
init
parents
Showing
{kind=link}

790 KB
{kind=link}

788 KB
{kind=link}

633 KB
{kind=link}

631 KB
{kind=link}

629 KB
{kind=link}
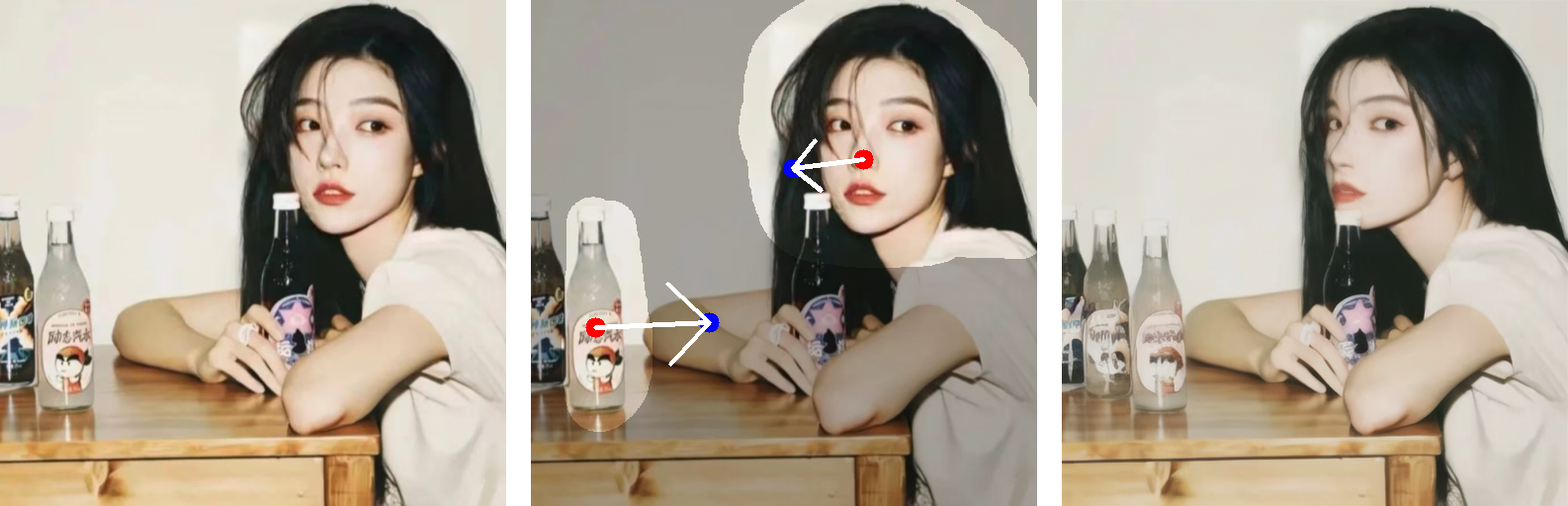
625 KB
{kind=link}
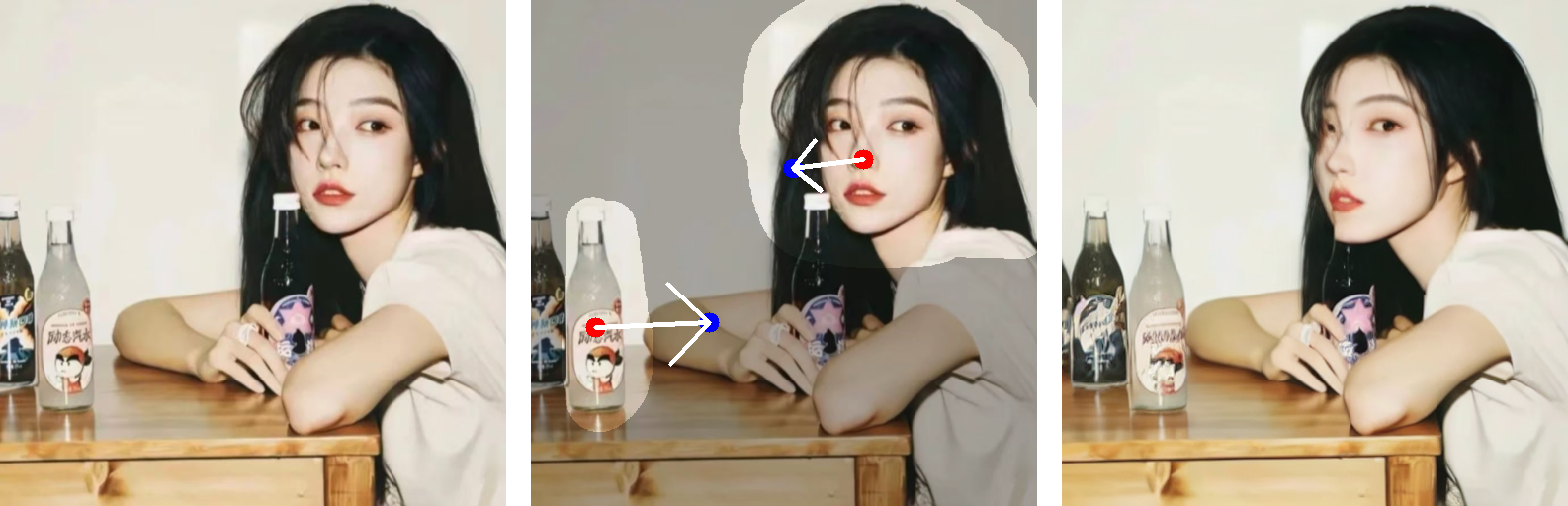
632 KB
File added
File added
File added
File added
File added
utils/attn_utils.py
0 → 100644
utils/drag_utils.py
0 → 100755
utils/freeu_utils.py
0 → 100644
utils/lora_utils.py
0 → 100755
utils/ui_utils.py
0 → 100755