author={Holger Caesar and Varun Bankiti and Alex H. Lang and Sourabh Vora and Venice Erin Liong and Qiang Xu and Anush Krishnan and Yu Pan and Giancarlo Baldan and Oscar Beijbom},
title={nuScenes: A multimodal dataset for autonomous driving},
journal={arXiv preprint arXiv:1903.11027},
year={2019}
}
@INPROCEEDINGS{Argoverse2,
author={Benjamin Wilson and William Qi and Tanmay Agarwal and John Lambert and Jagjeet Singh and Siddhesh Khandelwal and Bowen Pan and Ratnesh Kumar and Andrew Hartnett and Jhony Kaesemodel Pontes and Deva Ramanan and Peter Carr and James Hays},
title={Argoverse 2: Next Generation Datasets for Self-driving Perception and Forecasting},
booktitle={Proceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks (NeurIPS Datasets and Benchmarks 2021)},
<palign="right">(<ahref="#top">back to top</a>)</p>
## Benchmark and Leaderboard
We will provide an initial benchmark on the OpenLane-V2 dataset, please stay tuned for the release.
Currently, we are maintaining leaderboards on the [*val*](https://paperswithcode.com/sota/3d-lane-detection-on-openlane-v2-2) and [*test*](https://eval.ai/web/challenges/challenge-page/1925/leaderboard/4549) split of `subset_A`.
<palign="right">(<ahref="#top">back to top</a>)</p>
## Highlight - why we are exclusive?
### The world is three-dimensional - Introducing 3D lane
Previous datasets annotate lanes on images in the perspective view. Such a type of 2D annotation is insufficient to fulfill real-world requirements.
Following the [OpenLane](https://github.com/OpenDriveLab/OpenLane) dataset, we annotate **lanes in 3D space** to reflect their properties in the real world.
### Be aware of traffic signals - Recognizing Extremely Small road elements
Not only preventing collision but also facilitating efficiency is essential.
Vehicles follow predefined traffic rules for self-disciplining and cooperating with others to ensure a safe and efficient traffic system.
**Traffic elements** on the roads, such as traffic lights and road signs, provide practical and real-time information.
### Beyond perception - Topology Reasoning between lane and road elements
A traffic element is only valid for its corresponding lanes.
Following the wrong signals would be catastrophic.
Also, lanes have their predecessors and successors to build the map.
Autonomous vehicles are required to **reason** about the **topology relationships** to drive in the right way.
In this dataset, we hope to shed light on the task of **scene structure perception and reasoning**.
### Data scale and diversity matters - building on Top of Awesome Benchmarks
Experience from the sunny day does not apply to the dancing snowflakes.
For machine learning, data is the must-have food.
We provide annotations on data collected in various cities, from Austin to Singapore and from Boston to Miami.
The **diversity** of data enables models to generalize in different atmospheres and landscapes.
<palign="right">(<ahref="#top">back to top</a>)</p>
## Task
The primary task of the dataset is **scene structure perception and reasoning**, which requires the model to recognize the dynamic drivable states of lanes in the surrounding environment.
The challenge of this dataset includes not only detecting lane centerlines and traffic elements but also recognizing the attribute of traffic elements and topology relationships on detected objects.
We define the **[OpenLane-V2 Score (OLS)](./docs/metrics.md#openlane-v2-score)**, which is the average of various metrics covering different aspects of the primary task:
The metrics of different subtasks are described below.
### 3D Lane Detection 🛣️
The [OpenLane](https://github.com/OpenDriveLab/OpenLane) dataset, which is the first real-world and the largest scaled 3D lane dataset to date, provides lane line annotations in 3D space.
Similarly, we annotate 3D lane centerlines and include the F-Score for evaluating predicted results of undirected lane centerlines.
Furthermore, we define the subtask of 3D lane detection as detecting directed 3D lane centerlines from the given multi-view images covering the whole horizontal FOV.
The instance-level evaluation metric of average precision $\text{DET}_{l}$ is utilized to measure the detection performance on lane centerlines (l).
<palign="center">
<imgsrc="./imgs/lane.gif"width="696px">
</p>
### Traffic Element Recognition 🚥
Traffic elements and their attribute provide crucial information for autonomous vehicles.
The attribute represents the semantic meaning of a traffic element, such as the red color of a traffic light.
In this subtask, on the given image in the front view, the location of traffic elements (traffic lights and road signs) and their attributes are demanded to be perceived simultaneously.
