@@ -122,14 +122,14 @@ In ppocr, the network is divided into four stages: Transform, Backbone, Neck and
| num_workers | The number of sub-processes used to load data, if it is 0, the sub-process is not started, and the data is loaded in the main process | 8 | \ |
## MULTILINGUAL CONFIG FILE GENERATION
## 3. MULTILINGUAL CONFIG FILE GENERATION
PaddleOCR currently supports 80 (except Chinese) language recognition. A multi-language configuration file template is
provided under the path `configs/rec/multi_languages`: [rec_multi_language_lite_train.yml](../../configs/rec/multi_language/rec_multi_language_lite_train.yml)。
There are two ways to create the required configuration file::
### Automatically generated by script
1. Automatically generated by script
[generate_multi_language_configs.py](../../configs/rec/multi_language/generate_multi_language_configs.py) Can help you generate configuration files for multi-language models
...
...
@@ -176,7 +176,7 @@ There are two ways to create the required configuration file::
```
Italian is made up of Latin letters, so after executing the command, you will get the rec_latin_lite_train.yml.
### Manually modify the configuration file
2. Manually modify the configuration file
You can also manually modify the following fields in the template:
...
...
@@ -203,3 +203,25 @@ Italian is made up of Latin letters, so after executing the command, you will ge
...
```
Currently, the multi-language algorithms supported by PaddleOCR are:
| Configuration file | Algorithm name | backbone | trans | seq | pred | language | character_type |
For more supported languages, please refer to : [Multi-language model](https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.1/doc/doc_en/multi_languages_en.md#4-support-languages-and-abbreviations)
The multi-language model training method is the same as the Chinese model. The training data set is 100w synthetic data. A small amount of fonts and test data can be downloaded using the following two methods.
*[1.4 LOAD TRAINED MODEL AND CONTINUE TRAINING](#14-load-trained-model-and-continue-training)
*[1.5 TRAINING WITH NEW BACKBONE](#15-training-with-new-backbone)
*[1.6 EVALUATION](#16-evaluation)
*[1.7 TEST](#17-test)
*[1.8 INFERENCE MODEL PREDICTION](#18-inference-model-prediction)
-[2. FAQ](#2-faq)
# 1. TEXT DETECTION
This section uses the icdar2015 dataset as an example to introduce the training, evaluation, and testing of the detection model in PaddleOCR.
## DATA PREPARATION
## 1.1 DATA PREPARATION
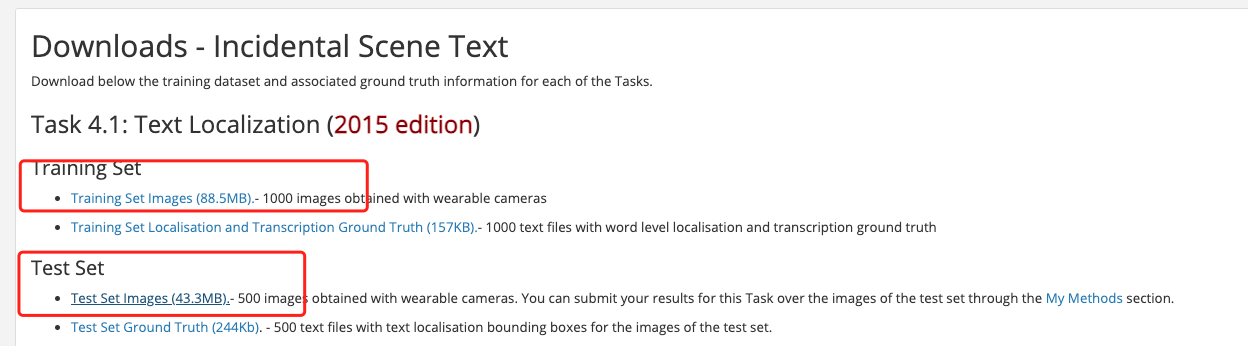
The icdar2015 dataset can be obtained from [official website](https://rrc.cvc.uab.es/?ch=4&com=downloads). Registration is required for downloading.
