Inference with Mixtral 8x7B requires at least 2 GPUS, such that a distributed checkpoint with EP>=2 or PP>=2 converted with above script is needed.
The Megatron-LM have included a simple REST server to use for text generation in `tools/run_text_generation_server.py`, launch it with the following script:
```
#!/bin/bash
# This example will start serving the Mixtral 8x7B model.
DISTRIBUTED_ARGS="--nproc_per_node 2 \
--nnodes 1 \
--node_rank 0 \
--master_addr localhost \
--master_port 6000"
CHECKPOINT=<Path to checkpoint>
TOKENIZER_MODEL=<Path to tokenizer (e.g. /tokenizer.model)>
The above functionality also applys to Mixtral 8x22B actually, you should set the model config (including hidden_size/head_num/num_layers/ffn_hidden_size) properly according to the original [config](https://huggingface.co/mistralai/Mixtral-8x22B-v0.1/blob/main/config.json).
## Acknowledgements
Contributors outside NVIDIA for the huggingface converter and example of Mixtral models in Megatron-Core:
*NOTE: This example is under active development and is expected change.*
The following walks through all the steps required to pretrain and instruction tune a llava architecture vision-language model (VLM). It is important to precisely follow all steps to obtain the benchmark scores at the end.
This example has been tested on an A100 based DGX cluster. Pretraining and instruction tuning took approximately 1 day and 11 hours respectively on 64 GPUs using four way tensor parallelism (tp=4). Training speed will scale approximately linearly with number of GPUs available.
Multimodal support in megatron is still under active development. This example is not intended to produce state-of-the-art model quality (that would require more data and model refinements), it is merely intended to demonstrate the multimodal functionality in megatron. If you hit any problems, please open a github issue.
## Setup
### Docker container
You can build a docker container using `examples/multimodal/Dockerfile` to run this example.
### Language model
Follow the instructions in `megatron-lm/docs/llama_mistral.md` to download weights for Mistral-7B-Instruct-v0.3 and convert to mcore format with tensor parallel size 4
### Vision model
This example uses the OpenAI CLIP `ViT-L/14@336px` Vision model. To download the weights from OpenAI and convert them to a format that can be loaded in megatron, please run the following:
Update the paths to point to the mcore converted CLIP and Mistral models and run the following script to combine the Mistral and CLIP models into a single multimodal checkpoint folder:
4. Run the following command to convert to megatron-energon format:
```
cd <LLaVA-Pretrain dir>/wds
energon ./
```
select the following values for the presented options:
```
> Please enter a desired train/val/test split like "0.5, 0.2, 0.3" or "8,1,1": 9,1,0