Compared to typical 2D detection datasets, the challenge is that the size of traffic elements is tiny due to the large scale of outdoor environments.
Similar to the typical 2D detection task, the metric of $\text{DET}_{t}$ is utilized to measure the performance of traffic elements (t) detection averaged over different attributes.
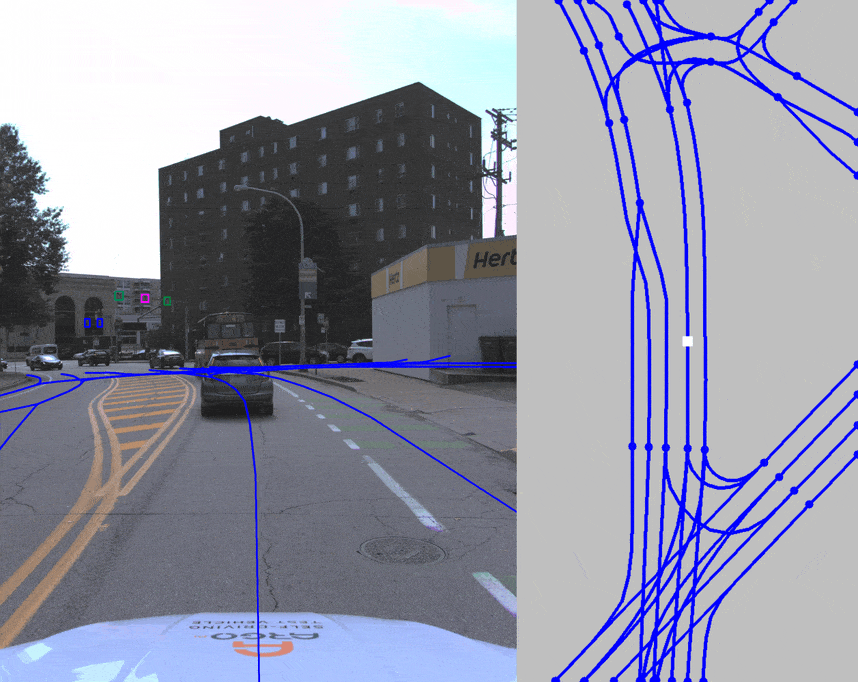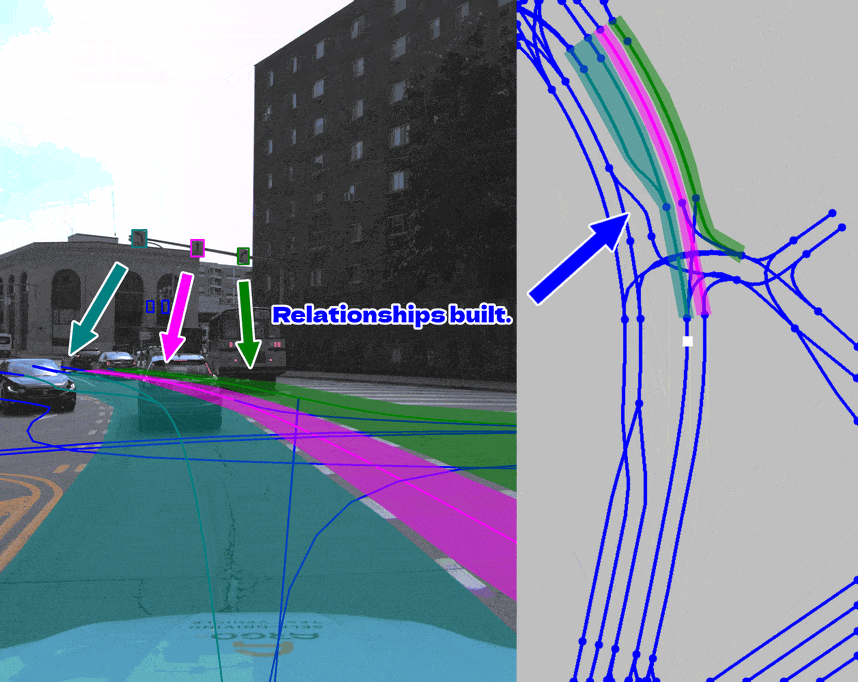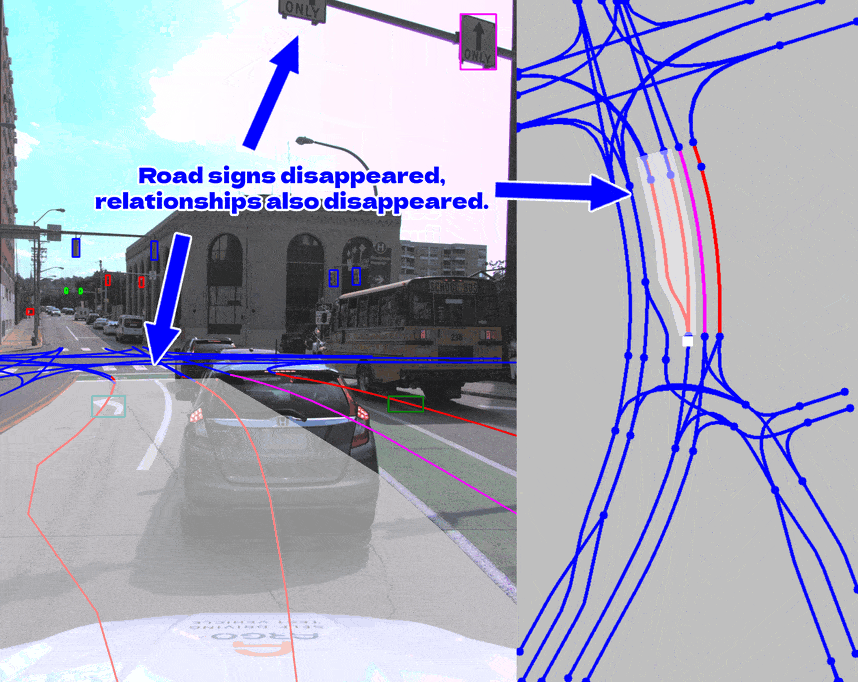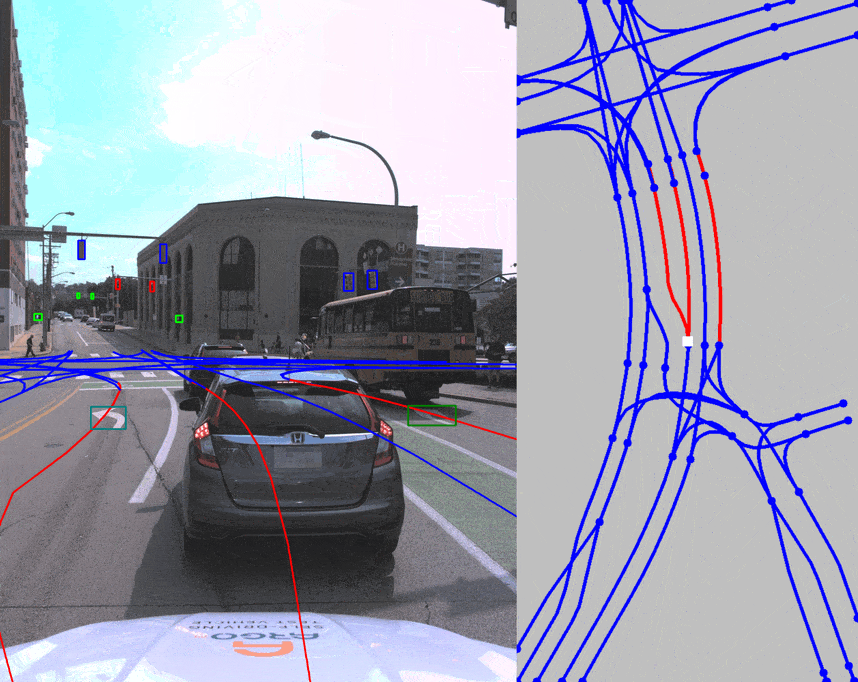
We first define the task of recognizing topology relationships in the field of autonomous driving.
Given multi-view images, the model learns to recognize the topology relationships among lane centerlines and between lane centerlines and traffic elements.
The most similar task is link prediction in the field of graph, in which the vertices are given and only edges are predicted by models.
In our case, both vertices and edges are unknown for the model.
Thus, lane centerlines and traffic elements are needed to be detected first, and then the topology relationships are built.
Adapted from the task of link prediction, $\text{TOP}$ is used for topology among lane centerlines (ll) and between lane centerlines and traffic elements (lt).
<palign="center">
<imgsrc="./imgs/topology.gif"width="696px">
</p>
<palign="right">(<ahref="#top">back to top</a>)</p>
## Data
The OpenLane-V2 dataset is a large-scale dataset for scene structure perception and reasoning in the field of autonomous driving.