After registering and logging in, download the part marked in the red box in the figure below. And, the content downloaded by `Training Set Images` should be saved as the folder `icdar_c4_train_imgs`, and the content downloaded by `Test Set Images` is saved as the folder `ch4_test_images`
Decompress the downloaded dataset to the working directory, assuming it is decompressed under PaddleOCR/train_data/. In addition, PaddleOCR organizes many scattered annotation files into two separate annotation files for train and test respectively, which can be downloaded by wget:
```shell
# Under the PaddleOCR path
...
...
@@ -36,10 +58,11 @@ The `points` in the dictionary represent the coordinates (x, y) of the four poin
If you want to train PaddleOCR on other datasets, please build the annotation file according to the above format.
## TRAINING
## 1.2 DOWNLOAD PRETRAINED MODEL
First download the pretrained model. The detection model of PaddleOCR currently supports 3 backbones, namely MobileNetV3, ResNet18_vd and ResNet50_vd. You can use the model in [PaddleClas](https://github.com/PaddlePaddle/PaddleClas/tree/release/2.0/ppcls/modeling/architectures) to replace backbone according to your needs.
And the responding download link of backbone pretrain weights can be found in (https://github.com/PaddlePaddle/PaddleClas/blob/release%2F2.0/README_cn.md#resnet%E5%8F%8A%E5%85%B6vd%E7%B3%BB%E5%88%97).
First download the pretrained model. The detection model of PaddleOCR currently supports 3 backbones, namely MobileNetV3, ResNet18_vd and ResNet50_vd. You can use the model in [PaddleClas](https://github.com/PaddlePaddle/PaddleClas/tree/develop/ppcls/modeling/architectures) to replace backbone according to your needs.
And the responding download link of backbone pretrain weights can be found in [PaddleClas repo](https://github.com/PaddlePaddle/PaddleClas#mobile-series).
If you expect to load trained model and continue the training again, you can specify the parameter `Global.checkpoints` as the model path to be loaded.
**Note**: The priority of `Global.checkpoints` is higher than that of `Global.pretrain_weights`, that is, when two parameters are specified at the same time, the model specified by `Global.checkpoints` will be loaded first. If the model path specified by `Global.checkpoints` is wrong, the one specified by `Global.pretrain_weights` will be loaded.
## EVALUATION
## 1.5 TRAINING WITH NEW BACKBONE
The network part completes the construction of the network, and PaddleOCR divides the network into four parts, which are under [ppocr/modeling](../../ppocr/modeling). The data entering the network will pass through these four parts in sequence(transforms->backbones->
necks->heads).
```bash
├── architectures # Code for building network
├── transforms # Image Transformation Module
├── backbones # Feature extraction module
├── necks # Feature enhancement module
└── heads # Output module
```
If the Backbone to be replaced has a corresponding implementation in PaddleOCR, you can directly modify the parameters in the `Backbone` part of the configuration yml file.
However, if you want to use a new Backbone, an example of replacing the backbones is as follows:
1. Create a new file under the [ppocr/modeling/backbones](../../ppocr/modeling/backbones) folder, such as my_backbone.py.
2. Add code in the my_backbone.py file, the sample code is as follows:
```python
importpaddle
importpaddle.nnasnn
importpaddle.nn.functionalasF
classMyBackbone(nn.Layer):
def__init__(self,*args,**kwargs):
super(MyBackbone,self).__init__()
# your init code
self.conv=nn.xxxx
defforward(self,inputs):
# your network forward
y=self.conv(inputs)
returny
```
3. Import the added module in the [ppocr/modeling/backbones/\__init\__.py](../../ppocr/modeling/backbones/__init__.py) file.
After adding the four-part modules of the network, you only need to configure them in the configuration file to use, such as:
```yaml
Backbone:
name:MyBackbone
args1:args1
```
**NOTE**: More details about replace Backbone and other mudule can be found in [doc](add_new_algorithm_en.md).
## 1.6 EVALUATION
PaddleOCR calculates three indicators for evaluating performance of OCR detection task: Precision, Recall, and Hmean.
PaddleOCR calculates three indicators for evaluating performance of OCR detection task: Precision, Recall, and Hmean(F-Score).
Run the following code to calculate the evaluation indicators. The result will be saved in the test result file specified by `save_res_path` in the configuration file `det_db_mv3.yml`
...
...
