
init
parents
Showing
LICENSE
0 → 100755
README.md
0 → 100644
README_origin.md
0 → 100755
doc/overview.png
0 → 100644
{kind=link}
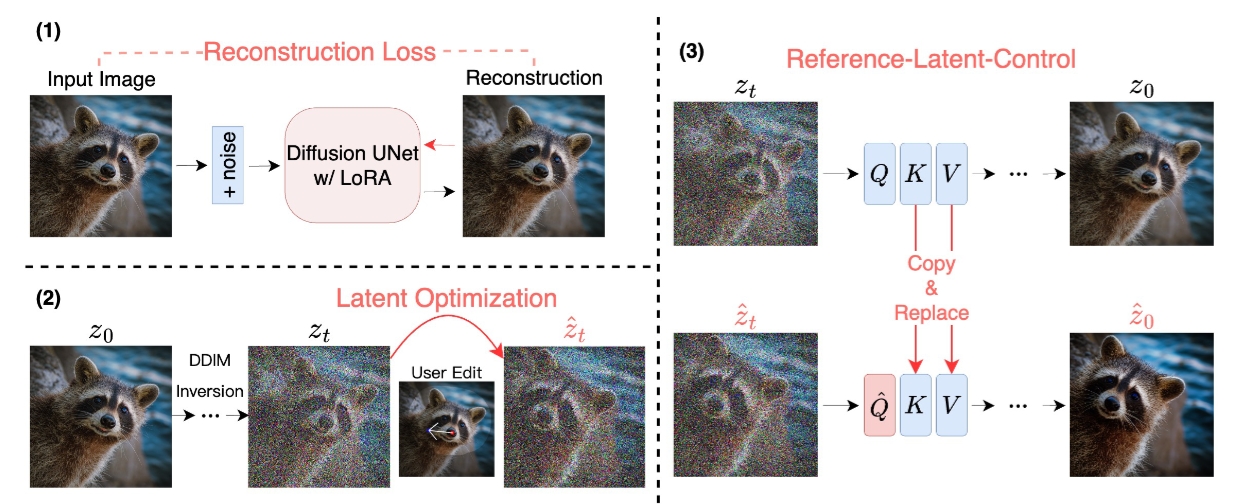
329 KB
doc/result1.png
0 → 100644
{kind=link}
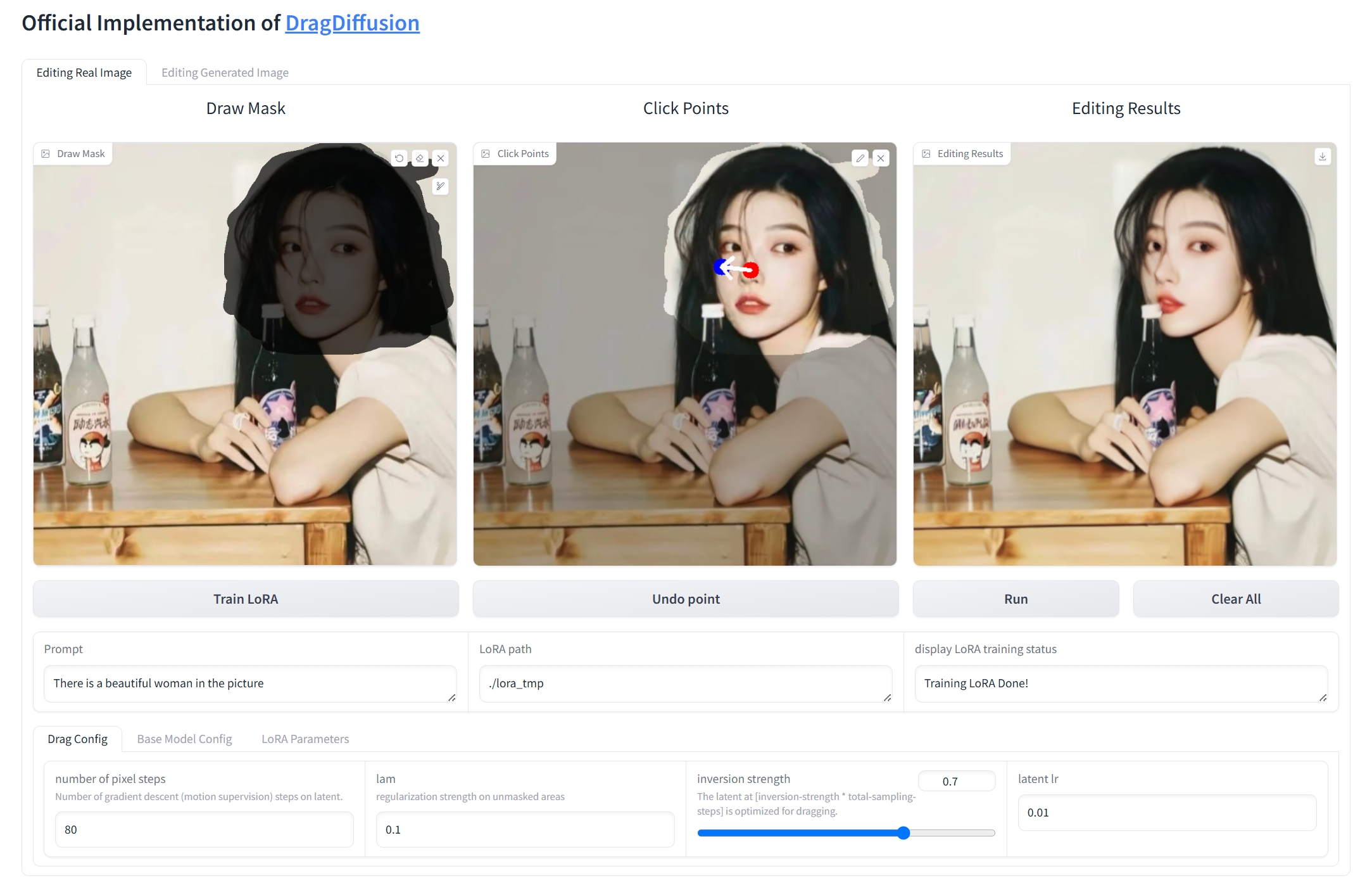
782 KB
doc/webui.png
0 → 100644
{kind=link}
313 KB
docker/Dockerfile
0 → 100644
drag_pipeline.py
0 → 100755
drag_ui.py
0 → 100755
environment.yaml
0 → 100755
icon.png
0 → 100644
{kind=link}
68.4 KB