Following [OpenLane](https://github.com/OpenDriveLab/OpenLane), the first 3D lane dataset, we provide lane annotations in 3D space.
The difference is that instead of lane lines, we annotate lane centerlines, which can be served as the trajectory for autonomous vehicles.
Besides, we provide annotations on traffic elements (traffic lights and road signs) and their attribute, and the topology relationships among lane centerlines and between lane centerlines and traffic elements.
The dataset is divided into two subsets.
**The `subset_A` serves as the primary subset and is utilized for the coming challenges and leaderboard, in which no external data, including the other subset, is allowed**.
The `subset_B` can be used to test the generalization ability of the model.
For more details, please refer to the corresponding pages: [use of data](./data/README.md), [notes of annotation](./docs/annotation.md), and [dataset statistics](./docs/statistics.md).
[Download](./data/README.md#download) now to discover our dataset!
<palign="right">(<ahref="#top">back to top</a>)</p>
## Devkit
We provide a devkit for easy access to the OpenLane-V2 dataset.
After installing the package, the use of the dataset, such as loading images, loading meta data, and evaluating results, can be accessed through the API of `openlanv2`.
For more details on the API, please refer to [devkit](./docs/devkit.md).
<palign="right">(<ahref="#top">back to top</a>)</p>
## Get Started
Please follow the steps below to get familiar with the OpenLane-V2 dataset.
1. Run the following commands to install the environment for setting up the dataset:
3. Run the [tutorial](./tutorial.ipynb) on jupyter notebook to get familiar with the dataset and devkit.
<palign="right">(<ahref="#top">back to top</a>)</p>
## Train a Model
Plug-ins to prevail deep learning frameworks for training models are provided to start training models on the OpenLane-V2 dataset.
We appreciate your valuable feedback and contributions to plug-ins on different frameworks.
### mmdet3d
The [plug-in](./plugin/mmdet3d/) to MMDetection3d is built on top of [mmdet3d v1.0.0rc6](https://github.com/open-mmlab/mmdetection3d/tree/v1.0.0rc6) and tested under:
- Python 3.8.15
- PyTorch 1.9.1
- CUDA 11.1
- GCC 5.4.0
- mmcv-full==1.5.2
- mmdet==2.26.0
- mmsegmentation==0.29.1
Please follow the [instruction](https://github.com/open-mmlab/mmdetection3d/blob/v1.0.0rc6/docs/en/getting_started.md) to install mmdet3d.
Assuming OpenLane-V2 is installed under `OpenLane-V2/` and mmdet3d is built under `mmdetection3d/`, create a soft link to the plug-in file:
```
└── mmdetection3d
└── projects
├── example_project
└── openlanev2 -> OpenLane-V2/plugin/mmdet3d
```
Then you can train or evaluate a model using the config `mmdetection3d/projects/openlanev2/configs/baseline.py`, whose path is replaced accordingly.
Options can be passed to enable supported functions during evaluation, such as `--eval-options dump=True dump_dir=/PATH/TO/DUMP` to save pickle file for submission and `--eval-options visualization=True visualization_dir=/PATH/TO/VIS` for visualization.
<palign="right">(<ahref="#top">back to top</a>)</p>
## Citation
Please use the following citation when referencing OpenLane-V2:
```bibtex
@misc{openlanev2_dataset,
author={{OpenLane-V2 Dataset Contributors}},
title={{OpenLane-V2: The World's First Perception and Reasoning Benchmark for Scene Structure in Autonomous Driving}},
<palign="right">(<ahref="#top">back to top</a>)</p>
## License
Our dataset is built on top of the [nuScenes](https://www.nuscenes.org/nuscenes) and [Argoverse 2](https://www.argoverse.org/av2.html) datasets.
Before using the OpenLane-V2 dataset, you should agree to the terms of use of the [nuScenes](https://www.nuscenes.org/nuscenes) and [Argoverse 2](https://www.argoverse.org/av2.html) datasets respectively.
All code within this repository is under [Apache License 2.0](./LICENSE).
<palign="right">(<ahref="#top">back to top</a>)</p>
The dataset is preprocessed into pickle files representing different collections, which then be used for training models or evaluation:
```sh
cd data
python OpenLane-V2/preprocess.py
```
## Hierarchy
The hierarchy of folder `OpenLane-V2/` is described below:
```
└── OpenLane-V2
├── train
| ├── [segment_id]
| | ├── image
| | | ├── [camera]
| | | | ├── [timestamp].jpg
| | | | └── ...
| | | └── ...
| | └── info
| | ├── [timestamp].json
| | └── ...
| └── ...
