "wan2.2_i2v_A14b_high_noise_*.safetensors"
+
+# 下载低噪声模型的多个版本
+huggingface-cli download lightx2v/Wan2.2-Distill-Models \
+ --local-dir ./models/wan2.2_models_multi/low_noise_model \
+ --include "wan2.2_i2v_A14b_low_noise_*.safetensors"
+```
+
+**目录结构**:
+
+```
+wan2.2_models_multi/
+├── high_noise_model/
+│ ├── wan2.2_i2v_A14b_high_noise_lightx2v_4step.safetensors # 原始精度
+│ ├── wan2.2_i2v_A14b_high_noise_fp8_e4m3_lightx2v_4step.safetensors # FP8 量化
+│ └── wan2.2_i2v_A14b_high_noise_int8_lightx2v_4step.safetensors # INT8 量化
+└── low_noise_model/
+│ ├── wan2.2_i2v_A14b_low_noise_lightx2v_4step.safetensors # 原始精度
+│ ├── wan2.2_i2v_A14b_low_noise_fp8_e4m3_lightx2v_4step.safetensors # FP8 量化
+│ └── wan2.2_i2v_A14b_low_noise_int8_lightx2v_4step.safetensors # INT8 量化
+└── t5/vae/config.json/xlm-roberta-large/google等其他组件 # 需要手动组织
+```
+
+**配置文件设置**:
+
+```json
+{
+ // 使用原始精度模型
+ "high_noise_original_ckpt": "./models/wan2.2_models_multi/high_noise_model/wan2.2_i2v_A14b_high_noise_lightx2v_4step.safetensors",
+ "low_noise_original_ckpt": "./models/wan2.2_models_multi/low_noise_model/wan2.2_i2v_A14b_low_noise_lightx2v_4step.safetensors",
+
+ // 或使用 FP8 量化模型
+ // "high_noise_quantized_ckpt": "./models/wan2.2_models_multi/high_noise_model/wan2.2_i2v_A14b_high_noise_fp8_e4m3_lightx2v_4step.safetensors",
+ // "low_noise_quantized_ckpt": "./models/wan2.2_models_multi/low_noise_model/wan2.2_i2v_A14b_low_noise_fp8_e4m3_lightx2v_4step.safetensors",
+ // "dit_quantized": true,
+ // "dit_quant_scheme": "fp8-vllm"
+
+ // 或使用 INT8 量化模型
+ // "high_noise_quantized_ckpt": "./models/wan2.2_models_multi/high_noise_model/wan2.2_i2v_A14b_high_noise_int8_lightx2v_4step.safetensors",
+ // "low_noise_quantized_ckpt": "./models/wan2.2_models_multi/low_noise_model/wan2.2_i2v_A14b_low_noise_int8_lightx2v_4step.safetensors",
+ // "dit_quantized": true,
+ // "dit_quant_scheme": "int8-vllm"
+}
+```
+
+### 使用提示
+
+> 💡 **配置参数说明**:
+> - **high_noise_original_ckpt** / **low_noise_original_ckpt**:用于指定原始精度模型(BF16/FP32/FP16)的路径
+> - **high_noise_quantized_ckpt** / **low_noise_quantized_ckpt**:用于指定量化模型(FP8/INT8)的路径,需配合 `dit_quantized` 和 `dit_quant_scheme` 参数使用
+
+
+### 可用模型列表
+
+#### Wan2.1 单文件模型列表
+
+**图生视频模型(I2V)**
+
+| 文件名 | 精度 | 说明 |
+|--------|------|------|
+| `wan2.1_i2v_480p_lightx2v_4step.safetensors` | BF16 | 4步模型原始精度 |
+| `wan2.1_i2v_480p_scaled_fp8_e4m3_lightx2v_4step.safetensors` | FP8 | 4步模型FP8 量化 |
+| `wan2.1_i2v_480p_int8_lightx2v_4step.safetensors` | INT8 | 4步模型INT8 量化 |
+| `wan2.1_i2v_480p_scaled_fp8_e4m3_lightx2v_4step_comfyui.safetensors` | FP8 | 4步模型ComfyUI 格式 |
+| `wan2.1_i2v_720p_lightx2v_4step.safetensors` | BF16 | 4步模型原始精度 |
+| `wan2.1_i2v_720p_scaled_fp8_e4m3_lightx2v_4step.safetensors` | FP8 | 4步模型FP8 量化 |
+| `wan2.1_i2v_720p_int8_lightx2v_4step.safetensors` | INT8 | 4步模型INT8 量化 |
+| `wan2.1_i2v_720p_scaled_fp8_e4m3_lightx2v_4step_comfyui.safetensors` | FP8 | 4步模型ComfyUI 格式 |
+
+**文生视频模型(T2V)**
+
+| 文件名 | 精度 | 说明 |
+|--------|------|------|
+| `wan2.1_t2v_14b_lightx2v_4step.safetensors` | BF16 | 4步模型原始精度 |
+| `wan2.1_t2v_14b_scaled_fp8_e4m3_lightx2v_4step.safetensors` | FP8 | 4步模型FP8 量化 |
+| `wan2.1_t2v_14b_int8_lightx2v_4step.safetensors` | INT8 | 4步模型INT8 量化 |
+| `wan2.1_t2v_14b_scaled_fp8_e4m3_lightx2v_4step_comfyui.safetensors` | FP8 | 4步模型ComfyUI 格式 |
+
+#### Wan2.2 单文件模型列表
+
+**图生视频模型(I2V)- A14B 系列**
+
+| 文件名 | 精度 | 说明 |
+|--------|------|------|
+| `wan2.2_i2v_A14b_high_noise_lightx2v_4step.safetensors` | BF16 | 高噪声模型-4步原始精度 |
+| `wan2.2_i2v_A14b_high_noise_scaled_fp8_e4m3_lightx2v_4step.safetensors` | FP8 | 高噪声模型-4步FP8量化 |
+| `wan2.2_i2v_A14b_high_noise_int8_lightx2v_4step.safetensors` | INT8 | 高噪声模型-4步INT8量化 |
+| `wan2.2_i2v_A14b_low_noise_lightx2v_4step.safetensors` | BF16 | 低噪声模型-4步原始精度 |
+| `wan2.2_i2v_A14b_low_noise_scaled_fp8_e4m3_lightx2v_4step.safetensors` | FP8 | 低噪声模型-4步FP8量化 |
+| `wan2.2_i2v_A14b_low_noise_int8_lightx2v_4step.safetensors` | INT8 | 低噪声模型-4步INT8量化 |
+
+> 💡 **使用提示**:
+> - Wan2.2 模型采用双噪声架构,需要同时下载高噪声(high_noise)和低噪声(low_noise)模型
+> - 详细的目录组织方式请参考上方"Wan2.2 单文件模型"部分
+
+---
+
+## 🗂️ 格式三:LightX2V LoRA 模型
+
+LoRA(Low-Rank Adaptation)模型提供了一种轻量级的模型微调方案,可以在不修改基础模型的情况下实现特定效果的定制化。
+
+### 模型仓库
+
+- **Wan2.1 LoRA 模型**:[lightx2v/Wan2.1-Distill-Loras](https://huggingface.co/lightx2v/Wan2.1-Distill-Loras)
+- **Wan2.2 LoRA 模型**:[lightx2v/Wan2.2-Distill-Loras](https://huggingface.co/lightx2v/Wan2.2-Distill-Loras)
+
+### 使用方式
+
+#### 方式一:离线合并
+
+将 LoRA 权重离线合并到基础模型中,生成新的完整模型文件。
+
+**操作步骤**:
+
+参考 [模型转换文档](https://github.com/ModelTC/lightx2v/tree/main/tools/convert/readme_zh.md) 进行离线合并。
+
+**优点**:
+- ✅ 推理时无需额外加载 LoRA
+- ✅ 性能更优
+
+**缺点**:
+- ❌ 需要额外存储空间
+- ❌ 切换不同 LoRA 需要重新合并
+
+#### 方式二:在线加载
+
+在推理时动态加载 LoRA 权重,无需修改基础模型。
+
+**LoRA 应用原理**:
+
