Skip to content
GitLab
Menu
Projects
Groups
Snippets
Loading...
Help
Help
Support
Community forum
Keyboard shortcuts
?
Submit feedback
Contribute to GitLab
Sign in / Register
Toggle navigation
Menu
Open sidebar
wangsen
paddle_dbnet
Commits
fcc70660
Commit
fcc70660
authored
May 08, 2022
by
Leif
Browse files
Merge remote-tracking branch 'origin/dygraph' into dygraph
parents
80aced81
013db618
Changes
51
Hide whitespace changes
Inline
Side-by-side
Showing
11 changed files
with
246 additions
and
28 deletions
+246
-28
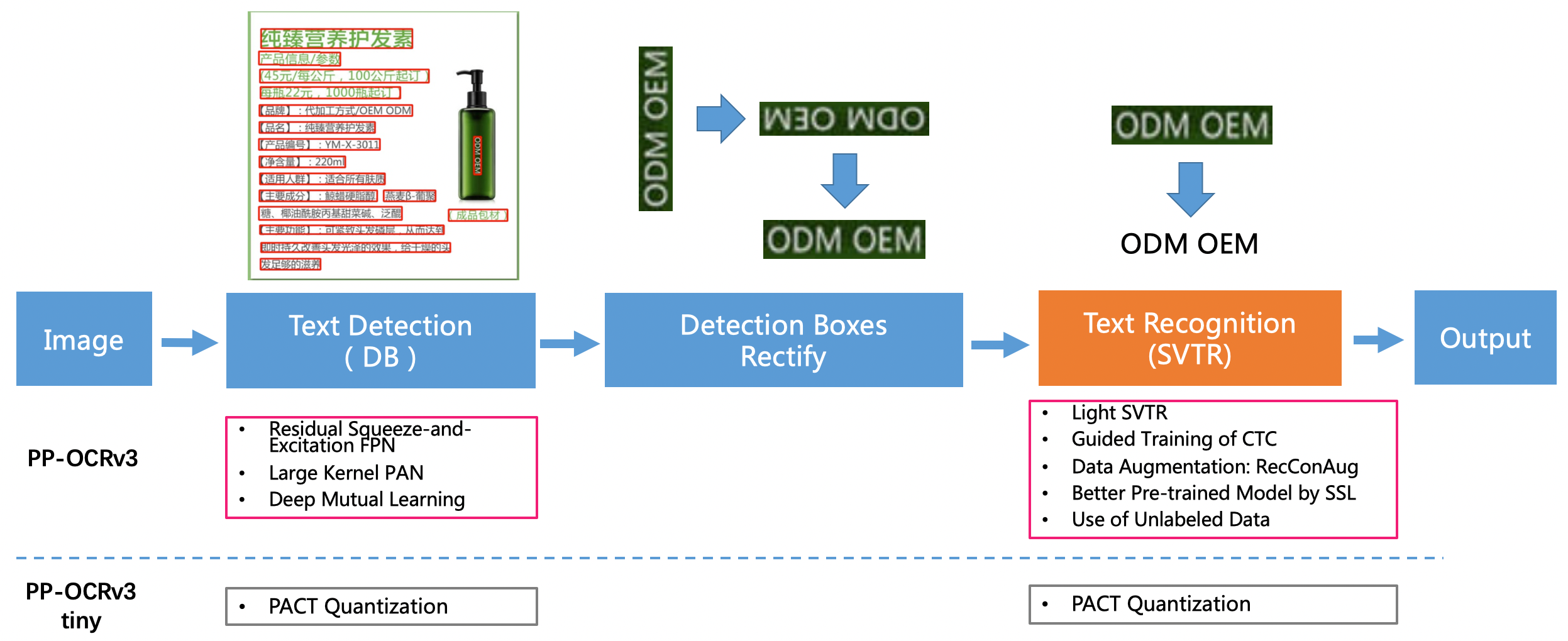
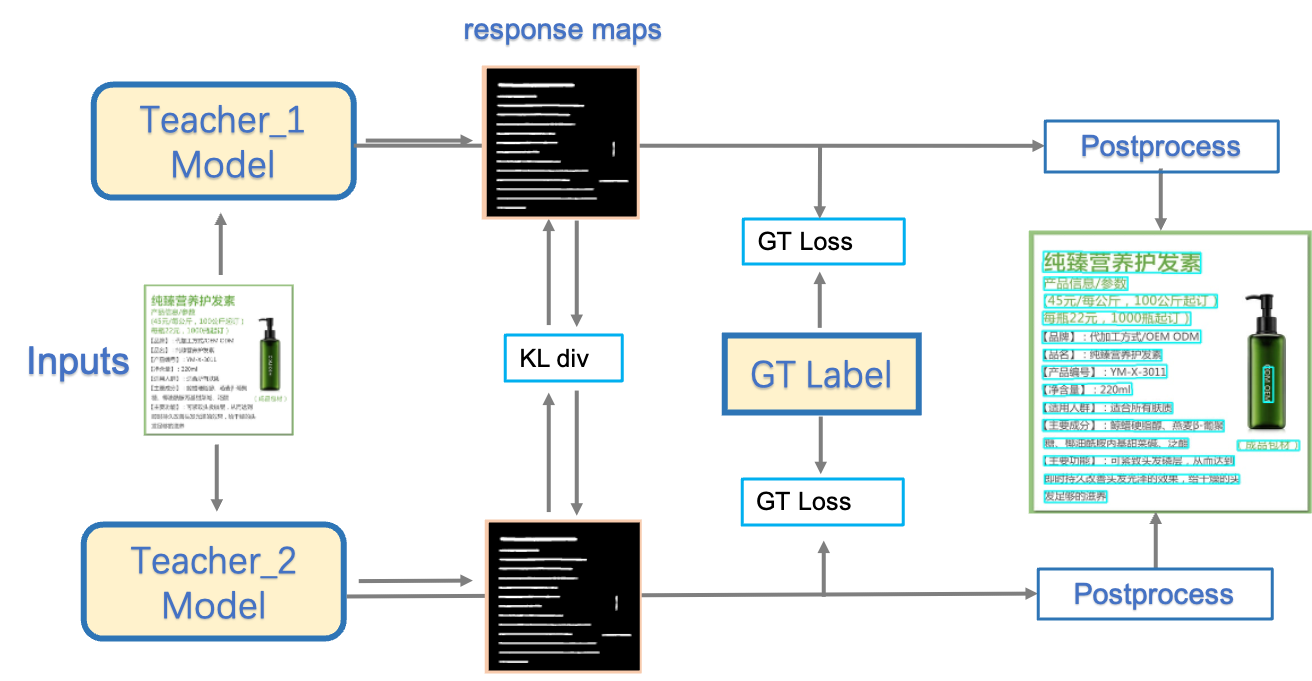
doc/ppocr_v3/teacher_dml.png
doc/ppocr_v3/teacher_dml.png
+0
-0
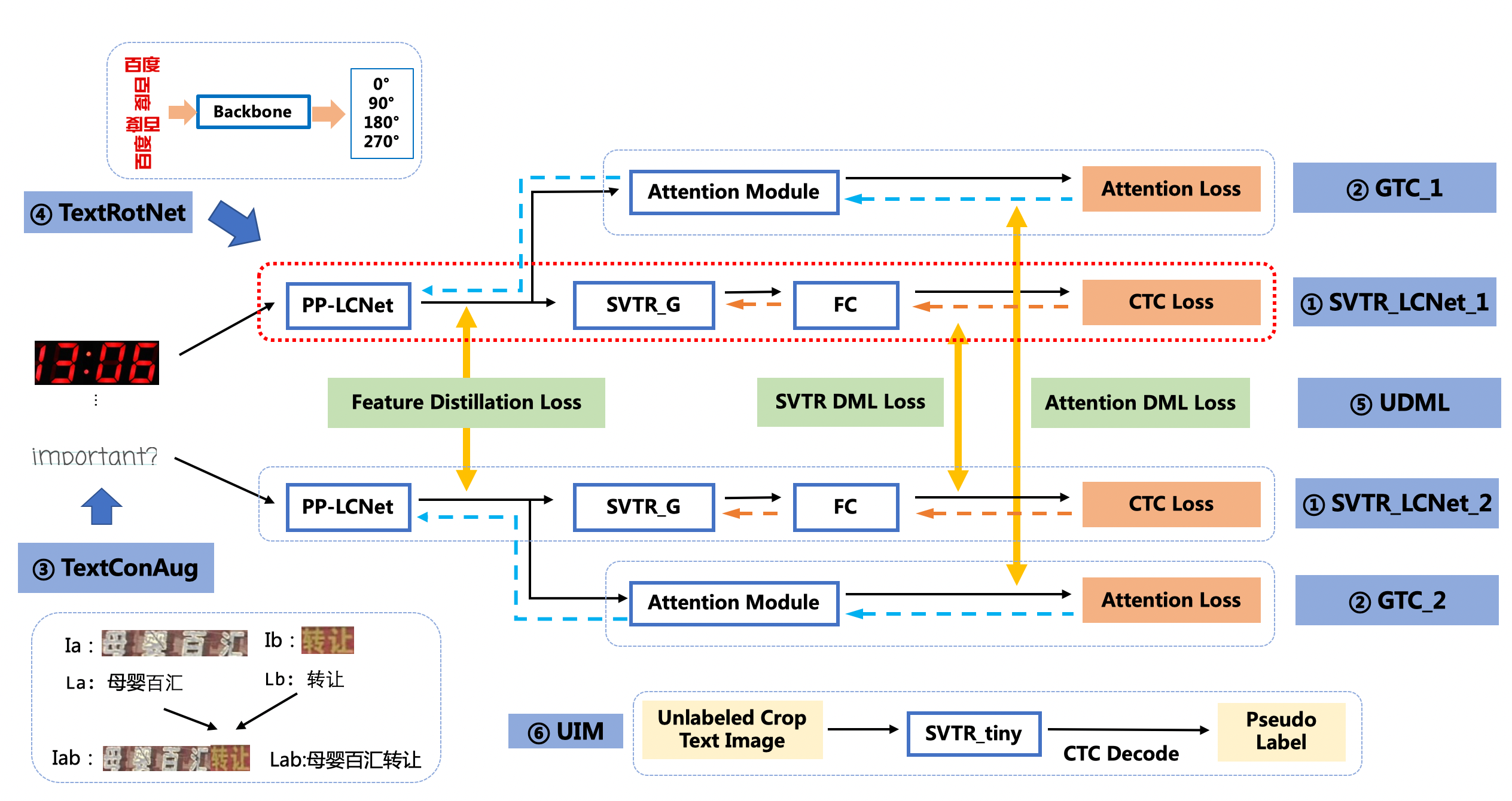
doc/ppocr_v3/v3_rec_pipeline.png
doc/ppocr_v3/v3_rec_pipeline.png
+0
-0
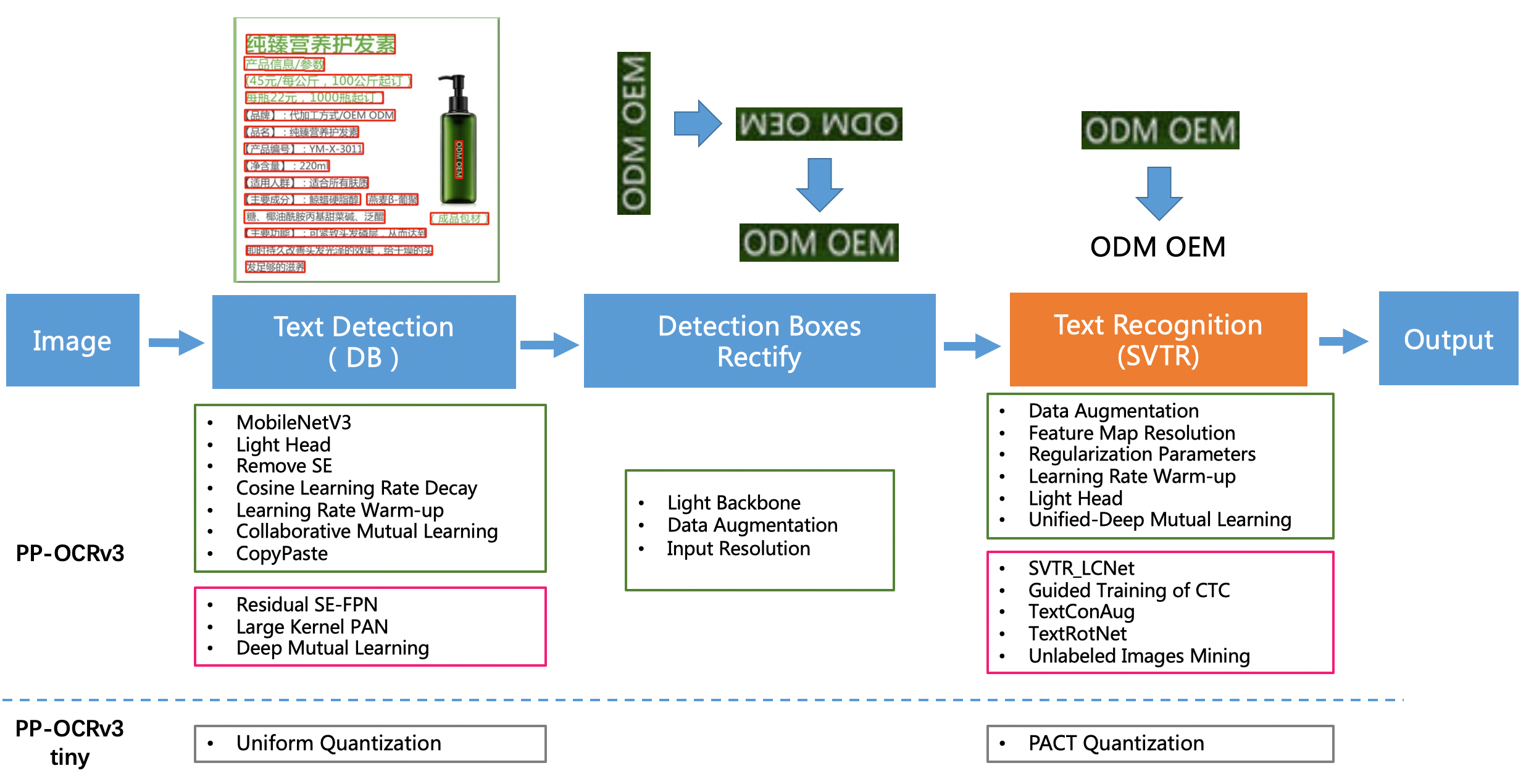
doc/ppocrv3_framework.png
doc/ppocrv3_framework.png
+0
-0
paddleocr.py
paddleocr.py
+62
-2
ppocr/modeling/heads/rec_sar_head.py
ppocr/modeling/heads/rec_sar_head.py
+4
-4
