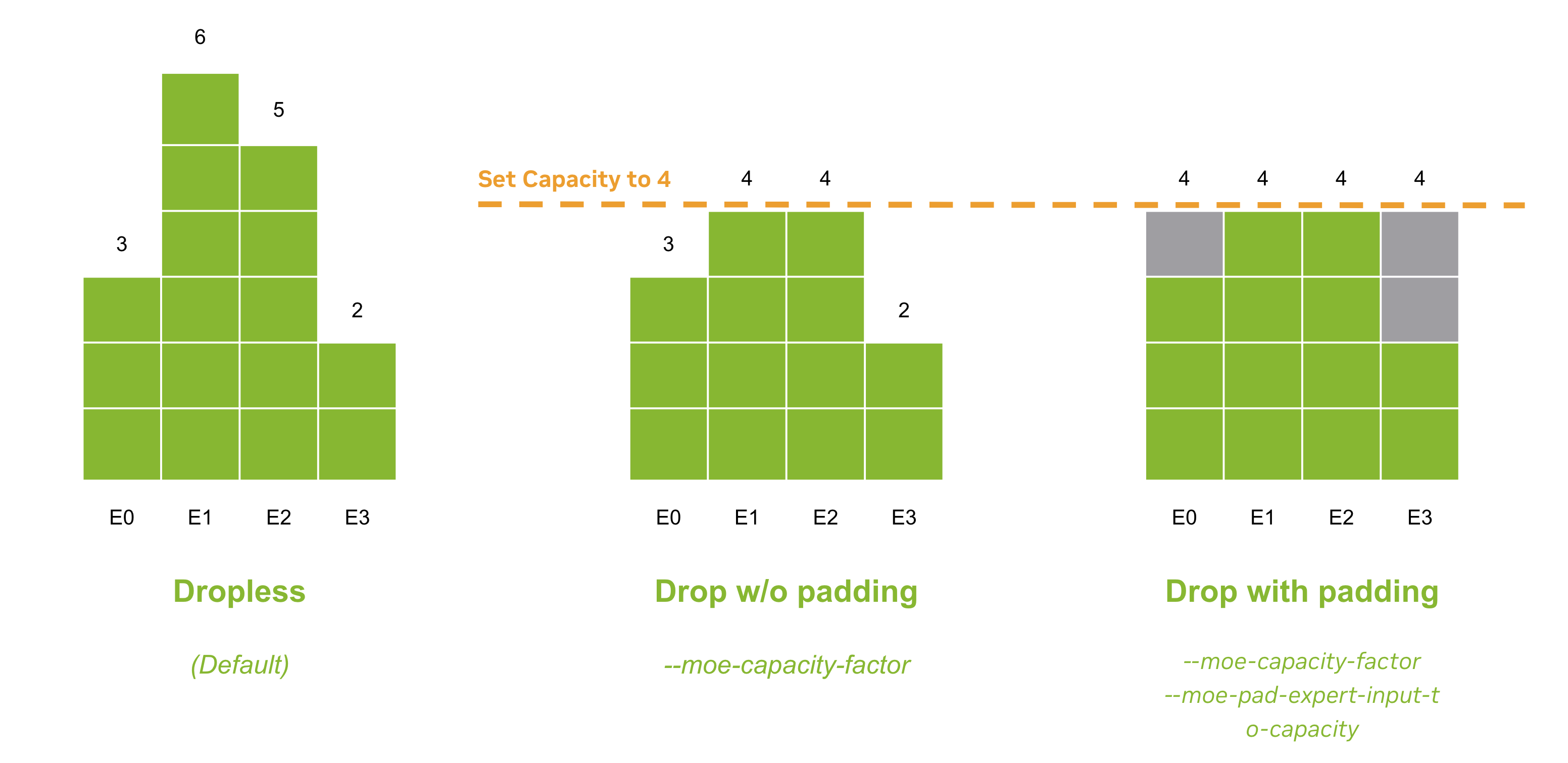
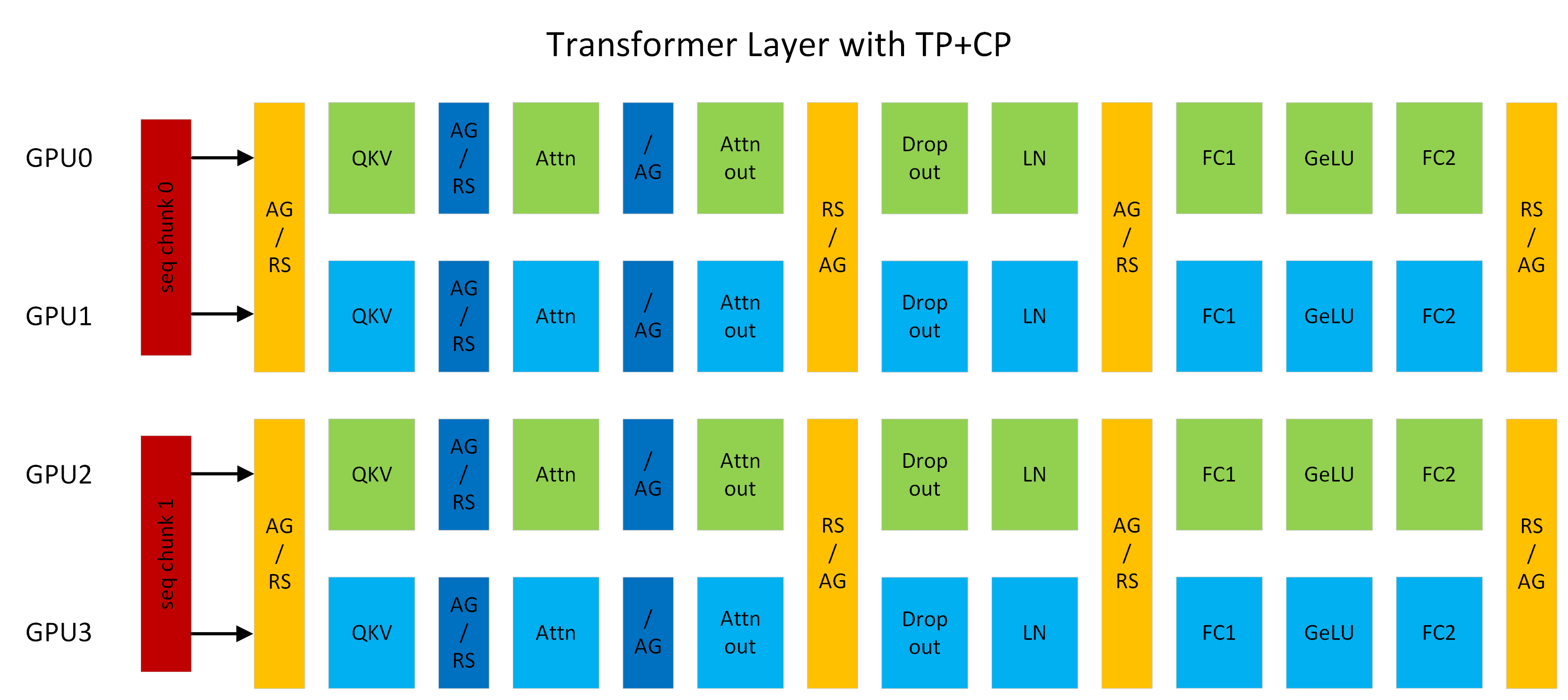
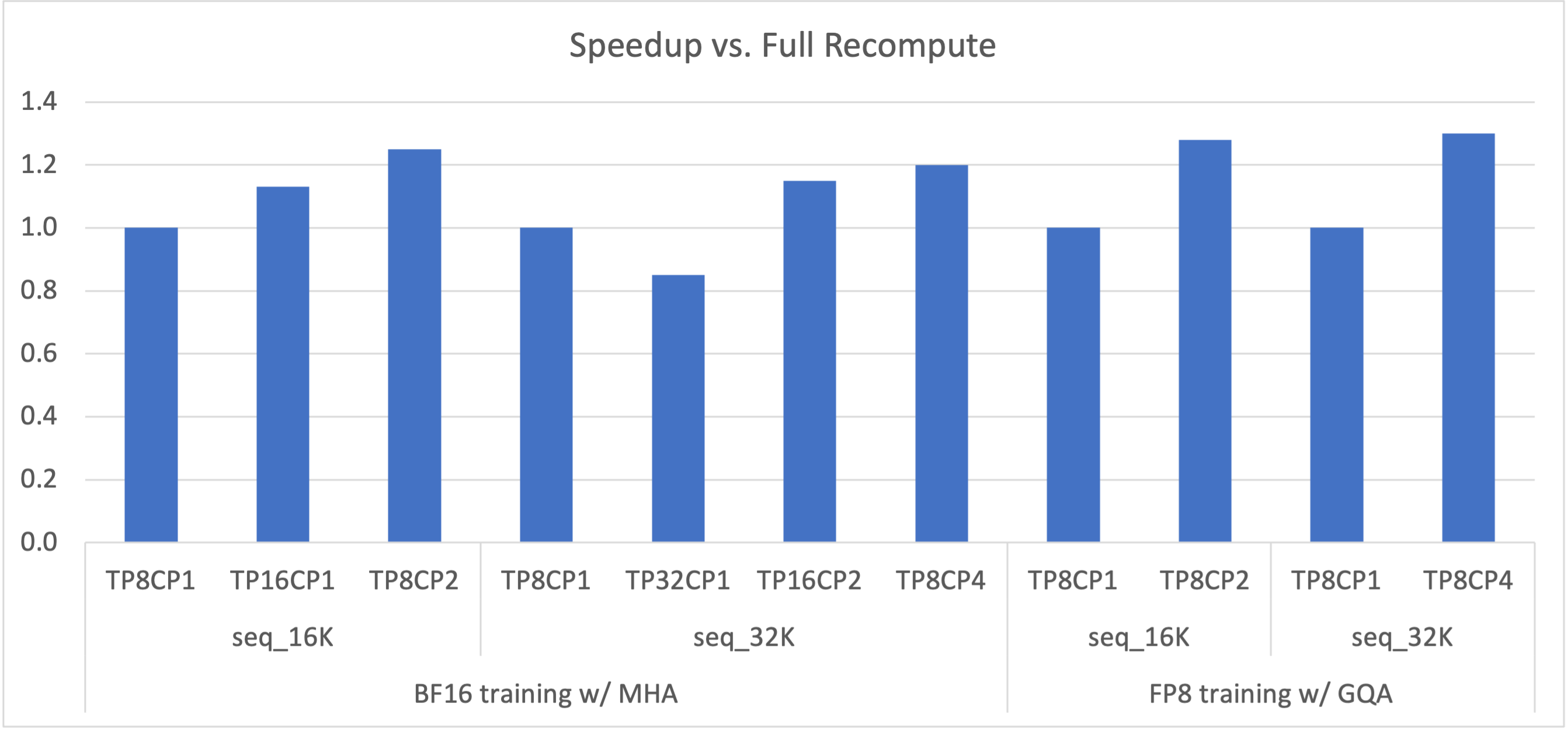
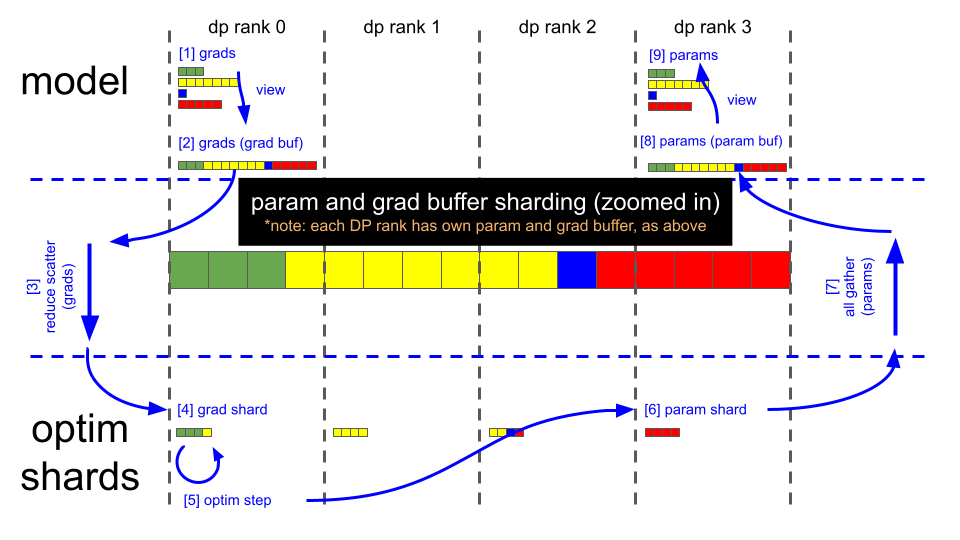
This is the implementation of the popular GPT model. It supports several features like model parallelization (Tensor Parallel, Pipeline Parallel, Data Parallel) , mixture of experts, FP8 , Distributed optimizer etc. We are constantly adding new features. So be on the lookout or raise an issue if you want to have something added.
This package contains most of the popular LLMs . Currently we have support for GPT, Bert, T5 and Retro . This is an ever growing list so keep an eye out.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}