
Initial commit
parents
Showing
README.md
0 → 100644
README_CN.md
0 → 100644
This diff is collapsed.
assets/framework.png
0 → 100644
{kind=link}
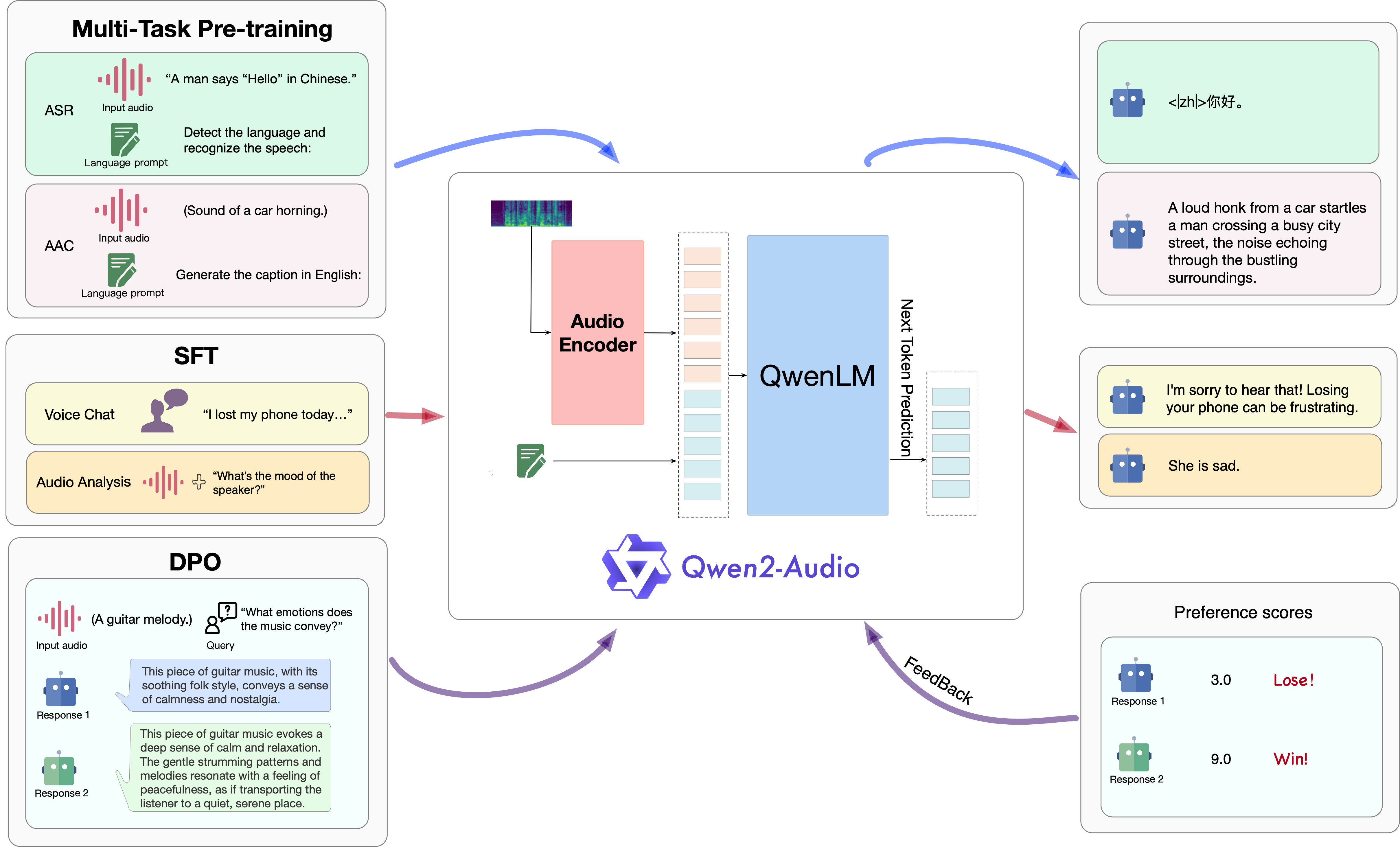
888 KB
assets/logo.png
0 → 100644
{kind=link}
282 KB
{kind=link}
947 KB
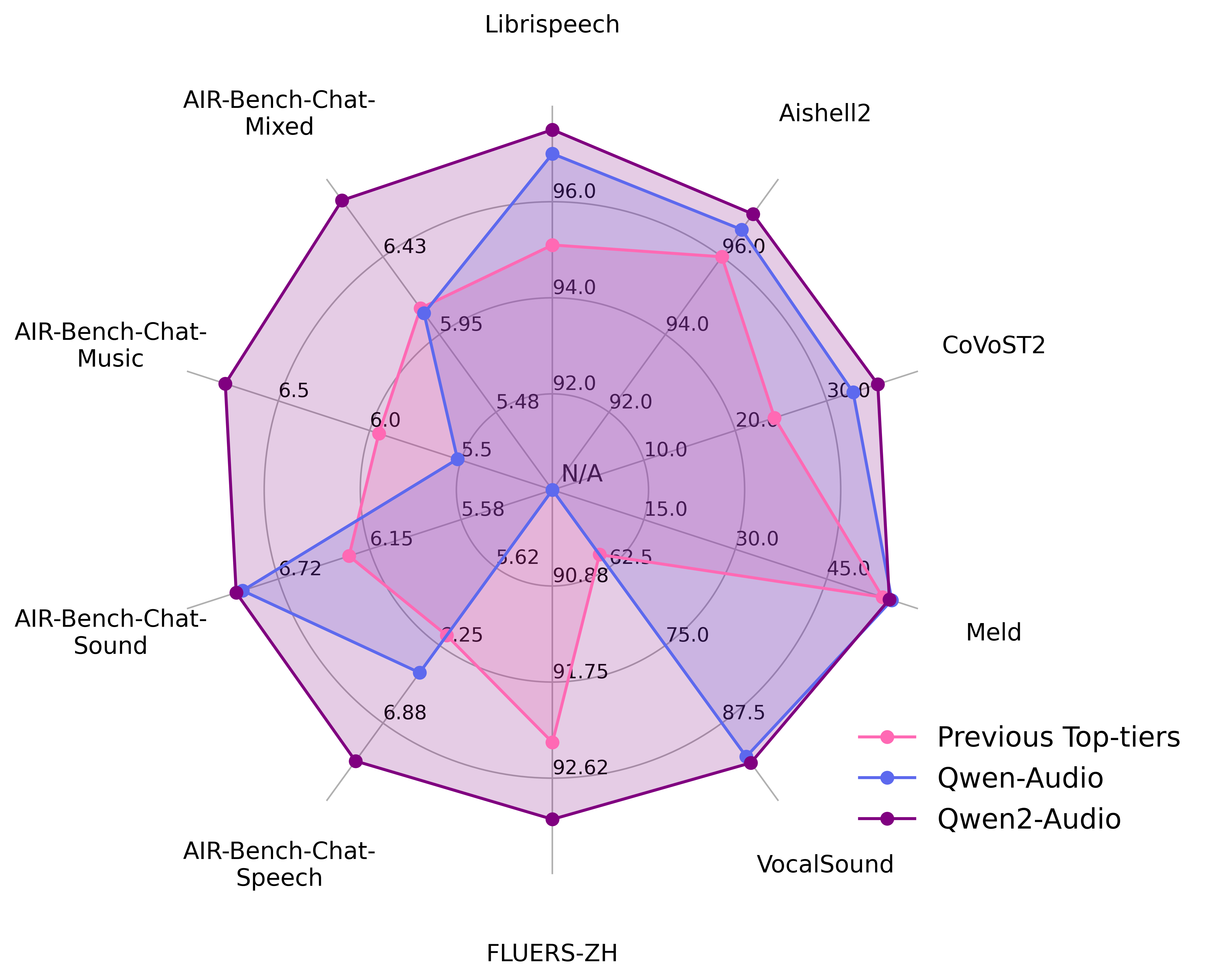
assets/results.png
0 → 100644
{kind=link}

28.5 KB
assets/theory.png
0 → 100644