ppocr/utils/loggers/__init__.py
ppocr/utils/loggers/__init__.py
+3
-0
ppocr/utils/loggers/base_logger.py
ppocr/utils/loggers/base_logger.py
+15
-0
ppocr/utils/loggers/loggers.py
ppocr/utils/loggers/loggers.py
+18
-0
ppocr/utils/loggers/vdl_logger.py
ppocr/utils/loggers/vdl_logger.py
+21
-0
ppocr/utils/loggers/wandb_logger.py
ppocr/utils/loggers/wandb_logger.py
+78
-0
tools/program.py
tools/program.py
+45
-22
No files found.
doc/ppocr_v3/teacher_dml.png
0 → 100644
View file @
fcc70660
228 KB
doc/ppocr_v3/v3_rec_pipeline.png
0 → 100644
View file @
fcc70660
971 KB
doc/ppocrv3_framework.png
View replaced file @
80aced81
View file @
fcc70660
957 KB
|
W:
|
H:
1.15 MB
|
W:
|
H:
2-up
Swipe
Onion skin
paddleocr.py
View file @
fcc70660
...
...
@@ -67,6 +67,10 @@ MODEL_URLS = {
'url'
:
'https://paddleocr.bj.bcebos.com/PP-OCRv3/english/en_PP-OCRv3_det_infer.tar'
,
},
'ml'
:
{
'url'
:
'https://paddleocr.bj.bcebos.com/PP-OCRv3/multilingual/Multilingual_PP-OCRv3_det_infer.tar'
}
},
'rec'
:
{
'ch'
:
{
...
...