+```python
+# LoRA 权重应用公式
+# lora_scale = (alpha / rank)
+# W' = W + lora_scale * B @ A
+# 其中:B = up_proj (out_features, rank)
+# A = down_proj (rank, in_features)
+
+if weights_dict["alpha"] is not None:
+ lora_scale = weights_dict["alpha"] / lora_down.shape[0]
+elif alpha is not None:
+ lora_scale = alpha / lora_down.shape[0]
+else:
+ lora_scale = 1.0
+```
+
+**配置方法**:
+
+**Wan2.1 LoRA 配置**:
+
+```json
+{
+ "lora_configs": [
+ {
+ "path": "wan2.1_i2v_lora_rank64_lightx2v_4step.safetensors",
+ "strength": 1.0,
+ "alpha": null
+ }
+ ]
+}
+```
+
+**Wan2.2 LoRA 配置**:
+
+由于 Wan2.2 采用双模型架构(高噪声/低噪声),需要分别为两个模型配置 LoRA:
+
+```json
+{
+ "lora_configs": [
+ {
+ "name": "low_noise_model",
+ "path": "wan2.2_i2v_A14b_low_noise_lora_rank64_lightx2v_4step.safetensors",
+ "strength": 1.0,
+ "alpha": null
+ },
+ {
+ "name": "high_noise_model",
+ "path": "wan2.2_i2v_A14b_high_noise_lora_rank64_lightx2v_4step.safetensors",
+ "strength": 1.0,
+ "alpha": null
+ }
+ ]
+}
+```
+
+**参数说明**:
+
+| 参数 | 说明 | 默认值 |
+|------|------|--------|
+| `path` | LoRA 模型文件路径 | 必填 |
+| `strength` | LoRA 强度系数,范围 [0.0, 1.0] | 1.0 |
+| `alpha` | LoRA 缩放因子,`null` 时使用模型内置值 | null |
+| `name` | (仅 Wan2.2)指定应用到哪个模型 | 必填 |
+
+**优点**:
+- ✅ 灵活切换不同 LoRA
+- ✅ 节省存储空间
+- ✅ 可动态调整 LoRA 强度
+
+**缺点**:
+- ❌ 推理时需额外加载时间
+- ❌ 略微增加显存占用
+
+---
+
+## 📚 相关资源
+
+### 官方仓库
+- [LightX2V GitHub](https://github.com/ModelTC/LightX2V)
+- [LightX2V 单文件模型仓库](https://huggingface.co/lightx2v/Wan2.1-Distill-Models)
+- [Wan-AI 官方模型仓库](https://huggingface.co/Wan-AI)
+
+### 模型下载链接
+
+**Wan2.1 系列**
+- [Wan2.1 Collection](https://huggingface.co/collections/Wan-AI/wan21-68ac4ba85372ae5a8e282a1b)
+
+**Wan2.2 系列**
+- [Wan2.2 Collection](https://huggingface.co/collections/Wan-AI/wan22-68ac4ae80a8b477e79636fc8)
+
+**LightX2V 单文件模型**
+- [Wan2.1-Distill-Models](https://huggingface.co/lightx2v/Wan2.1-Distill-Models)
+- [Wan2.2-Distill-Models](https://huggingface.co/lightx2v/Wan2.2-Distill-Models)
+
+### 文档链接
+- [量化技术文档](../method_tutorials/quantization.md)
+- [参数卸载文档](../method_tutorials/offload.md)
+- [配置文件示例](https://github.com/ModelTC/LightX2V/tree/main/configs)
+
+---
+
+通过本文档,您应该能够:
+
+✅ 理解 LightX2V 支持的所有模型格式
+✅ 根据需求选择合适的模型和精度
+✅ 正确下载和组织模型文件
+✅ 配置启动参数并成功运行推理
+✅ 解决常见的模型加载问题
+
+如有其他问题,欢迎在 [GitHub Issues](https://github.com/ModelTC/LightX2V/issues) 中提问。
diff --git a/docs/ZH_CN/source/getting_started/quickstart.md b/docs/ZH_CN/source/getting_started/quickstart.md
new file mode 100644
index 0000000000000000000000000000000000000000..a62a1939cbc4a1f65169d4a2e11b49b2f70295d0
--- /dev/null
+++ b/docs/ZH_CN/source/getting_started/quickstart.md
@@ -0,0 +1,352 @@
+# LightX2V 快速入门指南
+
+欢迎使用 LightX2V!本指南将帮助您快速搭建环境并开始使用 LightX2V 进行视频生成。
+
+## 📋 目录
+
+- [系统要求](#系统要求)
+- [Linux 系统环境搭建](#linux-系统环境搭建)
+ - [Docker 环境(推荐)](#docker-环境推荐)
+ - [Conda 环境搭建](#conda-环境搭建)
+- [Windows 系统环境搭建](#windows-系统环境搭建)
+- [推理使用](#推理使用)
+
+## 🚀 系统要求
+
+- **操作系统**: Linux (Ubuntu 18.04+) 或 Windows 10/11
+- **Python**: 3.10 或更高版本
+- **GPU**: NVIDIA GPU,支持 CUDA,至少 8GB 显存
+- **内存**: 建议 16GB 或更多
+- **存储**: 至少 50GB 可用空间
+
+## 🐧 Linux 系统环境搭建
+
+### 🐳 Docker 环境(推荐)
+
+我们强烈推荐使用 Docker 环境,这是最简单快捷的安装方式。
+
+#### 1. 拉取镜像
+
+访问 LightX2V 的 [Docker Hub](https://hub.docker.com/r/lightx2v/lightx2v/tags),选择一个最新日期的 tag,比如 `25111101-cu128`:
+
+```bash
+docker pull lightx2v/lightx2v:25111101-cu128
+```
+
+我们推荐使用`cuda128`环境,以获得更快的推理速度,若需要使用`cuda124`环境,可以使用带`-cu124`后缀的镜像版本:
+
+```bash
+docker pull lightx2v/lightx2v:25101501-cu124
+```
+
+#### 2. 运行容器
+
+```bash
+docker run --gpus all -itd --ipc=host --name [容器名] -v [挂载设置] --entrypoint /bin/bash [镜像id]
+```
+
+#### 3. 中国镜像源(可选)
+
+对于中国大陆地区,如果拉取镜像时网络不稳定,可以从阿里云上拉取:
+
+```bash
+# cuda128
+docker pull registry.cn-hangzhou.aliyuncs.com/yongyang/lightx2v:25111101-cu128
+
+# cuda124
+docker pull registry.cn-hangzhou.aliyuncs.com/yongyang/lightx2v:25101501-cu124
+```
+
+### 🐍 Conda 环境搭建
+
+如果您希望使用 Conda 自行搭建环境,请按照以下步骤操作:
+
+#### 步骤 1: 克隆项目
+
+```bash
+# 下载项目代码
+git clone https://github.com/ModelTC/LightX2V.git
+cd LightX2V
+```
+
+#### 步骤 2: 创建 conda 虚拟环境
+
+```bash
+# 创建并激活 conda 环境
+conda create -n lightx2v python=3.11 -y
+conda activate lightx2v
+```
+
+#### 步骤 3: 安装依赖及代码
+
+```bash
+pip install -v -e .
+```
+
+#### 步骤 4: 安装注意力机制算子
+
+**选项 A: Flash Attention 2**
+```bash
+git clone https://github.com/Dao-AILab/flash-attention.git --recursive
+cd flash-attention && python setup.py install
+```
+
+**选项 B: Flash Attention 3(用于 Hopper 架构显卡)**
+```bash
+cd flash-attention/hopper && python setup.py install
+```
+
+**选项 C: SageAttention 2(推荐)**
+```bash
+git clone https://github.com/thu-ml/SageAttention.git
+cd SageAttention && CUDA_ARCHITECTURES="8.0,8.6,8.9,9.0,12.0" EXT_PARALLEL=4 NVCC_APPEND_FLAGS="--threads 8" MAX_JOBS=32 pip install -v -e .
