
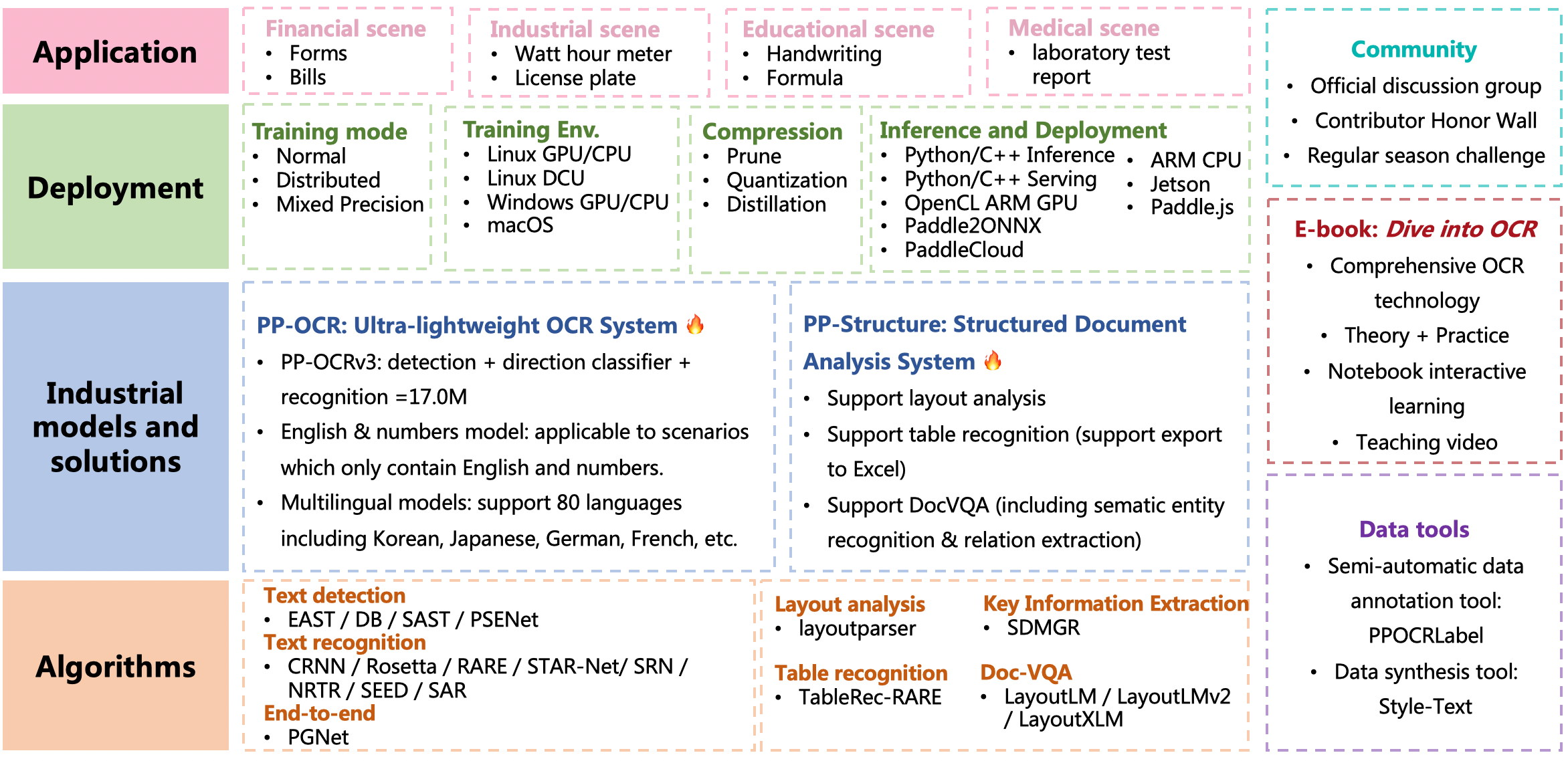
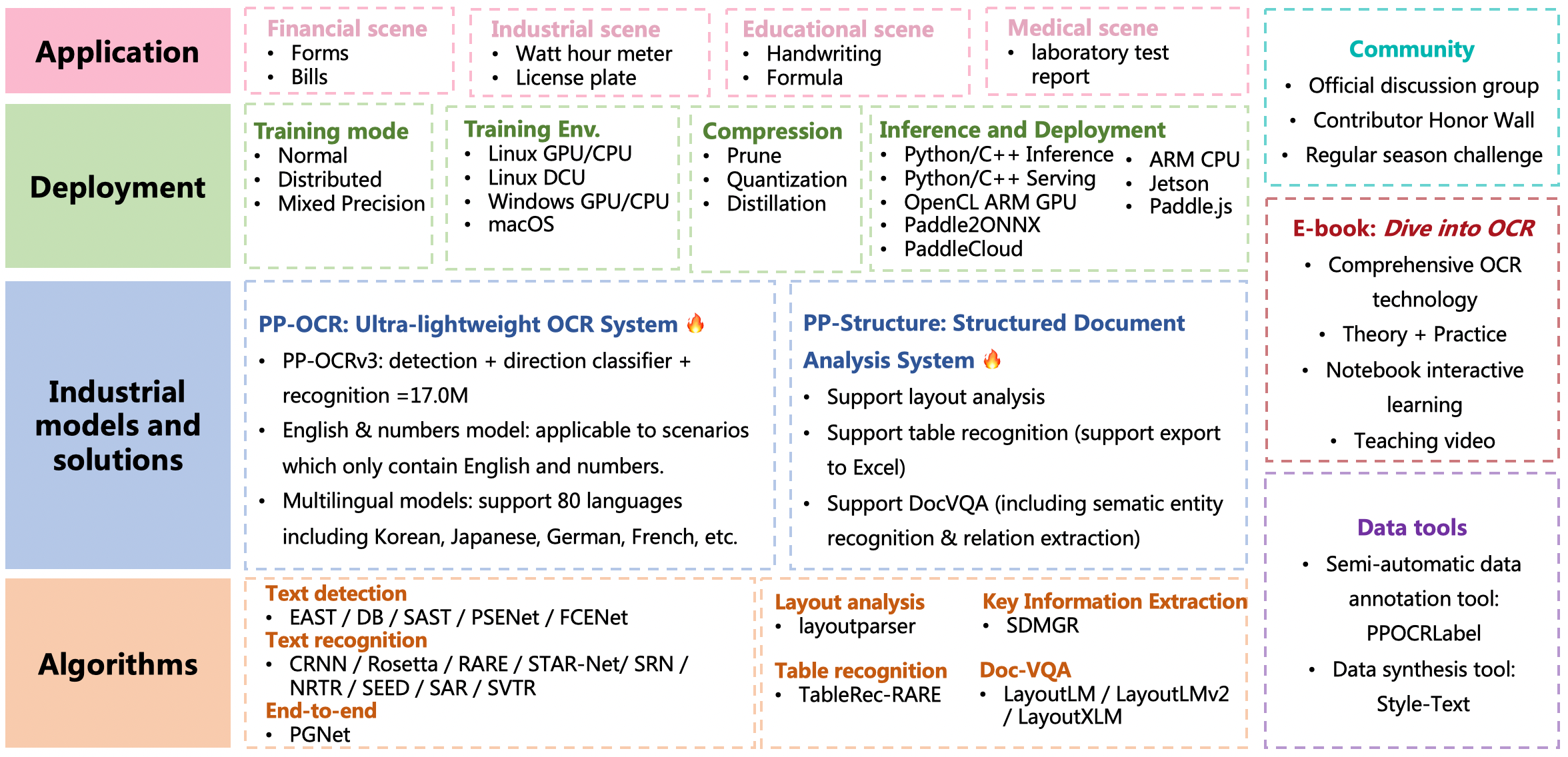
Merge branch 'release/2.5' of https://github.com/PaddlePaddle/PaddleOCR