@@ -79,6 +83,56 @@ MODEL_URLS = {
'https://paddleocr.bj.bcebos.com/PP-OCRv3/english/en_PP-OCRv3_rec_infer.tar'
,
'dict_path'
:
'./ppocr/utils/en_dict.txt'
},
'korean'
:
{
'url'
:
'https://paddleocr.bj.bcebos.com/PP-OCRv3/multilingual/korean_PP-OCRv3_rec_infer.tar'
,
'dict_path'
:
'./ppocr/utils/dict/korean_dict.txt'
},
'japan'
:
{
'url'
:
'https://paddleocr.bj.bcebos.com/PP-OCRv3/multilingual/japan_PP-OCRv3_rec_infer.tar'
,
'dict_path'
:
'./ppocr/utils/dict/japan_dict.txt'
},
'chinese_cht'
:
{
'url'
:
'https://paddleocr.bj.bcebos.com/PP-OCRv3/multilingual/chinese_cht_PP-OCRv3_rec_infer.tar'
,
'dict_path'
:
'./ppocr/utils/dict/chinese_cht_dict.txt'
},
'ta'
:
{
'url'
:
'https://paddleocr.bj.bcebos.com/PP-OCRv3/multilingual/ta_PP-OCRv3_rec_infer.tar'
,
'dict_path'
:
'./ppocr/utils/dict/ta_dict.txt'
},
'te'
:
{
'url'
:
'https://paddleocr.bj.bcebos.com/PP-OCRv3/multilingual/te_PP-OCRv3_rec_infer.tar'
,
'dict_path'
:
'./ppocr/utils/dict/te_dict.txt'
},
'ka'
:
{
'url'
:
'https://paddleocr.bj.bcebos.com/PP-OCRv3/multilingual/ka_PP-OCRv3_rec_infer.tar'
,
'dict_path'
:
'./ppocr/utils/dict/ka_dict.txt'
},
'latin'
:
{
'url'
:
'https://paddleocr.bj.bcebos.com/PP-OCRv3/multilingual/latin_PP-OCRv3_rec_infer.tar'
,
'dict_path'
:
'./ppocr/utils/dict/latin_dict.txt'
},
'arabic'
:
{
'url'
:
'https://paddleocr.bj.bcebos.com/PP-OCRv3/multilingual/arabic_PP-OCRv3_rec_infer.tar'
,
'dict_path'
:
'./ppocr/utils/dict/arabic_dict.txt'
},
'cyrillic'
:
{
'url'
:
'https://paddleocr.bj.bcebos.com/PP-OCRv3/multilingual/cyrillic_PP-OCRv3_rec_infer.tar'
,
'dict_path'
:
'./ppocr/utils/dict/cyrillic_dict.txt'
},
'devanagari'
:
{
'url'
:
'https://paddleocr.bj.bcebos.com/PP-OCRv3/multilingual/devanagari_PP-OCRv3_rec_infer.tar'
,
'dict_path'
:
'./ppocr/utils/dict/devanagari_dict.txt'
},
},
'cls'
:
{
'ch'
:
{
...
...
@@ -259,7 +313,7 @@ def parse_lang(lang):
'af'
,
'az'
,
'bs'
,
'cs'
,
'cy'
,
'da'
,
'de'
,
'es'
,
'et'
,
'fr'
,
'ga'
,
'hr'
,
'hu'
,
'id'
,
'is'
,
'it'
,
'ku'
,
'la'
,
'lt'
,
'lv'
,
'mi'
,
'ms'
,
'mt'
,
'nl'
,
'no'
,
'oc'
,
'pi'
,
'pl'
,
'pt'
,
'ro'
,
'rs_latin'
,
'sk'
,
'sl'
,
'sq'
,
'sv'
,
'sw'
,
'tl'
,
'tr'
,
'uz'
,
'vi'
'sw'
,
'tl'
,
'tr'
,
'uz'
,
'vi'
,
'french'
,
'german'
]
arabic_lang
=
[
'ar'
,
'fa'
,
'ug'
,
'ur'
]
cyrillic_lang
=
[
...
...
@@ -285,8 +339,10 @@ def parse_lang(lang):
det_lang
=
"ch"
elif
lang
==
'structure'
:
det_lang
=
'structure'
el
se
:
el
if
lang
in
[
"en"
,
"latin"
]
:
det_lang
=
"en"
else
:
det_lang
=
"ml"
return
lang
,
det_lang
...
...
@@ -356,6 +412,10 @@ class PaddleOCR(predict_system.TextSystem):
params
.
cls_model_dir
,
cls_url
=
confirm_model_dir_url
(
params
.
cls_model_dir
,
os
.
path
.
join
(
BASE_DIR
,
'whl'
,
'cls'
),
cls_model_config
[
'url'
])
if
params
.
ocr_version
==
'PP-OCRv3'
:
params
.
rec_image_shape
=
"3, 48, 320"
else
:
params
.
rec_image_shape
=
"3, 32, 320"
# download model
maybe_download
(
params
.
det_model_dir
,
det_url
)
maybe_download
(
params
.
rec_model_dir
,
rec_url
)
...
...
ppocr/modeling/heads/rec_sar_head.py
View file @
fcc70660
...
...
@@ -99,8 +99,8 @@ class SAREncoder(nn.Layer):
if
valid_ratios
is
not
None
:
valid_hf
=
[]
T
=
holistic_feat
.
shape
[
1
]
for
i
,
valid_ratio
in
enumerate
(
valid_ratios
):
valid_step
=
min
(
T
,
math
.
ceil
(
T
*
valid_ratio
))
-
1
for
i
in
range
(
len
(
valid_ratios
)
)
:
valid_step
=
min
(
T
,
math
.
ceil
(
T
*
valid_ratio
s
[
i
]
))
-
1
valid_hf
.
append
(
holistic_feat
[
i
,
valid_step
,
:])
valid_hf
=
paddle
.
stack
(
valid_hf
,
axis
=
0
)
else
:
...