{kind=link}
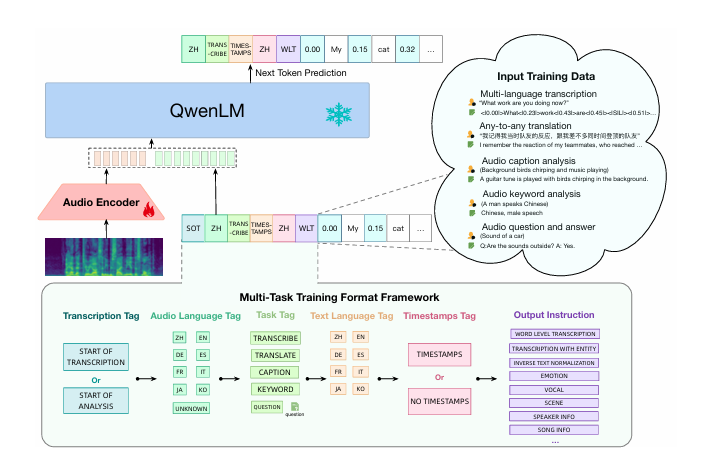
78 KB
demo/demo.sh
0 → 100644
demo/web_demo_audio.py
0 → 100644
docker/Dockerfile
0 → 100644
docker/requirements.txt
0 → 100644
eval_audio/EVALUATION.md
0 → 100644
eval_audio/cn_tn.py
0 → 100644
This diff is collapsed.
eval_audio/evaluate_asr.py
0 → 100644
eval_audio/evaluate_chat.py
0 → 100644
eval_audio/evaluate_st.py
0 → 100644