into release/2.5
Showing
deploy/paddlecloud/README.md
0 → 100644
{kind=link}
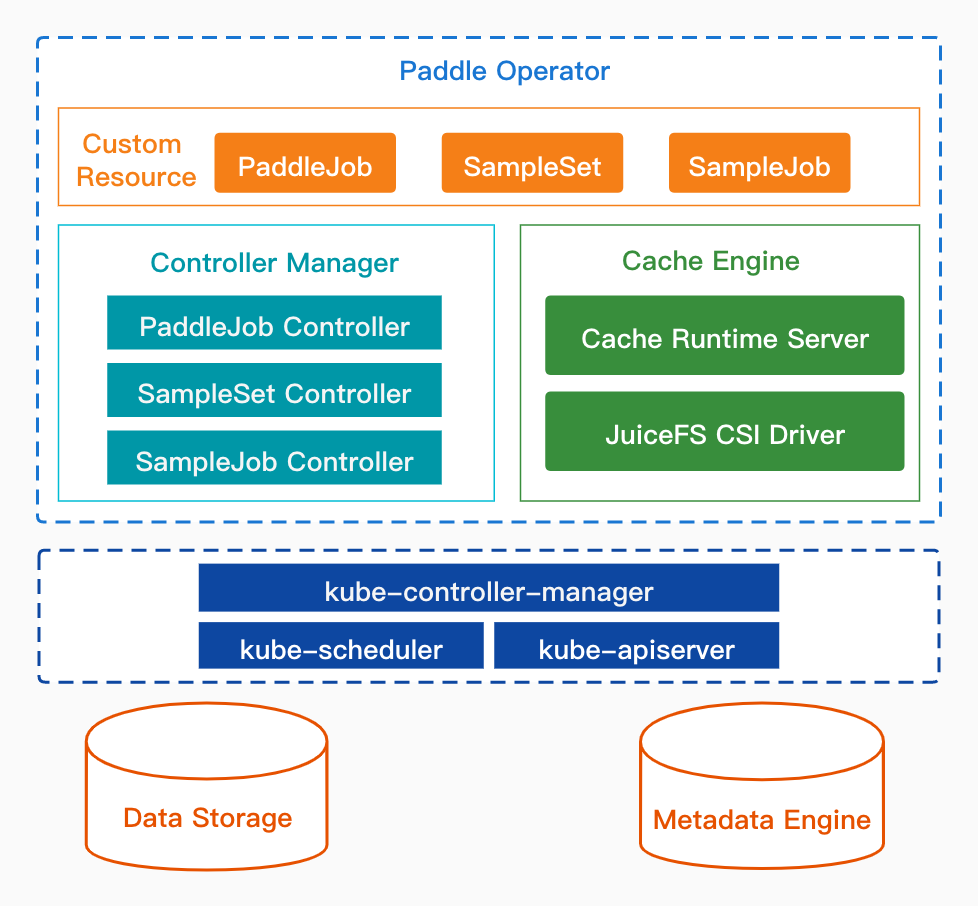