...
@@ -252,8 +252,8 @@ class ParallelSARDecoder(BaseDecoder):
if
valid_ratios
is
not
None
:
# cal mask of attention weight
for
i
,
valid_ratio
in
enumerate
(
valid_ratios
):
valid_width
=
min
(
w
,
math
.
ceil
(
w
*
valid_ratio
))
for
i
in
range
(
len
(
valid_ratios
)
)
:
valid_width
=
min
(
w
,
math
.
ceil
(
w
*
valid_ratio
s
[
i
]
))
if
valid_width
<
w
:
attn_weight
[
i
,
:,
:,
valid_width
:,
:]
=
float
(
'-inf'
)
...
...
ppocr/utils/loggers/__init__.py
0 → 100644
View file @
fcc70660
from
.vdl_logger
import
VDLLogger
from
.wandb_logger
import
WandbLogger
from
.loggers
import
Loggers
ppocr/utils/loggers/base_logger.py
0 → 100644
View file @
fcc70660
import
os
from
abc
import
ABC
,
abstractmethod
class
BaseLogger
(
ABC
):
def
__init__
(
self
,
save_dir
):
self
.
save_dir
=
save_dir
os
.
makedirs
(
self
.
save_dir
,
exist_ok
=
True
)
@
abstractmethod
def
log_metrics
(
self
,
metrics
,
prefix
=
None
):
pass
@
abstractmethod
def
close
(
self
):
pass
\ No newline at end of file
ppocr/utils/loggers/loggers.py
0 → 100644
View file @
fcc70660
from
.wandb_logger
import
WandbLogger
class
Loggers
(
object
):
def
__init__
(
self
,
loggers
):
super
().
__init__
()
self
.
loggers
=
loggers
def
log_metrics
(
self
,
metrics
,
prefix
=
None
,
step
=
None
):
for
logger
in
self
.
loggers
:
logger
.
log_metrics
(
metrics
,
prefix
=
prefix
,
step
=
step
)
def
log_model
(
self
,
is_best
,
prefix
,
metadata
=
None
):
for
logger
in
self
.
loggers
:
logger
.
log_model
(
is_best
=
is_best
,
prefix
=
prefix
,
metadata
=
metadata
)
def
close
(
self
):
for
logger
in
self
.
loggers
:
logger
.
close
()
\ No newline at end of file
ppocr/utils/loggers/vdl_logger.py
0 → 100644
View file @
fcc70660
from
.base_logger
import
BaseLogger
from
visualdl
import
LogWriter
class
VDLLogger
(
BaseLogger
):
def
__init__
(
self
,
save_dir
):
super
().
__init__
(
save_dir
)
self
.
vdl_writer
=
LogWriter
(
logdir
=
save_dir
)
def
log_metrics
(
self
,
metrics
,
prefix
=
None
,
step
=
None
):
if
not
prefix
:
prefix
=
""
updated_metrics
=
{
prefix
+
"/"
+
k
:
v
for
k
,
v
in
metrics
.
items
()}
for
k
,
v
in
updated_metrics
.
items
():
self
.
vdl_writer
.
add_scalar
(
k
,
v
,
step
)
def
log_model
(
self
,
is_best
,
prefix
,
metadata
=
None
):
pass
def
close
(
self
):
self
.
vdl_writer
.
close
()
\ No newline at end of file
ppocr/utils/loggers/wandb_logger.py
0 → 100644
View file @
fcc70660
import
os
from
.base_logger
import
BaseLogger
class
WandbLogger
(
BaseLogger
):
def
__init__
(
self
,
project
=
None
,
name
=
None
,
id
=
None
,
entity
=
None
,
save_dir
=
None
,
config
=
None
,
**
kwargs
):
try
:
import
wandb
self
.
wandb
=
wandb
except
ModuleNotFoundError
:
raise
ModuleNotFoundError
(
"Please install wandb using `pip install wandb`"
)
self
.
project
=
project
self
.
name
=
name
self
.
id
=
id
self
.
save_dir
=
save_dir
self
.
config
=
config
self
.
kwargs
=
kwargs
self
.
entity
=
entity
self
.