@@ -95,10 +171,9 @@ The model parameters during training are saved in the `Global.save_model_dir` di
* Note: `box_thresh` and `unclip_ratio` are parameters required for DB post-processing, and not need to be set when evaluating the EAST and SAST model.
* Note: `box_thresh` and `unclip_ratio` are parameters required for DB post-processing, and not need to be set when evaluating the EAST model.
The inference model (the model saved by `paddle.jit.save`) is generally a solidified model saved after the model training is completed, and is mostly used to give prediction in deployment.
The model saved during the training process is the checkpoints model, which saves the parameters of the model and is mostly used to resume training.
Compared with the checkpoints model, the inference model will additionally save the structural information of the model. Therefore, it is easier to deploy because the model structure and model parameters are already solidified in the inference model file, and is suitable for integration with actual systems.
Firstly, we can convert DB trained model to inference model:
Q1: The prediction results of trained model and inference model are inconsistent?
**A**: Most of the problems are caused by the inconsistency of the pre-processing and post-processing parameters during the prediction of the trained model and the pre-processing and post-processing parameters during the prediction of the inference model. Taking the model trained by the det_mv3_db.yml configuration file as an example, the solution to the problem of inconsistent prediction results between the training model and the inference model is as follows:
- Check whether the [trained model preprocessing](https://github.com/PaddlePaddle/PaddleOCR/blob/c1ed243fb68d5d466258243092e56cbae32e2c14/configs/det/det_mv3_db.yml#L116) is consistent with the prediction [preprocessing function of the inference model](https://github.com/PaddlePaddle/PaddleOCR/blob/c1ed243fb68d5d466258243092e56cbae32e2c14/tools/infer/predict_det.py#L42). When the algorithm is evaluated, the input image size will affect the accuracy. In order to be consistent with the paper, the image is resized to [736, 1280] in the training icdar15 configuration file, but there is only a set of default parameters when the inference model predicts, which will be considered To predict the speed problem, the longest side of the image is limited to 960 for resize by default. The preprocessing function of the training model preprocessing and the inference model is located in [ppocr/data/imaug/operators.py](https://github.com/PaddlePaddle/PaddleOCR/blob/c1ed243fb68d5d466258243092e56cbae32e2c14/ppocr/data/imaug/operators.py#L147)
- Check whether the [post-processing of the trained model](https://github.com/PaddlePaddle/PaddleOCR/blob/c1ed243fb68d5d466258243092e56cbae32e2c14/configs/det/det_mv3_db.yml#L51) is consistent with the [post-processing parameters of the inference](https://github.com/PaddlePaddle/PaddleOCR/blob/c1ed243fb68d5d466258243092e56cbae32e2c14/tools/infer/utility.py#L50).
- Select `Anaconda3-2021.05-MacOSX-x86_64.pkg` at the bottom to download
- After downloading, double click on the .pkg file to enter the graphical interface
- Just follow the default settings, it will take a while to install
- It is recommended to install a code editor such as vscode or pycharm
#### 1.2.2 Open a terminal and create a conda environment
- Open the terminal
- Press command and spacebar at the same time, type "terminal" in the focus search, double click to enter terminal
-**Add conda to the environment variables**
- Environment variables are added so that the system can recognize the conda command
- Open `~/.bash_profile` in the terminal by typing the following command.
```shell
vim ~/.bash_profile
```
- Add conda as an environment variable in `~/.bash_profile`.
```shell
# Press i first to enter edit mode
# In the first line type.
export PATH="~/opt/anaconda3/bin:$PATH"
# If you customized the installation location during installation, change ~/opt/anaconda3/bin to the bin folder in the customized installation directory
```
```shell
# The modified ~/.bash_profile file should look like this (where xxx is the username)
export PATH="~/opt/anaconda3/bin:$PATH"
# >>> conda initialize >>>
# !!! Contents within this block are managed by 'conda init' !!!
- When you are done, press `esc` to exit edit mode, then type `:wq!` and enter to save and exit
- Verify that the conda command is recognized.