+```
+
+#### 步骤 4: 安装量化算子(可选)
+
+量化算子用于支持模型量化功能,可以显著降低显存占用并加速推理。根据您的需求选择合适的量化算子:
+
+**选项 A: VLLM Kernels(推荐)**
+适用于多种量化方案,支持 FP8 等量化格式。
+
+```bash
+pip install vllm
+```
+
+或者从源码安装以获得最新功能:
+
+```bash
+git clone https://github.com/vllm-project/vllm.git
+cd vllm
+uv pip install -e .
+```
+
+**选项 B: SGL Kernels**
+适用于 SGL 量化方案,需要 torch == 2.8.0。
+
+```bash
+pip install sgl-kernel --upgrade
+```
+
+**选项 C: Q8 Kernels**
+适用于 Ada 架构显卡(如 RTX 4090、L40S 等)。
+
+```bash
+git clone https://github.com/KONAKONA666/q8_kernels.git
+cd q8_kernels && git submodule init && git submodule update
+python setup.py install
+```
+
+> 💡 **提示**:
+> - 如果不需要使用量化功能,可以跳过此步骤
+> - 量化模型可以从 [LightX2V HuggingFace](https://huggingface.co/lightx2v) 下载
+> - 更多量化相关信息请参考 [量化文档](method_tutorials/quantization.html)
+
+#### 步骤 5: 验证安装
+```python
+import lightx2v
+print(f"LightX2V 版本: {lightx2v.__version__}")
+```
+
+## 🪟 Windows 系统环境搭建
+
+Windows 系统仅支持 Conda 环境搭建方式,请按照以下步骤操作:
+
+### 🐍 Conda 环境搭建
+
+#### 步骤 1: 检查 CUDA 版本
+
+首先确认您的 GPU 驱动和 CUDA 版本:
+
+```cmd
+nvidia-smi
+```
+
+记录输出中的 **CUDA Version** 信息,后续安装时需要保持版本一致。
+
+#### 步骤 2: 创建 Python 环境
+
+```cmd
+# 创建新环境(推荐 Python 3.12)
+conda create -n lightx2v python=3.12 -y
+
+# 激活环境
+conda activate lightx2v
+```
+
+> 💡 **提示**: 建议使用 Python 3.10 或更高版本以获得最佳兼容性。
+
+#### 步骤 3: 安装 PyTorch 框架
+
+**方法一:下载官方 wheel 包(推荐)**
+
+1. 访问 [PyTorch 官方下载页面](https://download.pytorch.org/whl/torch/)
+2. 选择对应版本的 wheel 包,注意匹配:
+ - **Python 版本**: 与您的环境一致
+ - **CUDA 版本**: 与您的 GPU 驱动匹配
+ - **平台**: 选择 Windows 版本
+
+**示例(Python 3.12 + PyTorch 2.6 + CUDA 12.4):**
+
+```cmd
+# 下载并安装 PyTorch
+pip install torch-2.6.0+cu124-cp312-cp312-win_amd64.whl
+
+# 安装配套包
+pip install torchvision==0.21.0 torchaudio==2.6.0
+```
+
+**方法二:使用 pip 直接安装**
+
+```cmd
+# CUDA 12.4 版本示例
+pip install torch==2.6.0+cu124 torchvision==0.21.0+cu124 torchaudio==2.6.0+cu124 --index-url https://download.pytorch.org/whl/cu124
+```
+
+#### 步骤 4: 安装 Windows 版 vLLM
+
+从 [vllm-windows releases](https://github.com/SystemPanic/vllm-windows/releases) 下载对应的 wheel 包。
+
+**版本匹配要求:**
+- Python 版本匹配
+- PyTorch 版本匹配
+- CUDA 版本匹配
+
+```cmd
+# 安装 vLLM(请根据实际文件名调整)
+pip install vllm-0.9.1+cu124-cp312-cp312-win_amd64.whl
+```
+
+#### 步骤 5: 安装注意力机制算子
+
+**选项 A: Flash Attention 2**
+
+```cmd
+pip install flash-attn==2.7.2.post1
+```
+
+**选项 B: SageAttention 2(强烈推荐)**
+
+**下载源:**
+- [Windows 专用版本 1](https://github.com/woct0rdho/SageAttention/releases)
+- [Windows 专用版本 2](https://github.com/sdbds/SageAttention-for-windows/releases)
+
+```cmd
+# 安装 SageAttention(请根据实际文件名调整)
+pip install sageattention-2.1.1+cu126torch2.6.0-cp312-cp312-win_amd64.whl
+```
+
+> ⚠️ **注意**: SageAttention 的 CUDA 版本可以不严格对齐,但 Python 和 PyTorch 版本必须匹配。
+
+#### 步骤 6: 克隆项目
+
+```cmd
+# 克隆项目代码
+git clone https://github.com/ModelTC/LightX2V.git
+cd LightX2V
+
+# 安装 Windows 专用依赖
+pip install -r requirements_win.txt
+pip install -v -e .
+```
+
+#### 步骤 7: 安装量化算子(可选)
+
+量化算子用于支持模型量化功能,可以显著降低显存占用并加速推理。
+
+**安装 VLLM(推荐):**
+
+从 [vllm-windows releases](https://github.com/SystemPanic/vllm-windows/releases) 下载对应的 wheel 包并安装。
+
+```cmd
+# 安装 vLLM(请根据实际文件名调整)
+pip install vllm-0.9.1+cu124-cp312-cp312-win_amd64.whl
+```
+
+> 💡 **提示**:
+> - 如果不需要使用量化功能,可以跳过此步骤
+> - 量化模型可以从 [LightX2V HuggingFace](https://huggingface.co/lightx2v) 下载
+> - 更多量化相关信息请参考 [量化文档](method_tutorials/quantization.html)
+
+#### 步骤 8: 验证安装
+```python
+import lightx2v
+print(f"LightX2V 版本: {lightx2v.__version__}")
+```
+
+## 🎯 推理使用
+
+### 📥 模型准备
+
+在开始推理之前,您需要提前下载好模型文件。我们推荐:
+
+- **下载源**: 从 [LightX2V 官方 Hugging Face](https://huggingface.co/lightx2v/)或者其他开源模型库下载模型
+- **存储位置**: 建议将模型存储在 SSD 磁盘上以获得更好的读取性能
+- **可用模型**: 包括 Wan2.1-I2V、Wan2.1-T2V 等多种模型,支持不同分辨率和功能
+
+### 📁 配置文件与脚本
+
+推理会用到的配置文件都在[这里](https://github.com/ModelTC/LightX2V/tree/main/configs),脚本都在[这里](https://github.com/ModelTC/LightX2V/tree/main/scripts)。
+
+需要将下载的模型路径配置到运行脚本中。除了脚本中的输入参数,`--config_json` 指向的配置文件中也会包含一些必要参数,您可以根据需要自行修改。
+
+### 🚀 开始推理
+
+#### Linux 环境
+
+```bash
+# 修改脚本中的路径后运行
+bash scripts/wan/run_wan_t2v.sh
+```
+
+#### Windows 环境
+
+```cmd
+# 使用 Windows 批处理脚本
+scripts\win\run_wan_t2v.bat
+```
+#### Python脚本启动
+
+```python
+from lightx2v import LightX2VPipeline
+
+pipe = LightX2VPipeline(
+ model_path="/path/to/Wan2.1-T2V-14B",
+ model_cls="wan2.1",
+ task="t2v",
+)
+
+pipe.create_generator(
+ attn_mode="sage_attn2",
+ infer_steps=50,
+ height=480, # 720
+ width=832, # 1280
+ num_frames=81,
+ guidance_scale=5.0,
+ sample_shift=5.0,
+)
+
+seed = 42
+prompt = "Two anthropomorphic cats in comfy boxing gear and bright gloves fight intensely on a spotlighted stage."