> Do you want to create a dataset.yaml interactively? [Y/n]: Y
> Please enter a number to choose a class: 10 (VQAWebdataset)
> Do you want to set a simple field_map[Y] (or write your own sample_loader [n])? [Y/n]: Y
> Please enter a webdataset field name for 'image' (<class 'torch.Tensor'>): jpg
> Please enter a webdataset field name for 'context' (<class 'str'>): json[0][value]
> Please enter a webdataset field name for 'answers' (typing.Optional[typing.List[str]], default: None): json[1][value]
> Please enter a webdataset field name for 'answer_weights' (typing.Optional[torch.Tensor], default: None):
```
5. Update `pretrain_dataset.yaml` so that both `path` variables point to `LLaVA-Pretrain/wds`
6. Run the following script to pretrain a llava model for image captioning:
```
cd <megatron-lm dir>
examples/multimodal/pretrain_mistral_clip.sh
```
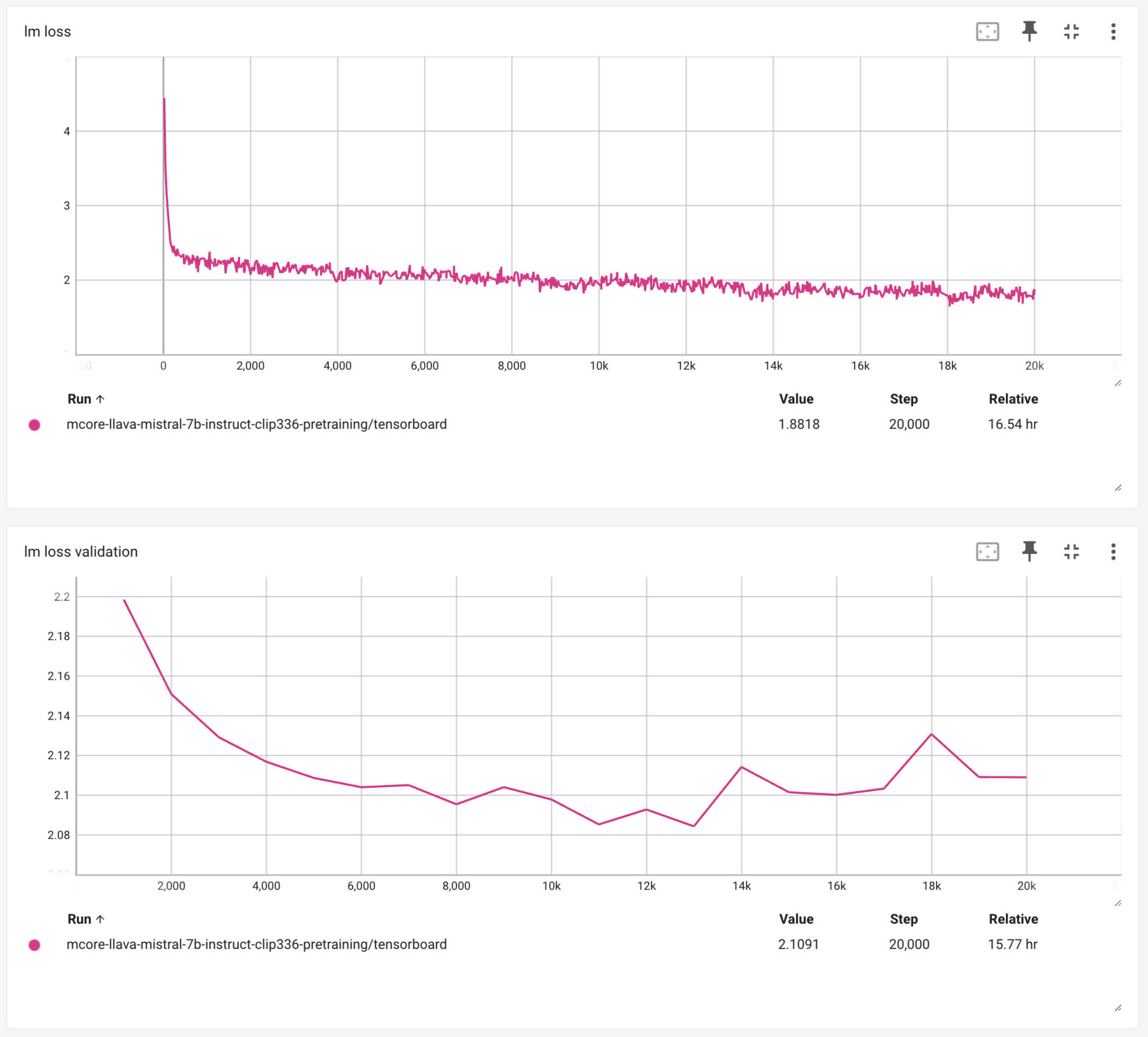
All being well you should observe training and validation loss curves similar to the following:
<imgsrc="assets/pretrain_curves.png"alt="Pretraining loss curves"width="600"/>
These curves were obtained with global batch size of 256. Changing this value will likely change the curves. For pretraining and instruction tuning llava models we have found that loss curves are an unreliable predictor of downstream task performance. Therefore it is necessary to run test generation and evaluation on a range of metrics to understand model quality. We intend to add training time zero-shot evaluation in a future update.
You can execute the pretraining script multiple times to resume training. On resuming, the latest model, optimizer, and dataloader state are loaded.
### SFT
1. Prepare an instruction tuning dataset such in [megatron-energon format](https://nvidia.github.io/Megatron-Energon/data_prep.html#). NOTE: we do not provide instructions for this.
2. Update `sft_dataset.yaml` so that both `path` variables point to the train and val splits of your instruction tuning dataset.
Run the following script to instruction tune the pre-trained llava model:
```
examples/multimodal/sft_mistral_clip.sh
```
You can execute the SFT script multiple times to resume training. On resuming, the latest model, optimizer, and dataloader state are loaded.
For the mistral-7b-instruct plus clip llava model you should obtain a COCO CIDer score of approximately 94.
### After SFT
#### MMMU
The official MMMU repository is not pip installable currently so please clone their code in `examples/multimodal` by running `git clone https://github.com/MMMU-Benchmark/MMMU.git`.
The MMMU dataset is loaded from HuggingFace automatically as part of the code.
Run text generation using `--task MMMU`. Then, run the following command:
# Copyright (c) 2024, NVIDIA CORPORATION. All rights reserved. Except portions as noted which are Copyright (c) 2023 OpenGVLab and licensed under the MIT license found in LICENSE.

{kind=link}