├── val
| └── ...
├── test
| └── ...
├── data_dict_example.json
├── data_dict_subset_A.json
├── data_dict_subset_B.json
├── openlanev2.md5
└── preprocess.py
```
-`[segment_id]` specifies a sequence of frames, and `[timestamp]` specifies a single frame in a sequence.
-`image/` contains images captured by various cameras, and `info/` contains meta data and annotations of a single frame.
-`data_dict_[xxx].json` notes the split of train / val / test under the subset of data.
## Meta Data
The json files under the `info/` folder contain meta data and annotations for each frame.
Each file is formatted as follows:
```
{
'version': <str> -- version
'segment_id': <str> -- segment_id
'meta_data': {
'source': <str> -- name of the original dataset
'source_id': <str> -- original identifier of the segment
}
'timestamp': <int> -- timestamp of the frame
'sensor': {
[camera]: { <str> -- name of the camera
'image_path': <str> -- image path
'extrinsic': <dict> -- extrinsic parameters of the camera
'intrinsic': <dict> -- intrinsic parameters of the camera
},
...
}
'pose': <dict> -- ego pose
'annotation': <dict> -- anntations for the current frame
}
```
## Annotations
For a single frame, annotations are formatted as follow:
```
{
'lane_centerline': [ (n lane centerlines in the current frame)
{
'id': <int> -- unique ID in the current frame
'points': <float> [n, 3] -- 3D coordiate
'confidence': <float> -- confidence, only for prediction
},
...
],
'traffic_element': [ (k traffic elements in the current frame)
{
'id': <int> -- unique ID in the current frame
'category': <int> -- traffic element category
1: 'traffic_light',
2: 'road_sign',
'attribute': <int> -- attribute of traffic element
0: 'unknown',
1: 'red',
2: 'green',
3: 'yellow',
4: 'go_straight',
5: 'turn_left',
6: 'turn_right',
7: 'no_left_turn',
8: 'no_right_turn',
9: 'u_turn',
10: 'no_u_turn',
11: 'slight_left',
12: 'slight_right',
'points': <float> [2, 2] -- top-left and bottom-right corners of the 2D bounding box
'confidence': <float> -- confidence, only for prediction
},
...
],
'topology_lclc': <float> [n, n] -- adjacent matrix among lane centerlines
'topology_lcte': <float> [n, k] -- adjacent matrix between lane centerlines and traffic elements
}
```
-`id` is the identifier of a lane centerline or traffic element and is consistent in a sequence.
For predictions, it can be randomly assigned but unique in a single frame.
-`topology_lclc` and `topology_lcte` are adjacent matrices, where row and column are sorted according to the order of the lists `lane_centerline` and `traffic_element`.
It is a MUST to keep the ordering the same for correct evaluation.
For ground truth, only 0 or 1 is a valid boolean value for an element in the matrix.
For predictions, the value varies from 0 to 1, representing the confidence of the predicted relationship.
- #lane_centerline and #traffic_element are not required to be equal between ground truth and predictions.
In the process of evaluation, a matching of ground truth and predictions is determined.
The road structure cognition task is defined as inputting the surrounding view images, reconstructing the high-precision map of the self-vehicle, and outputting the recognition result of the direction of the self-vehicle.
The specific expansion is to input the surrounding view images of the vehicle, HDMap; the output is the lane centerlines, the traffic signs, the topology of the lane centerlines, and the correspondence between lanes centerlines and traffic signs.
Below are examples of visualizing annotations and relationships between different elements on 2D images.
Given the ground truth and predictions, which are formatted dict or the path to pickle storing the dict that ground truth is preprocessed pickle file and predictions are formatted as described [here](./submission.md#format), this function returns a dict storing all metrics defined by our task.
## openlanev2.io
This subpackage wraps all IO operations of the OpenLane-V2 devkit.
Given a data_dict storing identifiers of frames, this function collects meta data the frames and stores it into a pickle file for efficient IO for the following operations.
#### `check_results(results : dict) -> None`
Check format of results.
## openlanev2.visualization
This subpackage provides tools for visualization. Please refer to the [tutorial](../tutorial.ipynb) for examples.
To evaluate performances on different aspects of the task, several metrics are adopted:
- $\text{DET}_{l}$ for mAP on directed lane centerlines,
- $\text{DET}_{t}$ for mAP on traffic elements,
- $\text{TOP}_{ll}$ for mAP on topology among lane centerlines,
- $\text{TOP}_{lt}$ for mAP on topology between lane centerlines and traffic elements.