_run
=
None
self
.
_wandb_init
=
dict
(
project
=
self
.
project
,
name
=
self
.
name
,
id
=
self
.
id
,
entity
=
self
.
entity
,
dir
=
self
.
save_dir
,
resume
=
"allow"
)
self
.
_wandb_init
.
update
(
**
kwargs
)
_
=
self
.
run
if
self
.
config
:
self
.
run
.
config
.
update
(
self
.
config
)
@
property
def
run
(
self
):
if
self
.
_run
is
None
:
if
self
.
wandb
.
run
is
not
None
:
logger
.
info
(
"There is a wandb run already in progress "
"and newly created instances of `WandbLogger` will reuse"
" this run. If this is not desired, call `wandb.finish()`"
"before instantiating `WandbLogger`."
)
self
.
_run
=
self
.
wandb
.
run
else
:
self
.
_run
=
self
.
wandb
.
init
(
**
self
.
_wandb_init
)
return
self
.
_run
def
log_metrics
(
self
,
metrics
,
prefix
=
None
,
step
=
None
):
if
not
prefix
:
prefix
=
""
updated_metrics
=
{
prefix
.
lower
()
+
"/"
+
k
:
v
for
k
,
v
in
metrics
.
items
()}
self
.
run
.
log
(
updated_metrics
,
step
=
step
)
def
log_model
(
self
,
is_best
,
prefix
,
metadata
=
None
):
model_path
=
os
.
path
.
join
(
self
.
save_dir
,
prefix
+
'.pdparams'
)
artifact
=
self
.
wandb
.
Artifact
(
'model-{}'
.
format
(
self
.
run
.
id
),
type
=
'model'
,
metadata
=
metadata
)
artifact
.
add_file
(
model_path
,
name
=
"model_ckpt.pdparams"
)
aliases
=
[
prefix
]
if
is_best
:
aliases
.
append
(
"best"
)
self
.
run
.
log_artifact
(
artifact
,
aliases
=
aliases
)
def
close
(
self
):
self
.
run
.
finish
()
\ No newline at end of file
tools/program.py
View file @
fcc70660
...
...
@@ -31,6 +31,7 @@ from ppocr.utils.stats import TrainingStats
from
ppocr.utils.save_load
import
save_model
from
ppocr.utils.utility
import
print_dict
,
AverageMeter
from
ppocr.utils.logging
import
get_logger
from
ppocr.utils.loggers
import
VDLLogger
,
WandbLogger
,
Loggers
from
ppocr.utils
import
profiler
from
ppocr.data
import
build_dataloader
...
...
@@ -161,7 +162,7 @@ def train(config,
eval_class
,
pre_best_model_dict
,
logger
,
vdl
_writer
=
None
,
log
_writer
=
None
,
scaler
=
None
):
cal_metric_during_train
=
config
[
'Global'
].
get
(
'cal_metric_during_train'
,
False
)
...
...
@@ -300,10 +301,8 @@ def train(config,
stats
[
'lr'
]
=
lr
train_stats
.
update
(
stats
)
if
vdl_writer
is
not
None
and
dist
.
get_rank
()
==
0
:
for
k
,
v
in
train_stats
.
get
().
items
():
vdl_writer
.
add_scalar
(
'TRAIN/{}'
.
format
(
k
),
v
,
global_step
)
vdl_writer
.
add_scalar
(
'TRAIN/lr'
,
lr
,
global_step
)
if
log_writer
is
not
None
and
dist
.
get_rank
()
==
0
:
log_writer
.
log_metrics
(
metrics
=
train_stats
.
get
(),
prefix
=
"TRAIN"
,
step
=
global_step
)
if
dist
.
get_rank
()
==
0
and
(
(
global_step
>
0
and
global_step
%
print_batch_step
==
0
)
or
...
...
@@ -349,11 +348,9 @@ def train(config,
logger
.
info
(
cur_metric_str
)
# logger metric
if
vdl_writer
is
not
None
:
for
k
,
v
in
cur_metric
.
items
():
if
isinstance
(
v
,
(
float
,
int
)):
vdl_writer
.
add_scalar
(
'EVAL/{}'
.
format
(
k
),
cur_metric
[
k
],
global_step
)
if
log_writer
is
not
None
:
log_writer
.
log_metrics
(
metrics
=
cur_metric
,
prefix
=
"EVAL"
,
step
=
global_step
)
if
cur_metric
[
main_indicator
]
>=
best_model_dict
[
main_indicator
]:
best_model_dict
.
update
(
cur_metric
)
...