- Enter `source ~/.bash_profile` in the terminal to update the environment variables
- Enter `conda info --envs` in the terminal again, if it shows that there is a base environment, then conda has been added to the environment variables
- Create a new conda environment
```shell
# Enter the following command at the command line to create an environment called paddle_env
# Here to speed up the download, use Tsinghua source
The above anaconda environment and python environment are installed
<aname="1.3"></a>
### 1.3 Linux
Linux users can choose to run either Anaconda or Docker. If you are familiar with Docker and need to train the PaddleOCR model, it is recommended to use the Docker environment, where the development process of PaddleOCR is run. If you are not familiar with Docker, you can also use Anaconda to run the project.
#### 1.3.1 Anaconda environment configuration
- Note: To use paddlepaddle you need to install the python environment first, here we choose the python integrated environment Anaconda toolkit
- Anaconda is a common python package manager
- After installing Anaconda, you can install the python environment, as well as numpy and other required toolkit environment
- When you are done, press `esc` to exit edit mode, then type `:wq!` and enter to save and exit
- Verify that the conda command is recognized.
- Enter `source ~/.bash_profile` in the terminal to update the environment variables
- Enter `conda info --envs` in the terminal again, if it shows that there is a base environment, then conda has been added to the environment variables
- Create a new conda environment
```shell
# Enter the following command at the command line to create an environment called paddle_env
# Here to speed up the download, use Tsinghua source
For more software version requirements, please refer to the instructions in [Installation Document](https://www.paddlepaddle.org.cn/install/quick) for operation.
-[Paste Your Document In Here](#paste-your-document-in-here)
-[INTRODUCTION ABOUT OCR](#introduction-about-ocr)
*[BASIC CONCEPTS OF OCR DETECTION MODEL](#basic-concepts-of-ocr-detection-model)
*[Basic concepts of OCR recognition model](#basic-concepts-of-ocr-recognition-model)
*[PP-OCR model](#pp-ocr-model)
*[And a table of contents](#and-a-table-of-contents)
*[On the right](#on-the-right)
# INTRODUCTION ABOUT OCR
This section briefly introduces the basic concepts of OCR detection model and recognition model, and introduces PaddleOCR's PP-OCR model.
OCR (Optical Character Recognition, Optical Character Recognition) is currently the general term for text recognition. It is not limited to document or book text recognition, but also includes recognizing text in natural scenes. It can also be called STR (Scene Text Recognition).
OCR text recognition generally includes two parts, text detection and text recognition. The text detection module first uses detection algorithms to detect text lines in the image. And then the recognition algorithm to identify the specific text in the text line.
## BASIC CONCEPTS OF OCR DETECTION MODEL
Text detection can locate the text area in the image, and then usually mark the word or text line in the form of a bounding box. Traditional text detection algorithms mostly extract features manually, which are characterized by fast speed and good effect in simple scenes, but the effect will be greatly reduced when faced with natural scenes. Currently, deep learning methods are mostly used.
Text detection algorithms based on deep learning can be roughly divided into the following categories:
1. Method based on target detection. Generally, after the text box is predicted, the final text box is filtered through NMS, which is mostly four-point text box, which is not ideal for curved text scenes. Typical algorithms are methods such as EAST and Text Box.
2. Method based on text segmentation. The text line is regarded as the segmentation target, and then the external text box is constructed through the segmentation result, which can handle curved text, and the effect is not ideal for the text cross scene problem. Typical algorithms are DB, PSENet and other methods.
3. Hybrid target detection and segmentation method.
## Basic concepts of OCR recognition model
The input of the OCR recognition algorithm is generally text lines images which has less background information, and the text information occupies the main part. The recognition algorithm can be divided into two types of algorithms:
1. CTC-based method. The text prediction module of the recognition algorithm is based on CTC, and the commonly used algorithm combination is CNN+RNN+CTC. There are also some algorithms that try to add transformer modules to the network and so on.
2. Attention-based method. The text prediction module of the recognition algorithm is based on Attention, and the commonly used algorithm combination is CNN+RNN+Attention.
## PP-OCR model
PaddleOCR integrates many OCR algorithms, text detection algorithms include DB, EAST, SAST, etc., text recognition algorithms include CRNN, RARE, StarNet, Rosetta, SRN and other algorithms.