+negative_prompt = "镜头晃动,色调艳丽,过曝,静态,细节模糊不清,字幕,风格,作品,画作,画面,静止,整体发灰,最差质量,低质量,JPEG压缩残留,丑陋的,残缺的,多余的手指,画得不好的手部,画得不好的脸部,畸形的,毁容的,形态畸形的肢体,手指融合,静止不动的画面,杂乱的背景,三条腿,背景人很多,倒着走"
+save_result_path="/path/to/save_results/output.mp4"
+
+pipe.generate(
+ seed=seed,
+ prompt=prompt,
+ negative_prompt=negative_prompt,
+ save_result_path=save_result_path,
+)
+```
+
+
+## 📞 获取帮助
+
+如果您在安装或使用过程中遇到问题,请:
+
+1. 在 [GitHub Issues](https://github.com/ModelTC/LightX2V/issues) 中搜索相关问题
+2. 提交新的 Issue 描述您的问题
+
+---
+
+🎉 **恭喜!** 现在您已经成功搭建了 LightX2V 环境,可以开始享受视频生成的乐趣了!
diff --git a/docs/ZH_CN/source/index.rst b/docs/ZH_CN/source/index.rst
new file mode 100644
index 0000000000000000000000000000000000000000..3ea4ebd747337c67518da537f3833879d0e4187a
--- /dev/null
+++ b/docs/ZH_CN/source/index.rst
@@ -0,0 +1,68 @@
+欢迎了解 Lightx2v!
+==================
+
+.. figure:: ../../../assets/img_lightx2v.png
+ :width: 80%
+ :align: center
+ :alt: Lightx2v
+ :class: no-scaled-link
+
+.. raw:: html
+
+
+
+
+ LightX2V: 一个轻量级的视频生成推理框架
+
+
+
+LightX2V 是一个轻量级的视频生成推理框架,集成多种先进的视频生成推理技术,统一支持 文本生成视频 (T2V)、图像生成视频 (I2V) 等多种生成任务及模型。X2V 表示将不同的输入模态(X,如文本或图像)转换(to)为视频输出(V)。
+
+GitHub: https://github.com/ModelTC/lightx2v
+
+HuggingFace: https://huggingface.co/lightx2v
+
+文档列表
+-------------
+
+.. toctree::
+ :maxdepth: 1
+ :caption: 快速入门
+
+ 快速入门
+ 模型结构
+ 基准测试
+
+.. toctree::
+ :maxdepth: 1
+ :caption: 方法教程
+
+ 模型量化
+ 特征缓存
+ 注意力机制
+ 参数卸载
+ 并行推理
+ 变分辨率推理
+ 步数蒸馏
+ 自回归蒸馏
+ 视频帧插值
+
+.. toctree::
+ :maxdepth: 1
+ :caption: 部署指南
+
+ 低延迟场景部署
+ 低资源场景部署
+ Lora模型部署
+ 服务化部署
+ Gradio部署
+ ComfyUI部署
+ 本地windows电脑部署
diff --git a/docs/ZH_CN/source/method_tutorials/attention.md b/docs/ZH_CN/source/method_tutorials/attention.md
new file mode 100644
index 0000000000000000000000000000000000000000..06f9570579cdfb4042e3cfdcf6f63329bf4a9554
--- /dev/null
+++ b/docs/ZH_CN/source/method_tutorials/attention.md
@@ -0,0 +1,35 @@
+# 注意力机制
+
+## LightX2V支持的注意力机制
+
+| 名称 | 类型名称 | GitHub 链接 |
+|--------------------|------------------|-------------|
+| Flash Attention 2 | `flash_attn2` | [flash-attention v2](https://github.com/Dao-AILab/flash-attention) |
+| Flash Attention 3 | `flash_attn3` | [flash-attention v3](https://github.com/Dao-AILab/flash-attention) |
+| Sage Attention 2 | `sage_attn2` | [SageAttention](https://github.com/thu-ml/SageAttention) |
+| Radial Attention | `radial_attn` | [Radial Attention](https://github.com/mit-han-lab/radial-attention) |
+| Sparge Attention | `sparge_ckpt` | [Sparge Attention](https://github.com/thu-ml/SpargeAttn) |
+
+---
+
+## 配置示例
+
+注意力机制的config文件在[这里](https://github.com/ModelTC/lightx2v/tree/main/configs/attentions)
+
+通过指定--config_json到具体的config文件,即可以测试不同的注意力机制
+
+比如对于radial_attn,配置如下:
+
+```json
+{
+ "self_attn_1_type": "radial_attn",
+ "cross_attn_1_type": "flash_attn3",
+ "cross_attn_2_type": "flash_attn3"
+}
+```
+
+如需更换为其他类型,只需将对应值替换为上述表格中的类型名称即可。
+
+tips: radial_attn因为稀疏算法原理的限制只能用在self attention
+
+如需进一步定制注意力机制的行为,请参考各注意力库的官方文档或实现代码。
diff --git a/docs/ZH_CN/source/method_tutorials/autoregressive_distill.md b/docs/ZH_CN/source/method_tutorials/autoregressive_distill.md
new file mode 100644
index 0000000000000000000000000000000000000000..19845ce07f44e7b6ea3d15e7255637cc4d13bea4
--- /dev/null
+++ b/docs/ZH_CN/source/method_tutorials/autoregressive_distill.md
@@ -0,0 +1,53 @@
+# 自回归蒸馏
+
+自回归蒸馏是 LightX2V 中的一个技术探索,通过训练蒸馏模型将推理步数从原始的 40-50 步减少到 **8 步**,在实现推理加速的同时能够通过 KV Cache 技术生成无限长视频。
+
+> ⚠️ 警告:目前自回归蒸馏的效果一般,加速效果也没有达到预期,但是可以作为一个长期的研究项目。目前 LightX2V 仅支持 T2V 的自回归模型。
+
+## 🔍 技术原理
+
+自回归蒸馏通过 [CausVid](https://github.com/tianweiy/CausVid) 技术实现。CausVid 针对 1.3B 的自回归模型进行步数蒸馏、CFG蒸馏。LightX2V 在其基础上,进行了一系列扩展:
+
+1. **更大的模型**:支持 14B 模型的自回归蒸馏训练;
+2. **更完整的数据处理流程**:生成 50,000 个提示词-视频对的训练数据集;
+
+具体实现可参考 [CausVid-Plus](https://github.com/GoatWu/CausVid-Plus)。
+
+## 🛠️ 配置文件说明
+
+### 配置文件
+
+在 [configs/causvid/](https://github.com/ModelTC/lightx2v/tree/main/configs/causvid) 目录下提供了配置选项:
+
+| 配置文件 | 模型地址 |
+|----------|------------|
+| [wan_t2v_causvid.json](https://github.com/ModelTC/lightx2v/blob/main/configs/causvid/wan_t2v_causvid.json) | https://huggingface.co/lightx2v/Wan2.1-T2V-14B-CausVid |
+
+### 关键配置参数
+
+```json
+{
+ "enable_cfg": false, // 关闭CFG以提升速度
+ "num_fragments": 3, // 一次生成视频的段数,每段5s
+ "num_frames": 21, // 每段视频的帧数,谨慎修改!
+ "num_frame_per_block": 3, // 每个自回归块的帧数,谨慎修改!
+ "num_blocks": 7, // 每段视频的自回归块数,谨慎修改!
+ "frame_seq_length": 1560, // 每帧的编码长度,谨慎修改!