...
@@ -374,10 +371,12 @@ def train(config,
]))
logger
.
info
(
best_str
)
# logger best metric
if
vdl_writer
is
not
None
:
vdl_writer
.
add_scalar
(
'EVAL/best_{}'
.
format
(
main_indicator
),
best_model_dict
[
main_indicator
],
global_step
)
if
log_writer
is
not
None
:
log_writer
.
log_metrics
(
metrics
=
{
"best_{}"
.
format
(
main_indicator
):
best_model_dict
[
main_indicator
]
},
prefix
=
"EVAL"
,
step
=
global_step
)
log_writer
.
log_model
(
is_best
=
True
,
prefix
=
"best_accuracy"
,
metadata
=
best_model_dict
)
reader_start
=
time
.
time
()
if
dist
.
get_rank
()
==
0
:
...
...
@@ -392,6 +391,10 @@ def train(config,
best_model_dict
=
best_model_dict
,
epoch
=
epoch
,
global_step
=
global_step
)
if
log_writer
is
not
None
:
log_writer
.
log_model
(
is_best
=
False
,
prefix
=
"latest"
)
if
dist
.
get_rank
()
==
0
and
epoch
>
0
and
epoch
%
save_epoch_step
==
0
:
save_model
(
model
,
...
...
@@ -404,11 +407,14 @@ def train(config,
best_model_dict
=
best_model_dict
,
epoch
=
epoch
,
global_step
=
global_step
)
if
log_writer
is
not
None
:
log_writer
.
log_model
(
is_best
=
False
,
prefix
=
'iter_epoch_{}'
.
format
(
epoch
))
best_str
=
'best metric, {}'
.
format
(
', '
.
join
(
[
'{}: {}'
.
format
(
k
,
v
)
for
k
,
v
in
best_model_dict
.
items
()]))
logger
.
info
(
best_str
)
if
dist
.
get_rank
()
==
0
and
vdl
_writer
is
not
None
:
vdl
_writer
.
close
()
if
dist
.
get_rank
()
==
0
and
log
_writer
is
not
None
:
log
_writer
.
close
()
return
...
...
@@ -565,15 +571,32 @@ def preprocess(is_train=False):
config
[
'Global'
][
'distributed'
]
=
dist
.
get_world_size
()
!=
1
if
config
[
'Global'
][
'use_visualdl'
]
and
dist
.
get_rank
()
==
0
:
from
visualdl
import
LogWriter
loggers
=
[]
if
'use_visualdl'
in
config
[
'Global'
]
and
config
[
'Global'
][
'use_visualdl'
]:
save_model_dir
=
config
[
'Global'
][
'save_model_dir'
]
vdl_writer_path
=
'{}/vdl/'
.
format
(
save_model_dir
)
os
.
makedirs
(
vdl_writer_path
,
exist_ok
=
True
)
vdl_writer
=
LogWriter
(
logdir
=
vdl_writer_path
)
log_writer
=
VDLLogger
(
save_model_dir
)
loggers
.
append
(
log_writer
)
if
(
'use_wandb'
in
config
[
'Global'
]
and
config
[
'Global'
][
'use_wandb'
])
or
'wandb'
in
config
:
save_dir
=
config
[
'Global'
][
'save_model_dir'
]
wandb_writer_path
=
"{}/wandb"
.
format
(
save_dir
)
if
"wandb"
in
config
:
wandb_params
=
config
[
'wandb'
]
else
:
wandb_params
=
dict
()
wandb_params
.
update
({
'save_dir'
:
save_model_dir
})
log_writer
=
WandbLogger
(
**
wandb_params
,
config
=
config
)
loggers
.
append
(
log_writer
)
else
:
vdl
_writer
=
None
log
_writer
=
None
print_dict
(
config
,
logger
)
if
loggers
:
log_writer
=
Loggers
(
loggers
)
else
:
log_writer
=
None
logger
.
info
(
'train with paddle {} and device {}'
.
format
(
paddle
.
__version__
,
device
))
return
config
,
device
,
logger
,
vdl
_writer
return
config
,
device
,
logger
,
log
_writer
Prev
1
2
3
Next
Write
Preview
Markdown
is supported
0%
Try again
or
attach a new file
.
Attach a file
Cancel
You are about to add
0
people
to the discussion. Proceed with caution.
Finish editing this message first!
Cancel
Please
register
or
sign in
to comment

{kind=link}
{kind=link}
{kind=link}
{kind=link}