Among them, PaddleOCR has released the PP-OCR series model for the general OCR in Chinese and English natural scenes. The PP-OCR model is composed of the DB+CRNN algorithm. It uses massive Chinese data training and model tuning methods to have high text detection and recognition capabilities in Chinese scenes. And PaddleOCR has launched a high-precision and ultra-lightweight PP-OCRv2 model. The detection model is only 3M, and the recognition model is only 8.5M. Using [PaddleSlim](https://github.com/PaddlePaddle/PaddleSlim)'s model quantification method, the detection model can be compressed to 0.8M without reducing the accuracy. The recognition is compressed to 3M, which is more suitable for mobile deployment scenarios.
|ch_ppocr_server_v2.0_det|General model, which is larger than the lightweight model, but achieved better performance|[ch_det_res18_db_v2.0.yml](../../configs/det/ch_ppocr_v2.0/ch_det_res18_db_v2.0.yml)|47M|[inference model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_server_v2.0_det_infer.tar) / [trained model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_server_v2.0_det_train.tar)|
...
...
@@ -40,6 +42,8 @@ Relationship of the above models is as follows.
|ch_ppocr_mobile_slim_v2.0_rec|Slim pruned and quantized lightweight model, supporting Chinese, English and number recognition|[rec_chinese_lite_train_v2.0.yml](../../configs/rec/ch_ppocr_v2.0/rec_chinese_lite_train_v2.0.yml)| 6M | [inference model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_rec_slim_infer.tar) / [trained model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_rec_slim_train.tar) |
|ch_ppocr_mobile_v2.0_rec|Original lightweight model, supporting Chinese, English and number recognition|[rec_chinese_lite_train_v2.0.yml](../../configs/rec/ch_ppocr_v2.0/rec_chinese_lite_train_v2.0.yml)|5.2M|[inference model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_rec_infer.tar) / [trained model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_rec_train.tar) / [pre-trained model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_rec_pre.tar) |
|ch_ppocr_server_v2.0_rec|General model, supporting Chinese, English and number recognition|[rec_chinese_common_train_v2.0.yml](../../configs/rec/ch_ppocr_v2.0/rec_chinese_common_train_v2.0.yml)|94.8M|[inference model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_server_v2.0_rec_infer.tar) / [trained model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_server_v2.0_rec_train.tar) / [pre-trained model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_server_v2.0_rec_pre.tar) |
...
...
@@ -120,12 +124,14 @@ For more supported languages, please refer to : [Multi-language model](./multi_l