+ "denoising_step_list": [ // 去噪时间步列表
+ 999, 934, 862, 756, 603, 410, 250, 140, 74
+ ]
+}
+```
+
+## 📜 使用方法
+
+### 模型准备
+
+将下载好的模型(`causal_model.pt` 或者 `causal_model.safetensors`)放到 Wan 模型根目录的 `causvid_models/` 文件夹下即可
+- 对于 T2V:`Wan2.1-T2V-14B/causvid_models/`
+
+### 推理脚本
+
+```bash
+bash scripts/wan/run_wan_t2v_causvid.sh
+```
diff --git a/docs/ZH_CN/source/method_tutorials/cache.md b/docs/ZH_CN/source/method_tutorials/cache.md
new file mode 100644
index 0000000000000000000000000000000000000000..a867119c81d3f779a66105feed3be7df695a2ea5
--- /dev/null
+++ b/docs/ZH_CN/source/method_tutorials/cache.md
@@ -0,0 +1,3 @@
+# 特征缓存
+
+由于要展示一些视频的播放效果,你可以在这个[🔗 页面](https://github.com/ModelTC/LightX2V/blob/main/docs/ZH_CN/source/method_tutorials/cache_source.md)获得更好的展示效果以及相对应的文档内容。
diff --git a/docs/ZH_CN/source/method_tutorials/cache_source.md b/docs/ZH_CN/source/method_tutorials/cache_source.md
new file mode 100644
index 0000000000000000000000000000000000000000..37624af05f9d2ad63a65d071891a62a9911b28d8
--- /dev/null
+++ b/docs/ZH_CN/source/method_tutorials/cache_source.md
@@ -0,0 +1,139 @@
+# 特征缓存
+
+## 缓存加速算法
+- 在扩散模型的推理过程中,缓存复用是一种重要的加速算法。
+- 其核心思想是在部分时间步跳过冗余计算,通过复用历史缓存结果提升推理效率。
+- 算法的关键在于如何决策在哪些时间步进行缓存复用,通常基于模型状态变化或误差阈值动态判断。
+- 在推理过程中,需要缓存如中间特征、残差、注意力输出等关键内容。当进入可复用时间步时,直接利用已缓存的内容,通过泰勒展开等近似方法重构当前输出,从而减少重复计算,实现高效推理。
+
+### TeaCache
+`TeaCache`的核心思想是通过对相邻时间步输入的**相对L1**距离进行累加,当累计距离达到设定阈值时,判定当前时间步不使用缓存复用;相反,当累计距离未达到设定阈值时则使用缓存复用加速推理过程。
+- 具体来说,算法在每一步推理时计算当前输入与上一步输入的相对L1距离,并将其累加。
+- 当累计距离未超过阈值,说明模型状态变化不明显,则直接复用最近一次缓存的内容,跳过部分冗余计算。这样可以显著减少模型的前向计算次数,提高推理速度。
+
+实际效果上,TeaCache 在保证生成质量的前提下,实现了明显的加速。在单卡H200上,加速前后的用时与视频对比如下:
+
+
+
+ |
+ 加速前:58s
+ |
+
+ 加速后:17.9s
+ |
+
+
+ |
+
+ |
+
+
+ |
+
+
+
+
+- 加速比为:**3.24**
+- config:[wan_t2v_1_3b_tea_480p.json](https://github.com/ModelTC/lightx2v/tree/main/configs/caching/teacache/wan_t2v_1_3b_tea_480p.json)
+- 参考论文:[https://arxiv.org/abs/2411.19108](https://arxiv.org/abs/2411.19108)
+
+### TaylorSeer Cache
+`TaylorSeer Cache`的核心在于利用泰勒公式对缓存内容进行再次计算,作为缓存复用时间步的残差补偿。
+- 具体做法是在缓存复用的时间步,不仅简单地复用历史缓存,还通过泰勒展开对当前输出进行近似重构。这样可以在减少计算量的同时,进一步提升输出的准确性。
+- 泰勒展开能够有效捕捉模型状态的微小变化,使得缓存复用带来的误差得到补偿,从而在加速的同时保证生成质量。
+
+`TaylorSeer Cache`适用于对输出精度要求较高的场景,能够在缓存复用的基础上进一步提升模型推理的表现。
+
+
+
+ |
+ 加速前:57.7s
+ |
+
+ 加速后:41.3s
+ |
+
+
+ |
+
+ |
+
+
+ |
+
+
+
+
+- 加速比为:**1.39**
+- config:[wan_t2v_taylorseer](https://github.com/ModelTC/lightx2v/tree/main/configs/caching/taylorseer/wan_t2v_taylorseer.json)
+- 参考论文:[https://arxiv.org/abs/2503.06923](https://arxiv.org/abs/2503.06923)
+
+### AdaCache
+`AdaCache`的核心思想是根据指定block块中的部分缓存内容,动态调整缓存复用的步长。
+- 算法会分析相邻两个时间步在特定 block 内的特征差异,根据差异大小自适应地决定下一个缓存复用的时间步间隔。
+- 当模型状态变化较小时,步长自动加大,减少缓存更新频率;当状态变化较大时,步长缩小,保证输出质量。
+
+这样可以根据实际推理过程中的动态变化,灵活调整缓存策略,实现更高效的加速和更优的生成效果。AdaCache 适合对推理速度和生成质量都有较高要求的应用场景。
+
+
+
+ |
+ 加速前:227s
+ |
+
+ 加速后:83s
+ |
+
+
+ |
+
+ |
+
+
+ |
+
+
+
+
+- 加速比为:**2.73**
+- config:[wan_i2v_ada](https://github.com/ModelTC/lightx2v/tree/main/configs/caching/adacache/wan_i2v_ada.json)
+- 参考论文:[https://arxiv.org/abs/2411.02397](https://arxiv.org/abs/2411.02397)
+
+### CustomCache
+`CustomCache`综合了`TeaCache`和`TaylorSeer Cache`的优势。
+- 它结合了`TeaCache`在缓存决策上的实时性和合理性,通过动态阈值判断何时进行缓存复用.
+- 同时利用`TaylorSeer`的泰勒展开方法对已缓存内容进行利用。
+
+这样不仅能够高效地决定缓存复用的时机,还能最大程度地利用缓存内容,提升输出的准确性和生成质量。实际测试表明,`CustomCache`在多个内容生成任务上,生成的视频质量优于单独使用`TeaCache、TaylorSeer Cache`或`AdaCache`的方案,是目前综合性能最优的缓存加速算法之一。
+
+
+
+ |
+ 加速前:57.9s
+ |
+
+ 加速后:16.6s
+ |
+
+
+ |
+
+ |
+
+
+ |
+
+
+
+
+- 加速比为:**3.49**