122 KB
{kind=link}
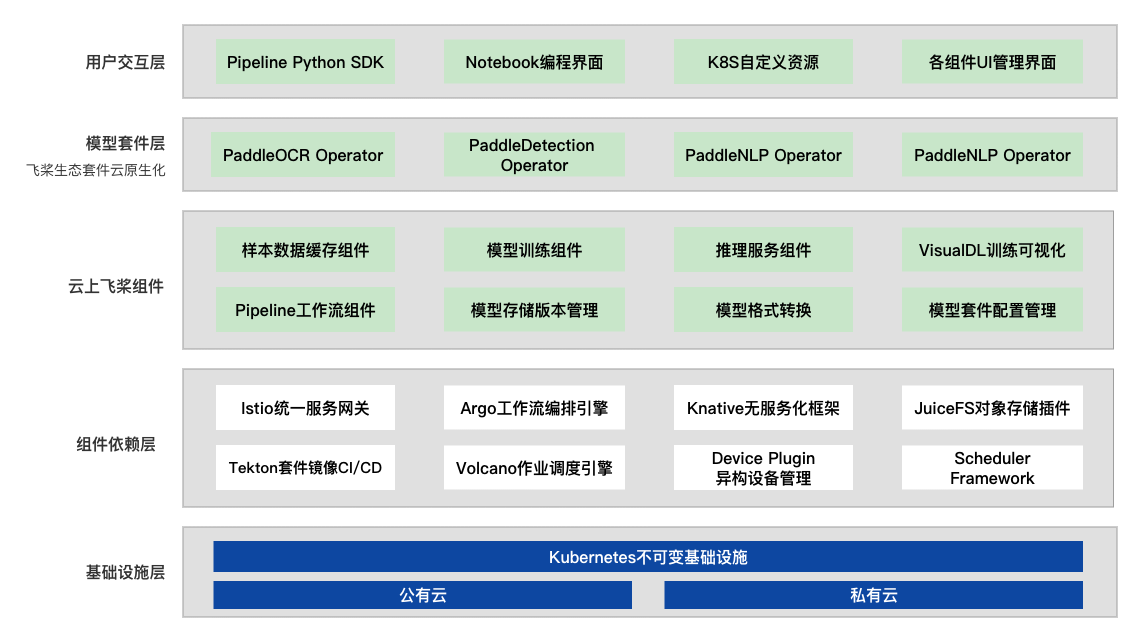
114 KB
{kind=link}
{kind=link}
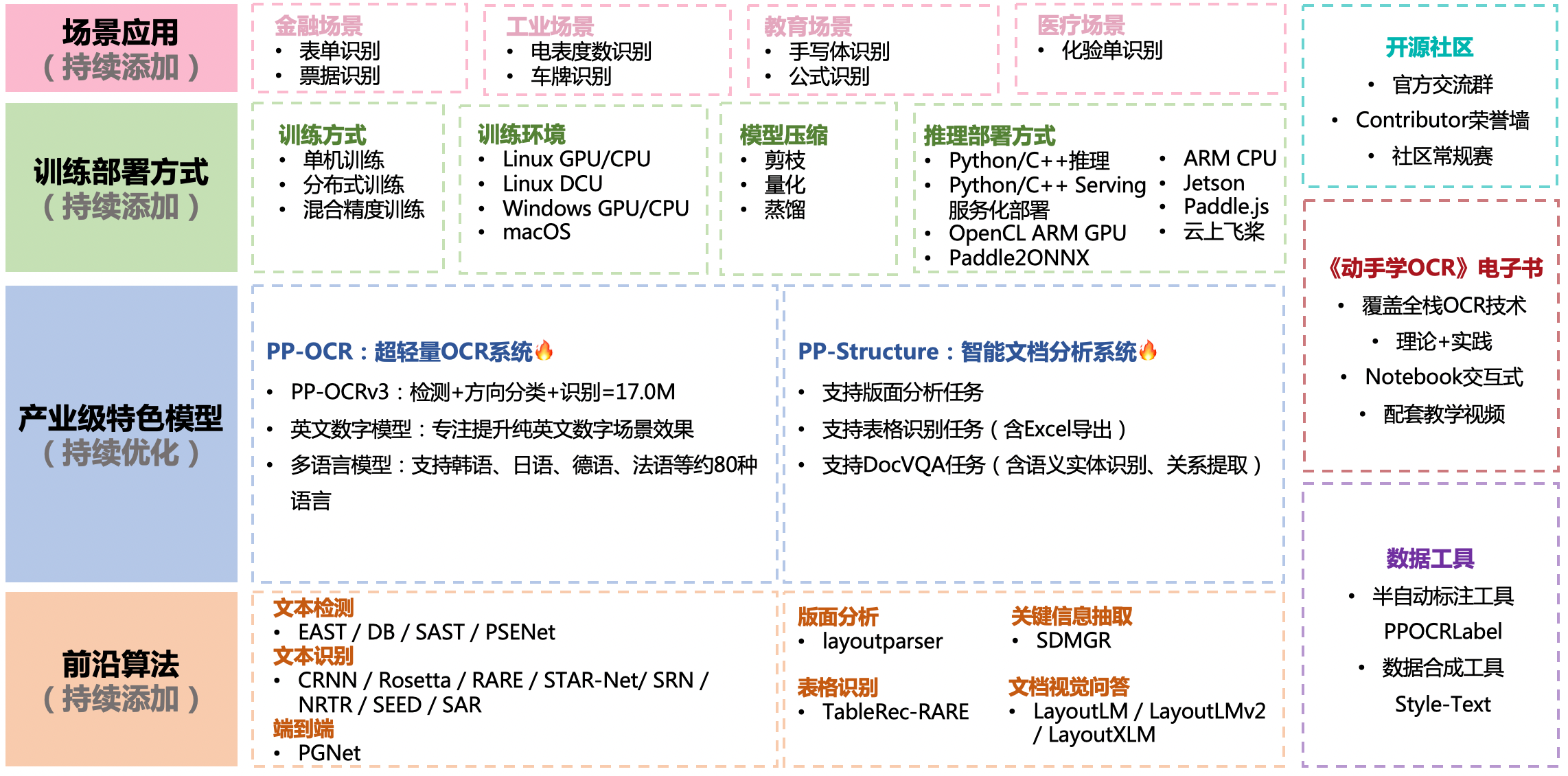