|ch_ppocr_mobile_slim_v2.0_cls|Slim quantized model for text angle classification|[cls_mv3.yml](../../configs/cls/cls_mv3.yml)| 2.1M | [inference model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_slim_infer.tar) / [trained model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_slim_train.tar) |
|ch_ppocr_mobile_v2.0_cls|Original model for text angle classification|[cls_mv3.yml](../../configs/cls/cls_mv3.yml)|1.38M|[inference model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar) / [trained model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_train.tar) |
<aname="Paddle-Lite"></a>
### 4. Paddle-Lite Model
|Version|Introduction|Model size|Detection model|Text Direction model|Recognition model|Paddle-Lite branch|
|---|---|---|---|---|---|---|
|V2.0|extra-lightweight chinese OCR optimized model|7.8M|[download link](https://paddleocr.bj.bcebos.com/dygraph_v2.0/lite/ch_ppocr_mobile_v2.0_det_opt.nb)|[download link](https://paddleocr.bj.bcebos.com/dygraph_v2.0/lite/ch_ppocr_mobile_v2.0_cls_opt.nb)|[download link](https://paddleocr.bj.bcebos.com/dygraph_v2.0/lite/ch_ppocr_mobile_v2.0_rec_opt.nb)|v2.9|
|V2.0(slim)|extra-lightweight chinese OCR optimized model|3.3M|[download link](https://paddleocr.bj.bcebos.com/dygraph_v2.0/lite/ch_ppocr_mobile_v2.0_det_slim_opt.nb)|[download link](https://paddleocr.bj.bcebos.com/dygraph_v2.0/lite/ch_ppocr_mobile_v2.0_cls_slim_opt.nb)|[download link](https://paddleocr.bj.bcebos.com/dygraph_v2.0/lite/ch_ppocr_mobile_v2.0_rec_slim_opt.nb)|v2.9|
|V2.1|ppocr_v2.1 extra-lightweight chinese OCR optimized model|11M|[download link](https://paddleocr.bj.bcebos.com/dygraph_v2.1/chinese/ch_ppocr_mobile_v2.1_det_infer_opt.nb)|[download link](https://paddleocr.bj.bcebos.com/dygraph_v2.0/lite/ch_ppocr_mobile_v2.0_cls_opt.nb)|[download link](https://paddleocr.bj.bcebos.com/dygraph_v2.1/chinese/ch_ppocr_mobile_v2.1_rec_infer_opt.nb)|v2.9|
|V2.1(slim)|extra-lightweight chinese OCR optimized model|4.9M|[download link](https://paddleocr.bj.bcebos.com/dygraph_v2.1/chinese/ch_ppocr_mobile_v2.1_det_slim_opt.nb)|[download link](https://paddleocr.bj.bcebos.com/dygraph_v2.0/lite/ch_ppocr_mobile_v2.0_cls_slim_opt.nb)|[download link](https://paddleocr.bj.bcebos.com/dygraph_v2.1/chinese/ch_ppocr_mobile_v2.1_rec_slim_opt.nb)|v2.9|
|V2.0|ppocr_v2.0 extra-lightweight chinese OCR optimized model|7.8M|[download link](https://paddleocr.bj.bcebos.com/dygraph_v2.0/lite/ch_ppocr_mobile_v2.0_det_opt.nb)|[download link](https://paddleocr.bj.bcebos.com/dygraph_v2.0/lite/ch_ppocr_mobile_v2.0_cls_opt.nb)|[download link](https://paddleocr.bj.bcebos.com/dygraph_v2.0/lite/ch_ppocr_mobile_v2.0_rec_opt.nb)|v2.9|