+- config:[wan_t2v_custom_1_3b](https://github.com/ModelTC/lightx2v/tree/main/configs/caching/custom/wan_t2v_custom_1_3b.json)
+
+
+## 使用方式
+
+特征缓存的config文件在[这里](https://github.com/ModelTC/lightx2v/tree/main/configs/caching)
+
+通过指定--config_json到具体的config文件,即可以测试不同的cache算法
+
+[这里](https://github.com/ModelTC/lightx2v/tree/main/scripts/cache)有一些运行脚本供使用。
diff --git a/docs/ZH_CN/source/method_tutorials/changing_resolution.md b/docs/ZH_CN/source/method_tutorials/changing_resolution.md
new file mode 100644
index 0000000000000000000000000000000000000000..e4a51490d032bcf556d3ca1cae9f06b7648bbc9d
--- /dev/null
+++ b/docs/ZH_CN/source/method_tutorials/changing_resolution.md
@@ -0,0 +1,68 @@
+# 变分辨率推理
+
+## 概述
+
+变分辨率推理是一种优化去噪过程的技术策略,通过在不同的去噪阶段采用不同的分辨率来提升计算效率并保持生成质量。该方法的核心思想是:在去噪过程的前期使用较低分辨率进行粗略去噪,在后期切换到正常分辨率进行精细化处理。
+
+## 技术原理
+
+### 分阶段去噪策略
+
+变分辨率推理基于以下观察:
+
+- **前期去噪**:主要处理粗糙的噪声和整体结构,不需要过多的细节信息
+- **后期去噪**:专注于细节优化和高频信息恢复,需要完整的分辨率信息
+
+### 分辨率切换机制
+
+1. **低分辨率阶段**(前期)
+ - 将输入降采样到较低分辨率(如原尺寸的0.75)
+ - 执行初始的去噪步骤
+ - 快速移除大部分噪声,建立基本结构
+
+2. **正常分辨率阶段**(后期)
+ - 将第一步的去噪结果上采样回原始分辨率
+ - 继续执行剩余的去噪步骤
+ - 恢复细节信息,完成精细化处理
+
+
+### U型分辨率策略
+
+如果在刚开始的去噪步,降低分辨率,可能会导致最后的生成的视频和正常推理的生成的视频,整体差异偏大。因此可以采用U型的分辨率策略,即最一开始保持几步的原始分辨率,再降低分辨率推理。
+
+## 使用方式
+
+变分辨率推理的config文件在[这里](https://github.com/ModelTC/LightX2V/tree/main/configs/changing_resolution)
+
+通过指定--config_json到具体的config文件,即可以测试变分辨率推理。
+
+可以参考[这里](https://github.com/ModelTC/LightX2V/blob/main/scripts/changing_resolution)的脚本运行。
+
+
+### 举例1:
+```
+{
+ "infer_steps": 50,
+ "changing_resolution": true,
+ "resolution_rate": [0.75],
+ "changing_resolution_steps": [25]
+}
+```
+
+表示总步数为50,1到25步的分辨率为0.75倍原始分辨率,26到最后一步的分辨率为原始分辨率。
+
+### 举例2:
+```
+{
+ "infer_steps": 50,
+ "changing_resolution": true,
+ "resolution_rate": [1.0, 0.75],
+ "changing_resolution_steps": [10, 35]
+}
+```
+
+表示总步数为50,1到10步的分辨率为原始分辨率,11到35步的分辨率为0.75倍原始分辨率,36到最后一步的分辨率为原始分辨率。
+
+通常来说,假设`changing_resolution_steps`为[A, B, C],去噪的起始步为1,总步数为X,则推理会被分成4个部分。
+
+分别是,(0, A], (A, B]. (B, C], (C, X],每个部分是左开右闭集合。
diff --git a/docs/ZH_CN/source/method_tutorials/offload.md b/docs/ZH_CN/source/method_tutorials/offload.md
new file mode 100644
index 0000000000000000000000000000000000000000..2f30f47d8496efb08581bc1bf5fc80dab8c3657b
--- /dev/null
+++ b/docs/ZH_CN/source/method_tutorials/offload.md
@@ -0,0 +1,177 @@
+# 参数卸载
+
+## 📖 概述
+
+Lightx2v 实现了先进的参数卸载机制,专为在有限硬件资源下处理大型模型推理而设计。该系统通过智能管理不同内存层次中的模型权重,提供了优秀的速度-内存平衡。
+
+**核心特性:**
+- **分block/phase卸载**:高效地以block/phase为单位管理模型权重,实现最优内存使用
+ - **Block**:Transformer模型的基本计算单元,包含完整的Transformer层(自注意力、交叉注意力、前馈网络等),是较大的内存管理单位
+ - **Phase**:Block内部的更细粒度计算阶段,包含单个计算组件(如自注意力、交叉注意力、前馈网络等),提供更精细的内存控制
+- **多级存储支持**:GPU → CPU → 磁盘层次结构,配合智能缓存
+- **异步操作**:使用 CUDA 流实现计算和数据传输的重叠
+- **磁盘/NVMe 序列化**:当内存不足时支持二级存储
+
+## 🎯 卸载策略
+
+### 策略一:GPU-CPU 分block/phase卸载
+
+**适用场景**:GPU 显存不足但系统内存充足
+
+**工作原理**:在 GPU 和 CPU 内存之间以block或phase为单位管理模型权重,利用 CUDA 流实现计算和数据传输的重叠。Block包含完整的Transformer层,而Phase则是Block内部的单个计算组件。
+
+
+
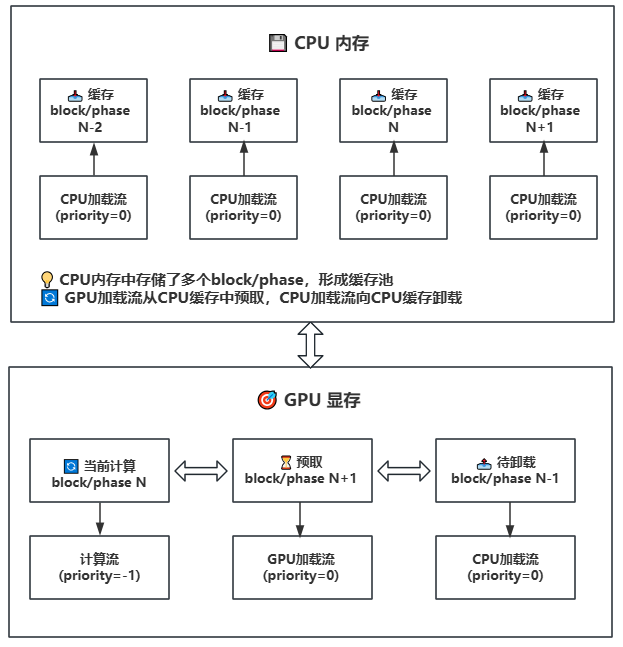
+
+
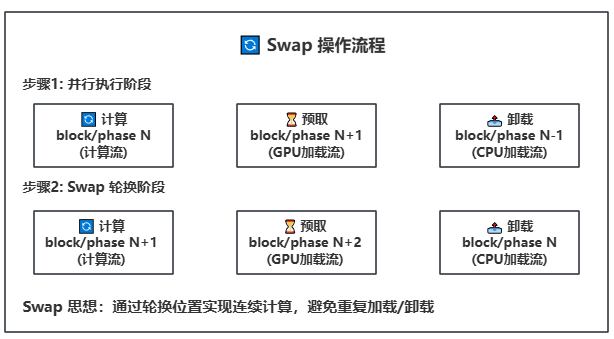
+
+
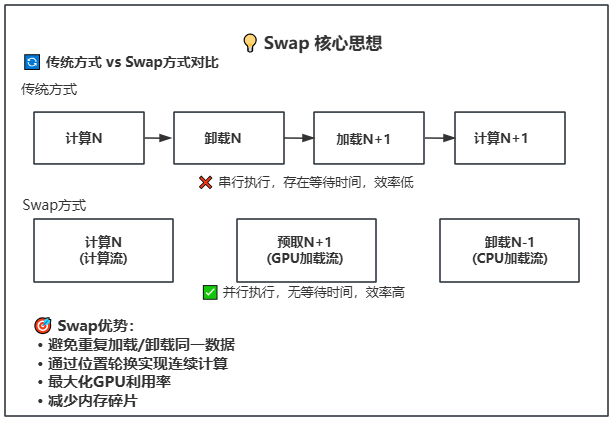
+
+
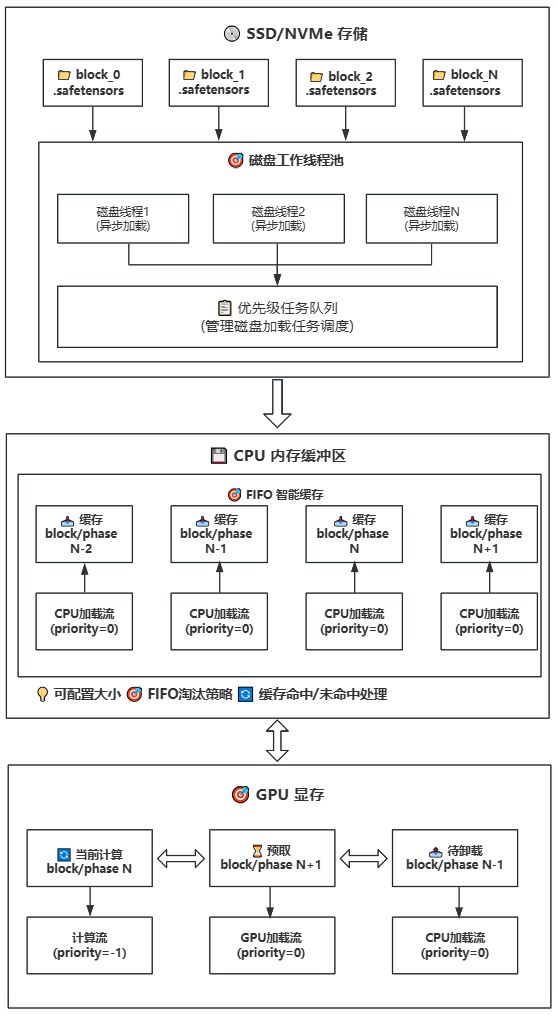
+
+
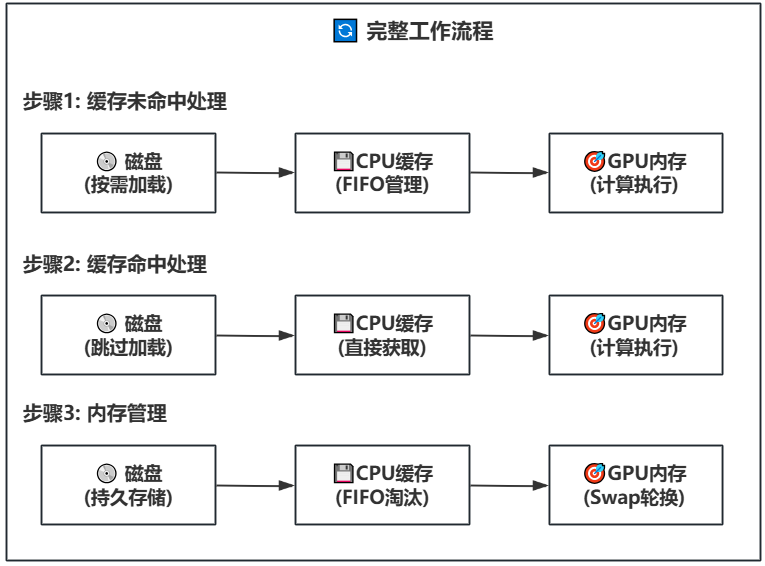
+
+
+
Frontend not found
", status_code=404)
+
+
+# =========================
+# Main Entry
+# =========================
+
+if __name__ == "__main__":
+ ProcessManager.register_signal_handler()
+ parser = argparse.ArgumentParser()
+
+ cur_dir = os.path.dirname(os.path.abspath(__file__))
+ base_dir = os.path.abspath(os.path.join(cur_dir, "../../.."))
