
Merge branch 'zhiAn123-main-patch-82168' into 'main'
Update doc/image (1).png, doc/image (10).png, doc/image (2).png, doc/image... See merge request !1
Showing
.png){kind=link}
.png){kind=link}
.png)
| W: | H:
.png)
| W: | H:
{kind=link}
{kind=link}
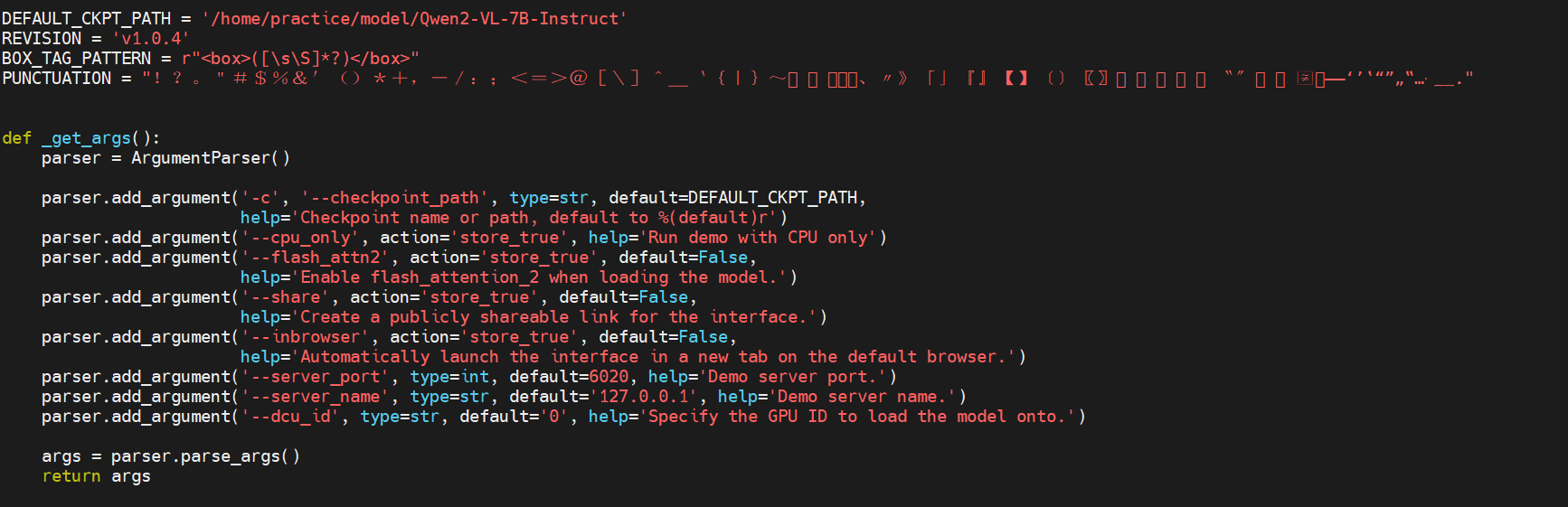
| W: | H:
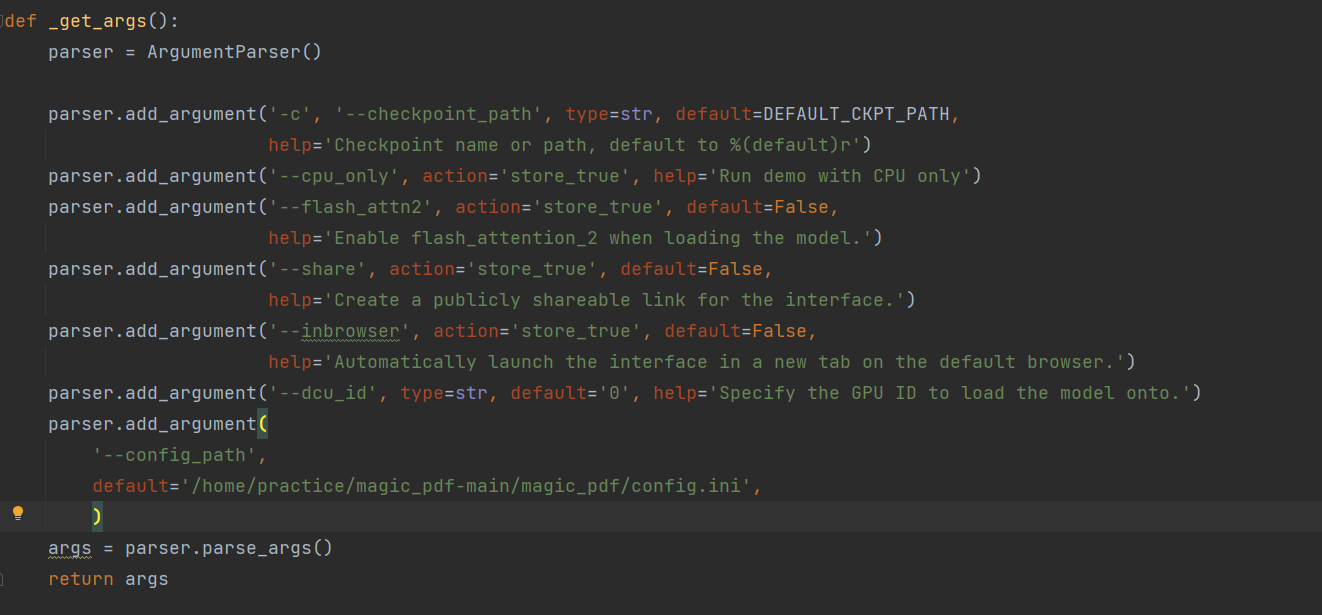
| W: | H:
doc/image12.png
0 → 100644
{kind=link}
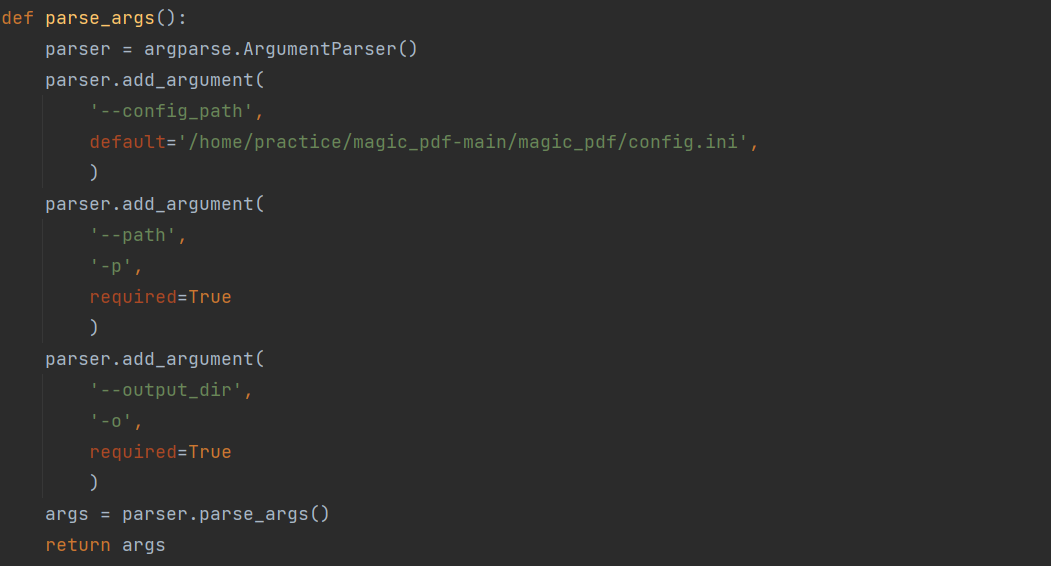
42.7 KB
magic_pdf/config.ini
0 → 100644