
[major] add flux.1-redux; update the flux.1-tools demos
Showing
{kind=link}

520 KB
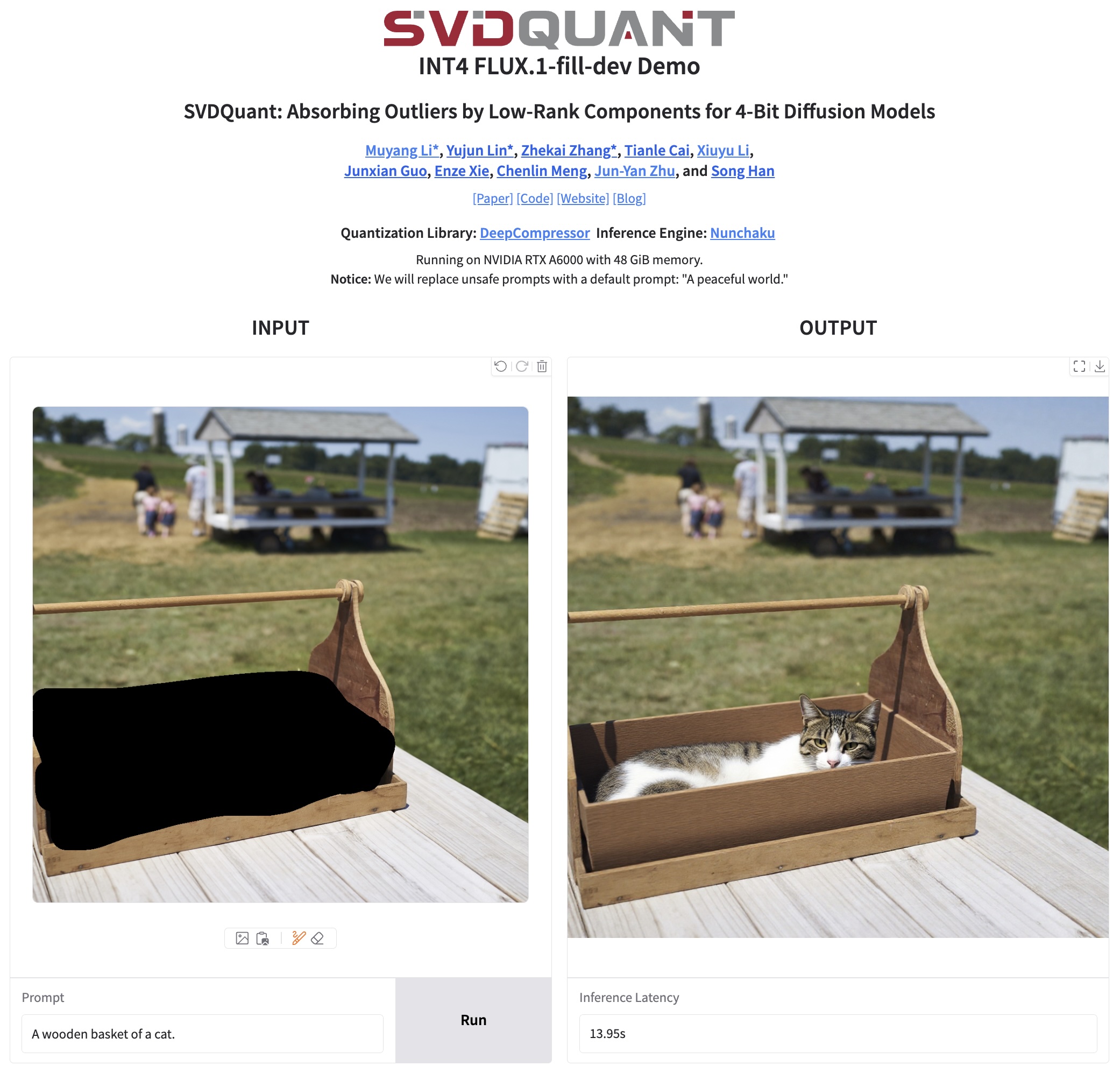
app/flux.1/fill/README.md
0 → 100644