+ dft_pipeline_json = os.path.join(base_dir, "configs/model_pipeline.json")
+ dft_task_url = os.path.join(base_dir, "local_task")
+ dft_data_url = os.path.join(base_dir, "local_data")
+ dft_queue_url = os.path.join(base_dir, "local_queue")
+ dft_volcengine_tts_list_json = os.path.join(base_dir, "configs/volcengine_voices_list.json")
+
+ parser.add_argument("--pipeline_json", type=str, default=dft_pipeline_json)
+ parser.add_argument("--task_url", type=str, default=dft_task_url)
+ parser.add_argument("--data_url", type=str, default=dft_data_url)
+ parser.add_argument("--queue_url", type=str, default=dft_queue_url)
+ parser.add_argument("--redis_url", type=str, default="")
+ parser.add_argument("--template_dir", type=str, default="")
+ parser.add_argument("--volcengine_tts_list_json", type=str, default=dft_volcengine_tts_list_json)
+ parser.add_argument("--ip", type=str, default="0.0.0.0")
+ parser.add_argument("--port", type=int, default=8080)
+ parser.add_argument("--face_detector_model_path", type=str, default=None)
+ parser.add_argument("--audio_separator_model_path", type=str, default="")
+ args = parser.parse_args()
+ logger.info(f"args: {args}")
+
+ model_pipelines = Pipeline(args.pipeline_json)
+ volcengine_tts_client = VolcEngineTTSClient(args.volcengine_tts_list_json)
+ volcengine_podcast_client = VolcEnginePodcastClient()
+ face_detector = FaceDetector(model_path=args.face_detector_model_path)
+ audio_separator = AudioSeparator(model_path=args.audio_separator_model_path)
+ auth_manager = AuthManager()
+ if args.task_url.startswith("/"):
+ task_manager = LocalTaskManager(args.task_url, metrics_monitor)
+ elif args.task_url.startswith("postgresql://"):
+ task_manager = PostgresSQLTaskManager(args.task_url, metrics_monitor)
+ else:
+ raise NotImplementedError
+ if args.data_url.startswith("/"):
+ data_manager = LocalDataManager(args.data_url, args.template_dir)
+ elif args.data_url.startswith("{"):
+ data_manager = S3DataManager(args.data_url, args.template_dir)
+ else:
+ raise NotImplementedError
+ if args.queue_url.startswith("/"):
+ queue_manager = LocalQueueManager(args.queue_url)
+ elif args.queue_url.startswith("amqp://"):
+ queue_manager = RabbitMQQueueManager(args.queue_url)
+ else:
+ raise NotImplementedError
+ if args.redis_url:
+ server_monitor = RedisServerMonitor(model_pipelines, task_manager, queue_manager, args.redis_url)
+ else:
+ server_monitor = ServerMonitor(model_pipelines, task_manager, queue_manager)
+
+ uvicorn.run(app, host=args.ip, port=args.port, reload=False, workers=1)
diff --git a/lightx2v/deploy/server/auth.py b/lightx2v/deploy/server/auth.py
new file mode 100644
index 0000000000000000000000000000000000000000..11801257463992bc102bed480314943db147e3eb
--- /dev/null
+++ b/lightx2v/deploy/server/auth.py
@@ -0,0 +1,205 @@
+import os
+import time
+import uuid
+
+import aiohttp
+import jwt
+from fastapi import HTTPException
+from loguru import logger
+
+from lightx2v.deploy.common.aliyun import AlibabaCloudClient
+
+
+class AuthManager:
+ def __init__(self):
+ # Worker access token
+ self.worker_secret_key = os.getenv("WORKER_SECRET_KEY", "worker-secret-key-change-in-production")
+
+ # GitHub OAuth
+ self.github_client_id = os.getenv("GITHUB_CLIENT_ID", "")
+ self.github_client_secret = os.getenv("GITHUB_CLIENT_SECRET", "")
+
+ # Google OAuth
+ self.google_client_id = os.getenv("GOOGLE_CLIENT_ID", "")
+ self.google_client_secret = os.getenv("GOOGLE_CLIENT_SECRET", "")
+ self.google_redirect_uri = os.getenv("GOOGLE_REDIRECT_URI", "")
+
+ self.jwt_algorithm = os.getenv("JWT_ALGORITHM", "HS256")
+ self.jwt_secret_key = os.getenv("JWT_SECRET_KEY", "your-secret-key-change-in-production")
+ self.jwt_expiration_hours = int(os.getenv("JWT_EXPIRATION_HOURS", "168"))
+ self.refresh_token_expiration_days = int(os.getenv("REFRESH_TOKEN_EXPIRATION_DAYS", "30"))
+ self.refresh_jwt_secret_key = os.getenv("REFRESH_JWT_SECRET_KEY", self.jwt_secret_key)
+
+ # Aliyun SMS
+ self.aliyun_client = AlibabaCloudClient()
+
+ logger.info(f"AuthManager: GITHUB_CLIENT_ID: {self.github_client_id}")
+ logger.info(f"AuthManager: GITHUB_CLIENT_SECRET: {self.github_client_secret}")
+ logger.info(f"AuthManager: GOOGLE_CLIENT_ID: {self.google_client_id}")
+ logger.info(f"AuthManager: GOOGLE_CLIENT_SECRET: {self.google_client_secret}")
+ logger.info(f"AuthManager: GOOGLE_REDIRECT_URI: {self.google_redirect_uri}")
+ logger.info(f"AuthManager: JWT_SECRET_KEY: {self.jwt_secret_key}")
+ logger.info(f"AuthManager: WORKER_SECRET_KEY: {self.worker_secret_key}")
+
+ def _create_token(self, data, expires_in_seconds, token_type, secret_key):
+ now = int(time.time())
+ payload = {
+ "user_id": data["user_id"],
+ "username": data["username"],
+ "email": data["email"],
+ "homepage": data["homepage"],
+ "token_type": token_type,
+ "iat": now,
+ "exp": now + expires_in_seconds,
+ "jti": str(uuid.uuid4()),
+ }
+ return jwt.encode(payload, secret_key, algorithm=self.jwt_algorithm)
+
+ def create_access_token(self, data):
+ return self._create_token(data, self.jwt_expiration_hours * 3600, "access", self.jwt_secret_key)
+
+ def create_refresh_token(self, data):
+ return self._create_token(data, self.refresh_token_expiration_days * 24 * 3600, "refresh", self.refresh_jwt_secret_key)
+
+ def create_tokens(self, data):
+ return self.create_access_token(data), self.create_refresh_token(data)
+
+ def create_jwt_token(self, data):
+ # Backwards compatibility for callers that still expect this name
+ return self.create_access_token(data)
+
+ async def auth_github(self, code):
+ try:
+ logger.info(f"GitHub OAuth code: {code}")
+ token_url = "https://github.com/login/oauth/access_token"
+ token_data = {"client_id": self.github_client_id, "client_secret": self.github_client_secret, "code": code}
+ headers = {"Accept": "application/json"}
+
+ proxy = os.getenv("auth_https_proxy", None)