| W: | H:
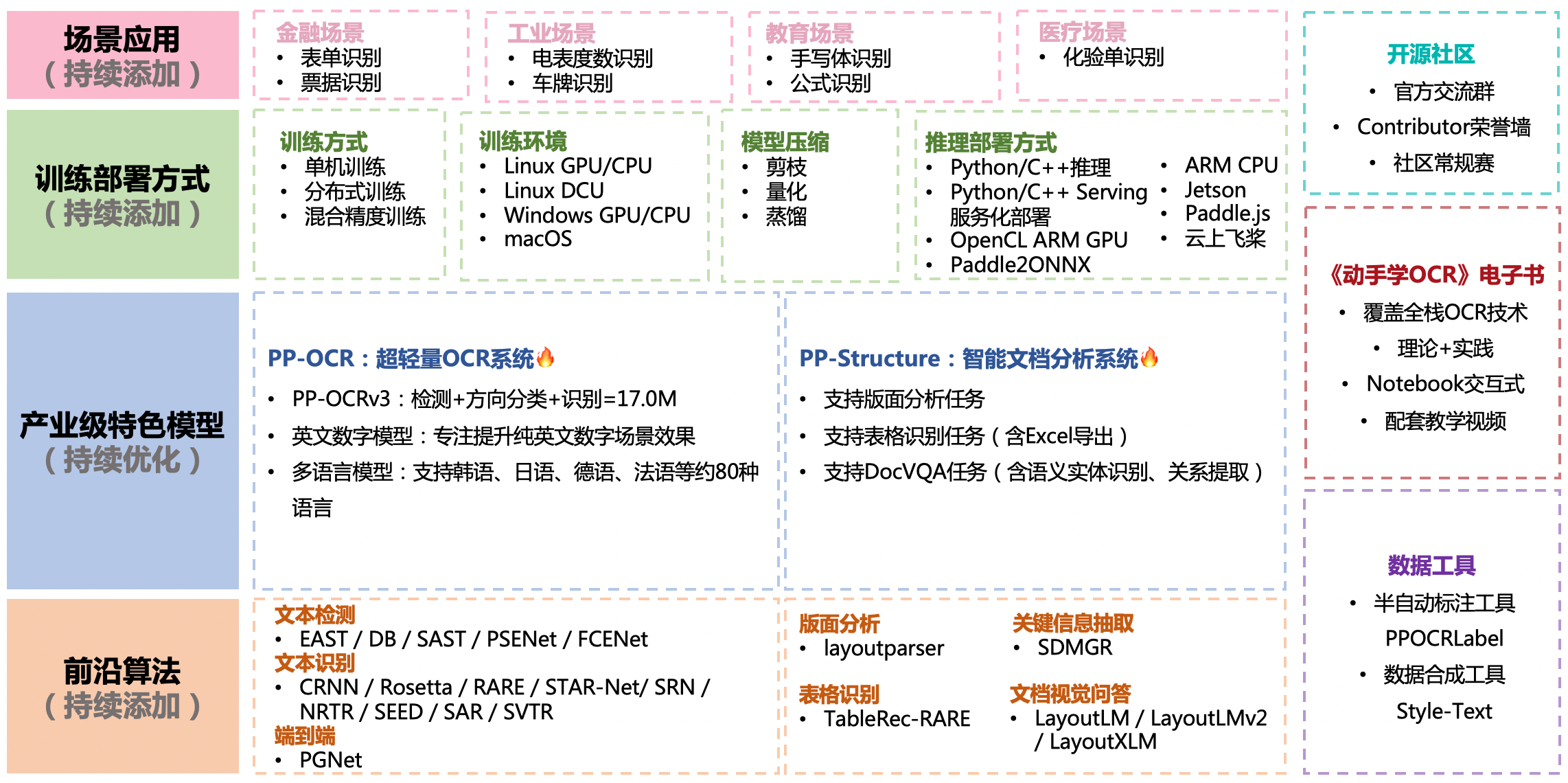
| W: | H:
{kind=link}
{kind=link}
| W: | H:
| W: | H:
This diff is collapsed.
This diff is collapsed.
This diff is collapsed.
This source diff could not be displayed because it is too large. You can view the blob instead.