{kind=link}
603 KB
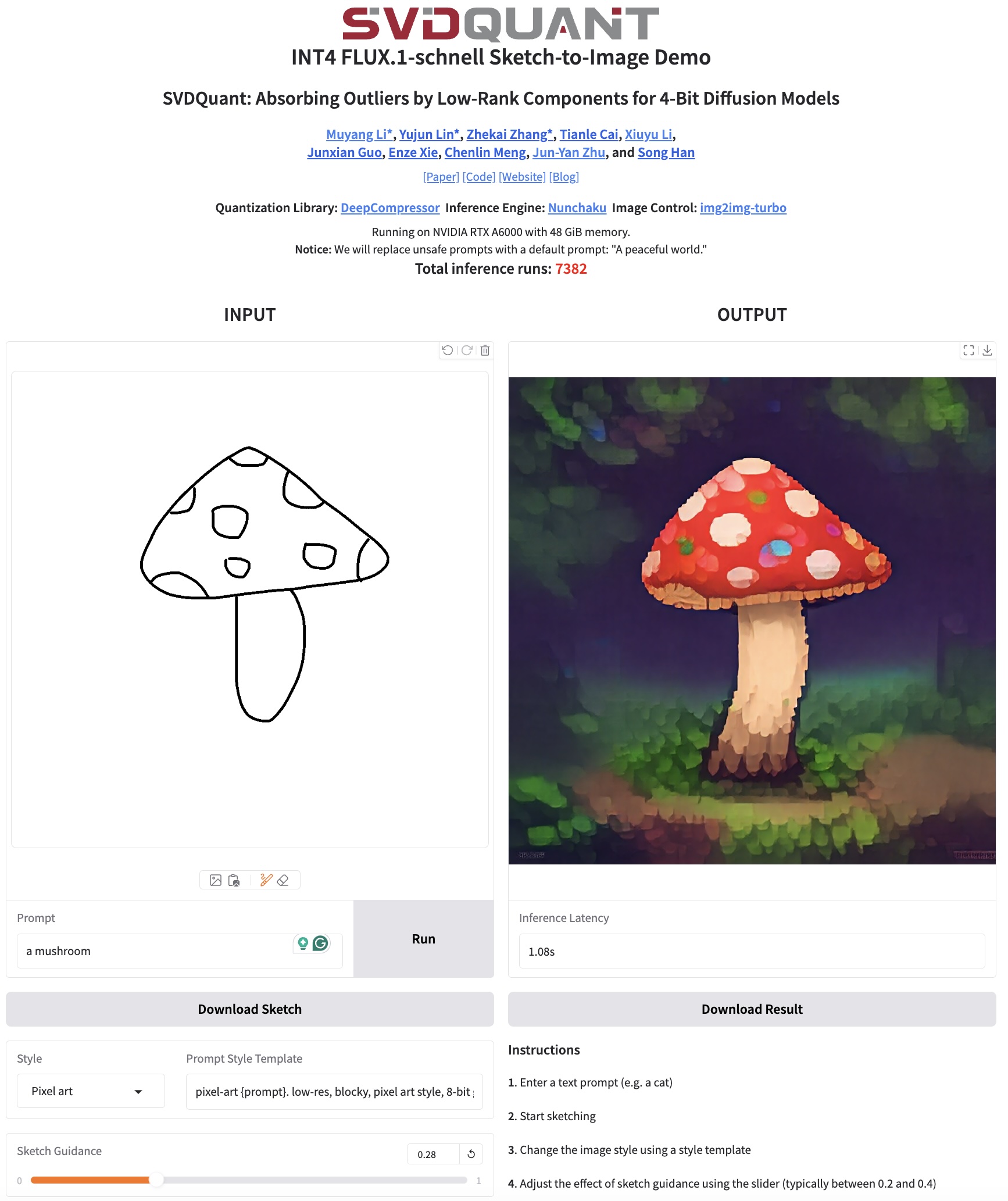
app/flux.1/sketch/README.md
0 → 100644
{kind=link}
436 KB
File moved
{kind=link}
File moved
File moved
File moved