+ if proxy:
+ logger.info(f"auth_github use proxy: {proxy}")
+ async with aiohttp.ClientSession() as session:
+ async with session.post(token_url, data=token_data, headers=headers, proxy=proxy) as response:
+ response.raise_for_status()
+ token_info = await response.json()
+
+ if "error" in token_info:
+ raise HTTPException(status_code=400, detail=f"GitHub OAuth error: {token_info['error']}")
+
+ access_token = token_info.get("access_token")
+ if not access_token:
+ raise HTTPException(status_code=400, detail="Failed to get access token")
+
+ user_url = "https://api.github.com/user"
+ user_headers = {"Authorization": f"token {access_token}", "Accept": "application/vnd.github.v3+json"}
+ async with aiohttp.ClientSession() as session:
+ async with session.get(user_url, headers=user_headers, proxy=proxy) as response:
+ response.raise_for_status()
+ user_info = await response.json()
+
+ return {
+ "source": "github",
+ "id": str(user_info["id"]),
+ "username": user_info["login"],
+ "email": user_info.get("email", ""),
+ "homepage": user_info.get("html_url", ""),
+ "avatar_url": user_info.get("avatar_url", ""),
+ }
+
+ except aiohttp.ClientError as e:
+ logger.error(f"GitHub API request failed: {e}")
+ raise HTTPException(status_code=500, detail="Failed to authenticate with GitHub")
+
+ except Exception as e:
+ logger.error(f"Authentication error: {e}")
+ raise HTTPException(status_code=500, detail="Authentication failed")
+
+ async def auth_google(self, code):
+ try:
+ logger.info(f"Google OAuth code: {code}")
+ token_url = "https://oauth2.googleapis.com/token"
+ token_data = {
+ "client_id": self.google_client_id,
+ "client_secret": self.google_client_secret,
+ "code": code,
+ "redirect_uri": self.google_redirect_uri,
+ "grant_type": "authorization_code",
+ }
+ headers = {"Content-Type": "application/x-www-form-urlencoded"}
+
+ proxy = os.getenv("auth_https_proxy", None)
+ if proxy:
+ logger.info(f"auth_google use proxy: {proxy}")
+ async with aiohttp.ClientSession() as session:
+ async with session.post(token_url, data=token_data, headers=headers, proxy=proxy) as response:
+ response.raise_for_status()
+ token_info = await response.json()
+
+ if "error" in token_info:
+ raise HTTPException(status_code=400, detail=f"Google OAuth error: {token_info['error']}")
+
+ access_token = token_info.get("access_token")
+ if not access_token:
+ raise HTTPException(status_code=400, detail="Failed to get access token")
+
+ # get user info
+ user_url = "https://www.googleapis.com/oauth2/v2/userinfo"
+ user_headers = {"Authorization": f"Bearer {access_token}"}
+ async with aiohttp.ClientSession() as session:
+ async with session.get(user_url, headers=user_headers, proxy=proxy) as response:
+ response.raise_for_status()
+ user_info = await response.json()
+ return {
+ "source": "google",
+ "id": str(user_info["id"]),
+ "username": user_info.get("name", user_info.get("email", "")),
+ "email": user_info.get("email", ""),
+ "homepage": user_info.get("link", ""),
+ "avatar_url": user_info.get("picture", ""),
+ }
+
+ except aiohttp.ClientError as e:
+ logger.error(f"Google API request failed: {e}")
+ raise HTTPException(status_code=500, detail="Failed to authenticate with Google")
+
+ except Exception as e:
+ logger.error(f"Google authentication error: {e}")
+ raise HTTPException(status_code=500, detail="Google authentication failed")
+
+ async def send_sms(self, phone_number):
+ return await self.aliyun_client.send_sms(phone_number)
+
+ async def check_sms(self, phone_number, verify_code):
+ ok = await self.aliyun_client.check_sms(phone_number, verify_code)
+ if not ok:
+ return None
+ return {
+ "source": "phone",
+ "id": phone_number,
+ "username": phone_number,
+ "email": "",
+ "homepage": "",
+ "avatar_url": "",
+ }
+
+ def _verify_token(self, token, expected_type, secret_key):
+ try:
+ payload = jwt.decode(token, secret_key, algorithms=[self.jwt_algorithm])
+ token_type = payload.get("token_type")
+ if token_type and token_type != expected_type:
+ raise HTTPException(status_code=401, detail="Token type mismatch")
+ return payload
+ except jwt.ExpiredSignatureError:
+ raise HTTPException(status_code=401, detail="Token has expired")
+ except Exception as e:
+ logger.error(f"verify_jwt_token error: {e}")
+ raise HTTPException(status_code=401, detail="Could not validate credentials")
+
+ def verify_jwt_token(self, token):
+ return self._verify_token(token, "access", self.jwt_secret_key)
+
+ def verify_refresh_token(self, token):
+ return self._verify_token(token, "refresh", self.refresh_jwt_secret_key)
+
+ def verify_worker_token(self, token):
+ return token == self.worker_secret_key
diff --git a/lightx2v/deploy/server/frontend/.gitignore b/lightx2v/deploy/server/frontend/.gitignore
new file mode 100644
index 0000000000000000000000000000000000000000..a547bf36d8d11a4f89c59c144f24795749086dd1
--- /dev/null
+++ b/lightx2v/deploy/server/frontend/.gitignore
@@ -0,0 +1,24 @@
+# Logs
+logs
+*.log
+npm-debug.log*
+yarn-debug.log*
+yarn-error.log*
+pnpm-debug.log*
+lerna-debug.log*
+
+node_modules
+dist
+dist-ssr
+*.local
+
+# Editor directories and files
+.vscode/*
+!.vscode/extensions.json
+.idea
+.DS_Store
+*.suo
+*.ntvs*
+*.njsproj
+*.sln
+*.sw?
diff --git a/lightx2v/deploy/server/frontend/README.md b/lightx2v/deploy/server/frontend/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..1511959c22b74118c06679739cf9abe2ceeea48c
--- /dev/null
+++ b/lightx2v/deploy/server/frontend/README.md
@@ -0,0 +1,5 @@
+# Vue 3 + Vite
+
+This template should help get you started developing with Vue 3 in Vite. The template uses Vue 3 `
+
+
+
+
+
+
+
+
+ 功能亮点
+
+ - 电影级数字人视频生成
+ - 20倍生成提速
+ - 超低成本生成
+ - 精准口型对齐
+ - 分钟级视频时长
+ - 多场景应用
+ - 最新tts语音合成技术,支持多种语言,支持100+种音色,支持语音指令控制合成语音细节
+
+
+
+ 快速开始
+
+ - 上传图片及音频,输入视频生成提示词,点击开始生成
+ - 生成并下载视频
+ - 应用模版,一键生成同款数字人视频
+
+
+