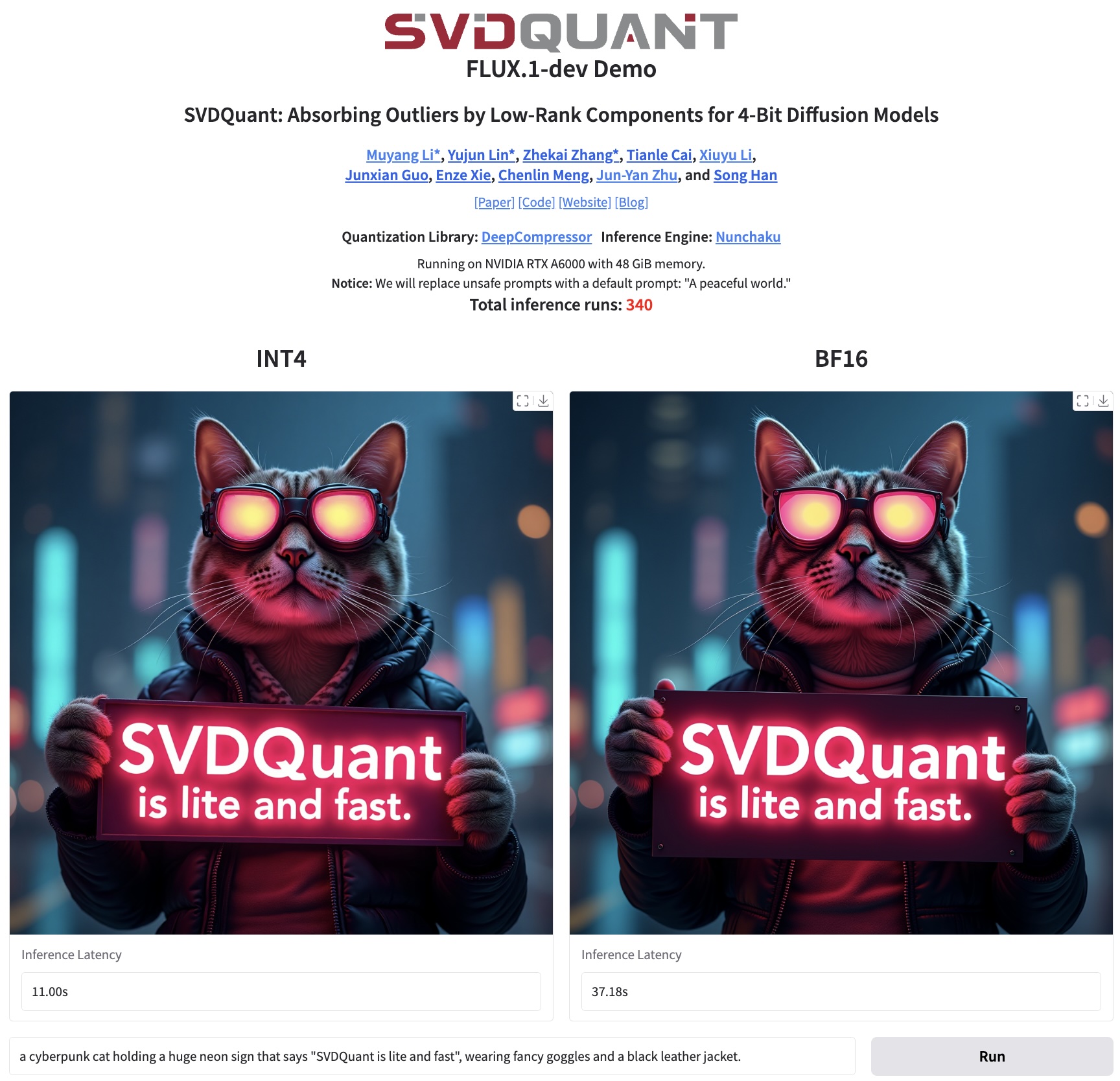
This interactive Gradio application can generate an image based on your provided text prompt. The base model can be either [FLUX.1-schnell](https://huggingface.co/black-forest-labs/FLUX.1-schnell) or [FLUX.1-dev](https://huggingface.co/black-forest-labs/FLUX.1-dev).
This interactive Gradio application can generate an image based on your provided text prompt. The base model is [SANA-1.6B](https://huggingface.co/Efficient-Large-Model/Sana_1600M_1024px_BF16_diffusers).

{kind=link}
{kind=link}