|V2.0(slim)|ppovr_v2.0 extra-lightweight chinese OCR optimized model|3.3M|[download link](https://paddleocr.bj.bcebos.com/dygraph_v2.0/lite/ch_ppocr_mobile_v2.0_det_slim_opt.nb)|[download link](https://paddleocr.bj.bcebos.com/dygraph_v2.0/lite/ch_ppocr_mobile_v2.0_cls_slim_opt.nb)|[download link](https://paddleocr.bj.bcebos.com/dygraph_v2.0/lite/ch_ppocr_mobile_v2.0_rec_slim_opt.nb)|v2.9|
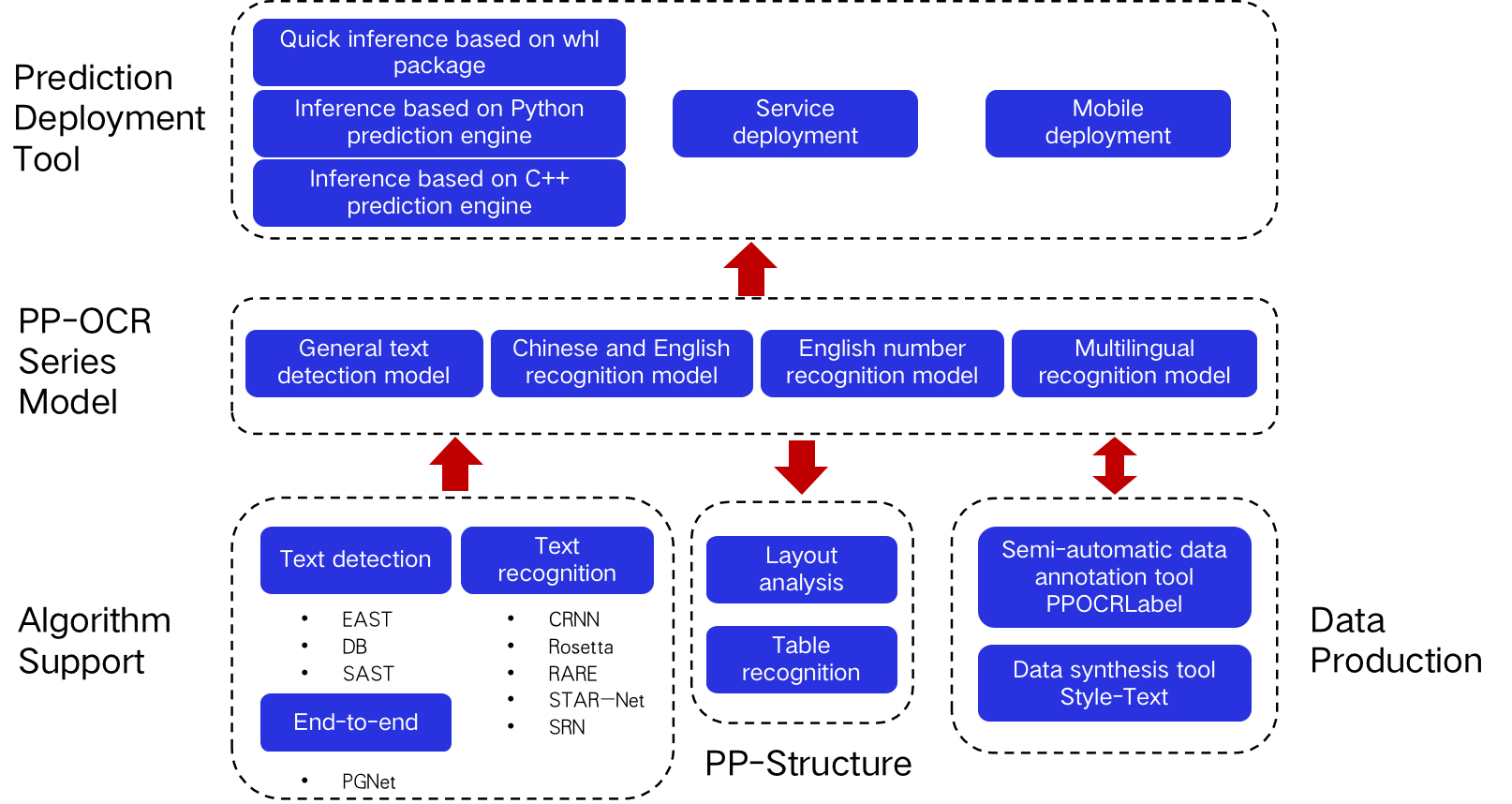
PaddleOCR contains rich text detection, text recognition and end-to-end algorithms. Combining actual testing and industrial experience, PaddleOCR chooses DB and CRNN as the basic detection and recognition models, and proposes a series of models, named PP-OCR, for industrial applications after a series of optimization strategies. The PP-OCR model is aimed at general scenarios and forms a model library according to different languages. Based on the capabilities of PP-OCR, PaddleOCR releases the PP-Structure tool library for document scene tasks, including two major tasks: layout analysis and table recognition. In order to get through the entire process of industrial landing, PaddleOCR provides large-scale data production tools and a variety of prediction deployment tools to help developers quickly turn ideas into reality.
# Note: The cloud-hosting code may not be able to synchronize the update with this GitHub project in real time. There might be a delay of 3-5 days. Please give priority to the recommended method.
```
### **2.2 Install third-party libraries**
```
cd PaddleOCR
pip3 install -r requirements.txt
```
If you getting this error `OSError: [WinError 126] The specified module could not be found` when you install shapely on windows.
Please try to download Shapely whl file using [http://www.lfd.uci.edu/~gohlke/pythonlibs/#shapely](http://www.lfd.uci.edu/~gohlke/pythonlibs/#shapely).
Reference: [Solve shapely installation on windows](
For more software version requirements, please refer to the instructions in [Installation Document](https://www.paddlepaddle.org.cn/install/quick) for operation.
<aname="12-install-paddleocr-whl-package"></a>
### 1.2 Install PaddleOCR Whl Package
## 1. Install PaddleOCR Whl Package
```bash
pip install"paddleocr>=2.0.1"# Recommend to use version 2.0.1+
...
...
@@ -59,7 +41,7 @@ pip install "paddleocr>=2.0.1" # Recommend to use version 2.0.1+
### 2.1 Use by command line
PaddleOCR provides a series of test images, click xx to download, and then switch to the corresponding directory in the terminal
PaddleOCR provides a series of test images, click [here](https://paddleocr.bj.bcebos.com/dygraph_v2.1/ppocr_img.zip) to download, and then switch to the corresponding directory in the terminal

{kind=link}
{kind=link}
{kind=link}