We consolidate the above metrics by computing an average of them, resulting in the **OpenLane-V2 Score (OLS)**.
### Lane Centerline
We adopt the average precision (AP) but define a match of lane centerlines by considering the discrete Frechet distance in the 3D space.
The mAP for lane centerlines is averaged over match thresholds of $\\{1.0, 2.0, 3.0\\}$ on the similarity measure.
### Traffic Element
Similarly, we use AP to evaluate the task of traffic element detection.
We consider IoU distance as the affinity measure with a match threshold of $0.75$.
Besides, traffic elements have their own attribute.
For instance, a traffic light can be red or green, which indicates the drivable state of the lane.
Therefore, the mAP is then averaged over attributes.
### Topology
The topology metrics estimate the goodness of the relationship among lane centerlines and the relationship between lane centerlines and traffic elements.
To formulate the task of topology prediction as a link prediction problem, we first determine a match of ground truth and predicted vertices (lane centerlines and traffic elements) in the relationship graph.
We choose Frechet and IoU distance for the lane centerline and traffic element respectively.
Also, the metric is average over different recalls.
We adopt mAP from link prediction, which is defined as a mean of APs over all vertices.
Two vertices are regarded as connected if the predicted confidence of the edge is greater than $0.5$.
The AP of a vertex is obtained by ranking all predicted edges and calculating the accumulative mean of the precisions:
where $N(v)$ denotes ordered list of neighbors of vertex $v$ ranked by confidence and $P(v)$ is the precision of the $i$-th vertex $v$ in the ordered list.
Given ground truth and predicted connectivity of lane centerlines, the mAP is calculated on $G^{l} = (V^{l}, E^{l})$ and $\hat{G}^{l} = (\hat{V}^{l}, \hat{E}^{l})$.
As the given graphs are directed, e.g., the ending point of a lane centerline is connected to the starting point of the next lane centerline, we take the mean of mAP over graphs with only in-going or out-going edges.
To evaluate the predicted topology between lane centerlines and traffic elements, we ignore the relationship among lane centerlines.
The relationship among traffic elements is also not taken into consideration.
Thus this can be seen as a link prediction problem on a bipartite undirected graph that $G = (V^{l} \cup V^{t}, E)$ and $\hat{G} = (\hat{V}^{l} \cup \hat{V}^{t}, \hat{E})$.
## Distances
To measure the similarity between ground truth and predicted instances, we adopt Frechet and IoU distances for directed curves and 2D bounding boxes respectively.
### Frechet Distance
Discrete Frechet distance measures the geometric similarity of two ordered lists of points.
Given a pair of curves, namely a ground truth $v = (p_1, ..., p_n)$ and a prediction $\hat{v} = (\hat{p}_1, ..., \hat{p}_k)$, a coupling $L$ is a sequence of distinct pairs between $v$ and $\hat{v}$:
where $a_1, ..., a_m$ and $b_1, ..., b_m$ are nondecreasing surjection such that $1 = a_1 \leq a_i \leq a_j \leq a_m = n$ and $1 = b_1 \leq b_i \leq b_j \leq b_m = k$ for all $i < j$. Then the norm $||L||$ of a coupling $L$ is the distance of the most dissimilar pair in $L$ that:
The submitted results are required to be stored in a pickle file, which is a dict of identifier and [formatted predictions](../data/README.md#annotations) of a frame:
```
{
'method': <str> -- name of the method
'authors': <list> -- list of str, authors
'e-mail': <str> -- e-mail address
'institution / company': <str> -- institution or company
'country / region': <str> -- country or region, checked by iso3166*
'results': {
[identifier]: { <tuple> -- identifier of the frame, (split, segment_id, timestamp)
'lane_centerline': ...
'traffic_element': ...
'topology_lclc': ...
'topology_lcte': ...
},
...
}
}
```
*: For validation, `from iso3166 import countries; countries.get(str)` can be used.
## Steps
1. Create a team on [EvalAI](https://eval.ai/web/challenges/challenge-page/1925).
2. Click the 'Participate' tag, then choose a team for participation.
3. Choose the phase 'Test Phase (CVPR 2023 Autonomous Driving Challenge)' and upload the file formatted as mentioned above.
4. Check if the submitted file is valid, which is indicated by the 'Status' under the tag of 'My Submissions'. A valid submission would provide performance scores.

{kind=link}

{kind=link}
{kind=link}

{kind=link}